문맥-자유 언어
형식 언어와 오토마타
: Peter Linz 저서, 장직현. 김응모. 엄영익. 한광록 공역, 사이텍미디어, 2001
(원서 : An Introduction to Formal Languages and Automata. 3rd ed, Jones and
Bartlett. 2001), Page 133~158
1. 문맥-자유 문법
(1) 문맥-자유 문법의 예
(2) 좌측우선 유도와 우측우선 유도
(3) 유도 트리
(4) 문장 형태와 유도 트리와의 관계
연습문제
2. 파싱과 모호성
(1) 파싱과 소속성
(2) 문법과 언어에서의 모호성
연습문제
3. 문맥-자유 문법과 프로그래밍 언어
연습문제
앞장에서 우리는 모든 언어들이 정규 언어가 될
수 없음을 알아보았다. 이는 정규 언어가 단순한 패턴들을 표현하는데 효과적인데
반하여, 정규 언어가 아닌 언어들의 예들을 쉽게 찾을 수 있다. 몇몇 예제들을 다시
해석해 보면, 이러한 제한성 (limitation) 의 프로그래밍 언어들과의 연관성은 분명해진다.
만일 언어 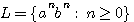 에서 a 를 왼쪽 괄호, b 를 오른쪽 괄호로 치환하면, (( )) 나 ((( ))) 와 같은
괄호 문자열들은 L 에 속하는 반면 (( ) 문자열은 속하지 않는다. 이 언어는 프로그래밍
언어에서 접할 수 있는 일종의 중첩 구조 (nested structure) 를 나타내는 것으로서,
프로그램의 몇몇 성질들은 정규 언어 이상의 어떤 것을 필요로 함을 시사한다. 따라서
중첩 구조와 그 외의 다른 좀더 복잡한 특성들을 표현하려면, 언어군을 확대하여야
한다. 이를 위하여 문맥-자유 언어 (context-free language) 와 문법을 살펴보기로
하자.
에서 a 를 왼쪽 괄호, b 를 오른쪽 괄호로 치환하면, (( )) 나 ((( ))) 와 같은
괄호 문자열들은 L 에 속하는 반면 (( ) 문자열은 속하지 않는다. 이 언어는 프로그래밍
언어에서 접할 수 있는 일종의 중첩 구조 (nested structure) 를 나타내는 것으로서,
프로그램의 몇몇 성질들은 정규 언어 이상의 어떤 것을 필요로 함을 시사한다. 따라서
중첩 구조와 그 외의 다른 좀더 복잡한 특성들을 표현하려면, 언어군을 확대하여야
한다. 이를 위하여 문맥-자유 언어 (context-free language) 와 문법을 살펴보기로
하자.
우선 문맥-자유 문법과 언어를 정의한다. 이 정의들을
몇 개의 간단한 예를 가지고 설명해 본다. 그리고, 중요한 소속성 문제를 고려해
본다. 특히, 임의의 문자열이 주어진 문법에 의하여 유도될 수 있는지를 묻는 문제를
고려해 본다. 문장을 문법적인 유도를 통하여 설명하는 것은 자연 언어를 공부한
우리들에게 익숙하고, 이 과정을 파싱 (parsing) 이라 부른다. 파싱은 문장의 구조를
표현하는 한 방법이다. 예를 들어, 한 언어를 다른 언어로 번역하는 데에서와 같이
문장의 의미를 이해하는 것을 필요로 할 때에 항상 파싱은 중요한 역할을 한다. 컴퓨터
과학에서는, 번역기 (interpreter), 컴파일러 (compiler), 그리고 또 다른 프로그램
번역 등이 이와 연관된다.
문맥-자유 언어는 프로그래밍 언어에 적용이 되기
때문에, 이에 관한 연구는 아마도 형식 언어 이론의 가장 중요한 부분일 것이다.
실제의 프로그래밍 언어는 문맥-자유 언어로 잘 표현될 수 있는 여러 특성들을 가지고
있다. 형식 언어 이론에서 밝혀진 문맥-자유 언어에 대한 결과들은 프로그래밍 언어의
설계에서 뿐만 아니라 효율적인 컴파일러 작성에 중요하게 사용된다. 이에 대하여
3 절에서 간단하게 다루어 본다.
정규 문법에서는 생성규칙이 두 가지 면에서 제약되어
있다. 생성규칙의 좌변은 반드시 하나의 변수이어야 하는데 반하여, 우변은 반드시
특별한 형태이어야 한다. 따라서 좀더 강력한 문법을 만들기 위해서는 이러한 제약
중 일부를 완화하여야 한다. 생성규칙의 좌변의 제약은 그대로 두고, 우변에는 어떤
문자열이든 허용함으로써, 문맥-자유 문법을 정의할 수 있다.
정의
1
문법 G = (V, T, S, P) 에서 모든 생성규칙이
의 형태를 가지면 G 를 문맥-자유 문법 (context-free
grammar : CFG) 이라고 한다. 여기서 A ∈ V 이고, x ∈ (V∪T)* 이다.
또한
언어 L 에 대해서 L = L(G) 를 만족하는 문맥-자유 문법 G 가 존재하고 오직 그럴 때에만
L 을 문맥-자유 언어 (context-free language : CFL) 라고 한다.
위의 정의에 의하면 모든 정규 문법은 문맥-자유
문법이 되며, 따라서 정규 언어는 문맥-자유 언어임을 알 수 있다. 그러나, L = {anbn
: n ≥ 0} 와 같은 예로부터 알고 있듯이, 정규 언어가 아닌 언어가 존재한다. 따라서
정규 언어군은 문맥-자유 언어군의 진부분 집합임을 알 수 있다.
문맥-자유 문법이란
이름은 문장 형태에 있는 임의의 변수는 그 변수를 좌변으로 갖는 생성규칙에 의하여
치환될 수 있다는 사실로부터 유래된다. 이러한 치환은 문장 형태(문장)에 있는 나머지
심볼들과는 상관없이 이루어진다. 이런 특징은 생성규칙의 좌변에 변수 하나만이
허용되기 때문에 얻어지는 결과이다.
예제
1
다음의 생성규칙을 갖는 문법 G = ({S}, (a, b},
S, P) 는 문맥-자유 문법이다.
다음은 이 문법에 의한 전형적인 유도이다.
이 예로부터 이 문법에 의해 정의되는 언어가 다음과
같음이 명백하다.
L(G) = {wwR : w ∈ {a, b}*}
따라서 L(G) 는 문맥-자유 언어이지만 정규 언어가 아님이 확인되었다.
예제
2
다음의 생성규칙을 갖는 문법 G = ({S, A, B}, {a,
b}, S, P)는 문맥-자유 문법이다.
이 문법에 의해 정의되는 언어는 다음과 같다.
이에 대한 증명은 독자에게 맡긴다.
위의 두 예제에서 논의된 문법들은 모두 문맥-자유
문법일 뿐만 아니라, 선형 문법이다. 정규 문법과 선형 문법은 당연히 문맥-자유
문법이지만, 문맥-자유 문법은 반드시 선형 문법인 것은 아니다.
예제
3
언어
는 문맥-자유 언어이다.
이를 보이기 위해서는 그 언어에 대한 문맥-자유
문법을 만들어내야 한다. n = m 인 경우는 예제
11 에서 알아보았다. n > m 인 경우를 생각해 보자. 먼저 a 와 b 의 개수가
같은 문자열을 생성한 후 추가로 a 들을 왼쪽에 덧붙인다. 이런 문자열은 다음과
같은 생성규칙에 의하여 유도될 수 있다.
유사한 논리로 n < m 에 대한 경우도 해결할
수 있다. 따라서 언어 L 에 대한 문법의 생성규칙들은 다음과 같음을 알 수 있다.
결과의 문법은 문맥-자유 문법이고, 따라서
L 은 문맥-자유 언어이다. 그러나, 이 문법은 선형 문법은 아니다.
여기서 주어진 문법의 특별한 형식은 설명을
위한 목적으로 선택되었다. 물론 동치인 다른 문맥-자유 문법이 여러 개 존재한다.
실제로 이 언어에 대한 간단한 선형 문법이 존재한다. 이 절의 끝에 있는 연습문제
25 에서 그러한 문법을 찾는 것을 요구할 것이다.
예제
4
다음의 생성규칙을 갖는 문맥-자유 문법 G 를 고려해
보자.
S → aSb | SS | λ
이 문법은 문맥-자유 문법이면서 선형 문법이
아닌 또 다른 예이다. 여기서 abaabb, aababb, ababab ... 등이 L(G) 에 속한
문자열들이다. G 가 생성하는 언어는 다음과 같다는 것을 추측하고 이를 증명하는
것은 그리 어렵지 않을 것이다.
L = {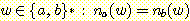 그리고
그리고  ,
,
단,
v 는 w 의 접두부임} (1)
만일 a 와 b 를 각각 왼쪽 괄호와 오른쪽 괄호로
대체한다면, 이 언어가 프로그래밍 언어와 연관이 있음을 분명히 알 수 있다.
이 언어는 (( )), ( ) ( ) ( ) 과 같은 문자열들을 포함하며, 실제로 일반적인
프로그래밍 언어에 대한 올바르게 중첩된 모든 괄호 구조들의 집합이다.
역시 이 언어에 대해 동등한 문법이 여러 개
있다. 그러나 예제 3 과는 달리, 이 언어에 대한 선형 문법이 존재하는지를 알아보는
것은 쉽지 않다. 이에 대한 답은 제 8 장에서 알아보기로 한다.
선형 문법이 아닌 문맥-자유 문법에 대한 유도에서,
두 개 이상의 변수를 포함하고 있는 문장 형태가 나타날 수 있다. 이러한 경우에,
여러 변수들을 어느 순서로 대체할 것인가 하는 선택이 우리에게 주어진다. 예를
들어, 다음의 생성규칙을 갖는 문법 G = ({A, B, S}, {a, b}, S, P) 를 고려해 보자.
문법 G 가 생성하는 언어가  인 것을 쉽게 확인할 수 있다.
인 것을 쉽게 확인할 수 있다.
