
자연어 이해
인공지능의 이론과 실제 : 김화수.고순주, 집문당, 1993, page 221~243
|
3.1 단어 이해 (Word Understanding) 3.2 문장 이해 (Sentence Understanding) |
자연어란 프로그래밍 언어들, 즉 FORTRAN, COBOL, PASCAL, C, C++, Ada, LISP 및 PROLOG 등과 같은 인공 언어와는 다르게, 어법이 정해진 규칙만을 따르지 않고 일상적으로 사용되는 언어의 구조적인 체계를 말한다. 요약하면 자연어는 어떤 정돈된 완벽한 문법이나 형식적인 의미가 없는 언어를 말한다.
인간과 인간이 통신을 하고자 할 때에는 문어 (written language) 및 구어 (spoken language) 에 의한 수단으로 할 수 있다. 문어는 구어에 비해 문장의 애매모호함의 정도가 작은데, 그 이유는 정돈된 문법을 어느 정도 따르기 때문이다. 반면에 구어는 어떤 정돈된 완벽한 문법이나 형식적인 의미에 구애받지 않고 사용되므로 구어를 이해하기 위해서는 모든 잡음과 가청신호의 애매함을 처리할 수 있는 충분한 지식이 있어야 하므로 구어를 이해하는 것은 문어를 이해하는 것보다 훨씬 어렵다.
그러므로, 자연어 처리에서는 구어 및 문어를 동시에 이해하는 것이 필요하다. 즉 전체 자연어 이해를 위해서는 다음 두 가지를 동시에 만족해야 한다.
첫째, 자연어의 어휘분석 (lexical), 구문분석 (syntactic) 및 의미분석 (semantic) 지식을 이용하여 문어의 내용을 이해할 수 있어야 한다.
둘째, 담화하는 과정에서 발생하는 불확실한 것들을 처리하기 위해 충분히 주어진 정보를 이용하여 구어의 내용을 이해할 수 있어야 한다.
자연어 이해 (자연어 understanding) 란 한 가지 표현방법에서 다른 표현 방법으로 변환시켜 자연어의 숨은 뜻을 정확히 알아내는 것을 말하는 것으로서, 자연어를 완벽하게 이해한다는 것은 충분한 사전지식이 없으면 결코 쉬운 일이 아니다.
예를 들면, Kim: "What do you like tonight, LG or Hai-Tai?" 즉 김 X X 가 "오늘밤 럭키금성 혹은 해태 중 어느 것을 좋아하는가 : 라고 질문을 하였다. 이때 만약 우리가 이러한 질문을 완전히 이해하였다면 오늘 저녁 TV에서 중계하는 야구게임에서 럭키금성과 해태가 경기를 하는데 어느 팀을 좋아하는가를 질문하는 것임을 알아야 한다. 또한, 질의 응답 지원을 위한 전문가 시스템상에서 '가능한 빨리 알고 싶다'라고 말하였을 시, 이러한 시스템을 완벽하게 이해하였다면 가능한 빨리 알고 싶어하는 질의에 대한 해 (solution) 를 찾게 될 것이다.
Rich의 항공기 예약 시스템에서 자연어 이해를 살펴보면 다음과 같다. 항공기 예약 시스템에서, "I want to go to N.Y. as soon as possible." 라고 말한다면 이러한 시스템에서는 N.Y. 에 가는 첫 비행기를 찾아내라는 것으로 이해를 하게 될 것이다. 그러나 만약에 당신의 가족이 N.Y. 에 살고 있다는 것을 아는 여자친구에게 동일한 이야기를 하였다면, 그 여자친구는 당신의 가족에 어떤 문제가 생겼다는 의미로 이해를 할 수도 있기 때문에 자연어를 완벽하게 이해한다는 것은 결코 쉬운 일이 아니다.
