전문가 시스템
(Expert System)
C 인공지능 프로그래밍 : Herbert Schildt 지음, 신경숙.류성렬 옮김, 세웅, 1991 (원서 : Artificial Intelligence using C, McGraw-Hill, 1987), page 93~153
1. 전문가시스템 이란 무엇인가? (WHAT IS AN EXPERT SYSTEMS?)
(1) 전문가시스템의 장점은 무엇인가? (What Are the Advantages of an Expert Systems ?)
(2) 상업적 전문가시스템 몇가지 예 (Some Examples of Commercial Expert Systems)
2. 전문가시스템은 어떻게 동작하는가? (HOW EXPERT SYSTEMS WORK?)
(1) 지식베이스 (The Knowledge Base)
(2) 추론기관 (The Inference Engine)
3. 만능 전문가시스템 만들기 (CREATING A GENERAL-PURPOSE EXPERT SYSTEM)
3.1. 연산의 본질적 요소 (The Essential of Operation)
3.2. 지식베이스 구조화 (Structuring the Knowledge Base)
3.3. 지식베이스 로드 (Loading the Knowledge Base)
3.4. 추론기관 구현 (Implementing the Inference Engine)
3.6. 복수의 해 찾기 (Finding Multiple Solutions)
4. 더 복잡한 버전 (A MORE SOPHISTICATED VERSION)
5. 지식 엔지니어링 (KNOWLEDGE ENGINEERING)
5.1. 지식베이스 구조 (Knowledge Base Organization)
5.2. 전문가 찾기 (Finding the Expert)
5.3. 지식베이스 확증 (Verifying the Knowledge Base)
전문가시스템은 주로 두 가지 이유 때문에 흥미롭다 : 먼저, 현실의 요구를 수행하는, 일반적으로 유용하고 실용적인 프로그램이다. 두 번째로, 실현할 수가 있다. 이것이 바로 전문가시스템이 AI 의 상업적 성공의 대부분을 차지하는 이유이다. 이 장의 첫 부분은 전문가시스템이 무엇인가 하는 것과 수행할 수 있는 여러 가지 방법을 보여줄 것이다. 이 장의 두 번째 부분은 완전하고, 일반적인 목적으로 사용되는 전문가시스템을 하나 개발한다.
제 1 장에서 언급했듯이, 전문가시스템은 사람 전문가의 행위를 흉내내는 프로그램이다. 사용자가 어떤 주제에 관한 견해를 표현하기 위하여 제공하는 정보를 사용한다. 그러므로, 전문가시스템은 대답과 일치하는 대상을 알아낼 수 있을 때까지 질문을 한다. 전문가시스템이 무엇인지 이해하기 위하여, 과일 전문가와 충고를 구하는 어떤 사람 사이의 다음 대화를 생각해 보자.
컴퓨터화된 과일 전문가시스템의 목표는 이 대화를 재생산하는 것이다. 더 일반적으로, 전문가시스템은 전문기술의 주제에 관해 사용자에게 충고를 하려고 시도한다.
전문가시스템의 바람직함은 주로 유용성과 편의성에 기초한다. 잠을 자고, 먹고, 피로를 풀고, 쉬고 하는 등의 일을 해야 하는 사람 전문가와는 달리, 전문가시스템은 하루 24 시간, 연중 매일 사용하기에 유용하다. 또한, 사람 전문가의 수는 제한 될 수 있는 반면, 많은 전문가시스템은 만들어질 수 있다. 더욱이, 사람과는 달리, 컴퓨터화된 전문가는 절대 죽지 않고 지식을 취한다. 전문가시스템에 있는 지식은, 쉽게 복사되고 저장될 수 있으므로, 전문 지식의 영구적인 손실이 거의 드물다.
사람 전문가에 비해 전문가시스템의 또 다른 장점은, 컴퓨터화된 전문가는 항상 성능이 최고하는 것이다. 사람 전문가가 지칠 때, 전문가 충고의 신뢰성은 사라질런지도 모른다. 그러나 컴퓨터화된 전문가는 항상 최상의 견해 - 자기의 지식의 제한 범위 안에서 - 를 생성할 것이다.
전문가시스템의 덜 중요한 장점은 개성이 부족하다는 것이다. 아마도 알겠지만, 개성은 항상 적합한 것은 아니다. 전문가와 친하게 지내지 않는다면, 전문가의 지식을 이용하는 것이 마음 내키지 않을 수도 있다. 반대 상황도 생길수 있다 : 좋아하지 않는 사람 전문가는 신뢰할 만한 정보를 표현할 수 없을 지도 모른다. 그러나 컴퓨터화된 전문가는 개성을 갖지 않는다. 따라서 이러한 문제들은 제거된다.
전문가시스템의 마지막 장점은, 컴퓨터화된 전문가가 존재한 후, 단순히 한 기계에서 다른 기계로 프로그램을 복사함으로써 새로운 전문가를 만들어 낼 수 있다. 사람은 어떤 분야에서 전문가가 되기 위하여 오랜 기간을 필요로 하는데, 이것 때문에 사람 전문가를 얻기가 힘들다.
MYCIN 이라는 전문가시스템이 없다면, 전문가시스템은 AI 연구실에 머물고 외부로 진출하지 못했을런지도 모른다. AI 의 가장 커다란 관념 문제들 (image problems) 중의 하나는, 다른 프로그래머를 포함해서 많은 사람들이 AI 기법은 엄밀한 규칙들과 가정을 요구하는 문제에 대해서만 작동한다고 믿는 것이었다. 이 사람들은 AI 는 결코 어려운 문제를 해결하기 위하여 사용될 수 없다고 믿었다. MYCIN 은 그 모두를 변화시켰다.
MYCIN 은 세계에서 최초로 성공한 전문가시스템이다. 1970 년대 중반에 스탠포드 대학에서 개발되었는데, 의사가 어떤 세균성 질병을 진단하는 것을 돕기 위하여 설계하였다. 병을 진단하는 것은 본질적으로 환자가 제시하는 증상과 병의 징후 사이에 일치가 발견될 때까지 그 둘을 비교하는 일이다. 문제는, 의사가 존재하는 모든 병을 빠르고 자신있게 진단하는 것은 어렵다는 것이다. MYCIN 은 진단을 확실히 해줌으로써 이 요구를 만족시켰다.
상업적으로 생존가능한 전문가시스템의 또 다른 예는, 1978 년 리차드 듀다, 피터, 하드, 그리고 레네 레보우가 만든 PROSPECTOR 이다. PROSPECTOR 는 지질학에서의 전문가이다 : 어떤 광상이 어떤 특별한 지역에서 발견될수 있는 가능성을 예측한다. 석유, 천연가스, 헬륨의 발견을 예측하는 프로그램을 포함하여, 이 프로그램을 변형한 것이 여럿 있다.
1980 년대 초에는 세금 상담, 보험 충고, 법적인 도움을 줄 수 있는 전용 전문가시스템들이 도입되었다. 많은 프로그래머들은 1980 년대 말까지, 집이나 사무실에서 사용될 수 있는 "개인의" 전문가시스템의 커다란 시장이 생길 것이라고 믿는다. 이 시스템들은 원예 에서부터 자동 수리까지 많은 분야에서 전문가가 될 것이다. 실상, 전문가시스템은 개인용 컴퓨터에서 수행되는 가장 흔한 유형의 프로그램임을 증명할 수도 있다.
모든 전문가시스템은 지식베이스와 추론기관의 두 부분을 갖는다. 이 절에서는 전문가시스템이 두 부분을 모두 구현할 수 있는 여러 가지 서로 다른 방법들을 설명한다.