여기서 문자열 aab 가 유도되는 과정을 다음과
같은 두 가지 방식으로 살펴보기로 하자.
어떤 생성규칙들이 적용되었는지를 보이기 위하여,
생성규칙들에 번호를 매겨서 심볼 ⇒ 위에 적절한 번호를 적어 놓았다. 이로부터
위의 두 유도가 문장을 유도할 뿐 아니라 정확히 같은 생성규칙들을 사용한다는 것을
알 수 있다. 차이점은 단지 생성규칙들이 적용된 순서이다. 이러한 관계없는 요소를
제거하기 위하여, 변수들이 특정 순서로 대체되도록 하는 것이 필요하다.
정의
2
유도 과정의 각 단계에서 각 문장 형태의 가장
좌측 변수가 대체되는 유도를 좌측우선 유도 (leftmost derivation) 라 하며,
가장 우측 변수가 대체되는 유도를 우측우선 유도 (rightmost derivation) 라고
한다.
예제
5
다음의 생성규칙을 갖는 문맥-자유 문법을 고려해
보자.
S → aAB
A → bBb
B → A | λ
여기서 다음의 유도는 문자열 abbbb 에 대한
좌측우선 유도이고,
또한 다음의 유도는 우측우선 유도이다.
유도 과정을 보이는 또 다른 방법으로 유도 트리
(derivation tree) 가 있다. 이 표현 방법은 사용된 생성규칙들의 순서와는 무관하다.
유도 트리는 순서 트리 (ordered tree) 로서 부모 노드는 생성규칙의 좌변에 있는
변수 (혹은 비단말) 로 라벨이 주어지고, 이 노드의 자식 노드들은 대응되는 우변에
있는 심볼들을 표현한다. 예를 들면, 그림 1 은 다음의 생성규칙에 대한 유도 트리의
한 부분을 보여주고 있다.
즉, 유도 트리에서는, 생성규칙의 좌변에 있는
변수를 라벨로 갖는 노드는 이 규칙의 우변에 있는 심볼들을 자식 노드들로 갖게
된다. 유도 트리는 유도 과정에서 각 변수들이 어떻게 대체되는가를 보여준다. 이
개념을 자세하게 정의하면 다음과 같다.
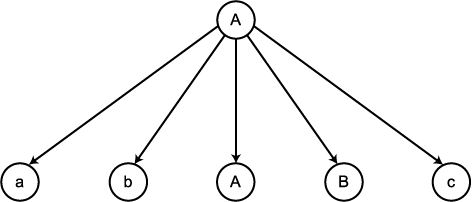
그림 1
정의
3
G = (V, T, S, P) 가 문맥-자유 문법이라 하자.
순서 트리가 G 의 유도 트리가 되기 위한 필요충분 조건은 다음과 같다.
1.
루트 노드의 라벨은 시작 심볼 S 이다.
2.
각 리프 노드의 라벨은 T ∪ {λ} 의 심볼이다.
3.
각 내부 노드의 라벨은 V 의 심볼이다.
4.
만약 라벨이 A ∈ V 인 노드가 라벨이 (왼쪽에서 오른쪽으로 차례로) 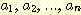 인 자식 노드들을 갖는다면, P 는 다음 형태의 생성규칙을 갖고 있어야 한다.
인 자식 노드들을 갖는다면, P 는 다음 형태의 생성규칙을 갖고 있어야 한다.
5.
라벨이 λ 인 자식 노드는 형제 노드가 없다. 즉, 라벨이 λ 인 자식 노드를
갖는 노드는 다른 자식들을 가질 수 없다.
트리가 위의 조건들 중에서 3, 4, 5 를 항상
만족하며, 1 은 반드시 만족할 필요는 없고, 조건 2 대신 2a 를 만족하는 경우,
이 트리를 부분 유도 트리 (partial derivation tree) 라고 한다.
트리의 리프 노드들을 왼쪽에서 오른쪽으로
차례로 읽어서 얻어진 (λ 은 생략한) 심볼들의 문자열을 이 트리의 생성물 (yield)
이라고 한다. 왼쪽에서 오른쪽으로라는 서술적인 용어는 정확한 의미가 주어질
수 있다. 생성물은 트리가 항상 탐색되지 않은 가장 왼쪽 가지를 택하여 수행하는
깊이-우선 방식 (depth-first manner) 으로 만나게 되는 순서대로의 단말들의
문자열이다.
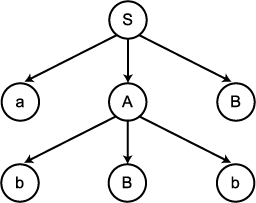
그림 2
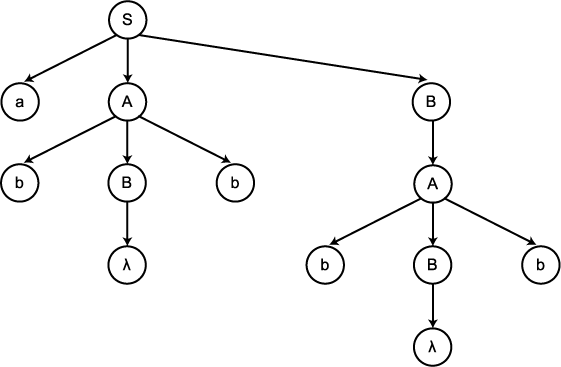
그림 3
그림 2 의 트리는 G 에 대한 부분 유도 트리이고,
반면에 그림 3 의 트리는 유도 트리이다. 여기서 문자열 abBbB 는 그림 2 의
부분 유도 트리의 생성물로서 G 의 문장 형태이다. 또한 문자열 abbbb 는 그림
3 의 유도 트리의 생성물로서 L(G) 에 속하는 문장임을 알 수 있다.
유도 트리는 유도를 명확하고 쉽게 이해되는 표현하는
방법이다. 앞에서 소개한 유한 오토마타의 전이 그래프와 같이, 이 명확성은 논증을
하는 데 있어 큰 도움이 된다. 우선, 유도와 유도 트리와의 관계를 알아보기로 하자.
정리
1
G = (V, T, P, S) 가 문맥-자유 문법이라 하자.
모든 w ∈ L(G) 에 대해, 생성물이 w 인 G 의 유도 트리가 존재한다. 역으로,
모든 유도 트리의 생성물은 L(G) 에 속한다. 만약 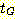 가 로트 노드가 S 인 G 의 부분 유도 트리이면,
가 로트 노드가 S 인 G 의 부분 유도 트리이면, 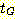 의 생성물은 G 의 문장 형태이다.
의 생성물은 G 의 문장 형태이다.
증명 : 우선 L(G) 의 모든 문장 형태에 대해
이에 대응하는 부분 유도 트리가 존재함을 보이자. 유도에서 적용된 단계수에
대한 수학적 귀납법을 이용하여 증명한다. 기저 (basis) 로서, 한 단계의 유도
과정으로 얻어진 모든 문장 형태에 대해 부분 유도 트리가 존재한다. 이는 만약
S ⇒ u 이면 이에 대한 규칙 S → u 가 존재하며, 정의 3 에 의해 이에 대응하는
부분 유도 트리가 존재한다.
n 단계의 유도 과정으로 유도되는 모든 문장
형태에 대해, 이에 대응되는 부분 유도 트리가 존재한다고 가정하자. 이때 (n
+ 1) 번의 단계를 거친 후에 유도되는 문장 w 는 다음과 같이 유도되어야 한다
: n 단계를 거쳐서,
S 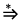 xAy,
xAy, 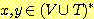 , A ∈ V
, A ∈ V
그리고 마지막으로,
가정에 의해 생성물이 xAy 인 부분 유도 트리가
존재하고, 또한 마지막 단계에 적용되는 생성규칙 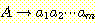 이 G 에 존재한다. 따라서 부분 유도 트리의 리프 노드 A 를 확장함으로써 생성물이
이 G 에 존재한다. 따라서 부분 유도 트리의 리프 노드 A 를 확장함으로써 생성물이
 인 부분 유도 트리를 얻게 된다. 따라서, 귀납법에 의하여 모든 문장 형태에
대해 그 결과가 성립한다.
인 부분 유도 트리를 얻게 된다. 따라서, 귀납법에 의하여 모든 문장 형태에
대해 그 결과가 성립한다.
유사한 방법으로, 모든 부분 유도 트리에 대해,
이에 대한 문장 형태가 존재함을 보일 수 있다. 이에 대한 증명은 연습문제로
남겨둔다.
유도 트리는 또한 리프 노드가 단말 심볼로만
이루어진 부분 유도 트리이다. 따라서 L(G) 의 모든 문장은 G 의 유도 트리의
생성물이며, 모든 유도 트리의 생성물은 L(G) 에 속한다.
유도 트리는 문장을 얻기 위해 어떠한 규칙들이
사용되었는가는 보여주지만, 그들이 어떤 순서로 적용되었는가는 보여주지 못한다.
즉 유도 트리는 어떠한 유도든지 나타낼 수 있으며, 생성규칙이 적용되는 순서는
관계가 없음을 반영한다. 여기서 유도 과정과 유도 트리와의 관계를 살펴보면 다음과
같다. 정의에 의하여, 모든 문자열 w ∈ L(G) 에 대하여 유도가 존재하지만, 우리는
좌측우선 혹은 우측우선 유도가 존재한다고 하지는 않았다. 하지만, 유도 트리가
존재할 경우, 트리에서 항상 가장 왼쪽 변수를 확장하는 방식으로 이 트리가 완성되는
것으로 생각하면, 우리는 항상 좌측우선 유도를 얻을 수 있다. 약간의 세부 사항을
채우면, 모든 w ∈ L(G) 에 대하여, 좌측우선 유도와 우측우선 유도가 존재한다는
당연한 결과를 얻게 된다 (자세한 사항은 이 절의 연습문제 24 를 참조하라).
1. 예제 2 에서
보여진 언어가 주어진 문법에 의해 생성됨을 보여라.
2. 예제 1 의
유도에 대응하는 유도 트리를 그려라.
3. 예제 2 에서
주어진 문법에 대하여, w = abbbaabbaba 에 대한 유도 트리를 보여라. 유도 트리를
이용하여 좌측우선 유도를 구하라.
4. 예제 4 의
문법이 식 (1) 에 의해 정의되는 언어를 생성한다는 것을 보여라.
5. 예제 2 의
언어가 정규 언어인가?
6. 로트 노드
S 를 갖는 모든 부분 유도 트리의 생성물이 문법 G 의 문장 형태임을 보여 정리 1
에 대한 증명을 완성하라.
7. 다음의 각
언어에 대한 문맥-자유 문법을 만들어라. 단, 여기서 n ≥ 0, m ≥ 0 이다.
(a)
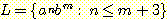
(b)
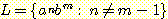
(c)

