P
Q
∼P (NOT)
~Q
P ∧ Q
P ∨ Q
P  Q
Q
P → Q (IMPLIES)
P ↔ Q (EQUIVALENT)
T
T
F
F
T
F
T
F
F
F
T
T
F
T
F
T
T
F
F
F
T
T
T
F
F
T
T
F
T
F
T
T
T
F
F
T
논리와 불확실성
(Logic and Uncertainty)
C 인공지능 프로그래밍 : Herbert Schildt 지음, 신경숙.류성렬 옮김, 세웅, 1991 (원서 : Artificial Intelligence using C, McGraw-Hill, 1987), page 341~404
1.1. 논리의 간단한 역사 (A short History of Logic)
1.2. 명제논리 (Propositional Logic)
1.3. 술어논리 (Predicate Calculus)
4. 확률시스템 (PROBABILISTIC SYSTEMS)
4.1. 기본 확률 이론 (Basic probability Theory)
4.2. 전통적인 확률이론을 전문가시스템에 적용 (Applying Classical Probability Theory to Expert Systems)
4.3. Weakest-Link 방식 (The Weakest-Link Approach)
4.4. Strongest-Link 방식 (The Strongest-Link Approach)
4.5. 방법 선택 (Choosing a Method)
이 장에서는 기계 지능 (machine intelligence) 과 밀접히 관계있는 두가지 중요한 개념을 다룬다. 첫 번째 개념은 불확실성 또는 더 정확히 논리 문장에서 불확실성의 해결 (resolution) 이다. 명백히, 많은 지식은 특히 관찰에서 얻어진다면 어느 정도 개연성이 있다 (probabilistic) : 즉, 어떤 것에 대하여 에러 가능성을 여전히 허용하는 반면 참이라고 믿을 수 있다. 컴퓨터가 인간과 같이 생각하고 추론하기 위하여, 이 불확실성을 논리와 통합할 것이 요구된다.
논리의 개념을 설명하기 위해, 이 장에서는 두 개의 프로그램을 개발한다. 첫 번째 프로그램은 어떤 논리적 변형 (transformation) 을 수행하고, 두 번째 프로그램은 논리 표현에 대한 간단한 자기호출 하향파서 (recursive-descent parser) 를 구현한다. 마지막으로, 논리와 불확실성을 연결하는 예로서, 이 장에서는 제 3 장에서 개발된 전문가시스템이 각 속성 (attribute) 에 확실성 계수 (certainty coefficient) 를 포함하도록 변형한다. 그리고 나서 해에 대한 확실성 요소를 생성하기 위하여 이 확실성 계수들을 사용한다.
논리는 컴퓨터 프로그램의 중심이다. 여러 면에서, 프로그래밍 언어는 단순히 특별한 형태의 논리를 구현한 것이다. C 와 같은 언어에서, 논리는 if 문의 사용에 의해 알 수 있는 것처럼, 일반적으로 절차적 (procedural) 이지만, 프롤로그와 같은 언어는 나중에 설명될, 술어논리 (predicate calculus) 라 부르는 특별한 유형의 논리를 사용한다. 그러나, 어떤 타입의 언어에서든 논리는 프로그래밍의 중추를 형성한다. AI 에 대한 논리의 중요성 때문에 그 역사를 간단히 살펴본다.
최초로 알려진 논리학자는 그리스의 철학자이자 자연과학자인 Aristoteles 이었다. 그는, 현재 추론논리 (syllogistic logic) 또는 고전 논리 (classic logic) 라고 부르는 이론을 개발했다. 기본적으로 추론논리는 철학적 논쟁으로부터 진리 (또는 거짓) 을 이끌어내는 것을 다룬다. 이런 유형의 논리는 사실상 모든 합리적 논쟁의 기초이기 때문에 아직도 널리 사용된다. 예를들어, 다음의 짧은 논쟁을 공부해 보자 :
존이 남성이 되기 전에 소년이었다는 것은 상식적으로 알 수 있다. 추론 형태로 변형된 후에 이 논쟁은 다음과 같이 된다.
여기서 기호, J, M, B 는 각각 John, Man, Boys 를 의미한다. → 를 "의미한다 (implies)" 또는 "이다 (is)" 로 읽어라.
여러면에서, 추론논리는 단순히 상식을 형식화한 것이다. 그러나, 추론 논리는 자연언어에 기호하기 때문에 종종 부정확하고 오해의 소지가 있는 자연언어의 잠재적 결점 때문에 어려움이 있다. 또한, 사람들은 선택해서 듣거나 읽으려는 경향이 있는데 이것이 더 혼란을 일으킬 수 있다. 이러한 정확성의 부족 때문에 결국 기호논리가 나오게 되었다.
기호논리는 Gottfried Leibnitz 가 시작했지만 그가 죽은 후 잊혀졌다. 그것을 발명했다고 인정되는 사람인 George Boole 에 의해 전 분야가 다시 발견되었다. 이런 유형의 논리를 일반적으로 불리언 논리하고 부른다. 기호논리는 개념을 기호로 추상화하고, 연산자를 사용하여 이 기호를 연결한다. 예를들어, 다음을 공부해보자 :
기호논리는 대부분의 절차적 (procedural) 프로그래밍 언어의 기초를 형성하는데, 이 장에서 초점을 둘 논리의 형태이다.
기호논리는 두가지 구별되는, 하지만 연결되는 분야가 있다 : 첫 번째로 명제논리 (propositional logic) 이고 다른 하나는 술어논리 (predicate logic) 이다. 명제논리는 명제의 참과 거짓을 다루는 반면, 술어논리는 대상 (object) 과 대상의 부류 (class) 사이의 관계도 포함한다.
명제논리는 여러 명제의 옳고 그름에 대한 결정을 다룬다. 명제는 적당히 형성된, 참이나 거짓인 문장이다. 명제논리는 명제들을 연결하기 위하여 연산자들을 사용한다. 대부분 흔히 쓰이는 연산자들은 다음과 같다 : AND, OR, NOT, IMPLIES, EQUIVALENT
예를들어, 두 개의 명제 P 와 Q 를 가정하자. 다음의 진리표는 P 와 Q 의 다른 값들에 연산자들을 적용한 후의 각 연산에 대한 결과 값을 보여준다.
P |
Q |
∼P (NOT) |
~Q |
P ∧ Q |
P ∨ Q |
P |
P → Q (IMPLIES) |
P ↔ Q (EQUIVALENT) |
T T F F |
T F T F |
F F T T |
F T F T |
T F F F |
T T T F |
F T T F |
T F T T |
T F F T |
이 연산들은, 사실상 모든 프로그래밍 언어와 프로그램 제어의 기초로서 명제논리를 사용하기 때문에 잘 알아야 한다. 이 연산자들을 사용하여 다음에 있는 것처럼, 복잡한 수식을 만들어 낼 수 있다 :
A AND B OR C AND NOT D
이 수식은 왼쪽에서 오른쪽으로 값이 결정된다 (evaluate). 수식에 괄호를 첨가시키면 수학에서와 같은 방법으로 기능을 한다 : 괄호는 그 안에 있는 수식의 일부 (subexpression) 의 우선순위를 높인다. 다음 수식은 방금 주어진 수식의 자연적인 계산순서 (evaluation order) 를 보여주기 위하여 괄호를 사용한다.