또한, 영어나 우리말도 동일한 단어가 여러 개의 의미를 갖는 것이 많다. 예를 들면 영어의 'diamond' 는 보석이 될 수 있고, 야구장의 다이아몬드를 의미할 수도 있으며, 우리말의 '배'를 보면 바다나 강에서의 교통 수단인 배가 될 수 있고, 과일로서 먹는 배가 될 수 있으며, 인간 및 동물 등의 신체부분인 배의 의미가 될 수 있으므로 더욱 자연어를 완벽히 이해한다는 것은 쉬운 일이 아님을 강조한다.
자연어를 이해하는 데에는 (i) 매칭 (matching) 되는 목적표현이 복잡하고, (ii) 대응 (mapping) 의 형태가 복잡하며, 즉 1대 1 (one-to-one), 1 대 다수 (one-to-many), 다수 대 1 (many-to-one), 그리고 (iii) 소스 (source) 표현 요소들간의 상호작용의 정도 때문에 자연어를 이해하는 데 어려움이 따르게 되는 것이다. 상기 (i), (ii) 및 (iii) 의 상세한 문제점은 다음과 같다.
먼저 목적표현이 비교적 간단한 예를 살펴본다. 자연어를 처리하는 방법에서 키워드(keyword)를 사용하여 문장을 검색하는 시스템과 문장을 이용하여 대화를 나누는 경우를 생각해 보자.
자연어 이해란 원래의 표현방법에서 다른 표현방법으로 변환되는 것을 의미하므로, 'I want to predict results of the korea presidential election.'이란 문장은 (search keywords=election+president)의 목적표현으로 변환된다.
다른 단순한 예를 하나 더 들면 다음과 같다.
'A Prolog program consists of a set of facts and rules.'
여기에서, 상기 문장은 (search keywords = fact + rule) 의 목적표현으로 변환된다.
초기의 자연어 이해는 상기와 같이 매우 간단한 목적표현을 사용하였으나, 조금 더 실세계의 문제를 완벽하게 해결하기 위하여 계속적인 연구를 통하여 보다 복잡한 목적표현을 시도하게 되었다. 실세계의 자연어 이해를 명확하고 세부적으로 이해하기 위해서는 복잡한 목적표현을 사용해야 하므로 자연어를 이해하는 데 문제점이 대두된다.
왜 과거의 작업은 비교적 단순한 목적표현을 사용했는가 하는 이유는 다음과 같다.
첫째, 과거에는 문장들을 매우 피상적으로 분석하여 표현하였다.
둘째, 과거에는 블럭 문제와 같은 매우 의미론적 (semantic) 인 극히 제한된 실세계의 지식을 표현하였다.
이미 언급하였듯이 대응은 1 대 1, 1 대 다수 및 다수 대 1의 형태가 있다.
첫째,
1 대 1 (one-to-one) 대응 형태
1 대 1 대응 형태는 가장 간단한
대응 형태이나, 실세계에서는 많이 사용되고 있지 않다. 1 대 1 형태의 예를 설명하면
그림 1 과 같다.
그림 1 은 문장의 본래 형태인 idl:=id2+id3*70을 조금 더
유익한 형태인 트리를 이용하여 데이터 구조를 표현한 것이다.
둘째,
1 대 다수 (one-to-many) 대응 형태
1 대 다수 대응 형태는
원래 표현을 여러 가지의 목적표현 방법으로 변환하여, 여러 목적표현 방법들 중에서
가장 정확하고 적합한 목적표현을 선택하는 것이다. 즉 소스 (source) 언어 문장은
애매모호할 수 있다. 이러한 1 대 다수 대응형태에서는 가장 정확하고 적합한 하나의
목적표현을 선택하기 위하여 많은 양의 비언어적인 지식이 필요하다.
그림 1 1 대 1 대응 형태
1 대 다수 대응 형태의 예를 들면 다음과 같다.
They
are flying planes.