(d)
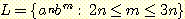
(e)

(f)

(g)
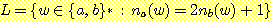
8. 다음의 각
언어에 대한 문맥-자유 문법을 만들어라. 단, 여기서 n ≥ 0, m ≥ 0, k ≥ 0 이다.
(a)

(b)

(c)

(d)

(e)

(f)

(g)

(h)

9. 위의 연습문제
7(a) 의 언어를 L 이라 하자. head(L) 에 대한 문맥-자유 문법을 만들어라. head(L)
에 대한 정의는 4.1 절의 연습문제 18 을 참조하라.
10. 언어 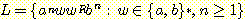 에 대한 문맥-자유 문법을 만들어라.
에 대한 문맥-자유 문법을 만들어라.
11. L 에 대하여
주어진 문법 G 로부터 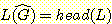 을 만족하는 문법
을 만족하는 문법 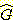 를 어떻게 구성하는지를 보여라.
를 어떻게 구성하는지를 보여라.
12. 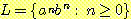 이라 하자.
이라 하자.
(a)
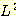 이 문맥-자유 언어임을 보여라.
이 문맥-자유 언어임을 보여라.
(b)
 가 문맥-자유 언어임을 보여라 (단, k ≥ 1).
가 문맥-자유 언어임을 보여라 (단, k ≥ 1).
(c)
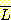 와
와 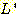 이 모두 문맥-자유 언어임을 보여라.
이 모두 문맥-자유 언어임을 보여라.
13. 연습문제
8(a) 의 언어를 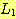 , 그리고 연습문제 8(d) 의 언어를
, 그리고 연습문제 8(d) 의 언어를 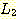 라 하자.
라 하자. 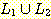 가 문맥-자유 언어임을 보여라.
가 문맥-자유 언어임을 보여라.
14. 다음의
언어가 문맥-자유 언어임을 보여라.
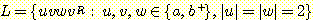
15. 예제 1
의 언어의 여집합이 문맥-자유 언어임을 보여라.
16. 연습문제
8(b) 의 언어의 여집합이 문맥-자유 언어임을 보여라.
17. 언어 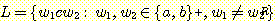 이 문맥-자유 언어임을 보여라. 여기서 Σ = {a, b, c} 이다.
이 문맥-자유 언어임을 보여라. 여기서 Σ = {a, b, c} 이다.
18. 다음의
생성규칙을 갖는 문법에 대해 문자열 aabbbb 의 유도 트리를 그려라.
또한
이 문법에 의해 생성되는 언어를 말로 설명하라.
19. 다음의
생성규칙을 갖는 문법을 고려해 보자.
S → aaB
A → bBb
| λ
B → Aa
문자열
aabbabba 가 이 문법에 의해 유도되지 않음을 보여라.
20. 아래에
주어진 유도 트리를 고려해 보자.

