ГэИЎ ЧСЗЮБзЗЁЙж О№Ою
ЧСЗЮБзЗЁЙж О№ОюЗа : Robert W. Sebesta ПјРњ, РЏПјШё.ЧЯЛѓШЃ ПЊ, ШЋИЊАњЧаУтЦЧЛч, 1999 (ПјМ : Concepts of Programming Languages, 4th ed), Page 701~740
(1) АќАшЧќ ЕЅРЬХЭКЃРЬНК АќИЎ НУНКХл
РЬ РхРЧ ИёРћРК ГэИЎ ЧСЗЮБзЗЁЙжРЧ АГГфАњ Prolog КЮКа С§ЧеРЧ АЃАсЧб БтМњРЛ ЦїЧдЧЯПЉ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюИІ МвАГЧЯДТ АЭРЬДй. ГэИЎ ЧСЗЮБзЗЁЙж О№ОюРЧ БтУЪАЁ ЕЧДТ МњОю ЧиМЎЧа (Predicate calculus) РЧ МвАГЗЮ НУРлЧбДй. ЕкРЬОю МњОю ЧиМЎЧаРЬ РкЕП СЄИЎ СѕИэ НУНКХлПЁМ ЛчПыЕЩ Мі РжДТ ЙцЙ§РЛ ГэРЧЧбДй. Бз ШФПЁ, ГэИЎ ЧСЗЮБзЗЁЙжРЧ РќУМРћРЮ АГАќРЛ МвАГЧбДй. ДйРНРИЗЮ, Бф Р§РК ЛъМњ, ИЎНКЦЎ УГИЎИІ ЦїЧдЧб Prolog ЧСЗЮБзЗЁЙжРЧ БтУЪПЭ ЧСЗЮБзЗЅРЛ Е№ЙіБыЧЯДТ ЕЅ ЕЕПђРЛ СжАэ Prolog НУНКХлРЬ ЕПРлЧЯДТ ЙцЙ§РЛ МГИэЧЯДТ ЕЅ ЛчПыЕЧДТ УпРћ ЕЕБИРЧ ЛчПыРЛ МвАГЧбДй. ИЖСіИЗ ЕЮ Р§РК ГэИЎ О№ОюЗЮМ Prolog РЧ ЙЎСІСЁАњ Prolog АЁ ЛчПыЕЧАэ РжДТ РРПы КаОпИІ БтМњЧбДй.
14 РхРК ИэЗЩЧќ О№ОюПЁМ ЛчПыЕШ МвЧСЦЎПўОю АГЙп ЙцЙ§ЗаАњ ИХПь ДйИЅ ЧдМі ЧСЗЮБзЗЁЙж ЦаЗЏДйРгРЛ ГэРЧЧпДй. РЬ РхПЁМДТ ДйИЅ ЧСЗЮБзЗЁЙж ЙцЙ§ЗаРЛ БтМњЧбДй. РЬ АцПьПЁМ СЂБй ЙцЙ§РК ЧСЗЮБзЗЅРЛ БтШЃ ГэИЎРЧ ЧќНФРИЗЮ ЧЅЧіЧЯАэ АсАњИІ ЕЕУтЧЯДТ ГэИЎРћ УпЗа АњСЄРЛ ЛчПыЧЯДТ АЭРЬДй. ГэИЎ ЧСЗЮБзЗЅРК Р§ТїРћРЬЖѓБтКИДйДТ МБО№РћРЬДй. БзАЭРК АсАњИІ ЕЕУтЧЯБт РЇЧб ММКЮРћРЮ Р§ТїАЁ ОЦДЯЖѓ ПјЧЯДТ АсАњРЧ ИэММАЁ ММњЕШДйДТ АЭРЛ РЧЙЬЧбДй.
ЧСЗЮБзЗЁЙж О№ОюЗЮМ БтШЃ ГэИЎРЧ ЧќНФРЛ ЛчПыЧЯДТ ЧСЗЮБзЗЁЙжРК ГэИЎ ЧСЗЮБзЗЁЙж (logic Programming language) ЖЧДТ МБО№Рћ О№Ою (declarative language) Жѓ КвИАДй. ПьИЎДТ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюИІ БтМњЧЯБт РЇЧи Prolog ИІ МБХУЧпДй. ПжГФЧЯИщ Prolog ДТ БЄЙќРЇЧЯАд ЛчПыЕЧДТ РЏРЯЧб О№ОюРЬБт ЖЇЙЎРЬДй.
ГэИЎ ЧСЗЮБзЗЁЙж О№ОюРЧ БИЙЎРК ИэЗЩЧќ О№ОюГЊ ЧдМі О№ОюРЧ БИЙЎАњДТ ЧіРњЧЯАд ДйИЃДй. ГэИЎ ЧСЗЮБзЗЅРЧ РЧЙЬДТ ИэЗЩЧќ О№Ою ЧСЗЮБзЗЅРЧ РЧЙЬПЭ АХРЧ ДрСі ОЪОвДй. РЬЗБ АќТћРК ЕЖРкПЁАд ГэИЎ ЧСЗЮБзЗЁЙжАњ МБО№Чќ О№ОюРЧ КЛСњПЁ АќЧи ШЃБтНЩРЛ РЏЙпНУХВДй.
ГэИЎ ЧСЗЮБзЗЁЙжРЛ ГэРЧЧЯБт РќПЁ БтУЪРЮ ЧќНФ ГэИЎИІ АЃДмЧЯАд СЖЛчЧЯАэРк ЧбДй. РЬАЭРЬ РЬ УЅПЁМ ЧќНФГэИЎПЁ УГРН СЂЧЯДТ АЭРК ОЦДЯДй. ЧќНФ ГэИЎДТ 3 РхПЁМ ММњЧб АјИЎ РЧЙЬЗа (axiomatic semantics) ПЁМ БЄЙќРЇЧЯАд ЛчПыЕЧОњДй.
ИэСІ (proposition) ДТ ТќРЬАХГЊ АХСўРЮ ГэИЎРћ ЙЎРхРЬЖѓАэ Л§АЂЕЩ Мі РжДй. ИэСІДТ АДУМПЭ АДУМ ЛѓШЃАЃРЧ АќАшЗЮ БИМКЕШДй. ЧќНФРћРИЗЮ О№БоЕШ ИэСІРЧ РЏШПМКРЬ АЫЛчЕЧДТ АЭРЛ ЧуПыЧв ИёРћРИЗЮ, ЧќНФ ГэИЎДТ ИэСІИІ БтМњЧЯБт РЇЧб ЙцЙ§РЛ СІАјЧЯБт РЇЧи АГЙпЕЧОњДй.
БтШЃ ГэИЎ (Symbolic logic) ДТ ЧќНФ ГэИЎРЧ ММ АЁСі БтКЛ ПфБИ - ИэСІ ЧЅЧі, ИэСІ ЛчРЬРЧ АќАш ЧЅЧі, ТќРЬЖѓАэ УпСЄЕЧДТ ИэСІРЧ УЪБт С§Че (initial set) РЬДй. СЄИЎДТ УЪБт С§ЧеРИЗЮКЮХЭ УпЗаЕЩ Мі РжДТ КЮАЁРћРЮ ИэСІРЬДй.
ГэИЎ ЧСЗЮБзЗЁЙжРЛ РЇЧи ЛчПыЕШ БтШЃ ГэИЎРЧ ЦЏКАЧб ЧќНФРЛ МњОю ЧиМЎЧа (predicate calculus) РЬЖѓ КЮИЅДй. ДйРНКЮР§ПЁМ, ПьИЎДТ МњОю ЧиМЎЧаРЛ АЃДмШї МвАГЧбДй. ПьИЎРЧ ИёРћРК ГэИЎ ЧСЗЮБзЗЁЙжАњ ГэИЎ ЧСЗЮБзЗЁЙж О№Ою Prolog РЧ ГэРЧИІ РЇЧб БтУЪИІ СиКёЧЯДТ АЭРЬДй.
ГэИЎ ЧСЗЮБзЗЁЙж ИэСІПЁМ АДУМДТ ЛѓМіГЊ КЏМіРЮ ДмМјЧб ЧзПЁ РЧЧиМ ЧЅЧіЕШДй. ЛѓМіДТ АДУМИІ ЧЅЧіЧЯДТ БтШЃРЬИч, КЏМіДТ, КёЗЯ ОюДР РЧЙЬПЁМ ИэЗЩЧќ ЧСЗЮБзЗЁЙж О№ОюРЧ КЏМіКИДй МіЧаПЁ СЛДѕ АЁБюПяСіЖѓЕЕ, АЂБт ДйИЅ НУАЃПЁ ДйИЅ АДУМИІ ЧЅЧіЧЯДТ БтШЃРЬДй.
БтКЛ ИэСІ (atomic propositions) Жѓ КвИЎДТ АЁРх АЃДмЧб ИэСІДТ КЙЧе ЧзРИЗЮ БИМКЕШДй. КЙЧе Чз (Compound term) РК МіЧа АќАшРЧ ПјМвРЬИч, МіЧа ЧдМі БтШЃРЧ И№ОчРЛ АЎДТ ЧќНФРИЗЮ ОВПЉСјДй. МіЧа ЧдМіДТ ЧЅЧіНФ, ЦЉЧУРЧ ХзРЬКэ, ЖЧДТ ЦЉЧУ ИЎНКЦЎЗЮ ЧЅЧіЕШ ЛчЛѓРЬЖѓДТ АЭРЛ 14 РхРИЗЮКЮХЭ ЛѓБтЧЯРк. БзЗЏЙЧЗЮ КЙЧе ЧзРК ЧдМіРЧ ХзРЬКэ СЄРЧРЧ ПјМвРЬДй.
КЙЧе ЧзРК ЕЮ КЮКаРИЗЮ БИМКЕШДй. АќАшИІ ИэИэЧЯДТ ЧдМі БтШЃРЮ РлПыРк (functor) ПЭ ИХАГКЏМіРЧ МјМШ ИЎНКЦЎРЬДй. ДмРЯ ИХАГКЏМіИІ АЎДТ КЙЧе ЧзРК 1-ЦЉЧУРЬАэ, ЕЮ АГРЧ РЮРкИІ АЎДТ КЙЧе ЧзРК 2-ЦЉЧУРЬДй. ААРК ЙцЙ§РИЗЮ АшМгЕШДй. ПЙЗЮ ЕщИщ, ЕЮ АГРЧ ИэСІ
man
(jake)
like (bob, steak)
РЬ РжДйАэ ЧЯРк. ПЉБтМ {jake} ДТ man РЬЖѓАэ ИэИэЕШ АќАшРЧ 1-ЦЉЧУРЬАэ, {bob, steak} ДТ like ЖѓАэ ИэИэЕШ АќАшРЧ 2-ЦЉЧУРЬДй. ИИОр ПьИЎАЁ ИэСІ
man (fred)
ИІ РЇРЧ ЕЮ ИэСІПЁ УЗАЁЧЯИщ, АќАш man РК ЕЮ АГРЧ ДйИЅ ПјМвРЮ {jake} ПЭ {fred} ИІ АЎДТДй. РЬЗБ ИэСІПЁМ И№Еч АЃДмЧб Чз - man, jake, like, bob, БзИЎАэ steak - РК ЛѓМіРЬДй. РЬЗБ ИэСІДТ КЛСњРћРЮ РЧЙЬИІ АЎСі ОЪРНПЁ РЏРЧЧЯЖѓ. БзАЭЕщРК ПьИЎАЁ РЧЙЬЧЯАэРк ЧЯДТ АЭРЛ ГЊХИГНДй. ПЙЗЮ ЕщИщ, РЇПЁМ ЕЮЙјТА ПЙСІДТ bob РЬ steak ИІ ССОЦЧЯАХГЊ, ЖЧДТ steak АЁ bob РЛ ССОЦЧЯАХГЊ, bob РЬ ОюЖВ ИщПЁМ steak ПЭ КёНСЧЯДйДТ АЭРЛ РЧЙЬЧбДй.
ИэСІДТ ЕЮ АЁСі ОчНФ (mode) РИЗЮ ГЊХИГО Мі РжДй. ИэСІАЁ ТќРИЗЮ СЄРЧЕЧДТ ОчНФАњ, ИэСІРЧ СјИЎ АЊРЬ АсСЄЕЩ Мі РжДТ ОчНФРЬДй. ДйНУ ИЛЧЯИщ, ИэСІДТ ЛчНЧРЬГЊ СњРЧИІ ГЊХИГНДй. РЇРЧ ИэСІДТ ЛчНЧРЬГЊ СњРЧРЯ Мі РжДй.
КЙЧе ИэСІ (compound proposition) ДТ КЙЧе ГэИЎНФРЬ ИэЗЩЧќ О№ОюПЁМ БИМКЕШ АЭАњ ЕПРЯЧб ЙцЙ§РИЗЮ ГэИЎ ПЌАсРк Ся ПЌЛъРкПЁ РЧЧи ПЌАсЕШ ЕЮ АГ ЖЧДТ Бз РЬЛѓРЧ БтКЛ ИэСІ (atom proposition) ИІ АЁСіАэ РжДй. МњОю ЧиМЎЧаРЧ ГэИЎРћ ПЌАсРк (logical connector) РЧ РЬИЇ, БтШЃ, РЧЙЬДТ ДйРНАњ ААДй.
|
РЬИЇ |
БтШЃ |
ПЙСІ |
РЧЙЬ |
|
КЮСЄ ГэИЎАі ГэИЎЧе ЕПЕю ЧдУр
|
Ёў Ёћ Ёњ Ёе Ёљ Ёј |
Ёўa a Ёћ b a Ёњ b a Ёе b a Ёљ b a Ёј b |
a АЁ ОЦДЯДй. a БзИЎАэ b a ЖЧДТ b a ДТ b ПЭ ЕПФЁРЬДй. a ДТ b ИІ ЦїЧдЧбДй. b ДТ a ИІ ЦїЧдЧбДй. |
ДйРНРК КЙЧе ИэСІРЧ ПЙСІРЬДй.
a Ёћ b Ёљ c
a Ёћ Ёўb Ёљ d
ПЌЛъРк Ёў РК АЁРх ГєРК ПЌЛъРк ПьМБ МјРЇИІ АЎДТДй. ПЌЛъ Ёћ, Ёњ Ањ Ёе РК И№ЕЮ Ёљ Ањ Ёј КИДй ГєРК ПЌЛъРк ПьМБ МјРЇИІ АЎДТДй. БзЗЁМ РЇРЧ ЕЮЙјТА ПЙСІДТ
(a Ёћ (Ёўb)) Ёљ d
Ањ ЕПФЁИІ РЬЗщДй.
КЏМіДТ ЧбСЄЛч (quantifier) Жѓ КвИЎДТ ЦЏКАЧб БтШЃПЁ РЧЧи БтМњЕЩ ЖЇИИ ИэСІПЁ ГЊХИГДй. МњОю ЧиМЎЧаРК ДйРНПЁМ БтМњЕЧДТ ЕЮ АГРЧ ЧбСЄЛчИІ ЦїЧдЧЯАэ РжДй. ПЉБтМ X ДТ КЏМіРЬАэ, P ДТ ИэСІРЬДй.
|
РЬИЇ |
ПЙСІ |
РЧЙЬ |
|
РќФЊ ЧбСЄЛч СИРч ЧбСЄЛч |
ЂЃX.P ЂЄX.P |
И№Еч X ПЁ ДыЧЯПЉ P ДТ ТќРЬДй. P АЁ ТќРЮ X АЁ СИРчЧбДй. |
X ПЭ P ЛчРЬРЧ ИЖФЇЧЅ ( .) ДТ ИэСІПЁМ КЏМіИІ АЃДмЧЯАд КаИЎЧбДй. ПЙЗЮ, ДйРНРЛ Л§АЂЧиКИРк.
ЂЃX.
(woman (X) Ёљ human (X))
ЂЄX. mother (mary, X) Ёћ
male (X))
УЙЙјТА ИэСІДТ X РЧ И№Еч АЊПЁ ДыЧи, ИИОр X АЁ ПЉРкИщ, X ДТ ЛчЖїРЬЖѓДТ АЭРЛ РЧЙЬЧбДй. ЕЮЙјТА ИэСІДТ mary ДТ X РЧ ОюИгДЯРЬАэ, X ДТ ГВРкРЮ X РЧ АЊРЬ СИРчЧбДйДТ АЭРЛ РЧЙЬЧбДй. ДйНУ ИЛЧЯИщ, mary ПЁАдДТ ОЦЕщРЬ РжДТ АЭРЬДй. РќФЊ (universal) Ањ СИРч (existential) ЧбСЄЛчРЧ ПЕПЊРК ЧбСЄЛчАЁ УЗКЮЕШ БтКЛ ИэСІРЬДй. БзЗБ ПЕПЊРК ЙцБн ММњЧб ЕЮ АГРЧ ИэСІУГЗГ А§ШЃИІ ЛчПыЧиМ ШЎРхЕШДй. БзЗЁМ РќФЊ ЧбСЄЛчРЧ СИРч ЧбСЄЛчДТ ДйИЅ ПЌЛъРкЕщКИДй ГєРК ПЌЛъРк ПьМБ МјРЇИІ АЎДТДй.
ПьИЎДТ МњОю ЧиМЎЧаРЬ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюРЧ БтУЪРЬБт ЖЇЙЎПЁ МњОю ЧиМЎЧаРЛ ГэРЧЧЯАэ РжДй. ДйИЅ О№ОюПЭ ИЖТљАЁСіЗЮ, ГэИЎ О№ОюДТ СпКЙ (redundancy) РЬ БтУЪШЕШ АЭРЛ РЧЙЬЧЯДТ СІРЯ ДмМјЧб ЧќНФРЬ АЁРх ССДй.
СіБнБюСі ММњЧб МњОю ЧиМЎЧаРЧ ЙЎСІДТ ЕПРЯЧб РЧЙЬИІ АЎДТ ИэСІИІ ЧЅЧіЧЯДТ ДйИЅ ЙцЙ§РЬ ГЪЙЋ ИЙДйДТ АЭРЬДй. Ся СпКЙРЬ ГЪЙЋ ИЙРЬ СИРчЧбДй. РЬАЭРК ГэИЎЧаРкПЁАдДТ ЙЎСІАЁ ЕЧСі ОЪСіИИ, ИИОр МњОю ЧиМЎЧаРЬ РкЕПШЕШ НУНКХлПЁМ ЛчПыЕШДйИщ, БзАЭРК НЩАЂЧб ЙЎСІРЬДй. ЙЎСІИІ ДмМјШЧЯБт РЇЧи ИэСІРЧ ЧЅСи ЧќНФРЬ ЙйЖїСїЧЯДй. ЛѓДыРћРИЗЮ ИэСІРЧ АЃДмЧб ЧќНФРЮ ХЌЗЮСю ЧќНФ (clausal form) РК ЧЅСи ЧќНФСпРЧ ЧЯГЊРЬДй. РЯЙнМКРЛ РвСі ОЪАэ, И№Еч ИэСІДТ ХЌЗЮСю ЧќНФРИЗЮ ЧЅЧіЕЩ Мі РжДй. ХЌЗЮСю ЧќНФПЁМ ИэСІДТ ОЦЗЁПЭ ААРК РЯЙнРћРЮ БИЙЎРЛ АЎДТДй.
ПЉБтМ A ПЭ B ДТ ЧзРЬДй. РЬЗБ ХЌЗЮСю ЧќНФ ИэСІРЧ РЧЙЬДТ ДйРНАњ ААДй. ИИОр И№Еч A АЁ ТќРЬИщ, РћОюЕЕ ЧЯГЊРЧ B ДТ ТќРЬДй. ХЌЗЮСю ЧќНФ ИэСІРЧ БтКЛРћРЮ ЦЏМКРК ДйРНАњ ААДй. СИРч ЧбСЄЛчДТ ПфБИЕЧСі ОЪАэ, РќФЊ ЧбСЄЛчДТ БтКЛ ИэСІРЧ КЏМі ЛчПыПЁМ ЙЌНУРћРЬАэ, ГэИЎАі (conjunction) Ањ ГэИЎЧе (disjunction) РЬПмРЧ ДйИЅ ПЌЛъРкДТ ПфБИЕЧСі ОЪДТДй. ЙАЗа, ГэИЎАіАњ ГэИЎЧеРК РЯЙнРћРЮ ХЌЗЮСю ЧќНФПЁМ КИПЉСј МјМЗЮ ГЊХИГЊДТ АЭРЬ ЧЪПфЧЯДй. ГэИЎЧеРК ПоТЪПЁ ГэИЎАіРК ПРИЅТЪПЁ РЇФЁЧбДй. И№Еч МњОю ЧиМЎЧа ИэСІДТ ОЫАэИЎСђПЁ РЧЧи ХЌЗЮСю ЧќНФРИЗЮ КЏШЏЕШДй. Nilsson (1971) РК КЏШЏРЛ МіЧрЧЯБт РЇЧб АЃДмЧб КЏШЏ ОЫАэИЎСђАњ ОЫАэИЎСђРЬ СІДыЗЮ МіЧрЕШДйДТ АЭРЛ СѕИэЧЯПДДй.
ХЌЗЮСю ЧќНФ ИэСІРЧ ПьКЏРЛ РќСІ (antecedent) Жѓ КЮИЃИч, СТКЏРК РќСІ СјИЎ АЊРЧ АсАњРЬБт ЖЇЙЎПЁ АсЗа (consequent) РЬЖѓ КвИАДй. ХЌЗЮСю ЧќНФ ИэСІРЧ ПЙСІЗЮМ ДйРНРЛ Л§АЂЧи КИРк.
likes (bob, trout) Ёј likes (bob, fish) Ёћ fish (trout)
father (louis, al) Ёњ father (louis, violet) Ёј father (al, bob) Ёћ mother (violet, bob) Ёћ grandfather (louis, bob)
УЙЙјТА ПЙСІПЁДТ ИИОр bob РЬ fish ИІ ССОЦЧЯАэ, trout АЁ fish РЬИщ, bob РК trout РЛ ССОЦЧбДйДТ АЭРЛ ГЊХИГНДй. ЕЮЙјТА ПЙСІДТ ИИОр al РЬ bob РЧ ОЦЙіСіРЬАэ violet РЬ bob РЧ ОюИгДЯРЬАэ louis АЁ bob РЧ ЧвОЦЙіСіЖѓИщ, louis ДТ al РЧ ОЦЙіСіРЬАХГЊ violet РЧ ОЦЙіСіРЬДйИІ ГЊХИГНДй.
МњОю ЧиМЎЧаРК ИэСІРЧ С§ЧеРЛ ЧЅЧіЧЯДТ ЙцЙ§РЛ СІАјЧбДй. ИэСІ С§ЧеРЧ ЛчПыРК ОюЖВ ШяЙЬЗгАХГЊ РЏПыЧб ЛчНЧРЬ ИэСІ С§ЧеРИЗЮКЮХЭ УпЗаЕЩ Мі РжДТСіИІ АсСЄЧЯДТ АЭРЬДй. РЬАЭРК РЬЙЬ ОЫЗССј СЄИЎГЊ АјИЎЗЮКЮХЭ УпЗаЕЩ Мі РжДТ ЛѕЗЮПю СЄИЎИІ ЙпАпЧвЗСАэ ГыЗТЧЯДТ МіЧаРкРЧ ПЌБИПЭ ОЦСж РЏЛчЧЯДй.
