СЄИЎ СѕИэ (Theorem Proving)
РЮАјСіДЩ ПјЗа : РЏМЎРЮ, БГЧаЛч, 1988, Page 213~245
2. КёБГШэМі КЮСЄ НУНКХл (resolution refutation system)
(2) КёБГШэМі КЮСЄ (resolution refutation)
(3) КёБГШэМі (resolution) АњСЄ СІОю
3. БдФЂПЁ БтУЪЧб УпЗа (rule-based deduction)
(1) РќЧт (forward) УпЗа НУНКХл
(2) ШФЧт (backward) УпЗа НУНКХл
РЬ РхПЁМДТ СЄИЎ СѕИэРЛ РЇЧи РЬПыЕЧДТ ЕЮ АГРЧ НУНКХл, Ся КёБГШэМі КЮСЄ (resolution refutation) НУНКХлАњ БдФЂПЁ БтУЪЧб ПЌПЊ (rule-based deduction) НУНКХлПЁ ДыЧи АэТћЧбДй.
КёБГШэМі КЮСЄ НУНКХлРК ОюЖВ ИёЧЅЙЎРхРЬ, СжОюСј ЙЎРхЕщРЧ С§ЧеРИЗЮКЮХЭ ГэИЎРћРИЗЮ ЕкЕћИЃАэ РжДТСіИІ СѕИэЧЯБт РЇЧи РЬ ИёЧЅЙЎРхРЛ ИеРњ КЮСЄЧб ШФ СжОюСј ЙЎРхЕщАњ ЧеЧЯПЉ ЛѕЗЮПю С§ЧеРЛ ИИЕщАэ, Бз ДйРНПЁ КёБГШэМі (2 Р§ПЁМ О№Бо) АњСЄРЛ РЬПыЧиМ И№МјРЛ РЏЕЕЧЯДТ НУНКХлРЬДй. ЙАЗа РЬЗЏЧб ЙцЙ§РЬ ГэИЎРћРИЗЮ СЄДчЧЯДйДТ АЭРК ЕоР§ПЁМ СѕИэЕШДй. КёБГШэМі КЮСЄ НУНКХлРЧ СпНЩРћРЮ СжСІДТ КёБГШэМіЙцЙ§РЛ ИэШЎШї РЬЧиЧЯДТЕЅМ КёЗдЕШДй. КёБГШэМіПЁ ЛчПыЕЧДТ ЙЎРхЕщРК ПьМБ РћПыАЁДЩЧб ЧЅЧіЧќХТ (Р§ (clause) РЬЖѓ ЧЯИч (1) Р§ПЁМ КЏШЏР§ТїИІ О№Бо) ЗЮ КЏШЏЕЧОюОп ЧбДй. ДѕПьБт ОюЖВ ЙЎРхРЛ МБХУЧЯПЉ КёБГШэМіАњСЄРЛ МіЧрЧв АЭРЮАЁ ЧЯДТ СІОюЙцЙ§ ((3) Р§ПЁМ РкММШї О№Бо) РК НУНКХлРЧ ШПРВМКРЛ СѕАЁНУХАДТЕЅ БтПЉИІ ЧЯАд ЕШДй.
РЮАјСіДЩ НУНКХлПЁ РЧЧи ЛчПыЕЧДТ СіНФРЧ ДыКЮКаРК ОЯНУБтШЃ (ЂЁ) ИІ ЛчПыЧиМ ЧЅЧіРЬ АЁДЩЧЯДй. КёБГШэМі КЮСЄ НУНКХлПЁМДТ РЬЗЏЧб ЧЅЧіРЛ ПьМБ Р§ЕщРЧ ЧЅЧіРИЗЮ КЏШЏЧЯПЉ ЛчПыЧбДй. БзЗЏГЊ РЬЗЏЧб КЏШЏАњСЄПЁМДТ ОЯНУРћ ЧЅЧіПЁМ СжОюСіДТ ОюЖВ РЏПыЧб СІОюСЄКИИІ РвОю ЙіИБ Мі РжДй. ПЙИІ ЕщОю Р§РЧ ЧЅЧі (A Ё§ B Ё§ C) ДТ ОЯНУРћ ЧЅЧі (~A Ёќ ~B) ЂЁ C, (~A Ёќ ~C) ЂЁ B, (~B Ёќ ~C) ЂЁ A, ~A ЂЁ (B Ё§ C), ~B ЂЁ (A Ё§ C), ~C ЂЁ (A Ё§ B) ЕюАњ ГэИЎРћРИЗЮДТ ААСіИИ, РЬЗЏЧб ОЯНУРћ ЧЅЧіЕщПЁДТ Р§РЧ ЧЅЧіПЁ ГЊХИГЊСі ИјЧЯДТ АЂБт ДйИЅ СІОюСЄКИИІ АЁСјДй. КёБГШэМі КЮСЄ НУНКХлАњДТ ДоИЎ БдФЂРЛ БтУЪЗЮ Чб ПЌПЊ НУНКХлРЬЖѕ ОЯНУРћ ЧЅЧі Бз РкУМИІ БдФЂРИЗЮ ЛчПыЧЯДТ НУНКХлРЬДй.
БдФЂРЛ БтУЪЗЮ Чб ПЌПЊ НУНКХлПЁДТ РЬПЭ ААРЬ РЯЙнРћ СіНФРЛ ЧЅЧіЧб БдФЂ (rule) ЕщАњ РќУМ ЕЅРЬХЭКЃРЬНК (global database) ИІ РЬЗчДТ ЦЏСЄЧб СіНФРЛ ЧЅЧіЧб ЛчНЧЕщ (БдФЂЕщРЬ РћПыЕЪПЁ ЕћЖѓ РќУМ ЕЅРЬХЭКЃРЬНКРЧ ГЛПыРЬ КЏЧи АЈ) ЗЮКЮХЭ ИёЧЅ wff ИІ СѕИэЧбДй. РЬЗЏЧб ПЌПЊ НУНКХлРК РќЧт (forward) НУНКХлАњ ШФЧт (backward) НУНКХлРИЗЮ КаЗљЕШДй.
РќЧт НУНКХлРЬЖѕ, РќУМ ЕЅРЬХЭКЃРЬНКАЁ ИёЧЅ wff ИІ ЦїЧдЧЯАд ЕЩ ЖЇБюСі РќУМ ЕЅРЬХЭКЃРЬНКПЁ БдФЂ (F-БдФЂРЬЖѓ Чд ) ЕщРЛ РћПыНУХАДТ АЭРЬИч, ШФЧт НУНКХлРЬЖѕ, ИёЧЅ wff ЗЮ ЕШ РќУМ ЕЅРЬХЭКЃРЬНКПЁ БдФЂ (B-БдФЂРЬЖѓ Чд) ЕщРЛ РћПыНУФб ПјЗЁ СжОюСј ЛчНЧЕщЗЮ РЬЗчОюСј РќУМ ЕЅРЬХЭКЃРЬНКИІ РЏЕЕЧЯДТ НУНКХлРЬДй.
СІ 2 РхПЁМ ГэИЎБтШЃИІ РЬПыЧб СіНФ ЧЅБтЙцЙ§ПЁ ДыЧи ЛьЦьКИОвДй. СіНФ ЧЅЧіРЮ Рп БИМКЕШ АјНФ (wff) РЧ Чб СОЗљЗЮ Р§ (clause) РЬ РжДТЕЅ, Р§РЬЖѕ ЙЎРкЕщРЧ ГэИЎЧеРИЗЮ БИМКЕШ wff ЗЮ СЄРЧЕШДй. ПЉБтМ ГэЧв КёБГШэМіЙцЙ§РЬЖѕ РЬЗЏЧб Р§ЕщПЁ РћПыЕЧДТ ЧЯГЊРЧ СпПфЧб УпЗаБдФЂРЬДй. КёБГШэМіЙцЙ§РЛ МГИэЧЯБтПЁ ОеМ ИеРњ ОЦЗЁРЧ ММњЧќ ИэСІ wff РЛ Р§ЕщРЧ С§ЧеРИЗЮ КЏШЏНУХАДТ АњСЄРЛ ЛьЦьКИРк.
(ЂЃx) {P(x) ЂЁ {(ЂЃy) [P(y) ЂЁ P(f(x, y))] Ёќ ~(ЂЃy) [Q(x, y) ЂЁ P(y)]}}
1) ЂЁ РЛ СІАХЧбДй : РЬАЭРК X1 ЂЁ X2 ПЭ ~X1 Ё§ X2 РЬ ЕПФЁЖѓДТ ЛчНЧРЛ РЬПыЧбДй. РЇРЧ СжОюСј wff ИІ КЏШЏНУХАИщ
(ЂЃx) {~P(x) Ё§ {(ЂЃy) [~P(y) Ё§ P(f(x, y))] Ёќ ~(ЂЃy) [~Q(x, y) Ё§ P(y)]}}
2) ~РЧ ПЕПЊРЛ УрМвЧбДй : РЬАЭРК ~(~P) = P, ~(A Ёќ B) = ~A Ё§ ~B, ~(A Ё§ B) = ~A Ёќ ~B, ~(ЂЃx) Px = (ЂЄx) ~P(x), ~(ЂЄx)P(x) = (ЂЃx)~P(x) ЕюПЁ РЧЧи РЬЗчОюСјДй. ДмАш 1 ЗЮКЮХЭРЧ wff ИІ КЏШЏНУХАИщ
(ЂЃx) {~P(x) Ё§ {(ЂЃy) [~P(y) Ё§ P(f(x, y))] Ёќ (ЂЄy) [Q(x, y) Ёќ ~P(y)]}}
3) КЏМіЕщРЛ ЧЅСиШЧбДй : КЏМіДТ АЁЛѓРЬИЇРЬАэ wff РЧ СјИЎАЊПЁДТ ПЕЧтРЛ ЙЬФЁСі ОЪРИЙЧЗЮ АЂ ЧбСЄЛчДТ АэРЏЧб АЁЛѓКЏМіИІ АЁСњ Мі РжДй. Ся (ЂЃx) [P(x) ЂЁ (ЂЄx)Q(x)] ДТ (ЂЃx) [P(x) ЂЁ (ЂЄy)Q(y)] ЗЮ КЏЧќЕЧОю КЏМі ЧЅСиШИІ РЬЗщДй. ДмАш 2 ЗЮКЮХЭРЧ wff ИІ КЏШНУХАИщ
(ЂЃx) {~P(x) Ё§ {(ЂЃy) [~P(y) Ё§ P(f(x, y))] Ёќ (ЂЄw) [Q(x, w) Ёќ ~P(w)]}}
4) СИРчЧбСЄБтШЃ (existential quantifier) ИІ СІАХЧбДй : (ЂЃy)[(ЂЄx)P(x, y)] ЖѓДТ wff ИІ ПьИЎИЛЗЮ ЧЯИщ 'И№Еч y ПЁ ДыЧи P(x, y) ИІ ИИСЗНУХАДТ y ПЁ СОМгЕЧДТ x АЁ СИРчЧбДй' ЗЮ ЕШДй. ПЉБтМ y ПЁ СОМгЕЧОю АсСЄЕЧДТ x ИІ y ПЁ ДыЧб ОюЖВ ЧдМіЗЮ ЧЅЧіЧи g(y) ЗЮ ЧЅЧіЧв Мі РжДй. РЬПЭ ААРК ЧдМі g ИІ НКФнЗН ЧдМі (Skolem function) Жѓ ЧЯИч, ДѕПьБт ОюЖВ ИХАГ КЏМіЕЕ АЁСіСі ОЪДТ НКФнЗН ЧдМіИІ НКФнЗН ЛѓМі (Skolem constant) Жѓ ЧбДй. ДмАш 3 РИЗЮКЮХЭРЧ wff ПЁ РЬИІ РћПыНУХАИщ
(ЂЃx) {~P(x) Ё§ {(ЂЃy) [~P(y) Ё§ P(f(x, y))] Ёќ [Q(x, g(x)) Ёќ ~P(g(x))]}}
5) ЧСИЎДаНК Чќ (prenex form) РИЗЮ КЏШЏЧбДй : ДмАш 4 ИІ ЧрЧб ШФРЧ wff ДТ ЧбСЄЛч (quantifier) ЗЮ РќУМЧбСЄБтШЃ (universal quantifier) ЕщИИ ГВАэ РЬЕщ КЏМіЕщРК РЬЙЬ ЧЅСиШЕЧОњРИЙЧЗЮ РЬАЭЕщРЛ wff РЧ СІРЯ ОеПЁ ГѕОЦ СјИЎАЊПЁ ПЕЧтРЛ СмРЬ ОјРЬ АЂ ЧбСЄЛчРЧ ПЕПЊРЛ wff РќУМПЁ ЙЬФЁЕЕЗЯ Чв Мі РжДй. РЬПЭ ААРЬ ЧЯПЉ КЏШЏЕШ wff ИІ ЧСИЎДаНК ЧќРИЗЮ ЧЅБтЕЧОњДй ЧбДй. ЖЧЧб ЧСИЎДаНК ЧќРЧ wff ПЁМ ЧбСЄЛчЕщЗЮИИ ЕШ ОеКЮКаРЛ СЂЕЮЛч (prefix) Жѓ ЧЯАэ ГЊИгСі ЕоКЮКаРЛ ИХЦЎИЏНК (matrix) Жѓ ЧбДй. ДмАш 4 ЗЮКЮХЭРЧ КЏШЏЕШ ЧСИЎДаНК ЧќРК
(ЂЃx)(ЂЃy) {~P(x) Ё§ {[~P(y) Ё§ P(f(x, y))] Ёќ [Q(x, g(x) Ёќ ~P(g(x))]}}
6) ИХЦЎИЏНКИІ ГэИЎАіРЧ СЄБдЧќ (conjunctive normal form) РИЗЮ КЏШЏЧбДй. ГэИЎАіРЧ СЄБдЧќРЬЖѕ ЙЎРк (literal) ЕщРЧ ГэИЎЧеРИЗЮ РЬЗчОюСј РЏЧбС§ЧеПЁ ДыЧб ГэИЎАіРЛ ИЛЧбДй. ДмАш (5) ПЁМРЧ ИХЦЎИЏНКДТ КаЙшБдФЂРЛ ПЌМгРћРИЗЮ РћПы, (X1 Ё§ (X2 Ёќ X3)) ДТ (X1 Ё§ X2) Ёќ (X1 Ё§ X3) ЗЮ ЧдПЁ РЧЧи ДйРНАњ ААРЬ ЕШДй.
(ЂЃx)(ЂЃy) {[~P(x) Ё§ ~P(y) Ё§ P(f(x, y))] Ёќ [~P(x) Ё§ Q(x, g(x))] Ёќ [~P(x) Ё§ ~P(g(x))]}
7) СЂЕЮЛчИІ Л§ЗЋЧбДй : ДмАш 6 ПЁМ БИЧб wff ПЁМ СЂЕЮЛчИІ СІАХЧЯАэ АјНФПЁ ГЊХИГЊДТ И№Еч КЏМіДТ РќУМ ЧбСЄБтШЃЗЮ ЧбСЄЕШ КЏМіЗЮНс АЁСЄЧбДй.
8) Ёќ ИІ ОјОиДй : Ся X1 Ёќ X2 ДТ {X1, X2} ЗЮ ЧЅЧіЕШДй. РЬПЭ ААРЬ ГЊХИГЊДТ АЂАЂРЧ ЕЖИГЕШ РЮРкИІ Р§ (clause) РЬЖѓ КЮИЅДй. БзЗЏЙЧЗЮ ДмАш (7) РЬ АјНФРК ДйРНАњ ААРК Р§ЕщРЧ С§ЧеРИЗЮ КЏШЏЕШДй.
~P(x) Ё§ ~P(y) Ё§ P(f(x, y))
~P(x) Ё§ Q(x, g(x))
~P(x) Ё§ ~P(g(x))
9) КЏМіЕщРЛ СЖСЄЧбДй : РЬАЭРК ДмАш (8) ПЁМ БИЧб ОюЖАЧб ЕЮ АГРЧ Р§ЕЕ ААРК РЬИЇРЧ КЏМіАЁ ГЊХИГЊСі ОЪЕЕЗЯ ЧЯБт РЇЧиМДй. БзЗЏЙЧЗЮ ДйРНАњ ААРЬ КЏМі СЖСЄРЛ Чв Мі РжДй.
~P(x1) Ё§ ~P(y) Ё§ P(f(x1, y))
~P(x2) Ё§ Q(x2, g(x2))
~P(x3) Ё§ ~P(g(x3))
РЇРЧ 9 АЁСі ДмАшИІ АХУФ wff ДТ Р§ЕщРЧ С§ЧеРИЗЮ КЏШЏРЬ ЕШДй. ИИРЯ wff X АЁ wff ЕщРЧ С§Че S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃДТ (logically follow) АЭРЬЖѓИщ С§Че S ПЁ РжДТ И№Еч wff ЕщРЛ Р§РЧ ЧќХТЗЮ КЏШЏНУХВ С§ЧеПЁ wff X ДТ ГэИЎРћРИЗЮ ЕкЕћИЃДТ АЭРЛ КИРЯ Мі РжДй. БзЗЏЙЧЗЮ Р§РЧ ЧЅЧіИИРЛ УыБоЧЯДТ КёБГШэМіЙцЙ§РК СЄИЎСѕИэ НУНКХлПЁМРЧ Чб УпЗаБдФЂРИЗЮ РЬПыРЬ ЕЩ Мі РжРНРЬ СЄДчШ ЕШДй.
ИИРЯ КЏМіИІ АЁСіСі ОЪДТ ЧзРЬ Р§РЧ КЏМіПЁ ДыФЁЕЧОюСњ ЖЇ ГЊХИГЊДТ ЧЅЧіРЛ КЛЗЁ Р§РЧ БтУЪПЙНУ (ground instance) Жѓ ЧбДй. ПЙЗЮМ РЯСОРЧ ДмМјЧб Р§РЮ Q(A, f(B)) ДТ Q(x, y) РЧ Чб БтУЪПЙНУРЬДй. КёБГШэМіЙцЙ§РЛ НБАд РЬЧиЧЯДТ ЙцЙ§РК РЬЗЏЧб БтУЪР§ЕщПЁ ОюЖЛАд КёБГШэМіЙцЙ§РЬ РћПыЕЧДТАЁ ЛьЦь КИДТ АЭРЬ ЦэИЎЧЯДй. ЕЮ АГРЧ БтУЪ Р§, P1 Ё§ P2 Ё§ ЁІ Ё§ PN Ањ ~P1 Ё§ Q2 Ё§ ЁІ Ё§ QM РЬ РжДйАэ ЧЯРк. Pi ПЭ Qj И№ЕЮ МЗЮ ДйИЅ АЭРЬЖѓАэ АЁСЄЧбДй. РЬ ЕЮ АГРЧ КЮИ№Р§ (parant clause) ЗЮКЮХЭ КёБГШэМі Р§ (resolvent) РЬЖѓДТ ЛѕЗЮПю Р§РЛ ГэИЎРћРИЗЮ РЏЕЕЧв Мі РжДй. РЬ КёБГШэМіР§РК ЕЮ АГРЧ Р§ПЁ ДыЧи ГэИЎЧеРЛ УыЧЯИщ P1 Ё§ ~P1 Ё§ P2 Ё§ ЁІ Ё§ PN Ё§ Q2 Ё§ ЁІ Ё§ QM РЬ ЕЧИч ПЉБтМ КИМіНж (complementary pair) РЮ P1 Ё§ ~P1 РЛ СІАХЧдПЁ РЧЧи БИЧиСјДй. КёБГШэМіЙцЙ§РЧ ШяЙЬЗгАэ ЦЏМіЧб АцПьАЁ ЧЅ 1 ПЁ РжДй. ДйРНПЁДТ РЬЗБ ДмМјЧб БдФЂРЬ КЏМіИІ СіДб Р§ЕщПЁДТ ОюЖЛАд ШЎРхЕЧДТСі ЛьЦьКИРк.
ЧЅ 1
|
КЮИ№ Р§Ещ |
КёБГШэМіР§ |
МГИэ |
|
P, ~P Ё§ Q (Ся P ЂЁ Q) |
Q |
И№ДѕНК ЦїГйНК(modus ponens) |
|
P Ё§ Q, ~P Ё§ Q |
Q |
РЬ КёБГШэМіР§РЛ ЧеКД (merge) РЬЖѓ Чд |
|
P Ё§ Q, ~P Ё§ ~Q |
Q Ё§ ~Q, P Ё§ ~P |
ЕЮ АГРЧ КёБГШэМіР§РЬ АЁДЩЧЯИч РЬЕщРК И№ЕЮ ЧзЛѓ ИИСЗЕЧДТ ЕПФЁИэСІ (tautology) ЕщРг. |
|
~P, P |
NIL |
И№Мј (contradiction) РЛ ГЊХИГП |
|
~P Ё§ Q (Ся P ЂЁ Q), ~Q Ё§ R (Ся Q ЂЁ R) |
~P Ё§ R (Ся P ЂЁ R) |
ПЌАсМК (chaining) |
КЏМіИІ СіДб Р§ПЁ ДыЧб КёБГШэМіЙцЙ§РК СІ 2 РхРЧ ДмРЯШ АњСЄПЁМ О№БоЧб ФЁШЏ ЙцЙ§РЛ ЕЮ АГРЧ КЮИ№Р§ПЁ РћПыЧЯПЉ РЬЕщРЬ КИМіЙЎРк (complementary) ЕщРЛ МЗЮ АЁСіЕЕЗЯ ЧдРИЗЮНс РЬЗчОюСјДй. АјНФШЕШ ЧЅЧіРЛ РЇЧиМ ИеРњ КЮИ№Р§РЛ ЙЎРкЕщРЧ С§ЧеРИЗЮ ЧЅЧіЧбДйИщ, ЕЮ АГРЧ КЮИ№Р§РК АЂБт {Li}, {Mi} ПЭ ААРЬ ГЊХИГЛСіАэ КЏМіЕщРК ЕћЗЮ ЧЅСиШЕЧОю РжДйАэ АЁСЄЧв Мі РжДй (С§ЧеРЧ ЙЎРкЕщРЛ МЗЮ ГэИЎЧеРЛ РЬЗчАэ РжРН). ДѕПьБт {li} ПЭ {mi} ДТ АЂАЂ {Li}, {Mi} РЧ КЮКаС§ЧеРИЗЮ {li} ПЭ {~mi} РЧ ЧеПЁ ДыЧб АЁРх РЯЙнРћ ДмРЯШ (РЬИІ s Жѓ ЧЯАкРН) АЁ СИРчЧбДйАэ ЧЯРк. БзЗЏИщ РЬСІ ЕЮ АГРЧ Р§ {Li} ПЭ {Mi} ДТ КёБГШэМіЕЧОю ДйРНАњ ААРК КёБГШэМіР§РЬ РЏЕЕЕЧОюСјДй.
{{Li} - {li} s Ёњ {{Mi} - {mi}}s
ПЙЗЮНс ДйРНРЧ ЕЮ Р§ПЁ ДыЧб Ию АГРЧ КёБГШэМіР§РЛ БИЧи КИРк.
P[x, f(A)] Ё§ P[x, f(y)] Ё§ Q(y)
~P[z, f(A)] Ё§ ~Q(z)
ПЉБтМ
{li} = {P[x, f(A)], P[x, f(y)]}, {mi} = {~P[z, f(A)]} Жѓ ЧЯИщ РЬРЧ КёБГ ШэМіР§РК
Q(A) Ё§ ~Q(z)
РЬ ЕШДй.
ЕЮ АГРЧ КЮИ№Р§ЗЮКЮХЭ РЏЕЕЕЧОюСј КёБГШэМіР§РК ЖЧЧб РЬ КЮИ№Р§ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃАэ РжРНРЛ НБАд КИРЯ Мі РжДй. РЬИІ БтЙнРИЗЮ wff ЕщРЧ С§Че S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃАэ РжДТ wff ЕщРК РЬ wff С§Че S ПЁ КёБГШэМі КЮСЄЙцЙ§РЛ РћПыЧиМ РЏЕЕЕЧОюСјДй. БзЗЏЙЧЗЮ СЄИЎ СѕИэ НУНКХлРЧ Чб СОЗљРЮ ПЯРќМКРЛ СіДб КёБГШэМіЙцЙ§РЛ ЛчПыЧЯДТ КёБГШэМі КЮСЄ НУНКХлРЧ РЬЧиДТ РЬКИДй Дѕ ШПРВРћРЮ ПЉЗЏ СЄИЎ СѕИэ НУНКХлРЛ РЬЧиЧЯДТЕЅ БйКЛРћРЮ БтУЪИІ СІАјЧЯАд ЕШДй.
wff РЧ С§Че S ПЁ ОюЖВ wff X АЁ ГэИЎРћРИЗЮ ЕкЕћИЅДйДТ АЭРЛ СѕИэЧЯБт РЇЧи КёБГШэМіИІ РЬПыЧЯДТ КёБГШэМі КЮСЄЙцЙ§РК ИеРњ С§Че S ПЁ X РЧ КЮСЄРЮ ~X ИІ УЗАЁЧЯПЉ С§Че P = S Ёњ {~X} РЛ ЧќМКЧбДй. РЬСІ РЬ ЛѕЗЮПю С§Че P ЗЮКЮХЭ КёБГШэМіАњСЄРЛ ХыЧи РЏЕЕЕЧДТ ЛѕЗЮПю КёБГШэМіР§ Ri РЛ РЏЕЕЧЯАэ, С§Че P ПЁ Ri ИІ УпАЁЧЯПЉ ГЊПРДТ ЛѕЗЮПю С§ЧеПЁ ДыЧи ДйНУ КёБГШэМіИІ ЧрЧЯДТ АњСЄРЛ ЙнКЙЧбДй. РЬ ЖЇ АњСЄРЬ СОАсЕЧДТ НУБтДТ ЛѕЗЮРЬ РЏЕЕЕЧДТ КёБГШэМіР§РЬ И№Мј (NIL ЗЮ ЧЅБтЧд) РЛ ГЊХИГЛДТ АцПьРЬИч, РЬЗЮКЮХЭ wff X ДТ С§Че S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЅДйАэ ЧбДй. РЬПЭ ААРК КёБГШэМі КЮСЄЙцЙ§ПЁ РЧЧи СЄИЎ СѕИэРЬ СЄДчШЕЧДТ РЬРЏДТ ДйРНАњ ААРК ГэИЎЗЮ МГИэЕШДй.
wff ЕщЗЮ БИМКЕШ С§Че S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃДТ wff X АЁ РжДйАэ АЁСЄЧЯРк. БзЗЏИщ, АЁСЄПЁ РЧЧи S РЛ ИИСЗЧЯДТ И№Еч ЧиМЎ (interpretation) РК ЖЧЧб X РЛ ИИСЗЧбДй. РЬАЭРК S РЛ ИИСЗЧЯДТ ОюЖАЧб ЧиМЎЕЕ ~X РЛ ИИСЗЧЯСі ИјЧбДйДТ ЛчНЧАњ ААДй. БзЗЏЙЧЗЮ РЇРЧ О№БоЧб И№Еч ЧиМЎЕщРК S ПЭ {~X} ИІ ЕПНУПЁ ИИСЗНУХАСі ИјЧбДй (ПЉБтМ ОюЖВ ЧиМЎПЁ РЧЧиМЕЕ ИИСЗЕЧСі ОЪДТ wff РЧ С§ЧеРЛ КвИИСЗ (unsatisfiable) ЧЯДйАэ ЧбДй.).
НЧСІРћРИЗЮ X АЁ S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЅ wff ЖѓИщ S Ёњ {~X} ДТ КвИИСЗЧЯДй. ИИРЯ КёБГШэМіАњСЄРЬ КвИИСЗЧб С§ЧеПЁ ЙнКЙРћРИЗЮ РћПыРЬ ЕЧИщ АсБЙПЁДТ И№Мј (NIL) РЬ РЏЕЕЕЧДТ АЭРЛ КИРЯ Мі РжДй. БзЗЏЙЧЗЮ ИИРЯ X АЁ S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃИщ КёБГШэМіАњСЄПЁ РЧЧб S Ёњ {~X} РЧ С§ЧеРИЗЮКЮХЭ NIL Р§РЛ АсБЙПЁДТ РЏЕЕЧЯАд ЕЩ АЭРЬДй. ПЊРИЗЮ, ИИРЯ NIL РЬ С§Че S Ёњ {~X} ЗЮКЮХЭ РЏЕЕЕШДйИщ X ДТ S ЗЮКЮХЭ ГэИЎРћРИЗЮ ЕкЕћИЅДйДТ АЭРЛ КИРЯ Мі РжДй.
КёБГШэМі КЮСЄЙцЙ§РЛ ЧЯГЊРЧ ПЙИІ ХыЧи ЛьЦьКИРк. ИеРњ wff РЧ С§Че S АЁ ДйРНАњ ААДйАэ Чв ЖЇ, I(z) Ёќ ~R(z) РЬ S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃДТСіИІ СѕИэЧЯАэРк ЧбДй.
1) ~R(x) Ё§ L(x)
2) ~D(y) Ё§ ~L(y)
3a) D(A)
3b) I(A)
ИеРњ ИёЧЅ wff РЮ I(z) Ёќ ~R(z) РЛ КЮСЄЧЯПЉ ОЦЗЁРЧ ЧќХТПЭ ААРК Р§РЛ БИЧбДй.
4) ~I(z) Ёќ R(z)
1) ~ 4) ЗЮ РЬЗчОюСј С§ЧеРИЗЮКЮХЭ NIL РЧ РЏЕЕПЁ РЬИЃДТ ЕПОШРЧ КёБГШэМіАњСЄРЛ ГЊХИГЛИщ БзИВ 1 Ањ ААРК ЦЎИЎ ЧќХТАЁ ЕШДй.
БзИВ 1 КёБГШэМі КЮСЄ ЦЎИЎ
Ое Р§РЧ ПЙПЁМ КИЕэРЬ И№МјР§РЮ NIL РЛ РЏЕЕЧЯБт РЇЧи ОюЖАЧб ЕЮ АГРЧ КЮИ№Р§РЛ МБХУЧиМ ДмАшРћРИЗЮ КёБГШэМіАњСЄРЛ МіЧрЧЯАд ЕШДй. РЬПЭ ААРЬ КёБГШэМіЕЧДТ ЕЮ АГРЧ Р§РЛ МБХУЧЯДТ ЙцЙ§ПЁДТ ПЉЗЏ АЁСіАЁ РжРЛ Мі РжДй. Бз СпПЁМ ОюЖВ СІОюЙцНФРК И№МјРЬ СИРчЧв АцПьПЁДТ О№СІГЊ РЬЗЏЧб СИРчИІ СѕИэЧЯАд ЧбДй. РЬЗЏЧб СІОюЙцЙ§РЛ ПЯРќ (complete) ЧЯДйАэ ЧбДй (ОеПЁМ ГэЧб УпЗаБдФЂРЧ ГэИЎРћ ПЯРќМКАњДТ КААГРЧ АГГфРг). БзЗЏГЊ РЮАјСіДЩ РРПыКаОпПЁМДТ, И№МјРЛ КИДй ШПРВРћРИЗЮ БИЧЯДТ АЭРЬ ПЯРќМККИДй Дѕ СпПфЧЯАд ЙоОЦЕщПЉСіАэ РжДй. РЬСІ ОеР§РЧ ПЙИІ РЬПыЧЯПЉ КёБГШэМіАњСЄ СІОюЙцНФЕщРЛ ЛьЦьКИРк.
1) ГЊКё-ПьМБ (breadth-first) ЙцНФ
РЬ ЙцНФРК ИеРњ УЙ ДмАшПЁМ БтУЪС§Че S ЗЮКЮХЭ И№Еч АЁДЩЧб КёБГШэМіР§РЛ РЏЕЕЧЯАэ, ЕЮЙјТА ДмАшПЁМДТ, РЬ РЏЕЕЕШ Р§ЕщАњ УЙ ДмАшРЧ С§Че S ИІ ЧеФЃ ЛѕЗЮПю С§ЧеРИЗЮКЮХЭ ДйНУ И№Еч АЁДЩЧб КёБГШэМіР§РЛ РЏЕЕЧЯИч, Бз ДйРНПЁ ММЙјТА ДмАш ЕюРИЗЮ ЙнКЙ МіЧрЧЯАд ЕШДй (Ся, i-ЙјТА ДмАшРЧ КёБГШэМіР§РЛ РЏЕЕЧЯДТ ЕЮ АГРЧ КЮИ№Р§ СпРЧ ЧЯГЊДТ (i - 1)-ЙјТА ДмАшПЁМ РЏЕЕЕШ КёБГШэМіР§РЬДй).