->
(they are (flying airplanes))
->
(they (are flying) airplanes)
->
(they are (flying planning tools))
->
(they (are flying) (planning tools))
셋째, 다수
대 1 (many-to-one) 대응 형태
다수 대 1 대응 형태는 다른 것보다
일반적인 대응 형태로서 특히 영어문장과 같이 다양한 구조와 어휘 및 의미를 보다
간단하고 쉽게 적은 목적표현으로 대응시킬 때 유용한 방법이다.
다음은 다수 대 1 대응 형태의 예를 설명한 것이다.
1) Tell me all
about the last presidential election.
2) I'd like to see
all the stories on the last presidential election.
3) I
am interested in the last presidential election.
1), 2), 3) 의 여러 문장에 대하여 하나의 대응되는 목적표현을 나타내면 search keywords = election + president 가 된다. 이러한 다수 대 1 의 변환 형태에서는 소스 (source) 언어에서 표현될 수 있는 여러 가지 방법들에 대해 알아야 할 필요성이 있다.
각 문장들은 여러 구성요소들, 즉 오퍼레이터
및 오퍼랜드 등으로 구성되어 있다. 이러한 구성요소들의 상호작용에 있어서 한 구성요소가
다른 구성요소와 상호작용을 거쳐야만 변환될 수 있다면, 상호작용의 복잡한 정도에
따라서 변환의 복잡성이 비례하게 될 것이다.
예를 들면, 문장
a + a*(b - c) + (b - c)*d 를 파서 (parser) 트리의 형태로 표현하면 그림 2 와 같다.
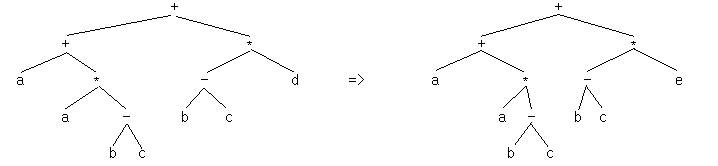
그림 2 a + a*(b - c) + (b - c)*d 의 파서 트리
그림 2 의 문장에서 왼쪽에 있는 문장의 전체 구조가 d를 e로 변환시킴으로써 전체적인 구조의 변화가 아닌 한 노드가 어떻게 변화되는가의 예를 보였다. 즉 그림에서는 다른 구성요소와 무관하게 변화할 수 있으므로 간단히 문장 중에 하나의 단어를 변경함으로써 전체적인 문장의 구조 및 의미를 변화시킬 수 있음을 보여주었다.
그러나 많은 자연어 문장에서는 하나의 단어를
변환시키는 데 단지 한 개의 노드를 변화시키는 것이 아니라 많은 노드들간의 상호작용의
복잡한 절차를 거쳐서 전체적인 구조를 변화시켜 주는 경우가 실세계에서 존재한다.
이렇게 구성요소들간에 상호작용이 많은 경우에 있어서의 예는 그림 3 과 같다.
|
John saw the boy in the park with
a telescope. John saw the boy in the park with
a dog. |
그림 3 구성요소들간의 상호작용이 큰 경우
그림 3 에서 삼각형 (△) 으로 표시된 부분은 더 이상의 분석이 불필요한 부분을 표시한 것이다.
이렇게 자연어를 이해하는 데는 작업과정의 난이성에 따르는 세 가지 요소인 목적 표현의 복잡성, 대응 형태의 다양성 및 구성요소들간의 상호작용의 복잡성 정도가 커다란 영향을 미치게 된다는 것을 살펴보았다.
자연어란 그 자체는 매우 복잡한 현상을 지니고 있다. 그 이유는 자연어 처리과정을 포함해서 음성 혹은 기록으로 인식하는 정도에 따라서 의미 자체가 쉽게 변화할 수 있기 때문이다. 이러한 매우 복잡한 자연어를 다루기 위하여 언어학자들은 자연어를 분석하는데 다음과 같은 수준 (level) 으로서 정의하였다.