ФФЧЛХЭ АњЧаРЧ УЪБтНУДы (1950 ГтДы ~ 1960 ГтДы УЪ) ПЁДТ СЄИЎ СѕИэ АњСЄРЛ РкЕПШЧЯДТ ЕЅ ИЙРК ШяЙЬИІ КИПДДй. РкЕП СЄИЎ СѕИэПЁМ АЁРх СпПфЧб ЕЙЦФБИДТ Syracuse ДыЧаРЧ Alan Robinson ПЁ РЧЧи Чи ЕЕУт ПјИЎ (resolution principle) РЧ ЙпАпРЬДй (Robinson, 1965).
Чи ЕЕУт (resolution) РК УпЗаЕШ ИэСІАЁ СжОюСј ИэСІЗЮКЮХЭ АшЛъЕЧДТ АЭРЛ ЧуПыЧЯДТ УпЗа БдФЂРЬДй. ЕћЖѓМ ЧиЕЕУтРК РкЕП СЄИЎ СѕИэПЁ РћПы АЁДЩЧб ЙцЙ§РЛ СІАјЧбДй. Чи ЕЕУтРК ХЌЗЮСю ЧќНФРЧ ИэСІПЁ РћПыЧЯБт РЇЧи АэОШЕЧОњДй. ЧиЕЕУтРЧ АГГфРК ДйРНАњ ААДй. ДйРНАњ ААРК ЧќНФРЛ ЕЮ АГРЧ ИэСІАЁ РжДйАэ АЁСЄЧЯРк.
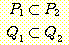
РЬАЭРК 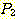 АЁ
АЁ 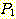 РЛ ЦїЧдЧЯАэ,
РЛ ЦїЧдЧЯАэ, 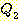 АЁ
АЁ 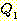 РЛ ЦїЧдЧЯДТ АЭРЛ РЧЙЬЧбДй. ДѕПэРЬ
РЛ ЦїЧдЧЯДТ АЭРЛ РЧЙЬЧбДй. ДѕПэРЬ 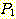 РЬ
РЬ 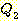 ПЭ ЕПРЯЧЯДйАэ ЧЯИщ, ПьИЎДТ
ПЭ ЕПРЯЧЯДйАэ ЧЯИщ, ПьИЎДТ 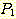 Ањ
Ањ 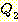 ИІ T ЗЮ ДйНУ ОЕ Мі РжДйАэ АЁСЄЧЯРк. БзЗЏИщ, ПьИЎДТ ДйРНАњ ААРЬ ЕЮ АГРЧ ИэСІИІ
ДйНУ ОЕ Мі РжДй.
ИІ T ЗЮ ДйНУ ОЕ Мі РжДйАэ АЁСЄЧЯРк. БзЗЏИщ, ПьИЎДТ ДйРНАњ ААРЬ ЕЮ АГРЧ ИэСІИІ
ДйНУ ОЕ Мі РжДй.
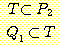
РЬСІ, 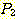 АЁ T ИІ ЦїЧдЧЯАэ, T АЁ
АЁ T ИІ ЦїЧдЧЯАэ, T АЁ 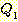 РЛ ЦїЧдЧЯБт ЖЇЙЎПЁ, ОЦЗЁПЁ ОД АЭУГЗГ, ГэИЎРћРИЗЮ ИэЙщШї
РЛ ЦїЧдЧЯБт ЖЇЙЎПЁ, ОЦЗЁПЁ ОД АЭУГЗГ, ГэИЎРћРИЗЮ ИэЙщШї 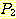 АЁ
АЁ 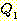 РЛ ЦїЧдЧбДй.
РЛ ЦїЧдЧбДй.

ПјЗЁРЧ ЕЮ ИэСІЗЮКЮХЭ РЬ ИэСІИІ УпЗаЧЯДТ ЙцЙ§РЬ Чи ЕЕУтРЬДй.
ДйИЅ ПЙЗЮМ, ДйРН ЕЮ АГРЧ ИэСІИІ Л§АЂЧи КИРк.
older (joanne, jake) Ёј mother (joanne, jake)
РЬ ИэСІЗЮКЮХЭ, ДйРНРЧ ИэСІАЁ Чи ЕЕУтРЛ ЛчПыЧиМ ИИЕщОюСњ Мі РжДй.
wiser (joanne, jake) Ёј mother (joanne, jake)
РЬЗБ Чи ЕЕУтРЧ БИМК ИоФЋДЯСђРК АЃДмЧЯДй. ЕЮ ИэСІРЧ СТКЏРЧ ЧзРК ЛѕЗЮПю ИэСІРЧ СТКЏРЛ ИИЕщБт РЇЧи ЧдВВ AND ПЌЛъРЛ ЧбДй. БзЗБШФ, ЕПРЯЧб ЙцЙ§РИЗЮ ЛѕЗЮПю ИэСІРЧ ПьКЏРЛ ИИЕчДй. ДйРНРИЗЮ, ЛѕЗЮПю ИэСІРЧ ОчКЏПЁ ГЊХИГЊДТ ЧзРК ОчКЏПЁМ СІАХЕШДй. ИэСІАЁ ДйСп ЧзРЛ Чб КЏРЬГЊ ОчКЏПЁ АЎДѕЖѓЕЕ Бз АњСЄРК ЕПРЯЧЯДй. ЛѕЗгАд УпЗаЕШ ИэСІРЧ СТКЏРК УГРНПЁ СжОюСј ЕЮ ИэСІРЧ СТКЏРЧ И№Еч ЧзРЛ АЁСіАэ РжДй. ЛѕЗЮПю ПьКЏЕЕ КёНСЧб ЙцЙ§РИЗЮ ИИЕщОюСјДй. БзЗБШФ, ЛѕЗЮПю ИэСІРЧ ОчКЏПЁ ГЊХИГЊДТ ЧзРЛ СІАХЧбДй. ПЙИІ ЕщОю, ДйРНАњ ААРК ИэСІИІ АЁСіАэ РжДйАэ АЁСЄЧЯРк.
father (bob, jake) Ёњ mother (bob, jake) Ёј parent (bob, jake)
grandfather (bob, fred) Ёј father (bob, jake) Ёћ father (jake, fred)
Чи ЕЕУтРК ДйРНАњ ААДй.
mother (bob, jake) Ёњ grandfather (bob, fred) Ёј parent (bob, jake) Ёћ father (jake, fred)
РЬ ИэСІДТ ПјЗЁ ИэСІРЧ БтКЛ ИэСІ Сп ЧЯГЊИИРЛ СІПмЧЯАэ И№Еч ИэСІИІ АЁСіАэ РжДй. УЙЙјТА ИэСІРЧ СТКЏАњ ЕЮЙјТА ИэСІРЧ ПьКЏПЁ РжДТ ПЌЛъ father (bob, jake) ИІ ЧуПыЧб БтКЛ ИэСІАЁ Л§ЗЋЕЧОњДй. ЙЎРхРИЗЮ ДйРНАњ ААРЬ ИЛЧв АЭРЬДй.
if : bob РЬ jake РЧ КЮИ№РЬДйДТ bob РЬ jake РЧ ОЦЙіСіРЬАХГЊ ОюИгДЯРЬДйИІ ЦїЧдЧбДй.
and : bob РЬ jake РЧ ОЦЙіСіРЬАэ jake АЁ fred РЧ ОЦЙіСіРЬДйДТ bob РЬ fred РЧ ЧвОЦЙіСіРЬДйИІ ЦїЧдЧбДй.
then : if bob РЬ jake РЬ КЮИ№РЬАэ jake АЁ fred РЧ ОЦЙіСіРЬДй, then : bob РЬ jake РЧ ОюИгДЯРЬАХГЊ bob РЬ fred РЧ ЧвОЦЙіСіРЬДй.
Чи ЕЕУтРК НЧСІЗЮ РЬЗБ АЃДмЧб ПЙСІАЁ МГИэЧЯДТ АЭКИДй ДѕПэ КЙРтЧЯДй. ЦЏШї, ИэСІПЁМ КЏМіРЧ СИРчДТ Чи ЕЕУт АњСЄПЁМ КЮЧе АњСЄ (matching process) РЬ МКАјЧЯДТ АЭРЛ ЧуПыЧЯДТ КЏМіРЧ АЊРЛ УЃРИЖѓАэ ПфБИЕШДй. КЏМіРЧ РЏПыЧб АЊРЛ АсСЄЧЯДТ РЬЗБ АњСЄРЛ ДмРЯШ (unification) ЖѓАэ КЮИЅДй. ДмРЯШИІ ЧуПыЧЯБт РЇЧи КЏМіПЁ АЊРЛ РЯНУРћРИЗЮ ДыРдНУХАДТ АЭРЛ ЛчЗЪШ (instantiation) Жѓ КЮИЅДй.
Чи ЕЕУт ДмАшПЁМ КЏМіПЁ АЊРЛ ЛчЗЪШЧЯАэ ПфБИЕШ ИХФЊРЛ ПЯМКЧЯДТ АЭРЬ НЧЦаЕШ ШФПЁ ПЊЧрЧиМ КЏМіПЁ ДйИЅ АЊРЛ ЛчЗЪШЧЯДТ АЭРК РЯЙнРћРЬДй. Prolog РЧ ЙЎИЦПЁМ ДмРЯШПЭ ПЊЧр (backtracking) РЛ СЛДѕ БЄЙќРЇЧЯАд ГэРЧЧв АЭРЬДй.
Чи ЕЕУтРЧ ОЦСж СпПфЧб МКСњРЛ СжОюСј ИэСІ С§ЧеПЁМ ОюЖВ КвРЯФЁ (inconsistency) ИІ ХНСіЧЯДТ ДЩЗТРЬДй. РЬЗБ МКСњРК ДйРНАњ ААРЬ, Чи ЕЕУтРЛ СЄИЎИІ СѕИэЧЯДТ ЕЅ ЛчПыЧЯДТ АЭРЛ ЧуПыЧбДй. МњОю ЧиМЎЧа АќСЁПЁМ СЄИЎ СѕИэРЛ РћДчЧб ИэСІРЧ СжОюСј С§Че (СЄИЎРЧ КЮСЄРЛ Лѕ ИэСІЗЮ ММњЕЪ) РИЗЮ КМ Мі РжДй. Чи ЕЕУтРЬ КвРЯФЁИІ ЙпАпЧдРИЗЮНс СЄИЎИІ СѕИэЧЯДТ ЕЅ ЛчПыЕЩ Мі РжЕЕЗЯ СЄИЎДТ КЮСЄЕШДй. РЬАЭРЬ И№МјПЁ РЧЧб СѕИэ (proof by contradiction) РЬДй. РќЧќРћРИЗЮ ПјЗЁРЧ ИэСІДТ АЁМГ (hypotheses) РЬЖѓАэ КвИЎАэ, СЄИЎРЧ КЮСЄРК ИёРћ (goal) РЬЖѓАэ КвИАДй.
РЬЗаЛѓРИЗЮ, РЬАЭРК РЏШПЧЯАэ РЏПыЧб АњСЄРЬДй. БзЗЏГЊ Чи ЕЕУтПЁ ПфБИЕЧДТ НУАЃРЬ ЙЎСІАЁ ЕЩ Мі РжДй. ИэСІРЧ С§ЧеРЬ РЏЧбРЯ ЖЇ Чи ЕЕУтЕЕ РЏЧб АњСЄРЯСіЖѓЕЕ, АХДыЧб ИэСІ ЕЅРЬХЭ КЃРЬНКПЁМ КвРЯФЁИІ УЃДТ ЕЅ ПфБИЕЧДТ НУАЃРК АХДыЧв Мі РжДй.
СЄИЎ СѕИэРК ГэИЎ ЧСЗЮБзЗЁЙжРЧ БтУЪРЬДй. АшЛъЕЧДТ ИЙРК КЮКаРЬ АЁМГЗЮМ СжОюСј ЛчНЧАњ АќАшРЧ ИЎНКЦЎПЭ, Чи ЕЕУтРЛ ЛчПыЧЯПЉ АЁМГЗЮКЮХЭ УпЗаЕШ ИёРћРЧ ЧќНФРИЗЮ ЧЅЧіЕШДй.
ИэСІАЁ Чи ЕЕУтРЛ РЇЧи ЛчПыЕЩ ЖЇ, Чи ЕЕУт АњСЄРЛ ДѕПэ ДмМјШНУХАДТ СІЧбЕШ СОЗљРЧ ХЌЗЮСю ЧќНФРЬ ЛчПыЕЩ Мі РжДй. РЬ ЦЏМіЧб ИэСІИІ ШЅ ХЌЗЮСю (Horn clauses) Жѓ КвИЎИч, ДмСі 2 АЁСі ЧќНФРИЗЮ СИРчЧбДй. Ся СТКЏРЬ ДмРЯ БтКЛ ИэСІРЬАХГЊ Л§ЗЋЕШДй. [ШЅ ХЌЗЮСюДТ РЬЗБ ЧќНФРИЗЮ ХЌЗЮСюИІ ПЌБИЧб Alfred Horn РЧ РЬИЇРЛ ЕћМ КйПЉСГДй (horn, 1951).] ХЌЗЮСю ЧќНФ ИэСІРЧ СТКЏРК ЖЇЖЇЗЮ ЧьЕх (head) Жѓ КвИЎАэ, СТКЏРЛ АЎДТ ШЅ ХЌЗЮСюДТ РЏЕЮ ШЅ ХЌЗЮСю (headed Horn clause) ЖѓАэ КвИАДй. ДйРНАњ ААРЬ РЏЕЮ ШЅ ХЌЗЮСюДТ АќАшИІ ГЊХИГЛДТ ЕЅ ЛчПыЕШДй.
likes (bob, trout) Ёј likes (bob, fish) Ёћ fish (trout)
ЛчНЧРЛ ГЊХИГЛДТ ЕЅ РкСж ЛчПыЕЧДТ СТКЏРЬ ОјДТ ШЅ ХЌЗЮСюДТ И№ЕЮ ШЅ ХЌЗЮСю (headless Horn clause) Жѓ КвИАДй. ПЙИІ ЕщИщ, ОЦЗЁПЭ ААДй.
father (bob, jake)
И№ЕЮДТ ОЦДЯСіИИ, ДыКЮКаРЧ ИэСІДТ ШЅ ХЌЗЮСюЗЮ ГЊХИГО Мі РжДй.
ГэИЎ ЧСЗЮБзЗЁЙжРЛ РЇЧи ЛчПыЕШ О№ОюИІ МБО№Рћ О№Ою (declarative language) ЖѓАэ КЮИЅДй. ПжГФЧЯИщ Бз О№ОюЗЮ РлМКЕШ ЧСЗЮБзЗЅРЬ ЙшСЄЙЎРЬГЊ СІОю ШхИЇЙЎРЬ ОЦДб МБО№РИЗЮ БИМКЕЧБт ЖЇЙЎРЬДй. РЬЗБ МБО№РК БтШЃ ГэИЎПЁМ НЧСІРћРИЗЮ ЙЎРх, Ся ИэСІРЬДй.
ГэИЎ ЧСЗЮБзЗЁЙж О№ОюРЧ ЧЪМіРћРЮ ЦЏМКРК МБО№Рћ РЧЙЬЗа (declarative semantics) РЬЖѓ КвИЎДТ РЧЙЬЗаРЬДй. РЬ РЧЙЬЗаРЧ БтКЛ АГГфРК АЂ ЙЎРхРЧ РЧЙЬИІ АсСЄЧЯДТ АЃДмЧб ЙцЙ§РЬ РжАэ, РЧЙЬДТ ЙЎСІИІ ЧЎБт РЇЧи ЙЎРхРЬ ЛчПыЕЧДТ ЙцЙ§ПЁ СОМгЕЧСі ОЪДТДйДТ АЭРЬДй. МБО№Рћ РЧЙЬЗаРК ИэЗЩЧќ О№Ою (imperative language) РЧ РЧЙЬЗаКИДй АЃДмЧЯДй. ПЙИІ ЕщИщ, ГэИЎ ЧСЗЮБзЗЁЙж О№ОюПЁМ СжОюСј ИэСІРЧ РЧЙЬДТ ЙЎРх Бз РкУМЗЮКЮХЭ АЃАсЧЯАд АсСЄЕЩ Мі РжДй. ИэЗЩЧќ О№ОюПЁМ АЃДмЧб ЙшСЄЙЎРЧ РЧЙЬДТ СіПЊ МБО№РЧ СЖЛч, О№ОюРЧ ПЉПЊ БдФЂРЧ СіНФ, БзИЎАэ НЩСіОю ЙшСЄЙЎ КЏМіРЧ ХИРдРЛ АсСЄЧЯБт РЇЧи ДйИЅ ЦФРЯРЧ ЧСЗЮБзЗЅ СЖЛчИІ ПфБИЧбДй. БзЗБ ШФ, ЙшСЄЙЎ ЧЅЧіНФРЬ КЏМіИІ АЁСіАэ РжДйИщ, ЙшСЄЙЎ РЬРќРЧ ЧСЗЮБзЗЅРЧ НЧЧрРК ЙнЕхНУ РЬЗБ КЏМіРЧ АЊРЛ АсСЄЧЯБт РЇЧи УпРћЕЧОюОп ЧбДй. Бз ДйРНПЁ ЙшСЄЙЎРЧ АсАњДТ НЧЧр НУАЃ ЙЎИЦПЁ ДоЗС РжДй. РЬАЭРЛ ДмРЯ ЙЎРхРЧ АЃДмЧб АЫЛч, ХиНКЦЎРЧ ЙЎИЦРЬГЊ НЧЧрМјМИІ АэЗСЧв ЧЪПфАЁ ОјДТ АЭАњ КёБГЧЯИщ, МБО№Рћ РЧЙЬЗаРЬ ИэЗЩЧќ О№ОюРЧ РЧЙЬЗаКИДй ДѕПэ АЃДмЧЯДйДТ АЭРК ИэЙщЧЯДй. БзЗЏЙЧЗЮ, МБО№Рћ РЧЙЬЗаРК МБО№Рћ О№ОюАЁ ИэЗЩЧќ О№ОюПЁ ДыЧиМ АЁСіДТ РхСЁ СпПЁ ЧЯГЊРЬДй (Hogger, 1984, pp. 240 - 241).
ИэЗЩЧќ О№ОюПЭ ЧдМі О№ОюПЁМРЧ ЧСЗЮБзЗЁЙжРК БтКЛРћРИЗЮ Р§ТїРћ (procedural) РЬДй. БзАЭРК ЧСЗЮБзЗЁИгАЁ ЧСЗЮБзЗЅПЁ РЧЧи ЙЋОљРЬ МКУыЕЧДТСіИІ ОЫАэ АшЛъРЬ СЄШЎЧЯАд ОюЖЛАд МіЧрЕЧДТСіИІ ФФЧЛХЭПЁАд СіНУЧЯДТ АЭРЛ РЧЙЬЧбДй. ДйНУ ИЛЧЯИщ, ФФЧЛХЭДТ ИэЗЩРЛ ЕћИЃДТ АЃДмЧб РхФЁЗЮМ УыБоЕШДй. АшЛъЕЧДТ И№Еч АЭРК АшЛъРЧ И№Еч ММКЮ ЛчЧзРЬ ЛѓММШї МГИэЕЧОюОп ЧбДй. ОюЖВ ЛчЖїРК РЬЗБ АЭРЬ ФФЧЛХЭ ЧСЗЮБзЗЁЙжРЛ ОюЗЦАд ЧЯДТ ЧйНЩРЬЖѓАэ ЙЯДТДй.
ОюЖВ КёИэЗЩЧќ О№ОюПЁМРЧ ЧСЗЮБзЗЁЙж, ЦЏШї ГэИЎ ЧСЗЮБзЗЁЙж О№ОюПЁМРЧ ЧСЗЮБзЗЁЙжРК КёР§ТїРћРЬДй. РЬЗЏЧб О№ОюПЁМРЧ ЧСЗЮБзЗЅРК АсАњАЁ АшЛъЕЧДТ ЙцЙ§РЛ СЄШЎЧЯАд ММњЧЯСі ОЪАэ АсАњРЧ ЧќНФРЛ ММњЧбДй. ТїРЬСЁРК ПьИЎАЁ ФФЧЛХЭ НУНКХлРЬ ОюТЗЕч АсАњАЁ ОђОюСіДТ ЙцНФРЛ АсСЄЧбДйАэ АЁСЄЧЯДТ АЭРЬДй. ГэИЎ ЧСЗЮБзЗЁЙж О№ОюПЁ РЬ ДЩЗТРЛ СІАјЧЯБт РЇЧи ЧЪПфЧб АЭРК РћДчЧб СЄКИПЭ ПјЧЯДТ АшЛъ АсАњИІ УпЗаЧЯДТ ЙцЙ§РЛ ФФЧЛХЭПЁАд СІАјЧЯДТ АЃАсЧб МіДмРЬДй. МіЗЗ ЧиМЎЧаРК ФФЧЛХЭПЁ ДыЧб БтКЛ ХыНХ ЧќНФРЛ СІАјЧЯАэ, Robinson ПЁ РЧЧи УЙЙјТАЗЮ АГЙпЕШ СѕИэ ЙцЙ§РК УпЗа БтЙ§РЛ СІАјЧбДй.
Р§ТїРћ НУНКХлАњ КёР§ТїРћ НУНКХлРЧ ТїРЬИІ МГИэЧЯДТ ЕЅ ЛчПыЕЧДТ РЯЙнРћРЮ ПЙСІДТ ЕЅРЬХЭИІ ОюЖВ ЦЏСЄЧб МјМЗЮ ЙшПЧЯДТ АњСЄ Ся СЄЗФ (sorting) РЬДй. C++ ПЭ ААРК О№ОюПЁМ СЄЗФРК C++ ФФЦФРЯЗЏИІ АЁСј ФФЧЛХЭПЁАд СЄЗФ ОЫАэИЎСђРЧ И№Еч ММКЮЛчЧзРЛ C++ ЧСЗЮБзЗЅРИЗЮ БтМњЧдРИЗЮНс НЧЧрЕШДй. C++ ЧСЗЮБзЗЅРЛ БтАш ФкЕхГЊ РЮХЭЧСИЎХЭ СпАЃФкЕхЗЮ КЏШЏЧб ШФПЁ ФФЧЛХЭДТ ИэЗЩОюИІ ЕћИЃИч СЄЗФЕШ ИЎНКЦЎИІ Л§МКЧбДй.