БзИВ 2 ГЊКё-ПьМБЙцНФРЧ ПЙ
2) ММЦЎ-ПРКъ-МЦїЦЎ (set of support) ЙцНФ
КёБГШэМіАЁ АЁДЩЧб ЕЮ АГРЧ КЮИ№Р§ СпРЧ ЧЯГЊДТ СѕИэЧЯЗСДТ ИёРћ wff РЧ КЮСЄЕШ ЧќХТЗЮКЮХЭ Л§МКЕЧДТ Р§РЬАХГЊ ЖЧДТ, БзЗЏЧб Р§РЛ ЦїЧдЧб КёБГШэМіАњСЄПЁМ ОђОюСіДТ Р§РЬПЉОпИИ ЧбДй. РЏЕЕЧЯЗСДТ И№МјРЬ КёБГШэМіЧЯДТ АњСЄРЧ ИХ ДмАшИЖДй ЦїЧдЕЧБт ЖЇЙЎПЁ РЬ СІОюЙцНФРК ПЯРќЧЯАд ЕШДй. БзИВ 3 РК РЬ СІОюЙцНФПЁ РЧЧб КёБГШэМі КЮСЄ БзЗЁЧСИІ КИПЉСиДй. РЬ ЙцНФРК ГЊКё-ПьМБЙцНФКИДй РћРК МіРЧ Р§РЛ Л§МКЧЯСіИИ NIL АЁСі РЬИЃБт РЇЧб ЦЎИЎ ЛѓРЧ БэРЬДТ СѕАЁЧЯАд ЕЧДТ АцПьЕЕ РжДй.