자연어 분석단계는 서로 다른 철학과 응용에 따라서 변경될 수 있으나 일반적으로 다음과 같이 네 단계를 거친다.
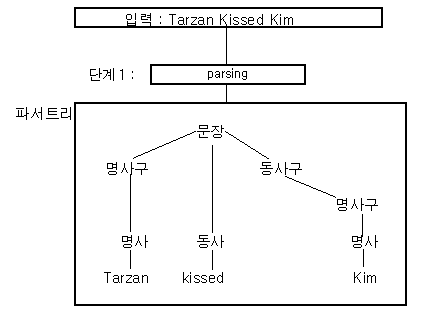
그림 4 어휘분석 (Parsing) 단계
첫번째 단계는 어휘분석으로서 문장의 어휘구조가 문법에 맞는가를 분석하는 것이다. 어휘분석은 문장의 어휘가 문법대로 구성되었는가를 확중하는 것에 부가하여 언어학적인 구조를 결정한다.
그림 4 와 같이 어휘분석에서는 주어-동사, 동사-목적어 등과 같은 중요한 언어학적인 관계를 형성함에 의하여, 어휘분석기 (parser) 에서는 단계 2 인 의미해석 (semantic interpretation) 에 대한 기반을 제공한다. 그림 4 는 파서 트리 (parser tree) 로 표현된다.
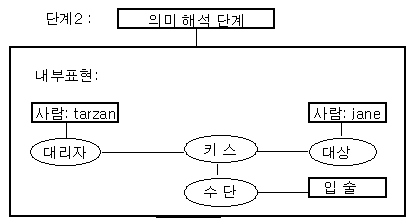
그림 5 의미해석 (Semantic Interpretation) 단계
두 번째 단계인 의미해석은 문장의 의미에
관한 내부표현을 생성하는 역할을 한다. 의미해석에서는 단어의 의미 및 언어학적인
구조에 관련된 지식을 사용한다.
그림 5 에서는 의미론적인
해석에서 프로그램은 키스 (kiss) 를 하기 위한 수단으로 입술이라는 디폴트 (default)
값을
키스의 의미 지식에 추가한 지식을 사용하였다.
의미해석 단계에서는
또한 계속해서 동일한 의미를 지니는가를 검사하는 기능을 수행한다.

그림 6 확장된 지식해석 단계
예를 들면 동사인 키스의 정의는, 만약 대리자
(agent) 가 사람이라면
대상이 또한 사람이어야 하는 제약 조건이 따른다. 즉 일반적으로 Tarzan does not
kiss cheetah 이다.
그림 5 의미해석 단계는 그림 4 어휘분석
단계를 계속해서 연결시킨 것이다.
세 번째 단계의 확장된 지식해석은 문자의 내부표현에 지식베이스로부터의 구조를 첨가하여 문장의 의미를 확장하여 표현하는
역할을 수행한다. 확장된 지식해석 단계에서는 문장을 완벽하게 이해할 때에 필요한
실세계 지식 (world knowledge) 을 부가하는 것이다. 예를 들면 'Tarzan 은 Jane
을 사랑한다.
Jane 및 Tarzan 은 정글에서 살며 cheetah 는 Tarzan 의 동물이다' 등이다. 이러한 결과의
구조는 자연어 문장의 의미를 표현하고 다음 단계 처리를 위하여 시스템에 의하여
사용된다.
확장된 지식해석 단계는 그림 6 을 참고 바란다.
네 번째 단계에서는 질의 응답기, 데이터베이스 질의기 및 변환기 등에 전달되며 데이터베이스 언어의 적당한 질의로 변환되게 된다.
단수문장이란 각각의 단어에 의미를 부과하여
전체적인 문장에 대한 뜻을 표현하는 구조를 형성하기 위하여 이러한 단어들을 배치하는
것을 말한다.