КёР§ТїРћ О№ОюПЁМДТ СЄЗФЕШ ИЎНКЦЎРЧ ЦЏМКРЛ БтМњЧЯБтИИ ЧЯИщ ЕШДй. БзАЭРК РЮСЂ 2 ПјМвРЧ АЂ НжПЁ ДыЧиМ, СжОюСј АќАшНФРЬ МКИГЧЯДТ ИЎНКЦЎРЧ ФЁШЏРЬДй. РЬАЭРЛ ЧќНФРћРИЗЮ МГИэЧЯРк. СЄЗФЕЧДТ ИЎНКЦЎАЁ УЗРкЙќРЇ 1..n РЛ АЎДТ list ЖѓДТ РЬИЇРЧ ЙшПРЬЖѓАэ АЁСЄЧЯРк. old_list ЖѓДТ СжОюСј ИЎНКЦЎРЧ ПјМвИІ СЄЗФЧЯАэ Бз АсАњИІ ДйИЅ ЙшППЁ ГѕДТДйДТ АГГфРЛ ДйРНАњ ААРЬ ЧЅЧіЧв Мі РжДй.
sort (old_list,
new_list) Ёј permute (old_list, new_list) Ёћ sorted (new_list)
sorted
(list) Ёј ЂЃj such that 1 ЁТ j < n, list (j) ЁТ list (j + 1)
ПЉБтМ permute ДТ ЕЮЙјТА ИХАГКЏМі ЙшПРЬ УЙЙјТА ИХАГКЏМі ЙшПРЧ ФЁШЏРЬИщ, ТќРЛ ЕЧЕЙЗССжДТ МњОю (predicate) РЬДй.
РЬЗБ ММњЗЮКЮХЭ, КёР§ТїРћ О№Ою НУНКХлРК СЄЗФЕШ ИЎНКЦЎИІ Л§МКЧв Мі РжДй. БзАЭРК КёР§ТїРћ ЧСЗЮБзЗЁЙжРЛ АЃАсЧб МвЧСЦЎПўОю ПфБИ ИэММРЧ ДмМјЧб Л§ЛъЙАУГЗГ КИРЬАд ЧбДй. БзЗЏГЊ КвЧрЧЯАдЕЕ, БзЗИАд АЃДмЧЯСі ОЪДй. ДмСі Чи ЕЕУтИИ ЛчПыЧЯДТ ГэИЎ ЧСЗЮБзЗЅРК БтАш ШПРВМКРЬЖѓДТ НЩАЂЧб ЙЎСІПЁ СїИщЧбДй. ДѕПэРЬ, ГэИЎ О№ОюРЧ УжРћ ЧќНФРК ОЦСїБюСі АсСЄЕЧСі ОЪОвАэ, ГэИЎ ЧСЗЮБзЗЁЙж О№ОюПЁМ АХДыЧб ЙЎСІИІ ЧиАсЧЯБт РЇЧб ЧСЗЮБзЗЅРЛ Л§МКЧЯДТ ССРК ЙцЙ§РК ОЦСї АГЙпЕЧСі ОЪОвДй.
2 РхПЁМ ММњЧб АЭУГЗГ, Edinburgh ДыЧаРЧ Robert Kowalski РЧ СіПјРЛ ЙоРК Aix-marseille ДыЧаРЧ Alain Colmerauer ПЭ Phillipe Roussel РК Prolog РЧ БтКЛРћРЮ МГАшИІ АГЙпЧЯПДДй. Colmerauer ПЭ Roussel РК РкПЌОю УГИЎПЁ АќНЩРЬ РжОњАэ Kowaski ДТ РкЕПШЕШ СЄИЎ СѕИэПЁ АќНЩРЬ РжОњДй. Aix-Marseille ДыЧаАњ Edinburgh ДыЧаРЧ ЧљЗТРК 1970 ГтДы СпЙнБюСі АшМгЕЧОњДй. Бз ШФПЁ, О№Ою АГЙпАњ ЛчПыПЁ АќЧб ПЌБИАЁ ЕЮ СіПЊПЁМ ЕЖИГРћРИЗЮ СјЧрЕЧОњАэ, Бз АсАњ БИЙЎРћРИЗЮ ДйИЅ ЕЮ АГРЧ Prolog ЦФЛ§ОюАЁ ИИЕщОюСГДй.
Prolog РЧ АГЙпАњ ГэИЎ ЧСЗЮБзЗЁЙжПЁМ ДйИЅ ПЌБИ ГыЗТРК РЯКЛ СЄКЮАЁ 5 ММДы ФФЧЛЦУ НУНКХл (FGCS - Fifth Generation Computing Systems) (Fuchi, 1981 ; Moto-oka, 1981) РЬЖѓ КвИЎДТ ДыЧќ ПЌБИ ЧСЗЮСЇЦЎИІ НУРлЧпДйДТ ЙпЧЅАЁ 1981 ГтПЁ РжБт РќБюСіДТ Edinburgh ПЭ Marseille ДыЧа ПмКЮПЁМДТ СІЧбРћРЮ АќНЩИИРЛ ЙоОвДй. ЧСЗЮСЇЦЎРЧ БтКЛ ИёРћРК СіДЩ БтАшИІ АГЙпЧЯДТ АЭРЬОњАэ, Prolog АЁ РЬЗБ ПЌБИРЧ БтУЪЗЮ МБХУЕЧОњДй. FGCS РЧ ЙпЧЅДТ ЙЬБЙ СЄКЮПЭ РЏЗД ПЉЗЏ ГЊЖѓРЧ ПЌБИРкПЭ СЄКЮПЁ РЮАјСіДЩАњ ГэИЎ ЧСЗЮБзЗЁЙжПЁ СяАЂРћРЬАэ АЗТЧб АќНЩРЛ КвЗЏ РЯРИФзДй.
ЧіРч ИЙРК Prolog РЧ ДйИЅ ЦФЛ§ОюАЁ СИРчЧбДй. РЬЗБ АЭРК ПЉЗЏ АГРЧ КЮЗљЗЮ КаЗљЧв Мі РжДй. Marseille БзЗьРИЗЮКЮХЭ ЙпРќЧб АЭ, Edinburgh БзЗьРИЗЮКЮХЭ ГЊПТ АЭ, БзИЎАэ Clark Ањ McCabe (1984) ПЁ РЧЧи БтМњЕШ micro-Prolog ПЭ ААРК ИЖРЬХЉЗЮ ФФЧЛХЭИІ РЇЧи АГЙпЕШ ЦФЛ§ОюРЧ И№РгРЬДй. РЬАЭЕщРЧ БИЙЎ ЧќНФРК ОрАЃ ДйИЃДй. Prolog РЧ ПЉЗЏ ЦФЛ§Ою ШЄРК РЬЕщРЧ ШЅЧеЧќ БИЙЎРЛ БтМњЧЯБтКИДйДТ, БЄЙќРЇЧЯАд ЛчПыЕЧАэ РжАэ Edinburgh ПЁМ АГЙпЧб ЦЏКАЧб ЦФЛ§ОюИІ МБХУЧпДй. РЬ О№Ою ЧќНФРК ЖЇЖЇЗЮ Edinburgh БИЙЎРЬЖѓАэ КвИАДй. БзАЭРЧ УЙЙјТА БИЧіРК DEC НУНКХл - 10 ПЁМ РЬЗчОюСГДй (Warren et al., 1979).
ДйИЅ О№ОюРЧ ЧСЗЮБзЗЅУГЗГ, Prolog ЧСЗЮБзЗЅЕЕ ЙЎРхРЧ С§ЧеРИЗЮ БИМКЕШДй. Prolog ПЁДТ ДмСі 2 ~ 3 СОЗљРЧ ЙЎРхРЬ РжСіИИ, БзАЭРК КЙРтЧв Мі РжДй. И№Еч Prolog ЙЎРхРК ЧзРИЗЮКЮХЭ БИМКЕШДй.
Prolog ЧзРК ЛѓМі, КЏМі, ЖЧДТ БИСЖРЬДй. ЛѓМіДТ ПјРк (atom) РЬАХГЊ СЄМіРЬДй. ПјРкДТ Prolog РЧ БтШЃ АЊРЬАэ, LISP РЧ ПјРкПЭ РЏЛчЧЯДй. ЦЏШї, ПјРкДТ МвЙЎРкЗЮ НУРлЧЯДТ ЙЎРк, М§Рк, ЙиСй ЙЎРк (underscore) РЧ НКЦЎИЕРЬАХГЊ ЕћПШЧЅЗЮ БИКаЕШ ЧСИАЦЎ АЁДЩЧб ASCII ЙЎРкРЧ НКЦЎИЕРЬДй.
КЏМіДТ ДыЙЎРкЗЮ НУРлЧЯДТ ЙЎРкГЊ М§Рк, ЙиСй ЙЎРкРЧ НКЦЎИЕРЬДй. КЏМіДТ МБО№ПЁ РЧЧи ХИРдПЁ ЙйРЮЕљЕЧСі ОЪДТДй. АЊАњ ХИРдРЛ КЏМіПЁ АсЧеНУХАДТ АЭРЛ ЛчЗЪШ (instantiation) Жѓ КЮИЅДй. ЛчЗЪШДТ Чи ЕЕУт АњСЄ (resolution process) ПЁМИИ РЯОюГДй. АЊ ЧвДчРЬ ОШЕШ КЏМіДТ КёЛчЗЪШ (uninstantiation) КЏМіЖѓ КвИАДй. ЛчЗЪШДТ Чб ИэСІРЧ СѕИэРЬГЊ ЙнСѕРЛ ЦїЧдЧЯДТ ЧЯГЊРЧ ПЯРќЧб ИёРћРЛ ИИСЗНУХГ Мі РжДТ Чб АшМгЕШДй. Prolog КЏМіДТ, РЧЙЬГЊ ЛчПы АќСЁПЁМ, ИэЗЩЧќ О№ОюРЧ КЏМіПЭДТ ДйИЃДй.
ЧзРЧ ИЖСіИЗ СОЗљДТ БИСЖЖѓ КвИАДй. БИСЖДТ МњОю ЧиМЎЧаРЧ БтКЛ ИэСІЗЮ ЧЅЧіЕЧАэ, РЯЙнРћРЮ ЧќНФРК ЕПРЯЧЯДй.
functor (ИХАГКЏМі ИЎНКЦЎ)
functor ДТ ОюЖВ ПјРкРЬАэ БИСЖИІ РЮНФЧЯДТ ЕЅ ЛчПыЕШДй. ИХАГ КЏМі ИЎНКЦЎДТ ПјРк, КЏМіГЊ ДйИЅ БИСЖРЧ ИЎНКЦЎАЁ ЕЩ Мі РжДй. ДйРН Р§ПЁМ ЛѓММШї ГэРЧЕЧАкСіИИ, БИСЖДТ Prolog ПЁМ ЛчНЧ (fact) РЛ ИэНУЧЯДТ ЕЕБИРЬДй. БИСЖДТ АДУМЗЮ Л§АЂЕЩ Мі РжДй. РЬ АцПь БИСЖДТ ЛчНЧРЬ АќЗУЕШ ПЉЗЏ ПјРкРЧ ЧзПЁМ ЧЅНУЕЧДТ АЭРЛ ЧуПыЧбДй. РЬЗБ РЧЙЬПЁМ, БИСЖДТ Чз ЛчРЬРЧ АќАшИІ ГЊХИГЛБт ЖЇЙЎПЁ АќАшРЬДй. ЖЧЧб БИСЖДТ ЙЎИЦРЬ БИСЖИІ СњЙЎРИЗЮ ИэНУЧв ЖЇДТ МњОюРЬДй.
Prolog ЙЎПЁ ДыЧб ГэРЧДТ АЁМГ Ся УпСЄЕШ СЄКИРЧ ЕЅРЬХЭКЃРЬНКИІ БИМКЧЯДТЕЅ ЛчПыЕЧДТ ЙЎРхРИЗЮ НУРлЧбДй. РЬ ЙЎРхРИЗЮКЮХЭ ЛѕЗЮПю СЄКИАЁ УпЗаЕЩ Мі РжДй.
Prolog ДТ ЕЮ АГРЧ БтУЪ ЙЎРх ЧќНФРЛ АЎДТДй. РЬАЭРК МњОю ЧиМЎЧаРЧ ЙЋЕЮ ШЅ ХЌЗЮСюПЁ ЧиДчЕШДй. Prolog РЧ ЙЋЕЮ ШЅ ХЌЗЮСюРЧ АЁРх АЃДмЧб ЧќНФРЬ ДмРЯ БИСЖРЬДй. РЬАЭРК ЙЋСЖАЧРћ ДмО№ Ся ЛчНЧЗЮ ЧиМЎЕШДй. ГэИЎРћРИЗЮ ЛчНЧРК ТќРЮ ДмМј ИэСІРЬДй.
ДйРН ПЙСІДТ Prolog ЧСЗЮБзЗЅПЁМ АЁСњ Мі РжДТ ЛчНЧРЧ СОЗљИІ МГИэЧбДй. И№Еч Prolog ЙЎРхРЬ ИЖФЇЧЅЗЮ ГЁГЊДТ АЭПЁ СжРЧЧиЖѓ.
female
(shelley).
male (bill).
female (mary).
male (jake).
father (bill, jake).
father (bill, shelley).
mother (mary,
jake).
mother (mary, shelley).
РЬ АЃДмЧб БИСЖЕщРК jake, shelley, bill, mary ПЁ АќЧб ОюЖВ ЛчНЧРЛ ГЊХИГНДй. ПЙЗЮ, УЙЙјТА АЭРК shelley АЁ ПЉРкЖѓДТ АЭРЛ ГЊХИГНДй. ИЖСіИЗ Гз АГДТ ПјРк functor ЗЮ РЬИЇРЬ КйПЉСј АќАшЗЮ ЕЮ ИХАГКЏМіИІ ПЌАсЧбДй. ПЙИІ ЕщИщ, ДйМИЙјТА ИэСІДТ bill РЬ jake РЧ ОЦЙіСіЖѓДТ РЧЙЬЗЮ ЧиМЎЕШДй. МњОю ЧиМЎЧаРЧ ИэСІУГЗГ Prolog ИэСІДТ АэРЏРЧ РЧЙЬИІ АЁСіАэ РжСі ОЪРНПЁ РЏРЧЧЯЖѓ. БзЕщРК ЧСЗЮБзЗЁИгАЁ БзЕщПЁАд ГЊХИГЛБтИІ ПјЧЯДТ АЭРЛ РЧЙЬЧбДй. ПЙИІ ЕщИщ, ИэСІ
father (bill, jake).
ДТ bill Ањ jake АЁ ЕПРЯЧб ОЦЙіСіИІ АЎАХГЊ jake АЁ bill РЧ ОЦЙіСіЖѓДТ АЭРЛ РЧЙЬЧв Мі РжДй. БзЗЏГЊ АЁРх РЯЙнРћРЬАэ СїМГРћРЮ РЧЙЬДТ bill РЬ jake РЧ ОЦЙіСіЖѓДТ АЭРЬДй.
ЕЅРЬХЭКЃРЬНКИІ БИМКЧЯБт РЇЧб Prolog РЧ ДйИЅ БтКЛ ЧќНФРК РЏЕЮ ШЅ ХЌЗЮСюПЁ ДыРРЕШДй. РЬ ЧќНФРК МіЧаПЁМ СжОюСј СЖАЧ С§ЧеРЬ ИИСЗЕЧИщ АсАњАЁ ГЊПРДТ АЭРИЗЮ ОЫЗССј СЄИЎПЭ ПЌАќНУХГ Мі РжДй. ПьКЏРК РќСІ, Ся if КЮКаРЬИч, СТКЏРК АсЗа, Ся then КЮКаРЬДй. ИИОр Prolog ЙЎРхРЧ РќСІАЁ ТќРЬИщ, ЖЧЧб ЙЎРхРЧ АсАњЕЕ ТќРЬДй. БзЕщРК ШЅ ХЌЗЮСюРЬБт ЖЇЙЎПЁ, Prolog ЙЎРкРЧ АсАњДТ ДмРЯ ЧзРЬАэ, ЙнИщПЁ РќСІДТ ДмРЯ ЧзРЬАХГЊ ГэИЎАі (conjunctions) РЬ ЕЩ Мі РжДй.
ГэИЎАі (conjunctions) РК ГэИЎ AND ПЌЛъРкПЁ РЧЧи КаИЎЕШ ДйСп ЧзРЛ АЁСіАэ РжДй. Prolog ПЁ AND ПЌЛъРкДТ ОЯНУРћРЬДй. БтКЛ ИэСІИІ ГэИЎАіРИЗЮ ИэБтЧЯДТ БИСЖДТ ФоИЖЗЮ КаИЎЕЧИч, БзЗЁМ ФоИЖИІ AND ПЌЛъРкЗЮ АЃСжЧв Мі РжДй. ГэИЎАі ПЙСІЗЮМ, ДйРНРЛ Л§АЂЧи КИРк.
female (shelley), child (shelley).
Prolog РЧ РЏЕЮ ШЅ ХЌЗЮСю ЙЎРхРЧ РЯЙнРћРЮ ЧќНФРК ДйРНАњ ААДй.
АсЗа_1 :- РќСІ_ЧЅЧіНФ.
РЬАЭРК ДйРНАњ ААРЬ РаРЛ Мі РжДй. "ИИОр РќСІ_ЧЅЧіНФРЬ ТќРЬАХГЊ КЏМіРЧ ЛчЗЪШПЁ РЧЧи ТќРЬ ЕЧИщ АсЗа_1 РЬ МКИГЧбДй." ДйРН ПЙСІИІ КИРк.
ancestor (mary, shelly) :- mother (mary, shelley).
РЬ ПЙСІДТ "ИИОр mary АЁ shelley РЧ ОюИгДЯРЬИщ, mary ДТ shelley РЧ СЖЛѓРЬДй" ЖѓДТ АЭРЛ ГЊХИГНДй. РЏЕЮ ШЅ ХЌЗЮСюДТ ИэСІЛчРЬРЧ ЧдУр БдФЂРЛ ММњЧЯБт ЖЇЙЎПЁ, РЏЕЮ ШЅ ХЌЗЮСюДТ БдФЂ (Rule) РЬЖѓАэ КвИАДй.
МњОю ЧиМЎЧаРЧ ХЌЗЮСю ЧќНФ ИэСІУГЗГ, Prolog ЙЎРК БзЕщРЧ РЧЙЬИІ РЯЙнШЧЯДТ КЏМіИІ ЛчПыЧв Мі РжДй. ХЌЗЮСю ЧќНФРЧ КЏМіДТ ГЛРчЕШ РќФЊ (universal) ЧбСЄЛчИІ СІАјЧбДй. ДйРНРК Prolog ЙЎПЁМ КЏМіРЧ ЛчПыРЛ КИПЉСжАэ РжДй.
parent
(X, Y) :- mother (X, Y).
parent (X, Y) :- father (X, Y).
grandparent (X, Z) :- parent (X, Y), parent (Y, Z).
sibling
(X, Y) :- mother (M, X), mother (M, Y), father (F, X), father (F, Y).
РЬ ЙЎРК КЏМіГЊ РЯЙн АДУМЛчРЬРЧ ЧдУр БдФЂРЛ СІАјЧбДй. РЬ АцПьПЁ, РЯЙн АДУМДТ X, Y, Z, M, F РЬДй. УЙЙјТА БдФЂРК ИИОр mother (X, Y) ТќРЬ ЕЧДТ X, Y РЧ ЛчЗЪШАЁ РжДйИщ, ЕПРЯЧб X, Y РЧ ЛчЗЪШПЁ ДыЧи parent (X, Y) ЕЕ ТќРЬДйЖѓДТ БдФЂРЛ ММњЧбДй.
СіБнБюСі ПьИЎДТ ОЫЗССј ЛчНЧРЬГЊ ЛчНЧЕщРЧ ГэИЎРћ АќАшИІ ГЊХИГЛДТ БдФЂРЛ БтМњЧЯДТ ЕЅ ЛчПыЕШ ГэИЎ ИэСІИІ РЇЧи Prolog ЙЎРЛ БтМњЧЯПДДй. РЬЗЏЧб ЙЎРхРК СЄИЎ СѕИэ И№ЕЈПЁМ БтУЪРЬДй. СЄИЎДТ НУНКХлРЬ СѕИэРЬГЊ ЙнСѕЕЧБтИІ ПјЧЯДТ ИэСІ ЧќНФРЬДй. Prolog ПЁМ, РЬЗБ ИэСІДТ ИёРћ (goal) РЬГЊ СњРЧ (query) ЖѓАэ КвИАДй. Prolog ИёРћЙЎРЧ БИЙЎ ЧќНФРК ЙЋЕЮ ШЅ ХЌЗЮСюПЭ ЕПРЯЧЯДй. ПЙИІ ЕщИщ, ДйРН ИёРћЙЎРЛ КИРк.
man (fred).
РЬ ИёРћЙЎПЁ ДыЧи НУНКХлРК "ПЙ" ГЊ "ОЦДЯПР" ЖѓАэ РРДфЧбДй. ДыДфРЬ "ПЙ" РЬИщ НУНКХлРК СжОюСј ЛчНЧАњ АќАшРЧ ЕЅРЬХЭКЃРЬНКПЁМ ИёРћРЬ ТќРЬЖѓАэ НУНКХлРЬ СѕИэЧЯПДДйДТ АЭРЛ РЧЙЬЧбДй. ДыДфРЬ "ОЦДЯПР" РЬИщ ИёРћРЬ АХСўРЬАХГЊ НУНКХлРЬ СѕИэРЬГЊ ЙнСѕРЛ АЃДмШї Чв Мі ОјДйДТ АЭРЛ РЧЙЬЧбДй.
ГэИЎАі ИэСІПЭ КЏМіИІ АЎДТ ИэСІЕЕ ЧеЙ§РћРЮ ИёРћ ЙЎРЬДй. КЏМіАЁ СИРчЧв ЖЇ, НУНКХлРК ИёРћРЧ РЏШПМКРЛ СжРхЧв ЛгИИ ОЦДЯЖѓ ИёРћРЛ ТќРИЗЮ ИИЕхДТ КЏМіРЧ ЛчЗЪШИІ ШЎРЮЧбДй. ПЙИІ ЕщИщ,
father (X, mike).
ЗЮ СњРЧЧв Мі РжДй. БзЗБ ШФПЁ, НУНКХлРК ДмРЯШИІ ХыЧи ИёРћРЛ ТќРИЗЮ ИИЕхДТ X РЧ ЛчЗЪШИІ УЃЕЕЗЯ НУЕЕЧбДй.