БзИВ 3 ММЦЎ-ПРКъ-МЦїЦЎ ЙцНФРЧ ПЙ
3) ДмРЇ-ПьМБ (unit preference) ЙцНФ
РЬ ЙцНФРК КёБГШэМіАЁ АЁДЩЧб ПЉЗЏ КЮИ№Р§Ещ СпПЁМ ЧЯГЊРЧ ЙЎРкИИРИЗЮ РЬЗчОюСј Р§РЛ ЦїЧдЧЯДТ КЮИ№Р§РЛ ПьМБРћРИЗЮ МБХУЧбДй. РЬЗЏЧб КёБГШэМіАњСЄПЁ РЧЧи ЕЮ КЮИ№Р§ Сп Дѕ Бф КЮИ№Р§РЛ БИМКЧЯАэ РжДТ ЙЎРкРЧ МіКИДй РћРК МіРЧ ЙЎРкЗЮ БИМКЕШ ЛѕЗЮПю Р§РЛ ОђРЛ Мі РжРИЙЧЗЮ АсБЙПЁДТ Кѓ Р§РЮ NIL РЛ ЛЁИЎ РЏЕЕЧЯАд ЕШДйДТ ПјИЎПЁМ ШПРВМКРЛ СѕАЁЧЯАд ЕШДй. БзИВ 1 РК ДмРЇ-ПьМБЙцНФРЛ РЬПыЧб ПЙЖѓАэ Чв Мі РжДй.
4) МБЧќ РдЗТЧќ (linear-input form) ЙцНФ
РћОюЕЕ ЧЯГЊРЧ КЮИ№Р§РК БтУЪС§ЧеПЁ ЦїЧдЕШ Р§РЬОюОп ЧбДй. БзИВ 4 ДТ РЬ ЙцНФРЛ КИПЉ СжДТЕЅ 1 ДмАшБюСіДТ БзИВ 2 ПЭ ААСіИИ 2 ДмАшКЮХЭДТ ДйИЃДй. ОЦЗЁРЧ ПЙПЁ КИЕэРЬ РЬ ЙцНФРК ПЯРќ (complete) ЧЯСі ОЪДй. БтУЪС§ЧеРЬ ДйРНАњ ААРИИщ БзИВ 5 ПЁМ СѕИэЕЧЕэРЬ И№МјРЬ СИРчЧЯЙЧЗЮ КвИИСЗ (unsatisfiable) Чб С§ЧеРЬДй.
Q(u) Ё§ P(A),
~Q(w) Ё§ P(w),
~Q(x) Ё§ ~P(x),
Q(y) Ё§ ~P(y),
БзЗЏГЊ NIL РЛ РЏЕЕЧЯБт РЇЧиМДТ КёБГШэМіЕЧДТ ЕЮ Р§РЬ И№ЕЮ ЧЯГЊРЧ ЙЎРкЗЮ РЬЗчОюСј ДмРЇР§РЬАХГЊ, КёБГШэМіЕЧОю ПЯРќШї NIL РЬЖѓДТ Кѓ Р§РЬ Л§БтЕЕЗЯ ЧЯДТ Р§ЕщРЬ РжОюОп ЧЯДТЕЅ РЬЗЏЧб МКСњРЛ СіДб ЕЮ АГРЧ КЮИ№Р§РЛ РЬ СІОюЙцНФРИЗЮДТ БИЧв Мі ОјДй. РЬПЭ ААРЬ МБЧќ РдЗТЧќ СІОюЙцНФРК ПЯРќЧЯСіДТ ИјЧЯДй. БзЗЏГЊ СІОюРЧ ДмМјМКАњ ШПРВМКРИЗЮ РЮЧи РкСж РЬПыРЬ ЕШДй.