이
트리가 문자열 aab 의 유도 트리가 되도록 하는 간단한 문법 G 를 찾아보아라. L(G)
에 속한 다른 문장 두 개를 찾아라.
21. 두 가지의
괄호, ( ) 와 [ ] 로 이루어진 올바르게 중첩된 괄호 구조에 대하여 정의하라. 직관적으로,
이 경우에서 ([ ]), ([[ ]]), [( )] 등은 올바르게 중첩된 괄호이나, ([) 나 ((]]
는 아니다. 제시한 정의를 사용하여, 모든 올바르게 중첩된 괄호를 생성하는 문맥-자유
문법을 제시하라.
22. 알파벳
{a, b} 에 대한 모든 정규 표현들이 집합에 대한 문맥-자유 문법을 만들어라.
23. 단말들의
집합 T = {a, b} 와 변수들의 집합 V = {A, B, C} 에 대한 문맥-자유 언어들에 대한
모든 생성규칙들을 생성할 수 있는 문맥-자유 문법을 만들어라.
24. 만일 G
가 문맥-자유 문법이라면, 모든 w ∈ L(G) 에 대한 좌측우선 유도와 우측우선 유도가
존재함을 증명하라. 유도 트리로부터 좌측우선 (우측우선) 유도를 구하는 알고리즘을
만들어라.
25. 예제 3
의 언어에 대한 선형 문법을 만들어라.
26. G = (V,
T, S, P) 가 모든 생성규칙이 A → v 형태인 (단, |v| = k > 1) 문맥-자유 언어라
하자. 임의의 문자열 w ∈ L(G) 의 유도 트리의 높이 h 가 다음의 부등식을 만족함을
보여라.
지금까지 주로 문법의 생성적인 측면을 살펴보았다.
즉 문법 G 가 주어졌을 때 G 로부터 유도될 수 있는 문자열들의 집합, 즉 G 가 생성하는
언어가 무엇인가에 대해 살펴보았다. 실제 응용에 있어서는, 주어진 단말들의 문자열
w 가 L(G) 에 속하는지의 여부를 알고자 하는 문법의 분석적인 측면 또한 중요하다.
만약 w 가 L(G) 에 속하는 경우, 우리는 w 에 대한 유도를 찾을 필요가 있을 것이다.
w 가 L(G) 에 속하는지 혹은 아닌지를 판별하는 알고리즘을 소속성 알고리즘이라
한다. 파싱 (parsing) 의 의미는 L(G) 에 속하는 w 가 유도되는 데 사용된 일련의
생성규칙들을 찾는 것이라 할 수 있다.
L(G) 에 속하는 주어진 문자열 w 에 대한 단순한
파싱 방법 가운데 하나는 체계적으로 가능한 모든 (예를 들어, 좌측우선) 유도들을
구성해 가면서 그 중에 w 와 일치하는 것이 있는지를 알아보는 것이다. 구체적으로,
첫 번째 라운드에서 우선 다음과 같은 형태의 시작 심볼을 좌변으로 갖는 모든 생성규칙들을
살펴보아서,
시작 심볼 S 로부터 한 단계에 유도될 수 있는
모든 문장 형태 x 를 찾는다. 만약 어느 x 도 w 와 일치하지 않으면, 다음 라운드에서,
각 x 의 가장 왼쪽 변수에 적용될 수 있는 모든 생성규칙들을 적용한다. 새로운 문장
형태들의 집합이 생성되고, 그 가운데 일부는 w 로 유도될 수 있을 것이다. 계속되는
각 라운드에서, 가장 왼쪽 변수를 취해서 가능한 모든 생성규칙들을 적용한다. 새롭게
생성된 문장 형태들 가운데 w 로 유도될 수 없는 문장 형태는 제외된다. 그러나,
일반적으로, 매라운드마다 문장 형태들의 집합이 남게 된다. 첫번째 라운드가 끝나면,
단 하나의 생성규칙을 적용하여 유도될 수 있는 문장 형태들의 집합이 남게 되고,
두번째 라운드가 끝나면, 두 단계에 유도될 수 있는 문장 형태들의 집합이 남게 되고,
이런 방식으로 계속된다. 만약 w 가 L(G) 에 속하면, 반드시 이에 대한 유한한 길이의
좌측우선 유도가 존재하게 된다. 이 방법은 결국 w 의 좌측우선 유도를 만들어 낸다.
이러한 방법은 w 의 유도를 찾기 위해 시작 심볼
S 로부터 모든 가능한 유도들을 생성하기 때문에 이를 철저한 탐색 파싱 (exhaustive
search parsing) 이라 부른다. 이 파싱 방법은 유도 트리를 루트에서부터 시작하여
아래로 내려오면서 구성하는 것으로 볼 수 있기 때문에, 하향식 파싱 (top-down parsing)
의 한 형태이다.
예제
7
다음의 생성규칙을 갖는 문법 G 에서 문자열 w
= aabb 가 유도되는지의 여부를 살펴보자.
우선 첫 라운드에서 다음의 네 가지 유도가
가능하다.
1. S ⇒ SS
2. S ⇒ aSb
3. S ⇒ bSa
4. S ⇒ λ
위의 유도들 중에서 3 과 4 의 어느 것도 aabb
로 유도될 수 없기 때문에 고려 대상에서 이들을 제외시킬 수 있다. 두 번째
라운드에서 1 의 문장 형태 SS 의 가장 좌측 변수 S 에 생성규칙들을 적용하면
다음의 문장 형태들이 산출된다.
S ⇒ SS ⇒ SSS
S ⇒ SS ⇒ aSbS
S ⇒ SS ⇒ bSaS
S ⇒ SS ⇒ S
유사하게 2 의 문장 형태로부터 다음의 문장
형태들이 산출된다.
S ⇒ aSb ⇒ aSSb
S ⇒ aSb ⇒ aaSbb
S ⇒ aSb ⇒ abSab
S ⇒ aSb ⇒ ab
위의 새로운 문장 형태들 중 일부를 제외시킬
수 있다. 다음 라운드에서, 다음과 같은 aabb 의 유도를 찾을 수 있다.
따라서 aabb 는 주어진 문법에 의해 생성되는
언어에 속한다.
위에서 언급한 철저한 탐색 파싱은 몇 가지 문제점들이
있다. 가장 당연한 문제점은 이 방법이 너무 지루하다는 것이다. 모든 가능한 유도
과정들을 다 고려하기 때문에 효율적인 파싱을 요구하는 경우에는 사용되기 어렵다.
효율성이 가장 중요한 문제가 아니더라도, 더 확실한 단점이 있다. 이 방법은 L(G)
에 속한 문자열은 항상 파싱을 하지만, w 가 L(G) 에 속하지 않은 경우에는, 종료되지
않을 수도 있다. 이에 대한 자세한 설명을 위해, 예제 7 의 문법 G 에서 w = abb
인 경우를 고려해 보자. 이 경우에는 분명히 w 가 L(G) 에 속하지 않음을 알 수 있다.
우리가 철저한 탐색방법에 종료하는 방법을 추가하지 않으면, 철저한 탐색방법은
w 와 일치하는 문장을 찾기 위해 모든 가능한 문장 형태들을 계속 무한히 생성할
것이다.
여기서 만약 문법이 가질 수 있는 형태에 어느
제한을 두면, 철저한 탐색 파싱에서 발생하는 비종료 (nontermination) 문제가 제법
쉽게 해결될 수 있다. 예제 7 을 다시 살펴보면, 문법 G 가 S → λ 형태의 생성규칙을
갖고 있기 때문에 이러한 문제가 발생할 수 있다는 것을 알 수 있다. 이 생성규칙은
유도 과정 중에서 다음에 나타나는 문장 형태들의 길이를 줄이는데 사용될 수 있기
때문에, 언제 수행을 종료할 것인지를 쉽게 알 수가 없게 된다. 만일 이러한 생성규칙들을
갖고 있지 않다면, 문제점들이 많이 줄어든다. 실제로, 두 가지의 바람직하지 않은
형태의 생성규칙들이 알려져 있다. 이들은 A → λ 형태의 생성규칙들 뿐 아니라
A → B 형태의 생성규칙들이며, 이들을 배제시키는 것이 바람직하다. 다음 장에서