지식베이스는 어떤 주제에 대하여 특정한 정보와 규칙을 갖는 데이터베이스이다. 이 설명을 위해, 알아야 하는 두 가지 용어가 있다 :
그러므로, 지식베이스를 대상 사이의 관련 규칙과 속성을 갖는 일련의 대상으로 생각해보자. 가장 간단한 의미에서 (그리고, 많은 응용을 위하여), 속성에 적용되는 규칙은, 대상이 그 속성을 "갖는다 (has)" 또는 "갖지 않는다 (has not)" 라는 것을 말해준다. 그러므로, 대상이 소유하거나 소유하지 않는 일련의 속성을 사용하여 대상을 정의할 수 있다. 예를 들어, 여러 가지 유형의 과일을 나타내주는 전문가시스템은 다음과 같은 지식베이스를 가질 것이다.
|
대상 |
규칙 |
속성 |
|
사과 |
갖는다 갖는다 갖지 않는다 갖는다 |
나무에서 자란다 둥근 모양이다 아주 남쪽에서 자란다 빨간색이나 노란색이다 |
|
포도 |
갖는다 갖는다 갖는다 갖지 않는다 갖는다 |
덩굴에서 자란다 작은 크기이다 자주색이다 가시있는 덩굴이다 포도주를 만들 수 있다 |
|
귤 |
갖는다 갖는다 갖지 않는다 갖는다 |
나무에서 자란다 둥근 모양이다 북부에서 자란다 오렌지색이다 |
이 지식베이스에 대하여 생각해 보면, 간단해질 수 있다는 것을 알 수 있다. 단 한가지 규칙 - "갖는다" - 만 사용할 수 있고, "갖지 않는다" 관계를 설정해야 한다면 그 속성의 부정형을 사용할 수 있다. 그러므로, 규칙은 단순히 "소유한다 (possesses)" 가 되고, 간단해진 지식베이스는 다음과 같다 :
|
대상 |
소유 |
|
사과 |
나무에서 자란다 둥근 모양이다 아주 남부에서 자라지 않는다 빨간색이나 노란색이다 |
|
포도 |
덩굴에서 자란다 작은 크기이다 색이 가지각색이다 덩굴에는 가시가 없다 포도주를 만들기 위해 사용될수 있다. |
|
귤 |
나무에서 자란다 둥근 모양이다 북부에서 자랄수 있다 오렌지색이다 |
비록 어떤 복잡한 전문가시스템은 단순히 "소유한다" 보다 더 복잡한 규칙을 필요로 할지도 모르지만, 이 규칙은 많은 상황에 대하여 충분하고 지식베이스를 크게 간략화시킨다. 이 책의 나머지에서는 지식베이스가 대상과 속성으로만 이루어졌다고 가정한다.
추론기관은 일치하는 대상을 찾기 위하여 제공하는 정보를 사용하려고 시도하는 전문가시스템의 일부분이다. 추론기관의 두가지 넓은 부류가 있다 ; 결정적 (deterministic) 과 확률적 (probabilistic). 이 두 부류 사이의 차이점을 이해하기 위해서, 두 전문가를 생각해보자 - 하나는 화학에서 다른 하나는 사회학에서. 화학자는 문제의 원자가 두 개의 전자 (electron) 을 가지면 헬륨 원자라고 확실히 (certainty) 보고할 수 있다. 전자의 수가 원소의 유형을 결정하기 때문에 원자의 명명에 대해서는 의심이 없다. 그러나, 사회학자에게, 학생들이 학교를 그만두는 것을 막는 최선의 방법이 무엇이냐고 물으면, 사회학자는 단지 있을 수 있는 것으로, 또는 어떤 성공률을 갖는 것으로 제한된 대답을 할 것이다. 그러므로, 대답은 가능성은 있지만 불확실하다.
대부분은 결정적이 아니고 오히려 어느 정도 확률적이다. 그러나, 이 중 많은 수에 대하여, 그것들을 결정적인 상황으로 다룰 수 있기 때문에 불확실성 요인이 통계적으로 중요하지 않다. 이 장의 나머지 부분에서는 결정적 전문가시스템의 논리가 더 명확하므로 그것만을 다룬다 (그러나, 제 8 장에서는 확률과 불확실성을 다룬다.)
확실성과 불확실성이라는 두 가지 넓은 부류 외에, 추론기관을 구성하는 세가지 기본 방법이 있다 : 전진추론, 후진추론, 규칙값. 이 방법들의 차이점은 추론이 목표에 도달하려고 시도하는 방법에 관계된다.
전진연쇄는 데이터 지향 (data-driven) 이라고도 부른다. 왜냐하면 추론기관이 대상물 (object) 인 종단 지점에 도달할 때까지 논리 AND 와 OR 들의 네트워크를 통해 이동하도록 사용자가 제공하는 정보를 추론기관이 사용하기 때문이다. 만약 추론기관이, 존재하는 정보를 사용하여 대상을 발견할 수 없다면, 더 많은 정보를 요구한다. 대상을 정의하는 속성은 대상으로 유도하는 경로를 만든다 : 대상에 도달하는 유일한 방법은 모든 규칙을 만족하는 것이다. 그러므로, 전진연쇄 추론기관은 어떤 정보를 가지고 시작하여 그 정보에 맞는 대상을 발견하려고 한다.
전진연쇄가 어떻게 작동하는지 이해하기 위하여, 차가 작동하지 않는 문제에 대한 견해를 듣기 위하여 이 경우의 전문가인 기능공에게 전화를 건다고 생각해 보자. 기능공은 무엇이 잘못되었는지 설명해 줄 것을 요구한다. 차에 전력손실과 노킹 (knocking) 이 있다는 것과, 때때로 점화 장치를 끈 후에도 계속 운전했으며, 여러 달 동안 엔진을 조정해 주지 않았다는 것을 설명한다. 이 정보를 이용하여 기능공은 차는 엔진 조정을 절실히 필요로 할 가능성이 가장 높다고 말한다.
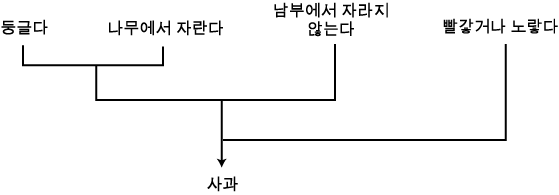
만약 앞에서 설명된 과일 지식베이스로 되돌아가 생각한다면 그림 1 에서처럼 적절한 속성이 주어질 때 전진연쇄 추론기관이, 대상인 사과에 어떻게 도달하는가를 보이는 다이아그램을 만들 수 있다. 보는 바와 같이, 전진연쇄 시스템은 기본적으로 잎 노드로부터 루트 노드로 트리를 만든다.
그림 1 대상물 사과 (apple) 를 향한 전진연쇄 방법
후진연쇄는 전진연쇄의 반대이다. 후진연쇄 추론기관은 가설 (hypothesis) 을 갖고 시작하여 그것을 확신하거나 부정하기 위한 정보를 요구한다. 후진연쇄는, 전문가시스템이 한 대상을 갖고 시작하여 그것을 확증하려고 하기 때문에, 때때로 목적 지향 (object-driven) 이라고 부른다.
후진 연쇄가 어떻게 작동하는지 이해하기 위해서, 컴퓨터가 갑자기 작동을 멈추었다고 생각해보자. 첫 번째 가설은 전력이 나갔다는 것이다. 이를 체크하기 위해, 환풍기 (fan) 소리를 들어본다. 환풍기가 돌아가는 소리가 들리면 이 가설을 거절하고 다른 것으로 진행한다. 두 번째 가설은 잘못된 소프트웨어 때문에 컴퓨터가 고장났다는 것이다. 이 가능성을 확인하거나 거절하기 위하여, 컴퓨터가 성공적으로 다시 부트될 것인지 알기 위하여 리셋시킨다. 다행히도, 컴퓨터는 재부트된다 ; 두 번째 가설은 참이 된다.
문제의 과일이 사과이면, 과일 지식베이스에 후진연쇄 추론을 적용하여 그림 2 에 있는 도표를 만들어낸다. 도표가 보여주듯이, 후진연쇄는 트리를 자른다. 이것은 트리를 구성하는, 전진연쇄의 반대 과정이다.