БзИВ 4 МБЧќ РдЗТЧќ ЙцНФРЧ ПЙ

БзИВ 5 КёБГШэМі КЮСЄ ЦЎИЎ
5) СЖЛѓР§-МБХУЧќ (ancestry-filtered form) ЙцНФ
РЬДТ МБЧќ-РдЗТЧќ ЙцНФРЧ КвПЯРќМКРЛ КИПЯЧЯБт РЇЧб ЙцНФРИЗЮ АЂ КёБГШэМіР§РЧ ЕЮ КЮИ№Р§ СпПЁ РћОюЕЕ ЧЯГЊДТ БтУЪС§ЧеПЁ ЦїЧдЕШ Р§РЬАХГЊ, ЧбТЪРЧ КЮИ№Р§РЬ ДйИЅ ТЪ КЮИ№Р§РЧ СЖЛѓР§РЬЖѓДТ АќАшПЁ РжРИИщ ЕШДй. БзИВ 5 ДТ СЖЛѓР§ МБХУЧќ СІОюЙцНФРЛ РЬПыЧб КёБГШэМі КЮСЄ ЦЎИЎЖѓ Чв Мі РжДй. КёБГШэМіР§ NIL РЧ Чб КЮИ№Р§РЮ * ЗЮ ЧЅБтЕШ ~P(x) ДТ ДйИЅ Чб КЮИ№Р§РЮ P(A) РЧ СЖЛѓРЬДй.
ДѕПьБт КёБГШэМіПЁ РЬПыЕЧДТ СЖЛѓР§ЕщРЬ ЧеКД (merge) ЕщРЬИщ РЬ СІОюЙцНФРК ПЯРќМКРЛ АЁСјДй ((1) Р§ПЁМ О№БоЧб ЧеКДРЬЖѕ ЧЯГЊРЧ ЙЎРкЗЮЕШ КёБГШэМіР§ЗЮ РЬАЭРК ЕЮ АГРЧ КЮИ№Р§ПЁ ЕПНУПЁ МгЧи РжДТ ЙЎРкРЬДй. БзИВ 5 РЧ ~P(x) ДТ ЧеКДРЬДй).
ЖЇЖЇЗЮ Р§ЕщЗЮ РЬЗчОюСј ОюЖВ С§ЧеПЁМ Ию АГРЧ Р§РЬ СІАХЕЧАХГЊ ЖЧДТ Р§РЛ РЬЗчДТ ОюЖВ ЙЎРкЕщРЬ СІАХЕЩ Мі РжДй. РЬЗЏЧб ДмМјШДТ ПјЗЁРЧ С§ЧеРЬ КвИИСЗЧб С§ЧеРЬИщ ДмМјШАЁ ЕШ ШФРЧ ЛѕЗЮПю С§ЧеЕЕ КвИИСЗЧдРЛ РЏСіЧЯДТ ЙцЧтРИЗЮ СјЧрЕЩ Мі РжДй. БзЗЏЙЧЗЮ РЬЗЏЧб ДмМјШ ЙцЙ§РЧ РћПыРК КёБГШэМі КЮСЄЙцЙ§РЧ МіЧрАњСЄПЁМ Л§АмГЊДТ КёБГШэМіР§РЧ МіИІ СйРЬДТЕЅ ЕЕПђРЛ СиДй.
1) ЕПФЁИэСІ (tautology) РЧ СІАХ
ЙЎРкПЭ РЬАЭРЧ КЮСЄЕШ ЙЎРкИІ ЧдВВ ЦїЧдЧЯДТ ОюЖАЧб Р§ЕЕ СІАХЕЩ Мі РжДй (РЬЗЏЧб Р§РЛ ЕПФЁИэСІЖѓ Чд). ПжГФЧЯИщ ЕПФЁИэСІИІ ЦїЧдЧб КвИИСЗЧб С§ЧеРК РЬАЭРЛ СІАХЧб С§ЧеЕЕ КвИИСЗЧб АЭРЬБт ЖЇЙЎРЬДй. ПЙЗЮМ, P(x) Ё§ B(y) Ё§ ~B(y), P(f(A)) Ё§ ~P(f(A)) ЕюРК СІАХЕЧОюЕЕ ЙЋЙцЧЯДй.
2) ЧСЗЮНУСъОюРЧ КЮТј (procedure attachment)
ЖЇЖЇЗЮ ЙЎРкГЊ РЬАЭРЧ КЮСЄРЛ БтУЪС§ЧеПЁ ЦїЧдНУХАДТ АЭКИДйДТ РЬ ЙЎРкРЧ СјИЎАЊРЛ АшЛъЧи ЙіИЎДТ АЭРЬ ЦэИЎЧЯДй. ШчШї РЬЗЏЧб АшЛъРК БтУЪПЙНУ (ground instance) ЕщПЁ ЧиДчЕШДй. ПЙИІ ЕщОю, ММњЧќ ИэСІ E(x, y) АЁ ЕЮ АГРЧ М§Рк x ПЭ y ЛчРЬРЧ ХЉБтАЁ ААРКСі ПЉКЮИІ ГЊХИГНДйАэ ЧЯИщ, РЬАЭРЧ БтУЪПЙНУАЁ (ПЙЗЮМ E(7, 3) Ањ ААРК) МіЧрАњСЄНУ Л§АмГЏ ЖЇИЖДй АшЛъЧЯПЉ ТќРЮСі АХСўРЮСі АсСЄЧи ЙіИЎАэ, E(x, y), ~E(x, y) РЧ ИЙРК ЧќХТРЧ БтУЪПЙНУЕщРЛ БтУЪС§ЧеПЁ ЦїЧдНУХАСі ОЪРНРИЗЮ ЧиМ ШПРВМКРЛ СѕАЁНУХВДй. ПЉБтПЁДТ E(7, 3) Ањ ААРК ЧЅЧіРЧ СјИЎАЊРЛ БИЧЯБт РЇЧб ЧСЗЮНУСъОюАЁ СжОюСЎОп ЧбДй. РЬПЭ ААРЬ ММњЧќ ИэСІПЭ РЬАЭРЧ НЧЧрРЛ ЧрЧЯДТ ФФЧЛХЭ ФкЕх ЛчРЬИІ ПЌАсЧи СжДТ ЧќХТАЁ МКИГЕЧДТЕЅ РЬАЭРЛ ЧСЗЮНУСъОюРЧ КЮТјРЬЖѓ ЧбДй.
3) ЦїЧд (subsume) ПЁ РЧЧб СІАХ
{Li}s АЁ {Mi} РЧ КЮКаС§ЧеРЬ ЕЧАдЧЯДТ ФЁШЏ s АЁ СИРчЧбДйИщ Р§ {Li} ДТ Р§ {Mi} РЛ ЦїЧдЧбДй ЖѓАэ СЄРЧЧбДй. ПЙИІ ЕщОю,
P(x) ДТ P(y) Ё§ Q(z) ИІ ЦїЧдЧЯИч,
P(x) ДТ P(A) ИІ ЦїЧдЧЯИч,
P(x) ДТ P(A) Ё§ Q(z) ИІ ЦїЧдЧЯИч,
P(x) Ё§ Q(A) ДТ P(f(A)) Ё§ Q(A) Ё§ R(y) ИІ ЦїЧдЧбДй.
КвИИСЗЧб С§ЧеПЁМРЧ Чб Р§РЬ ДйИЅ Р§ПЁ РЧЧи ЦїЧдРЬ ЕЧИщ РЬ ЦїЧдЕЧДТ Р§РЬ СІАХЕЧОюЕЕ КвИИСЗЧб С§ЧеРЬ РЏСіЕШДй. РЬПЭ ААРЬ ЦїЧдПЁ РЧЧб СІАХДТ КёБГШэМіРЧ МіИІ СйРЬДТЕЅ ЛѓДчЧб ШПАњИІ СиДй.
ИЙРК ММњ ГэИЎ СЄИЎ СѕИэ НУНКХлПЁДТ СИРчИІ ГЊХИГЛДТ КЏМіАЁ АсБЙ ЙЋОљРИЗЮ ПЙНУЕЧДТСі ОЫАэРк ЧЯДТ АцПьАЁ РжДй. ПЙЗЮМ БтУЪС§Че S ПЁ ГэИЎРћРИЗЮ ЕкЕћИЃДТ (ЂЄx)W(x) АЁ РжДйИщ x АЁ ЙЋОљРИЗЮ ПЙНУЕЧДТАЁ ЧЯДТ АЭРЬДй. РЬИІ ЧиАсЧЯБт РЇЧб АњСЄРЛ ПЙИІ ЕщОю ЛьЦьКИРк.
"JOHN РЬ АЁДТ РхМвИщ FIDO ЕЕ ЙнЕхНУ Бз РхМвПЁ АЃДй." ДТ ЛчНЧРЬ СжОюСГРЛ ЖЇ
"JOHN РЬ ЧаБГПЁ АЁИщ FIDO ДТ ОюЕ№ПЁ АЁДТАЁ?" ЖѓДТ СњЙЎРЬ РжДйАэ ЧЯРк.
РЬАЭРК ДйРНАњ ААРЬ ЧЅЧіЕШДй.
(ЂЃx)[AT(JOHN, x) ЂЁ AT(FIDO, x)], AT(JOHN, SCHOOL),
(ЂЄx)AT(FIDO, x)
ПЉБтМ СѕИэЧЯАэРк ЧЯДТ АЭРК ИёЧЅ wff (ЂЄx)AT(FIDO, x) ПЁМ x АЁ ЙЋОљРЮАЁ ЧЯДТ АЭРЬДй. РЬИІ БИЧЯБт РЇЧи (ЂЄx)AT(FIDO, x) РЧ КЮСЄРЮ (ЂЃx)~AT(FIDO, x) ИІ УЗАЁЧЯПЉ ДйРНАњ ААРК БтУЪС§ЧеРЬ ЧќМКЕШДй.
~AT(JOHN, x) Ё§ AT(FIDO, x), AT(JOHN, SCHOOL),
~AT(FIDO, x)
РЬ БтУЪС§ЧеРЛ РЬПыЧи NIL РЛ РЏЕЕЧЯДТ КёБГШэМі КЮСЄ ЦЎИЎДТ БзИВ 6 Ањ ААДй. БзЗЏГЊ (ЂЄx)AT(FIDO, x) ПЁМ x ИІ БИЧЯБт РЇЧиМДТ ~AT(FIDO, x) ИІ ДйНУ Чб Йј КЮСЄЧб AT(FIDO, x) ИІ УпАЁЧЯПЉ ГэИЎЧеРЛ НУХВДй. БзЗЏИщ ДйРНАњ ААРК БтУЪС§ЧеРЬЕЧИч РЬЗЮКЮХЭ РЇПЁМПЭ ААРК Р§ТїИІ АХУФ КёБГШэМіИІ ЧрЧЯИч, АсБЙПЁДТ NIL РЬ ОЦДб ДыДфРЛ СіДб ЙЎРхРЬ РЏЕЕЕШДй.
~AT(JOHN, x) Ё§ AT(FIDO, x), AT(JOHN, SCHOOL),
~AT(FIDO, x) Ё§ AT(FIDO, x).
РЇРЧ АњСЄРЛ АХФЃ ДыДф РЏЕЕИІ РЇЧб ЦЎИЎДТ БзИВ 7 Ањ ААРИИщ AT(FIDO, SCHOOL) РК ПјЧЯДТ ЧиДфРЬ ЕШДй.

БзИВ 6 КёБГШэМі КЮСЄ ЦЎИЎ

БзИВ 7 МіСЄЕШ СѕИэ ЦЎИЎ
ОеРЧ АцПьПЭДТ ДоИЎ РќУМ ЧбСЄПЁ РЧЧб КЏМіИІ СіДб ИёЧЅ wff АЁ РжДТ АцПьИІ ЛьЦьКИРк. ИёЧЅ wff РЧ КЮСЄРЬ РЬЗчОюСіДТ АњСЄПЁМ РЬ КЏМіДТ СИРчКЏМіАЁ ЕЧОю НКФнЗНЧдМі (skolem function) ЗЮ ДыФЁЕШДй.
РЬСІ ДыДфРЛ РЏЕЕЧб АсАњПЁМ РЬЗЏЧб НКФнЗН ЧдМіАЁ ОюЖЛАд ЧиМЎРЬ ЕЧДТСі ДйРНРЧ ПЙИІ ХыЧи ЛьЦь КИРк.
"И№Еч x ПЁ ДыЧи x ДТ p(x) РЧ РкНФРЬДй."
"И№Еч x ПЭ y ПЁ ДыЧи x АЁ y РЧ РкНФРЬИщ y ДТ x РЧ КЮИ№РЬДй."
"И№Еч x ПЁ ДыЧи x РЧ КЮИ№ДТ ДЉБИРЮАЁ?"
ПЉБтМ ИёЧЅ wff (ЂЃx)(ЂЄy)P(y, x) РЧ КЮСЄРК (ЂЄx)(ЂЃx)~P(y, x) РЬ ЕЧИч, x ДТ НКФнЗН ЧдМіЗЮ ДыФЁЕЧЙЧЗЮ ~P(y, A) ЗЮ ЕЧОю ДыДф РЏЕЕИІ РЇЧб БтУЪС§ЧеРК ОЦЗЁПЭ ААРЬ ГЊХИГДй.
C(x, p(x)), ~C(x, y) Ё§ P(y, x),
~P(y, A) Ё§ P(y, A)
РЬСІ ДыДф РЏЕЕИІ РЇЧб СѕИэ ЦЎИЎДТ БзИВ 8 УГЗГ ЕШДй. ПЉБтМРЧ ДыДфРК НКФнЗН ЧдМі A(ЛѓМі ЧќХТРг) РЛ СіДб P(p(A), A) АЁ ЕШДй. БзЗЏГЊ КЛЗЁРЧ СњЙЎРЬ "И№Еч x ПЁ ДыЧи x РЧ КЮИ№ДТ ДЉБИРЮАЁ? Ся x РЧ КЮИ№ДТ x ПЭ ОюЖЛАд ПЌАќЕЧДТ ЛчЖїРЮАЁ?" РЬЙЧЗЮ A РЧ ЧиМЎРЛ ЛѓМіАЁ ОЦДб И№Еч A ПЁ ДыЧи P(p(A), A) ЗЮ ЧиМЎЧдРЬ ХИДчЧЯДй.