확인되는 바와 같이, 이러한 제한이 결과로 주어지는 문법의 능력에 심각한 영향은
주지 않는다.
예제
8
다음의 생성규칙을 갖는 문법 G 를 고려하자.
여기서 G 는 λ-규칙과 A → B 형태의 규칙이
없다. 또한 G 는 λ 를 제외한 예제 7 의 문법이 생성하는 언어와 동일한 언어를
생성한다는 것을 알 수 있다.
또한 모든 문자열 w ∈ {a, b}+
에 대하여 철저한 탐색 파싱 방법은, 항상 |w| 단계 이내에 모든 파싱 과정이
종료하게 된다. 이는 각 유도 단계에서 나타나는 문장 형태가 최소한 한 개의
심볼이 증가되기 때문이다. 따라서 |w| 단계 후에는, w 가 L(G) 에 속하는지
혹은 속하지 않은지의 여부를 판정하면서 성공적으로 종료하게 된다.
이 예제에서의 아이디어는 일반화될 수 있고 일반적인
문맥-자유 문법에 대한 정리로 만들어질 수 있다.
정리
2
문맥-자유 문법 G = (V, T, S, P) 가 다음 형태의
생성규칙을 갖고 있지 않다고 하자.
혹은
여기서 A, B ∈ V 이다. 철저한 탐색 파싱은
모든 w ∈ Σ* 에 대해 w 의 파싱을 산출하든지 파싱이 불가능하다고
알려주는 알고리즘이 될 수 있다.
증명 : 우선 각 문장 형태 w 에 대하여 w 의
길이와 w 를 구성하는 단말 심볼들의 개수를 고려하자. 이때 유도 과정의 각
단계를 살펴보면, 연속적으로 유도되는 각 문장 형태가 최소한 심볼 한 개씩
증가하고 있음을 알 수 있다. 이는 G 가 위의 A → λ 혹은 A → B 형태의 규칙을
갖고 있지 않기 때문이다. 여기서 w 의 길이 혹은 w 를 구성하는 단말 심볼들의
개수가 |w| 를 초과할 수 없기 때문에, 유도 과정의 총 단계수는 2|w| 를 초과할
수 없기 때문에 항상 종료하게 된다.
철저한 탐색방법은 파싱이 항상 이루어질 수 있다는
이론적인 보증은 제공하지만, 실질적인 유용성은 제한되어 있다. 그 이유는 이 방법에
의하여 생성되는 문장 형태들의 수가 지나치게 많을 수가 있기 때문이다. 문장 형태들이
정확하게 얼마나 많이 생성되는지는 경우에 따라 다르다. 정확한 일반적인 결과는
수립될 수는 없지만 대략적인 상한은 구할 수 있다. 만일 우리가 좌측우선 유도로
제한한다면, 첫 단계 후에 우리는 최대 |P| 개의 문장 형태를 가질 수 있고, 두 번째
단계 후에는 최대 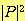 개의 문장 형태를 가질 수 있으며, 계속해서 각 단계 후의 생성될 수 있는 문장
형태들의 최대 개수를 계산할 수 있다. 정리 2 의 증명에서, 우리는 파싱이 2|w|
단계를 넘을 수 없다는 것을 관찰하였다. 따라서 문장 형태의 총 수는 아래의 식으로
주어진 수를 초과할 수 없다.
개의 문장 형태를 가질 수 있으며, 계속해서 각 단계 후의 생성될 수 있는 문장
형태들의 최대 개수를 계산할 수 있다. 정리 2 의 증명에서, 우리는 파싱이 2|w|
단계를 넘을 수 없다는 것을 관찰하였다. 따라서 문장 형태의 총 수는 아래의 식으로
주어진 수를 초과할 수 없다.
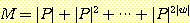 (2)
(2)
이는 철저한 탐색 파싱의 작업량이 문자열의 길이에
대하여 지수적으로 증가할 수 있음을 나타내고 있어 이 방법의 비용을 감당할 수
없게 만든다. 물론 식 (2) 는 단지 한계값이고 때로는 생성되는 문장 형태의 수가
아주 작을 수도 있다. 그럼에도 불구하고, 실제로 철저한 탐색 파싱이 대부분의 경우
아주 비효율적임이 밝혀졌다.
문맥-자유 언어에 대한 더 효율적인 파싱을 구성하는
것은 컴파일러 과목에 속하는 복잡한 내용이다. 우리는 이 구성에 대해서 몇 개의
개별적인 결과를 제외하고는 여기서 추구하지는 않을 것이다.
이 결과를 성취할 수 있는 여러 알려진 방법들이
있다. 그러나 이 방법들 모두는 우리가 추가적인 결과들을 만들어 내지 않고서는
설명할 수 없을 정도로 아주 복잡하다. 6.3 절에서 이 문제를 간략하게 다시 다루어
볼 것이다. 더 자세한 내용들은 Harrison 1978 과 Hopcroft and Ullman 1979 를 참고하기
바란다. 이 문제를 자세하게 추구하지 않는 이유는 이 알고리즘들조차도 만족스럽지
못하기 때문이다. 한 방법은 그 작업량이 문자열의 길이에 3 차 식에 비례하여 지수함수적인
알고리즘보다는 좋지만 여전히 상당히 비효율적이다. 이 알고리즘을 기반으로 하는
컴파일러는 적당히 긴 프로그램조차도 파싱하는 데 지나치게 긴 시간을 필요로 할
것이다. 우리가 갖고자 하는 것은 문자열의 길이에 비례하는 시간이 걸리는 파싱
방법이다. 그런 방법을 선형 시간 (linear time) 파싱 알고리즘이라 부른다. 우리는
일반적인 문맥-자유 언어들에 대한 어떤 선형 시간 파싱 알고리즘도 알고 있지 못한다.
그러나 그러한 알고리즘들은 제한적이지만 중요한 특정 경우에 대해서는 찾아질 수
있다.
정의
4
문맥-자유 문법 G = (V, T, S, P) 의 모든 생성규칙들이
다음과 같은 형태이면 단순 문법 (simple grammar) 혹은 s-문법 (s-grammar)
이라 불린다.
여기서 A ∈ V, a ∈ T, x ∈ V*
이고 임의의 쌍 (A, a) 는 P 에서 많아야 한 번 나타난다.
예제
9
문법
는 s-문법이다. 문법
는 s-문법이 아니다. 그 이유는 쌍 (S, a)
가 두 생성규칙 S → aS 와 S → aSS 에서 나타나기 때문이다.
s-문법들은 상당히 제한적이지만, 그들에게 약간의
흥미는 있다. 우리가 다음 절에서 알아보게 되겠지만, 일반적인 프로그래밍 언어들의
많은 기능들이 s-문법으로 기술될 수 있다.
만일 G 가 s-문법이면, L(G) 에 속한 모든 문자열
w 가 |w| 에 비례하는 노력으로 파싱될 수 있다. 이를 알아보기 위하여, 문자열 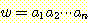 에 대한 철저한 탐색방법을 살펴보자. 좌변에 S 가 있고 우변이
에 대한 철저한 탐색방법을 살펴보자. 좌변에 S 가 있고 우변이 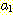 으로 시작하는 생성규칙이 많아야 하나 있을 수 있기 때문에, 유도는 다음과
같이 시작되어야 한다.
으로 시작하는 생성규칙이 많아야 하나 있을 수 있기 때문에, 유도는 다음과
같이 시작되어야 한다.
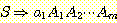
그 다음에 변수 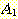 을 치환한다. 역시 많아야 하나의 선택밖에 없기 때문에, 우리는 다음과 같은
유도를 가져야만 한다.
을 치환한다. 역시 많아야 하나의 선택밖에 없기 때문에, 우리는 다음과 같은
유도를 가져야만 한다.
S