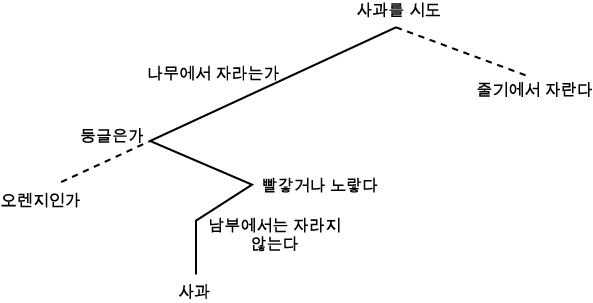
그림 2 대상물 사과 (apple) 를 향한 후진연쇄 방법
규칙값 추론기관은 시스템의 현재 상태에 따라 가장 큰 중요성을 갖는 정보를 요구하기 때문에 전진연쇄나 후진연쇄 시스템보다 이론상 우수하다. 규칙값 추론기관은 실제로 개선된 후진연쇄 기관이다. 일반적인 작동 원리는 이렇다. 즉, 시스템으로부터 불확실성이 가장 큰 것을 제거할 (remove the most uncertainty from the system) 정보를 다음 정보로서 시스템이 요구한다.
규칙값 접근 방식을 이해하기 위해, 아이가 아파서 의사를 불렀다고 생각해보자. 의사는 먼저 아이가 열이 있는지를 묻는데, 이것은 이 질문에 대한 많은 가능성의 수를 줄이기 때문이다. 당신이 "예" 하고 대답하면, 의사는 당신에게 아이가 구토를 느끼는 지를 묻는다. 첫 번째 질문에서처럼, 의사는 현재 상태가 주어져 있을 때 그 대답이 진단에 가장 큰 영향을 미치기 때문에 다른 질문들보다 이 질문을 한다. 이 과정은 의사가 진단을 할수 있을 때 까지 계속된다. 이 예에서, 중요한 점은 의사가 결론까지 가장 빠르게 이를 질문들을 선택한다는 것이다.
규칙값 시스템의 문제점은 구현하기가 어렵다는 것이다. 여기에는 두가지 이유가 있다 : 우선, 실생활에서, 지식베이스는 종종 너무 커서 가능한 조합의 수는 시스템 용량을 초과한다. 그러므로, 시스템은 어떤 주어진 상태에 대하여 어느 정보가 가장 많은 불확실성을 제거하는지 알 수 없다. 두 번째, 규칙값 시스템은 지식베이스로 하여금 표준 대상-속성 정보뿐만 아니라 값 한정사 (Quantifier) 를 포함하도록 요구하는데 이것은 지식베이스 구성하는 일을 더 어렵게 한다. 그러나, 자신을 다른 것들보다 규칙값 추론으로 유도하는 어떤 상황이 있다. 또한, 구현될 때, 규칙값 시스템은 일반적으로 다른 두 방법보다 더 나은 일을 한다.
어떤 규칙값 전문가시스템은 시스템의 여러 면을 기록하기 위하여 통계 모듈을 갖는 전진연쇄 또는 후진연쇄로 시작했다. 후에, 그런 유형의 전문가시스템이 잠깐 사용된 뒤에, 이 통계 정보는 규칙값 접근 방식을 구현하기 위하여 사용될 수 있다.
이 시점에서, 추론기관의 세가지 유형 중 어느 것이 사용하기에 가장 좋은지 알고 싶어할 것이다. 대답은, 세가지 모두가 그 일을 할수 있기 때문에 다분히 각각의 성능에 따른다. 앞에서 언급했듯이, 규칙값 시스템이 구현하기가 다소 어렵다는 것을 알수 있다 : 따라서, 전문가시스템을 구축하는데에 전문가가 될 때 까지 아마도 이 방법을 피해야 할 것이다.
전진연쇄 방법은 트리를 구성하기 때문에 지식베이스로부터 가장 많은 양의 정보를 이끌어내는 과정을 다소 쉽게 한다. 전형적인 전진연쇄 시스템은 속성과 일치하는 가능한 모든 대상들을 발견하다. 후진연쇄 방법의 장점은 대상을 발견하기에 충분한 정보만들 요구한다는 것이다. 그러므로, 후진연쇄 시스템은 목표위주 (goal-driven) 이기 때문에 적절한 정보만이 시스템에 입력되게 한다. 후진연쇄 시스템은 단 하나의 대상만을 원할 때 좋다 - 비록 다른 대상들도 그 속성을 만족한다고 하더라도 좋다. 복수해를 발견하는 후진연쇄 전문가시스템을 만들 수 있다. 하지만 전진연쇄 전문가시스템을 구성하는 것보다 약간 더 많은 일을 요구한다.
최종적인 분석에서, 사용하려는 실제 접근방식은 각자에게 달려있다. 그러나, 모든 것이 같으면, 후진연쇄 방법은 구현하기가 더 쉬우므로, 기대할 것으로 생각하는 방법인 듯한 전문가시스템을 생성한다. 이러한 이유 때문에, 이 장에서는 후진연쇄를 사용하는 전문가시스템을 개발한다.
이제 전문가시스템에 필요한 배경을 갖고 있으므로, 실제 전문가시스템이 어떤가를 볼 준비가 되어있다. 이 절에서는 후진 연쇄를 사용하는 만능 전문가시스템을 만든다. 여러 가지 다른 지식베이스들을 가지고 같은 추론 기관을 사용할수 있게 하기 때문에 만능이라고 부른다. 또한 지식베이스를 만드는데 필요한 루틴들을 포함한다. 그러나 시작하기 전에, 전문가시스템이 구현되는 방법에 대하여 가질 수 있는 몇 가지 선입견을 버리는 것이 중요하다.
불행하지만 또 이해가 가는 사실은, 사실상 AI 에 관한 모든 소개 책들은 간단한 동물 전문가시스템을 예로 사용한다는 것이다. 때때로, 소개적인 책은 그것을 다른 것으로 부를 수도 있지만, 거의 같은 방법으로 구성되어 있다. 비록 이 간단한 전문가시스템이 전문가시스템의 여러 면을 설명하는 (그리고 상상력을 자극하는) 역할을 하지만, 전문가시스템을 구현하는 데에 옳지 못한 방법을 제시한다. 추론기관에 대상과 속성이 혼합되어 있다 : 이것은 지식베이스가 프로그램으로 코드화되기 어렵다는 것을 의미한다. 이것은 여러 가지 이유 때문에 나쁜 프로그래밍 기법이다. 가장 나쁜 이유 중의 하나는, 지식베이스를 변경하고 질을 높이거나 확장하는 것은 프로그램 코드로의 변경-그리고 재컴파일을 의미하는 것이다. 이 변경은 우발적인 컴파일 에러에서부터 익숙치 못한 프로그래머에 의한 실제 코드의 다변성까지의 범위에 이르는 모든 종류의 골치거리로 노출된다. 지식베이스를 프로그램으로 어렵게 코딩하는 것이 나쁜 프로그래밍 기법이라는 또다른 이유는, 지식베이스로의 실지 변화는 사용자가 프로그램을 변화시킬 것을 요구할 것인데 이것은 자존심 있는 어떤 프로그래머도 원하지 않는 일일 것이다. 또, 이렇게 되면 사용자가 원시 코드를 필요로 한다는 의미인데 이것은 어떤 상업 소프트웨어 개발자도 허용하지 않을 것이다.
이 설명에서 보여주듯이, 지식베이스는 추론기관과 분리되어야 한다. 이런 방식으로 만이 현명한 소프트웨어 개발자들은 진실로 작동할 수 있는 시스템을 만들 수 있다. 이것이 바로 모든 상업적 전문가시스템의 구조이고 이 장에 있는 전문가시스템의 구조이다.
전문가시스템 프로그램 작성하는 방법을 보기 전에, 이 절에서는 추론기관을 만들기 위한 것들을 실제 용어로 정의한다. 이 절에서는 지식베이스가 단지 대상과 그 속성들로만 구성될 것이라고 가정한다. 추론기관이 무엇을 할수 있어야 하는지 이해하기 위해서, 다음의 작은 지식베이스를 사용해보자 :
|
대상 |
속성 |
|
1 2 3 4 |
A, B, C A, B, Y B, X A, B, D |
가장 원시적인 수준에서, 추론기관은 대상 1 이 목표라고 가정하여 시작하고 목표가 대상 1 의 속성을 가지고 있는지 물어 이를 확인하려고 한다. 만약 그렇다면, 추론기관은 대상 1 이 답이라고 보고한다. 그렇지 않으면, 추론기관은 대상 2 로 진행하고 대상 2 의 속성에 관하여 질문한다. 이 과정은 추론 기관이 적당한 대상을 발견하거나 대상이 더 이상 없을 때 까지 반복된다. 이것이 추론기관이 따라가는 단계이고 대상 4 가 목표이면 다음 대화가 생긴다.
