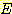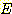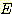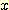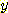
Clustering
Pattern Recognition and Image Analysis : Earl Gose. Richard Johnsonbaugh. Steve Jost РњМ, Prentice Hall, 1996, Page 199~219
БИКаЧЯЗСАэ ЧЯДТ АЂ classПЁ ДыЧб ОЦЙЋЗБ СіНФРЬ ОјДТ ЛѓХТПЁМ classifyЧЯДТ АЭРЬЙЧЗЮ unsupervised learningПЁ ЧиДчЧбДй. Ся sampleЕщПЁ ДыЧб СіНФОјРЬ similarity (РЏЛчЕЕ) ПЁ БйАХЧЯПЉ cluster ЕщРЛ БИКаЧбДй. ЦаХЯ АјАЃПЁ СжОюСј РЏЧб АГРЧ ЦаХЯЕщРЬ МЗЮ АЁБѕАд И№ПЉМ ЙЋИЎИІ РЬЗчАэ РжДТ ЦаХЯ С§ЧеРЛ cluster (БКС§) РЬЖѓЧЯАэ ЙЋИЎСіПі ГЊАЁДТ УГИЎ АњСЄРЛ clustering РЬЖѓ ЧбДй.
cluster АЃРЧ РЏЛчЕЕИІ ЦђАЁЧЯБт РЇЧи ПЉЗЏ АЁСіРЧ АХИЎ УјСЄ ЧдМіИІ ЛчПыЧЯДТЕЅ ПЙИІЕщИщ Euclidean distance, Mahalanobis distance, Lance-Williams distance, Hamming distance ЕюРЬ ЛчПыЕШДй.
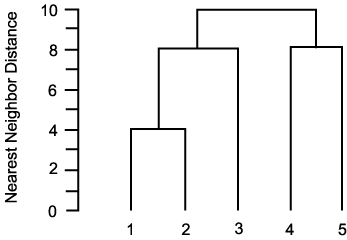
hierarchy ДТ ДйРН БзИВАњ ААРЬ tree БИСЖЗЮ ЧЅЧіЕЩ Мі РжДй. ЕПЙА КДПјПЁМ ШЏРкЕщРК ХЉАд АГПЭ АэОчРЬЗЮ БИМКЕЧИч АЂРк subgroup РИЗЮ ГЊДВСіИч БзАЭРК ДйНУ subgroup РИЗЮ ГЊДВСјДй. АЂАГРЧ ЕПЙАРК 1 ~ 5 ЗЮ БИКаЕЧИч АЁРх ОЦЗЁПЁ РЇФЁЧбДй. hierarchical clustering РК dataИІ ИЙРК РлРК БзЗьРИЗЮ БИМКЕЧДТ ХЋ БзЗьРЛ БИМКЧЯДТ АњСЄРЛ РЧЙЬЧбДй. ШчШї tree ГЊ dendrogram РИЗЮ БзЗСМ ЧЅЧіЧЯИч АЁРх ЙЬММЧб БзЗьРК АЁРх ОЦЗЁПЁ РЇФЁЧЯИч АЂ sample РК ЧЯГЊРЧ clusterИІ ЧќМКЧбДй. АЁРх ХЋ БзЗьРЬ СІРЯ РЇПЁ РЇФЁЧЯИч АЂ sample ЕщРК ЧЯГЊРЧ cluster БзЗьПЁ МгЧбДй.
РЇРЧ БзИВПЁМ level ПЁ ЕћЖѓ ДйРНРЧ sample ЕщЗЮ БИМКЕЧДТ cluster ЗЮ БИМКЕШДй.
level 0 : {1}, {2}, {3}, {4}, {5},
level 1 : {1, 2}, {3}, {4}, {5}.
level 2 : {1, 2}, {3}, {4, 5}.
level 3 : {1, 2, 3}, {4, 5}.
level 4 : {1, 2, 3, 4, 5} : ЧЯГЊРЧ cluster ЗЮ БИМКЕШДй.
hierarchical clustering ПЁМДТ ОюЖВ level ПЁ ЧЯГЊРЧ cluster ПЁ МгЧЯДТ ЕЮ sample РЬ РжДйИщ БзАЭРК ЛѓРЇ level ПЁМДТ ААРК cluster ПЁ МгЧбДй. Ся РЇРЧ БзИВПЁМ level 2 ПЁМРЧ 4 ПЭ 5 ДТ ААРК cluster ПЁ МгЧЯИч БзАЭРК level 3 Ањ 4 ПЁМЕЕ ААРК cluster ПЁ МгЧбДй.
hierarchical clustering algorithm РК АшУўБИСЖИІ bottom up ЙцНФРИЗЮ ИИЕщ АцПь agglomerative (КДЧеНФ) РЬЖѓАэ ЧЯАэ, top down ЙцНФРЬИщ divisive (КаЧвНФ) РЬЖѓАэ ЧбДй.
cluster АЃРЧ РЏЛчЕЕИІ УјСЄЧЯДТ ДйИЅ ЙцЙ§ЕщРЛ ЛчПыЧЯПЉ ДйИЅ hierarchical clustering algorithmРЛ БИЧв Мі РжДй. Бз РЏЛчЕЕИІ УјСЄЧЯДТ ЧЯГЊРЧ ЙцЙ§РЬ cluster АЃ АХИЎИІ УјСЄЧЯДТ ЧдМіИІ СЄРЧЧЯДТ АЭРЬДй. АХИЎ ЧдМіДТ sample РЧ НжЕщАЃ АХИЎИІ УјСЄЧЯДТ РсРч ЧдМіПЁ РЧЧи РЏЕЕЕШДй. nearest neighbor РЧ АцПьУГЗГ cluster ЙцЙ§ПЁМЕЕ АЁРх РЯЙнРћРЮ АХИЎ УјСЄРК Eucledian distance ПЭ city block distance ЙцЙ§РЬДй.
РЯЙнРћРЮ agglomerative clustering algorithm РК ЙІЛчЧЯБтАЁ МіПљЧЯДй. sample РЧ РќУМ МіИІ n РЬЖѓАэ Чв АцПь ДйРНАњ ААРК АњСЄРЛ АХФЃДй.
1. n АГРЧ cluster ЗЮ НУРлЧбДй. АЂАЂРК ЧЯГЊРЧ sampleРЛ ЦїЧдЧбДй.
2. step 3РЛ n - 1 Йј ЙнКЙЧбДй.
3. АЁРх РЏЛчЧб cluster 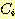 ПЭ
ПЭ 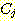 РЛ УЃОЦМ ЧЯГЊРЧ cluster ЗЮ КДЧеЧбДй. ИИРЯ ААРК АЊРЬ РжРИИщ ИеРњ ЙпАпЕШ
НжРЛ КДЧеЧбДй.
РЛ УЃОЦМ ЧЯГЊРЧ cluster ЗЮ КДЧеЧбДй. ИИРЯ ААРК АЊРЬ РжРИИщ ИеРњ ЙпАпЕШ
НжРЛ КДЧеЧбДй.
ДйИЅ РЬИЇРИЗЮДТ minimum method ПЭ nearest neighbor method ЗЮЕЕ КвИЎПюДй. ШФРкРЧ РЬИЇРК nearest neighbor classification Ањ ЙаСЂЧб АќАшИІ КИПЉСиДй. АЂ clusterПЁ ЧЯГЊОПРЧ СЁРЬ РжРЛ ЖЇ ЕЮ СЁ АЃРЧ АЁРх АЁБюПю АХИЎИІ ЕЮ cluster АЃРЧ АХИЎЗЮМ СЄРЧЧЯДТ ОЫАэИЎСђРЬДй.
ЕЮ cluster 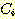 ПЭ
ПЭ 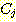 АЁ РжРЛ ЖЇ БзЕщ ЛчРЬРЧ АХИЎДТ ДйРНАњ ААРЬ СЄРЧЕШДй. ПЉБтМ
АЁ РжРЛ ЖЇ БзЕщ ЛчРЬРЧ АХИЎДТ ДйРНАњ ААРЬ СЄРЧЕШДй. ПЉБтМ 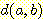 ДТ sample
ДТ sample 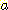 ПЭ
ПЭ 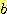 ЛчРЬРЧ АХИЎИІ РЧЙЬЧбДй.
ЛчРЬРЧ АХИЎИІ РЧЙЬЧбДй.