(A AND B) OR (C AND NOT D)
여기서, 괄호는 자연적인 계산 순서를 바꾸기 위하여 사용된다 :
A AND (B OR (C AND NOT D))
많은 다른 법칙들이 수식의 조작을 통제한다. 첫 번째 법칙은 교환법칙이다. 이것은 다음과 같다.
P AND Q ↔ Q AND P
P OR Q ↔ Q OR P
여기서 ↔ 는 "~와 같다" 를 의미한다.
결합법칙은 다음과 같다.
(P AND Q) AND R ↔ P AND (Q AND R)
(P OR Q) OR R ↔ P OR (Q OR R)
좀 더 중요한 법칙중의 하나가 드모르강의 법칙인데, 다음과 같다.
NOT (P OR Q) ↔ NOT P AND NOT Q
NOT (P AND Q) ↔ NOT P OR NOT Q
배분법칙은 다음을 말한다.
P AND (Q OR R) ↔ (P AND Q) OR (P AND R)
P OR (Q AND R) ↔ (P OR Q) AND (P OR R)
C 자체가 명제논리를 지원하기 때문에, 이러한 변환규칙 (transformation rule) 을 적용할 C 프로그램을 작성하는 것은 아주 쉽다. 예를들어, 출발점으로서 다음 프로그램을 사용할 수 있다. 이 프로그램은 드모르강 변환을 수행한다. 프로그램은 아주 짧고, 그것의 동작은 명백해야 한다. 주요 루틴인 transform() 은, 먼저 어떤 유형의 수식이 있는지를 결정하고 그리고나서 요구되는대로 변을 수행함으로써 대부분의 일을 한다.
|
/* Logical transformation program for DeMorgan's laws */
char input[80]; char token[80];
char *p_pos;
main() { for (; ;) { printf(" : "); gets(input) if (!*input) break; p_pos=input; transform(); } }
/* do the transformations */ transform() { char p[80], q[80], s[4]; char is_and;
/* try DeMorgan's theorems */ /* first, try form : not (p or q) ==> not p and not q */ get_token(); if (!strcmp(token, "not")) { get_token(); if (*token=='(') { get_token(); strcpy(p, token); get_token(); if (!strcmp(token, "and")) is_and=1; else is_and=0; get_token(); strcpy(q, token); get_token(); if (*token==')') { /* is a DeMorgan expression */ if (is_and) strcpy(s, "or"); else strcpy(s, "and"); printf("not %s %s not %s \n", p, s, q); return; } } } /* now try reverse transformation of form
not p or q ==> not (p and q)
*/ p_pos=input; /* reset */ get_token(); if (!strcmp(token, "not")) { get_token(); strcpy(p, token); get_token(); if (!strcmp(token, "and")) is_and=1; else is_and=0; get_token(); if (!strcmp(token, "not")) { get_token(); strcpy(q, token); if (is_and) strcpy(s, "or"); else strcpy(s, "and"); printf("not (%s %s %s) \n", p, s, q); } } }
/* return a token from the input stream */ get_token() { char *p;
p=token; /* skip spaces */ while (*p_pos==' ') p_pos++;
if (*p_pos=='\0') { /* is end of input */ *p++='\0'; return; } if (is_in(*p_pos, "()")) { *p=*p_pos; p++, p_pos++; *p='\0'; return; }
/* read word until */ while (*p_pos!=' ' && !is_in(*p_pos, "()")) { *p=*p_pos++; p++; } *p='\0': }
is_in(c, s) char c, *s; { while (*s) { if (c==*s) return 1; s++; } return 0; } |
이 프로그램을 사용하기 위해, 유효한 수식을 넣어라. 그러면 프로그램은 변환을 디스플레이할 것이다. 예를들어,
|
not (a and b) |
를 입력하면 프로그램은 변환 (드모르강의 법칙에 의해서)
|
not a or not b |
를 디스플레이할 것이다.
나머지 변환규칙들을 구현하는 것이 재미있다는 것을 알 수 있을 것이다. 또한, 단순히 답을 프린트하는 대신, transform() 으로 하여금 자신에게 반복적으로 (recursively) 전달한 스트링을 생성하게 하여 다중변환 (multiple transformations) 을 허용할 수 있다.
명제논리가 비록 지능과 컴퓨터 언어에 대한 기초를 형성하지만, 그것만으로 세계에 대한 인간의 지식을 표현하기 위하여 그것을 사용할 수는 없다. 명제논리는 대상들 사이의 관계를 표현하는 능력이 부족하기 때문에, 주어진 경우에 대한 옳고 그름을 결정하는 데에만 한정되고 분류 (classifications) 에서는 사용될 수 없다. 이 부족은 다음 절의 주제인 술어논리로 이끈다.
술어논리는 미적분학 (calculus) 이라고 하는 더 높은 수학의 가지와 관계가 전혀 없다. 때로 predicate logic 이라고 불리는 predicate calculus 는 단순히, 개개의 대상들에 대한 문장이 진리값을 위하여 검토되게 하는 명제논리를 확장한 것이다.
술어논리에 대한 기초는, 기본적으로 인자에 따라 참값이나 거짓의 값을 리턴하는 함수인 술어 (predicate) 이다. (프롤로그를 알면 그 개념과 이름에 친숙할 것이다). 한가지 간단한 술어는 is-hard 일 수 있다. 인자인 rock 을 계산 (evaluate) 할 때, is-hard 는 참값을 리턴할 것이다. 그러나, 인자인 cotton 을 계산하면 is-hard 는 거짓을 리턴할 것이다. 술어논리에서 이것은 다음과 같이 쓰여질 것이다.
is_hard(rock) → true
is_hard(cotton) → false
이 두가지 술어와 인자들을 명제논리로 다음과 같이 쓸 수 있다.
a rock is hard
cotton is not hard
술어논리와 명제논리 사이의 근본적 차이는 아마도 속성 (attribute) 을 소유하는 대상으로부터 그것을 분리한다는 것이다 : 즉, 술어논리에서, 어떤 주어진 대상의 견고성도 결정하는 함수를 만들 수 있다. 그러나, 명제논리에서, 각 경우에 대하여 새로운 문장을 만들어내야 한다. 술어는 여러 개의 인자를 가질 수 있다는 것을 이해하는 것이 중요하다. 예를들어, 술어 equal 은 두 개의 인자를 요구하고 둘이 같으면 참을 리턴한다.
아마도 술어논리가 명제논리에 대하여 제공하는 가장 큰 개선은 변수의 사용에 있을 것이다. 술어논리는 다음에 있는 것처럼, 술어들을 일반화하기 위하여 변수를 사용한다.
man(X) → not woman(X)
이를 "만약 X 가 남성이면, X 는 여성이 아니다" 라고 읽어야 한다.
술어논리의 또 다른 중요한 면은 한정자 (Quantifier) 의 사용이다. 술어논리는 두 개의 한정자를 사용하는데, 여기에 표준 표기법으로 보여진다.
|
의미 |
술어논리 기호 |
설명 |
전칭기호(全稱記號, for all) |
∀x 또는 (x) |
모든 x에 대하여, 영문으로 for all x. ∀를 생략하고 그냥 (x) 로 쓰기도 한다. 보편양화기호 또는 전칭정량자 로 번역 |
존재기호(存在記號, there exists) |
∃x |
어떤 x에 대하여 ... 인 x 가 적어도 하나 존재한다. 영문으로는 for some x, there exist at least some x such that .... 존재 양화기호 또는 존재 정량자 로 번역 |
"for all" 한정자는
모든 고양이는 동물이다. (All cats are animals.)
