Support Vector Machine
.... Support vector machine (SVM) 은 분류 (classification) 와 회귀 (regression) 에 응용할 수 있는 지도학습 (supervised learning) 의 일종이다 .........
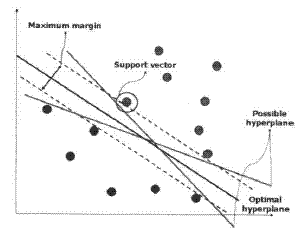
기본적인 분류를 위한 SVM 은 입력공간에 maximum-margin hyperplane을 만든다. yes 또는 no 값이 주어진 training sample 이 주어지고, 가장 가까이 있는 example (margin) 에서 hyperplane 까지의 거리가 최대가 되도록 training sample 들을 yes 와 no 로 나누게 되며, 그것이 maximum-margin hyperplane 이다. margin 이 최대일 때 최소가 되는 probabilistic test error bound를 보여주는 Vapnik Chervonenkis theory에서 maximum-margin hyperplane 이 처음 사용되었다. maximum-margin hyperplane 의 파라미터들은 quadratic programming (QP) optimization problem을 풀어서 얻어진다. SVM에서 생기는 QP problem을 빠르게 풀기 위한 몇가지의 알고리즘들이 존재한다.
Vladimir Vapnik 이 1963 년에 발표한 원래의 optimal hyperplane 은 선형분류기 (linear classifier)였다. 그러나 1992 년에 Bernhard Boser, Isabelle Guyon and Vapnik 은 maximum-margin hyperplane 에 kernel trick (원래 Aizerman 이 발표한것)을 응용하였다. 결과적으로는 모든 dot product (inner product) 가 비선형 kernel function 으로 교체된 것을 제외하고는 유사한 알고리즘이다. 이것으로 인해 선형 알고리즘이 다른 공간에서 작동할 수 있게 되었다. kernel trick을 사용해서 maximum margin hyperplane 이 특징공간 (feature space) 에 적합하게 하였다. 특징공간은 보통 원래의 입력공간보다는 훨씬 더 큰 차원을 가지는 non-linear map 이다. 이러한 방법으로 비선형 분류기가 만들어질 수 있다. 사용된 kernel 이 radial basis function 이라면 그러한 특징공간은 무한 차원의 Hilbert space 이다.
Maximum margin classifiers 는 잘 조절될경우 무한차원이라고 해서 나쁜 결과를 낳지 않는다. 1995 년에 Corinna Cortes 와 Vapnik 은 잘못이름지워진 예 (mislabeled example) 의 경우에도 적용되는 변형된 maximum margin idea를 제안했다. 즉 example 들을 yes 와 no 로 구분할 수 있는 hyperplane 이 존재하지 않을 경우, Soft margin method 는 가장 가까이 있는 example 까지의 거리를 최대로 하면서, 가능한한 깨끗하게 example 들을 구분하여 주는 hyperplane을 선택한다. 이러한 작업을 보통 Support Vector Machine 또는 SVM 이라고 표현한다.
회귀 (regression)을 위한 SVM 은 1997 년에 Vapnik, Steven Golowich, Alex Smola 가 제안했으며 Support Vector Regression (SVR) 이라고 불린다. 위에서 언급한 Support Vector Classification 으로 만들어진 모델은 training data 의 부분집합에만 의존한다. 왜냐하면 그 모델을 만들기 위한 cost function 은 margin을 벗어난 training point 는 고려하지 않기 때문이다. 유사하게, Support Vector Regression 으로 만든 모델은 training data 의 부분집합에만 의존한다. 왜냐하면 그 모델을 만들기 위한 cost function 은 그 모델 예측에 가까이 있는 (threshold ε 범위에서) 어떠한 training data 도 무시하기 때문이다.............. (Wikipedia : SVM)
최근에 패턴분류에 있어서 각광을 받고 있는 SVM 모델은 1995 년 Vladimir Naumovich Vapnik 에 의해 개발된 통계적 학습이론으로서 학습데이터와 범주 정보의 학습진단을 대상으로 학습과정에서 얻어진 확률분포를 이용하여 의사결정함수를 추정한후 이 함수에 따라 새로운 데이터를 이원 분류하는 것으로 VC (Vapnik-Chervonenkis) 이론이라고도 한다. 특히 SVM 은 분류 문제에 있어서 일반화 기능이 높기 때문에 많은 분야에서 응용되고 있다.