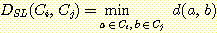
Example 5.1 single-linkage algorithmРЛ ЛчПыЧб Hierarchical clustering
5 АГРЧ sample Ањ 2 АГРЧ feature  ПЭ
ПЭ  ИІ АЁСіДТ АцПьИІ КИРк. 5 АГРЧ sampleРК ДйРН БзИВАњ ААРЬ КаЦїЧи РжДйАэ ЧЯРк. sample
АЃРЧ АХИЎ УјСЄРЛ РЇЧи Euclidean distanceИІ ЛчПыЧЯЖѓ
ИІ АЁСіДТ АцПьИІ КИРк. 5 АГРЧ sampleРК ДйРН БзИВАњ ААРЬ КаЦїЧи РжДйАэ ЧЯРк. sample
АЃРЧ АХИЎ УјСЄРЛ РЇЧи Euclidean distanceИІ ЛчПыЧЯЖѓ
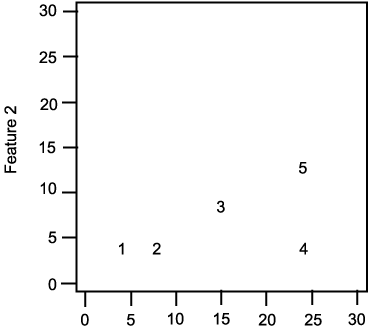
ДйРН ЧЅДТ АЂ sample РЧ feature АЊАњ sample НжЕщ
АЃРЧ АХИЎ  ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
ЧЯГЊРЧ sampleРЛ АЁСіДТ cluster  ПЭ
ПЭ 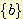 АЁ РжАэ БзЕщАЃРЧ АХИЎДТ
АЁ РжАэ БзЕщАЃРЧ АХИЎДТ 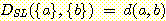 РЬДй.
РЬДй.
ОЫАэИЎСђРК АЂРк ЧЯГЊРЧ sampleРЛ АЁСіДТ 5 АГРЧ cluster ЗЮ НУРлЧбДй. БзИЎАэ ГЊМ 2 АГРЧ АЁРх АЁБюПю cluster АЁ КДЧеЕШДй. РЇРЧ ЧЅПЁМ АЁРх РлРК МіДТ 4 РЬАэ sample 1 Ањ 2 ЛчРЬРЧ АХИЎРЬДй. ЕћЖѓМ cluster {1} Ањ {2} АЁ КДЧеЕШДй. РЬЖЇДТ ДйРНРЧ 4 АГРЧ cluster АЁ ЕШДй.
{1, 2}, {3}, {4}, {5}
ДйРНПЁДТ 4 АГРЧ cluster АЃРЧ АХИЎАЁ ДйРН ЧрЗФАњ ААРЬ СжОюСјДй.
|
|
{1, 2} |
3 |
4 |
5 |
|
{1, 2} 3 4 5 |
- 8.1 16.0 17.9 |
8.1 - 9.8 9.8 |
16.0 9.8 - 8.0 |
17.9 9.8 8.0 - |
Чр {1, 2} Ањ П 3 РЇФЁПЁ РжДТ АЊ 8.1 РК cluster
{1, 2} Ањ {3} ЛчРЬРЧ АХИЎРЬИч ДйРНАњ ААРЬ АшЛъЕШДй. РЇРЧ УЙ ЙјТА ЧЅПЁМ  РЬИч
РЬИч  РЛ КИПЉСиДй. single cluster algorithm ПЁМДТ ЕЮ АЊСпПЁМ УжМвАЊ 8.1РЛ cluster
АЃРЧ АХИЎЗЮ МБХУЧбДй. УЙТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ АшЛъЕШДй. УЙТА ЧрАњ
П РЬПмРЧ ДйИЅ АЊЕщРК Бз ДыЗЮ НТАшЧбДй. ДйРНРИЗЮ ЧрЗФЧЅПЁМРЧ УжМвАЊРЬ 8 РЬБт
ЖЇЙЎПЁ cluster {4} ПЭ {5} АЁ КДЧеЕШДй. ЕћЖѓМ 3 АГРЧ cluster АЁ ЕШДй.
РЛ КИПЉСиДй. single cluster algorithm ПЁМДТ ЕЮ АЊСпПЁМ УжМвАЊ 8.1РЛ cluster
АЃРЧ АХИЎЗЮ МБХУЧбДй. УЙТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ АшЛъЕШДй. УЙТА ЧрАњ
П РЬПмРЧ ДйИЅ АЊЕщРК Бз ДыЗЮ НТАшЧбДй. ДйРНРИЗЮ ЧрЗФЧЅПЁМРЧ УжМвАЊРЬ 8 РЬБт
ЖЇЙЎПЁ cluster {4} ПЭ {5} АЁ КДЧеЕШДй. ЕћЖѓМ 3 АГРЧ cluster АЁ ЕШДй.
{1, 2}, {3}, {4, 5}
3 АГРЧ cluster АЃРЧ АХИЎДТ ДйРН ЧрЗФЧЅПЭ ААДй.
|
|
{1, 2} |
3 |
{4, 5} |
|
{1, 2} 3 {4, 5} |
- 8.1 16.0 |
8.1 - 9.8 |
16.0 9.8 - |
РЇ ЧЅПЁМРЧ УжМвАЊРК 8.1 РЬБт ЖЇЙЎПЁ cluster {1, 2} ПЭ {3} РЬ КДЧеЕЧОю 2 АГРЧ cluster ЗЮ ЕШДй.
{1, 2, 3}, {4, 5}
ДйРНРИЗЮ АХИЎ 9.8ПЁМ ГВОЦРжДТ cluster ЕЮ АГИІ КДЧеЧбДй. РЬЗЁМ hierarchical clustering РЬ ПЯМКЕЧИч Бз tree РК ДйРНАњ ААДй.
КДЧеЧЯДТ cluster АЃРЧ АХИЎ  РК vertical УрПЁМ КМ Мі РжДй.
РК vertical УрПЁМ КМ Мі РжДй.
ДйИЅ РЬИЇРИЗЮДТ maximum method
ЖЧДТ farthest neighbor method ЖѓАэЕЕ КвИАДй. МЗЮ ДйИЅ cluster
ПЁ РЇФЁЧЯДТ sample Ещ АЃПЁ АЁРх ХЋ АХИЎИІ ЕЮ cluster АЃРЧ АХИЎЗЮ СЄРЧЧЯПЉ
БИЧЯПЉСјДй. ЕЮ cluster 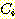 ПЭ
ПЭ 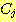 ЛчРЬРЧ АХИЎДТ ДйРНАњ ААРЬ СЄРЧЕШДй.
ЛчРЬРЧ АХИЎДТ ДйРНАњ ААРЬ СЄРЧЕШДй.
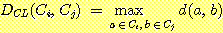
Example 5.2 complete linkage algorithmРЛ ЛчПыЧб hierarchical clustering
ДйРН БзИВАњ ААРЬ data АЁ КаЦїЧбДйАэ ЧЯРк. sample АЃРЧ АХИЎ УјСЄРЛ РЇЧи Euclidean distanceИІ ЛчПыЧЯЖѓ
ДйРН ЧЅДТ АЂ sample РЧ feature АЊАњ sample НжЕщ
АЃРЧ АХИЎ 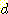 ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
ЧЯГЊРЧ sampleРЛ ЦїЧдЧЯДТ ДйМИ АГРЧ cluster ЗЮ НУРлЧбДй. АЁРх АЁБюРЬ РжДТ cluster {1} ПЭ {2} ДТ КДЧеЕЧОю ЛѕЗЮПю clusterИІ ИИЕчДй.
{1, 2}, {3}, {4}, {5}
РЬ cluster АЃРЧ АХИЎИІ БИЧб ЧрЗФРЬ ДйРНАњ ААДй.
|
|
{1, 2} |
3 |
4 |
5 |
|
{1, 2} 3 4 5 |
- 11.7 20.0 21.5 |
11.7 - 9.8 9.8 |
20.0 9.8 - 8.0 |
21.5 9.8 8.0 - |
Чр {1, 2} Ањ П 3 РЇФЁРЧ АЊРК 11.7 РЬИч РЬАЭРК cluster {1, 2} ПЭ {3} ЛчРЬРЧ АХИЎИІ РЧЙЬЧЯИч БзАЭРК ДйРНАњ ААРЬ БИЧиСјДй.
ПјЗЁ СжОюСј dataПЁМ  ПЭ
ПЭ  РЧ АЊРЬ СжОюСіИч complete linkage ОЫАэИЎСђПЁМДТ УжДыАЊРЮ
11.7РЛ cluster АЃРЧ АХИЎИІ МБХУЧбДй. УЙ ЙјТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ
БИЧиСјДй. УЙТА ЧрАњ ЋRТА П РЬПмРЧ АЊРК БзЗЁЕЕ НТАшЧбДй. Бз ЖЇ ЧрЗФПЁМРЧ УжМвАЊРК
8 РЬИч ЕћЖѓМ cluster {4} ПЭ {5} АЁ КДЧеЧбДй. РЬЖЇРЧ cluster ДТ ДйРНАњ ААДй.