다시 말하면, 단수문장에서는 문장 가운데서
한 부분을 이해하기 위해서는 문장들 사이의 관계를 알아낼 필요가 없는데, 그 이유는
하나의 문장을 이해하기 때문이다.
단수문장을 이해하기 위해서는
먼저 단어 (word) 의 이해 단계를 거쳐서 문장 (sentence) 을 이해하여야만 하므로, 다음
3.1 절에서는 단어 이해를 3.2절에서는 문장의 이해를 살펴본다.
일반적으로 단어 그 자체를 이해하는 것은 매우 쉬운 듯 생각되나, 실제적으로는 결코 쉬운 일이 아니다. 왜냐하면 하나의 단어가 여러 개의 의미를 갖고 있는 것이 실세계에 많이 존재하기 때문이다. 이미 기술하였듯이, 예를 들면 '배' 라는 의미는 다음과 같은 여러 의미를 가지고 있다.
다음과 같은 문장에서 '쪽'이란 단어에 대하여
완벽한 의미를 선택하기 위해서는 사전에 각각 세 가지 '쪽' 의 의미를 명확히 인식하고
있어야 한다.
각 단어의 정확한 의미를 결정하기 위해서는
어휘 (lexical) 를 수록해 놓은 어휘 목록집에 있는 각 단어에 각각의 의미가 나타낼
수 있는 문맥들에 관한 정보들을 연관시켜서 문장에 있는 각 단어들이 어떤 문맥의
한 부분으로 결정되어야만 하는 것으로서, 이러한 것을 단어의미 애매모호 제거화
(word-sense
disambiguation) 라고 말한다.
이러한 단어의미 애매모호 제거화에 대한 방법은 간단하지가 않다. 예를 들면, 다이아몬드라는 단어는 다음과 같은 여러 가지 의미를 가지고 있다.
"John saw Susan's diamond shimmering from across the room." 의 문장이 있을 때, 이러한 다이아몬드에 대한 정확한 단어를 이해하기 위하여는 다이아몬드가 반짝거려야 하는 특징이 있는 반면에 다른 의미를 갖는 것, 즉 야구장 및 네 개의 동일한 면을 갖는 기하학적인 구조들은 반짝거리지 않아야 되는 특징으로 분류되어야 한다. 이렇게 하여야만, 다이아몬드가 이 문맥에서 반짝이는 보석으로서의 적절한 의미로서 선택될 수 있다.
문장은 단어의 집합으로 이루어져 있다. 제 3.1 절에서 단어 이해 (Word Understanding) 를 살펴보았듯이 부분적인 단어의 의미를 완벽하게 이해하였으면, 다음 단계로는 '어떻게 하면 단어들을 잘 배열 합성하여 하나의 문장을 형성하여 뜻을 나타내는 구조를 형성하는가?' 하는 것 또한 중요한 문제이다. 이러한 문제는 언어학적인 것으로서 언어의 지식, 언어에 대한 관습, 속어, 비어 등 다양한 언어지식 소스 (source) 에 따라 좌우된다.
이러한 문장 이해를 위해서는 일반적으로 다음의 세 가지 요소들을 다룬다.
이러한 세 가지 단계, 즉 구문분석 단계, 의미분석 단계 및 실용분석 단계는 때로는 순서대로 행하여지고, 때로는 동시에 행해질 수도 있다는 것에 유의하기 바라며, 많은 학자들의 주장은 상기 세 단계의 경계가 모호함을 주장한다.
단수언어를 이해하는 방법에는 일반적으로 다음의 세 가지 방법을 사용한다.
단수언어를 이해하는 데 가장 단순하게 사용할 수
잇는 방법으로서, 우리가 관심을 가지고 있는 키워드만을 선택해서 사용하고
그 나머지는 무시하는 방법이다. 키워드 매칭방법의 특징은 특이한 문장, 즉 문법적으로
맞지 않는 문장들 조차도 인식되어 지게끔 한다는 것이다. 이러한 방법에는 noise-disposal
parser 방법이 있다.