기존의 학습 알고리즘은 학습집단을 이용하여 학습오류 (empirical error)를 최소화하는 경험적 위험 최소화 원칙 (Empirical Risk Minimization : EMR)을 구현하는 것인데 비해 구조적 위험 최소화 원칙 (Structural Risk Minimization : SRM) 은 전체집단을 하위 집단으로 세분화한 뒤 이 집단에 대한 경험적 위험도를 최소화하는 의사결정함수를 선택하는 것이다.
SVM 은 신경망처럼 패턴분류나 함수추정 등을 효과적으로 수행할 능력이 있지만 다음 같은 점에서 개선되는 것이 바람직하다. 어떤 학습데이터는 패턴분류 문제에 있어서 다른 데이터들보다 더 결정적인 영향력을 가질 수도 있으므로 우선적으로 올바르게 분류되어져야 하며 잡음 (noise) 또는 이상치 (outlier) 들은 기계학습 과정에서 영향력이 작아지길 원한다.
예를들어 순차 데이터들이 추세를 형성할 때 가장 최근 데이터들의 패턴에 영향을 많이 받는다면, 순차적 성질을 갖는 Fuzzy 소속함수를 정의하여 각 훈련 데이터에 적용하면 학습할 때 모든 훈련벡터들이 획일적으로 취급되지 않고 순차 데이터들의 패턴에 영향을 받도록 학습시킬 수 있다. 따라서 SVM 기법은 신경망, 퍼지이론, 유전알고리즘, 혼돈이론 등의 인공지능 기법과 통합한 패턴분류기의 설계가 바람직하다. (2002 이일병)
SVM 은 분류 문제를 해결하기 위해 최적의 분리 경계면 (hyperplane)을 제공한다. SVM 이 주목받는 이유는 첫째, 명백한 이론적 근거에 기반하므로 결과 해석이 용이하고, 둘째, 실제 응용에 있어서 인공신경망 수준의 높은 성과를 내고, 셋째, 적은 학습자료만으로 신속하게 분별학습을 수행할수 있기 때문이다.
SVM 은 MDA, Logit, CBR 과 비교해서 우수한 예측력을 보였으며 .... 인공신경망과 비슷한 수준의 높은 예측력을 나타낼 뿐만 아니라 인공신경망의 한계점으로 지적되었던 과대적한, 국소최적화와 같은 한계점들을 완화하는 장점을 가진다. (2003 한인구)
SVM 은 원래 이진분류 (binary classification)를 위하여 개발되었으며 현재에는 생물정보학 (bioinformatics), 문자인식, 필기인식, 얼굴 및 물체인식등 다양한 분야에서 성공적으로 적용되고 있다. (2003 차성덕)
term :
Support Vector Machine 패턴인식 (Pattern Recognition) 신경망 (Neural Network) 기계학습 (Machine Learning) 지도학습 (Supervised Learning) Vladimir Vapnik
paper :
Fuzzy 이론과 SVM을 이용한 KOSPI 200 지수 패턴분류기 (Pattern Classifier utilizing Fuzzy Theory and SVM) : 이일병, 이수용, 한국증권학회, 2002
The Efficiency of Boosting on SVM : 석경하, 류태욱, 한국데이터정보과학회, 2002
SVM 기반의 효율적인 신분 위장 기법 탐지 (Efficient Masquerade Detection Based on SVM) : 차성덕, 김한성, 권영희, 한국정보보호학회, 2003
SVM을 이용한 얼굴 검출 성능향상 방법 (Performance Improvement Method of Face Detection Using SVM) : 이경희, 정용화, 지형근, 한국정보처리학회, 2004
복합 알고리즘을 이용한 실시간 얼굴검출 및 SVM 인식기술 : 박정선, 이상웅, 유명현, 정여아, 양희덕, 한국정보보호학회, 2002
Support Vector Machine 을 이용한 기업부도 예측 : 김경재, 한인구, 박정민, 한국경영정보학회, 2003
한국어 정보처리 : 휴리스틱을 이용한 kNN 의 효율성 개선 (Korean Information Processing : An Improvement Of Efficiency For kNN By Using A Heuristic) : 이재문, 한국정보처리학회, 2003
행렬전치를 이용한 효율적인 NaiveBayes 알고리즘 (An Efficient Algorithm for NaiveBayes with Matrix Transposition) : 이재문, 한국정보처리학회, 2004
video :
인공지능을 위한 머신러닝 알고리즘 5강 - 서포트 벡터 머신 : SKtechx Tacademy : 2017/07/06 ... 동영상 15개