이렇게 작동하는 전문가시스템은 사용하기가 지루할 뿐 아니라 시스템에 대상이 좀 더 많을 때는 거의 가치가 없다. 이런 시스템에는 두가지 단점이 있다. 첫째, 같은 속성에 대하여 여러번 묻는다. 둘째, 대상 3 을 조사할 때 불필요한 질문을 한다. 시스템은 이전의 질문으로부터 문제의 대상이 속성 A 를 갖는다는 것을 알았어야 했다 : 대상 3 은 속성 A 를 갖지 않기 때문에 더 시도하지 않고 대상 3 을 거절했어야 했다. 속성 X 에 대한 지식이 유용했을 수도 (could) 있지만, 추론기관은 현재 상태와 맞지 않는 모든 대상들을 건너뛴다면 평균적으로 더 효율적일 것이다. 그러므로, 요구되는 것은, 목표와 같은 대상 4 를 갖는 지식베이스가 주어졌을 때 다음 대화를 생성하는 추론기관이다.
이런 유형의 추론기관을 목표로 하면 추론기관이 갖추어야 할 시방은 다음과 같다 :
1. 전문가시스템은 같은 속성에 대하여 두 번 질문을 해서는 안된다.
2. 전문가시스템은, 즉시 거절해야 하고, 이미 알려진 필요한 속성들중 하나 이상 갖지 않는, 또는 이미 거절된 속성을 갖는 모든 대상을 그냥 넘어가야 한다.
3. 명령에 대하여, 전문가시스템은 왜 그 추론을 따르고 있는지 보고할 수 있어야 한다.
세 번째 제한조건은 전문가시스템이 올바로 동작하고 있다는 것을 증명하는 방법일 뿐 아니라 사용자를 교육시키는 방법이기도 하다.
전문가시스템을 만들 때, 첫 단계는 지식베이스의 구조를 정의하는 것이다. 지식베이스에 있는 각 엔트리는 대상의 이름과 일련의 속성들로 구성되어야 한다. 대상을 포함하는 부분을 구성하는 가장 쉬운 방법 중의 하나는 다음 구조를 갖는 배열을 사용하는 것이다 (연결 리스트나 트리를 사용할 수도 있지만).
|
struct object { char name[80]; struct attribute *alist; /* pointer to list of attribute */ } ob; struct object k_base[MAX]; /* holds the knowledge base */ |
속성의 수를 모르기 때문에, 속성 리스트는 다음 구조의 단일 연결 리스트이다.
|
struct attribute { char attrib[80]; struct attribute *next; /* use linked list */ } at; |
알게 되겠지만, 추론기관은 목표에 속하는 모든 속성과 속하지 않는 속성을 추적해 나가야 한다. 이를 하는 가장 좋은 방법은 구조 유형 attribute 의 두 연결 리스트를 사용하는 것이다 : 두 포인터 yes 와 no 는 이 리스트들의 처음을 갖게 된다. 총괄변수 l_pos 는 현재 지식베이스에 있는 대상들의 수를 가지고 있다. 전문가시스템의 전체 데이터베이스 선언 부분이 다음에 있다 :
|
# define MAX 100 /* arbitrary, could be much larger */ struct attribute { char attrib[80]; struct attribute *next; /* use linked list */ } at; struct object { char name[80]; struct attribute *alist; /* pointer to list of attribute */ } ob; struct object k_base[MAX]; /* holds the knowledge base */ int l_pos=-1; /* location of top of k base */ struct attribute *yes, *no; /* used for yes and no lists */ struct attribute *yesnext, *nonext; |
실제로 추론기관을 개발하기 전에, 지식베이스에 정보를 넣을 루틴을 만들어야 한다. 보통 상업적 전문가시스템에서처럼 별도의 프로그램을 작성할 수 있지만, 간단히 하기 위해, 사용자로 하여금 시스템에 정보를 입력하게 하는 루틴들은, 여기서 개발된 전문가시스템에 구축된 선택 사항일 것이다. 다음에서 보듯이, enter() 는 대상의 이름과 속성 리스트를 읽는다. 이 과정은 사용자가 빈 줄을 타이핑할 때 까지 반복된다. 그리고 나서, enter() 는 또 다른 대상을 위하여 프롬프트를 내보낸다 : 다른 대상의 이름과 속성을 입력하거나, 엔트리 과정을 건너뛰기 위하여 빈 줄을 입력하게 하였다.
|
/* input an object and its list of attributes */ enter( ) { int t; struct attribute *p, *oldp;
for (; ;) { t=get_net( ); /*get the index of next available object in k_base */ if (t == -1) { printf("Out of list space. \n"); return ; } printf("object name : "); gets(k_base[t].name) { if (!*_base[t].name) { l_pos--; break; } p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf("Out of memory. \n"); return; } k_base[t].alist=p; printf("Enter attributes (RETURN to quit) \n"); for (; ;) { printf(": "); gets(p->attrib); if(!p->attrib[0]) break; oldp=p; p->next=struct attribute *) malloc(sizeof(at)); p=p->next; p->next'\0' ' if (p == '\0') { printf("Out of memory. \n"); return; } } oldp->next='\0'; } } |
이제 정보를 지식베이스에 로드할 수 있게 되었으므로, 추론기관은 도전해볼 준비가 되어있다. 추론기관은 전문가시스템의 추진력이다. 비록 추상적인 의미에서는 아주 간단하지만, 추론기관을 구현하는 것은 어려울 수도 있다. 여기서 개발된 추론기관은 아주 간단하지만, 실제로 많은 업무에 유용하다. 상업적 전문가시스템은 일반적으로 이 전문가시스템에 부과하는 것보다 더 많은 제약조건과 요구사항을 갖는다는 것을 기억해야 한다. 그러나, 여기에서 개발한 추론기관은 더 발전된 시스템을 위한 시작점 역할은 충분히 할 수 있다.
추론기관의 맨 윗 수준 함수는 다음에 있는 query() 이다.
|
/* inquire information from the expert */ query( ) { int t; char ch; struct attribute *p;
for (t=0 ; t<=1_pos;t++) { p=k_base[t].alist; if (try(p,k_base[t].name)) { printf("the object is %s\n", k_base[t].name); return; } } printf("No object found\n"); } |
query() 함수는 주요 루틴, try() 함수에 대한 드라이버로서의 역할만 하기 때문에 매우 간단하다. 본질적으로, query() 는 try() 가 일치 (match) 를 발견하거나 지식베이스에 더이상 할 것이 없을 때까지 한 번에 한 대상 씩을 try() 에게 보낸다. try() 함수는 다음에 있는 것처럼, 추론기관의 지능 (intelligence) 을 포함한다.
|
/* try an object */ try(p, ob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p)) return 0 ;
if (!trailyes(p)) return 0 ; while(p) { /* if already been asked then move on to next attribute */ if (ask(p->attrib)) { printf("is/does/has if %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out of memory\n"); return ; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib,p->attrib); if (!no) { no=a; nonext=no; } else { nonext->next=a; nonext=a; } return 0; case 'y': strcpy(a->attrib,p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } p=p->next; break; case 'w' : /* why? */ printf("trying %s\n", ob); if(yes) printf("it is/has/does:\", ob); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf("and is/has/does not :\n"); t=no; while(t) { printf("%s\n", t->attrib); t=t->next; } break; } } else p=p->next; } return 1; } |
try() 함수는 다음과 같이 작동한다. 첫째, trailyes() 와 trailno() 루틴은 건네진 각 대상의 속성 리스트를 체크한다. trailyes() 와 trailno() 루틴은 시스템의 현재 상태를 만족시키지 않는 대상을 스크린으로 내보낸다. 실제로, trailyes() 는 대상의 속성이 그 대상이 가져야 한다고 사용자가 지정한 모든 속성을 갖는다는 것을 체크하고, trailno() 는 그 대상이 거절된 대상을 갖지 않는다는 것을 확인하기 위하여 체크한다. 이 단계는 시방의 첫 번째 제약조건을 만족시킨다.