БзИВ 8 ДыДф РЏЕЕИІ СіДб СѕИэ ЦЎИЎ
ЧЯГЊРЧ ПЙИІ Дѕ ЛьЦьКИРк. БтУЪС§Че S АЁ ЧЯГЊРЧ Р§ P(B, w, w) Ё§ P(A, u, u) ПЭ ИёЧЅ wff (ЂЄx)(ЂЃz)(ЂЄy)P(x, z, y) ИІ ЦїЧдЧбДй ЧЯРк.
РЬАЭРЧ КёБГШэМі КЮСЄ ЦЎИЎДТ БзИВ 9 ПЭ ААРЬ ЕЧИч ДыДф РЏЕЕИІ РЇЧб СѕИэ ЦЎИЎДТ БзИВ 10 Ањ ААРЬ ЕШДй. ПЉБтМ КИИщ НКФнЗН ЧдМі g(x) ДыНХПЁ КЏМі t АЁ ЛчПыЕЧОњРИИч АсАњРћРИЗЮ P(A, t, t) Ё§ P(B, z, z) РЛ РЏЕЕЧЯПДДй. БзЗЏГЊ P(A, t, t) ПЭ P(B, z, z) РК ААРК РЧЙЬИІ АЁСјДй.

БзИВ 9 КёБГШэМі КЮСЄ ЦЎИЎ

БзИВ 10 МіСЄЕШ СѕИэ ЦЎИЎ
АсЗаРћРИЗЮ, КёБГШэМіЙцЙ§РЛ РЬПыЧб ДыДф РЏЕЕАњСЄРЧ Р§ТїДТ ДйРНАњ ААДй.
1) ИеРњ КёБГШэМі КЮСЄ ЦЎИЎИІ БИЧбДй (ПЉБтМ ДмРЯШЕЧДТ КЮКаПЁДТ ЙиСйРЛ БзОю ЧЅНУЧбДй.).
2) ИёЧЅ wff РЧ КЮСЄЧќХТПЁМ Л§БтДТ И№Еч НКФнЗН ЧдМіЕщРЛ ЛѕЗЮПю КЏМіЕщЗЮ ДыФЁ НУХВДй.
3) (2) ПЁ Л§Бф Р§Ањ РЬАЭРЧ КЮСЄЕШ Р§РЛ ГэИЎЧеНУФб ЕПФЁИэСІ ЧќХТИІ УыЧбДй.
4) (1) ПЁМ БИЧб ЦЎИЎ БИСЖИІ РЬПыЧиМ (ААРК ДмРЯШ АњСЄ) МіСЄЕШ СѕИэ ЦЎИЎИІ ОђДТДй.
5) СѕИэ ЦЎИЎРЧ ЗчЦЎ ГыЕхПЁ РжДТ Р§РЬ БИЧЯАэРк ЧЯДТ ДыДф ЙЎРхРЬ ЕШДй.
1) AND/OR ЧќХТРЧ ЛчНЧ (fact) ЧЅЧі
РќЧт НУНКХлРК ЛчНЧРЧ С§ЧеРИЗЮ РЬЗчОюСј УЪБтРЧ РќУМ ЕЅРЬХЭКЃРЬНКИІ АЁСјДй. РЬ ЛчНЧЕщРК AND/OR ЧќХТЖѓ КвИЎОюСіДТ ОЯНУРћ ЧЅЧі (ЂЁ) РЬ ОјДТ ММњГэИЎЙЎ (predicate calculus) РИЗЮ ГЊХИГЛОюСјДй. ПЙЗЮМ ОюЖВ wff ИІ AND/OR ЧќХТЗЮ РќШЏЧЯДТ ЙцЙ§РК ДйРНАњ ААДй :
(ЂЄu)(ЂЃv){Q(v, u) Ёќ ~[[R(v) Ё§ P(v)] Ёќ S(u, v)]}
РЇПЭ ААРК wff ПЁМ СИРчИІ ГЊХИГЛДТ СИРчЧбСЄБтШЃ (ЂЄ) ДТ НКФнЗН ЧдМіПЁ РЧЧи СІАХЧЯАэ РќУМЧбСЄБтШЃ (ЂЃ) ДТ Л§ЗЋЧЯАэ КЮСЄ НЩКМ (~) РК РЬАЭРЧ ПЕПЊРЬ Чб АГРЧ ЙЎРкПЁ РЬИІ ЖЇБюСі ЕхИ№ИЃА Й§ФЂРЛ РЬПыЧЯПЉ ЙйВйИщ, ДйРНАњ ААРК ЧЅЧіРИЗЮ КЏЧбДй.
Q(v, A) Ёќ {[~R(v) Ёќ ~P(v)] Ё§ ~S(A, v)]}
ПЉБтМ ЛчНЧ ЧЅЧіРЬ ДйИЅ AND АсЧеПЁ ААРК КЏМіАЁ РжСі ОЪБт РЇЧиМ КЏМіЕщРЛ ЧЅСиШЕЧИщ ДйРНАњ ААРК ЧЅЧіРЬ ЕШДй.
Q(w, A) Ёќ {[~R(v) Ёќ ~P(v)] Ё§ ~S(A, v)}.
AND/OR ЧќХТРЧ ЧЅЧіРК Ёќ ПЭ Ё§ НЩКМПЁ РЧЧи ПЌАсЕШ ЙЎРкЕщРЧ КЮЧЅЧі (subexpression) ЕщЗЮ БИМКЕЧОюСјДй.
2) ЛчНЧ ЧЅЧіРЛ ГЊХИГЛБт РЇЧб AND/OR БзЗЁЧСРЧ РЬПы
AND/OR БзЗЁЧСДТ AND/OR ЧќХТЗЮ ЕШ ЛчНЧ ЧЅЧіРЛ ГЊХИГЛБт РЇЧи РЬПыРЬ ЕЩ Мі РжДй. ПЙИІ ЕщИщ, БзИВ 11 РК ОеПЁМ ИИЕч AND/OR ЧќХТРЧ ЛчНЧ ЧЅЧіРЛ ГЊХИГЛАэ РжДй. OR АсЧеПЁ АќАшЕШ КЮЧЅЧі (E1 Ё§ ЁІ Ё§ Ek) РК АЂ РкНФ ГыЕхЕщРЬ БзЕщРЧ КЮИ№ ГыЕхПЁ k-ПЌАсРкЗЮ ПЌАсРЬ ЕЧОюСЎ ЧЅЧіРЬ ЕЧАэ AND АсЧеПЁ АќЗУЕШ КЮЧЅЧі (E1 Ёќ ЁІ Ёќ En) РК АЂ СіНФ ГыЕхАЁ БзРЧ КЮИ№ ГыЕхПЁ 1-ПЌАсРкПЁ ПЌАсРЬ ЕЧОюМ ЧЅЧіЕЧОюСјДй. РЬИЎЧЯИщ AND/OR БзЗЁЧСРЧ Рй (leaf) ГыЕхДТ ЛчНЧЧЅЧі ГЛПЁ СИРчЧЯДТ ЧиДч ЙЎРк (literal) ЗЮ СжОюСјДй.

БзИВ 11 ЛчНЧ ЧЅЧіРЧ AND/OR ЦЎИЎ ЧЅЧі
3) БдФЂ РћПыПЁ РЧЧб AND/OR БзЗЁЧСРЧ КЏШЏ
РќЙцЧт Л§МК НУНКХлПЁ ЛчПыЕЧДТ БдФЂРК ЙЎСІПЕПЊПЁ ДыЧб РЯЙнРћРЮ СіНФРЛ ОЯНУРћРЮ wff ЗЮ ЧЅЧіЧб АЭРЬДй. РЬЗЏЧб wff ИІ ДйРНАњ ААРЬ СІЧбЕШ ЧќХТЗЮ БИМКЧЯПДДй ЧЯРк. Ся,
L ЂЁ W,
ПЉБтМ L РК Чб АГРЧ ЙЎРкРЬАэ, W ДТ ОюЖВ РгРЧРЧ wff РЬДй. РЬЗЏЧб ЧќХТРЧ wff ДТ ЧбСЄКЏМіРЧ СОЗљПЁ АќАшОјРЬ ОЯНУРћ НЩКМРЧ ПоТЪПЁ БЙЧбЕШ ЧбСЄКЏМіИІ ИеРњ "ПЊ" РИЗЮ ЧЯАэ, Бз ДйРНПЁ И№Еч СИРчЧбСЄКЏМіЕщРК НКФнЗНЧЯПЉ ЧбСЄКЏМіРЧ ПЕПЊРЬ Рќ ЙќРЇПЁ АЩФЁЕЕЗЯ ЧЯДТ ЧќХТЗЮ ЙйВм Мі РжДй. ПЙИІ ЕщИщ, ДйРНАњ ААРК wff ДТ РЬЗЏЧб ДмАшИІ АХУФ КЏШЏРЬ ЕШДй.
(ЂЃx){[(ЂЄy)(ЂЃz)P(x, y, z)] ЂЁ (ЂЃu)Q(x, u)}
(1) (РЯНУРћРИЗЮ) ОЯНУРћ НЩКМ "ЂЁ" РЛ ОјОиДй.
(ЂЃx){~[(ЂЄy)(ЂЃz)P(x, y, z)] Ё§ (ЂЃu)Q(x, u)}
(2) КЮСЄ НЩКМ "~" РЛ СјЧрНУФб УЙЙјТА OR АсЧеПЁ РжДТ УЙЙјТА ЙЎРкПЁ АќЗУЕШ ЧбСЄ КЏМіЕщРЛ "ПЊ" РИЗЮ КЏШЏНУХВДй.
(ЂЃx){(ЂЃy)(ЂЄz)[~P(x, y, z)] Ё§ (ЂЃu)Q(x, u)}
(3) СИРчЧбСЄКЏМіИІ НКФнЗННУХВДй.
(ЂЃx){(ЂЃy)[~P(x, y, f(x, y))] Ё§ (ЂЃu)Q(x, u)}
(4) И№Еч РќУМЧбСЄКЏМіИІ ОјОиДй.
~P(x, y, f(x, y)) Ё§ Q(x, u)
(5) ОЯНУРћ НЩКМРЛ ДйНУ ГЊХИГНДй.
P(x, y, f(x, y)) ЂЁ Q(x, u)
РЬЗЏЧб ОЯНУРћ НЩКМРЛ АЁСј БдФЂРЬ ПЉБтМ ОюЖЛАд AND/OR БзЗЁЧСПЁ РћПыРЬ ЕЧДТСі ЛьЦьКИРк. ИеРњ КЏМіИІ АЁСіСі ОЪДТ ММњНФРЧ АцПьИІ Л§АЂЧЯИщ, L ЂЁ W РЧ БдФЂРЬ РжДйАэ Чв ЖЇ ЛчНЧ ЧЅЧі F(L) РЛ ГЊХИГЛДТ AND/OR БзЗЁЧСПЁ L ЂЁ W ИІ РћПыЧЯПЉ ЛѕЗЮПю ЛчНЧ ЧЅЧі F(W) ИІ ГЊХИГЛДТ AND/OR БзЗЁЧСИІ ОђРЛ Мі РжДй. РЬ F(W) ИІ ЧЅЧіЧЯДТ ЛѕЗЮПю AND/OR БзЗЁЧСЛѓПЁМ Рй ГыЕхЕщЗЮ ГЁГЊДТ ЧиАс БзЗЁЧС (solution graphs) ЕщРК F(W) ЗЮКЮХЭ Л§МКЕЧДТ Р§ (clauses) ЕщРЛ ГЊХИГЛАд ЕШДй. ПЙИІ ЕщОю ОЦЗЁПЭ ААРК БдФЂАњ БзИВ 12 ПЁ СжОюСј КЏМіАЁ ОјДТ AND/OR БзЗЁЧСИІ Л§АЂЧи КИРк.