와 같은 문장을 동일한 술어논리로 변환한다 :
∀x.cat(X) → animal(x)
"there exists" 한정자는
Tom 이라고 하는 사람이 있다. (There is a person called Tom.)
와 같은 개념을 다음과 같은 표현으로 변형한다 :
∃x.person(X) and name(X, Tom)
"name" 은 이름을 사람과 연결하기 위하여 두 개의 인자를 사용한다는 것을 주목해야 한다.
술어논리의 다른 면들이 있지만, 이 설명이 기본 개념을 주기에 다양한 실세계 사실들을 논리적 표현으로 일반화해서 표현할 수 있는 수단을 제공하기 때문이다.
만약 술어논리에 대하여 더 많은 것을 배우는 데에 관심이 있다면, 그 주제에 관한 여러 가지 책들과, 술어논리를 구현하는 프롤로그 프로그래밍 언어를 참조해야 한다. 이 책이 비록 C 로 술어논리의 특정한 예들을 개발하지 않지만 술어논리를 구현하는 C 프로그램을 작성하기를 바랠런지도 모든다 - 아주 도전할 만한 일로 증명된다.
논리의 가장 호감이 가는 면 중의 하나는 확실하다는 것이다. 논리로 표현되는 것들은 참이거나 거짓일 뿐이다. 그러나 실세계는 그렇지가 않다 : 중간 지역이 많다. 더 중요하게, 대부분의 관찰에 대한 유효성과 옳음은 그것과 관련된 확률요소에 의해 지배를 받는다. 예를들어, 머리위로 나는 큰 새를 보면 독수리 일 수도 (could) 있었지만 매 일지도 (might) 모른다. 대부분 사람들은 익숙해 있지 때문에 큰 어려움없이 자연 관찰에 대한 불확실성을 다룰 수 있다. 그러나, 컴퓨터로 하여금 불확실성을 다루게 하는 것은 얼마간의 노력을 요구한다.
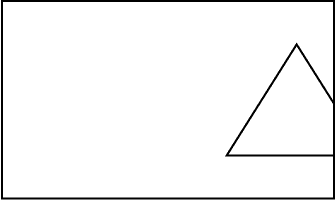
불확실성을 해결하거나 다루는 것은 실세계와의 성공적인 접촉을 위하여 요구되기 때문에 기계지능 (machine intelligence) 에 중요하다. 패턴인식에 대한 장으로 돌아가 생각해보자 : 거기서 부딪친 가장 어려운 하지만 해결되지 않은 문제들 중의 하나는 부분적으로만 보이는 물체의 인식이다. 예를들어, 컴퓨터가 다음 장면을 보면 그 물체가 삼각형이라고 기록할 것인가?
|
|
또 다른 예는 여러 가지 조건의 결과에 바탕을 둔 업무를 수행하도록 지시받은 로봇이다. 조건들 중 하나의 상태가 알려져 있지 않다면 로봇은 무엇을 하는가? 이러한 성질의 어려운 점들은 컴퓨터를 자연 환경에 적응하도록 만들려고 할 때 널리 퍼지게 된다.
어떤 정보가 알려져 있지 않은 상황을 해결하려고 시도하는 것은 AI 연구의 두 가지 중요한 분야로 이끈다. 첫 번째 분야는 퍼지 로직 (fuzzy logic) 인데 이것은 미지의 값을 포함하는 논리적 표현의 계산을 다룬다. 두 번째 분야는 확률시스템 (probabilistic systems) 을 다루는데 이것은 답에 도달하기 위하여 여러 사건들의 발생 확률을 이용한다.
퍼지 로직 (fuzzy logic) 이란 용어의 정확한 의미는, 너무나 많은 다른 상황에 적용되었기 때문에 모호해진다. 이 설명에서, 퍼지 로직 (fuzzy logic) 은 미지수를 포함할 수 있는 논리 수식들의 계산을 일컫는다. 논리는 결정적 (deterministic) 이기 때문에, 미지수의 존재가 논리표현을 쓸모없게 만든다고 생각할 수도 모른다 : 그러나 어떤 경우에, 미지수는 그 수식이 계산될 수 없다는 것을 의미하지 않는다. 퍼지 로직에서, 논리값은 다음 중의 하나이다 :
미지의 값은 정확히 다음과 같다 : 참이거나 거짓일 수 있지만 실제값이 알려져 있지 않다. 논리 수식에서 미지수를 어떻게 다룰 수 있을지 보기 위하여, 논리 연산자들에 대하여 표 1 에 있는 확장된 진리표를 공부해 보자. 그림에서 보여주듯이, NOT 과 EQUIVALENT 와 같은 몇몇 연산들은 수식이 미지의 값을 포함할 때 항상 불확실하다. 그러나, AND, OR, 그리고 IMPLIES 에 대하여 어떤 결합들은 여전히 알려진 결과를 산출할 것이다. 이 결과에 대한 이유를 이해하기 위하여, AND 의 결과는 어느 오퍼랜드라도 거짓이면 항상 거짓임을 기억해야 한다 : 한 오퍼랜드나 두 오퍼랜드 모두가 참이면 OR 의 결과는 참이다. 그리고, IMPLIES 에 대하여 거짓인 전제는 항상 참을 의미한다 (imply).
P |
Q |
∼P (NOT) |
P ∧ Q |
P ∨ Q |
P → Q (IMPLIES) |
P ↔ Q (EQUIVALENT) |
T T F F U U T F |
T F T F T F U U |
F F T T U U F T |
T F F F U F U F |
T T T F T U T U |
T F T T U U U T |
T F F T U U U U |
표 1. 진리치표를 확장하면 알려지지 않은 것도 포함된다.
퍼지 로직의 규칙들을 어떻게 컴퓨터화 하는지를 보이기 위하여, 이 절에서는 자기호출 하향 논리 수식 파서 (recursive-descent logical-expression parser) 를 개발할 것이다. 파서는 수식을 계산하는 루틴들의 집합임을 기억해야 한다. 컴퓨터 프로그램이 결과를 결정하기 위하여 산술식을 계산할 수 있는 것과 똑같이, 컴퓨터 프로그램은 논리 수식을 계산할 수 있다. 파서는 모든 고수준 언어 컴파일러와 대부분의 스프레드시트와 데이터베이스 프로그램들에 의해 사용된다.
또한 4 장에서 자연언어 파서의 사용을 보았다. 그러나, 어떤 임의의 논리 수식도 계산할 루틴을 작성하는 방법은 직관적인 과정이 아니다. 예를들어, 다음의 유효한 수식을 생각해보자. 여기서 1 은 참을 나타내고, 0 은 거짓을 나타내고, U 는 미지수를 나타낸다.
1 AND 1
1 OR (U & 0)
NOT (1 | 0) & 1
모든 수식이 1 AND 1 처럼 간단하면, 먼저 오퍼랜드를 읽고, 그리고나서 오퍼레이터 (연산자) 를 읽고, 마지막으로 두 번째 오퍼랜드를 읽는 루틴을 작성하는 것이 쉬울 것이다. 그러나 이런 방식은 더 복잡하고 괄호가 많은 수식으로 일반화될 수가 없다. 또한, 루틴은 여러 가지 연산자들의 우선순위를 어떻게 다룰 것인가? 이러한 문제들은 여기에 제시될 것들과 같은 파서를 개발하게 한다.