РЧ АЊРЬ СжОюСіИч complete linkage ОЫАэИЎСђПЁМДТ УжДыАЊРЮ
11.7РЛ cluster АЃРЧ АХИЎИІ МБХУЧбДй. УЙ ЙјТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ
БИЧиСјДй. УЙТА ЧрАњ ЋRТА П РЬПмРЧ АЊРК БзЗЁЕЕ НТАшЧбДй. Бз ЖЇ ЧрЗФПЁМРЧ УжМвАЊРК
8 РЬИч ЕћЖѓМ cluster {4} ПЭ {5} АЁ КДЧеЧбДй. РЬЖЇРЧ cluster ДТ ДйРНАњ ААДй.
{1, 2}, {3}, {4, 5}
РЬ cluster АЃРЧ АХИЎДТ ДйРН ЧрЗФАњ ААРЬ БИЧиСјДй.
|
|
{1, 2} |
3 |
{4, 5} |
|
{1, 2} 3 {4, 5} |
- 11.7 21.5 |
11.7 - 9.8 |
21.5 9.8 - |
РЇ ЧрЗФРЧ УжМвАЊРК 9.8 РЬБт ЖЇЙЎПЁ cluster {3} Ањ {4, 5} АЁ КДЧеЕЧОю clusterДТ ДйРНАњ ААДй.
{1, 2}, {3, 4, 5}
РЇРЧ cluster ДТ single linkage algorithm РЧ ЕПЕюЧб РЇФЁПЁМРЧ БИЧиСј cluster ПЭДТ ДйИЅ АЭРЛ ОЫ Мі РжДй. ДйРН АњСЄРИЗЮ ГВОЦРжДТ cluster ЕщРЬ КДЧеЕЧОю hierarchical clustering РЬ ПЯМКЕЧИч Бз tree РК ДйРНАњ ААДй.
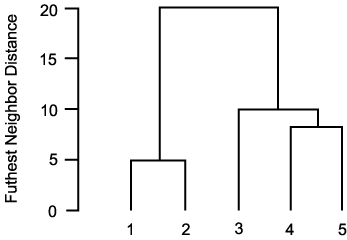
single linkage algorithm РК tree ЛѓПЁМ cluster ЕщРЬ БцАэ АЁДТ(long and thin) И№ОчРЛ КИРЯ Мі РжДй. complete linkage algorithm ПЁМДТ КИДй compact Чб И№ОчРЛ КИРЮДй. ЕЮ clustering ЙцЙ§ И№ЕЮ КёСЄЛѓРћРЮ АќТћПЁ ЙЮАЈЧЯПЉ КЏЧќЕЩ Мі РжДй. ЕЮ ОЫАэИЎСђРЧ БиДмРЛ Р§УцЧЯБт РЇЧб ЙцЙ§РЬ average linkage algorithm РЬДй.
average linkage algorithm РК ДйИЅ РЬИЇРИЗЮДТ
unweighted pair group method using arithmetic average (UPGMA) ЖѓАэЕЕ КвИЎПьИч
АЁРх ГЮИЎ ЛчПыЕЧДТ hierarchical clustering algorithm Сп ЧЯГЊРЬДй. МЗЮ
ДйИЅ cluster ПЁ МгЧб ЕЮ СЁ ЛчРЬРЧ ЦђБе АХИЎИІ ЕЮ cluster АЃРЧ АХИЎЗЮ СЄРЧ ЧдРИЗЮНс
average linkage algorithm РЬ МіЧрЕШДй. ИИРЯ cluster 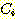 АЁ
АЁ 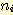 АГРЧ ИтЙіАЁ РжАэ, cluster
АГРЧ ИтЙіАЁ РжАэ, cluster 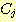 АЁ
АЁ 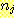 АГРЧ ИтЙіИІ АЁСњ АцПь ЕЮ cluster АЃРЧ АХИЎДТ ДйРНАњ ААДй.
АГРЧ ИтЙіИІ АЁСњ АцПь ЕЮ cluster АЃРЧ АХИЎДТ ДйРНАњ ААДй.
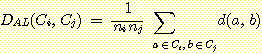
Example 5.3 average linkage algorithmРЛ ЛчПыЧб hierarchical clustering
ДйРН БзИВАњ ААРЬ data АЁ КаЦїЧбДйАэ ЧЯРк. sample АЃРЧ АХИЎ УјСЄРЛ РЇЧи Euclidean distanceИІ ЛчПыЧЯЖѓ
ДйРН ЧЅДТ АЂ sample РЧ feature АЊАњ sample НжЕщ
АЃРЧ АХИЎ 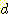 ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
ЧЯГЊРЧ sampleРЛ ЦїЧдЧЯДТ ДйМИ АГРЧ cluster ЗЮ НУРлЧбДй. АЁРх АЁБюРЬ РжДТ cluster {1} ПЭ {2} ДТ КДЧеЕЧОю ЛѕЗЮПю clusterИІ ИИЕчДй.
{1, 2}, {3}, {4}, {5}
РЬ cluster АЃРЧ АХИЎИІ БИЧб ЧрЗФРЬ ДйРНАњ ААДй.
|
|
{1, 2} |
3 |
4 |
5 |
|
{1, 2} 3 4 5 |
- 9.9 18 19.7 |
9.9 - 9.8 9.8 |
18.0 9.8 - 8.0 |
19.7 9.8 8.0 - |
Чр {1, 2} Ањ П 3 РЇФЁРЧ АЊРК 9.9 РЬИч РЬАЭРК cluster {1, 2} ПЭ {3} ЛчРЬРЧ АХИЎИІ РЧЙЬЧЯИч БзАЭРК ДйРНАњ ААРЬ БИЧиСјДй.
ПјЗЁ СжОюСј dataПЁМ  ПЭ
ПЭ  РЧ АЊРЬ СжОюСіИч average linkage ОЫАэИЎСђПЁМДТ ЦђБеАЊРЮ
9.9ИІ cluster АЃРЧ АХИЎЗЮ МБХУЧбДй. УЙ ЙјТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ
БИЧиСјДй. УЙТА ЧрАњ ЋRТА П РЬПмРЧ АЊРК БзЗЁЕЕ НТАшЧбДй. Бз ЖЇ ЧрЗФПЁМРЧ УжМвАЊРК
8 РЬИч ЕћЖѓМ cluster {4} ПЭ {5} АЁ КДЧеЧбДй. РЬЖЇРЧ cluster ДТ ДйРНАњ ААДй.
РЧ АЊРЬ СжОюСіИч average linkage ОЫАэИЎСђПЁМДТ ЦђБеАЊРЮ
9.9ИІ cluster АЃРЧ АХИЎЗЮ МБХУЧбДй. УЙ ЙјТА ЧрРЧ ДйИЅ АЊЕщЕЕ ААРК ЙцЙ§РИЗЮ
БИЧиСјДй. УЙТА ЧрАњ ЋRТА П РЬПмРЧ АЊРК БзЗЁЕЕ НТАшЧбДй. Бз ЖЇ ЧрЗФПЁМРЧ УжМвАЊРК
8 РЬИч ЕћЖѓМ cluster {4} ПЭ {5} АЁ КДЧеЧбДй. РЬЖЇРЧ cluster ДТ ДйРНАњ ААДй.
{1, 2}, {3}, {4, 5}
РЬ cluster АЃРЧ АХИЎДТ ДйРН ЧрЗФАњ ААРЬ БИЧиСјДй.
|
|
{1, 2} |
3 |
{4, 5} |
|
{1, 2} 3 {4, 5} |
- 9.9 18.9 |
9.9 - 9.8 |
18.9 9.8 - |
РЇ ЧрЗФРЧ УжМвАЊРК 9.8 РЬБт ЖЇЙЎПЁ cluster {3} Ањ {4, 5} АЁ КДЧеЕЧОю clusterДТ ДйРНАњ ААДй.
{1, 2}, {3, 4, 5}
ДйРН АњСЄРИЗЮ ГВОЦРжДТ cluster ЕщРЬ КДЧеЕЧОю hierarchical clustering РЬ ПЯМКЕШДй.
ДйИЅ РЬИЇРИЗЮДТ minimum variance method ЖѓАэЕЕ ЧбДй. ДйИЅ ОЫАэИЎСђ УГЗГ АЂ sampleРЛ РЇЧб ЧЯГЊРЧ cluster ЗЮНс НУРлЧбДй. И№Еч cluster Нж ЛчРЬПЁМ ЙнКЙРЛ ХыЧи АЁРх РлРК squared errorИІ АЁСіДТ НжРЛ КДЧеЧЯПЉ ЛѕЗЮПю clusterИІ ИИЕчДй. АЂ clusterИІ РЇЧб squared errorДТ ДйРНАњ ААРЬ СЄРЧЕШДй.