다음, 대상이 이미 확인된 속성을 포함하면, try() 는 리스트에서 다음 속성으로 진행한다 - 그리하여 질문이 두 번 생기는 것을 막는다. ask() 함수는 이 결정을 하고 시방의 두 번째 제약조건을 만족시킨다.
다음, try() 는 사용자에게 속성에 대하여 묻는다. 각각의 긍정적인 대답은 try() 로 하여금 yes 속성 리스트에 그 속성을 더하게 한다. 그리고 나서 try() 는 다음 속성을 시도한다. 모든 속성들이 일치하면, 대상이 발견되었고 try() 는 참 (true) 을 리턴한다. 각각의 부정적인 대답은 try() 로 하여금 no 리스트에 그 속성을 더하게 하고 거짓 (false) 을 리턴한다.
마지막으로, 사용자는 또한 "Why" 의 W 를 타이프할 수 있다. 이것은 시스템으로 하여금 현재의 추론과정을 정당화 (justify) 하게 한다. 이 단계는 시방의 세 번째 제약조건을 만족시킨다. 지원 함수 trailyes(), trailno(), ask() 가 다음에 있다.
|
/* see if it has any attributes known not trailno(p) struct attribute *p; { struct attribute *a, *t;
a=no; while(a) { t=p; while(t) { if (!strcmp(t->atrib, a->attrib)) return 0; /* does have a negative attribute */ t=t->next; } a=a->next; } return 1; }
/* see if it has all attributes known to be part of the object by checking the yes list */ trailyes(p) struct attribute *p; { struct attribute *a, *t; char ok;
a=yes; while(a) { ok=0 t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) ok=1; /* does have a needed attribute */ t=t->next; } if (!ok) return 0; a=a->next; } return 1; }
/* see if attribute already asked*/ ask(attrib) char *attrib; {
struct attribute *p;
p=yes; whiple(p && strcmp(attrib, p->attrib)) p=->next;
if (!p) return 1; /*false if end of list */ else return 0; } |
사용자는 지식베이스에 정보를 한 번 넣기만 하면 되기 때문에, save() 와 load() 함수는 디스크 파일 expert.dat 로부터 지식베이스를 저장하고 로드하기 위하여 사용된다 (그러나, 사용자로 하여금 파일의 이름을 지정하는 것이 쉬울 것이다. 이러한 개선을 직접 하기 원할지도 모른다). save() 와 load() 루틴들이 아래에 나와 있다.
|
/* save the knowledge base */ save() { int t, x; stuct attribut *p; FILE *fp;
if ((fp=fopen("expert.dat", "w")) ==0) { printf("cannt open file\n" return; } printf("saving knowledge base\n");
for(t=0;t<=1_pos;++t) { for (x=0;x<sizeof(k_base[t].name);x++) putc(k_base[t].name[x], ); p=k_base[t].alist; while(p) { for (x=0;x<sizeof(p->atrib);x++) putc(p->attrib[x], fp); p=p->next; } /* end of list marker */ for (x=0;x<sizeof(p->attrib);x++) putc('\0', fp); } putc('\0', fp); fclose(fp); }
/* load the knowledge base */ load( ) { int t, x; struct attribute *p, *oldp; FILE *fp;
if ((fp=fopen("expert.dat", "r"))==0) { printf("cannot open file\n"); return; } printf("loading knowledge base\n");
/* free any old lists */ clear_kbase();
for (t=0;t<MAX;++t) { if ((k_base[t].name[0]=getc(fp))==0) break; for (x=1;x<sizeof(k_base[t].name);x++) k_base[t].name[x]=getc(fp); k_base[t].alist=(struct attribute *) malloc(sizeof(at)); if(!k_base[t].alist) { printf("Out of memory\n"); break; }
k_base[t].alist=(struct attribute *) malloc(sizeof(at)); p=k_base[t].alist; if(!p) { printf("Out of memory\n"); return; } for (;;) { for (x=0;x<sizeof(p->attrib);x++) p->attrib[x]=getc(fp);
if (!p->attrib[0]) { oldp->next='\0'; break; /* end of list */ } p->next=(struct attribute *) malloc(sizeof(at)); if (!p->next) printf("Out of memory\n"); break; } oldp=p; p=p->next; } } fclose(fp); l_pos=t-1; } |
전체 전문가시스템 프로그램이 다음에 있다. 이제 시범 수행을 할 수 있도록 컴퓨터에 입력해야 한다.
|
/* A simple expert system */
#include <stdio.h> #include <malloc.h>
#define MAX 100 /* arbitrary, could be much larger */
struct attribute { char attrib[80]; struct attribute *next; /* use linked list */ } at;
struct object { char name[80]; struct attribute *alist; /* pointer to list of attribute */ } ob;
struct object k_base[MAX]; /* holds the knowledge base */ int l_pos=-1; /* location of top of k base */
struct attribute *yes, *no; /* used for yes and no lists */ struct attribute *uesnext, *nonext; main() { char ch;
no-yes='\0'; do { free_trails(); ch=menu(); switch(ch) { case 'e': enter(); break; case 'q': query(); break; case 's': save(); break; case 'l': load(); }
} while (ch != 'x'); }
free_trails() { struct attribute *p;
while(yes) { p=yes->next; free(yes); yes=p; }
while(no) { p=no->next; free(no); no=p; } }
/* input an object and its list of attributes */ enter() { int t,i; struct attribute *p, *oldp;
for (;;) { t=get_next();
/* get the index of the next if (t == -1) { printf("Out of list space. \n"); return; } printf("Object name: "); gets(k_base[t].name);
if (!*k_base[t].name) { l_pos--; break; } p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf("Out of memory.\n"); return; } k_base[t].alist=p; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; printf("Enter attributes (RETURN to quit)\n"); for (;;) { printf(": "); gets(p->attrib); if(!p->attrib[0]) break; oldp=p; p->nest=(struct attribute *) malloc(sizeof(at)); if (p->next == '\0') { printf("Out of memory.\n"); return; } p=p->next; p->next='\0'; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; } oldp->next = '\0'; } }
/* These routines make up the inference engine */
/* inquire information from the expert */ query() { int t; char ch; struct attribute *p;
for (t=0;t<=l_pos;t++) { p=k_base[t].alist; if (try(p, k_base[t].name)) { printf("the object is %s\n", k_base[t].name); return; } } printf("No object found\n"); }
/* try an object */ try(p, ob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p)) return 0;
if (!trailyes(p)) return 0;
while(p) { /*
if already been asked then move on to next if (ask(p->attrib)) { printf("is/does/has it %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out of memory\n"); return ; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib, p->attrib); if (!no) { no=a; nonext=no; } else { nonext->next=a; nonext=a; } return 0; case 'y' : strcpy(a->attrib, p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } p=p->next; break; case 'w': /* why? */ printf("Trying %s\n", ob); if(yes) printf("it is/has/does:\n", ob); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf("and is/has/does not :\n"); t=no; while(t) { printf("%s\n", t->attrib); t=t->next; } break; } } else p=p->next; } return 1; }
/*