ИёРћЙЎАњ КёИёРћЙЎРК ЕПРЯЧб ЧќНФ (ЙЋЕЮ ШЅ ХЌЗЮСю) РЛ АЁСіБт ЖЇЙЎПЁ, Prolog БИЧіРК РЬ ЕЮ АГИІ БИКАЧЯДТ ЙцЙ§РЛ ЙнЕхНУ АЁСЎОп ЧбДй. ДыШНФ Prolog БИЧіРК ДйИЅ ДыШНФ ЧСЗвЧСЦЎПЁ РЧЧи ЧЅНУЕЧДТ АЃДмЧб ЕЮ АГРЧ И№ЕхИІ АЁСќРИЗЮМ РЬАЭРЛ МіЧрЧбДй. Ся ЛчНЧАњ БдФЂРЛ РдЗТЧЯДТ ЧСЗвЧСЦЎПЭ ИёРћРЛ РдЗТЧЯДТ ЧСЗвЧСЦЎРЬДй. ЛчПыРкДТ О№СІЖѓЕЕ И№ЕхИІ ЙйВм Мі РжДй.
РЬ Р§ПЁМ Prolog РЧ Чи ЕЕУтРЛ СЖЛчЧЯАэРк ЧбДй. Prolog РЧ ШПРВРћРЮ ЛчПыРК ЧСЗЮБзЗЁИгАЁ Prolog НУНКХлРЬ ЧСЗЮБзЗЅРИЗЮ МіЧрЧЯДТ АЭРЛ РкММШї ОЫ АЭРЛ ПфБИЧбДй.
СњРЧДТ ИёРћ (goal)
РЬЖѓ КвИАДй. ИёРћРЬ КЙЧе ИэСІРЯ ЖЇ, АЂ ЛчНЧ (БИСЖ) РК КЮИёРћ (subgoal) РЬЖѓ
КвИАДй. ИёРћРЬ ТќРЬЖѓДТ АЭРЛ СѕИэЧЯБт РЇЧи, УпЗа АњСЄРК ИёРћРЛ ЕЅРЬХЭ КЃРЬНКРЧ
ЧЯГЊ ЖЧДТ Бз РЬЛѓРЧ ЛчНЧАњ ПЌАсНУХАДТ ЕЅРЬХЭ КЃРЬНКРЧ УпЗа БдФЂАњ/ЖЧДТ ЛчНЧРЧ
УМРЮРЛ УЃОЦОп ЧбДй. ПЙИІ ЕщИщ, ИИОр Q АЁ ИёРћРЬИщ, Q ДТ ЕЅРЬХЭКЃРЬНКПЁМ ЛчНЧЗЮМ
УЃОЦСіАХГЊ УпЗа АњСЄРК P АЁ МКИГЧЯДТ ЛчНЧ 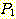 Ањ ИэСІ
Ањ ИэСІ  РЧ МјМПРЛ УЃОЦОп ЧбДй.
РЧ МјМПРЛ УЃОЦОп ЧбДй.
ЙАЗа, РЬ АњСЄРК БдФЂРЧ КЙЧе ИэСІЗЮ БИМКЕШ ПьКЏАњ БдФЂРЧ КЏМіРЧ СИРчПЁ РЧЧиМ КЙРтЧиСњ Мі РжАэ, АЁВћРК КЙРтЧЯДй. P (СИРчЧв ЖЇ) ИІ УЃДТ ЙцЙ§РК БйКЛРћРИЗЮ МЗЮ ДйИЅ ЧзАњРЧ КёБГ Ся КЮЧе (matching) РЬДй.
КЮИёРћРЛ СѕИэЧЯДТ АњСЄРК ИэСІ-КЮЧе АњСЄРИЗЮ МіЧрЕЧБт ЖЇЙЎПЁ, БзАЭРК ЖЇЖЇЗЮ КЮЧеРЬЖѓ КвИАДй. ОюЖВ АцПьПЁМДТ КЮИёРћРЛ СѕИэЧЯДТ АЭРК КЮИёРћРЛ ИИСЗ (satisfying) ЧЯДТ АЭРЬЖѓ КвИАДй.
ДйРН СњРЧИІ Л§АЂЧиКИРк.
man (bob).
РЬ ИёРћЙЎРК АЁРх АЃДмЧб СОЗљРЬДй. Чи ЕЕУтРЬ ТќРЮСі АХСўРЮСіИІ АсСЄЧЯДТ АЭРК ЛѓДыРћРИЗЮ НБДй. РЬ ИёРћРЧ ЦаХЯРК ЕЅРЬХЭКЃРЬНКРЧ ЛчНЧАњ БдФЂПЁ КёБГЕШДй. ИИОр ЕЅРЬХЭКЃРЬНКАЁ ЛчНЧ
man (bob).
РЛ ЦїЧдЧбДйИщ, СѕИэРК ДмМјЧЯДй. БзЗЏГЊ ИИОр ЕЅРЬХЭКЃРЬНКАЁ ДйРНРЧ ЛчНЧАњ УпЗа БдФЂРЛ АЁСіАэ РжДйИщ,
father
(bob).
man (X) :- father (X).
Prolog ДТ РЬ ЕЮ ЙЎРхРЛ УЃЕЕЗЯ ПфБИЧЯИч, ИёРћРЧ СјИЎ АЊРЛ УпЗаЧЯБт РЇЧи РЬЕщРЛ ЛчПыЧбДй. РЬАЭРК РЯНУРћРИЗЮ X ИІ bob РИЗЮ ЛчЗЪШЧЯДТ ДмРЯШИІ ЧЪПфЗЮ ЧбДй.
РЬСІ ДйРН ИёРћРЛ ЛьЦьКИРк.
man (X).
РЬ АцПьПЁ, Prolog ДТ ИёРћРЛ ЕЅРЬХИКЃРЬНКРЧ ИэСІПЭ КЮЧеНУФбОп ЧбДй. ИХАГКЏМіЗЮ АДУМИІ АЎАэ, ИёРћРЧ ЧќНФРЛ АЎДТ Prolog АЁ УЃДТ УЙЙјТА ИэСІДТ X ИІ АДУМРЧ АЊРИЗЮ ЛчЗЪШНУХВДй. БзЗБ ШФ, X ДТ АсАњЗЮМ Е№НКЧУЗЙРЬ (УтЗТ) ЕШДй. ИёРћРЧ ЧќНФРЛ АЎДТ ИэСІАЁ ОјДйИщ, НУНКХлРК "ОЦДЯПР" ЖѓАэ ИЛЧЯИщМ, ИёРћРЛ ИИСЗНУХГ Мі ОјДйАэ ГЊХИГНДй.
СжОюСј ИёРћРЬ ЕЅРЬХЭКЃРЬНКРЧ ЛчНЧАњ КЮЧеЧЯБт РЇЧб НУЕЕПЁДТ ЕЮ АЁСі ДыИГЕЧДТ СЂБй ЙцЙ§РЬ РжДй. НУНКХлРК ЕЅРЬХЭКЃРЬНКРЧ ЛчНЧАњ БдФЂРЛ АЁСіАэ НУРлЧЯАэ, ИёРћПЁ ЕЕДоЧЯДТ КЮЧе МјМИІ УЃЕЕЗЯ НУЕЕЧбДй. РЬЗЏЧб СЂБй ЙцЙ§РК ЛѓЧтНФ Чи ЕЕУт ЖЧДТ РќЧт УМРЮ (forward chaining) РЬЖѓАэ КвИАДй. ДйИЅ ЙцЙ§РК ИёРћРИЗЮ НУРлЧЯАэ, ЕЅРЬХЭКЃРЬНКПЁМ ПјЗЁРЧ ОюЖВ ЛчНЧ С§ЧеПЁ ЕЕДоЧЯДТ КЮЧе ИэСІРЧ МјМИІ ХНЛіЧЯЕЕЗЯ НУРЮЧбДй. РЬЗБ СЂБй ЙцНФРК ЧЯЧтНФ Чи ЕЕУт ЖЧДТ ШФЧт УМРЮ (backward chaining) РЬЖѓАэ КвИАДй. РЯЙнРћРИЗЮ ШФЧт УМРЮРК ШФКИ ЧиДфРЧ С§ЧеРЬ РћДчЧЯАд РлРЛ ЖЇ Рп РлЕПЧбДй. РќЧт УМРЮ СЂБй ЙцЙ§РК АЁДЩЧб ДфРЧ МіАЁ ИЙРЛ ЖЇ Рп ЕПРлЧбДй. РЬЗЏЧб ЛѓШВПЁМ ШФЧт УМРЮРК ЧиДфРЛ ОђБт РЇЧи ИЙРК МіРЧ КЮЧеРЛ ПфБИЧбДй. МГАшРкДТ АХДыЧб КЮЗљРЧ ЙЎСІПЁ ДыЧи РќЧт УМРЮКИДй ШФЧт УМРЮРЬ РћЧеЧЯДйАэ ЙЯБт ЖЇЙЎПЁ, Prolog БИЧіРК Чи ЕЕУтРЛ РЇЧи ШФЧт УМРЮРЛ ЛчПыЧбДй.
ДйНУ СњРЧ ПЙСІИІ ЛьЦьКИРк.
man (bob).
ЕЅРЬХЭКЃРЬНКПЁ ДйРНРЬ РжДйАэ АЁСЄЧЯРк.
father
(bob).
man (X) :- father (X).
РќЧт УМРЮРК УЙЙјТА ИэСІИІ ХНЛіЧЯАэ УЃДТДй. БзЗБ ШФ, X ИІ bob РИЗЮ ЛчЗЪШЧЯПЉ УЙЙјТА ИэСІИІ ЕЮЙјТА БдФЂРЧ ПьКЏ ((father (X)) Ањ КЮЧеЧб ШФ ЕЮЙјТА ИэСІРЧ СТКЏРЛ ИёРћПЁ КЮЧеНУХДРИЗЮМ ИёРћРЬ УпЗаЕШДй. ШФЧт УМРЮРК ИеРњ X ИІ bob РИЗЮ ЛчЗЪШИІ ХыЧиМ ИёРћРЛ ЕЮЙјТА ИэСІРЧ СТКЏ (man (X)) Ањ КЮЧеЧбДй. ИЖСіИЗ ДмАшПЁМ, ЕЮЙјТА ИэСІРЧ ПьКЏ (father (bob)) РК УЙЙјТА ИэСІПЭ КЮЧеЧбДй.
ДйРН МГАш ЙЎСІДТ РЇПЁМ КЛ ПЙСІУГЗГ ИёРћРЬ ЧЯГЊ РЬЛѓРЧ БИСЖИІ АЁСњ ЖЇ ЙпЛ§ЧбДй. ПЉБтПЁМРЧ ЙЎСІДТ Чи ЕЕУт ХНЛіРЬ ГаРЬ ПьМБ (breadth-first) ЖЧДТ БэРЬ ПьМБ (depth-first) РИЗЮ МіЧрЕЧДРГФРЬДй. БэРЬ ПьМБ ХНЛіРК ДйИЅ КЮИёРћПЁ РлОїЧЯБт РќПЁ СжОюСј ИёРћРЧ УЙЙјТА КЮИёРћРЧ ИэСІ-СѕИэ- РЧ ПЯРќЧб МјМИІ УЃДТДй. ГаРЬ ПьМБ ХНЛіРК СжОюСј ИёРћРЧ И№Еч КЮИёРћПЁ КДЗФРћРИЗЮ РлОїЧбДй. Prolog МГАшРкДТ БэРЬ ПьМБ ХНЛі СЂБй ЙцЙ§РЬ РћРК ФФЧЛХЭ РкПјРЛ АЁСіАэ МіЧрЕЩ Мі РжБт ЖЇЙЎПЁ БтКЛРћРИЗЮ БэРЬ ПьМБ ХНЛі СЂБй ЙцЙ§РЛ МБХУЧЯПДДй. ГаРЬ ПьМБ ХНЛіРК ИЙРК ИоИ№ИЎ ЛчПыРЛ ПфБИЧЯДТ КДЗФ ХНЛіРЬДй.
ГэРЧЧиОп Чв Prolog Чи ЕЕУт БИСЖРЧ ИЖСіИЗ ЦЏТЁРК ПЊЧр (backtracking) РЬДй. ДйСп КЮИёРћРЛ АЁСј ИёРћРЬ УГИЎЕЧАэ НУНКХлРЬ КЮИёРћ Сп ЧЯГЊРЧ СјИЎАЊРЛ КИПЉСжДТ АЭРЛ НЧЦаЧв ЖЇ, НУНКХлРК СѕИэЧв Мі ОјДТ Бз КЮИёРћРЛ ЦїБтЧбДй. ДыНХПЁ, НУНКХлРК ИИОр Бз КЮИёРћРЬ РжРИИщ РЬРќ КЮИёРћРЛ ДйНУ АэЗСЧЯПЉ ДйИЅ ЧиДфРЛ УЃЕЕЗЯ НУЕЕЧбДй. РЬРќПЁ СѕИэЕШ КЮИёРћРЧ РчАэИІ РЇЧи ИёРћПЁМ ШФХ№ЧЯДТ АЭРЛ ПЊЧр (backtracking) РЬЖѓ КЮИЅДй. ЛѕЗЮПю ЧиДфРК Бз КЮИёРћРЧ РЬРќ ХНЛіРЬ СпДмЕШ АїПЁМ ХНЛіРЛ НУРлЧдРИЗЮМ УЃРЛ Мі РжДй. КЮИёРћРЧ ДйМіРЧ ЧиДТ КЏМіРЧ АЂАЂ ДйИЅ ЛчЗЪШПЁ БтРЮЧбДй. ПЊЧрРК НУАЃАњ АјАЃРЛ ИЙРЬ ПфБИЧбДй. ПжГФЧЯИщ, АЂ КЮИёРћРЧ И№Еч АЁДЩЧб СѕИэРЛ УЃОЦОпЧЯБт ЖЇЙЎРЬДй. РЬЗБ КЮИёРћ СѕИэРК ИЖСіИЗ ПЯРќЧб СѕИэРЬ ЕЧДТ АсАњ СѕИэРЛ УЃБт РЇЧи ПфБИЕШ НУАЃРЬ УжМвШЕЧЕЕЗЯ СЖСїЕЧСі ОЪДТДй. РЬАЭРК ЙЎСІИІ ОЧШНУХВДй.
ПЊЧрПЁ ДыЧб РЬЧиИІ ШЎНЧШї ЧЯБт РЇЧи ДйРН ПЙСІИІ ЛьЦьКИРк. ЕЅРЬХЭКЃРЬНКПЁ ЛчНЧАњ БдФЂРЧ С§ЧеРЬ РжАэ, Prolog ПЁ ДйРНАњ ААРК КЙЧе ИёРћРЬ СІНУЕЧОњДйАэ АЁСЄЧЯРк.
male (X), parent (X, shelley).
РЬ ИёРћРК X АЁ male РЬАэ X АЁ shelley РЧ parent АЁ ЕЧДТ X РЧ ЛчЗЪШАЁ РжДТСіИІ ЙЏДТДй. Prolog ДТ ИеРњ РлПыРк (functor) ЗЮ male РЛ АЁСіАэ РжДТ ЕЅРЬХЭКЃРЬНКПЁМ УЙЙјТА ЛчНЧРЛ УЃДТДй. БзЗБ ШФ, X ИІ УЃРК ЛчНЧРЧ ИХАГКЏМі mike ЗЮ ЛчЗЪШНУХВДй. Бз ДйРНРИЗЮ, parent (mike, shelley) АЁ ТќРЬЖѓДТ СѕИэРЛ НУЕЕЧбДй. ИИОр БзАЭРЬ НЧЦаЧЯИщ, УЙЙјТА КЮИёРћ male (X) ЗЮ ЕЧЕЙОЦАЁАэ, X РЧ ДйИЅ ЛчЗЪШЗЮ ИИСЗНУХГЗСАэ НУЕЕЧбДй. Чи ЕЕУт АњСЄРК shelley РЧ КЮИ№РЮ male РЛ УЃБт РќПЁ ЕЅРЬХЭКЃРЬНКПЁМ И№Еч male РЛ УЃРЛ МіЕЕ РжДй. Чи ЕЕУт АњСЄРК ИёРћРЛ ИИСЗНУХГ Мі ОјДйДТ АЭРЛ СѕИэЧЯБт РЇЧи И№Еч male РЛ ШЎНЧШї УЃОЦОпЧбДй. ИИОр ЕЮ АГРЧ КЮИёРћРЧ МјМАЁ ЙнДыЗЮ ЕЧОю РжРИИщ, ПьИЎРЧ ПЙСІДТ СЛДѕ ШПРВРћРИЗЮ УГИЎЕШДй. БзЗБ ШФ, Чи ЕЕУтРЬ shelley РЧ КЮИ№ИІ ЙпАпЧб ШФ Бз ЛчЖїАњ КЮИёРћ male ИІ КЮЧеНУХГЗСАэ Чв АЭРЬДй. ИИОр ЕЅРЬХЭКЃРЬНКПЁ shelley АЁ male КИДй РћРК parent ИІ АЁСіАэ РжРИИщ (АјСЄЧб АЁСЄУГЗГ Л§АЂЕЪ) РЬАЭРК СЛДѕ ШПРВРћРЬДй. 7.1 Р§ПЁМ Prolog НУНКХлПЁ РЧЧиМ МіЧрЕЧДТ ПЊЧрРЛ СІЧбНУХАДТ ЙцЙ§РЛ ЛьЦьКЛДй.
Prolog ПЁМ ЕЅРЬХЭКЃРЬНК ХНЛіРК ЧзЛѓ УЙЙјТАПЁМ ИЖСіИЗ ЙцЧтРИЗЮ СјЧрЕШДй.
ДйРН ЕЮ КЮР§РК Чи ЕЕУт АњСЄРЛ Дѕ ЛѓММШї МГИэЧЯДТ Prolog ПЙСІИІ БтМњЧбДй.
Prolog ДТ СЄМі КЏМіПЭ СЄМі ЛъМњ ПЌЛъРЛ СіПјЧбДй. ПјЗЁ, ЛъМњ ПЌЛъРкДТ РлПыРк (functor) ПДДй. БзЗЁМ 7 Ањ КЏМі X РЧ ЧеРК ДйРНАњ ААРЬ ЧќМКЕШДй.
+ (7, X)
Prolog ДТ is ПЌЛъРкЗЮМ ЛъМњ ПЌЛъРЧ ДѕПэ АЃАсЧб БИЙЎРЛ ЧуПыЧбДй. РЬ ПЌЛъРкДТ ПРИЅТЪ ЧЧПЌЛъРкЗЮМ ЛъМњ ЧЅЧіНФРЛ ПоТЪ ЧЧПЌЛъРкЗЮМ КЏМіИІ УыЧбДй. ЧЅЧіНФРЧ И№Еч КЏМіДТ ЙнЕхНУ ЙЬИЎ ЛчЗЪШЕЧОюОп ЧЯСіИИ, СТКЏРЧ КЏМіДТ РќПЁ ЛчЗЪШЕЩ Мі ОјДй. ПЙИІ ЕщОю, ДйРН НФРЛ Л§АЂЧи КИРк.
A is B / 17 + C.
ИИОр B ПЭ C АЁ ЛчЗЪШЕЧОњСіИИ, A ДТ ОШЕЧОњДйИщ, РЬ ХЌЗЮСюДТ A ИІ ЧЅЧіНФРЧ АЊРИЗЮ ЛчЗЪШЧв АЭРЬДй. РЬЗБ РЯРЬ ЙпЛ§ЧЯИщ, ХЌЗЮСюДТ ИИСЗЕШДй. ИИОр B ПЭ C АЁ ЛчЗЪШЕЧСі ОЪАэ A ИИРЬ ЛчЗЪШЕЧОњДйИщ, ХЌЗЮСюДТ ИИСЗЕЧСі ОЪРИИч A РЧ ЛчЗЪШДТ ЙпЛ§ЕЩ Мі ОјДй. is ИэСІРЧ РЧЙЬДТ ИэЗЩЧќ О№ОюРЧ ЙшСЄЙЎАњДТ ИЙРК ТїРЬАЁ РжДй. РЬ ТїРЬДТ ШяЙЬЗЮПю ЛѓШВРЛ РЬВјОю ГО Мі РжДй. is ПЌЛъРкДТ ХЌЗЮСюИІ ЙшСЄЙЎУГЗГ КИРЬАд ЧЯБт ЖЇЙЎПЁ, УЪКИ Prolog ЧСЗЮБзЗЁИгДТ ДйРНАњ ААРК ЙЎРхРЛ РлМКЧв Мі РжДй.
Sum is Sum + Number.
РЬАЭРК Prolog ПЁМ ЧеЙ§РћРЯСіЖѓЕЕ РЏПыЧЯСі ОЪДй. ИИОр Sum РЬ ЛчЗЪШЕЧСі ОЪОвДйИч, ПьКЏРЧ ТќСЖДТ СЄРЧЕЧСі ОЪАэ, ХЌЗЮСюДТ НЧЦаЧбДй. ИИОр Sum РЬ РЬЙЬ ЛчЗЪШЕЧОњДйИщ, is АЁ ЦђАЁЕЩ ЖЇ ПоТЪ ЧЧПЌЛъРкДТ ЧіРч ЛчЗЪШИІ АЁСњ Мі ОјБт ЖЇЙЎПЁ ХЌЗЮСюДТ НЧЦаЧбДй. ОюДР АцПьЕч, ЛѕЗЮПю АЊПЁ ДыЧб Sum РЧ ЛчЗЪШДТ ЙпЛ§ЧЯСі ОЪДТДй (ИИОр Sum + Number РЧ АЊРЬ ПфБИЕЧИщ, БзАЭРК ОюЖВ ЛѕЗЮПю РЬИЇПЁ ЙйРЮЕљЕЩ Мі РжДй).
Prolog ДТ ИэЗЩЧќ О№ОюПЭ ААРК ЕПРЯЧб РЧЙЬЗЮ ЙшСЄЙЎРЛ АЎСі ОЪДТДй. БзЕщРК Prolog АЁ МГАшЕШ ДыКЮКаРЧ ЧСЗЮБзЗЁЙжПЁМ ЧЪПфФЁ ОЪДй. ИэЗЩЧќ О№ОюПЁМ ЙшСЄЙЎРЧ РЏПыМКРК ЙшСЄЙЎРЬ ГЛРхЕШ ФкЕхРЧ НЧЧр СІОю ШхИЇРЛ СІОюЧЯДТ ЧСЗЮБзЗЁИгРЧ ДЩЗТПЁ ДоЗСРжДй. РЬЗБ ЧќРЧ СІОюДТ Prolog ПЁМ ЧзЛѓ АЁДЩЧЯСі ОЪБт ЖЇЙЎПЁ, РЬЗЏЧб ЙЎРхРК АХРЧ РЏПыЧЯСі ОЪДй.