БзИВ 12 КЏМіИІ АЁСіСі ОЪДТ AND/OR БзЗЁЧС

БзИВ 13 БдФЂ РћПы ШФРЧ AND/OR БзЗЁЧС
S ЂЁ (x Ёќ y) Ё§ z
БзИВ 12 ПЁ S ЗЮ ИэФЊРЬ КйПЉСј ГыЕхДТ S ЂЁ (X Ёќ Y) Ё§ z ПЁ РЧЧи ЛѕЗЮПю ЧќХТРЧ AND/OR БзЗЁЧСАЁ БзИВ 13 УГЗГ ГЊХИГЊАд ЕШДй. РЬ ЖЇ S ПЁ ПЌАсЕШ МБРЛ КёБГМБХУ ОЦХЉ (match arc) Жѓ ЧбДй.
БдФЂ S ЂЁ [(X Ёќ Y) Ё§ Z] РК ДйРНАњ ААРК 2 АГРЧ Р§ (clause) ЗЮ Л§АЂЕЩ Мі РжДй.
~S Ё§ X Ё§ Z, ~S Ё§ Y Ё§ Z
СжОюСј ЛчНЧ ЧЅЧі [(P Ё§ Q) Ё§ R] Ё§ [S Ёќ (T Ё§ U)] ЗЮКЮХЭ Л§МКЕЧДТ Р§ (clause) Ещ СпПЁ S ИІ ЦїЧдЧЯДТ Р§ЕщРК ДйРНАњ ААДй.
P Ё§ Q Ё§ S, R Ё§ S
РЬЕщАњ РЇРЧ БдФЂПЁМ Л§МКЕЧДТ Р§ЕщРЛ КёБГШэМі (resolution) ЧЯИщ ДйРНАњ ААРК Гз АЁСі Р§ЕщРЬ РЏЕЕЕШДй.
X Ё§ Z Ё§ P Ё§ Q, Y Ё§ Z Ё§ P Ё§ Q, R Ё§ Y Ё§ Z, R Ё§ X Ё§ Z
РЇРЧ И№Еч Р§ЕщРК БзИВ 13 РЧ БзЗЁЧСРЧ Рй ГыЕхЕщЗЮ БИМКЕЧДТ ЧиАс БзЗЁЧСЕщЗЮ ГЊХИГЛОю СјДй.
РЬПЭ ААРЬ AND/OR БзЗЁЧСДТ ЛчНЧАњ БдФЂРЬ РћПыЕШ ШФРЧ РЏЕЕЕЧДТ ЛчНЧЕщРК ОЫОЦГЛДТЕЅ ИХПь РЏПыЧб ЕЕБИЗЮНс ЛчПыЕЩ Мі РжДй.
ОеПЁМ ИЛЧб МГИэРК ЛчНЧ ЧЅЧіПЁ КЏМіАЁ ГЊХИГЊСі ОЪДТ АцПьИІ АќЧб АЭРЬИч, КЏМіАЁ ГЊХИГЊДТ ЧЅЧіПЁ АќЧиМДТ КЏМіАЁ ОјДТ СОАсСЖАЧРЛ ЛьЦь КЛ РЬШФПЁ АХЗаЧЯБтЗЮ ЧбДй.
4) СОАсРЛ РЇЧб ИёЧЅ wff РЧ ЛчПы
РќЙцЧт НУНКХлРЧ ИёРћРК СжОюСј ЛчНЧАњ БдФЂЕщЗЮКЮХЭ ОюЖВ ИёЧЅ wff ИІ СѕИэЧЯДТ АЭРЬДй. РЬ ЖЇРЧ ИёЧЅ wff ДТ ЙЎРкЕщРЧ OR АсЧе ЧќХТЗЮИИ СІЧбЕЧОю СјДй. РЬЗЏЧб СІЧбРК ГЊСпПЁ МГИэЕЧДТ ПЊЙцЧт НУНКХлАњ КЙЧеЕШ НУНКХлПЁМДТ СИРчЧЯСі ОЪДТДй. БдФЂ РћПыНУПЭ ИЖТљАЁСіЗЮ ИёЧЅ ЙЎРкДТ AND/OR БзЗЁЧСРЧ РкМе ГыЕхЗЮ УЗАЁЕЧОюСјДй. РќЙцЧт НУНКХлРК ИёЧЅ ГыЕхЕщЗЮ РЬЗчОюСіДТ ЧиАс БзЗЁЧСИІ ЦїЧдЧЯДТ AND/OR БзЗЁЧСАЁ Л§МКЕЩ Ды МКАјРћРИЗЮ ГЁГДй.
5) КЏМіИІ СіДЯДТ ЧЅЧі
РЬСІКЮХЭ КЏМіИІ СіДЯДТ ЧЅЧіРЛ ДйЗчДТ РќЧт УпЗа НУНКХлРЛ ЛьЦьКИРк. СИРчЧбСЄКЏМі ШЄРК РќУМЧбСЄКЏМіЕщРЛ СіДб ИёЧЅ wff ПЁ ДыЧиМДТ ЛчНЧРЬГЊ БдФЂПЁ ДыЧи ЛчПыЧб НКФнЗН АњСЄРЛ ЙнДыЗЮ МіЧрЧбДй. Ся, ИёЧЅПЁ РжДТ РќУМЧбСЄКЏМіЕщРК НКФнЗН ЧдМіЗЮ ГЊХИГЛОюСјДй. РЬДТ КёБГШэМі КЮСЄ НУНКХлПЁМ ИёЧЅ wff АЁ КЮСЄРЬ ЕЧОю УЗАЁЕЧОюСіДТ АЭРЛ Л§АЂЧЯИщ НБАд РЬЧиЕЩ Мі РжДй. Бз ДйРНПЁ ИёЧЅ wff РЧ СИРчЧбСЄКЏМіЕщРК ЛшСІЕШДй. ИёЧЅ wff ИІ НКФнЗНЧб ШФПЁДТ ЕЮ АГ РЬЛѓРЧ OR АсЧеПЁ ААРК КЏМіАЁ ГЊПРСі ОЪЕЕЗЯ ЙЎРкЕщРЛ ЧЅСиШНУХВДй. L ЂЁ W ЧќХТРЧ БдФЂРЬ AND/OR БзЗЁЧСПЁ РћПыЕЧДТ АњСЄРЛ ДйРНРЧ ПЙЗЮМ ЛьЦьКИРк.

БзИВ 14 КЏМіИІ ЦїЧдЧЯДТ ЛчНЧ ЧЅЧіРЧ AND/OR БзЗЁЧС
{P(x, y) Ё§ [Q(x, A) Ёќ R(B, y)]}
РЬ ЛчНЧРЧ AND/OR БзЗЁЧС ЧЅЧіРК ОеРЧ БзИВ 14 ПЭ ААДй.

БзИВ 15 КЏМіИІ СіДЯДТ БдФЂРЬ РћПыЕШ ШФРЧ AND/OR БзЗЁЧС
P(A, B) ЂЁ [S(A) Ё§ X(B)] ИІ AND/OR БзЗЁЧСПЁ РћПыЧЯИщ БзИВ 15 ПЭ ААРЬ ЕШДй.
РЬЗЮКЮХЭ Рй ГыЕхЕщЗЮ БИМКЕЧДТ ЧиАс БзЗЁЧСЕщРК ДйРНАњ ААРК ЕЮ АГРЧ Р§ЗЮНс ЧЅЧіЕЧОю СјДй.
S(A) Ё§ X(B) Ё§ Q(A, A), S(A) Ё§ X(B) Ё§ R(B, B)
РЬЗЏЧб Р§ЕщРЛ РЏЕЕЧЯДТЕЅДТ ЧиАс БзЗЁЧСРЧ Рй ГыЕхПЁ ЙЎРкЕщПЁ АЁРх РЯЙнРћ ДмРЯШ (mgu) РЮ u ИІ РћПыЧЯИщ ЕШДй. ОюЖВ AND/OR БзЗЁЧСПЁ ЧЯГЊ РЬЛѓРЧ БдФЂРЬ АЁЧиСј ШФПЁДТ ЧЯГЊ РЬЛѓРЧ КёБГМБХУ ОЦХЉАЁ Л§БфДй. ЦЏШї ЙЎРк ГыЕхЗЮ СОАсЕЧДТ AND/OR БзЗЁЧСРЧ ОюЖВ ЧиАс БзЗЁЧСДТ ПЉЗЏ АГРЧ КёБГМБХУ ОЦХЉИІ АЁСњ Мі РжДй. РЬ ПЉЗЏ АГРЧ КёБГМБХУ ОЦХЉИІ АЁСіДТ AND/OR БзЗЁЧСЗЮКЮХЭ РЏЕЕЕЧДТ Р§ЕщРЛ БИЧЯДТ АцПьПЁДТ РЯФЁЧЯДТ (consistent) КёБГМБХУ ОЦХЉРЧ ФЁШЏРИЗЮ ЙЎРк ГыЕхПЁМ СОАсЕЧДТ ЧиАс БзЗЁЧСИИ МБХУЧЯИщ ЕШДй. РЬПЭ ААРЬ РЯФЁЧЯДТ ЧиАс БзЗЁЧСПЁ РЧЧи РЏЕЕЕЧДТ Р§РК ДмРЯШ АсЧе (unifying composition) РЬЖѓ КвИЎДТ ЦЏКАЧб ФЁШЏРЛ СОЗс (ЙЎРк) ГыЕхЕщРЧ OR АсЧеПЁ РћПыЧдРИЗЮНс БИЧи СјДй.
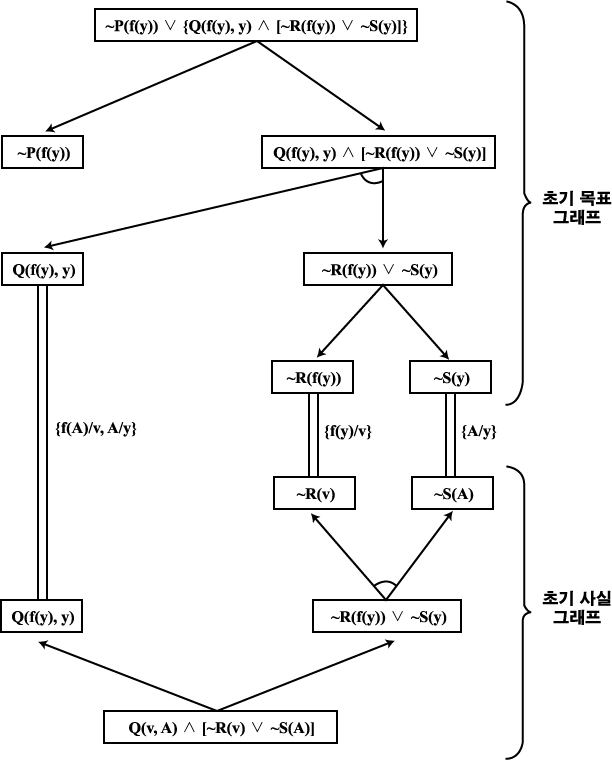
РЯФЁЧЯДТ ФЁШЏАњ ФЁШЏРЧ ДмРЯШ АсЧеРК ДйРНАњ ААРЬ СЄРЧЕШДй.
 РЛ ФЁШЏРЧ С§ЧеРЬЖѓ ЧЯИч АЂ
РЛ ФЁШЏРЧ С§ЧеРЬЖѓ ЧЯИч АЂ 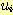 ДТ ДйРНАњ ААРК НжРЧ С§ЧеРЬДй.
ДТ ДйРНАњ ААРК НжРЧ С§ЧеРЬДй.

ПЉБтМ t ЕщРК ЙРН
(term) РЬАэ v ЕщРК КЏМіРЬДй.  РИЗЮКЮХЭ ЕЮ АГРЧ МіНФРЛ СЄРЧЧбДй.
РИЗЮКЮХЭ ЕЮ АГРЧ МіНФРЛ СЄРЧЧбДй.
 ,
,

ФЁШЏ  РЬ РЯФЁЧбДй (consistent) ДТ ИЛРК
РЬ РЯФЁЧбДй (consistent) ДТ ИЛРК 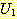 Ањ
Ањ 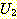 АЁ ДмРЯШ АЁДЩЧЯДйДТ ИЛАњ ААДй.
АЁ ДмРЯШ АЁДЩЧЯДйДТ ИЛАњ ААДй.  РЧ ДмРЯШ АсЧе u ДТ
РЧ ДмРЯШ АсЧе u ДТ 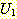 Ањ
Ањ 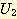 РЧ АЁРх РЯЙнРћ ДмРЯШИІ ИЛЧбДй.
РЧ АЁРх РЯЙнРћ ДмРЯШИІ ИЛЧбДй.
ДмРЯШ АсЧеРЧ ИюАЁСі ПЙАЁ ЧЅ 2 ПЁ СжОюСЎ РжДй.
ЧЅ 2 ДмРЯШ АсЧеПЁ РЧЧб ФЁШЏ
|
|
|
|
|
{A/x} {x/y} {f(z)/x} {x/y, x/z} {s} {g(y)/x} {f(g(x1))/x3, f(x2)/x4} |
{B/x} {y/z} {f(A)/x} {A/z} { } {f(x)/y} {x4/x3, g(x1)/x2}
|
КвРЯФЁ {x/y, x/z} {f(A)/x, A/z} {A/x, A/y, A/z} {s} КвРЯФЁ {f(g(x))/x3, f(g(x1))/x4, g(x1)/x2} |
ЧиАс БзЗЁЧСАЁ РЯФЁЕЧДТ КёБГМБХУ ОЦХЉРЧ ФЁШЏРЛ АЁСјДйДТ АЭРК ПјЗЁРЧ ЛчНЧПЁ БдФЂЕщРЛ РћПыЧпРЛНУ ЛѕЗЮПю Р§ЕщРЬ РЏЕЕЕШДйДТ АЭРЛ ИЛЧбДй. ЧЯГЊРЧ ПЙИІ ЛьЦьКИРк.
P(x) Ё§ Q(x) РЧ ЛчНЧАњ ЕЮ АГРЧ БдФЂ P(A) ЂЁ R(A), Q(B) ЂЁ R(B) РЧ AND/OR БзЗЁЧСДТ БзИВ 16 Ањ ААРЬ ЕШДй. КёЗЯ РЬ БзЗЁЧСАЁ R(A), R(B) ЗЮ РЬИЇРЬ КйПЉСј ЙЎРк ГыЕхИІ АЁСј ЧиАс БзЗЁЧСИІ ЦїЧдЧвСіЖѓЕЕ РЬ БзЗЁЧСДТ КвРЯФЁЕШ ФЁШЏРЛ ЦїЧдЧбДй. БзЗЏЙЧЗЮ [R(A) Ё§ R(B)] ДТ БзИВ 16 РЧ AND/OR БзЗЁЧСПЁ РЧЧи РЏЕЕЕЧДТ Р§РЬ ОЦДЯДй.
БзЗЏГЊ БзИВ 16 РК [R(A) Ё§ Q(A)] Р§РЧ ЧЅЧіРЛ ГЊХИГО Мі РжДй. R(A) ПЭ Q(x) РЬИЇРЬ КйПЉСј ЙЎРк ГыЕхЗЮ СОАсЕЧДТ ЧиАс БзЗЁЧСПЁ РЯФЁЕЧДТ R(A) Ё§ Q(x) ЧЅЧіПЁ ФЁШЏ {A/x} РЛ РћПыЧЯИщ [R(A) Ё§ Q(A)] РЧ Р§РЬ ОђОюСјДй.