see if it has any attributes known not trailno(p) struct attribute *p; { struct attribute *a, *t; a=no; while(a) {
t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) return 0; /* does have a negative attribute */ t=t->next; } a=a->next; } return 1; }
/* see if it has all attributes known to be part of the object by checking the yes list */ trailyes(p) struct attribute *p; {
struct attribute *a, *t; char ok;
a=yes; while(a) { ok=0; t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) ok=1; /* does have a needed attribute */ t=t->next; } if (!ok) return 0; a=a->next; } return 1; }
/* see if attribute already asked */ ask(attrib) char *attrib; { struct attribute *p;
p=yes; while(p && strcmp(attrib, p->attrib)) p=p->next;
if (!p) return 1; /* false if end of list */ else return 0; }
/* support routines */ /* get next free index in k_base array */ get_next() { l_pos++; if (l_pos<MAX) return l_pos; else return -1; }
menu() { char ch; printf("(E)nter, (Q)uery, (S)save, (L)oad, e(X)it\n"); do { printf("chooose one:"); ch=tolower(getche()); } while (!is_in(ch, "eqslx")); printf("\n"); return ch; }
/* save the knowledge base */ save() { int t, x; struct attribute *p; FILE *fp;
if ((fp=fopen("expert.dat", "w"))==0) { printf("cannot open file\n"); return; } printf("saving knowledge base\n");
for (t=0;t<=lpos;++t) { for (x=0;x<sizeof(k_base[T].name);x++) putc(k_base[t].name[x],fp); p=k_base[t].alist; while(p) { for (x=0;x<sizeof(p->attrib);x++) putc(p->attrib[x],fp); p=p->next; } /* end of list marker */ for (x=0;x<sizeof(p->attrib);x++)putc('\0',fp); } putc('\0',fp); fclose(fp); }
/* load the knowledge base */ load() { int t, x; struct attribute *p, *oldp; FILE *fp;
if ((fp=fopen("exper.dat", "r"))==0) { printf("cannot open file\n"); return; } priintf("loading knowledge base\n")'
/* free any old lists */ clear_kbase();
for (t=0;t<MAX;++t) { if ((k_basd[t].name[0]=getc(fp))==0) break; for (x=1;x<sizeof(k_base[t].name);x++) k_base[t].name[x]=getc(fp);
k_base[t].alist=(struct attribute *) malloc(sizeof(at)); p=k_base[t].alist; if(!p) { printf("Out of memory\n"); return; } for (;;) { for (x=0;x<sizeof(p->attri);x++) p->attrib[x]=getc(fp);
if (!p->attrib[0]) { oldp->next='\0'; break; /* end of list */ } p->next=(struct attribute *) malloc(sizeof(at)); if (!p->next) { printf("out of memory\n"); break; } oldp=p; p=p->next; } } fclose(fp); l_os=t-1; }
/* reset the k base */ clear_kbase() { int t; struct attribute *p, *p2;
for (t=0;t<=l_pos;t++) { p=k_base[t].alist; while(p) { p2=p; free(p); p=p2->next;
} } } is_in(ch, s) char ch, *s; { while(*s) if (ch==*s++) return 1; return 0; } |
이제 전문가시스템을 컴퓨터에 넣었으므로, 그것을 수행하고 다음 정보를 지식베이스에 넣는다.
|
대 상 |
속 성 |
|
사과 (Apple) 귤 (Orange) 포도 (Grape) 나무딸기 (Raspberry) 배 (Pear) 수박 (Watermelon) 체리 (Cherry) 탄제린 (Tangerine) |
둥글고, 빨갛거나 노랗고, 나무에서 자람 둥글고, 나무에서 자라고, 오렌지색 가시가 없고, 넝쿨에서 자라고, 자주색 가시가 있고, 빨갛고, 줄기에서 자람 둥글지 않고, 빨갛거나 녹색이고, 나무에서 자람 크고, 녹색이고, 가시가 없고, 넝쿨에서 자람 작고, 나무에서 자라고, 빨갛거나 노란색 오렌지 나무에서 자라고, 둥글고, 표면이 매끄러움 |
지식이 준비된 시스템을 가지고, 다른 유형의 과일을 알아내기 위하여 사용한다. 다음에 오는 세가지 대화가 이 시스템을 사용하여 산출되었다.
|
is/has/does it round y is/has/does it red or yellow n is/has/does it grow on trees y is/has/does it orange y it is orange |
|
is/has/does it round n is/has/does it not thorns y is/has/does it grow on vines y is/has/does it purple n is/has/does it large y is/has/does it green y it is watermelon |
|
is/has/does it round n is/has/does it no thorns y is/has/does it grow on vines y is/has/does it purple n is/has/does it large y is/has/does it green w
Trying watermelon: it is/has/does: grow on vines no thorns it is/has/does not: round purple
is/has/does it green y it is watermelon |
세 번째 대화에서 why 명령 사용을 눈여겨 보기 바란다. 시스템을 가지고 실험해보기 바란다 ; 작동을 이해하고 확신되면 곧 다음 절로 진행해야 한다.
지식베이스를 검토해보면, 탄제르가 표면이 부드럽다는 부가적인 속성을 갖는 것을 제외하고 오렌지와 탄제르의 정의가 동일한 것을 알게 될 것이다. 그러므로, 사용자에게 비록 탄제르가 있지만, 주어진 것과 같은 전문가시스템은 항상 오렌지를 보고할 것이다. 왜냐하면 탄제르의 처음 세가지 속성과 일치하기 때문이다. 이 답은 어떤 상황에서는 받아들일 수 있지만, 대부분 완전한 해를 찾는 것이 중요할 것이다.
이제 모든 해를 찾도록 이 시스템을 변경할 방법을 연구해 보자. 시스템이 복수해를 찾을 수 있도록 query() 함수만을 약간 변형하면 된다. 새 버전이 다음에 있다.
|
/* inquire information from the expert */ query() { int t; char ch; struct attribute *p;
for (t=0;t<=1_pos;t++) { p=k_base[t].alist; if (try((p, k_basee[t].name)) { printf("%s fits current description\n", k_base[t].name); printf("continue? (Y/N): "); ch=tolower(getche()); printf("\n"); if (ch=='n') return; } } printf("No (more) object(s) found\n"); } |
이 버전에서, 시스템이 현재의 사실과 맞는 대상을 발견할 때마다 query() 는 그 이름을 출력하고 사용자에게 계속할 것인지를 묻는다. 사용자가 y 를 타이프하면, 탐색은 계속된다. 다음 대화에 변화가 나타나 있다.
|
is/has/does it round y is/has/does it red or yellow n is/has/does it grow on trees y orange fits the current description continue (Y/N)? y is/has/does it soft skinned y tangerine fits the current description contine (Y/N)? n |
비슷한 정의를 갖는 새로운 과일을 가지고 실험하려고 시도하기 원할지도 모른다. 이와같이, 프로그램은 때때로 아주 영리해 보인다.
좀 더 노력하면, 시스템이 why 명령에 대한 반응을 향상 시킬 수 있다. 프로그램이 현재 특정한 대상에서 작동하고 있는 이유를 알려주고는 있지만 다른 대상들을 왜 거절했는지는 알려주지 않는다. 이를 변경하는 것은 새로운 데이터베이스, 두 개의 새로운 함수, 그리고 프로그램의 다른 여러 부분의 변화를 요구한다.
새로운 데이터베이스는 거절당한 대상의 이름과 거절의 원인이 된 속성을 갖게 된다. 다음 구조 배열은 이 정보를 유지하기 위하여 사용된다.
|
struct rejected_object { char name[80]; char attrib[80]; /* attribute that caused rejection */ char condition; /* should it or shouldn't it have been found ? */ } rj; struct rejected_object r_base[MAX]; |
condition 필드는 대상에 어떤 속성이 없는지, 또는 대상이 이미 거절된 속성을 갖는지를 말해준다. 한 대상이 거절될 때마다 - try() 에서의 no 대답에 의해서든 trailyes() 나 trailno() 에 의해서든지, reject() 는 거절된 데이터베이스에 그 대상과 속성을 넣는다. reject() 함수가 다음에 있다.
|
/* place rejected object into database */ reject(ob, at, cond) char *ob, *at, cond; { r_pos++;
strcpy(r_base[r_pos].name, ob); strcpy(r_base[r_pos].attrib, at); r_base[r_pos.condition=cond; } |
시스템이 why 명령을 내보낼 때마다, 시스템은 새로운 함수 reasoning() 을 호출하는데, 이것은 시스템의 현재 상태를 보일 뿐 아니라 어떤 대상이 왜 거절되었는지를 보여준다. reasoning() 함수가 다음에 있다.