Prolog ПЁМ МіФЁ АшЛъРЛ ЛчПыЧб АЃДмЧб ПЙСІЗЮМ, ДйРН ЙЎСІИІ Л§АЂЧи КИРк. ПьИЎДТ ОюЖВ ЦЏКАЧб РкЕПТї АцСж ЦЎЗЂПЁМ ПЉЗЏ РкЕПТїРЧ ЦђБе МгЕЕПЭ Бз ЦЎЗЂПЁ РжДТ РкЕПТїРЧ Уб НУАЃРЛ ОЫАэ РжДйАэ АЁСЄЧЯРк. РЬ БтКЛ СЄКИДТ ЛчНЧЗЮ ФкЕљЕЧАэ, МгЕЕ, НУАЃ, АХИЎ ЛчРЬРЧ АќАшДТ БдФЂРИЗЮ ДйРНАњ ААРЬ РлМКЕШДй.
speed
(ford, 100).
speed (vlovo, 80).
speed
(chevy, 105).
speed (dodge, 95).
time
(ford, 20).
time (chevy, 21).
time
(dodge, 24).
time (volvo, 24).
distance
(X, Y) :- speed (X, Speed),
time
(X, Time),
Y
is Speed * Time.
РЬСІ, СњРЧДТ ЦЏКАЧб РкЕПТїРЧ СжЧр АХИЎИІ ПфБИЧбДй. ПЙИІ ЕщИщ, СњРЧ
distance (chevy, Chevy_Distance).
ДТ Chevy_Distance ИІ 2205 ЗЮ ЛчЗЪШНУХВДй. АХИЎ АшЛъ ЙЎРхРЧ ПьКЏПЁМ УЙ ЕЮ ХЌЗЮСюДТ АЃДмЧЯАд КЏМі Speed ПЭ Time РЛ СжОюСј РкЕПТї РлПыРкРЧ ДыРР АЊРИЗЮ ЛчЗЪШНУХВДй. ИёРћРЬ ИИСЗЕШ ШФПЁ, ЖЧЧб Prolog ДТ Chevy_Distance ПЭ АЊРЛ Е№НКЧУЗЙРЬЧбДй.
РЬ НУСЁПЁМ, Prolog НУНКХлРЬ АсАњИІ Л§ЛъЧЯДТ ЙцЙ§РЛ ПЌЛъРћРЮ ИщПЁМ АќТћЧЯДТ АЭРК РЏРЭЧЯДй. Prolog ДТ СжОюСј ИёРћРЛ ИИСЗНУХАДТ ЕПОШПЁ АЂ ДмАшПЁМ МіЧрЧб КЏМіРЧ ЛчЗЪШИІ Е№НКЧУЗЙРЬЧЯДТ trace ЖѓДТ РЬИЇРЧ ГЛРх БИСЖИІ АЎДТДй. trace ДТ Prolog ЧСЗЮБзЗЅРЛ РЬЧиЧЯАэ Е№ЙіБзЧЯДТ ЕЅ ЛчПыЕШДй. trace ИІ РЬЧиЧЯБт РЇЧи, УпРћ И№ЕЈ (tracing model) РЬЖѓ КвИЎДТ Prolog ЧСЗЮБзЗЅРЧ ДйИЅ НЧЧр И№ЕЈРЛ МГИэЧЯДТ АЭРЬ АЁРх ССДй.
УпРћ И№ЕЈРК Гз АЁСі ЛчАЧРИЗЮ Prolog НЧЧрРЛ БтМњЧбДй. (1) call РК ИёРћРЛ ИИСЗНУХАЗСДТ НУЕЕ УЪБтПЁ ЙпЛ§ЧбДй. (2) exit ДТ ИёРћРЬ ИИСЗЕЧОњРЛ ЖЇ ЙпЛ§ЧбДй. (3) redo ДТ ИёРћРЛ Рч ИИСЗНУХГЗСАэ НУЕЕЧв ЖЇ ЙпЛ§ЧбДй. (4) fail РК ИёРћРЬ НЧЦаЕЧОњРЛ ЖЇ ЙпЛ§ЧбДй. ИИОр distance ПЭ ААРК ЧСЗЮММНКАЁ КЮЧСЗЮБзЗЅРИЗЮ Л§АЂЕШДйИщ call Ањ exit ДТ ИэЗЩЧќ О№ОюРЧ КЮЧСЗЮБзЗЅ НЧЧр И№ЕЈАњ СїСЂРћРИЗЮ АќЗУНУХГ Мі РжДй. ДйИЅ ЕЮ ЛчАЧРК ГэИЎ ЧСЗЮБзЗЁЙж НУНКХлПЁМИИ РЏРЯЧЯДй. ДйРН trace ПЙСІПЁМ, ИёРћРК redo ГЊ fail ЛчАЧРЛ ПфБИЧЯСі ОЪДТДй.
ДйРНРК Chevy_Distance ИІ РЇЧб АЊРЧ АшЛъ УпРћРЬДй.
trace.
distance (chevy, Chevy_Distance).
(1)
1 Call : distance (chevy, _0)?
(2) 2 Call : speed (chevy,
_5)?
(2) 2 Exit : speed (chevy, 105)
(3)
2 Call : time (chevy, _6)?
(3) 2 Exit : time (chevy, 21)
(4) 2 Call : _0 is 105 * 21?
(4) 2 Exit
: 2205 is 105 * 21
(1) 1 Exit : distance (chevy, 2205)
Chevy_distance = 2205
ЙиСй ЙЎРк (_) ЗЮ НУРлЧЯДТ УпРћ (trace) ПЁ РжДТ БтШЃДТ ЛчЗЪШЕШ АЊРЛ РњРхЧЯДТ ГЛКЮ КЏМіРЬДй. УпРћРЧ УЙ ПРК КЮЧеРЬ ЧіРч НУРлЕЧАэ РжДТ КЮИёРћРЛ АЁИЎХВДй. ПЙИІ ЕщИщ, РЇРЧ УпРћПЁМ ЧЅНУ (3) РЛ АЎДТ УЙ СйРК РгНУ КЏМі _6 ИІ chevy РЧ time АЊРИЗЮ ЛчЗЪШЧЯЗСДТ НУЕЕРЬДй. ПЉБтМ time РК distance РЧ АшЛъРЛ БтМњЧЯДТ ЙЎРхРЧ ПьКЏРЧ ЕЮЙјТА ЧзРЬДй. ЕЮЙјТА ПРК КЮЧе АњСЄРЧ ШЃУт БэРЬИІ ГЊХИГНДй. ММЙјТА ПРК ЧіРч ЕПРлРЛ ГЊХИГНДй.
ПЊЧрРЛ МГИэЧЯБт РЇЧи, ДйРН ПЙСІ ЕЅРЬХЭКЃРЬНКПЭ УпРћЕШ КЙЧе ИёРћРЛ Л§АЂЧиКИРк.
likes
(jake, chocolate).
likes (jake, apricots).
likes
(darcie, licorice).
likes (darcie, apricots).
trace.
likes (jake, X), likes (darcie, X).
(1)
1 Call : likes (jake, _0)?
(1) 1 Exit : likes (jake, chocolate)
(2) 1 Call : likes (darcie, chocolate)?
(2)
1 Fail : likes (darcie, chocolate)
(1) 1 Redo : likes
(jake, _0)?
(1) 1 Exit : likes (jake, apricots)
(3)
1 Call : likes (darcie, apricots)?
(3) 1 Exit : likes
(darcie, apricots)
X = apricots
Prolog АшЛъРЛ ДйРНАњ ААРЬ ЕЕЧЅЗЮ Л§АЂЧв Мі РжДй. АЂ ИёРћРЛ Гз АГРЧ ЦїЦЎ - call, fail, exit, redo - ИІ АЁСј ЛѓРкЗЮ Л§АЂЧи КИРк. СІОюАЁ РќСј ЙцЧтПЁМ call ЦїЦЎИІ ХыЧиМ ИёРћПЁ ЕщОюПТДй. ЖЧЧб СІОюДТ ЙнДы ЙцЧтРИЗЮ redo ЦїЦЎИІ ХыЧиМ ИёРћПЁ ЕщОюАЅ Мі РжДй. ИИОр ИёРћРЬ МКАјЧЯИщ, СІОюДТ exit ЦїЦЎИІ ХыЧиМ ЖАГДй. РЇРЧ ПЙСІ И№ЕЈРК БзИВ 1 ПЁ ГЊХИГЊ РжДй.
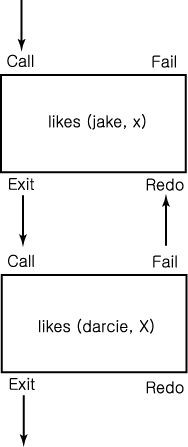
БзИВ 1 ИёРћ likes (jake, X) ПЭ likes (darcie, X) РЛ РЇЧб СІОю ШхИЇ И№ЕЈ
РЬ ПЙСІПЁМ, СІОю ШхИЇРК КЮИёРћРЛ ЕЮ Йј ХыАњЧбДй. ЕЮЙјТА КЮИёРћРК УГРНПЁ НЧЦаЧЯАэ, РЬАЭРК redo ИІ ХыЧиМ АСІЗЮ УЙ КЮИёРћРИЗЮ ЕЧЕЙЗС КИГНДй.
СіБнБюСі, ПьИЎАЁ ГэРЧЧб Prolog ЕЅРЬХЭ БИСЖДТ ЕЅРЬХЭ БИСЖКИДй Дѕ ЧдМі ШЃУтУГЗГ КИРЬДТ БтКЛ ИэСІРЬДй. ЖЧЧб БИСЖЖѓ КвИЎДТ БтКЛ ИэСІДТ НЧСІЗЮ ЗЙФкЕх ЧќНФРЬДй. СіПјЕЧДТ ДйИЅ БтКЛ ЕЅРЬХЭ БИСЖДТ LISP ПЁМ ЛчПыЕЧОњДј ИЎНКЦЎ БИСЖПЭ КёНСЧб ИЎНКЦЎРЬДй. ИЎНКЦЎДТ ИЙРК ПјМвРЧ ПЌМгРЬДй. ПЉБтМ ПјМвДТ ПјРк, БтКЛ ИэСІ ЖЧДТ ДйИЅ ИЎНКЦЎИІ ЦїЧдЧЯДТ ДйИЅ ЧзРЬДй.
Prolog ДТ ИЎНКЦЎИІ ИэНУЧЯБт РЇЧи РќХыРћ БИЙЎРЛ ЛчПыЧбДй. ИЎНКЦЎ ПјМвДТ ДйРНАњ ААРЬ ФоИЖПЁ РЧЧи КаИЎЕЧАэ, РќУМ ИЎНКЦЎДТ ЛчАЂ А§ШЃПЁ РЧЧи ЙќРЇАЁ СЄЧиСјДй.
[apple, prune, grape, kumquat]
ЧЅБтЙ§ [] ДТ Ај ИЎНКЦЎИІ ГЊХИГЛДТ ЕЅ ЛчПыЧбДй. ИЎНКЦЎИІ ИИЕщАХГЊ КаЧиЧЯДТ ИэНУРћРЮ ЧдМіИІ ЛчПыЧЯДТ ДыНХПЁ, Prolog ДТ АЃДмЧЯАд ЦЏКАЧб БтШЃИІ ЛчПыЧбДй. [X | Y] ДТ ЧьЕх X ПЭ ХзРЯ Y ИІ АЎДТ ИЎНКЦЎРЬДй. ПЉБтМ ЧьЕхПЭ ХзРЯРК LISP РЧ CAR, CDR ПЁ ДыРРЕШДй. РЬАЭРК Haskell ПЁМ ЛчПыЧЯДТ ЧЅБтЙ§Ањ РЏЛчЧЯДй.
ИЎНКЦЎДТ ДйРНАњ ААРЬ АЃДмЧб БИСЖИІ АЎАэ Л§МКЕШДй.
new_list ([apple, prune, grape, kumquat]).
РЬАЭРК ЛѓМі ИЎНКЦЎ [apple, prune, grape, kumquat] АЁ new_list (ЙцБн РлМКЧб РЬИЇ) ЖѓДТ РЬИЇРЛ АЎДТ АќАшРЧ ЛѕЗЮПю ПјМвЖѓИЅ АЭРЛ ГЊХИГНДй. РЬ ЙЎРхРК new_list ЖѓДТ РЬИЇРЛ АЎДТ КЏМіПЁ ИЎНКЦЎИІ ЙйРЮЕљЧЯСі ОЪДТДй. ПРШїЗС, БзАЭРК ДйРНАњ ААРК ИэСІ СпПЁ ЧЯГЊРЬДй.
male (jake)
Ся ИЛЧЯРкИщ, БзАЭРК [apple, prune, grape, kumquat] АЁ new_list РЧ ЛѕЗЮПю ПјМвЖѓДТ АЭРЛ ГЊХИГНДй. БзЗЏЙЧЗЮ, ПьИЎДТ ДйРНАњ ААРК ИЎНКЦЎ РЮРкИІ АЎДТ ЕЮЙјТА ИэСІИІ АЁСњ Мі РжДй.
new_list ([apricot, peach, pear])
СњРЧ И№ЕхПЁМ, new_list РЧ ПјМвДТ ДйРНАњ ААРЬ ЧьЕхПЭ ХзРЯЗЮ КаИЎЕЩ Мі РжДй.
new_list ([New_List_Head | New_List_Tail]).
ИИОр new_list АЁ РЇПЭ ААРЬ ЕЮ АГРЧ БИМК ПјМвИІ АЎЕЕЗЯ МГСЄЕЧОњДйИщ, РЬ ЙЎРхРК New_List_Tail ИІ ИЎНКЦЎРЧ ХзРЯ ([prune, grape, kumquat]) ЗЮ ЛчЗЪШЧбДй. ИИОр РЬАЭРЬ КЙЧе ИёРћРЧ КЮКаРЬАэ, ПЊЧрРЬ РЬАЭРЧ ЛѕЗЮПю ЦђАЁИІ АПфЧпДйИщ, [apricot, peach, pear] РЬ new_list РЧ ДйРН ПјМвРЬБт ЖЇЙЎПЁ New_List_Head ПЭ New_List_Tail РК АЂАЂ apricot ПЭ [peach, pear] ПЁ ЛчЗЪШЕШДй.
ИЎНКЦЎИІ КаЧиЧЯДТ ЕЅ ЛчПыЕШ ЧЅБтЙ§РК СжОюСј ЛчЗЪШЕШ ЧьЕхПЭ ХзРЯ ПјМвИІ ДйРНАњ ААРЬ ИЎНКЦЎИІ Л§МКЧЯДТ ЕЅ ЛчПыЕЩ Мі РжДй.
[Element_1 | List_2]
ИИОр Element_1 РЬ pickle ПЁ ЛчЗЪШЕЧАэ, List_2 АЁ [peanut, prune, popcorn] ПЁ ЛчЗЪШЕЧОњДйИщ, РЇПЭ ААРК ЧЅБтЙ§РК ИЎНКЦЎ [pickle, peanut, prune, popcorn] РЛ Л§МКЧбДй.
РЇПЁМ БтМњЕШ АЭУГЗГ, | БтШЃИІ ЦїЧдЧЯДТ ИЎНКЦЎ ЧЅБтЙ§РК КИЦэРћРЬДй. БзАЭРК ИЎНКЦЎ Л§МКРЬГЊ ИЎНКЦЎ КаЧиИІ ИэНУЧв Мі РжДй. ДйРНАњ ААРК ПЙСІДТ И№ЕЮ ЕПРЯЧЯДйДТ АЭПЁ РЏРЧЧиЖѓ.
[apricot,
peach, pear | []]
[apricot, peach | [pear]]
[apricot,
| [peach, pear]]
ИЎНКЦЎИІ ДйЗъ ЖЇ, LISP ПЁМ ЙпАпЕЧДТ АЭАњ ААРК ОюЖВ БтКЛ ПЌЛъРЬ СОСО ПфБИЧбДй. Prolog ПЁМ РЬЗЏЧб ПЌЛъРЧ ПЙСІЗЮМ, ПьИЎДТ LISP РЧ append ЧдМіПЭ АќЗУРЬ РжДТ append РЧ СЄРЧИІ ЛьЦьКЛДй. РЬ ПЙСІПЁМ, ЧдМіЧќ О№ОюПЭ МБО№Рћ О№ОюРЧ ТїРЬСЁАњ РЏЛчСЁРЛ КМ Мі РжДй. Prolog АЁ СжОюСј ИЎНКЦЎЗЮКЮХЭ ЛѕЗЮПю ИЎНКЦЎИІ Л§МКЧЯДТ ЙцЙ§ПЁ ДыЧи БтМњЧв ЧЪПфАЁ ОјДй. ПРШїЗС, ПьИЎДТ СжОюСј ИЎНКЦЎЗЮМ ЛѕЗЮПю ИЎНКЦЎРЧ ЦЏМКРЛ БтМњЧЯДТ АЭРЬ ЧЪПфЧЯДй.
ПмАќРћРИЗЮ, Prolog append СЄРЧДТ LISP append СЄРЧПЭ ИХПь РЏЛчЧЯАэ, Чи ЕЕУтПЁМ РчБЭДТ ЛѕЗЮПю ИЎНКЦЎИІ Л§МКЧЯБт РЇЧб РЏЛчЧб ЙцЙ§РИЗЮ ЛчПыЕШДй. Prolog РЧ АцПь, РчБЭДТ Чи ЕЕУт АњСЄПЁ РЧЧиМ ЙпЛ§ЕЧАэ СІОюЕШДй.
append
([], List, List)
append ([Head | List_1], List_2, [Head
| List_3]) :- append (List_1, List_2, List_3).
УЙ ИэСІДТ Ај ИЎНКЦЎАЁ ДйИЅ ИЎНКЦЎПЁ УЗАЁЕЩ ЖЇ, ДйИЅ ИЎНКЦЎАЁ АсАњЖѓДТ АЭРЛ ГЊХИГНДй. РЬ ЙЎРхРК LISP append ЧдМіРЧ РчБЭ-СОАс ДмАшПЁ ЧиДчЕШДй. СОАс ИэСІДТ РчБЭ ИэСІ РќПЁ РЇФЁЧбДйДТ АЭПЁ РЏРЧЧЯЖѓ. Prolog ДТ УГРНКЮХЭ НУРлЧЯПЉ МјМДыЗЮ (БэРЬ ПьМБ ХНЛіРЛ ЛчПыЧЯБт ЖЇЙЎПЁ) ЕЮ ИэСІПЁ КЮЧеЕШДйДТ АЭРЛ ОЫАэ РжБт ЖЇЙЎПЁ, РЬАЭРК МіЧрЕШДй.
ЕЮЙјТА ИэСІДТ ЛѕЗЮПю ИЎНКЦЎРЧ ПЉЗЏ АЁСі ЦЏМКРЛ ИэНУЧбДй. БзАЭРК LISP ЧдМіРЧ РчБЭ ДмАшПЁ ЧиДчЕШДй. СТКЏРЧ МњОюДТ ЛѕЗЮПю ИЎНКЦЎРЧ УЙ ПјМвАЁ УГРН СжОюСј ИЎНКЦЎРЧ УЙ ПјМвПЭ ЕПРЯЧЯДйДТ АЭРЛ ГЊХИГНДй. ПжГФЧЯИщ БзЕщРК Head ЖѓДТ РЬИЇРЛ АЎБт ЖЇЙЎРЬДй. Head АЁ АЊРИЗЮ ЛчЗЪШЕЩ ЖЇИЖДй, ИёРћПЁ РжДТ И№Еч Head ДТ, ЛчНЧЛѓ, ЕПНУПЁ Бз АЊРИЗЮ ЛчЗЪШЕШДй. ЕЮЙјТА ЙЎРхРЧ ПьКЏРК УЙЙјТА СжОюСј ИЎНКЦЎРЧ ХзРЯ (List_1) РК ЕЮЙјТА СжОюСј ИЎНКЦЎ (List_2) ИІ УЙЙјТА СжОюСј ИЎНКЦЎРЧ ХзРЯПЁ УЗАЁЧЯПЉ АсАњ ИЎНКЦЎРЧ ХзРЯ (List_3) РЛ ЧќМКЧЯЖѓАэ СіСЄЧбДй.
append РЧ ЕЮЙјТА ЙЎРхРЛ РаДТ ЙцЙ§РК ДйРНАњ ААДй. ИЎНКЦЎ [Head | List_1] ИІ List_2 ПЁ УЗАЁЧЯПЉ ИЎНКЦЎ [Head | List_3] РЛ Л§МКЧЯСіИИ, List_3 РК List_1 РЛ List_2 РЛ УЗАЁЧдРИЗЮНс ЧќМКЕШДй. LISP ПЁМ РЬАЭРЛ ДйРНАњ ААРЬ ОЕ Мі РжДй.
(CONS (CAR FIRST) (APPEND (CDR FIRST) SECOND))
Prolog ПЭ LISP append ПЁМ АсАњ ИЎНКЦЎДТ РчБЭАЁ СОЗс СЖАЧРЛ Л§ЛъЧв ЖЇБюСі ИИЕщОюСіСі ОЪДТДй. РЬ АцПьПЁ, УЙ ИЎНКЦЎДТ ЙнЕхНУ Ај ИЎНКЦЎРЬДй. БзЗБ ШФПЁ, АсАњ ИЎНКЦЎАЁ append ЧдМіИІ ЛчПыЧиМ ИИЕщОюСјДй. УЙ ИЎНКЦЎПЁМ УыЧиСј ПјМвДТ ПЊМјРИЗЮ ЕЮЙјТА ИЎНКЦЎПЁ УЗАЁЕШДй. ПЊМјРК РчБЭИІ ЧиАсЧдРИЗЮНс ПЯМКЕШДй.
ОюЖЛАд append АњСЄРЬ СјЧрЕЧДТАЁИІ МГИэЧЯБт РЇЧи, ДйРНРЧ УпРћЕШ ПЙСІИІ Л§АЂЧи КИРк.
trace.
append ([bob, jo], [jake, darcie], family).
(1)
1 Call : append ([bob, jo], [jake, darcie], _10)?
(2)
2 Call : append ([jo], [jake, darcie], _18)?
(3) 3 Call
: append ([], [jake, darcie], _25)?