ЧЯГЊРЧ cluster АЁ 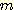 АГРЧ sample (
АГРЧ sample ( , ПЉБтМ
, ПЉБтМ  ДТ feature vector
ДТ feature vector 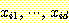 ) РЛ ЦїЧдЧбДйИщ, sample
) РЛ ЦїЧдЧбДйИщ, sample  РЧ squared error (ЦђБеПЁМРЧ squared Euclidean distance)ДТ ДйРНАњ ААДй.
РЧ squared error (ЦђБеПЁМРЧ squared Euclidean distance)ДТ ДйРНАњ ААДй.
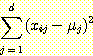
ПЉБтМ 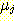 ДТ clusterПЁМ sampleЕщРЛ РЇЧб feature
ДТ clusterПЁМ sampleЕщРЛ РЇЧб feature  РЧ ЦђБеАЊРЬДй.
РЧ ЦђБеАЊРЬДй.

РќУМ cluster ПЁ ДыЧб squared error 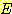 ДТ sample ЕщРЧ squared error ЕщРЧ ЧеРЬДй.
ДТ sample ЕщРЧ squared error ЕщРЧ ЧеРЬДй.
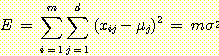
АЂ feature РЧ ЦђБеАЊРИЗЮ БИМКЕШ vector  РК Бз cluster РЧ mean vector ЖЧДТ centroid ЖѓАэ КвИЎПюДй. ЧЯГЊРЧ clusterИІ
РЇЧб squared error ДТ АЂ featureПЁМ cluster ИтЙіЗЮКЮХЭ БзЕщРЧ ЦђБеАЊБюСіРЧ
squared distance РЧ ЧеРЬДй. squared errorДТ cluster РЧ total variance
РК Бз cluster РЧ mean vector ЖЧДТ centroid ЖѓАэ КвИЎПюДй. ЧЯГЊРЧ clusterИІ
РЇЧб squared error ДТ АЂ featureПЁМ cluster ИтЙіЗЮКЮХЭ БзЕщРЧ ЦђБеАЊБюСіРЧ
squared distance РЧ ЧеРЬДй. squared errorДТ cluster РЧ total variance 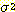 ПЁДйАЁ cluster РЧ sampleРЧ Мі
ПЁДйАЁ cluster РЧ sampleРЧ Мі 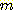 РЛ АіЧб АЭАњ ААДй. ПЉБтМ total varianceДТ АЂ feature РЧ variance РЧ ЧеРИЗЮНс
РЛ АіЧб АЭАњ ААДй. ПЉБтМ total varianceДТ АЂ feature РЧ variance РЧ ЧеРИЗЮНс
 ЗЮ СЄРЧЕШДй. РЯЗУРЧ clusterЕщРЛ РЇЧб squared error ДТ АЂ clusterЕщРЛ РЇЧб
squared error ЕщРЧ ЧеРИЗЮ СЄРЧЕШДй.
ЗЮ СЄРЧЕШДй. РЯЗУРЧ clusterЕщРЛ РЇЧб squared error ДТ АЂ clusterЕщРЛ РЇЧб
squared error ЕщРЧ ЧеРИЗЮ СЄРЧЕШДй.
Example 5.4 Ward's methodИІ ЛчПыЧб hierarchical clustering
ДйРН БзИВАњ ААРЬ data АЁ КаЦїЧбДйАэ ЧЯРк.
ДйРН ЧЅДТ АЂ sample РЧ feature АЊАњ sample НжЕщ
АЃРЧ АХИЎ 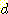 ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
РЬЖЇ squared error ДТ zero РЬДй. cluster НжРЛ КДЧеЧЯДТ ЙцЙ§РК 10 АЁСіАЁ РжДй. cluster {1} Ањ {2} КДЧе, {1} Ањ {3} КДЧеЕюЕю.
ДйРН ЧЅДТ АЁДЩЧб ЙцЙ§РЧ squared errorИІ КИПЉСиДй. ПЙИІЕщИщ cluster {1} ПЭ {2}ИІ КДЧеЧбДйАэ ЧЯРк. sample 1 РЧ feature vector ДТ (4,4) РЬАэ sample 2 ДТ (8,4) РЬИч ЕћЖѓМ feature ЦђБеРК 6 Ањ 4 РЬДй. cluster {1, 2}ИІ РЇЧб squared error ДТ ДйРНАњ ААРЬ БИЧиСјДй.
(4 - 6)2 + (8 - 6)2 + (4 - 4)2 + (4 - 4)2 = 8
ДйИЅ АЂАЂРЧ cluster {3}, {4}, {5} РЧ squared error ДТ 0 РЬДй. ЕћЖѓМ cluster {1, 2}, {3}, {4}, {5} РЧ total squared error ДТ ДйРНАњ ААДй.
8 + 0 + 0 + 0 = 8
ДйРН ЧЅПЁМ АЁРх РлРК squared error ДТ 8 РЬБт ЖЇЙЎПЁ cluster {1} ПЭ {2} ДТ КДЧеЕЧОю 4 АГРЧ cluster {1, 2}, {3}, {4}, {5}ИІ ИИЕчДй.
|
Clusters |
Squared |
|
{1, 2}, {3}, {4}, {5} {1, 3}, {2}, {4}, {5} {1, 4}, {2}, {3}, {5} {1, 5}, {2}, {3}, {4} {2, 3}, {1}, {4}, {5} {2, 4}, {1}, {3}, {5} {2, 5}, {1}, {3}, {5} {3, 4}, {1}, {2}, {5} {3, 5}, {1}, {2}, {4} {4, 5}, {1}, {2}, {3} |
8.0 68.5 200.0 232.0 32.5 128.0 160.0 48.5 48.5 32.0 |
4 АГРЧ clusterИІ ИИЕщ АцПьРЧ АЂАЂРЧ squared error
ДйРН ЧЅПЁМДТ {1, 2}, {3}, {4}, {5} СпПЁМ 2 АГИІ КДЧеЧЯДТ АЁДЩЧб АцПьРЧ squared errorИІ КИПЉСиДй. ДйРНЧЅПЁМ АЁРх РлРК squared error ДТ 40 РЬБт ЖЇЙЎПЁ cluster {4} ПЭ {5} АЁ КДЧеЕЧОю 3 АГРЧ clusterИІ ИИЕчДй.
{1, 2}, {3}, {4, 5}
|
Clusters |
Squared |
|
{1, 2, 3}, {4}, {5} {1, 2, 4}, {3}, {5} {1, 2, 5}, {3}, {4} {1, 2}, {3, 4}, {5} {1, 2}, {3, 5}, {4} {1, 2}, {4, 5}, {3} |
72.7 224.0 266.7 56.5 56.5 40.0 |
3 АГРЧ clusterИІ ИИЕщ АцПьРЧ АЂАЂРЧ squared error
ДйРН ЧЅПЁМДТ {1, 2}, {3}, {4, 5} СпПЁМ 2 АГИІ КДЧеЧЯДТ АЁДЩЧб АцПьРЧ squared errorИІ КИПЉСиДй. ДйРНЧЅПЁМ АЁРх РлРК squared error ДТ 94 РЬБт ЖЇЙЎПЁ cluster {3} Ањ {4, 5} АЁ КДЧеЕЧОю 2 АГРЧ clusterИІ ИИЕчДй.
{1, 2}, {3, 4, 5}
|
Clusters |
Squared |
|
{1, 2, 3}, {4, 5} {1, 2, 4, 5}, {3} {1, 2}, {3, 4, 5} |
104.7 380.0 94.0 |
2 АГРЧ clusterИІ ИИЕщ АцПьРЧ АЂАЂРЧ squared error
ДйРНРИЗЮ ГВРК 2 АГРЧ cluster АЁ КДЧеЕЧОю hierarchical clustering РЬ ПЯМКЕШДй. ДйРН БзИВРК ПЯМКЕШ treeИІ КИПЉСиДй.
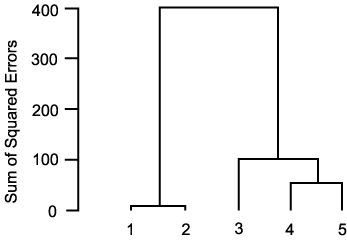
Ward's ЙцЙ§ПЁ РЧЧб ЦЎИЎ
cluster РЧ АшУўРЛ АэЗСЧЯСі ОЪАэ ЦђИщРћРИЗЮ clustering ЧЯДТ ЙцЙ§РИЗЮ РЯЙнРћРИЗЮ ЙЬИЎ Ию АГРЧ cluster ЗЮ ГЊДЉОю Сњ АЭРЬЖѓАэ ПЙЛѓЧЯАэ cluster РЧ АГМіИІ СЄЧЯДТ АЭРЬДй.