БзИВ 16 КвРЯФЁРЧ ФЁШЏРЛ СіДб AND/OR БзЗЁЧС
БдФЂАњ ИёЧЅ ЙЎРкЕщПЁ РЧЧи ШЎРхЕЧДТ AND/OR БзЗЁЧСРЧ АњСЄРК РЯФЁЕЧДТ ЧиАс БзЗЁЧСАЁ И№Еч СОЗс ГыЕхПЁМ ИёЧЅ ГыЕхИІ АЁСіДТ МјАЃПЁ МКАјРћРИЗЮ СОАсРЬ ЕШДй. РЬЗЮКЮХЭ Л§МК НУНКХлРК ИёЧЅПЁ ДыЧб OR АсЧеРЬ ЧиАс БзЗЁЧСПЁ РжДТ ИёЧЅ ГыЕхЗЮ РЬИЇРЬ КйПЉСј ЙЎРкРЧ OR АсЧеПЁ ДмРЯШ АсЧеРЛ ЧиМ ОђОюСјДйДТ АЭРЛ ОЫ Мі РжДй. РЬСІ АЃДмЧб ПЙИІ ЕщОю РќЧт Л§МК НУНКХлРЧ РлЕПРЛ МГИэЧбДй. ДйРНАњ ААРК ЛчНЧАњ БдФЂЕщРЛ АЁСіАэ РжДйАэ ЧиКИРк.
~DOG(FIDO) Ё§ [BARKS(FIDO) Ёќ BITES(FIDO)]
R1 : ~DOG(x) ЂЁ ~TERRIER(x)
R2 : BARKS(y) ЂЁ NOISY(y)
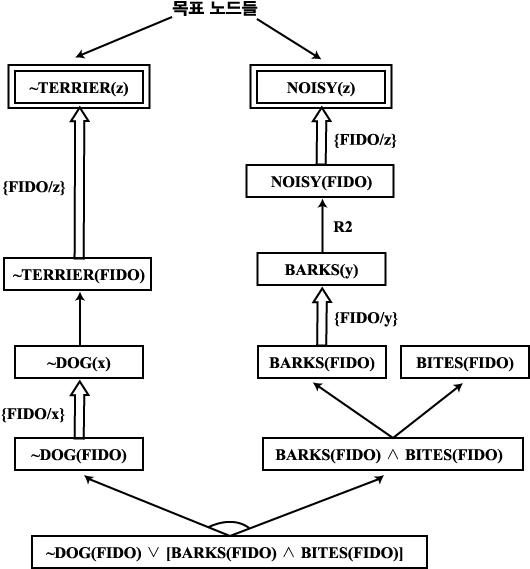
БзИВ 17 "Terrier" ЙЎСІРЧ AND/OR БзЗЁЧС
РЬЗЮКЮХЭ ~TERRIER(z) Ё§ NOISY(z) ЗЮ СжОюСіДТ ИёЧЅ wff ИІ СѕИэЧЯАэРк ЧбДй. ПЉБтМ z ДТ СИРчЧбСЄКЏМіРЬДй. РЬ ЙЎСІРЧ AND/OR БзЗЁЧСДТ ОеРЧ БзИВ 17 Ањ ААДй. РЬ AND/OR БзЗЁЧС ОШПЁМ РЯФЁЕЧДТ ЧиАс БзЗЁЧСДТ {FIDO/x}, {FIDO/y}, {FIDO/z} РЧ ФЁШЏРЛ АЁСјДй. РЬ ФЁШЏЕщРЧ ДмРЯШ АсЧеРК {FIDO/x, FIDO/y, FIDO/z} РЬ ЕЧИч, РЬАЭРЛ ИёЧЅ ЙЎРкЕщПЁ РћПыЧЯИщ ДйРНАњ ААРК АсАњИІ ОђДТДй.
~TERRIER(FIDO) Ё§ NOISY(FIDO)
РЬ ЧЅЧіРК ПьИЎАЁ СѕИэЧЯАэРк ЧЯДТ ИёЧЅ wff РЧ ДфРЬ ЕЧИч ПјЧЯДТ АсАњРЬДй.
1) AND/OR ЧќХТРЧ ИёЧЅ ЧЅЧі
ШФЧт НУНКХлРК ИёЧЅ ЧЅЧіРИЗЮ ОЦЙЋЗБ СІЧбЕЕ ЙоСі ОЪДТДй. РќЧт УпЗа НУНКХлПЁМРЧ ЛчНЧ ЧЅЧіРЧ РќШЏАњ РЏЛчЧЯАд ИёЧЅ ЧЅЧіРЧ wff ИІ AND/OR ЧќХТЗЮ ИеРњ РќШЏНУХВДй. Ся, ИеРњ ЂЁ НЩКМРЛ СІАХЧЯАэ КЮСЄ НЩКМРЛ ПђСїРЬИч, РќУМЧбСЄКЏМіИІ НКФнЗННУХААэ, СИРчЧбСЄКЏМіИІ ЛшСІЧбДй (ЧбСЄКЏМіРЧ КЏШЏРЬ РќЧт УпЗа НУНКХлРЧ ЛчНЧ ЧЅЧіРЧ АцПьПЭДТ ПЊРЬ ЕЕДТ АЭРЛ РЏРЧЧв АЭ).
ПЙИІ ЕщОю ДйРНАњ ААРК ИёЧЅ ЧЅЧі,
(ЂЄy)(ЂЃx) {P(x) ЂЁ [Q(x, y) Ёќ ~[R(x) Ёќ S(y)]]}
РК ОЦЗЁУГЗГ РќШЏРЬ ЕШДй.
~P(f(y)) Ё§ {Q(f(y), y) Ёќ [~R(f(y)) Ё§ ~S(y)]}.
КЏМіИІ ЧЅСиШНУХАИщ ДйРНАњ ААДй.
~P(f(y)) Ё§ {Q(f(y), y) Ёќ [~R(f(y)) Ё§ ~S(y)]}.
AND/OR ЧќХТРЧ ИёЧЅ wff ЕщРК AND/OR БзЗЁЧСЗЮМ ЧЅЧіРЬ ЕЧОюСјДй. БзЗЏГЊ ИёЧЅ ЧЅЧіРЛ АЁСј k-ПЌАсРкДТ AND АсЧеРИЗЮ ПЌАќЕШ КЮЧЅЧіЕщРЛ КаИЎЧЯДТЕЅ РЬПыРЬ ЕШДй. РЇРЧ КИБтРЧ AND/OR БзЗЁЧСДТ БзИВ 18 Ањ ААДй.

БзИВ 18 ИёЧЅ wff РЧ AND/OR БзЗЁЧС ЧЅЧі
РЬ БзЗЁЧСРЧ Рй ГыЕхЕщРК ИёЧЅ ЧЅЧіРЧ ЙЎРкЕщПЁ РЧЧи РЬИЇРЬ КйПЉСЎ РжДй. AND/OR БзЗЁЧСПЁМ, ЗчЦЎ (root) ГыЕхРЧ РкМеРЛ КЮИёЧЅ (subgoal) ГыЕхЖѓАэ ЧбДй. РЬ ИёЧЅ wff ЗЮКЮХЭ Л§МКЕЧДТ Р§ЕщРК Рй ГыЕхПЁ СОАсЕЧДТ ЧиАс БзЗЁЧСИІ ЕћЖѓАЁИщМ РЏЕЕЧв Мі РжДй. Ся,
~P(f(z)),
Q(f(y), y) Ёќ ~R(f(y)),
Q(f(y), y) Ёќ ~S(y).
ИёЧЅР§ЕщРК ЙЎРкЕщРЧ AND АсЧеРЬИч РЬ Р§ЕщРЧ OR АсЧеРЬ ИёЧЅ wff ИІ ГЊХИГНДй.
2) ШФЧт НУНКХлПЁМРЧ БдФЂ (B-БдФЂ) РћПы
B-БдФЂРЧ ЧќХТДТ ДйРНАњ ААРЬ СІЧбРЬ ЕШДй.
W ЂЁ L,
ПЉБтМ W ДТ ОюЖВ РгРЧРЧ wff (AND/OR ЧќХТПЁ РжДйАэ АЁСЄЧд) РЬАэ, L РК ЧЯГЊРЧ ЙЎРкРЬДй. ИёЧЅ wff ИІ ГЊХИГЛАэ РжДТ AND/OR БзЗЁЧСПЁ L Ањ ДмРЯШЕЩ Мі РжДТ L' ЗЮ РЬИЇРЬ КйРК ЙЎРк ГыЕхАЁ СИРчЧЯИщ РЇРЧ B-БдФЂРЛ РћПыЧв Мі РжДй. РЬ БдФЂРЧ РћПы ШФ ГЊХИГЊДТ БзЗЁЧСДТ L' ГыЕхЗЮКЮХЭ КёБГМБХУ ОЦХЉЗЮ РЬОюСіДТ ЛѕЗЮПю РкМе ГыЕх L РЛ УЗАЁЧб ЧќХТАЁ ЕЧИч, РЬ ЛѕЗЮПю РкМе ГыЕх L РЛ УЗАЁЧб ЧќХТАЁ ЕЧИч, РЬ ЛѕЗЮПю ГыЕхДТ u АЁ L Ањ L' РЧ АЁРх РЯЙнРћ ДмРЯШ (mgu) Жѓ Чв ЖЇ Wu ПЁ ДыЧб AND/OR БзЗЁЧСРЧ ЗчЦЎ ГыЕхАЁ ЕШДй. РЇРЧ МГИэРК ОеПЁМ МГИэЧб РќЧт НУНКХлПЁМРЧ F-БдФЂРЧ РћПыНУПЭ КёБГЧи КМ ЖЇ ЙнДы (duality) РЧ МКСњРЛ СіДЯАэ РжДй.
3) СОАс СЖАЧ
ШФЧт НУНКХлПЁ РЧЧи ЛчПыЕЧДТ ЛчНЧ ЧЅЧіЕщРК ЙЎРкЕщРЧ AND АсЧеРЧ ЧќХТПЁ ЧбСЄЕШДй. ШФЧт НУНКХлПЁМРЧ СОАсСЖАЧРК AND/OR БзЗЁЧСАЁ ЛчНЧ ГыЕхПЁМ ГЁГЊДТ РЯФЁЕШ (consistent) ЧиАс БзЗЁЧСИІ ЦїЧдЧЯДТ АЭРЬДй. ПЉБтМ РЯФЁЕШ ЧиАс БзЗЁЧСДТ КёБГ МБХУ ОЦХЉРЧ ФЁШЏЕщРЬ ДмРЯШ АсЧеРЛ ЧрЧЯДТ АцПьПЁ Л§БфДй. ПЙИІ ЕщОю ДйРНАњ ААРК ЛчНЧАњ БдФЂЕщРЬ РжДйАэ ЧЯРк.
|
F1 : F2 : F3 : F4 : R1 : R2 :
R3 : R4 : R5 : |
DOG(FIDO) ~BARKS(FIDO) WAGS-TAIL(FIDO) MEOWS(MYRTLE) [WAGS-TAIL(x1) Ёќ DOG(x1)] ЂЁ FRIENDLY(x1) [FRIENDLY(x2) Ёќ ~BARKS(x2)] ЂЁ ~AFRAID(y2, x2) DOG(x3) ЂЁ ANIMAL(x3) CAT(x) ЂЁ ANIMAL(x4) MEOWS(x5) ЂЁ CAT(x5) |
РЬЗЮКЮХЭ ДйРНАњ ААРК ИёЧЅ ЧЅЧіРЛ СѕИэЧЯАэРк ЧбДй.
(ЂЄx)(ЂЃy) {CAT(x) Ёќ DOG(y) Ёќ ~AFRAID(x, y)]
РЬ ЙЎСІПЁМ РЯФЁЕЧДТ ЧиАс БзЗЁЧСАЁ БзИВ 19 ПЁ ГЊХИГЊ РжДй. РЬ ЧиАс БзЗЁЧСРЧ РЯФЁМКРЛ КИРЬБт РЇЧи ЧиАс БзЗЁЧСПЁ РжДТ КёБГМБХУ ОЦХЉПЁ КаПЉСј И№Еч ФЁШЏЕщЗЮКЮХЭ ДмРЯШ АсЧеРЛ НУЕЕЧбДй. БзИВ 19 ПЁМ ({x/25}, {MYRTLE/x}, {FIDO/y}, {x/y2, y/x2}, {F1DO/y}, {y/x1}, {F1DO/y} {F1DO/y}) РЧ ДмРЯШ АсЧеРЛ ЧиОп ЧбДй. Бз АсАњДТ {MYRTLE/x5, MYRTLE/x, FIDO/y, MYRTLE/y2, FIDO/x2, FIDO/x1} РЬ ЕШДй. РЬ ДмРЯШ АсЧеРЛ ИёЧЅ ЧЅЧіПЁ РћПыНУХАИщ ДйРНАњ ААРК ЧиДфРЛ ОђАд ЕШДй.
[CAT(MYRTLE) Ёќ DOG(FIDO) Ёќ ~AFRAID(MYRTLE, FIDO)].