파서를 간단하게 유지하기 위하여, AND, OR, NOT 연산자들만을 지원할 것이다 - 선택한다면 나중에 확장시킬 수도 있지만, 파서는 연산자들의 우선순위가 다음과 같을 것으로 가정한다 :
최고 NOT
AND
최저 OR
파서를 작성할 수 있기 전에, 유효한 수식이 구성될 수 있는 방법을 묘사하는 생성규칙이라고 불리는 형식 규칙 (formal rules) 들의 집합을 정의해야 한다. 자연언어 처리에 관한 장에서 보았듯이 자기호출 하향 파서는 수식의 생성 규칙을 이 경우에는 논리 수식 - 그 수식을 계산하는 일련의 서로, 되부르는 함수들 (mutually recursive functions) 로 변환한다. 모든 생성 규칙은 왼쪽과 오른쪽을 생성할 수 있다. 또는 오른쪽으로 변형될 수 있다. 그러므로, 이름이 생성 규칙 (production) 이다. 생성 규칙의 일반적인 표기 (notation) 에서, 선택적 생성은 사각 모양의 괄호 안에 포함된다. 예를들어, 이 장에서 개발된 파서에 의해 사용된 생성 규칙이 다음에 있다.
Expression → Term [OR Term]
Term → Factor [AND Factor]
Factor → [Primitive] [(Expression)] [NOT Factor]
Primitive → [True] [False] [Unknown]
이 생성 규칙들은, AND, OR, NOT 연산자들을 사용하여 형성할 수 있는 괄호가 포함하여 가능한 유효수식들 모두를 정의할 뿐 아니라, 잠재적으로 연산자들의 우선순위를 결정한다. 이 규칙들이 작동하는지 알기 위하여 다음 수식을 생각해보자.
true AND (false OR true)
첫 번째 factor 는 primitive 인 true 인데, 이것은 두 번째 factor 를 형성하는 괄호가 있는 수식이 따라 나온다. 괄호가 있는 수식 안에서, false 는 첫 번째 term 이고 true 가 두 번째 term 이다.
단순성을 위해, 여기 주어진 파서는 다음 기호들을 사용한다 :
|
기호 |
의미 |
|
& | ! u 1 0 |
AND OR NOT unknown true false |
여기에 있는 자기호출 하향논리 수식 파서를 검토할 때, 방금 주어진 설명을 기억해야 한다. 이제 컴퓨터에 프로그램을 넣어야 한다.
|
/* fuzzy-logic analyzer */
char expr[80]; char token[80]; char *p_pos;
main() { int result; for (; ;) { printf("enter expression : "); gets(expr) if (!*expr) break; p_pos=expr; analyze(&result); printf("answer is : "); switch (result) { case 1 : printf("true\n"); break; case 0 : printf("false\n"); break; case 'u' : printf("unknown\n"); break; } } }
analyze(result) int *result; { get_token(); if (!*token) { serror(2); return; } level1(result); }
/* logic parser */ level1(result) int *result; { register char op; int hold;
level2(result); while ((op=*token)=='|') { get_token(); level2(&hold); determine(op, result, &hold); } }
level2(result) int *result; { int hold; char op;
level3(result); while ((op=*token)=='&') { get_token(); level3(&hold); determine(op, result, &hold); } }
level3(result) int *result; { register char op; op=0; if (*token=='!') { op='!'; get_token(); } level4(result); if (op) determine(op, result, result); }
level4(result) int *result; { if ((*token=='(')) { get_token(); level1(result); if (*token!=')') serror(1) get_token(); }
else primitive(result); }
primitive(result) int *result; { register int i;
if (is_in(*token, "01u")) { if (*token=='u') *result='u'; else *result=atoi(token); return get_token(); } serror(0); /* otherwise syntax error in expression */ }
determine(o, r, h) char o; int *r, *h; { register int t, ex; switch (o) { case '&' : if (*r!='u' && *h!='u') { *r=*r && *h; return; } if (*r=='u' && *h==0) *r=0; else if (*r==0 && *h=='u') *r=0; else *r='u'; break; case '|' : if (*r!='u' && *h!='u') { *r=*r && *h; return; } if (*r==1 && *h==1) *r=1; else *r='u'; break; case '!' : if (*r=='u') *r=!*r; else *r='u'; break; } }
serror(error) int error; { static char *e[]= { "syntax error", "unbalanced parenthesis", "no expression present" }; printf("%s\n", e[error]); }
get_token() { char *p; p=token; /* skip spaces */ while (*p_pos==' ') p_pos++; if (*p_pos=='\0') { /* is end of input * *p++='\0'; return; } if (is_in(*p_pos, "()|&!")) { *p=*p_pos; p++, p_pos++; *p='\0'; return; } /* read word until */ while (*p_pos!=' ' && !is_in(*p_pos, "()|&!")) { *p=*p_pos++; p++; } *p='\0': }
is_in(c, s) char c, *s; { while (*s) { if (c=*s) return 1; s++; } return 0; } |
이 프로그램을 사용하여
|
1 & (u|) |
과 같은 수식을 넣을 수 있고, 정확히 참으로 계산될 것이다. 반면 수식
|
1 & u |
은 불확실하기 때문에 미지의 값 (unknown) 으로 계산될 것이다.
파서를 이해하기 위하여, 단순히 앞에서 설명된 생성 규칙들을 구현한다는 것을 기억해야 한다. 파서는 AI 와 관계있는 많은 프로그램의 기초를 형성할 수 있는 가치있는 도구이기 때문에 그것을 이해할 때까지 파서의 동작을 공부해야 한다. 파서를 가지고 실험해 보라 - 아마도 IMPLIES 와 EQUIVALENT 와 같은 부가적인 연산들을 수용하는 수준을 첨가하면서.
불확실성의 처리를 요구하는 가장 중요한 분야들 중의 하나는 전문가시스템이 좋은 조언을 하는 것이라면, 또한 그 조언이 정확한 확률을 기록해야 한다. 이 절에서는 3 장에서 개발된 전문가시스템에 이 기능을 첨가한다. 그러나, 먼저, 전통적 확률이론의 기초에 대한 복습이 여기 제시된다. 이제 볼 것처럼, 이 규칙들을 AI decision-making 에 적용될 때 그것들을 그곳으로 돌려야 한다.
부분적으로, 발생할 수 있는 가능한 사건의 수는 발생하는 특정 사건의 확률을 결정한다. 어떤 상황에 관계되는 모든 가능한 사건들의 집합은 사건 공간 (event space) 이라고 불린다. 발생하는 사건 공간 속에서 각 사건의 가능성이 같으면, 그리고 어떤 사건도 겹치지 않으면 발생하는 특정 사건 X 의 확률 (P) 는 다음과 같다.
Px = 1/N
여기서 N 은 가능한 사건의 수이다. 예를들어, 던져진 동전의 앞이 나올 확률은, 두 개의 가능한 사건 - 앞과 뒤 - 이 있고 두 사건이 발생할 가능성이 같기 때문에, 1/2 이다. 하나의 주사위를 사용하여 3 을 던질 확률은 1/6 인데, 이것은 6 가지 가능한 결과가 있고 모든 결과가 발생할 가능성이 똑같기 때문이다.
AI 프로그래머에게 가장 흥미있는 확률부분은 사건들의 수열 또는 사건들의 조합이 발생할 가능성을 계산하는 것이다. 공식적 확률 이론에서, 사건들의 조합의 확률은 그 사건들 각각의 확률의 곱과 같다. 예를들어 동전을 던진 후 차례로 세 번 앞이 나올 확률은
1/2 * 1/2 * 1/2 = 1/8
이다. 수열이나 조합을 형성하는 사건들은 관련될 필요는 없다는 것을 이해하는 것은 중요하다. 예를들어, 동전의 앞이 나오고 주사위의 4 를 던질 확률은 다음과 같다.