АЁРх АЃДмЧб partitional clustering algorithm
СпРЧ ЧЯГЊАЁ Forgy's algorithm РЬДй. data РЬПмПЁ cluster РЧ Мі 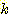 ИІ input РИЗЮ ЧЯИч РЬЖЇ
ИІ input РИЗЮ ЧЯИч РЬЖЇ 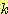 ИІ seed point ЖѓАэ ЧбДй. seed point ДТ РгРЧЗЮ МБХУЕЧИч ЙйЖїСїЧб cluster
БИСЖПЁ АќЧб ОюЖВ СіНФЕщРЬ seed pointИІ МБХУЧЯДТЕЅПЁ ЛчПыЕЩ Мі РжДй. Бз АњСЄРК
ДйРНАњ ААДй.
ИІ seed point ЖѓАэ ЧбДй. seed point ДТ РгРЧЗЮ МБХУЕЧИч ЙйЖїСїЧб cluster
БИСЖПЁ АќЧб ОюЖВ СіНФЕщРЬ seed pointИІ МБХУЧЯДТЕЅПЁ ЛчПыЕЩ Мі РжДй. Бз АњСЄРК
ДйРНАњ ААДй.
1. РгРЧРЧ АЙМіРЧ seed pointИІ cluster centroid ЗЮМ УЪБтШ ЧбДй.
2. АЂ sample ПЁ ДыЧи АЁРх АЁБюРЬ РжДТ cluster centroidИІ УЃОЦМ ЧиДч cluster ПЁ sampleРЛ ЙшСЄЧбДй.
3. ИИРЯ step 2ПЁМ sample РЬ clusterИІ КЏШНУХАСі ИјЧЯИщ СОЗсЧбДй.
4. КЏШЕШ cluster ЕщПЁ ДыЧб centroidИІ ДйНУ АшЛъЧиМ ДйНУ step 2 ЗЮ АЃДй.
Example 5.5 Forgy's algorithmРЛ ЛчПыЧб partitional clustering
ДйРН БзИВАњ ААРЬ data АЁ КаЦїЧбДйАэ ЧЯРк.
ДйРН ЧЅДТ АЂ sample РЧ feature 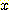 ,
, 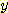 АЊАњ sample НжЕщ
АЃРЧ АХИЎ
АЊАњ sample НжЕщ
АЃРЧ АХИЎ 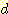 ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
step 1, УГРНПЁ 2 АГРЧ clusterИІ  ЗЮ ЕЮАэ seed point ЗЮМ АЂ cluster ДТ УжУЪРЧ ЕЮ sample (4,4), (8,4)ИІ ЛчПыЧбДй.
Forgy's algorithmПЁМДТ АшЛъПЁМРЧ ЦэРЧИІ РЇЧи sampleЕщРЧ МіКИДйДТ feature vector
ЗЮМ sample ЕщРЛ ЧЅБтЧбДй.
ЗЮ ЕЮАэ seed point ЗЮМ АЂ cluster ДТ УжУЪРЧ ЕЮ sample (4,4), (8,4)ИІ ЛчПыЧбДй.
Forgy's algorithmПЁМДТ АшЛъПЁМРЧ ЦэРЧИІ РЇЧи sampleЕщРЧ МіКИДйДТ feature vector
ЗЮМ sample ЕщРЛ ЧЅБтЧбДй.
step 2, АЂ sampleПЁМ АЁРх АЁБюРЬ РжДТ cluster centroidИІ УЃДТДй. ДйРН ЧЅПЁМДТ Бз АсАњИІ КИПЉСиДй. cluster 2 АГ {(4, 4)} ПЭ {(8, 4), (15, 8), (24, 4), (24, 12)} АЁ ИИЕщОю СГДй.
step 4, cluster ЕщРЛ РЇЧб centroidИІ АшЛъЧбДй. УЙ ЙјТА cluster РЧ centroid ДТ (4,4) РЬИч ЕЮ ЙјТАДТ (17.75, 7) РЬИч БзАЭРК ДйРНАњ ААРЬ АшЛъЕЧОњДй.
(8 + 15 + 24 + 24) / 4 = 17.75
(4 + 8 + 4 + 12) / 4 = 7
sampleЕщРЬ cluster ЕщРЛ КЏШНУФзБт (УГРНПЁДТ cluster АЁ ОјОњРИДЯБю) ЖЇЙЎПЁ step 2 ЗЮ ЕЙОЦАЃДй.
|
Sample |
Nearest |
|
(4, 4) (8, 4) (15, 8) (24, 4) (24, 12) |
(4, 4) (8, 4) (8, 4) (8, 4) (8, 4) |
Forgy's algorithm РЧ УЙ ЙјТА ЙнКЙ
ДйРН ЧЅПЁМДТ АЂ sample ЕщПЁ АЁРх АЁБюПю cluster centroidИІ УЃДТДй. cluster {(4, 4), (8, 4)} ПЭ {(15, 8), (24, 4), (24, 12)} РЬ ИИЕщОю СГДй.
step 4, cluster РЧ centroid (6, 4) ПЭ (21, 8) РЬ АшЛъЕШДй. sample (8, 4) АЁ cluster ЕщРЛ КЏШНУФзАэ ЕћЖѓМ step 2 ЗЮ АЃДй.
|
Sample |
Nearest |
|
(4, 4) (8, 4) (15, 8) (24, 4) (24, 12) |
(4, 4) (4, 4) (17.75, 7) (17.75, 7) (17.75, 7) |
Forgy's algorithm РЧ ЕЮ ЙјТА ЙнКЙ
ДйРН ЧЅПЁМДТ АЂ sample ЕщПЁ АЁРх АЁБюПю cluster centroidИІ УЃДТДй. cluster {(4, 4), (8, 4)} ПЭ {(15, 8), (24, 4), (24, 12)} РЬ ИИЕщОю СГДй.
step 4, cluster РЧ centroid (6, 4) ПЭ (21, 8) РЬ АшЛъЕШДй. ОюЖВ sample ЕЕ cluster ЕщРЛ КЏШНУХАСі ОЪОвБт ЖЇЙЎПЁ ОЫАэИЎСђРК СОЗсЕШДй.
|
Sample |
Nearest |
|
(4, 4) (8, 4) (15, 8) (24, 4) (24, 12) |
(6, 4) (6, 4) (21, 8) (21, 8) (21, 8) |
Forgy's algorithm РЧ ММ ЙјТА ЙнКЙ
РЇ ПЙСІПЁМДТ seed pointИІ УГРНРЧ
ЕЮ sampleЕщЗЮ РгРЧЗЮ МБХУЕЧОњДй. БзЗЏГЊ ДйИЅ АЁДЩМКРЬ СІОШЕЩ Мі РжДй. ЧЯГЊРЧ
АЁДЩМКРК hierarchical clustering algorithm СпРЧ ЧЯГЊЗЮ ИИЕщОюСј 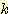 cluster ЗЮ НУРлЧЯПЉ УжУЪРЧ seed point ЗЮМ Бз centroidИІ ЛчПыЧЯДТ АЭРЬДй.
cluster ЗЮ НУРлЧЯПЉ УжУЪРЧ seed point ЗЮМ Бз centroidИІ ЛчПыЧЯДТ АЭРЬДй.
Forgy's algorithm Ањ РЏЛчЧб ЙцЙ§РЬДй. data РЬПмПЁ cluster РЧ Мі 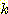 ИІ input РИЗЮ ЧЯИч РЬЖЇ
ИІ input РИЗЮ ЧЯИч РЬЖЇ 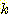 ИІ seed point ЖѓАэ ЧбДй. Forgy' algorithm Ањ ДйИЅСЁРК ЧЯГЊРЧ
sample РЬ ЧЯГЊРЧ cluster ПЁ ЧеЗљЧЯРкИЖРк А№ cluster РЧ centroid АЁ ДйНУ АшЛъЕШДйДТ
АЭРЬДй. ЖЧЧб Forgy' algorithm РЬ ЙнКЙРћ(iterative) Чб ЙнИщПЁ
ИІ seed point ЖѓАэ ЧбДй. Forgy' algorithm Ањ ДйИЅСЁРК ЧЯГЊРЧ
sample РЬ ЧЯГЊРЧ cluster ПЁ ЧеЗљЧЯРкИЖРк А№ cluster РЧ centroid АЁ ДйНУ АшЛъЕШДйДТ
АЭРЬДй. ЖЧЧб Forgy' algorithm РЬ ЙнКЙРћ(iterative) Чб ЙнИщПЁ 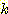 -means algorithm РК data setПЁМ ДмСі ЕЮ ЙјИИРЧ pass АЁ РЬЗчОюСјДй. Бз АњСЄРК
ДйРНАњ ААДй.
-means algorithm РК data setПЁМ ДмСі ЕЮ ЙјИИРЧ pass АЁ РЬЗчОюСјДй. Бз АњСЄРК
ДйРНАњ ААДй.