Noise-disposal parser 방법의 예를 들면
다음과 같다. 지의할 때 질의의 형식이 다음과 같은 형태라고 가정했다.
command <number> <name> <hedge> goal
다음과 같은 질의 문장이 입력되었다 하자.
"Show
me two people who are appropriate to work overseas.", "Is Kim very
young?" 그러면, 첫번째 질의에서 command 는 'show', number 는 'two', name
과
hedge 에 해당되는 단어는 없으며, goal 에는 'oversea' 가 매칭이 된다.
두
번째 질의에서는 'is' 가 command, 'Kim' 은 name, 'very' 는 hedge 에 그리고 'young'
은
goal 에 각각 해당된다. 이러한 noise-disposal parser 방법의 구현은 다음 프로그램을
참고 바란다.
<주프로그램>
|
CLAUSES loop(STR) :- STR><"", |
<스캐닝 및 필터링>
|
CLAUSES |
<파 싱>
|
CLAUSES |
<질의 평가>
|
CLAUSES |
<데이터베이스 검색>
|
CLAUSES |
<오차 탐지>
|
CLAUSES |
구문분석에는 일반적으로 파스-트리 (parse-tree) 라는 모델을 사용하여 문법관계를 조사 및 분석을 한다. 이미 기술하였듯이 구문분석은 주어진 입력이 구문명세서에 적합한가를 검사하는 것이다. 이때에 사용하는 파스-트리는 유도 트리(derivation tree) 라고도 부르며, 문법의 시작기호가 어떻게 스트링을 유도하는가를 트리로써 나타낸 것이다. 주어진 문맥자유 문법 (context-free grammar) 에서 파스-트리의 구조 특성은 다음과 같다.
파스-트리의
루트 노드는 시작기호가 위치한다.
파스-트리의 leaf노드에는
토큰이나 공집합이 위치한다.
중간노드에는 비종단(non-terminal)
기호가 위치한다.
이해를 돕기 위하여 한국어의 일부를 정의하여 보자. 한국어의 문장은 주어부와 술어부로 구성되어 있다. 주어부는 다시 명사와 조사로 세분화되며, 술어부는 동사로써 구성된다. 명사의 종류는 나, 너 등이 있으며, 동사의 종류에는 논다, 달린다, 헤엄친다, 웃긴다 등이 있다.
이러한 것을 문법의 형태로 표시하면 다음과 같다.
<문 장>
:- <주어부> <술어부>
<주어부> :-
<명 사> <조 사>
<술어부>
:- <동 사>
<명 사> :- - 나
| 너
<조 사> :- - 는 | 가 | 도
<동
사> :- 논다 | 달린다 | 헤엄친다 | 웃긴다 | 공부한다
여기에서 "< >" 표시는 구문요소 (Syntactic element) 라고 말하며 "|" 혹은 (or) 의 의미를 나타낸 것이다. "나는 논다" 라는 문장은 다음과 같은 순서로 상기 문법에 매칭되어 치환하여 만들 수 있다.
1. <문 장>
2.
<주어부> <술어부>
3. <명 사> <조
사> <술어부>
4. <명 사> <조
사> <동 사>
5. 나 <조 사>
<동 사>
6. 나는 <동 사>
7.
나는 논다.
"나는 공부한다."라는 문장을 파스-트리로 표시하면 그림 7 을 생성한다.
(문
장)
/
\
(주어부)
(술어부)
/
\ |
(명사)
(조사) (동사)
|
| |
나
는 공부한다
그림 7 "나는 공부한다"의 파스-트리 생성
이러한 파싱 과정은 어떠한 문장들이 문법적으로 맞는 것인가 맞지 않는 것인가를 검사하여, 문법적으로 맞으면 받아들이고 맞지 않으면 거부하는 것을 결정한다.