1/2 * 1/6 = 1/12
모든 확률은 0 과 1 을 포함하여 그 사이의 값이다. 1 의 확률을 갖는 사건은 확실한 사실이다 : 예를들어, 죽음은 확실한 사실이다. 0 의 확률을 갖는 사건은 불가능이다 : 예를들어, 영원히 사는 것은 불가능으로 생각될 것이다. 0 보다 작거나 1 보다 큰 확률을 갖는 것은 가능하지 않다.
앞에서 언급했듯이, 확실한 관찰은 거의 없다 - 오히려, 그것은 그럴 것 같은 것이다. 그러나, 어떤 유형의 정보는 다른 것보다 사실일 가능성이 더 높고, 성공적인 전문가시스템은 그러한 정보의 확률을 고려해야 한다. 불확실성을 해결할 방법으로 전통적인 확률 이론을 사용한 효과를 조사해 보기 전에, 제 3 장의 전문가시스템은 알고 있는 각 정보가 확률 인자를 갖추도록 변형되어야 한다.
먼저, 지식베이스를 변경해야 한다. 확실성 요소가 각 속성 (attribute) 와 관련되게 하는 것은, 다음에 있는 것처럼 attribute 구조에 또 다른 필드를 첨가할 것을 요구한다.
|
struct attribute { char attrib[80]; float prob; /* probability associated with attribute */ struct attrubute *next; /* use linked list */ } at; |
또한 prob 라고 하는 총괄 변수를 첨가해야 하는데, 이 변수는 해답이 옳을 확률을 갖는다.
사용자가 대상에 대한 각 속성을 넣을 때, 프로그램은 또한 그 속성이 특별한 대상에 관련되는 가능성을 반영하는 확률요소 (probability factor) 를 주도록 사용자에게 요구한다. 이 요소의 의미를 이해하기 위해서, 감기와 같이 병을 묘사하는 속성들을 생각해 보자. 모든 사람이 똑같은 식으로 감기를 앓는 것은 아니다 : 어떤 사람들은 콧물이 나고, 또 어떤 사람들은 재채기를 하고 등등. 감기의 증상을 전문가시스템의 지식베이스에 넣으면, 발생하는 각 증상의 확률을 나타내 주어야 한다. 예를들어, 콧물이 나는 증상에 90 % 의 확률을 줄 수 있다. 반면에 목이 아픈 증상에 40 % 의 확률을 줄 수 있다. 그러므로 enter() 함수가 속성과, 각 대상에 관련된 확률을 모두 입력하도록 그것을 바꾸어야 한다.
|
/* input an object and its list of attributes */ enter() { int t, i; struct attribute *p, *oldp;
for (;;) { t=get_next(); /* get the index of the next available object in k_base */ if (t == -1) { printf("Out of list space.\n"); return; } printf("Object name: "); gets(k_base[t].name);
if (!*k_base[t].name) { l_pos--; break; }
p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf("Out of memory.\n"); return; } k_base[t].alist=p; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; printf("Enter attributes (RETURN to quit)\n"); for (;;) { printf("attribute : "); gets(p->attrib); if(!p->attrib[0]) break; printf("probability : (0-1): "); scanf("%f", &p->prob); getchar(); /* throw away crfl */ oldp=p; p->next=(struct attribute *) malloc(sizeof(at)); if (p->next == '\0') { printf("Out of memory.\n"); return; } p=p->next; p->next='\0'; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; } oldp->next = '\0'; } } |
전문가시스템에서 해야 할 결정적인 변경은 try() 와 trailno() 가 부정적 반응을 다루는 방법이다. 3 장에서 개발된 초기 시스템에서 부정적 반응은 항상 사용자가 현재의 가정을 거절하고 있다는 것을 나타냈다 : 그러나, 확률 시스템에서 거절은 그 속성을 발견할 확률이 미리 정해진 어떤 양을 초과할 때에만 발생할 것이다.
예를들어, 초기 버전에서 속성의 부정적 반응을 받으면 그 속성을 no 데이터베이스에 놓고, 추론의 현재 라인을 취소하고 새로운 대상이 시도되게 했다. 그러나, 이 새로운 확률 버전은 여전히 속성을 no 데이터베이스에 놓지만, 절 (clause) 은 이 속성을 발견할 확률이 50 % 를 초과할 때에만 실패할 것이다. (이 비율은 임의로 선택되고 원한다면 바꿀 수 있다). 이런 식으로, 한 대상과 연관될 수 있는 속성들은 그 대상의 묘사의 일부를 형성할 수 있지만, 그 속성을 발견할 확률이 충분히 낮으면, 그 속성을 갖지 않는다고 해서 그 대상을 거절할 수는 없다. 여기에 변형된 함수 try() 와 trailno() 가 제시된다 :
|
/* try an object */ try(p, oob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p, ob)) return 0;
if (!trailyes(p, ob)) return 0;
while(p) {
/* if already been asked then move oon to next attribute */ if (ask(p->attrib)) { printf("is/does/has it %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out of memory\n"); return ; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib, p->attrib); if (!no) { no=a; nonext=no; } else { nonext->next=a; nonext=a; } reject(ob, p->attrib, 'n'); /* reject if porb >= 50% */ if (p->prob>=0.5) return 0; case 'y': strcpy(a->attrib, p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } compute_odds(p->prob); p=p->next; break; case 'w': /* why? */ reasoning(ob); break; } } else p=p->next; } return 1; }
/* see if it has any attributes known not to be part of the object by checking the no list */ trailno(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t;
a=no; while(a) { t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { reject(ob, t->attrib, 'n'); if (t->prob>=0.5) return 0; /* reject only if high prob */ } t=t->next; } a=a->next; } return 1; } |
전문가가 옳다고 판단할 최종 확률을 계산하는 새로운 루틴, compute-odds() 가 필요할 것이다. 여기에 있는 함수는 전통적인 확률 모델을 가정한다.
|
compute_odds(f) float f; { prob*=f; } |
compute-odds() 함수는 현재 속성에 대한 확률이 전달되고 해를 위하여 확률을 update 한다. 확률적 전문가시스템 전체가 여기에 보여진다. 이제 컴퓨터에 그것을 입력해야 한다.