(3) 3 Exit : append
([], [jake, darcie], [jake, darcie])
(2) 2 Exit : append
([jo], [jake, darcie], [jo, jake, darcie])
(1) 1 Exit
: append ([bob, jo], [jake, darcie], [bob, jo, jake, darcie])
Family
= [bob, jo, jake, darcie]
yes
КЮИёРћРЛ ЧЅЧіЧЯДТ УЙ ЕЮ АГРЧ call РК Ај ИЎНКЦЎАЁ ОЦДб List_1 РЛ АЎДТДй. БзЗЁМ ЕЮЙјТА ЙЎРхРЧ ПьКЏРИЗЮКЮХЭ РчБЭ ШЃУтРЛ Л§МКЧбДй. ЕЮЙјТА ЙЎРхРЧ СТКЏРК ШПАњРћРИЗЮ РчБЭ ШЃУт Ся ИёРћРЛ РЇЧб РЮРкИІ ИэНУЧбДй. БзЗЏЙЧЗЮ УЙЙјТА ИЎНКЦЎДТ АЂ ДмАш Дч ЧЯГЊРЧ ПјМвИІ КаИЎНУХВДй. УЙЙјТА ИЎНКЦЎАЁ ШЃУт Ся КЮИёРћПЁМ Ај ИЎНКЦЎРЯ ЖЇ, ЕЮЙјТА ЙЎРхРЧ ПьКЏРЧ РЮНКХЯНКДТ УЙЙјТА ЙЎРхПЁ КЮЧеЧдРИЗЮНс МКАјЧбДй. РЬАЭРЧ ШПАњДТ ММЙјТА ИХАГКЏМіЗЮМ ЕЮЙјТА ПјЗЁ ИХАГКЏМі ИЎНКЦЎПЁ УЗАЁЕШ Ај ИЎНКЦЎРЧ АЊРЛ ЙнШЏЧЯДТ АЭРЬДй. МКАјРћРЮ КЮЧеРЛ ЧЅЧіЧЯДТ ПЌМгРћРЮ exit ПЁМ УЙ ИЎНКЦЎЗЮКЮХЭ СІАХЕШ ПјМвДТ АсАњ ИЎНКЦЎ - Family - ПЁ УЗАЁЕШДй. УЙ ИёРћРЧ exit АЁ НЧЧрЕЩ ЖЇ, Бз АњСЄРК ПЯМКЕЧАэ, АсАњ ИЎНКЦЎАЁ ЧЅНУЕШДй.
append ИэСІДТ ДйРНАњ ААРК ДйИЅ ИЎНКЦЎ ПЌЛъРЛ Л§МКЧЯДТ ЕЅ ЛчПыЕЩ Мі РжДй. РЬ ПЌЛъРЧ АсАњИІ ПЉЗЏКаЕщРЬ АсСЄЧЯБт ЙйЖѕДй. list_op_2 ДТ УЙ ИХАГКЏМіЗЮ ИЎНКЦЎИІ, ЕЮЙјТА ИХАГКЏМіЗЮ КЏМіИІ СІАјЧЯАэ, list_op_2 РЧ АсАњДТ ЕЮЙјТА ИХАГКЏМіАЁ ЛчЗЪШЕШ АЊРгПЁ РЏРЧЧЯЖѓ.
list_op_2
([], []).
list_op_2 ([Head | Tail], List) :- List_op_2
(Tail, Result), append (Result, [Head], List).
ЕЖРкАЁ АсСЄЧв Мі РжДТ АЭУГЗГ, list_op_2 ДТ Prolog НУНКХлПЁАд ЕЮЙјТА ИХАГКЏМіИІ УЙЙјТА ИХАГКЏМіРЧ ИЎНКЦЎ ПјМвИІ ПЊМјРИЗЮ АЎДТ ИЎНКЦЎЗЮ ЛчЗЪШНУХААд ЧбДй. ПЙИІ ЕщИщ, ([apple, orange, grape], Q) ДТ Q ИІ ИЎНКЦЎ [grape, orange, apple] ЗЮ ЛчЗЪШЧбДй.
ДйНУ ЧбЙј, КёЗЯ LISP РЧ Prolog О№ОюАЁ КЛСњРћРИЗЮ ДйИЃДйАэ ЧвСіЖѓЕЕ, РЏЛчЧб ПЌЛъРК РЏЛчЧб СЂБй ЙцЙ§РЛ ЛчПыЧв Мі РжДй. ПЊ ИЎНКЦЎ ПЌЛъРЧ АцПьПЁ, Prolog РЧ list_op_2 ПЭ LISP РЧ reverse ЧдМіДТ РчБЭ СОЗс СЖАЧАњ АсАњ ИЎНКЦЎИІ Л§МКЧЯБт РЇЧЯПЉ ИЎНКЦЎРЧ CDR (Ся ХзРЯ) РЧ ПЊ ИЎНКЦЎИІ ИЎНКЦЎРЧ CAR (Ся ЧьЕх) ПЁ УЗАЁНУХАДТ БтКЛ АњСЄРЛ ЦїЧдЧбДй.
ДйРНРК reverse Жѓ РЬИЇ КйПЉСј РЬ АњСЄ УпРћРЬДй.
trace.
reverse ([a, b, c], Q).
(1)
1 Call : reverse ([a, b, c], _6)?
(2) 2 Call : reverse
([b, c], _65636)?
(3) 3 Call : reverse ([c], _65646)?
(4) 4 Call : reverse ([ ], _65656)?
(4)
4 Exit : reverse ([ ], [ ])
(5) 4 Call : append ([ ],
[c], _65646)?
(5) 4 Exit : append ([ ], [c], [c])
(3) 3 Exit : reverse ([c], [c])
(6)
3 Call : append ([c], [b], _65636)?
(7) 4 Call : append
([ ], [b], _25)?
(7) 4 Exit : append ([ ], [b], [b])
(6) 3 Exit : append ([c], [b], [c, b])
(2)
2 Exit : reverse ([b, c], [c, b])
(8) 2 Call : append
([c, b], [a], _6)?
(9) 3 Call : append ([b], [a], _32)?
(10) 4 Call : append ([ ], [a], _39)?
(10)
4 Exit : append ([ ], [a], [a])
(9) 3 Exit : append ([b],
[a], [b, a])
(8) 2 Exit : append ([c, b], [a], [c, b,
a])
(1) 1 eXIT :REVERSE ([A, B, C], [C, B, A])
Q = [c, b, a]
СжОюСј БтШЃАЁ СжОюСј ИЎНКЦЎПЁ РжДТСіИІ АсСЄЧЯДТ АЭРЬ ЧЪПфЧЯДйАэ АЁСЄЧЯРк. СїМГРћРЮ Prolog ЧЅЧіРК ДйРНАњ ААДй.
member
(Element, [Element | _]).
member (Element, [_ | List])
:- member (Element, List).
ЙиСй ЙЎРкДТ РЭИэ КЏМіИІ ГЊХИГЛАэ, БзАЭРК ДмРЯШЗЮКЮХЭ ОђОюСіДТ ЛчЗЪШПЁ АќНЩРЬ ОјДйДТ АЭРЛ РЧЙЬЧЯДТ ЕЅ ЛчПыЕШДй. ИИОр УГРНКЮХЭ ЖЧДТ ЕЮ ЙјТА ЙЎРхРЛ ХыАњЧЯПЉ ПЉЗЏ РчБЭАЁ РжРК ШФПЁ Element АЁ ИЎНКЦЎРЧ ЧьЕхРЬИщ, РЇРЧ УЙЙЎРхРК МКАјЧбДй. ИИОр Element АЁ ИЎНКЦЎРЧ ХзРЯ СпПЁ ЧЯГЊИщ, ЕЮ ЙјТА ЙЎРхРК МКАјЧбДй. ДйРН УпРћЕШ ПЙСІИІ Л§АЂЧиКИРк.
trace.
member (a, [b, c, d] ).
(1) 1 Call :
member (a, [b, c, d])?
(2) 2 Call : member (a, [c, d])?
(3) 3 Call : member (a, [d])?
(4) 4
Call : member (a, [ ])?
(4) 4 Fail : member (a, [ ])
(3) 3 Fail : member (a, [d])
(2) 2 Fail
: member (a, [c, d])
(1) 1 Fail : member (a, [b, c, d])
no
member
(a, [b, a, c]).
(1) 1 Call : member (a, [b, a, c])?
(2) 2 Call : member (a, [a, c])?
(2)
2 Exit : member (a, [a, c])
(1) 1 Exit : member (a, [b,
a, c])
yes
ГэИЎ ЧСЗЮБзЗЁЙж О№ОюЗЮМ Prolog ИІ ЛчПыЧв ЖЇ ПЉЗЏ АЁСі ЙЎСІАЁ ЙпЛ§ЧбДй. КёЗЯ БзАЭРЬ РЏПыЧб ЕЕБИРЯСіЖѓЕЕ, БзАЭРК МјМіЧЯАХГЊ ПЯРќЧб ГэИЎ ЧСЗЮБзЗЁЙж О№ОюАЁ ОЦДЯДй.
ШПРВРћРЮ РЬРЏЗЮ, Prolog ДТ ЛчПыРкАЁ Чи ЕЕУтРЛ МіЧрЧЯДТ ЕПОШПЁ ЦаХЯ ИХФЊРЧ МјМИІ СІОюЧЯДТ АЭРЛ ЧуПыЧбДй. МјМі ГэИЎ ЧСЗЮБзЗЁЙж ШЏАцПЁМДТ, Чи ЕЕУт ЕПОШПЁ ЙпЛ§Чб НУЕЕЕШ КЮЧеРЧ МјМДТ КёАсСЄРћРЬАэ И№Еч КЮЧеРК КДЗФРћРИЗЮ НУЕЕЕЩ Мі РжДй. БзЗЏГЊ Prolog ДТ ЧзЛѓ ЕЅРЬХЭКЃРЬНКРЧ УГРНАњ СжОюСј ИёРћРЧ ПоТЪ ГЁПЁМ НУРлЧЯДТ ЕПРЯЧб МјМЗЮ КЮЧеЕЧБт ЖЇЙЎПЁ, ЛчПыРкДТ ЦЏКАЧб РРПыРЛ УжРћШЧЯБт РЇЧи ЕЅРЬХЭКЃРЬНК ЙЎРхРЛ СЄЕЗЧдРИЗЮНс НЩПРЧЯАд ШПРВМКПЁ ПЕЧтРЛ ЙЬФЅ Мі РжДй. ПЙИІ ЕщИщ, ИИОр ЛчПыРкАЁ ЦЏКАЧб НЧЧр ЕПОШПЁ ОюЖВ БдФЂРЬ ДйИЅ БдФЂКИДй ДѕПэ МКАјЧв АЭ ААДйДТ СіНФРЛ АЁСіАэ РжДйИщ, БзЗБ БдФЂРЛ ЕЅРЬХЭКЃРЬНКРЧ УГРНПЁ РЇФЁЧЯАд ЧЯПЉ ЧСЗЮБзЗЅРЛ ДѕПэ ШПРВРћРИЗЮ ИИЕщ Мі РжДй.
ДРИА ЧСЗЮБзЗЅ НЧЧрРЬ Prolog ЧСЗЮБзЗЅПЁМ ЛчПыРк-СЄРЧ МјМРЧ КЮСЄРћРЮ АсАњИИРК ОЦДЯДй. ЙЋЧб ЗчЧС ЕћЖѓМ Рќ ЧСЗЮБзЗЅ НЧЦаИІ ЙпЛ§НУХАДТ ЧќНФРИЗЮ ЙЎРхРЛ РлМКЧЯБтДТ ИХПь НБДй. ПЙИІ ЕщИщ, ДйРН РчБЭ ЙЎРх ЧќНФРЛ АэЗСЧиКИРк.
f (x, y) :- f (z, Y), g (X, z).
Prolog РЧ СТПь (left-to-right) БэРЬ-ПьМБ ЦђАЁ МјМ ЖЇЙЎПЁ, ЙЎРх ИёРћПЁ АќАшОјРЬ, РЬАЭРК ЙЋЧб ЗчЧСИІ ЙпЛ§НУХВДй. РЬЗБ СОЗљРЧ ЙЎРхРЧ ПЙЗЮМ ДйРНРЛ Л§АЂЧиКИРк.
ancestor
(X, X).
ancestor (X, Y) :- ancestor (Z, Y), parent (X,
Z).
ЕЮ ЙјТА ИэСІРЧ ПьКЏРЧ УЙ КЮИёРћРЛ ИИСЗНУХАБт РЇЧб НУЕЕПЁМ, Prolog ДТ ancestor ИІ ТќРИЗЮ ЧЯБт РЇЧи Z ИІ ЛчЗЪШЧбДй. БзЗБ ШФ, РЬ Лѕ КЮИёРћРЛ ИИСЗНУХАЗСАэ НУЕЕЧбДй. Ся ancestor РЧ СЄРЧЗЮ ЕЙОЦАЁМ ААРК АњСЄРЛ ЙнКЙЧЯПЉ, АсБЙ ЙЋЧб РчБЭПЁ РЬИЅДй.
РЬ ЦЏКАЧб ЙЎСІДТ 3 РхПЁМ ГэРЧЕШ АЭУГЗГ, ЙЎЙ§ БдФЂПЁМ ПоТЪ РчБЭИІ АЎДТ РчБЭ ЧЯЧт ЦФМАЁ АЎДТ ЙЎСІПЭ ЕПРЯЧЯДй. ЦФНЬРЧ ЙЎЙ§ БдФЂУГЗГ, РЇ ИэСІРЧ ПьКЏПЁМ АЃДмЧЯАд ЧзРЧ МјМИІ ЙйВйИщ Бз ЙЎСІДТ СІАХЕШДй. РЬАЭРЧ ЙЎСІДТ Чз МјМРЧ АЃДмЧб КЏШЏРЬ ЧСЗЮБзЗЅ СЄШЎМКПЁ АсСЄРћРЬ ЕЧОюМДТ ОШЕШДйДТ АЭРЬДй. ЙЋОљКИДйЕЕ, СІОю МјМПЁ ДыЧи ЧСЗЮБзЗЁИгАЁ АЦСЄЧв ЧЪПфАЁ ОјДйДТ АЭРЬ ОЦИЖЕЕ ГэИЎ ЧСЗЮБзЗЁЙжРЧ РхСЁ СпПЁ ЧЯГЊРЯ АЭРЬДй.
ЛчПыРкПЁАд ЕЅРЬХЭКЃРЬНКПЭ КЮИёРћ МјМ СІОюИІ ЧуПыЧЯДТ АЭ РЬПмПЁЕЕ, ШПРВМКРЛ РЇЧиМ, Prolog ДТ ПЊЧрРЧ ИэНУРћРЮ СІОюИІ ЧуПыЧбДй. РЬАЭРК cut ПЌЛъРкЗЮ МіЧрЕЧАэ, АЈХКЛч (!) ЗЮ ЧЅНУЕШДй. cut ПЌЛъРкДТ ПЌЛъРкАЁ ОЦДЯЖѓ НЧСІЗЮ ИёРћРЬДй. ИёРћРИЗЮМ, cut РК ЧзЛѓ СяНУ МКАјЧЯСіИИ, ПЊЧрРЛ ХыЧиМ Рч ИИСЗНУХГ Мі РжДй. cut РЧ КЮРлПыРК КЙЧе ИёРћПЁМ cut РЧ ПоТЪ КЮИёРћРК ПЊЧрРЛ ХыЧиМ Рч ИИСЗНУХГ Мі ОјДйДТ АЭРЬДй. ПЙЗЮ ЕщИщ, ДйРНАњ ААРК ИёРћПЁМ,
a, b, !, c, d.
ИИОр a, b АЁ МКАјЧЯАэ, c АЁ НЧЦаЧЯИщ, РќУМ ИёРћРК НЧЦаЧбДй. c АЁ НЧЦаЧв ЖЇИЖДй, b ГЊ a ИІ Рч ИИСЗНУХАДТ АЭРЬ НУАЃ ГЖКёЖѓДТ АЭРЬ ОЫЗССГДйИщ, РЬ ИёРћРЬ ЛчПыЕЩ АЭРЬДй.
cut РЧ ИёРћРК ПЯРќЧб СѕИэРЛ Чв Мі ОјДТ КЮИёРћРЛ Рч ИИСЗНУХАЗСДТ НУЕЕИІ ЧЯСі ОЪРЛ НУСЁРЛ НУНКХлПЁАд ИЛЧЯАд ЧдРИЗЮНс ЛчПыРкАЁ ЧСЗЮБзЗЅРЛ ДѕПэ ШПРВРћРИЗЮ ИИЕхДТ АЭРЛ ЧуПыЧЯДТ АЭРЬДй.
cut ПЌЛъРкРЧ ЛчПы ПЙЗЮМ, 6.7 Р§РЧ member ЧдМіИІ Л§АЂЧи КИРк.
member
(Element, [Elemtne | _]).
member (Element, [_ | List])
:- member (Element, List).
ИИОр member РЧ ИЎНКЦЎ ИХАГКЏМіАЁ С§ЧеРЛ ГЊХИГЛИщ, БзАЭРК ДмСі ЧбЙјИИ ИИСЗЕЩ Мі РжДй (С§ЧеРК СпКЙЕШ ПјМвИІ АЎСі ОЪДТДй). БзЗЏЙЧЗЮ, ИИОр member АЁ ДйСп КЮИёРћРИЗЮ БИМКЕШ ИёРћ ЙЎРхРЧ КЮИёРћРИЗЮМ ЛчПыЕШДйИщ, ЙЎСІАЁ ЕЩ Мі РжДй. ЙЎСІДТ ИИОр member ДТ МКАјЧЯСіИИ ДйРН КЮИёРћРЬ НЧЦаЧбДйИщ, ПЊЧрРЬ Рќ КЮЧеРЛ АшМгЧдРИЗЮНс member ИІ РчИИСЗНУХАЗСАэ Чв АЭРЬДй. БзЗЏГЊ Рќ КЮЧеРЛ АшМгЧдРИЗЮНс member ИІ РчИИСЗНУХАЗСАэ Чв АЭРЬДй. БзЗЏГЊ member РЧ ИЎНКЦЎ ИХАГКЏМіДТ УГРНКЮХЭ Бз ПјМвДТ ЧЯГЊИИ АЁСіБт ЖЇЙЎПЁ, member ДТ ДйНУ МКАјЧв Мі ОјДй. member ИІ РчИИСЗНУХАЗСДТ КЮАЁРћРЮ НУЕЕПЁЕЕ КвБИЧЯАэ АсБЙРК РќУМ ИёРћРЬ НЧЦаЧЯАд ЕШДй. РЬЗБ КёШПРВМКПЁ ДыЧб ЧиАсУЅРК member СЄРЧРЧ УЙ ЙЎРх ПьКЏПЁ ДйРНАњ ААРЬ Дм ЧЯГЊРЧ ПјМвЗЮ cut ПЌЛъРкИІ УЗАЁНУХАДТ АЭРЬДй.
member (Element, [Element | _]) :- !.
ПЊЧрРК member ИІ Рч ИИСЗНУХАЗСАэ НУЕЕЧЯСі ОЪАэ, ДыНХ РќУМ КЮИёРћРЛ НЧЦаЧЯАд ЧбДй.
cut РК Prolog ПЁМ Л§МК-АЫЛч (generate and test) Жѓ КвИЎДТ ЧСЗЮБзЗЁЙж ЙцЙ§ПЁ ЦЏКАШї РЏПыЧЯДй. РЬЗБ ЧСЗЮБзЗЅПЁМ, ИёРћРК РсРчРћРЮ ЧиАсУЅРЛ Л§МКЧЯДТ КЮИёРћРИЗЮ БИМКЕШДй. РЬ РсРчРћРЮ ЧиАсУЅРК ГЊСп test КЮИёРћПЁ РЧЧиМ АЫЛчЕШДй. АХКЮЕШ РсРчРћРЮ ЧиАсУЅРК ЛѕЗЮПю РсРчРћРЮ ЧиАсУЅРЛ Л§МКЧЯДТ Л§МКРк КЮИёРћПЁ ПЊЧрРЛ ПфБИЧбДй. Л§МК-АЫЛч ЧСЗЮБзЗЅРЧ ПЙСІЗЮМ, Clocksin Ањ Mellish (1984) АЁ РњМњЧб УЅПЁ ГЊПРДТ ДйРН ПЙСІИІ Л§АЂЧи КИРк.
divide
(N1, N2, Result) :- is_integer (Result),
Product1
is Result * N2,
Product2
is (Result + 1) * N2,
Product1
=< N1, Product2 > N1, !.
РЬ ЧСЗЮБзЗЅРК ЧеАњ АіРЛ РЬПыЧиМ СЄМі ГЊДЉБтИІ НЧЧрЧбДй. ДыКЮКаРЧ Prolog НУНКХлРК ПЌЛъРкЗЮМ ГЊДЉМРРЛ СІАјЧЯБт ЖЇЙЎПЁ, АЃДмЧб Л§МК-АЫЛч ЧСЗЮБзЗЅРЛ МГИэЧЯДТ АЭ ПмПЁДТ РЬ ЧСЗЮБзЗЅРК НЧСІЗЮ РЏПыЧЯСі ОЪДй.
МњОю is_integer ДТ ИХАГКЏМіАЁ РНРЬ ОЦДб СЄМіПЁ ЛчЗЪШЕЧДТ Чб МКАјЧбДй. ИИОр ИХАГКЏМіАЁ ЛчЗЪШЕЧСі ОЪОвДйИщ, is_integer ДТ ИХАГКЏМіИІ ДйРН СЄМі АЊРИЗЮ ЛчЗЪШЧбДй.
БзЗЏЙЧЗЮ, divide ПЁМ is_integer ДТ Л§МКРк КЮИёРћРЬДй. БзАЭРК ИИСЗЕЩ ЖЇИЖДй ЧЯГЊОП, МіП 0, 1, 2, ..., РЧ ПјМвИІ Л§МКЧбДй. И№Еч ДйИЅ АЭРК АЫЛч КЮИёРћРЬДй. БзЕщРК is_integer ПЁ РЧЧи Л§МКЕШ АЊРЬ, НЧСІЗЮ, УЙ ЕЮ ИХАГКЏМі N1 Ањ N2 РЧ ИђРЮАЁИІ АсСЄЧЯБт РЇЧи АЫЛчЧбДй. ИЖСіИЗ КЮИёРћРИЗЮМ cut РЧ ПыЕЕДТ АЃДмЧЯДй. РЯДм ЧиАЁ ЙпАпЕЧИщ divide АЁ ДйИЅ ЧиИІ УЃРЛЗСДТ НУЕЕИІ ИЗДТДй. is_integer АЁ АХДыЧб ШФКИ МіИІ Л§МКЧв СіЖѓЕЕ, ЧЯГЊИИРЬ ЧиРЬДй. БзЗЁМ ПЉБтМРЧ cut РК ЕЮ ЙјТА ЧиИІ Л§МКЧвЗСДТ ОЕИ№ ОјДТ НУЕЕИІ ИЗДТДй.
cut ПЌЛъРкРЧ ЛчПыРК ИэЗЩЧќ О№ОюРЧ goto ЛчПыАњ КёБГЕЧОњДй (Van Emden, 1980). КёЗЯ БзАЭРЬ ЖЇЖЇЗЮ ЧЪПфЧвСіЖѓЕЕ, cut ИІ ГВПыЧЯДТ АЭЕЕ АЁДЩЧЯДй. НЧСІЗЮ, БзАЭРК ЖЇЖЇЗЮ ИэЗЩЧќ О№Ою НКХИРЯЗЮКЮХЭ ПЕАЈРЛ ЙоРК СІОю ШхИЇРЛ АЎДТ ГэИЎ ЧСЗЮБзЗЅРЛ ИИЕщБт РЇЧи ЛчПыЕШДй.