- 의미론적 문법 (Semantic grammar) : 문법을 형성시킬 때 문장론적 정보와 함께 어의론적 정보를 포함하여 규칙에 저장시킨다.
- 격 문법 (Case grammar) : 구문분석기 (parser) 가 어느 정도의 의미론적인 정보를 포함한다.
- 파스들의 의미론적인 여과(Parse semantic filtering) : 문장론적으로 생성된 파싱 결과가 나오는 대로 구분을 하는 방법으로, 이는 '파스' 들이 지나감에 따라 부분적으로 이들을 여과하는 방법과 안전한 파스들이 발견될 때까지 기다린 후에 이것이 의미론적으로 합리성이 있는가를 평가하는 두 가지 방법이 있다.
- 파싱에 중점을 두지 않고, 전체적으로 언어를 이해하는 과정에서 의미론적인 지식에 의하여 이해 과정을 유도한다.
자연어 이해를 위한 프로그램을 설계하는 데 중요한 병목현상 (bottleneck) 은 구어의 영역에 관한 충분한 지식을 획득하는 문제이다. 현재의 기술은 이러한 범주에 관하여 매우 잘 정의된 의미론적인 문법을 가지고는 매우 협소한 영역에 제한되어 활용되고 있는 실정이다.
비록 데이터베이스는 대용량의 정보를 저장하고 있지만, 그러한 정보는 크게 규칙적 (regular) 이고 영역이 협소하며, 더군다나 데이터베이스의 의미는 잘 정의되어 있다. 이러한 양사에 비추어 볼 때 데이터베이스의 유틸리티 (utility) 와 함께 자연어 질의를 받아들일 수 있고, 데이터베이스 Front-end 는 자연어 이해 기술의 중요한 응용 분야가 된다는 것을 알 수 있다.
데이터베이스 Front-end 의 임무는 자연어로 질문을 할 것을 데이터베이스 언어상의 잘 형성된 (well-formed) 질의어로 변환시켜 주는 역할을 한다. 예를 들면, SQL 이라는 데이터베이스 언어를 사용하여 자연어 Front-end 는 "Who hired John Smith?" 라는 질문을 다음 질의어로 변환시켜 준다.
Select Manager
From
Manager_of_hire
Where Employe
'John Smith'
이러한 변환 과정을 수행하는 데 있어서, 프로그램은 원래의 질의를 변환시키는 것에 부가하여, 데이터베이스 (the Manager_of_htre 관계) 의 어느 곳을 검사해야 하는가, 접근해야 하는 필드명 (field name) 여기서는 Manager 및 질의상의 제약조건 (Employee = 'John Smith') 을 반드시 결정해야 한다.
관계형
데이터베이스 (relational data base) 는 엔티티 (entity) 의 영역에 걸쳐 데이터 상호의
관계를 나타낸다. 예를 들면 고용인 (employee) 의 데이터베이스 형성 및 모든 고용인의
봉급 및 고용원을 채용한 매니저 (manager) 들을 접근 (access) 하고자 한다고 가정하자.
이러한
데이터베이스는 세 개의 영역 (domain) 인 매니저의 집합, 고용인의 집합 및 봉급의
집합으로 구성됨을 알 수 있다. 만약 우리가 이러한 데이터들을 두 개의 관계로 구성하고자
할 때, employee salary (고용인과 고용인의 봉급관계를 나타냄), manager of hire
(고용인과
고용인의 매니저의 관계를 나타냄)로 나타낼 수 있다.
관계형
데이터베이스에서 관계는 일반적으로 관계의 예 (instance) 를 열거한 테이블 (table)
로써
나타낸다. 테이블의 종행 (column) 은 이름을 표시하고, 이러한 이름들을 관계의 속성
(attribute) 이라고
한다.