|
/* show why a line of reasoning is being followed */ reasonig(ob) char *ob; { struct attribute *t; int i;
printf("Trying %s\n", ob); if (yes) printf("it is/has/does:\n"); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf("it is/has/does not:\n"); t=no; while(t) { printf("%s\n", t->attrib); t=t->next; }
for (i=0;i<=r_pos;i++) { printf("%s is rejected because ", r_base[i].name); if (r_base[i].condition=='n') printf("$s is not an attribute.\n", r_base[i].attrib); else printf("%s is not an attribute.\n", r_base[i].attrib); } } |
이 변화와 첨가를 지원하려면, 프로그램 전체에 약간의 변화를 많은 부분에서 요구한다. 따라서 편의상, 개선된 전문가시스템 전체를 다음에 제시한다 :
|
/* An improve expert system that finds multiple goals and displays reasoning */
#include "stdio.h" #include <malloc.h> #define MAX 100 struct attribute { char attrib[80]; struct attribute *next; /* use linked list */ } at;
struct object [ char name[80]; struct attribute *alist; /* pointer to list of attributes */ } ob;
struct rejected_object { char name[80]; char attrib[80]; /* attribute that caused rejection */ char condition; /* should it or shouldn't it have been found ? */ } rj; struct rejected_object r_base[MAX]; /* holds the knowledge base */ int l_pos=-1; /* location of top of k base */ int r_pos=-1; /* location of top of reject base */
struct attribute *yes, *no; /* used foor yes and no llists */ struct attribute *yesnext, *nonext;
main() { char ch;
no=yes='\0'; do { free_trails(); ch=menu(); switch(ch) { case 'e' : enter(); break; case 'q': query(); break; case 's': save(); break; case 'l': load(); } } while (ch != 'x'); }
free_trails() { struct attribute *p;
while(yes) { p=yes->next; free(yes); yes=p; }
while(no) { p=no->next; free(no); no=p; } r_pos=-1; } /* input an object and its list of attributes */ enter() { int t, i; struct attribute *p, *oldp;
for (;;) { t=get_next(); /* get the index of the next availabel object in k_base */ if (t == -1) { printf("Out of list space.\n"); return; } printf("Object name: "); gets(k_base[t].name);
if (!*k_base[t].name) { l_pos--; break; }
p=(struct attribute *) malloc(sizeof(at)); if (p=='\0') { printf ("out of memory.\n"); return; } k_base[t].alist=p; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; printf("Enter attributes (RETURN to quit)\n"); for (;;) { printf(": "); gets(p->attrib): if(!p->attrib[0]) break; oldp=p; p->next=(struct attribute *) malloc(sizeof(at)); if (p->next == '\0') { printf("Out of memory.\n"); return; } p=p->next; p->next-'\0'; for (i=0;i<sizeof(p->attrib);i++) p->attrib[i]=' '; } oldp->next = '\0'; } }
/* inquire information from the expert */ query() { int t; char ch; struct attribute *p;
for (t=0;t<=1_pos;t++) { p=k_base[t].alist; if (try(p, k_base[t].name)) { printf("%s fits current description\n", k_base[t].name); printf("continue? (Y/N): "); ch=tolower(getche()); printf("\n"); if (ch=='n') return; } } printf("No (more) object(s) found\n"); }
/* try an object */ try(p, ob) struct attribute *p; char *ob; { char answer; struct attribute *a, *t;
if (!trailno(p, ob)) return 0;
if (!trailyes(p, ob)) return 0;
while(p) { /* if already been asked then move on to next attribute */ if (ask(p->attrib)) { printf("is/does/has it %s? ", p->attrib); answer=tolower(getche()); printf("\n");
a=(struct attribute *) malloc(sizeof(at)); if (!a) { printf("out memory\n"); return 0; } a->next='\0'; switch(answer) { case 'n': strcpy(a->attrib, p->attrib); if (!no) { no=a; nonext=no; } else { nonext->next=a; nonext=a; } reject(ob, p->attrib, 'n'); return 0; case 'y': strcpy(a->attrib, p->attrib); if (!yes) { yes=a; yesnext=yes; } else { yesnext->next=a; yesnext=a; } p=p->next; break; case 'w': /* why? */ reasonig(ob); break; } } else p=p->next; } return 1; }
/* see if it has any attributes known not to be part of the object by checking the no list */ trailno(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t;
a=no; while(a) { t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { reject(ob, t->attrib, 'n'); return 0; /* does have a negative attribute */ } t=t->next; } a=a->next; } return 1; }
/* see if it has all attributes known to be part of the object by checking the yes list */ trailyes(p, ob) struct attribute *p; char *ob; { struct attribute *a, *t; char ok; a=yes; while(a) { ok=0; t=p; while(t) { if (!strcmp(t->attrib, a->attrib)) { ok=1; /* does have a needed attribute */ } t=t->next; } if (!ok) { reject (ob, a->attrib, 'y'); return 0; } a=a->next; } return 1; }
/* see if attribute already asked */ ask(attrib) char *attrib; { struct attribute *p;
p=yes; while(p && strcmp(attrib, p->attrib)) p=p->next;
if (!p) return 1; /* false if end of list */ else return 0; }
/* show why a line of reasoning is being followed */ reasoning(ob) char *ob; { stuct attribute *t; int i;
printf("Trying %s\n", ob); if (yes) printf("it is/has/does:\n"); t=yes; while(t) { printf("%s\n", t->attrib); t=t->next; } if (no) printf("it is/has/does noot:\n"); t=no; while(t) { printf("%s\n", t->attrib); t=t->next; }
for (i=0;i<=r_pos;i++) { printf("%s is rejected because ", r_base[i].name); if (r_base[i].condition=='n') printf("%s is not an attribute.\n", r_base[i].attrib); else printf("%s is a required attribute.\n", r_base[i].attrib); } }
/* place rejected object into databese */ reject(ob, at, cond) char *ob, *at, cond; { r_pos++;
strcpy(r_base[r_pos].name, ob); strcpy(r_base[r_pos].attrib, at); r_base[r_pos].condition=cond; }
/* get next free index in k_base array */ get_next() { l_pos++; if(l_pos<MAX) return l_pos; else ruturn -1; }
menu() { char ch; printf("(E)mneter, (Q)uery, (S)save, (L)oad, e(X)it\n"); do { printf("choose one:"); ch=toloower(getche()); } while (!is_in(ch, "eqslx")); printf("\n"); return ch; }
save() { int t, x; struct attribute *p; FILE *fp;
if ((fp=fopen("expert.dat", "w"))==0) { printf("cannot open file\n"); return; } printf("saving knowledge base\n");
for (t=0;t<=1_pos;++t) { for (x=0;x<sizeof(k_base[t].name);x++) putc(k_base[t].name[x], fp); p=k_base[t].alist; while(p) { for (x=0;x<sizeof(p->attrib);x++) putc(p->attrib[x], fp); p=p->next; } /* end of list marker */ for (x=0;x<sizeof(p->attrib);x++) putc('\0', fp); } putc(0, fp); fclose(fp); }
load() { int t, x; struct attribute *p, *oldp; FILE *fp;
if((fp=fopen("expert.dat", "r"))==0) { printf("cannot open file\n"); return; } printf("loading knowledge base\n");
/* free any old lists */ clear_kbase(); for(t=0;t<MAX;++t) { if((k_base[t].name[0]=getc(fp))==0) break; for (x=1;x<sizeof(k_base[t].name);x++) k_base[t].name[x]=getc(fp);
k_base[t].alist=(struct attribute *) malloc(sizeof(at)); p=k_base[t].alist; if(!p) { printf("Out of memory\n"); return; } for(;;) { for(x=0;x<sizeof(p->attrib);x++) p->attrib[x]=getc(fp); if(!p->attrib[0]) { oldp->next='\0'; break; /* end of list */ } p->next=(struct attribute *) malloc(sizeof(at)); if(!p->next) { printf("out of memory\n"); break; } oldp=p; p=p->next; } } fclose(fp); l_poos=t-1; }
clear_kbase() { int t; struct attribute *p, *p2;
for(t=0;t<=l_pos;t++) { p=k_base[t].alist; while(p) { p2=p->next; free(p); p=p2; } } }
is_in(ch, s) char ch, *s; { while(*s) if(ch==*s++) return 1; return 0; }
|
시범 수행에서 과일 데이터베이스를 사용한 향상된 출력 예가 다음에 나와 있다.