Prolog ЧСЗЮБзЗЅПЁМ СІОю ШхИЇРЛ АэФЅ Мі РжДТ ДЩЗТРК АсСЁРЬДй. ПжГФЧЯИщ БзАЭРК ГэИЎ ЧСЗЮБзЗЁЙжРЧ СпПфЧб РхСЁ СпПЁ ЧЯГЊ - ЧСЗЮБзЗЅРК ЧиАЁ ЙпАпЕЧДТ ЙцЙ§РЛ ИэБтЧЯСі ОЪДТДй - ПЁ ЧиЗгБт ЖЇЙЎРЬДй. ПРШїЗС, БзЕщРК АЃДмЧЯАд ЧиАсУЅРЧ ЧќХТИІ ИэБтЧбДй. РЬАЭРК ЧСЗЮБзЗЅРЛ ИИЕщБт НБАэ, РаБт НБАд ЧбДй. ЧСЗЮБзЗЅРК ЧиАсУЅРЬ АсСЄЕЧДТ ЙцЙ§РЧ ММКЮ ЛчЧзАњ, ЦЏШї, ЧиАсУЅРЛ Л§МКЧЯБт РЇЧи АшЛъРЬ МіЧрЕЧДТ СЄШЎЧб МјМЗЮ РЮЧи КЙРтЧЯАд ЕЧСі ОЪДТДй. ЕћЖѓМ, ГэИЎ ЧСЗЮБзЗЁЙжРЬ СІОю ШхИЇ ЙцЧтРЛ ПфБИЧЯСі ОЪСіИИ, СжЗЮ ШПРВРЛ РЇЧиМ, Prolog ЧСЗЮБзЗЅРК СІОюШхИЇРЛ РкСж ЛчПыЧбДй.
Prolog Чи ЕЕУтРЧ ЦЏМКРК ЖЇЖЇЗЮ РпИјЕШ АсАњИІ Л§МКЧбДй. Prolog ПЁ АќЧб Чб СјИЎДТ Prolog РЧ ЕЅРЬХЭКЃРЬНКИІ ЛчПыЧЯПЉ СѕИэЕШ СјИЎДй. Prolog ДТ ЕЅРЬХЭКЃРЬНК РЬПмПЁ НЧММАшРЧ СіНФРК ОјДй. ЕЅРЬХЭКЃРЬНКПЁ УцКаЧб СЄКИАЁ ОјДТ СњРЧДТ Р§ДыРћРИЗЮ АХСўРЬЖѓАэ АЁСЄЧбДй. Prolog ДТ СжОюСј ИёРћРЬ ТќРЮ АЭРЛ СѕИэЧв Мі РжСіИИ, СжОюСј ИёРћРЬ АХСўРЮ АЭРЛ СѕИэЧв Мі ОјДй. Prolog ДТ ИёРћРЬ ТќРЬЖѓАэ СѕИэЧв Мі ОјБт ЖЇЙЎПЁ ИёРћРЬ АХСўРгПЁ ЦВИВОјДйАэ АЃДмЧЯАд АЁСЄЧбДй. КЛСњРћРИЗЮ, Prolog ДТ Тќ/АХСў НУНКХлРЬ ОЦДЯЖѓ Тќ/НЧЦа НУНКХлРЬДй.
НЧСІРћРИЗЮ ДнШљ ММАш АЁСЄ (closed world assumption) РК ПЉЗЏКаПЁАд РќЧє ГИМБ АЭРК ОЦДЯДй. ПьИЎРЧ ЛчЙ§ НУНКХлЕЕ ЕПРЯЧЯАд ЕПРлЧбДй. ПыРЧРкДТ РЏСЫЗЮ СѕИэЕЩ ЖЇБюСі ЙЋСЫРЬДй. БзЕщРК ЙЋСЫЖѓАэ СѕИэЧв ЧЪПфАЁ ОјДй. ИИОр РчЦЧРЬ ОюЖВ ЛчЖїРЬ РЏСЫЖѓАэ СѕИэЧЯСі ИјЧЯИщ, ПыРЧРкДТ ЙЋСЫЗЮ РЮСЄЕШДй.
ДнШљ ММАш АЁСЄРЧ ЙЎСІСЁРК ДйРНР§ПЁМ ГэРЧЧв КЮСЄ ЙЎСІПЭ АќЗУЕЧОю РжДй.
Prolog РЧ ДйИЅ ЙЎСІДТ КЮСЄРЧ ОюЗСПђРЬДй. ЕЮ АГРЧ ЛчНЧАњ ЧЯГЊРЧ АќАшЗЮ БИМКЕШ ДйРН ЕЅРЬХЭКЃРЬНКИІ ЛьЦьКИРк.
parent
(bill, jake).
parent (bill, shelley).
sibling
(X, Y) :- parent (M, X), parent (M, Y).
РЬСІ, ДйРН СњРЧАЁ СжОюСГДйАэ АЁСЄЧЯРк.
sibling (X, Y).
Prolog ДТ ДйРНАњ ААРЬ РРДфРЛ Чв АЭРЬДй.
X
= jake
Y = jake
БзЗЏЙЧЗЮ, Prolog ДТ jake ИІ РкБт РкНХРЧ ЧќСІЖѓАэ Л§АЂЧбДй. РЬАЭРК НУНКХлРЬ УЙ КЮИёРћ parent (M, X) ИІ ТќРИЗЮ ИИЕщБт РЇЧи УГРНПЁ M РЛ bill Ањ x ИІ jake ЗЮ ЛчЗЪШНУФзБт ЖЇЙЎПЁ ЙпЛ§ЧбДй. БзЗБ ШФ, ЕЮ ЙјТА КЮИёРћ parent (M, Y) ИІ КЮЧеЧЯБт РЇЧи ДйНУ ЕЅРЬХЭКЃРЬНКРЧ УГРНПЁМ НУРлЧЯПЉ, M РЛ bill ПЁ Y ИІ jake ПЁ ЛчЗЪШНУХВДй. ЕЮ АГРЧ КЮИёРћРЧ КЮЧе И№ЕЮАЁ ЕЅРЬХЭКЃРЬНК УГРНПЁМ НУРлЧЯПЉ ЕЖИГРћРИЗЮ ИИСЗЕЧБт ЖЇЙЎПЁ, РЇПЭ ААРК РРДфРЬ ГЊПТДй. РЬАЭРЛ ЧЧЧЯБт РЇЧи, ИИОр БзЕщРЬ ЕПРЯЧб КЮИ№ИІ АЎАэ, БзЕщРЬ ААСі ОЪРЛ ЖЇИИ, X ДТ Y РЧ ЧќСІЖѓАэ БтМњЕЧОюОп ЧбДй. РЏАЈНКЗДАдЕЕ, ГэРЧЧЯАкСіИИ, Prolog ПЁМ X ПЭ Y АЁ ААСі ОЪДйДТ АЭРЛ ГЊХИГЛДТ АЭРК АЃДмЧЯСі ОЪДй. АЁРх СЄШЎЧб ЙцЙ§РК И№Еч ПјРк (atom) НжПЁ ДыЧиМ БзЕщРЬ ААСі ОЪДйДТ ЛчНЧРЛ УЗАЁЧЯДТ АЭРЬДй. ЙАЗа, БрСЄРћРЮ СЄКИКИДй КЮСЄРћРЮ СЄКИАЁ ШЮОР ИЙБт ЖЇЙЎПЁ ЕЅРЬХЭКЃРЬНКИІ ИХПь ФПСіАд ЧбДй. ПЙИІ ЕщИщ, ДыКЮКаРЧ ЛчЖїЕщРК Л§РЯРЮ ГЏКИДй ИЙРК 364 РЯРЧ Л§РЯРЬ ОЦДб ГЏРК АЁСіАэ РжДй.
АЃДмЧб ДыОШРћРЮ ЧиАсУЅРК ДйРНАњ ААРЬ ИёРћПЁ X ПЭ Y ДТ ЕПРЯЧЯСі ОЪДйАэ БтМњЧЯДТ АЭРЬДй.
sibling (X, Y) :- parent (M, X), parent (M, Y), not (X = Y).
ДйИЅ ЛѓШВПЁМДТ ЧиАсУЅРЬ БзИЎ АЃДмЧЯСі ОЪДй.
ИИОр Чи ЕЕУтРЬ КЮИёРћ X = Y ИІ ИИСЗЧЯСі ОЪРИИщ, Prolog not ПЌЛъРкДТ РЬ АцПьПЁ ИИСЗЧбДй. БзЗЏЙЧЗЮ ИИОр not ПЌЛъРкАЁ МКАјЧбДйИщ, БзАЭРК ЙнЕхНУ X АЁ Y ПЭ ЕПРЯЧЯСі ОЪДйАэ РЧЙЬЧЯСіДТ ОЪДТДй. ДѕПэРЬ РЬАЭРК Чи ЕЕУтРЬ ЕЅРЬХЭКЃРЬНКЗЮКЮХЭ X АЁ Y ПЭ ААДйДТ АЭРЛ СѕИэЧЯСі ИјЧбДйДТ АЭРЛ ЖцЧбДй. БзЗЏЙЧЗЮ Prolog not ПЌЛъРкДТ ГэИЎ NOT ПЌЛъРкПЭ ЕПРЯЧЯСі ОЪДй. РЬ АцПьПЁ (АХСўРЬИщ) NOT РК ЧЧПЌЛъРкАЁ ОЦИЖЕЕ ТќРЬЖѓДТ АЭРЛ РЧЙЬЧбДй. ИИОр Prolog not ПЌЛъРкАЁ СјСЄЧб ГэИЎ NOT ПЌЛъРкРЬАэ ПьИЎАЁ ПьПЌШї ДйРНАњ ААРК ЧќНФРЧ ИёРћРЛ АЎДТДйИщ, РЬЗБ КёЕПЕю (nonequivalency) РК ЙЎСІИІ ЙпЛ§НУХГ Мі РжДй.
not (not (some_goal)).
РЬАЭРК ОЦЗЁРЧ АЭАњ ЕПФЁДй.
some_goal.
БзЗЏГЊ ОюЖВ АцПьПЁДТ БзЕщРК ААСі ОЪДй. ПЙИІ ЕщИщ, ДйНУ member БдФЂРЛ ЛьЦьКИРк.
member
(Element, [Element | _]) :- !.
member (Element, [_
| List] :- member (Element, List).
СжОюСј ИЎНКЦЎ ПјМв Сп ЧЯГЊИІ УЃБт РЇЧи, ПьИЎДТ ДйРНАњ ААРК ИёРћРЛ ЛчПыЧв Мі РжДй.
member (X, [mary, fred, barb])
РЬАЭРК X ИІ mary ПЁ ЛчЗЪШНУХААэ ЧСИАЦЎЧбДй. БзЗЏГЊ ДйРН ИёРћРЛ ЛчПыЧбДйИщ,
not (not (member (X, [mary, fred, barb]))).
ДйРН РЯЗУРЧ ЛчАЧРЬ ЙпЛ§ЧбДй. ИеРњ, ОШТЪРЧ ИёРћРЬ МКАјЧЯПЉ, X ИІ mary ПЁ ЛчЗЪШНУХВДй. БзЗБ ШФПЁ Prolog ДТ ОЦЗЁПЭ ААРК ДйРН ИёРћРЛ ИИСЗНУХАЗСАэ НУЕЕЧбДй.
not (member (X, [mary, fred, barb])).
member АЁ МКАјЧпБт ЖЇЙЎПЁ РЬАЭРК НЧЦаЧв АЭРЬДй. ИёРћРЬ НЧЦаЕЩ ЖЇ, Prolog ДТ ЧзЛѓ НЧЦаЧб ИёРћПЁ РжДТ И№Еч КЏМіРЧ ЛчЗЪШИІ УыМвЧЯБт ЖЇЙЎПЁ X РЧ ЛчЗЪШЕЕ УыМвЕЩ АЭРЬДй. ДйРНРИЗЮ Prolog ДТ ЙйБљТЪРЧ not ИёРћРЛ ИИСЗНУХААэРк НУЕЕЧЯАэ, БзАЭРЧ ИХАГКЏМіАЁ НЧЦаЧпБт ЖЇЙЎПЁ МКАјЧбДй. ИЖСіИЗРИЗЮ АсАњ X АЁ УтЗТЕШДй. БзЗЏГЊ X ДТ ЧіРч ЛчЗЪШЕЧСі ОЪАэ, БзЗЁМ НУНКХлРК БзАЭРЛ ГЊХИГНДй. РЯЙнРћРИЗЮ ЛчЗЪШЕЧСі ОЪРК КЏМіДТ ЙиСйРЬ МБЧрЧЯДТ М§РкРЧ НКЦЎИЕ ЧќНФРИЗЮ УтЗТЕШДй. БзЗЁМ Prolog РЧ not РЬ ГэИЎРћРЮ NOT ПЭ ААСі ОЪДйДТ ЛчНЧРК, РћОюЕЕ РпИјЕЩ МіАЁ РжДй.
ГэИЎ NOT РЬ Prolog РЧ СпПфЧб КЮКаРЬ ЕЩ Мі ОјДТ БтКЛРћРЮ РЬРЏДТ ШЅ ХЉЗбСюРЧ ЧќНФПЁ РжДй.
A
:- 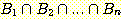
ИИОр И№Еч B ИэСІАЁ ТќРЬИщ, A АЁ ТќРЬЖѓАэ АсЗаСіРЛ Мі РжДй. БзЗЏГЊ B РЧ И№ЕЮ ЖЧДТ РЯКЮКаРЧ Тќ ЖЧДТ АХСўПЁ ЛѓАќОјРЬ, A АЁ АХСўРЬЖѓАэ АсЗа СіРЛ Мі ОјДй. БрСЄ ГэИЎДТ БрСЄ ГэИЎЗЮИИ АсЗаСіРЛ Мі РжДй. БзЗЏЙЧЗЮ ШЅ ХЉЗбСю ЧќНФРЧ ЛчПыРК ОюЖВ КЮСЄРћРЮ АсЗаРЛ ИЗДТДй.
4 Р§ПЁМ О№БоЧб АЭУГЗГ ГэИЎ ЧСЗЮБзЗЁЙжРЧ КЛСњРћРЮ ИёРћРК КёР§ТїРћРЮ ЧСЗЮБзЗЁЙжРЛ СІАјЧЯДТ АЭРЬДй. Ся, ЧСЗЮБзЗЁИгАЁ ЧСЗЮБзЗЅРЬ МіЧрЧв АЭРК СіСЄЧЯСіИИ МіЧрЧЯДТ ЙцЙ§РЛ СіСЄЧЯСі ОЪДТ НУНКХлРЬДй. СЄЗФРЛ РЇЧи СжОюСј ПЙСІДТ ПЉБтПЁ ДйНУ РлМКЧЯПДДй.
sort
(old_list, new_list) Ёј permute (old_list, new_list) Ёћ sorted (new_list)
sort (list) Ёј ЂЃj such that 1 ЁТ j < n, list (j) ЁТ list
(j + 1)
РЬАЭРК Prolog ЗЮ НБАд РлМКЧв Мі РжДй. ПЙИІ ЕщИщ, sorted РЧ КЮИёРћРК ДйРНАњ ААРЬ ЧЅЧіЕШДй.
sorted
([]).
sorted ([x]).
sorted ([x,
y | list]) :- x < = y, sorted ([y | list]).
РЇРЧ СЄЗФ АњСЄРЬ АЁСіАэ РжДТ ЙЎСІДТ БзАЭРЬ СЄЗФЕШ МјМИІ АЎДТ ИЎНКЦЎИІ Л§МКНУХГ ЖЇБюСі СжОюСј ИЎНКЦЎРЧ И№Еч ФЁШЏРЛ ПАХЧЯДТ АЭ ПмПЁДТ СЄЗФНУХАДТ ЙцЙ§РЛ И№ИЅДйДТ АЭРЬДй.
СіБнБюСі, ОЦЙЋЕЕ СЄЗФ ИЎНКЦЎРЧ СЄЗФРЛ РЇЧб ШПРВРћРЮ ОЫАэИЎСђРИЗЮ КЏШЏНУХГ Мі РжДТ ЙцЙ§РЛ ЙпАпЧЯСі ИјЧпДй. Чи ЕЕУтРК ИЙРК ШяЙЬЗЮПю РЯРЛ Чв Мі РжСіИИ, ШЎНЧШї РЬАЭРК ОЦДЯДй. БзЗЏЙЧЗЮ, ИэЗЩЧќ О№ОюГЊ ЧдМі О№ОюУГЗГ, ИЎНКЦЎИІ СЄЗФЧЯДТ Prolog ЧСЗЮБзЗЅРК СЄЗФРЬ МіЧрЕЧДТ ЙцЙ§ПЁ АќЧб ММКЮЛчЧзРЛ БтМњЧЯПЉОп ЧбДй.
РЬЗЏЧб И№Еч ЙЎСІЕщРЬ ГэИЎ ЧСЗЮБзЗЁЙжРК ЦїБтЧиОпИИ ЧбДйДТ АЭРЛ РЧЙЬЧЯДТАЁ? Р§ДыРћРИЗЮ ОЦДЯДй. БзАЭРК ИЙРК РЏПыЧб РРПыРЛ УГИЎЧЯДТ ДЩЗТРЬ РжДй. ДѕПэРЬ БзАЭРК ШЃБтНЩРЛ РкБиЧЯДТ АГГфРЛ БтЙнРИЗЮ ЧЯАэ РжАэ, БзЗЏЙЧЗЮ Бз РкУМЗЮ ШяЙЬЗгДй. ИЖСіИЗРИЗЮ, ЧСЗЮБзЗЅРЧ ИэММПЁМ how АЁ ОЦДЯЖѓ what ИИРЛ ПфБИЧЯДТ ГэИЎ ЧСЗЮБзЗЁЙж О№Ою НУНКХлРЛ ЧуПыЧЯДТ ОюЖВ ЛѕЗЮПю УпЗа БтМњРЬ АГЙпЕЩ АЁДЩМКЕЕ РжДй.
РЬ Р§ПЁМ РЯЙнРћРИЗЮ ГэИЎ ЧСЗЮБзЗЁЙж ЦЏШї Prolog РЧ ЧіРч БзИЎАэ РсРчРћРЮ РРПыРЧ Ию АГ КЮЗљИІ АЃДмШї ММњЧЯАэРк ЧбДй.
АќАшЧќ ЕЅРЬХЭКЃРЬНК АќИЎ НУНКХл (RDBMS) РК ЕЅРЬХЭИІ ХзРЬКэ ЧќНФРИЗЮ РњРхЧбДй. ЕЅРЬХЭКЃРЬНКПЁМРЧ СњРЧДТ СОСО БтШЃ ГэИЎРЧ ЧќНФРЛ АЎДТ АќАшЧќ АшЛъЙ§РИЗЮ ГЊХИГНДй. РЬЗБ НУНКХлРЧ СњРЧ О№ОюДТ ГэИЎ ЧСЗЮБзЗЁЙжРЬ Р§ТїРћРЮ АЭРЬЖѓДТ ЕПРЯЧб РЧЙЬПЁМ КёР§ТїРћРЬДй. ЛчПыРкДТ РРДфРЛ УпУтЧЯДТ ЙцЙ§РЛ БтМњЧЯСі ОЪДТДй. ПРШїЗС ЛчПыРкДТ РРДфРЧ ЦЏМКИИРЛ БтМњЧв Мі РжДй. ГэИЎ ЧСЗЮБзЗЁЙжАњ RDBMS ЛчРЬРЧ ПЌАсРК ИэЙщЧЯДй. СЄКИРЧ АЃДмЧб ХзРЬКэРК Prolog БИСЖПЁ РЧЧи БтМњЕЩ Мі РжАэ, ХзРЬКэРЧ АќАшДТ Prolog БдФЂПЁ РЧЧи ЦэИЎЧЯАэ НБАд БтМњЕШДй. АЫЛі АњСЄРК Чи ЕЕУтПЁМ КЛСњРћРЬДй. Prolog РЧ ИёРћЙЎРК RDBMS ИІ РЇЧб СњРЧИІ СІАјЧбДй. БзЗЏЙЧЗЮ ГэИЎ ЧСЗЮБзЗЁЙжРК RDBMS БИЧіПЁ РкПЌНКЗДАд КЮЧеЧбДй.
RDBMS БИЧіПЁ ГэИЎ ЧСЗЮБзЗЁЙжРЛ ЛчПыЧЯДТ РхСЁ Сп ЧЯГЊДТ ДмСі ДмРЯЧб О№ОюИИРЬ ПфБИЕШДйДТ АЭРЬДй. РќХыРћРЮ RDBMS ПЁМ, ЕЅРЬХЭКЃРЬНК О№ОюДТ ЕЅРЬХЭ СЄРЧ, ЕЅРЬХЭ СЖРл, СњРЧИІ РЇЧб ЙЎРхРЛ ЦїЧдЧЯИч, РЬ И№ЕЮДТ COBOL Ањ ААРК ЙќПы ЧСЗЮБзЗЁЙж О№ОюПЁ ГЛРхЕШДй. ЙќПы О№ОюДТ ЕЅРЬХЭ УГИЎГЊ РдЗТ, УтЗТ ЧдМіИІ РЇЧи ЛчПыЕЧОњДй. РЬЗБ И№Еч ЧдМіДТ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюЗЮ МіЧрЕЩ Мі РжДй.
RDBMS БИЧіПЁ ГэИЎ ЧСЗЮБзЗЁЙжРЛ ЛчПыЧЯДТ ДйИЅ РхСЁРК УпЗа ДЩЗТРЬ ГЛРхЕЧОю РжДйДТ АЭРЬДй. РќХыРћРЮ RDBMS ДТ ИэНУРћРИЗЮ ЕЅРЬХЭКЃРЬНКПЁ РњРхЕЧДТ АЭ ПмПЁДТ ЕЅРЬХЭКЃРЬНКЗЮКЮХЭ ОюЖВ АЭЕЕ УпЗаЧв Мі ОјДй. БзЕщРК ЛчНЧАњ УпЗа БдФЂРЛ АЁСіАэ РжДТ АЭРЬ ОЦДЯЖѓ ЛчНЧИИРЛ АЁСіАэ РжДй. РќХыРћРЮ RDBMS Ањ КёБГЧиМ RDBMS БИЧіПЁ ГэИЎ ЧСЗЮБзЗЁЙжРЛ ЛчПыЧЯДТ ДмСЁРК ГэИЎ ЧСЗЮБзЗЁЙж БИЧіРЬ ДРИЎДйДТ АЭРЬДй. ГэИЎРћ УпЗаРК ИэЗЩЧќ ЧСЗЮБзЗЁЙж БтМњРЛ ЛчПыЧб РЯЙн ХзРЬКэ ХНЛі ЙцЙ§КИДй НУАЃРЬ ДмМјШї Дѕ АЩИАДй.