|
/* A probabilistic expert system that finds multiple goals and displays reasoning using classical probability theory */ #include "stdio.h" #incclude <malloc.h>
#define MAX 100 struct attribute { char attrib[80]; float prob; /* probability assoc with attribute */ struct attribute *next; /* use linked list */ } at;
struct object { char name[80]; struct attribute *alist; /* pointer to list of attributes */ } ob;
struct rejected_object { char name[80]; char attrib[80]; /* attribute that caused rejection */ char condition; /* should it or shouldn't it have been found ? */ } rj; struct rejected_object r_base[MAX];
struct object k_base[MAX]; /* holds the knowledge base */ int l_pos=-1; /* location of top of k_base */ int r_pos=-1; /* location of top of reject base */
struct attribute *yes, *no; /* used for yes and no lists */ struct attribute *yesnext, *nonext;
float prob; /* holds the probability of the current solution */
main() { char ch;
no=yes='\0'; do { free_trails(); ch=menu(); switch(ch) { case 'e': enter (); break; case 'q': query(); break; case 's': save(); break; case 'l': load(); }
} while (ch != 'x'); }
free_trails() { struct attribute *p;
while(yes) { p=yes->next; free(yes); yes=p; }
while(no) { p=no->next; free(no); no=p; } r_pos=-1; }
/* input an object and its list of attributes */ enter() { int t, i; struct attribute *p, *oldp;
for (;;) { t=get_next(); /* get the index of the next available object in k_base */ if (t == -1) { printf("Out of list space.\n"); return; } printf("Object name: "); gets(k_base[t].name);
if (!*k_base[t].name) { l_pos--; break; }
p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf("Out of memory.\n"); return; } k_base[t].alist=p; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; printf("Enter attributes (RETURN to quit)\n"); for (;;) { printf("attribute : "); gets(p->attrib); if(!p->attrib[0]) break; printf("probability : (0-1): "); scanf("%f", &p->prob); getchar(); /* throw away crfl */ oldp=p; p->next=(struct attribute *) malloc(sizeof(at)); if (p->next == '\0') { printf("Out of memory.\n"); return; } p=p->next; p->next='\0'; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; } oldp->next = '\0'; } }
/* inquire information from the expert */ query() { int t; char ch; struct attribute *p; for (t=0;t<=l_pos;t++) { p=k_base[t].alist; prob=1,. 0; if (try(p, k_base[t].name)) { printf("%s fits current attributes\n", k_base[t].name); printf("with probability factoor of %f\n", prob); printf("continue? (Y/N): "); ch=tolower(getche()); printf("\n"); if (ch=='n') return; } } printf("No (more) object(s) found\n"); }
/* try an object */ try(p, ob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p, ob)) return 0;
if (!trailyes(p, ob)) return 0;
while(p) { /* if already been asked then move on to next attribute */ if (ask(p->attrib)) { printf("is/does/has it %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out of memory\n"); return ; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib, p->attrib); if (!no) { no=a; nonext=n; } else { nonext->next=a; nonext=a; } reject(ob, p->attrib, 'n'); /* reject if porb >= 50% */ if (p->prob>=0.5) return 0; case 'y': strcpy(a->attrib, p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } compute_odds(p->prob); p=p->next; break; case 'w': /* why? */ reasoning(ob); break; } } else p=p->next; } return 1; }
/* see if it has any attributes known not to be part of the object by checking the no list */ trailno(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t;
a=no; while(a) { t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { reject(ob, t->attrib, 'n'); if (t->prob>=0.5) return 0; /* reject only if high prob */ } t=t->next; } a=a->next; } return 1; }
/* see if it has all attributes known to be part of the object by checking the yes list */ trailyes(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t; char ok;
a=yes; while(a) { ok=0; t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { ok=1; /* does have a needed attribute */ compute_odds(t->prob); } t=t->next; } if (!ok) { reject(ob, a->attrib, 'y'); return 0; } a=a->next; } return 1; }
/* see if attribute already asked */ ask(attrib) char *attrib; { struct attribute *p, *q;
p=yes; while(p && strcmp(attrib, p->attrib)) p=p->next;
q=no; while(q && strcmp(attrib, q->attrib)) q=q->next;
if (q && q->prob<0.5) return 0; if (!p) return 1; /* false if end of list */ else return 0; }
/* show why a line of reasoning is being followed */ reasoning(ob) char *ob; { struct attribute *t; int i;
printf("Trying %s\n", ob); if (yes) printf("it is/has/does:\n"); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf('it is/has/does noot:\n"); t=no; while(t) { printf("%s\n", t-> attrib); t=t->next; }
for (i=0;i<=r_pos;i++) { printf("%s rejected because ", r_base[i].name); if (r_base[i].condition=='n') printf("%s is not an attribute.\n", r_base[i].attrib); else printf("%s is a required attribute.\n", r_base[i].attrib); } }
/* place rejected object into database */ reject(ob, at, cond) char *ob, *at, cond; { r_pos++;
strcpy(r_base[r_pos].name, ob); strcpy(r_base[r_pos].attrib, at); r_base[r_pos].condition=cond; }
/* get next free index in k_base array */ get_next() { l_pos++; if (l_pos<MAX) return l_pos; else return -1; }
menu() { char ch; printf("(E)nter, (Q)uery, (S)save, (L)oad, e(X)it\n"); do { printf("choose one:"); ch=tolower(getche()); } while (!is_in(ch, "eqslx")); printf("\n"); return ch; }
save() { int t, x; struct attribute *p; FILE *fp;
if ((fp=fopen("expert.dat", "w"))==0) { printf("cannot open file\n"); return; } printf("saving knowledge base\n"); for (t=0;t<=l_pos;++t) { for (x=0;x<sizeof(k_base[t].name);x++) putc(k_base[t].name[x], fp); p=k_base[t].alist; while(p) { for (x=0;x<sizeof(p->attrib);x++) putc(p->attrib[x], fp); fprintf(fp, "%f", p->prob); p=p->next; } /* end of list marker */ for (x=0;x<sizeof(p->attrib);x++) putc('\0', fp); } putc(0, fp); fclose(fp); }
load() { int t, x; struct attribute *p, *oldp; FILE *fp;
if ((fp=fopen("expert.dat", "r"))==0) { printf("cannot open file\n"); return; } printf("loading knowledge base\n");
/* free any old lists */ clear_kbase(); for (t=0;t<MAX;++t) { if ((k_base[t].name[0]=getc(fp))==0) break; for (x=1;x<sizeof(k_base[t].name);x++) k_base[t].name[x]=getc(fp);
k_base[t].alist=(struct attribute *) malloc(sizeof(at)); p=k_base[t].alist; if(!p) { printf("Out of memory\n"); return; } for (;;) { for (x=0;x<sizeof(p->attrib);x++) p->attrib[x]=getc(fp);
if (!p->attrib[0]) { oldp->next='\0'; break; /* end of list */ } p->next=(struct attribute *) malloc(sizeof(at)); if (!p->next) { printf("out of memory\n"); break; } fscanf(fp, "%f", &p->prob); oldp=p; p=p->next; } } fclose(fp); l_pos=t-1; } clear_kbase() { int t; struct attribute *p, *p2;
for (t=0;t<=l_pos;t++) { p=k_base[t].alist; while(p) { p2=p->next; free(p); p=p2;
} } }
is_in(ch, s) char ch, *s; { while(*s) if (ch==*s++) return 1; return 0; } compute_odds(f) float f; { prob*=f; } |
처음 이 프로그램을 수행할 때, 다음 정보를 넣어라.
|
대상 속성 사과 (apple) 식용 0.9, 빨간색 0.4, 나무에서 자람 1 오렌지 (orange) 식용 0.9, 오렌지색 0.9, 나무에서 자람 1 건포도 (plum) 식용 0.8, 보라색 0.5, 나무에서 자람 1 포도 (grape) 식용 0.8, 보라색 0.5, 나무에서 자람 0.01 |
포도의 묘사에서, 지식베이스는 포도가 나무에서 자랄 가능성은 1 % 뿐이라는 사실을 포함한다. 이 추론은 포도가 나무에서 자란다는 것이 아니다 - 물론, 넝쿨에서 자란다 - 그러나 사용자에게 아주 큰 넝쿨을 나무로 잘못 인식할 기회를 허용한다. (그리고, 그 점을 설명하는 데에 도움을 준다 !)