1. УГРНПЁ 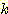 cluster ЗЮМ НУРлЧбДй. ГВОЦРжДТ
cluster ЗЮМ НУРлЧбДй. ГВОЦРжДТ  sampleЕщПЁ ДыЧиМДТ АЁРх АЁБюРЬ РжДТ centroidИІ УЃДТДй. РЬАЭПЁ АЁРх
АЁБюРЬ РжДТ centroidИІ АЁСіДТ АЭРЬ ШЎРЮЕШ cluster ПЁ sampleРЛ ЦїЧдНУХВДй. АЂАЂРЧ
sample ЕщРЬ ЧвДчЕШ ШФПЁ ЧвДчЕШ cluster РЧ centroid АЁ ДйНУ АшЛъЕШДй.
sampleЕщПЁ ДыЧиМДТ АЁРх АЁБюРЬ РжДТ centroidИІ УЃДТДй. РЬАЭПЁ АЁРх
АЁБюРЬ РжДТ centroidИІ АЁСіДТ АЭРЬ ШЎРЮЕШ cluster ПЁ sampleРЛ ЦїЧдНУХВДй. АЂАЂРЧ
sample ЕщРЬ ЧвДчЕШ ШФПЁ ЧвДчЕШ cluster РЧ centroid АЁ ДйНУ АшЛъЕШДй.
2. Бз dataИІ ЕЮ Йј УГИЎЧбДй. АЂ sampleПЁ ДыЧЯПЉ АЁРх АЁБюРЬ РжДТ centroidИІ УЃДТДй. АЁРх АЁБюРЬ РжДТ centroidИІ АЁСј АЭРИЗЮ ШЎРЮЕШ cluster ПЁ sampleРЛ РЇФЁНУХВДй. (РЬ step ПЁМДТ ОюЖВ centroid ЕЕ ДйНУ АшЛъЧЯСі ОЪДТДй.)
Example 5.6
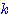 -means algorithmРЛ ЛчПыЧб partitional clustering
-means algorithmРЛ ЛчПыЧб partitional clustering
ДйРН БзИВАњ ААРЬ data АЁ КаЦїЧбДйАэ ЧЯРк.
ДйРН ЧЅДТ АЂ sample РЧ feature 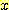 ,
, 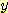 АЊАњ sample НжЕщ
АЃРЧ АХИЎ
АЊАњ sample НжЕщ
АЃРЧ АХИЎ 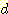 ИІ КИПЉСиДй.
ИІ КИПЉСиДй.
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
|
1 2 3 4 5 |
4 8 15 24 24 |
4 4 8 4 12 |
|
1 2 3 4 5 |
- 4.0 11.7 20.0 21.5 |
4.0 - 8.1 16.0 17.9 |
11.7 8.1 - 9.8 9.8 |
20.0 16.0 9.8 - 8.0 |
21.5 17.9 9.8 8.0 - |
УГРНПЁ 2 АГРЧ clusterИІ  ЗЮ ЕЮАэ УГРНРЧ ЕЮ sample ЕщРК (8,4) ПЭ (24,4) ЗЮ ЧбДй.
ЗЮ ЕЮАэ УГРНРЧ ЕЮ sample ЕщРК (8,4) ПЭ (24,4) ЗЮ ЧбДй.
step 1
ЕЮ АГРЧ cluster {(8, 4} ПЭ {(24, 4)} ЗЮ НУРлЧЯИч БзАЭРК (8, 4) ПЭ (24, 4) ПЁ centroidИІ АЎДТДй. ГЊИгСі 3 АГРЧ sample АЂАЂПЁ ДыЧиМДТ АЁРх АЁБюРЬ РжДТ centroidИІ УЃАэ Бз cluster ПЁ sampleРЛ ЕЮАэ cluster РЧ centroidИІ ДйНУ АшЛъЧбДй.
ДйРН sample (15, 8) РК centroid (8, 4) ПЁ АЁРх АЁБѕАэ ЕћЖѓМ cluster {(8, 4)} ПЁ ЧеЗљЧбДй. РЬЖЇПЁ cluster ЕщРК {(8, 4), (15, 8)} ПЭ {(24, 4)} РЬДй. УЙ ЙјТА cluster РЧ centroid ДТ (11.5, 6) ЗЮ ЙйВюДТЕЅ БзАЭРК ДйРНАњ ААРЬ АшЛъЕШ АЭРЬДй.
(8 + 15) / 2 = 11.5, (4 + 8) / 2 = 6
ДйРН sample (4, 4) РК centroid (11.5, 6) ПЁ АЁРх АЁБѕАэ ЕћЖѓМ cluster {(8, 4), (15, 8)} ПЁ ЧеЗљЧбДй. РЬЖЇПЁ cluster ЕщРК {(8, 4), (15, 8), (4, 4)} ПЭ {(24, 4)} РЬДй. УЙ ЙјТА cluster РЧ centroid ДТ (9, 5.3) ЗЮ ЙйВяДй.
ДйРН sample (24, 12) РК centroid (24, 4) ПЁ АЁРх АЁБѕАэ ЕћЖѓМ cluster {(24, 4)} ПЁ ЧеЗљЧбДй. РЬЖЇПЁ cluster ЕщРК {(8, 4), (15, 8), (4, 4)} ПЭ {(24, 12), (24, 4)} РЬДй. РЬЖЇ ЕЮ ЙјТА cluster РЧ centroid ДТ (24, 8) ЗЮ ЙйВяДй. РЬЖЇПЁ ОЫАэИЎСђРЧ step 1 РК ПЯМКЕШДй.
step 2
sampleЕщРЛ ЧЯГЊОП АЫЛчЧЯАэ АЁРх АЁБюРЬ РжДТ centroidИІ АЁСіДТ АЭРИЗЮ ШЎРЮЕШ cluster ПЁ АЂ sampleРЛ РЇФЁНУХВДй. ДйРН ЧЅПЁМ КИПЉСіДТ АЭУГЗГ sample ЕщРЬ cluster ЕщРЛ КЏШНУХАСі ИјЧв АцПьПЁ УжСОРћРИЗЮ ДйРНРЧ cluster ЕщЗЮ КаЗљЕШДй.
{(8, 4), (15, 8), (4, 4)} ПЭ {(24, 12), (24, 4)}
|
Sample |
Distance to |
Distance to |
|
(8, 4) (24, 4) (15, 8) (4, 4) (24, 12) |
1.6 15.1 6.6 6.6 16.4 |
16.5 4.0 9.0 40.4 4.0 |
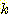 -means algorithm РЧ step 2ПЁМ ЛчПыЧЯБт РЇЧб distance
-means algorithm РЧ step 2ПЁМ ЛчПыЧЯБт РЇЧб distance
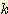 -means algorithm
-means algorithm  (8, (24, 12)
(8, (24, 12)
{(4, 4), (8, 4), (15, 8)}, {(24, 4), (24, 12)}
Isodata Algorithm РК Forgy's algorithm Ањ 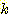 -means algorithm РЛ КИАЧб ЙцЙ§РИЗЮ Л§АЂЧв Мі РжДй. ААРК СЁРК АЁРх АЁБюРЬ
РжДТ centroid ПЁ sampleЕщРЛ ЧвДчЧЯПЉ squared errorИІ УжМвШ НУХВДйДТ АЭРЬДй.
ДйИЅСЁРК АэСЄЕШ МіРЧ cluster ЕщРЛ УГИЎЧЯДТ АЭРЬ ОЦДЯЖѓ, ЛчПыРкПЁ
РЧЧи ПфБИЕЧДТ cluster РЧ МіИІ ЦїЧдЧЯДТ ЙќРЇБюСі ЧуПыЕЧДТ
-means algorithm РЛ КИАЧб ЙцЙ§РИЗЮ Л§АЂЧв Мі РжДй. ААРК СЁРК АЁРх АЁБюРЬ
РжДТ centroid ПЁ sampleЕщРЛ ЧвДчЧЯПЉ squared errorИІ УжМвШ НУХВДйДТ АЭРЬДй.
ДйИЅСЁРК АэСЄЕШ МіРЧ cluster ЕщРЛ УГИЎЧЯДТ АЭРЬ ОЦДЯЖѓ, ЛчПыРкПЁ
РЧЧи ПфБИЕЧДТ cluster РЧ МіИІ ЦїЧдЧЯДТ ЙќРЇБюСі ЧуПыЕЧДТ 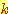 АГРЧ clusterИІ ДйЗщДйДТ АЭРЬДй. ИИРЯ cluster ЕщРЧ МіАЁ ГЪЙЋ ИЙОЦСіАХГЊ
cluster ЕщРЬ ГЪЙЋ АЁБюРЬ РжАд ЕЧИщ cluster ДТ КДЧеЕШДй.