우리는 이로부터 각 단계마다 하나의 단말 심볼이
생성되고 따라서 전체 과정이 |w| 단계 내에 완료되어야 한다는 것을 알 수 있다.
논의를 근거로 하여, 우리는 주어진 모든 w ∈
L(G) 에 대하여 철저한 탐색 파싱이 w 에 대한 하나의 유도 트리를 만들어 낼 것이라는
주장을 할 수 있다. 우리가 "하나의 유도 트리" 라 함은 한 문자열에 대하여
여러 개의 다른 유도 트리들이 존재할 가능성이 있기 때문이다. 이러한 상황을 모호성
(ambiguity) 이라 부른다.
정의
5
문맥-자유 문법 G 에서 두 개 이상의 서로 다른
유도 트리를 갖는 문자열 w 가 존재하면, 문법 G 는 모호하다 (ambiguous) 고
한다. 즉 모호성은 어떤 문자열 w 에 대해 두 개 이상의 좌측우선 혹은 우측우선
유도가 존재하는 것을 의미한다.
예제
10
생성규칙 S → aSb | SS | λ 를 갖는 문법 G 는
모호하다. 이는 그림 4 에서와 같이 두 개의 유도 트리들을 갖는 문자열 aabb
가 존재하기 때문이다. 여기서 두 개의 유도 트리는 서로 구조가 상이하다는
것을 알 수 있다. 따라서 이는 aabb 에 대한 좌측우선 유도 (혹은 우측우선 유도)
들이 역시 두 개 존재한다는 것을 의미한다.
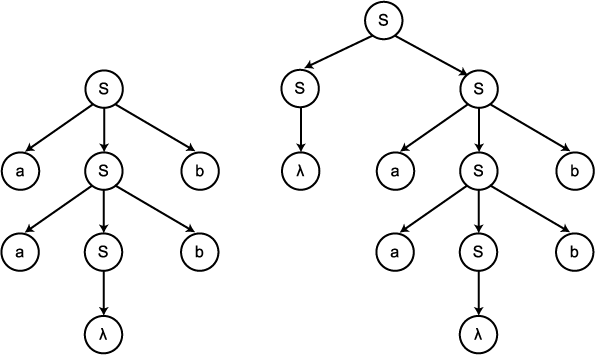
그림 4
모호성은 자연 언어의 일반적인 특징이다. 자연
언어에서는 모호성이 허용되며 여러 가지 방식으로 처리되고 있다. 프로그래밍 언어에서는
각 문장이 정확히 하나의 의미로 해석되어야 하므로 가능한 한 모호성을 제거해야만
한다. 때로는 주어진 문법을 동치이면서 모호하지 않은 (unambiguous) 다른 문법으로
다시 구성함으로써 모호성을 제거할 수 있다.
예제
11
문법 G = ({E, I}, {a, b, c, +, *, (, )}, E,
P) 의 생성규칙이 다음과 같다고 하자.
E → I
E → E + E
E → E * E
E → (E)
I → a|b|c
(a + b) * c 와 a * b + c 와 같은 문자열들이
L(G) 에 속한다. 문법 G 가 C 나 Pascal 과 같은 프로그래밍 언어에 대한 산술식들의
제한된 부분집합을 생성하는 것을 쉽게 알 수 있다. 문법 G 는 모호하다. 이는
문자열 a + b * c 가 그림 5 에서와 같이 상이한 유도 트리들을 갖고 있기 때문이다.
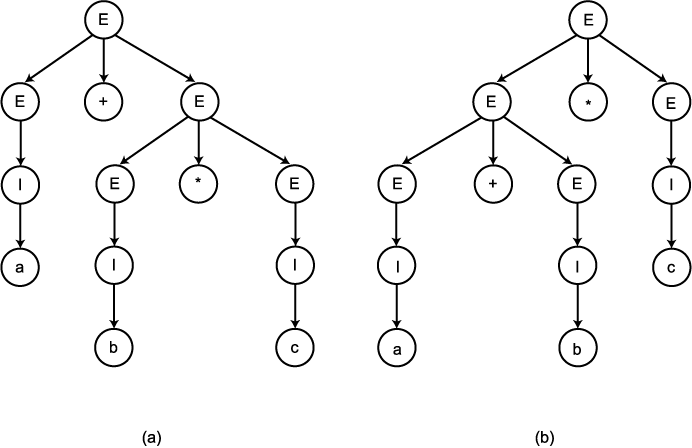
그림 5 a + b * c 에 대한
두 개의 유도 트리
예제
12
예제 11 의 문법을 다시 작성하기 위하여, 새로운
변수들 T 와 F 를 도입하여 V 를 {E, T, F, I} 로 하고 생성규칙들을 다음과
같은 생성규칙들로 대치한다.
E → T
T → F
F → I
E → (E)
I → a|b|c
문장 a + b * c 에 대한 유도 트리가 그림
6 에서 보여진다. 이 문자열에 대한 다른 유도 트리는 존재하지 않는다. 이 문법은
모호하지 않으며, 또한 예제 11 의 문법과 동치이다. 이 특정사례에 대한 이들
주장들을 확인하는 것은 그리 힘들지 않다. 그러나, 일반적으로, 주어진 문맥-자유
문법이 모호한지 또는 두 개의 주어진 문법이 동치인지를 결정하는 문제는 아주
어려운 문제들이다. 실제로, 나중에 우리는 이들 문제들을 해결할 수 있는 일반적인
알고리즘이 존재하지 않는다는 것을 보일 것이다.
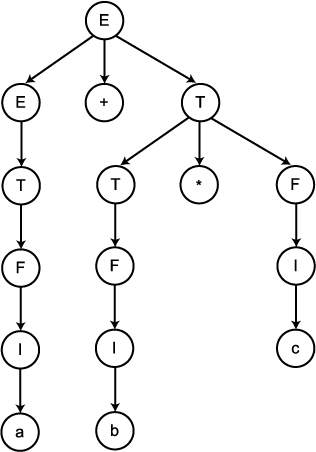
그림 6
앞에서 예를 든 문법들은 동치이면서 모호하지
않은 문법으로 재구성함으로써 모호함을 제거할 수 있었다. 따라서 이러한 의미로서
모호성은 문법에 기인한다. 그러나 어떤 언어는 언어 자체가 갖는 모호성 때문에
모호하지 않은 문법의 구성이 불가능한 경우가 있다.
정의
6
문맥-자유 언어 L 이 모호하지 않은 (unambiguous)
문법을 가지면 L 을 모호하지 않다고 한다. L 을 생성하는 모든 문법들에 대해서
각 문법이 모호하면 L 은 고유적으로 모호 (inherently ambiguous) 하다고 한다.
고유적으로 모호한 언어를 보이는 것은 다소 어려운
일이다. 여기서 우리가 할 수 있는 최선은 고유적으로 모호하다는 납득할 만한 주장을
할 수 있는 예제를 제시하는 것이다.
1. 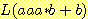 에 대한 s-문법을 만들어라.
에 대한 s-문법을 만들어라.
2. 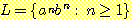 에 대한 s-문법을 만들어라.
에 대한 s-문법을 만들어라.
3.  에 대한 s-문법을 만들어라.
에 대한 s-문법을 만들어라.
4. 모든 s-문법은
모호하지 않다는 것을 보여라.
5. G = (V,
T, S, P) 를 s-문법이라 하자. P 의 최대 크기를 |V| 와 |T| 의 식으로 표현하라.
6. 다음의 생성규칙을
갖는 문법이 모호하다는 것을 보여라.
S → AB
| aaB
A → a
| Aa
B → b
7. 위의 연습문제
6 의 문법과 동치이면서 모호하지 않은 문법을 만들어라.
8. 예제 12
의 문법을 사용하여 (((a + b) * c)) + a + b 에 대한 유도 트리를 그려라.
9. 정규 언어는
고유적으로 모호하지 않다는 것을 보여라.
10. Σ = {a,
b} 에서 생성될 수 있는 모든 정규 표현들의 집합을 생성하는 모호하지 않은 문법을
만들어라.
11. 모호한
정규 문법이 존재할 수 있는가?
12. 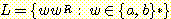 이 고유적으로 모호하지 않다는 것을 보여라.
이 고유적으로 모호하지 않다는 것을 보여라.
13. 다음의
생성규칙을 갖는 문법이 모호하다는 것을 보여라.
14. 예제 4
의 문법은 모호하지만, 이 문법에 의해 생성되는 언어는 모호하지 않다는 것을 보여라.
15. 예제 13
에서의 문법이 모호하다는 것을 보여라.
16. 예제 5
의 문법이 모호하지 않다는 것을 보여라.
17. 철저한
탐색 파싱 방법을 사용하여 문자열 abbbbbb 를 예제 5 의 문법에 대하여 파싱하라.
일반적으로, 이 언어에 속한 문자열 w 를 파싱하는 데 얼마나 많은 단계를 필요로
하는가?
18. 예제