|
is/has/does it round? y is/has/does it red or yellow? n is/has/does it grow on trees? w
Trying orange it is/has/does: round it is/has/does not: red or yellow
apple is rejected because red or yellow is not an attribute |
보는 바와 같이, 이 대화는 시스템이 여러 대상들을 왜 거절했는지 설명해 주기 때문에 사용자에게 상당히 많은 정보를 전달해 준다. 큰 지식베이스를 가지고, 많은 거절 (시스템의 현재 상태와 관계없는 많은 것들) 을 디스플레이 하는 것을 막을 방법을 찾는 것이 필요할 수도 있다. 이런 개선은 스스로 해보기 바란다 ; 그러나, 힌트로서, 지식베이스는 또한 시스템이 현재의 가설에 관련된 거절된 대상들만 디스플레이하도록 어떤 관계를 동반할 것을 요구할 것이다.
이 장에서 개발된 전문가시스템은 지식베이스에 있는 첫 번째 엔트리를 갖고 탐색을 시작한다. 그리고 단순히 대상들의 리스트를 따라 순서대로 진행한다. 이 과정은 대상이 적은 경우에는 좋지만, 더 큰 지식베이스를 사용할 때 문제를 일으킬 수도 있다. 예를 들어, 묘사하는 것이 숫자 999 로 표현한 천개의 대상이 있고 공통된 속성이 있으면, 찾는데에 오랜 시간이 걸릴 수도 있다. 다른 문제도 있겠지만 이런 종류의 문제를 해결하려고 하면 지식공학이라는 분야가 필요하다.
지식공학은 지식베이스가 조직되고, 구성되고, 확증되는 방법을 다루는 분야이다. 이 주제에 대하여 충분히 설명하는 것은 이 책의 범위를 넘어서지만, 지식베이스를 구축하려면 여러 가지 어려움에 봉착한다는 점은 알아야 한다. 지식공학 분야는 역사가 아주 짧고, 연구될 것이 많다는 것을 명심하자.
앞에서 말했듯이, 이 장에서 개발된 전문가시스템은 지식베이스의 기초에서 시작하여, 전체를 순차적으로 진행하였다. 휴리스틱만 추가되면, 이것은 추론기관에서 기대하는 가장 좋은 결과가 될 것이다. 그러나, 지식베이스를 만드는 사람으로서, 지식베이스의 구성도 제어할 수 있다. 이렇게 하면 더 좋아지기도 더 나빠지기도 할 것이다.
어떤 경우에는, 정보를 구성하는 좋은 방법으로 가장 가능성이 많은 대상들을 맨 위에 놓고, 가장 가능성이 적은 대상들을 아래 부분에 놓는다. 문제는 어느 대상이 가능성이 높고 어느 것이 가능성이 적은지를 결정하는 것이다. 사람 전문가조차도 어느 해가 가장 가능성이 높은지 모를 수 있다. 때때로, 지식베이스를 임의로 만들어서, 시스템이 각 대상을 선택하는 횟수를 기록하는 동안의 짧은 기간만 사용하는 수도 있다. 이런 빈도수를 사용하면 지식베이스를 다시 배열할 수 있다.
지식베이스를 구성하는 또 다른 방법은 지식베이스의 윗부분에 "트리" 의 가장 큰 부분이 잘리게 하는 그런 속성들을 놓는 것이다. 큰 지식베이스에 대해서, 어는 속성이 가장 큰 효과를 갖는지 결정하는 것은 어렵다는 것을 알 수 있다.
이 장 전체에서 사람 전문가를 찾을 수 있고, 그 전문가의 지식을 쉽게 빼낼 수 있다고 가정했다. 불행히도, 그런 경우는 거의 없다. 먼저, 누가 진짜 전문가이고 아닌지 결정하는 것은 꽤나 어렵다. 특히 그 주제에 대하여 거의 모를 때 문제가 된다. 두 번째로, 같은 대상에 대하여 두 명의 다른 전문가가 종종 의견이 틀리다 - 이것은 어느 것을 사용할지 아는 것을 어렵게 한다.
전문가들의 의견이 다를 때, 일반적으로 세가지 중에서 선택을 할 수 있다. 첫째, 한 전문가를 선택하고 다른 것을 무시한다. 이것은 분명 가장 쉬운 선택이다. 하지만 지식베이스가 어떤 잘못된 정보를 포함할 수 있다는 것을 의미한다 (그러나 옳지 못한 정보의 양은 사람 전문가가 제공할 수 있는 것뿐이다). 둘째, 정보를 평균화할 수 있다 : 즉, 두 전문가 사이에 공통된 정보만 사용한다. 이러한 선택이 첫 번째 것만큼 쉽지는 않지만 그리 큰 문제없이 이 과정을 종종 사용할 수 있다. 단점은 지식베이스의 내용이 완화된다는 것과, 어느 전문가의 지식도 충분히 반영되지 못한다는 것이다. 세 번째, 두 전문가의 지식을 모든 시스템에 포함해서 사용자가 결정하게 할 수도 있다. 각 항목에 대하여 확률 인자 (probability factor) 를 부가할 수 있다. 이 선택이 비록 어떤 상황에서는 받아들여 질 수 있지만, 많은 응용에 대하여 전문가시스템이 권위가 있기를 원할 것이다 - 즉, 사용자가 결정하기를 원하지 않는다.
또 다른 어려운 점은 대부분의 사람 전문가가 그들이 무엇을 아는지를 모른다는 것이다 : 사람은 컴퓨터가 할 수 있는 것과 같은 방법으로 "메모리 덤프" 를 할 수 없다. 그러므로, 필요한 정보를 모두 뽑아내는 것이 어려울 수 있다. 또한, 어떤 전문가들은 그들이 알고 있는 모든 것을 말해주기 위하여 시간이 걸리는 것을 자진해서 하려고 하지 않을 것이다.
비록 협조적이고, 자신의 전문지식에 대하여 완벽하게 설명해 줄 전문가를 찾았다고 하더라도, 지식을 컴퓨터에 정확하게 베껴 넣었다는 것을 확증하는 문제에 여전히 부딪치게 된다. 본질적으로, 지식베이스를 시험해 봐야 한다. 문제는 이렇다. 지식베이스를 어떻게 테스트할 것인가?
제 1 장에서 언급했듯이, 소모적인 탐색은 폭발적 탐색이 되기 때문에, 아주 작은 데이터 집합 이외의 어떤 것에도 적용이 불가능하다. 그러므로, 대부분의 실세계 전문가시스템에 대하여, 지식베이스가 정확하다는 것을 완벽하게 증명할 방법은 없다. 가장 좋은 해결은 지식베이스의 정확성에 대하여 아주 자신할 수 있도록 충분한 테스트를 하는 것이다. 통계적 표본 기법을 사용하여, 요구하는 어떤 신뢰수준 (confidence level) 이든 산출할 일련의 테스트를 고안할 수 있다.
또다른 접근 방식으로, 일관성을 위하여 지식베이스에 있는 모든 정보가 그 자체와 일치하는지 알기 위하여 시스템으로 하여금 직접 체크하게 할 수도 있다. 이것은 확실히 모든 문제를 발견하지는 않겠지만, 몇 개는 발견할 것이다. 그러나 이 자기체크 (self-check) 를 어떻게 구현하는 지에 따라서, 어떤 커다란 지식베이스에서는 폭발적인 '벽 (brick wall)" 에 부딪칠 수도 있다. 그래서 이 방법을 사용하는 것이 불가능할지도 모른다.
그러므로, 전문가시스템을 더 많이 사용하게 됨에 따라, 지식베이스 확증 (verification) 은 가장 중요한 연구분야 중의 하나가 될 것이다.