그림 8 은 employee_salary 및 manager_of_hire 의 관계를 테이블로 표시한 것이다.
|
employee salary |
manager_of_hire |
||
|
Hwa Soo Kim |
$30.000 |
Hwa Soo Kim |
Yong Soo Ra |
그림 8 employee 데이터베이스의 관계
그림 8 에서 manager_of_hire 는 두 개의 속성인 employee 및 manager 를 가지고 있다. 이때의 관계값은 emjployee 및 manager 의 쌍 (pair) 으로 이루어져 있다. 만약에 employee 가 오직 하나의 이름만 가지고 있다고 한다면, employee 이름은 salary 및 manager 모두에 대한 키 (key) 가 된다.
다음 그림 9 는 employee_salary 및 manager_of_hire 관계를 위한 엔티티 (entity) 관계 그래프를 나타낸다.
영어는 형식적인 질의 (formal query) 로 변환할 때, 응답 (answer) 을 포함하고 있는 레코드 (record) 를 반드시 결정해야 하고, 응답을 포함하고 있는 레코드의 필드 (field) 를 반드시 되돌려 주어야 하며, 그러한 필드를 결정하기 위한 키 (key) 의 값을 결정해야 한다.
영어를 데이터베이스 언어로 직접 변환한다기보다 영어를 개념 그래프 (conceptual graph) 와 같은 설명적인 그래프로 변환시키는 것이 필요하다. 먼저 설명적인 그래프로 변환시키는 것이 필요한 이유는 많은 영어 질의들은 애매모호하거나 혹은 잘 형성된 (well-formed) 데이터베이스 질의를 생성하기 위하여 부가적인 해석 (설명) 이 요구되기 때문이다. 즉 아주 좋은 설명적인 표현언어는 이러한 과정에 대단히 도움을 줄 수 있다.
예를 들면, "Who hired Young Sun Park?" 을 생각해 보자. 이러한 질의에 대하여, 그림 10 과 같은 "hire" 동사에 대한 지식베이스 입력 (entry) 들을 살펴볼 수 있다.
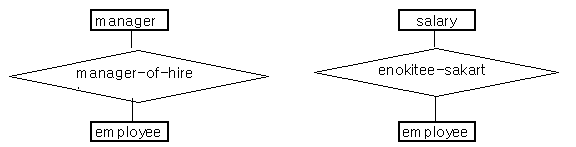
그림 9 Entity 관계 그래프

그림 10 "hire" 질의에 대한 지식베이스
의미 해석기 (semantic interpreter) 는 사용자의 질의 그래프를 생성하고 이러한 그래프는 적절한 지식 베이스 입력 (entry) 과 결합하게 된다. 만약 부가된 엔티티 관계 그래프에 있어서 키 (key) 들이 질문의 목표에 사상 (mapping) 된다면, 프로그램은 이러한 엔티티 관계 그래프를 사용하여 데이터베이스 질의를 형성한다.
그림 11 에서는 "Who hired Young Sun Park?" 의 질문에 대한 질의 그래프를 나타낸다. 그림 11 은 그림 10 의 지식베이스 입력과의 결합에 의한 결과를 나타낸 것임을 유의하기 바란다.
|
|
SQL
언어의 질의 : Seloect manager |
그림 11 자연어 입력 그래프로부터 데이터베이스 질의 (query) 개발
이것은 또한 그래프로부터 형성된 SQL 질의를 나타낸다. 중요한 것은 적절한 레코드명, 목적 필드 및 질의에 대한 키 (key) 들은 자연어 질의 내에서 세분화되지 않았다. 이러한 것들은 지식 베이스에 의하여 얻어진다.
지금까지 자연어를 데이터베이스 front-end 에 응용한 예를 간략하게 설명하였다. 즉, 자연언어 데이터베이스 front-end 를 형성하는 데 지식베이스 접근방법의 사용을 설명하였다. 개념 레코드상에 표현된 예제를 설명하였으나 프레임이나 혹은 논리-베이스 언어와 같은 다른 표현방법에도 적용될 수 있을 것이다.
