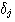 로 표현됨) 은 역전파 (Back-propagation) 알고리즘의
기초를 이룬다.
로 표현됨) 은 역전파 (Back-propagation) 알고리즘의
기초를 이룬다. Gradient Descent
(Gradient : 기울기, 경사도, 기울어진, 언덕, 비탈 descent : 강하, 하락, 하산 )
많은 최적화 (Optimization) 방법들 (예를들면
역전파 (Back-propagation), line search, quasi-Newton 같은 것)
이 기울기 (gradient) 의 계산에 기초한다. 피드포워드
(Feedforward) 신경망 (Neural
Network) 의 경우에는 이 기울기 방법이
신경망 출력 (thresholding 이전에) 에 관하여 에러함수를 부분적으로 유도하는 경우에
포함된다. 이러한 유도의 결과물 (보통 로 표현됨) 은 역전파 (Back-propagation) 알고리즘의
기초를 이룬다.

Wikipedia : Gradient descent : 기울기 하강 (Gradient descent) 는 현재의 위치에서 기울기 (또는 근사 기울기, approximate gradient) 에 비례해서 단계적으로 함수의 최소 또는 최대에 접근하는 점근적인 언덕오르기 (Hill Climbing) 알고리즘 이다. 즉 기울기가 음수값을 가진다면 local minimum 에 접근하여 갈것이다. 기계 학습 (Machine Learning) 에서 흔히 사용되는 gradient descent 는 크게 두가지 형태, 즉 batch 와 on-line 이 있다.
batch gradient descent 에서, true gradient 는 모델의 파라미터를 업데이트하기 위해 사용된다. true gradient 는 각각의 훈련예가 나타내는 기울기의 합이다. 그러므로 batch gradient descent 는 훈련 집합을 통해 한번에 (one sweep) 평가된 후에 파라미터들이 변화된다.
on-line gradient descent 에서, true gradient 는 단 하나의 훈련예에 대해서만 평가하는 비용함수의 기울기가 근사 기울기가 된다. 따라서 모델의 파라미터는 각 훈련예가 평가된 이후에 업데이트 된다. 데이터 집합이 큰 경우에 on-line gradient descent 는 batch gradient descent 보다 더 빠르게 될 수 있다.
두가지 형태 사이의 절충으로서 mini-batches 가 있다. 그 경우 true gradient 는 소수의 훈련예의 합으로써 근사 기울기가 구해진다.
on-line gradient descent 는 확률근사 (stochastic approximation) 의 한 형태이다. 확률근사 이론은 on-line gradient descent 가 수렴하는 조건을 제시한다.

(a) 1 차원 최적화. 이 그림은
f(x) 의 최소화가 -f(x) 의 최대화와 같음을 보여준다.
(b) 2 차원 최적화.
이 그림은 최대값 (함수의 등고선값이 산처럼 정상에서 최대값) 혹은 최소값
(함수의 등고선값이 계곡처럼 최소값) 을 나타낸다.
구배법 (Gradient Methods) : Steven C. Chapra, Raymond P. Canale : 최적화 문제를 분류하는 또 다른 방법은 차원에 따른 분류이다. 이 방법은 종종 1 차원 문제와 다차원 문제로 분류한다. 말 그대로 1 차원 문제는 함수가 한개의 종속변수에 의존하는 경우다. 그림 a 에서처럼 이 탐색은 1 차원의 정상들과 계곡들을 오르내리게 된다. 다차원 문제는 두 개, 혹은 그 이상의 종속변수들에 의존하는 함수들을 포함한다. 2 차원 최적화도 정상들과 계곡들을 탐색하는 것으로 표현되나, 실제 등산하는 것처럼 한 방향으로만 걸어가도록 구속되지 않고, 목적지에 효과적으로 도달하기 위해 지형을 탐사하게 된다 (그림 b) ..... 최소값을 찾는 과정은 최대값을 찾는 과정과 동일하다 왜냐하면, f(x) 를 최소화하는 x*값은 -f(x) 를 최대화하기 때문이다. 이러한 동등성은 그림 a 의 1 차원 함수에 그래프로 표현된다.