ИИРЯ cluster ЕщРЧ МіАЁ ГЪЙЋ РћАХГЊ cluster АЁ ОЦСж ДйИЅ СОЗљРЧ sample ЕщРЛ ЦїЧдЧЯАэ
РжДйИщ cluster ДТ КаИЎЕШДй. РкММЧб АЭРК ДйРНПЁ ММњЧбДй.
АГРЧ clusterИІ ДйЗщДйДТ АЭРЬДй. ИИРЯ cluster ЕщРЧ МіАЁ ГЪЙЋ ИЙОЦСіАХГЊ
cluster ЕщРЬ ГЪЙЋ АЁБюРЬ РжАд ЕЧИщ cluster ДТ КДЧеЕШДй.
ИИРЯ cluster ЕщРЧ МіАЁ ГЪЙЋ РћАХГЊ cluster АЁ ОЦСж ДйИЅ СОЗљРЧ sample ЕщРЛ ЦїЧдЧЯАэ
РжДйИщ cluster ДТ КаИЎЕШДй. РкММЧб АЭРК ДйРНПЁ ММњЧбДй.
isodata algorithm РЧ АцПь data ПЭ seed point РЬПмПЁ ДйРНРЧ parameter ЕщРЬ ЧЪПфЧЯДй.
no_clusters : cluster РЧ ЙйЖїСїЧб МіЗЮМ seed point РЧ МіПЭ ААДй.
min_elements : АЂ cluster ИЖДй ЧуПыЕЧДТ sample ЕщРЧ УжМв АЙМі.
min_dist : КДЧеРЬ РЯОюГЊСі ОЪДТ, cluster centroid ЛчРЬПЁ ЧуПыЕЧДТ УжМв АХИЎ
split_size : cluster РЧ КаИЎИІ СЖР§ЧЯДТ parameter
iter_start : ОЫАэИЎСђРЧ first partПЁМ ЙнКЙ(iteration) РЧ УжДыМі
max_merge : АЂ ЙнКЙ(iteration) ПЁМРЧ cluster КДЧеРЧ УжДыМі
iter_body : ОЫАэИЎСђРЧ main part ГЛПЁМ ЙнКЙРЧ УжДыМі
РЬЗЏЧб parameter ЕщРК ОЫАэИЎСђ АњСЄПЁМ РкММШї МГИэЕШДй.
Isodata Algorithm РЧ АњСЄРК ДйРНАњ ААДй.
1. РгРЧРЧ АЙМіРЧ seed pointИІ cluster centroid ЗЮМ УЪБтШ ЧбДй.(step 1ПЁМ 4 БюСіДТ Forgy's algorithm Ањ ААДй)
2. АЂ sample ПЁ ДыЧи АЁРх АЁБюРЬ РжДТ cluster centroidИІ УЃОЦМ ЧиДч cluster ПЁ sampleРЛ ЙшСЄЧбДй.
3. КЏШЕШ cluster РЧ centroidИІ АшЛъЧбДй..
4. ИИРЯ РћОюЕЕ ЧЯГЊРЧ sample РЬ clusterИІ КЏШНУХААэ ЙнКЙЕЧДТ МіАЁ iter_start КИДй РлДйИщ, step 2 ЗЮ АЃДй.
5. min_elements КИДй РћРКМіРЧ sampleРЛ АЁСј cluster ДТ ЦѓБтЧбДй. ЖЧЧб ЦїЧдЕШ sample ЕщЕЕ ЦѓБтЧбДй.
6. ИИРЯ cluster РЧ МіАЁ 2 * no_clusters КИДй ХЉАХГЊ АААэ, ЖЧДТ ЙнКЙЕЧДТ МіАЁ ТІМі(even)РЬЖѓИщ step 7 (КДЧе ЕПРл)РЛ НЧЧрЧЯАэ БзЗИСі ОЪРИИщ step 8 ЗЮ АЃДй.
7. ИИРЯ ЕЮ centroid АЃРЧ АХИЎАЁ min_dist КИДй РлДйИщ ЕЮ clusterИІ КДЧеЧЯАэ centroidИІ КЏШНУХВДй. БзЗИСі ОЪРИИщ step 7 ЗЮ АЃДй. РЬЗЏЧб stepРЛ max_merge ЙјРЛ ЙнКЙЧЯАэ step 8 ЗЮ АЃДй.
8. ИИРЯ cluster РЧ МіАЁ no_clusters / 2 КИДй РлАХГЊ АААэ, ЖЧДТ ЙнКЙРЧ МіАЁ ШІМі(odd) ЖѓИщ step 9 (КаИЎ ЕПРл)РЛ МіЧрЧЯАэ БзЗИСі ОЪРИИщ step 10 РИЗЮ АЃДй.
9. split_size * 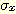 ИІ УЪАњЧЯДТ ЧЅСиЦэТїИІ АЁСіДТ clusterИІ УЃДТДй (ПЉБтМ
ИІ УЪАњЧЯДТ ЧЅСиЦэТїИІ АЁСіДТ clusterИІ УЃДТДй (ПЉБтМ 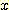 ДТ ОюЖВ КЏМіРЬАэ
ДТ ОюЖВ КЏМіРЬАэ 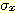 ДТ ПјЗЁРЧ sample С§ЧеПЁМ
ДТ ПјЗЁРЧ sample С§ЧеПЁМ 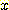 РЧ ЧЅСиЦэТїРЬДй). ИИРЯ ОјРИИщ step 10 РИЗЮ АЃДй. cluster ГЛПЁМ
РЧ ЧЅСиЦэТїРЬДй). ИИРЯ ОјРИИщ step 10 РИЗЮ АЃДй. cluster ГЛПЁМ 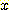 РЧ ЦђБеРЛ АшЛъЧбДй. РЬ cluster ПЁ РжДТ sample ЕщРЛ ЕЮ С§ЧеРИЗЮ ГЊДЋДй(
РЧ ЦђБеРЛ АшЛъЧбДй. РЬ cluster ПЁ РжДТ sample ЕщРЛ ЕЮ С§ЧеРИЗЮ ГЊДЋДй( 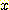 АЁ ЦђБеКИДй ХЉАХГЊ ААРК С§ЧеАњ
АЁ ЦђБеКИДй ХЉАХГЊ ААРК С§ЧеАњ 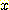 АЁ ЦђБеКИДй РлРК С§Че). РЬЗЏЧб ЕЮ cluster РЧ centroidИІ АшЛъЧбДй. ИИРЯ РЬЗЏЧб
centroid ЛчРЬРЧ АХИЎАЁ 1.1 * min_dist КИДй ХЉАХГЊ ААРИИщ ПјЗЁРЧ clusterИІ РЬЗЏЧб
ЕЮ АГРЧ cluster ЗЮ ЙйВйАэ, БзЗИСі ОЪРИИщ clusterИІ КаИЎЧЯСі ОЪДТДй.
АЁ ЦђБеКИДй РлРК С§Че). РЬЗЏЧб ЕЮ cluster РЧ centroidИІ АшЛъЧбДй. ИИРЯ РЬЗЏЧб
centroid ЛчРЬРЧ АХИЎАЁ 1.1 * min_dist КИДй ХЉАХГЊ ААРИИщ ПјЗЁРЧ clusterИІ РЬЗЏЧб
ЕЮ АГРЧ cluster ЗЮ ЙйВйАэ, БзЗИСі ОЪРИИщ clusterИІ КаИЎЧЯСі ОЪДТДй.
10. ИИРЯ step 10 РЬ iter_body ШНМіИИХ МіЧрЕЧАХГЊ, ИЖСіИЗ step 10 РЬ МіЧрЕШ РЬШФ cluster ПЁ ОЦЙЋЗБ КЏШЕЕ ЙпЛ§ЧЯСі ОЪРИИщ СпДмЧбДй. БзЗИСі ОЪРИИщ ЛѕЗЮПю seed point ЗЮМ cluster РЧ centroidИІ УыЧЯАэ step 2 ЗЮ АЃДй.
Example 5.7 isodata algorithmРЛ ЛчПыЧб partitional clustering
ДйРНАњ ААРК data ПЭ parameter ЕщРЬ РжРЛ АцПь dataИІ cluster ЧЯБтРЇЧи isodata algorithmРЛ ЛчПыЧи КИРк.
|
Number |
x |
y |
Number |
x |
y |
|
1 2 3 4 5 6 7 |
0.0 0.0 0.0 0.5 0.5 1.0 1.0 |
0.0 1.0 3.0 0.5 3.5 1.0 3.0 |
8 9 10 11 12 13 14 |
6.0 6.0 6.0 6.0 6.2 6.2 8.0 |
0.75 1.00 2.00 2.10 0.80 2.05 12.0 |
|
no_clusters = |
3 |
seed point ДТ sample 1, 3, 13 РЬИч, УГРНРЧ ЙнКЙ ШНМіДТ 0 РЬДй.