БзИВ 19 ШФЧт НУНКХлРЧ РЯФЁЕЧДТ ЧиАс БзЗЁЧС
РќЧтАњ ШФЧтРЧ БдФЂРЛ БтУЪЗЮЧб УпЗа НУНКХл АЂАЂРЬ РњИЖДйРЧ ЧбАшИІ АЁСјДй. ШФЧт НУНКХлРЧ АцПь, ОюЖАЧб РгРЧРЧ ЧќХТРЧ ИёЧЅ ЧЅЧіЕЕ АЁСњ Мі РжДТ ЙнИщПЁ ЛчНЧ ЧЅЧіРК ЙЎРкРЧ AND АсЧеРЬОюОпИИ ЧбДй. РќЧт НУНКХлРЧ АцПь, ОюЖАЧб РгРЧРЧ ЧќХТРЧ ЛчНЧ ЧЅЧіЕЕ АЁДЩЧЯСіИИ ИёЧЅ ЧЅЧіРК ЙЎРкЕщРЧ OR АсЧеРЬОюОп ЧбДй. БзЗЏИщ РЇПЁМ ИЛЧб РќЧтАњ ШФЧт НУНКХлПЁМ ГЊХИГЊДТ РхСЁИИРЛ АЁСіДТ НУНКХлРЛ Л§АЂЧи КМ ЧЪПфАЁ РжДй.
ЕбРЛ АсЧеЧб НУНКХлРЧ РќУМ ЕЅРЬХЭ КЃРЬНКДТ ЕЮ АГРЧ AND/OR БзЗЁЧС БИСЖИІ АЁСіИч, ЧЯГЊДТ ИёЧЅИІ, ЧЯГЊДТ ЛчНЧРЛ ГЊХИГНДй. РЬ БИСЖЕщРК ОеПЁМ О№БоЧпЕэРЬ B-БдФЂАњ, F-БдФЂПЁ РЧЧи АЂАЂ МіСЄРЬ ЕЧОюСјДй. РЬ АсЧеЕШ НУНКХлРК СОАсСЖАЧРЬ КЙРтЧЯАд ЕЧДТЕЅ, СОАсРЬ ЕЧДТ МјАЃРК БзЗЁЧСПЁМ КёБГМБХУЕЧДТ И№Еч ЙЎРк ГыЕхЕщРЬ ДмРЯШЕЧОюСіДТ МјАЃРЬДй. ЕЮ БзЗЁЧС ЛчРЬРЧ И№Еч АЁДЩЧб КёБГМБХУРЬ РЬЗчОюСј ШФ, ИёЧЅ БзЗЁЧСРЧ ЗчЦЎ ГыЕхПЁ РжДТ ЧЅЧіРЬ ЛчНЧ БзЗЁЧСРЧ ЗчЦЎ ГыЕхПЁ РжДТ ЧЅЧіАњ БдФЂРИЗЮКЮХЭ СѕИэРЬ ЕЧДТСіИІ АсСЄЧиОп ЧбДй. РЬАЭРЬ СѕИэЕЩ ЖЇ АсЧеЕШ НУНКХлРК СОАсРЬ ЕШДй. РЬ СОАсСЖАЧРК ЛчНЧ ГыЕхПЭ ИёЧЅ ГыЕхАЁ CANCEL ЕЩ ЖЇ РЬЗчОюСјДй. CANCEL РК ДйРНАњ ААРЬ МјШЏРћРИЗЮ СЄРЧЕШДй.
1. n РЬ ЛчНЧ ГыЕхРЬАэ m РЬ ИёЧЅ ГыЕхРЯ ЖЇ ЕЮ АГРЧ ГыЕх n Ањ m РК CANCEL ЕЩ Мі РжДй.
2. n Ањ m РЬ ДмРЯШЕЧДТ
ЙЎРкЕщПЁ РЧЧи СжОюСГАХГЊ ЖЧДТ n РЬ БзРЧ РкНФЕщРЧ ГыЕх { } ПЁ k-ПЌАсРкИІ АЁСіАэ ПЌАсЕЧОю РжРЛ ЖЇ АЂАЂРЧ
} ПЁ k-ПЌАсРкИІ АЁСіАэ ПЌАсЕЧОю РжРЛ ЖЇ АЂАЂРЧ  ГыЕхАЁ m Ањ CANCEL ЕЩ Мі РжДйИщ ЕЮ АГРЧ ГыЕх n Ањ m РК CANCEL ЕЩ Мі РжДй.
ГыЕхАЁ m Ањ CANCEL ЕЩ Мі РжДйИщ ЕЮ АГРЧ ГыЕх n Ањ m РК CANCEL ЕЩ Мі РжДй.
ПЙЗЮМ БзИВ 20 РЧ БНРК МБРК ЛчНЧ ГыЕхПЭ ИёЧЅ ГыЕхАЁ CANCEL ЕЧДТ АњСЄРЛ КИПЉСиДй.
БзИВ 20 CANCEL БзЗЁЧСРЧ ПЙ
1. ДйРНРЧ wff ЕщРЛ ХЌЗЮРњ ЧќХТЗЮ ЙйВйОюЖѓ.
(a) (ЂЃx) [P(x) ЂЁ P(x)]
(b) {~{(ЂЃx) P(x)}} ЂЁ (ЂЄx)[~P(x)]
(c) ~{(ЂЃx) {P(x) ЂЁ {(ЂЃy) [P(y) ЂЁ P(f(x, y))] Ёќ ~(ЂЃy) [Q(x, y) ЂЁ P(y)]}}}
(d) (ЂЃx)(ЂЄy) {[P(x, y) ЂЁ Q(y, x)] Ёќ [Q(y, x) ЂЁ S(x, y)]}
ЂЁ (ЂЄx) (ЂЃy) [P(x, y) ЂЁ S(x, y)]
2. АсСЄРК АЧРќ (sound) ЧдРЛ КИПЉЖѓ. Ся, ЕЮ ХЌЗЮРњРЧ АсСЄРкДТ ГэИЎРћРИЗЮ ЕЮ ХЌЗЮРњИІ ЕћИЅДйДТ АЭРЛ КИПЉЖѓ.
3. ДйРНРЧ ИИСЗЕЧСі ОЪРК ХЌЗЮРњЕщРЧ С§ЧеПЁ ДыЧи РЯТїРћ РдЗТЧќХТ ЙнКЙРЛ БИЧЯПЉЖѓ.
~P Ё§ ~Q Ё§ ~R
~S
Ё§ T
~T Ё§ P
S
~R
~S Ё§ U
~U Ё§ Q
4. ОЦЗЁРЧ ОюЖВ ХЌЗЮРњЕщРЬ P(f(x), y) ПЁ РЧЧи ЦїЧд (subsume) ЕЧДТСі СіРћЧЯПЉЖѓ.
(a) P(f(A), f(x)) Ё§ P(z, f(y))
(b) P(z, A) Ё§ ~P(A, z)
(c) P(f(f(x)), z)
(d) P(f(z), z) Ё§ Q(x)
(e) P(A, A) Ё§ P(f(x), y)
5. ДйРНРЧ АЂ АјНФРК ЧзСј (tautologies) РгРЛ АсСЄЙнКЙПЁ РЧЧи КИПЉЖѓ.
(a) (P ЂЁ Q) ЂЁ [(R Ё§ P) ЂЁ (R Ё§ Q)]
(b) [(P ЂЁ Q) ЂЁ P] ЂЁ R
(c) (~P ЂЁ P) ЂЁ P
(d) (P ЂЁ Q) ЂЁ (~Q ЂЁ ~P)
6. АсСЄЙнКЙЙцЙ§РЛ ЛчПыЧиМ ДйРНРЧ wff ЕщРЧ РЏШПМК (validity) РЛ СѕИэЧЯЖѓ.
(a) (ЂЄx) {[P(x) ЂЁ P(A)] Ёќ [P(x) ЂЁ P(B)]}
(b) (ЂЃz)[Q(z) ЂЁ P(z)] ЂЁ {(ЂЄx) [Q(x) ЂЁ P(A)] Ёќ [Q(x) ЂЁ P(B)]}
(c) (ЂЄx)(ЂЄy) {[P(f(x)) Ёќ Q(f(B))] ЂЁ [P(f(A)) Ёќ P(y) Ёќ Q(y)]}
(d) (ЂЄx)(ЂЃy)P(x, y) ЂЁ (ЂЃy)(ЂЄx)P(x, y)
(e) (ЂЃx){P(x) Ёќ [Q(A) Ё§ Q(B)]} ЂЁ (ЂЄx) [P(x) Ёќ Q(x)]
7. АсСЄЙнКЙПЁ РЧЧи wff (ЂЄx)(Px)) ДТ ГэИЎРћРИЗЮ wff[P(A1) Ё§ P(A2)] ЗЮКЮХЭ ЕћИЅДйДТ АЭРЛ КИПЉЖѓ. БзЗЏГЊ (ЂЄx)(P(x)) РЧ НКХЌЗНЧб ЧќХТРЮ, P(A) ДТ [P(A1) Ё§ P(A2)] ЗЮКЮХЭ ГэИЎРћРИЗЮ ЕћИЃСі ОЪДТДй. ПЉБтПЁ ДыЧи МГИэЧЯПЉЖѓ.
8. РќУМ ЕЅРЬХЭКЃРЬНКПЁМРЧ АсСЄБдФЂЙцНФРЛ ЛчПыЧб Л§МК НУНКХлРК АЁШЏМК (commutative) РЛ АЁСјДйДТ АЭРЛ КИПЉЖѓ.
9. ДйРНРЧ ЙЎРхЕщРЛ БдФЂПЁ БтУЪЧб БтЧЯСЄИЎСѕИэРЛ РЇЧб Л§МКБдФЂРИЗЮ ГЊХИГЛОюЖѓ.
(a) Corresponding angles of two congruent triangles are congruent.
(b) Corresponding sides of two congruent triangles are congruent.
(c) If the corresponding sides of two triangles are congruent, the triangles are congruent.
(d) The base angles of an isoceles triangle are congruent.
10. КэЗТ ЙЎСІРЧ ЛѓШВРЬ ДйРНРЧ wff ЕщРЧ С§ЧеПЁ РЧЧи ЙІЛчЕШДй.
ONTABLE(A) CLEAR(E)
ONTABLE(C)
CLEAR(D)
ON(D, C) HEAVY(D)
ON(B,
A) WOODEN(B)
HEAVY(B)
ON(E, B)
РЬЗЏЧб wff ЕщРЬ ЙІЛчЧЯАэРк ЧЯДТ ЛѓШВРЛ БтМњЧиКИОЦЖѓ.
ОЦЗЁРЧ ЙЎРхРК РЬЗЏЧб КэЗА ЙЎСІПЁ ДыЧб РЯЙнРћРЮ СіНФРЛ СІАјЧбДй.
Every
big, blue block is on a green block.
Each heavy,
wooden block is big.
All blocks with clear tops
are blue.
All wooden blocks are blue.
РЬЗЏЧб ЙЎРхЕщРЛ ОЯНУРћ ЧЅЧіРИЗЮ ГЊХИГЛОюЖѓ. ДѕПьБт "Which block is on a green block?" РЛ ЧЎБт РЇЧиМ B-БдФЂРЛ ЛчПыЧЯПЉ РЯФЁЧЯДТ AND-OR ЧиАс ЦЎИЎИІ БзЗСЖѓ.