14 에서의 문법이 모호하지 않다는 것을 보여라.
19. 다음의
결과를 증명하라. G = {V, T, S, P} 를 문맥-자유 문법이라 하자. 이 문법에서 모든
A ∈ V 는 많아야 하나의 생성규칙의 좌변에 나타난다. 그러면 이 문법은 모호하지
않다.
20. 예제 5
에서의 문법과 동치이면서 정리 2 의 조건을 만족하는 문법을 구하라.
형식 언어 이론을 실제적으로 응용하는 데 있어
중요한 점은 프로그래밍 언어를 정의하여 이들 언어에 대한 컴파일러 (compiler)
와 해석기 (interpreter) 를 만드는 것이다. 여기서 중요한 점은 프로그래밍 언어를
정확히 정의하고 이를 기반으로 하여 효율적이고 신뢰성 있는 번역 프로그램 (translation
programs) 을 구현하는 데 있다. 지금까지 배운 바에 의하면 정규 언어는 프로그래밍
언어의 어휘, 단어 등과 같은 단순한 패턴들을 정의하는 데 이용되는 반면에, 우리가
이 장의 서론에서 주장하였듯이, 이보다 복잡한 구성을 모델링하기 위해서는 문맥-자유
언어가 필요하다.
대부분의 다른 언어들과 마찬가지로 프로그래밍
언어는 문법을 이용하여 정의한다. 이러한 문법을 정의하기 위해 전형적으로 사용되는
기술 방법이 Backus-Naur 형 (= BNF) 이다. BNF 는 지금까지 사용했던 문법의 표기와
거의 유사하다. 따라서 예제 12 의 문법의 일부를 다음과 같은 표기로 BNF 로 표기할
수 있다.
<expression> ::= <term> | <expression>
+ <term>
<term> ::= <factor> | <term>
* <factor>
여기서 + 와 * 는 단말 심볼이며, ::= 는 → 를
나타낸다. 단지 변수는 처음은 < 로, 끝은 > 로 표기된다 (예 : <expression>,
<term>.. 등). 따라서 BNF 는 변수를 좀더 확실히 구분하여 나타나는 것 외에는
앞의 문법의 표기방법과 차이가 없다.
Pascal 과 같은 프로그래밍 언어의 많은 부분이
앞에서 배운 제한된 형태의 문맥-자유 문법으로 정의가 가능하다. 예를 들면, Pascal
의 if-then-else 문장은 다음과 같이 정의될 수 있다.
여기서 if 는 단말 심볼이며 다른 모든 심볼들은
다른 규칙에 의해 정의되는 변수이다. 예제 9 와 비교하면 위의 표기는 s-문법에서
요구하는 규칙과 유사하다는 것을 알 수 있다. 즉 좌변의 <if_statement> 변수는
항상 우변의 처음에 나타나는 단말 심볼인 if 와 연관되어 있다. 여기서 우리는 프로그래밍
언어에서 왜 키워드 (keyword) 가 사용되는지 그 이유를 알 수 있다. 키워드는 프로그램의
독자에게는 도움이 되는 어떤 시각적인 구조를 제공할 뿐 아니라 컴파일러의 작업을
더욱 쉽게 해준다.
불행하게도, 프로그래밍 언어의 모든 기능들이
s-문법에 의해 정의될 수는 없다. 예를 들면, 위의 <expression> 의 규칙이
이에 속하는 것으로서 이는 파싱을 어렵게 만드는 요인이 된다. 그렇다면 우리는
어떤 문법 규칙들을 허용할 수 있고 여전히 효율적인 파싱을 할 수 있을까 하는 문제가
제기된다. 컴파일러에서는 LL 문법과 LR 문법이라 불리는 문법들이 많이 사용되고
있다. LL 과 LR 문법들은 프로그래밍 언어들의 그리 명확하지 않는 기능들을 표현할
수 있으며, 또한 선형 시간 (linear time) 에 파싱을 효율적으로 할 수 있다. 이는
간단한 내용이 아니며, 이에 대한 대부분은 우리의 논의의 범위에서 벗어난다. 우리는
제 6 장에서 이 주제에 대하여 간략하게 다룰 것이다. 그러나 우리의 목표를 위해서는
그러한 문법들이 존재하고 널리 연구되고 있다는 것만 이해하면 충분하다.
이와 연관해서, 모호성의 문제에 추가적인 중요성을
부여하여야 한다. 프로그래밍 언어의 명세 (specification) 는 모호하지 않아야 한다.
그렇지 않으면, 어떤 프로그램이 여러 다른 컴파일러에 의해 처리되거나 여러 다른
시스템에서 실행될 경우 여러 다른 결과들을 산출할 수도 있을 것이다. 이에 우리에게
필요한 것은 한 문맥-자유 문법의 모호성을 찾아내고 제거하는 알고리즘과 한 언어가
고유적으로 모호한지 아닌지를 결정하는 알고리즘들이다. 그러나 불행하게도, 이들은
아주 어려운 작업들이고, 우리가 후에 확인하게 되겠지만, 일반적으로 이들 문제를
해결하는 것은 불가능하다.
문맥-자유 문법으로 모델링이 될 수 있는 프로그래밍
언어의 모습들을 보통 구문 (syntax) 이라고 한다. 그러나 구문적으로 올바른 프로그램
모두가 실제로 만족할 만한 프로그램은 아니라는 것이 일반적인 경우이다. 예를 들면,
Pascal 에서의 BNF 정의는 변수 (variable) 선언에 대해 다음과 같은 구성을 허용한다.
var x, y : real ;
x, z : integer
혹은
var x : integer,
x := 3.2
이 두 구성 어느 것도 Pascal 컴파일러에 의해
승인될 수 없다. 그 이유는 그들이 "정수 변수에는 실수 값이 배정될 수 없다"
와 같은 다른 제약조건들을 위반하고 있다. 이러한 종류의 제약조건은 특정 구성의
의미를 어떻게 해석하는가와 관계가 있기 때문에 프로그래밍 언어의 어의 (semantics)
에 관한 부분이다.
프로그래밍 언어의 어의는 매우 복잡하다. 어느
것도 문맥-자유 문법만큼 프로그래밍 언어의 어의를 정확하고 멋지게 표현하지 못한다.
결과적으로 일부 어의적인 특징들이 빈약하게 정의되거나 모호할 수도 있다. 프로그래밍
언어의 어의를 정의하는 효과적인 방법들이 제안되었으나, 그중 어느 것도 문맥-자유
문법만큼 널리 인정되고 어의적인 정의에 성공적이지 못하였다.
1. Pascal 에 대한 <expression> 의 완전한
정의를 제시하라.
2. Pascal while 문장에 대한 BNF 정의를 제시하라.
일반적인 개념 <statement> 는 정의하지 않아도 된다.
3. Pascal 프로그램과 그것의 부프로그램과의 관계를
보여주는 BNF 문법을 제시하라.
4. FORTRAN do 문장에 대한 BNF 정의를 제시하라.
5. C 에서의 if-else 문장의 올바른 형태에
대한 정의를 제시하라.
6. 문맥-자유 문법으로 기술도리 수 없는 C 의
기능들의 예를 찾아보아라.