РќЙЎАЁ НУНКХлРК ОюЖВ ЦЏКАЧб ПЕПЊРЧ РќЙЎРћРЮ СіНФРЛ АЁСј ЛчЖїРЛ И№ЙцЧЯБт РЇЧи МГАшЕШ ФФЧЛХЭ НУНКХлРЬДй. РќЙЎАЁ НУНКХлРК ЛчНЧРЧ ЕЅРЬХЭКЃРЬНК, УпЗа АњСЄ, ПЕПЊПЁ ДыЧб ОюЖВ АцЧш, НУНКХлРЛ РќЙЎ ЛѓДуРкУГЗГ КИРЬАд ИИЕхДТ ФЃМїЧб РЮХЭЦфРЬНКЗЮ БИМКЕШДй. ЛчЖї РќЙЎАЁПЁ РЧЧи СІАјЕШ УЪБт СіНФ КЃРЬНК ПмПЁЕЕ, РќЙЎАЁ НУНКХлРК ЛчПыЕЧДТ АњСЄПЁМ СіНФРЛ ЧаНРЧЯАэ, ЕћЖѓМ ЕЅРЬХЭКЃРЬНКДТ ЙнЕхНУ ЕПРћРИЗЮ ШЎРхЕЧДТ ДЩЗТРЬ РжОюОп ЧбДй. ЙАЗа РќЙЎАЁ НУНКХлРК СЄКИАЁ ЧЪПфЧЯДйАэ АсСЄЕЩ ЖЇ КЮАЁРћРЮ СЄКИИІ ОђБт РЇЧи ЛчПыРкПЁАд СњРЧЧЯДТ ДЩЗТРЬ РжОюОп ЧбДй.
РќЙЎАЁ НУНКХл МГАшРкИІ РЇЧб СпНЩРћРЮ ЙЎСІ СпПЁ ЧЯГЊДТ ЕЅРЬХЭКЃРЬНКРЧ ЧЧЧв Мі ОјДТ КвРЯФЁПЭ КвПЯРќМКРЛ ДйЗчДТ АЭРЬДй. ГэИЎ ЧСЗЮБзЗЁЙжРК РЬЗБ ЙЎСІИІ ДйЗчДТ ЕЅ ОЦСж РћЧеЧб АЭУГЗГ КИРЮДй. ПЙЗЮ ЕщИщ, Е№ЦњЦЎ УпЗа БдФЂРК КвПЯРќМКРЧ ЙЎСІИІ ДйЗчДТ ЕЅ ЕЕПђРЛ Сй Мі РжДй.
Prolog ДТ РќЙЎАЁ НУНКХлРЛ ИИЕхДТ ЕЅ ЛчПыЕЩ Мі РжАэ ЛчПыЕЧОю ПдДй. Prolog ДТ СњРЧ УГИЎРЧ БтКЛРИЗЮМ Чи ЕЕУт, ЧаНР ДЩЗТРЛ СІАјЧЯБт РЇЧи ЛчНЧРЬГЊ БдФЂРЛ УЗАЁЧЯДТ ДЩЗТ, СжОюСј АсАњПЁ ДыЧб РЬРЏИІ ЛчПыРкПЁАд ОЫИЎБт РЇЧЯПЉ УпРћ ДЩЗТРЛ ЛчПыЧЯПЉ РќЙЎАЁ НУНКХлРЧ БтКЛ ПхБИИІ НБАд ИИСЗНУХГ Мі РжДй. Prolog ПЁМ КќСј АЭРК КЮАЁРћРЮ СЄКИАЁ ЧЪПфЧв ЖЇ НУНКХлРЬ ЛчПыРкПЁАд БзЗЏЧб СЄКИИІ СњРЧЧЯДТ РкЕПРћРЮ ДЩЗТРЬДй.
РќЙЎАЁ НУНКХлПЁМ АЁРх ГЮИЎ ЛчПыЕЧДТ ГэИЎ ЧСЗЮБзЗЅРЧ ЛчПы СпПЁ ЧЯГЊДТ Sergot (1983) Ањ Hammond (1983) ПЁ РЧЧи БтМњЕШ APES ЗЮ ОЫЗССј РќЙЎАЁ НУНКХл СІРл НУНКХлРЬДй. APES НУНКХлРК РќЙЎАЁ НУНКХлРЛ БИУрЧЯДТ ЕПОШ ЛчПыРкЗЮКЮХЭ СЄКИИІ И№РИБт РЇЧб ИХПь РЏПЌЧб РхФЁИІ ЦїЧдЧбДй. ЖЧЧб СњРЧПЁ ДыЧб ЧиДфРЧ УГИЎ АњСЄ ММњРЛ Л§ЛъЧЯБт РЇЧи РЬТїРћРЮ РЮХЭЧСИЎХЭЕЕ ЦїЧдЧЯАэ РжДй.
APES ДТ СЄКЮ ЛчШИ КИРх ЧСЗЮБзЗЅРЧ БдФЂРЛ РЇЧб РќЙЎАЁ НУНКХлАњ ПЕБЙ НУЙЮБЧРЧ БдФЂРЧ ИэЙщЧб СТЧЅРЮ ПЕБЙ БЙРћЙ§ (British nationality) РЛ РЇЧб РќЙЎАЁ НУНКХлРЛ ЦїЧдЧЯПЉ ПЉЗЏ РќЙЎАЁ НУНКХлРЛ Л§ЛъЧЯДТ ЕЅ МКАјРћРИЗЮ ЛчПыЕЧАэ РжДй.
ОюЖВ СОЗљРЧ РкПЌОю УГИЎДТ ГэИЎ ЧСЗЮБзЗЁЙжРИЗЮ МіЧрЕЩ Мі РжДй. ЦЏШї, СіДЩ ЕЅРЬХЭКЃРЬНКПЭ ДйИЅ СіДЩ СіНФ БтЙн НУНКХл ААРК ФФЧЛХЭ МвЧСЦЎПўОю НУНКХлПЁ ДыЧб РкПЌОю РЮХЭЦфРЬНКДТ ГэИЎ ЧСЗЮБзЗЁЙжРИЗЮ ЦэИЎЧЯАд МіЧрЕЩ Мі РжДй. О№Ою БИЙЎ БтМњПЁ РжОюМ ГэИЎ ЧСЗЮБзЗЁЙжРЧ ЧќНФРК ЙЎИЦ РкРЏ ЙЎЙ§ (context-free grammar) Ањ ЕПРЯЧЯДйДТ АЭРЬ ОЫЗССГДй. ГэИЎ ЧСЗЮБзЗЁЙж НУНКХлПЁМРЧ СѕИэ Р§ТїДТ ОюЖВ ЦФНЬ РќЗЋАњ ЕПРЯЧб АЭРИЗЮ ОЫЗССГДй. НЧСІЗЮ, ШФЧт УМРЮ (backward chaining) Чи ЕЕУтРК ЙЎИЦ РкРЏ ЙЎЙ§ПЁ РЧЧи БтМњЕШ БИСЖИІ АЎДТ ЙЎРхРЛ ЦФНЬЧЯДТ ЕЅ СїСЂ ЛчПыЧв Мі РжДй. ЖЧЧб РкПЌОюРЧ ОюЖВ РЧЙЬЗаРК Бз О№ОюИІ ГэИЎ ЧСЗЮБзЗЁЙжРИЗЮ И№ЕЈИЕЧдРИЗЮНс ИэЙщЧиСњ Мі РжДйДТ АЭРЬ КИПЉСГДй. ЦЏШї, ГэИЎ-БтЙн РЧЙЬ ИСРЧ ПЌБИДТ РкПЌОю ЙЎРхРЧ С§ЧеРЬ ХЌЗЮСю ЧќНФРИЗЮ ЧЅЧіЕШДйДТ АЭРЛ КИПДДй (Deliyanni and Kowalski, 1979). ЖЧЧб Kowalski (1979) ГэИЎ БтЙн РЧЙЬ ИСРЛ ГэРЧЧпДй.
БГРА ПЕПЊПЁМ 7 ЛьРЧ ОюИА ОЦРЬЕщПЁАд ГэИЎ ЧСЗЮБзЗЁЙж О№Ою micro-Prolog ИІ ЛчПыЧЯДТ ЙцЙ§РЛ АЁИЃФЁДТ БЄЙќРЇЧб НЧЧшРЬ ЧрЧиСГДй (Ennals, 1980). ПЌБИРкЕщРК ОюИА ОЦРЬЕщПЁАд Prolog ИІ АЁИЃФЁДТ АЭРЬ ПЉЗЏ АЁСі РхСЁРЬ РжДйАэ СжРхЧбДй. УЙТА, РЬЗБ СЂБй ЙцНФРЛ ЛчПыЧиМ ФФЧЛЦУРЛ МвАГЧЯДТ АЭРЬ АЁДЩЧЯДй. ЖЧЧб КИДй ИэШЎЧб ЛчАэПЭ ЧЅЧіРЛ АЁСЎДйСжДТ ГэИЎ БГРАРЧ КЮМіРћРЮ ШПАњИІ АЁСіАэ РжДй. РЬАЭРК МіЧаРЧ ЙцСЄНФ ЧЎРЬ, РкПЌОюИІ РЇЧб ЙЎЙ§ ДйЗчБт, ЙАИЎ ММАшРЧ БдФЂАњ СњМИІ РЬЧиЧЯДТ АЭАњ ААРК ДйОчЧб СжСІИІ ЧаЛ§ЕщРЬ ЙшПьДТ ЕЅ ЕЕПђРЛ Сй Мі РжДй.
ИХПь ОюИА ОЦРЬЕщПЁАд ГэИЎ ЧСЗЮБзЗЁЙжРЛ АЁИЃФЁДТ НЧЧшРК ИэЗЩЧќ О№ОюПЁ АцЧшРЬ ИЙРК ЧСЗЮБзЗЁИгКИДй УЪНЩРкПЁАд ГэИЎ ЧСЗЮБзЗЁЙжРЛ АЁИЃФЁБтАЁ НБДйДТ ШяЙЬЗЮПю АсАњИІ ЕЕУтЧЯПДДй.
ИЙРК ЛчЖїЕщРК Prolog АЁ, РћОюЕЕ Чі НУСЁПЁМДТ ПЉРќШї АХДыЧб НЧЧшРЬЖѓАэ ЙЯАэ РжДй. БзЗЏГЊ ДйИЅ ИЙРК О№ОюУГЗГ ИЙРК СіСіРкАЁ РжДй. БзЕщРК ЧіРч ЛчПыСпРЮ ИэЗЩЧќ О№ОюДТ ФФЧЛХЭПЁ РЧЧи ЧиАсЕЧОюОп ЧЯДТ ЙЎСІИІ АЃДмЧЯАд ДыУГЧв Мі ОјДйДТ МвЧСЦЎПўОю РЇБтПЁ ДыЧб РћОюЕЕ ЧиАсУЅРЧ РЯКЮКаРЬ ЕЩ Мі РжДйАэ ЙЯДТДй (Cuadrado and Cuadrado, 1985).
СіСіРкЕщРЬ Prolog АЁ ИэЗЩЧќ О№ОюКИДй ССДйАэ ЙЯДТ Ию АЁСі РЬРЏ - ПјЗЁ Prolog СіСіРк СпПЁ ЧЯГЊРЮ Jacques Cohen (1985) ПЁ РЧЧи О№БоЕЧОњДј РЬРЏ - ДТ ОЦЗЁПЭ ААРК АЭРЬДй.
ЙАЗа РЬЗБ АЭПЁ ЕПРЧЧЯСі ОЪДТ ЛчЖїЕЕ РжДй. ИЙРК ФФЧЛХЭ АњЧаРкЕщРК Ию АЁСі РлРК РЮАј СіДЩ ПЕПЊ ЙлПЁМДТ Prolog РЏПыМКПЁ ШИРЧРћРЬДй. КёЗЯ Чі НУСЁПЁМДТ ШЎНЧШї ИэШЎЧЯСі ОЪСіИИ, Prolog ДТ РЮАјСіДЩРЧ СжПфЧб О№ОюРЮ LISP ИІ ДыУМЧв АЭРЬЖѓАэ РЯКЮ ЛчЖїЕщРК ЙЯДТДй. Warren et al. (1977) РК ЕЮ О№ОюИІ КёБГЧЯПДДй.
БтШЃ ГэИЎДТ ГэИЎ ЧСЗЮБзЗЁЙжАњ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюИІ РЇЧб БтУЪИІ СІАјЧбДй. ГэИЎ ЧСЗЮБзЗЁЙжРЧ СЂБй ЙцЙ§РК ЕЅРЬХЭКЃРЬНКЗЮМ ЛчНЧАњ ЛчНЧ ЛчРЬРЧ АќАшИІ ГЊХИГЛДТ БдФЂРЧ С§ЧеРЛ ЛчПыЧЯАэ ЛѕЗЮПю ИэСІРЧ ХИДчМКРЛ АЫЛчЧЯБт РЇЧи, ЕЅРЬХЭКЃРЬНКРЧ ЛчНЧАњ БдФЂРЬ ЛчНЧРЬЖѓАэ АЁСЄЧЯПЉ, РкЕП УпЗа АњСЄРЛ ЛчПыЧбДй. РЬЗБ СЂБй ЙцЙ§РК РкЕП СЄИЎ СѕИэРЛ РЇЧи АГЙпЕШ СЂБй ЙцЙ§РЬДй. Prolog ДТ АЁРх ГЮИЎ ЛчПыЕЧДТ ГэИЎ ЧСЗЮБзЗЁЙж О№ОюРЬДй. ГэИЎ ЧСЗЮБзЗЁЙжРЧ БтПјРК ГэИЎ УпЗаРЛ РЇЧб Чи ЕЕУт БдФЂРЛ АГЙпЧб Robinson ПЁАд РжДй. Prolog ДТ Edinburgh РЧ Kowalski ЗЮКЮХЭ ОрАЃРЧ ЕЕПђРЛ ЙоОЦ Marseille РЧ Roussel Ањ Colmeraur ПЁ РЧЧи УГРНРИЗЮ АГЙпЕЧОњДй.
ГэИЎ ЧСЗЮБзЗЅРК ЧиДфРЧ ЦЏМКРК СжОюСіСіИИ ЧиДфРЛ ОђДТ АњСЄРК СжОюСіСі ОЪДТ АЭРЛ РЧЙЬЧЯДТ КёР§ТїРћРЬОюОп ЧбДй.
Prolog ЙЎРхРК fact, БдФЂ ЖЧДТ ИёРћРЬДй. ДыКЮКаРЧ ЙЎРхРК БтКЛ ИэСІРЮ БИСЖПЭ, ЛъМњ ЧЅЧіНФРЬ ЧуПыЕЩСіЖѓЕЕ, ГэИЎ ПЌЛъРкЗЮ БИМКЕШДй.
Чи ЕЕУтРК Prolog РЮХЭЧСИЎХЭРЧ СжПфЧб ЕПРлРЬДй. ПЊЧрРЛ БЄЙќРЇЧЯАд ЛчПыЧЯДТ РЬ АњСЄРК СжЗЮ ИэСІЕщРЧ ЦаХЯ КЮЧеРЛ ЦїЧдЧбДй. КЏМіАЁ ЦїЧдЕЧОњРЛ ЖЇ, КЏМіДТ КЮЧеРЛ СІАјЧЯБт РЇЧи АЊРИЗЮ ЛчЗЪШЕШДй. РЬЗБ ЛчЗЪШ АњСЄРЛ ДмРЯШЖѓАэ КЮИЅДй.
Чі ЛѓХТРЧ ГэИЎ ЧСЗЮБзЗЁЙжРК ИЙРК ЙЎСІСЁРЛ АЁСіАэ РжДй. ШПРВМКРЧ РЬРЏПЭ ЙЋЧб ЗчЧСИІ ШИЧЧЧЯБт РЇЧи, ЧСЗЮБзЗЁИгДТ ЖЇЖЇЗЮ ЧСЗЮБзЗЅПЁМ СІОю ШхИЇ СЄКИИІ ГЊХИГЛОп ЧбДй. ЖЧЧб, ДнШљ ММАш АЁСЄАњ КЮСЄРЧ ЙЎСІАЁ РжДй.
ГэИЎ ЧСЗЮБзЗЁЙжРК ИЙРК ДйИЅ ПЕПЊ - СжЗЮ, АќАшЧќ ЕЅРЬХЭКЃРЬНК НУНКХл, РќЙЎАЁ НУНКХл, БзИЎАэ РкПЌОю УГИЎ - ПЁ ЛчПыЕЧОњДй.
Prolog О№ОюДТ ПЉЗЏ УЅПЁМ БтМњЕЧОњДй. О№ОюРЧ Edinburgh ЧќНФРК Clocksin Ањ Mellish (1997) ПЁ ММњЕЧОњДй. ИЖРЬХЉЗЮ ФФЧЛХЭ БИЧіРК Clark Ањ McCabe (1984) ПЁ РЧЧи БтМњЕЧОюСГДй.
Hogger (1984) ДТ РЯЙнРћРЮ ГэИЎ ЧСЗЮБзЗЁЙжРЧ ПЕПЊПЁ АќЧб ШЧИЂЧб УЅРЬДй. БзАЭРК РЬ РхПЁ РжДТ ГэИЎ ЧСЗЮБзЗЁЙж РРПы Р§ ГЛПыРЧ УтУГРЬДй.
1. ЧќНФ ГэИЎПЁМ БтШЃ ГэИЎРЧ ММ АЁСі СжЕШ ЛчПыРК ЙЋОљРЮАЁ?
2. КЙЧе ЧзРЧ ЕЮ КЮКаРК ЙЋОљРЮАЁ?
3. ХЌЗЮСю ЧќНФПЁМ ИэСІРЧ РЯЙнРћРЮ ЧќНФРК ЙЋОљРЮАЁ?
4. Чи ЕЕУтАњ ДмРЯШРЧ РЯЙнРћРЮ (ОіАнЧЯСі ОЪРК) СЄРЧИІ ГЊХИГЛНУПР.
5. ШЅ ХЌЗЮСю ЧќНФРК ЙЋОљРЮАЁ?
6. МБО№Рћ РЧЙЬЗаРЧ БтКЛ АГГфРК ЙЋОљРЮАЁ?
7. Prolog ЧзРЧ ММ АЁСі ЧќНФРК ЙЋОљРЮАЁ?
8. Prolog ПЁМ ЛчНЧЙЎАњ БдФЂЙЎРЧ БИЙЎЧќНФАњ ЛчПыЙ§РК ЙЋОљРЮАЁ?
9. ЕЅРЬХЭКЃРЬНКПЁ РжДТ ЛчНЧАњ ИёРћРЛ КЮЧеЧЯДТ ЕЮ АЁСі СЂБй ЙцЙ§РЛ МГИэЧЯНУПР.
10. ДйСп ИёРћРЬ ИИСЗЕЧДТ ЙцЙ§РЛ ГэРЧЧв ЖЇ, БэРЬ ПьМБАњ ГаРЬ ПьМБ ХНЛіРЧ ТїРЬСЁРЛ МГИэЧЯНУПР.
11. Prolog ПЁМ ПЊЧрРЬ ОюЖЛАд МіЧрЕЧДТСіИІ МГИэЧЯНУПР.
12. Prolog ЙЎРх "K is K + 1" ПЁ РпИјЕШ АЭРЬ ЙЋОљРЮСі МГИэЧЯНУПР.
13. ЧСЗЮБзЗЁИгАЁ Чи ЕЕУт ЕПОШ ЦаХЯ КЮЧеРЧ МјМИІ СІОюЧв Мі РжДТ ЕЮ АЁСі ЙцЙ§РК ЙЋОљРЮАЁ?
14. Prolog ПЁМ Л§МК-АЫЛч ЧСЗЮБзЗЁЙж РќЗЋРЛ МГИэЧЯНУПР.
15. Prolog ПЁ РЧЧи ЛчПыЕЧДТ ДнШљ ММАш АЁСЄРЛ МГИэЧЯНУПР. Пж РЬАЭРЬ ЧбАшРЮАЁ?
16. Prolog РЧ КЮСЄ ЙЎСІИІ МГИэЧЯНУПР. Пж РЬАЭРЬ ЧбАшРЮАЁ?
17. РкЕП СЄИЎ СѕИэАњ Prolog УпЗа АќАшРЧ ПЌАсРЛ МГИэЧЯНУПР.
18. Р§ТїРћ О№ОюПЭ КёР§ТїРћ О№ОюРЧ ТїРЬСЁРЛ МГИэЧЯНУПР.
19. Prolog НУНКХлРЬ ПЊЧрРЛ МіЧрЧЯДТ РЬРЏИІ МГИэЧЯНУПР.
20. Prolog ПЁМ Чи ЕЕУтАњ ДмРЯШ ЛчРЬРЧ АќАшДТ ЙЋОљРЮАЁ?
1. Prolog ПЭ Ada РЧ ЕЅРЬХЭ ХИРдРЧ АГГфРЛ КёБГЧЯНУПР.
2. ДйСп ЧСЗЮМММ БтАшАЁ Чи ЕЕУт БИЧіРЛ РЇЧи ЛчПыЕЧДТ ЙцЙ§РЛ БтМњЧЯНУПР. ЧіРч СЄРЧЕШ ДыЗЮ Prolog ДТ РЬ ЙцЙ§РЛ ЛчПыЧЯДТАЁ?
3. ДчНХРЧ СЖКЮИ№ПЭ И№Еч РкМеРЛ ЦїЧдЧЯПЉ ДчНХ АЁАшЕЕИІ Prolog ЗЮ РлМКЧЯНУПР. ЙАЗа И№Еч АќАшИІ ЦїЧдЧиОп ЧбДй.
4. ЕЮ ММДыИІ ХыЧб СЖКЮИ№ АќАшИІ ЦїЧдЧЯПЉ АЁСЗ АќАшИІ РЇЧб БдФЂРЧ С§ЧеРЛ РлМКЧЯНУПР. РЬСІ РЬ АќАшИІ ЙЎСІ 3 РЧ f ЛчНЧПЁ УЗАЁЧЯАэ, АЁДЩЧб Чб ИЙРК ЛчНЧРЛ СІАХЧЯНУПР.
5. ИИОр СжОюСј ЕЮ ИЎНКЦЎ ИХАГКЏМіРЧ БГС§ЧеРЬ Ај ИЎНКЦЎРЬИщ МКАјЧЯДТ Prolog ЧСЗЮБзЗЅРЛ РлМКЧЯНУПР.
6. СжОюСј ЕЮ ИЎНКЦЎРЧ ПјМвРЧ ЧеС§ЧеРЛ АЎДТ ИЎНКЦЎИІ ЙнШЏЧЯДТ Prolog ЧСЗЮБзЗЅРЛ РлМКЧЯНУПР.
7. СжОюСј ИЎНКЦЎРЧ ИЖСіИЗ ПјМвИІ ЙнШЏЧЯДТ Prolog ЧСЗЮБзЗЅРЛ РлМКЧЯНУПР.
8. Scheme Ањ Prolog РЧ ИЎНКЦЎ УГИЎ ДЩЗТРЧ РЏЛчЧб ЕЮ АЁСі ЙцЙ§РЛ МГИэЧЯНУПР.
9. Scheme Ањ Prolog РЧ ИЎНКЦЎ УГИЎ ДЩЗТРЬ ОюЖВ ИщПЁМ ДйИЅАЁ?