이러한 정보가 주어졌을 때, 발생할 수 있는 한가지 대화가 여기에 있다 :
|
is/has/does it edible ? y is/has/does it red ? y is/has/does it grew_on_tree ? y apple fits the current attributes with probability 0.36 continue ? n |
가능한 또다른 대화가 여기 있다 :
|
is/has/does it edible ? y is/has/does it red ? n is/has/does it grew_on_tree ? y apple fits the current attributes with probability 0.36 continue ? y is/has/does it orange ? n is/has/does it purple ? y plum fits the current attributes with probability 0.4 continue ? y grape fits the current attributes with probability 0.04 continue ? n |
첫 번째 대화가 산출된 방법은, 반응이 모두 긍정이고 apple 을 직접 가리키기 때문에 쉽다. 문제는 전통적인 확률 모델을 사용하는 전문가시스템이 이 해가 옳을 확률은 36 % (1 * 0.4 * 0.9) 만 준다는 것이다. 그러나, 이것은 틀린 것 같다 - 그리고 실제로 틀렸다 !
전통적인 확률 모델은 일련의 사건들을 다루도록 설계되었다. 그러나, 지식베이스에서 각 속성과 관련된 확률은 단순히 속성이 특정한 대상과 관련되는 가능성이다. 그러므로, 지식베이스와 관련된 확실성 상수 (certainty coefficients) 는 전통적인 확률이론의 기법들을 사용하여 분석될 수 없다. 사실, 전통적인 확률 모델을 사용하는 것은 이상한 전문가시스템이다.
두 번째 대화는 전문가시스템이 속성 리스트에서 가능한 생략을 해결하기 위하여 각 속성과 관련된 확률을 사용할 수 있는 방법을 보여준다. 대상이 빨간색인지를 묻는 질문에 사용자가 아니오 라고 대답할 때, 시스템은 그 반응을 no 데이터베이스에 저장한다. 그러나, 사과가 빨간색일 확률은 40 % 뿐 (노랗거나 초록색일 수도 있다.) 이기 때문에, 시스템은 추론의 이 라인을 중지하지 않는다. 그리고나서 시스템은 가능한 해로써 plum 과 grape 를 계속 발견한다.
성공의 확률이 나타내 주듯이, 전통적인 확률 모델을 정보의 불확실성을 해결하려고 적용시킬 때 잘 동작하지 않는다. 이제 이 문제를 해결하기 위한 두가지 다른, 좀 더 성공적인 방법을 볼 것이다.
확실성 요소가 특정한 속성과 관련될 때, 그 속성이 문제의 대상의 예에 속할 별개의 가능성이 있다는 것을 의미한다. 그러므로, 한가지 방식은, 어떤 해의 확실성은 그 대상과 관련된 최소의 확실성 상수이어야 한다는 것을 암시한다. 이 개념은 가장 약한 연결 (weakest link) 만큼 강한 체인과 유사하다.
확실한 전문가시스템으로 하여금 이런 방식으로 불확실성을 해결하게 하는 것은 여기에 있는 것처럼, compute_prob() 함수로의 변화만을 요구한다.
|
/* compute the probability of a solution */ /* weakest-link method */ compute_prob(f) float f; { if (prob>f) prob=f; } |
이 버전에서, 최하의 확실성 요소가 전체 해가 옳을 확률이 된다. 전문가시스템에서 이 함수를 대체하면, 생성될 수 있는 대화는 다음이다 :
|
is/has/does it edible ? y is/has/does it red ? y is/has/does it grew_on_tree ? y apple fits the current attributes with probability 0.4 continue ? n |
생성될 수 있는 또 다른 대화가 여기있다 :
|
is/has/does it edible ? y is/has/does it red ? n is/has/does it grew_on_tree ? y apple fits the current attributes with probability 0.4 continue ? y is/has/does it orange ? n is/has/does it purple ? y plum fits the current attributes with probability 0.5 continue ? y grape fits the current attributes with probability 0.2 continue ? n |
알 수 있듯이, 해는 같지만 확률이 바뀌었다 - 이 경우에, 높아졌다. 가장 약한 연결 방법의 주요한 장점은, 대상과 관련된 모든 속성들이 상호의존적인 것처럼 : 즉, 해의 가능성이 요소들의 조합에 기초하는 것처럼, 성공의 확률을 준다는 것이다. 한편, 가장 강력한 논의가 가장 약한 연결보다 더 중요하게 되는 상황들이 있다. 이러한 상황들은 가장 강한 연결 (strongest-link) 방식을 요구한다.
어떤 응용에서, 해가 옳을 확률은 가장 약한 지원 증거에 의존하는 것이 아니라, 오히려 가장 강하게 지원하는 증거에 기초를 둔다. 이것은 한가지 논의만으로 쟁점을 결정하기에 충분한 그런 논쟁과 비슷하다. 예를들어, 탄약을 장전한 총을 아이들이 발견할 수 있는 곳에 두는 것이 왜 나쁜가? 아이가 총을 쏴서 시끄럽고 혼란스러운 소리를 낼 수 있다든가, 아이가 총을 쏴서 재산에 손해를 입힐 수 있다는 것과 같은 여러 가지 이유가 있다. 그러나 가장 강력한 논의는, 아이가 총을 쏴서 누군가 상처를 입히거나 죽일 수 있다는 것이다. 분명히, 가장 강력한 논의가 되는 최후의 것이다.
전문가시스템에 적용될 때, 가장 강한 연결 (strongest-link) 방법은 단순히, 해가 옳을 확률은 발생할 가능성이 가장 큰 속성의 확률과 같다는 것을 의미한다. 이 방식을 구현하기 위해서, 아래에 있는 것처럼 compute_prob() 함수를 변형해야 한다 :
|
/* compute the probability of a solution */ /* strongest-link method */ compute_prob(f) float f; { if (prob<f) prob=f; } |
이 변화 이외에, try() 에 있는, prob 의 초기값을 1 에서 0 으로 바꾸어야 한다. 전통적인 확률 모델과 가장 약한 연결 방법에서 사용된다. 혼동을 피하기 위하여, strongest-link 전문가시스템 전체가 여기에 보여진다.