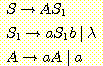
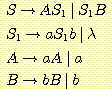

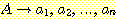

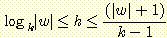
 에 비례하는 수의 단계 내에 파싱하는 알고리즘이 존재한다.
에 비례하는 수의 단계 내에 파싱하는 알고리즘이 존재한다.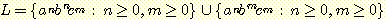
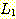 과
과 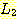 의 합집합으로 볼 수 있다.
의 합집합으로 볼 수 있다.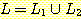
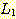 은 다음과 같은 생성규칙을 갖는 문법에 의하여 생성되고
은 다음과 같은 생성규칙을 갖는 문법에 의하여 생성되고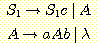
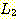 는 시작 심볼이
는 시작 심볼이 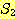 이고 다음과 같은 생성규칙을 갖는 유사한 문법에 의하여 생성된다.
이고 다음과 같은 생성규칙을 갖는 유사한 문법에 의하여 생성된다.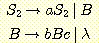
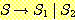
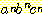 은 하나는
은 하나는  으로 시작하고 다른 하나는
으로 시작하고 다른 하나는  으로 시작하는 두 개의 다른 유도들을 갖기 때문이다. 물론 이로부터 L 이 고유적으로
모호하다고 할 수는 없다. 그 이유는 L 에 대한 어떤 다른 모호하지 않은 문법이
존재할 수도 있기 때문이다. 그러나
으로 시작하는 두 개의 다른 유도들을 갖기 때문이다. 물론 이로부터 L 이 고유적으로
모호하다고 할 수는 없다. 그 이유는 L 에 대한 어떤 다른 모호하지 않은 문법이
존재할 수도 있기 때문이다. 그러나 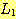 과
과 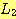 는 상반된 요구사항을 가지고 있다.
는 상반된 요구사항을 가지고 있다. 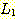 은 a 와 b 의 수가 같아야 하고 반면에
은 a 와 b 의 수가 같아야 하고 반면에 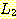 는 b 와 c 의 수가 같아야 한다. 몇 번의 시도를 통하여 이들 요구사항들을 n
= m 의 경우를 유일하게 처리하는 규칙들의 단일 집합으로 결합하는 것이 불가능하다는
것을 확신하게 될 것이다. 엄격한 증명은 아주 기술적이다. Harrison 1978 에서
그 증명을 찾아볼 수 있다.
는 b 와 c 의 수가 같아야 한다. 몇 번의 시도를 통하여 이들 요구사항들을 n
= m 의 경우를 유일하게 처리하는 규칙들의 단일 집합으로 결합하는 것이 불가능하다는
것을 확신하게 될 것이다. 엄격한 증명은 아주 기술적이다. Harrison 1978 에서
그 증명을 찾아볼 수 있다.