ОЫАэИЎСђРЧ Forgy part (step 1 ~4) РЧ МіЗХРЛ РЇЧи data РЧ ЧбЙјРЧ МіЧрРЬ ЧЪПфЧЯДй. РЬЖЇПЁДТ ДйРНАњ ААРЬ 3 АГРЧ cluster АЁ СИРчЧбДй.
{1, 2, 4, 6}, {3, 5, 7}, {8, 9, 10, 12, 13, 14}
step 5, ОюЖВ cluster ЕЕ min_elements КИДй ИтЙіМіАЁ РлСі ОЪБт ЖЇЙЎПЁ ЦѓБтЕЧДТ cluster ДТ ОјДй.
step 6, cluster РЧ МіАЁ 2 * no_clusters КИДй ХЉАХГЊ ААСі ОЪАэ, ЖЧДТ ЙнКЙЕЧДТ Мі (0) АЁ ТІМі(even)РЬЙЧЗЮ, step 7 (КДЧе ЕПРл)РЛ НЧЧрЧбДй. ЧЯАэ БзЗИСі ОЪРИИщ step 8 ЗЮ АЃДй.
cluster {1, 2, 4, 6} ПЭ {3, 5, 7} РЧ centroid АЃРЧ АХИЎАЁ min_dist КИДй РлБт ЖЇЙЎПЁ ЕЮ clusterИІ КДЧеЧЯАэ centroidИІ КЏШНУХВДй. РЬЖЇПЁ 2 АГРЧ cluster АЁ ДйРНАњ ААРЬ ЕШДй.
{1, 2, 3, 4, 5, 6, 7}, {8, 9, 10, 11, 12, 13, 14}
КДЧе step РЬ ЙнКЙЕЧСі ОЪРИЙЧЗЮ (max_merge = 1 РЬБт ЖЇЙЎ) step 8 ЗЮ ГЊОЦАЃДй. ( РЬ АцПь ГВОЦРжДТ cluster ЕщРК КДЧеЕЩ Мі ОјДй. ПжГФЧЯИщ centroid АЃРЧ АХИЎАЁ min_dist КИДй ХЉБт ЖЇЙЎРЬДй)
step 8, cluster РЧ Мі (2) АЁ no_clusters / 2 (1.5) КИДй ХЉБт ЖЇЙЎПЁ, ЖЧЧб ЙнКЙРЧ МіАЁ ШІМі(odd) АЁ ОЦДЯБт ЖЇЙЎПЁ step 10 РИЗЮ АЃДй.
step 10, ЙнКЙРЧ ШНМіАЁ ПфБИЕЧДТ Мі (5) КИДй РкАэ cluster ЕщРК КЏШЕЧОњДй. ЕћЖѓМ step 2 ЗЮ ГЊОЦАЃДй.
РЬЖЇПЁ ОЫАэИЎСђРЧ Forgy part (step 1~4) ДТ clusterИІ КЏШНУХАСі ОЪДТДй.
step 5, ОюЖВ cluster ЕЕ min_elements КИДй ИтЙіМіАЁ РлСі ОЪБт ЖЇЙЎПЁ ЦѓБтЕЧДТ cluster ДТ ОјДй.
step 6, cluster РЧ МіАЁ 2 * no_clusters КИДй ХЉАХГЊ ААСі ОЪАэ, ЖЧДТ ЙнКЙЕЧДТ Мі (1) АЁ ШІМі(odd)РЬЙЧЗЮ, step 8 ЗЮ АЃДй.
step 8, cluster РЧ Мі (2) АЁ no_clusters / 2 КИДй ХЉБт ЖЇЙЎПЁ, ЖЧЧб ЙнКЙРЧ МіАЁ ШІМі(odd) РЬЙЧЗЮ, КаИЎ ЕПРл (step 9) АЁ МіЧрЕШДй.
step 9, split_size *  ИІ УЪАњЧЯДТ (КЏМі
ИІ УЪАњЧЯДТ (КЏМі  ИІ РЇЧб) ЧЅСиЦэТїИІ АЁСіДТ cluster {8, 9, 10, 11, 12, 13, 14} АЁ РжДй. sample
ЕщРК cluster ПЁМРЧ
ИІ РЇЧб) ЧЅСиЦэТїИІ АЁСіДТ cluster {8, 9, 10, 11, 12, 13, 14} АЁ РжДй. sample
ЕщРК cluster ПЁМРЧ  РЧ ЦђБеКИДй РлАХГЊ ХЋ
РЧ ЦђБеКИДй РлАХГЊ ХЋ  АЊРЛ АЁСіДТ ЕЮ С§ЧеРИЗЮ ГЊДЖДй.
АЊРЛ АЁСіДТ ЕЮ С§ЧеРИЗЮ ГЊДЖДй.
{8, 9, 10, 11, 12, 13}, {14}
БзЕщРЧ centroid ЛчРЬРЧ АХИЎАЁ 1.1 * mid_dist КИДй ХЉАХГЊ ААБт ЖЇЙЎПЁ, cluster ДТ КаИЎЛѓХТИІ РЏСіЧбДй. РЬЖЇПЁДТ 3 АГРЧ cluster АЁ СИРчЧбДй.
{1, 2, 3, 4, 5, 6, 7}, {8, 9, 10, 11, 12, 13}, {14}
step 10, ЙнКЙ ШНМіАЁ ПфБИЕЧДТ МіКИДй РлАэ cluster АЁ КЏШЕЧОњРИЙЧЗЮ step 2 ЗЮ АЃДй.
ДйНУ РЬЖЇПЁ ОЫАэИЎСђРЧ Forgy part (step 1~4) ДТ clusterИІ КЏШНУХАСі ОЪДТДй.
step 5, cluster {14} ДТ min_elements ИтЙіМіКИДй РлБт ЖЇЙЎПЁ ЦѓБтЕШДй. РЬЖЇПЁДТ ЕЮ АГРЧ cluster АЁ ЕШДй.
{1, 2, 3, 4, 5, 6, 7}, {8, 9, 10, 11, 12, 13}
step 6, cluster РЧ МіАЁ 2 * no_clusters КИДй РлАэ ЙнКЙШНМі (2) АЁ ТІМіРЬБт ЖЇЙЎПЁ, КДЧеЕПРл (step 7) РЬ МіЧрЕШДй.
cluster {1, 2, 3, 4, 5, 6, 7} Ањ {8, 9, 10, 11, 12, 13} РЧ centroid ЛчРЬРЧ АХИЎАЁ min_dist КИДй РлБт ЖЇЙЎПЁ, РЬ cluster ЕщРК КДЧеЕЧСі ОЪДТДй. step 8 ЗЮ ГЊОЦАЃДй.
step 8, cluster РЧ Мі (2) АЁ no_clusters / 2 КИДй ХЉАэ ЙнКЙ ШНМіАЁ ТІМіРЬБт ЖЇЙЎПЁ step 10 РИЗЮ АЃДй.
step 10, ЙнКЙ ШНМіАЁ ПфБИЕЧДТ МіКИДй РлАэ cluster ЕщРЬ КЏШЕЧОњБт ЖЇЙЎПЁ step 2 ЗЮ АЃДй.
ДйНУ РЬЖЇПЁ ОЫАэИЎСђРЧ Forgy part (step 1~4) ДТ clusterИІ КЏШНУХАСі ОЪДТДй.
step 5, ОюЖВ cluster ЕЕ min_elements КИДй ИтЙіМіАЁ РлСі ОЪБт ЖЇЙЎПЁ ЦѓБтЕЧДТ cluster ДТ ОјДй.
step 6, cluster РЧ МіАЁ 2 * no_clusters КИДй РлАэ ЙнКЙШНМі (3) АЁ ШІМіРЬБт ЖЇЙЎПЁ step 8 ЗЮ ГЊОЦАЃДй.
step 8, cluster РЧ Мі (2) АЁ no_clusters / 2 КИДй ХЉАэ ЙнКЙШНМіАЁ ШІМіРЬБт ЖЇЙЎПЁ, КаИЎ ЕПРл (step 9) РЬ МіЧрЕШДй.
step 9, ОюЖВ cluster ЕЕ ЧЅСиЦэТїАЁ split_size * 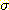 ИІ УЪАњЧЯДТ КЏМіИІ АЁСіАэ РжСі ОЪБт ЖЇЙЎПЁ step 10 РИЗЮ ГЊОЦАЃДй.
ИІ УЪАњЧЯДТ КЏМіИІ АЁСіАэ РжСі ОЪБт ЖЇЙЎПЁ step 10 РИЗЮ ГЊОЦАЃДй.
step 10, ЙнКЙ ШНМіАЁ ПфБИЕЧДТ МіКИДй РлДй, БзЗЏГЊ ОюЖВ cluster ЕЕ КЏШЕЧСі ОЪОвДй. ЕћЖѓМ ОЫАэИЎСђРК СОЗсЕШДй.