|
/* A probabilistic expert system that finds multiple goals and displays reasoning using the strongest link approach */
#include "stdio.h" #include <malloc.h>
#define MAX 100 struct attribute { char attrib[80]; float prob; /* probability assoc with attribute */ struct attribute *next; /* use linked list */ } at;
struct object { char name[80]; struct attribute *alist; /*pointer to list of attributes */ } ob;
struct rejected_object { char name[80]; char attrib[80]; /* attribute that caused rejection */ char condition; /* should it or shouldn't it have been found ? */ } rj; struct rejected_object r_base[MAX];
struct object k_base[MAX]; /* holds the knowledge base */ int l_pos=-1; /* location of top of k_base */ int r_pos=-1; /* location of top of reject base */
struct attribute *yes, *no; /* used for yes and no lists */ struct attribute *yesnext, *nonext;
float prob; /* holds the probability of the current solution */ main() { char ch;
no=yes='\0'; do { free_trails(); ch=menu(); switch(ch) { case 'e': enter(); break; case 'q': query(); break; case 's': save(); break; case 'l': load(); }
} while (ch != 'x'); }
free_trails() { struct attribute *p;
while(yes) { p=yes->next; free(yes); yes=p; }
while(no) { p=no->next; free(no); no=p; } r_pos=-1; }
/* input an object and its list of attributes */ enter() { int t, i; struct attribute *p, *oldp;
for (;;) { t=get_next(); /* get the index of the next available object in k_base */ if (t == -1) { printf("Out of list space.\n"); return; } printf("Object name: "); gets(k_base[t].name);
if (!*k_base[t].name) { l_pos--; break; }
p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf("Out of memory.\n"); return; } k_base[t].alist=p; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; printf("Enter attributes (RETURN to quit)\n"); for (;;) { printf("attribute : "); gets(p->attrib); if(dp->attrib[0]) break; printf("probability : (0-1): "); scanf("%f", &p->prob); getchar(); /* throw away crfl */ oldp=p; p->next=(struct attribute *) malloc(sizeof(at)); if (p->next == '\0') { printf("Out of memory.\n"); return; } p=p->next; p->next='\0'; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; } oldp->next = '\0'; } }
/* inquire information from the expert */ query() { int t; char ch; struct attribute *p; for (t=0;t<=l_pos;t++) { p=k_base[t].alist; prob=0.0; /* strongest length initial point */ if (try(p, k_base[t].name)) { printf("%s fits current description\n", k_base[t].name); printf("with probability factor of %f\n", prob); printf("coontinue? (Y/N): "); ch=tolower(getche()); printf("\n"); if (ch=='n') return; } } printf("No (more) object(s) found\n"); }
/* try an object */ try(p, ob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p, ob)) return 0;
if (!trailyes(p, ob)) return 0;
while(p) { /* if already been asked then move on to next attribute */ if (ask(p->attrib)) { printf("is/does/has it %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out of memory\n"); return ; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib, p->attrib); if (!no) { no=a; nonext=no; } else { nonext->next=a; nonext=a; } reject(ob, p->attrib, 'n'); /* reject if prob >= 50% */ if (p->prob>=0.5) return 0; case 'y': strcpy(a->attrib, p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } compute_prob(p->prob); p=p->next; break; case 'w': /* why? */ reasoning(ob); break; } } else p=p->next; } return 1; }
/* see if it has any attributes known not to be part of the object by checking the no list */ trailno(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t;
a=no; while(a) { t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { reject(ob, t->attrib, 'n'); if (t->prob>=0.5) return 0; /* reject only if high prob */ } t=t->next; } a=a->next; } return 1; }
/* see if it has all attributes known to be part of the object by checking the yes list */ trailyes(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t; char ok;
a=yes; while(a) { ok=0; t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { ok=1; /* dooes have a needed attribute */ compute_prob(t->prob); } t=t->next; } if (!ok) { reject(ob, a->attrib, 'y'); return 0; } a=a->next; } return 1; }
/* see if attribute already asked */ ask(attrib) char *attrib; { struct attribute *p, *;
p=yes; while(p && strcmp(attrib, p->attrib)) p=p->next;
q=no; while(q && strcmp(attrib, q->attrib)) q=q->next;
if (q && q->prob<0.5) return 0; if (!p) return 1; /* false if end of list */ else return 0; }
/* show why a line of reasoning is being followed */ reasoning(ob) char *ob; { struct attribute *t; int i;
printf("Trying %s\n", ob); if (yes) printf("it is/has/does:\n"); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf("it is/has/does not:\n"); t=no; while(t) { printf("%s\n", t->attrib); t=t->next; }
for (i=0;i<r-pos;i++) { printf("%s rejected because ", r_base[i].name); if (r_base[i].condition=='n') printf("%s is not an attribute.\n", r_base[i].attrib); else printf("%s is a required attribute.\n", r_base[i].attrib); } }
/* place rejected object into database */ reject(ob, at, cond) char *ob, *at, cond; { r_pos++;
strcpy(r_base[r_pos].name, ob); strcpy(r_base[r_pos].attrib, at); r_base[r_pos].condition=cond; }
/* get next free index in k_base array */ get_next() { l_pos++; if (l_pos<MAX) return l_pos; else return -1; }
menu() { char ch; printf("(E)nter, (Q)uery, (S)save, (L)oad, e(X)it\n"); do { printf("choose one:"); ch=tolower(getche()); } while (!is_in(ch, "eqslx")); printf("\n"); return ch; }
save() { int t, x; struct attribute *p; FILE *fp;
if ((fp=fopen("expert.dat", "w"))==0) { printf("cannot open file\n"); return; } printf("saving knowledge base\n"); for (t=0;t<=l_pos;++t) { for (x=0;x<sizeof(k_base[t].name);x++) putc(k_base[t].name[x], fp); p=k_base[t].alist; while(p) { for (x=0;x<sizeof(p->attrib);x++) putc(p->attrib[x], fp); fprintf(fp, "%f", p->prob); p=p->next; } /* end of list market */ for (x=0;x<sizeof(p->attrib);x++) putc('\0', fp); } putc(0, fp); fclose(fp); }
load() { int t, x; struct attribute *p, *oldp; FILE *fp;
if ((fp=fopen("expert.dat", "r"))==0) { printf("cannot open file\n"); return; } printf("loading knowledge base\n");
/* free any old lists */ clear_kbase(); for (t=0;t<MAX;++t) { if ((k_base[t].name[0]=getc(fp))==0) break; for (x=1;x<sizeof(k_base[t].name);x++) k_base[t].name[x]=getc(fp); k_base[t].alist=(struct attribute *) malloc(sizeof(at)); p=k_base[t[.alist; if(!p) { printf("Out of memory\n"); return } for (;;) { for (x=0;x<sizeof(p->attrib);x++) p->attrib[x]=getc(fp); if (!p->attrib[0]) { oldp->next='\0'; break; /* end of list */ } p->next=(struct attribute *) malloc(sizeof(at)); if (!p->next) { printf("out of memory\n"); break; } fscanf(fp, "%f", &p->prob); oldp=p; p=p->next; } } fclose(fp); l_pos=t-1; }
clear_kbase() { int t; struct attribute *p, *p2;
for (t=0;t<=l_pos;t++) { p=k_base[t].alist; while(p) { p2=p->next; free(p); p=p2;
} } }
is_in(ch, s) char ch, *s; { while(*s) if (ch==*s++) return 1; return 0; }
/* compute the probability of a solution */
/* strongest-link mithod */ compute_prob(f) float f; { if (prob<f) prob=f; } |
이 버전을 수행할 때, apple 과 plum 에 대한 확실성 요소는 1 이 된다. grape 에 대한 확실성 요소는 0.8 이다.
전통적인 확률 방법은, 가설적 정보를 사용하여 어떤 사건들의 확률을 예측할 전문가시스템과 같은 색다른 상황에서만 응용할 수 있다. 예를들어, 사건들이 달랐다면 역사적인 상황의 여러 가지 출력들의 확률을 줄 전문가시스템을 설계할 수 있다. 그러나, 이러한 종류에서 사용하는 것 외에, 전통적인 확률 모델은 지식베이스 시스템 (knowledge-based systems) 에서 잘 동작하지 않는다.
모든 속성들의 조합을 생각해야 할 때는 weakest-link 버전을 사용해야 한다. 이 경우에, 사용자에게 최악의 경우 (worst case) 가 무엇인지를 알려야 한다. 지식베이스가 적당히 정의되면 최악의 경우에 대한 확률은 여전히 매우 높을 것이다.
어떤 대상을 명시 (identify) 하기 위해서 어떤 속성이라도 사용할 수 있을 때는 언제나 strongest-link 방식을 써야 한다. 이 경우에, 확실성 요소는 가장 강력한 논의의 가능성을 반영한다.