휴리스틱
탐색
(Heuristic
Search)
인공지능-지능형
에이전트를 중심으로
: Nils
J.Nilsson 저서, 최중민. 김준태. 심광섭. 장병탁 공역, 사이텍미디어, 2000
(원서 : Artificial Intelligence :
A New Synthesis 1998), Page 145~167
평가 함수의 사용 (Using Evaluation Function)
일반적인 그래프 탐색 알고리즘 (A General Graph-Searching Algorithm)
(1) A* 알고리즘 (Algorithm A*)
(2) A* 의 허용성 (Admissibility of A*)
(3) 일관성 (또는 단조성) 조건 (The Consistency or Monotone Condition)
(4) 반복적 깊이증가 A* (Iterative Deepenig A*)
(5) 재귀적인 최상우선 탐색 (Recursive Best-First Search)
휴리스틱 함수와 탐색의 효율성 (Heuristic Functions and Search Efficiency)
참고문헌 및 토론 (Additional Readings and Discussion)
이 장에서 설명하는 탐색 방법은 너비우선 탐색과
비슷하지만, 탐색이 시작 노드에서부터 바깥쪽으로 균일하게 진행되지 않는 것이다.
대신에, 문제의 특성에 대한 정보인 휴리스틱 (heuristic) 에 따라 목표까지의 가장
좋은 경로상에 있다고 판단되는 노드를 우선 방문하도록 진행된다. 이러한 탐색 방법을
최상우선 (best-first) 또는 휴리스틱 (heuristic) 탐색이라고 한다. 기본적인 아이디어는
다음과 같다.
많은 경우에 최상우선 탐색을 수행하기 위한 좋은
평가 함수를 정의할 수 있다. 예를 들어, 8 퍼즐의 경우에는 어떤 상태의 좋고 나쁨을
측정하기 위하여 제자리에 있지 않은 타일의 개수를 이용할 수 있을 것이다.
 = 제자리에 있지 않은 타일의 수 (목표 상태와 비교했을 때)
= 제자리에 있지 않은 타일의 수 (목표 상태와 비교했을 때)

그림 1 휴리스틱 탐색의 한 예
앞에서 설명한 탐색 방법에 이 휴리스틱 함수를
적용하면 그림 1 과 같은 그래프가 만들어진다. 각 노드의 옆에 있는 숫자는 그 노드의
 값을 나타낸다.
값을 나타낸다.
이 예는 탐색 과정이 일찍 만들어진 노드를 선호하도록 할
필요가 있다는 것 (지나치게 낙관적인 휴리스틱에 의해 잘못된 길로 계속 내려가는
것을 막기 위해서) 을 보여준다. 따라서  에 깊이요소를 추가하여
에 깊이요소를 추가하여  으로 정의한다. 여기서
으로 정의한다. 여기서  은 그래프상에서
은 그래프상에서  의 깊이 (depth) (시작 노드에서
의 깊이 (depth) (시작 노드에서  까지 최단 경로의 길이) 에 대한 추정값이고,
까지 최단 경로의 길이) 에 대한 추정값이고,  은 노드
은 노드  에 대한 휴리스틱 평가값이다. 만일 앞에서처럼
에 대한 휴리스틱 평가값이다. 만일 앞에서처럼  = 제자리에 있지 않은 타일의 수라고 하고,
= 제자리에 있지 않은 타일의 수라고 하고,  = 탐색 그래프에서 노드
= 탐색 그래프에서 노드  의 깊이라고 하면 그림 2 와 같은 그래프가 만들어진다. 이 그림에는
의 깊이라고 하면 그림 2 와 같은 그래프가 만들어진다. 이 그림에는  값이 각 노드 옆에 나타나 있다. 이 경우에는 탐색이 더 곧바로 목표를 향해
진행하는 것을 볼 수 있다 (동그라미가 그려진 노드는 예외이다).
값이 각 노드 옆에 나타나 있다. 이 경우에는 탐색이 더 곧바로 목표를 향해
진행하는 것을 볼 수 있다 (동그라미가 그려진 노드는 예외이다).
을 이용한 휴리스틱탐색.gif)
그림 2  을 이용한 휴리스틱 탐색
을 이용한 휴리스틱 탐색
이 예는 두 가지 중요한 의문을 제기한다. 첫째,
최상우선 탐색의 방향을 결정하는 평가 함수를 어떻게 설정할 수 있는가? 둘째, 최상우선
탐색의 특성은 무엇인가? 최상우선 탐색은 언제나 목표 노드까지의 좋은 경로를 찾아내는가?
평가 함수를 선택하기 위한 가이드라인은 이 장의 뒷부분에서 이야기할 것이며, 평가
함수를 자동으로 학습하는 방법은 계획, 행동 그리고 학습에서 설명할 것이다. 그러나
이 장에서는 대부분 최상우선 탐색에 대한 정의와 여러 측면들을 이야기할 것이다.
우선 일반적인 그래프 탐색 알고리즘을 정의하도록 하자. 최상우선 탐색은 이러한
알고리즘의 한 특수한 경우에 해당한다 (휴리스틱 탐색에 관한 더 자세한 내용은
인용 논문과 Pearl [Pearl 1984] 의 책을 참고하라).
이 장에서 설명할 휴리스틱 탐색 방법에 대해 좀
더 상세하게 기술하려면 휴리스틱이나 무정보 탐색 어느 쪽에나 적용되는 일반적인
그래프 탐색 알고리즘을 이야기할 필요가 있다. 이 알고리즘을 GRAPHSEARCH 라고
하자. 이 알고리즘의 (첫번째) 정의는 다음과 같다.
이 알고리즘은 최상우선 탐색, 깊이우선 탐색,
또는 너비우선 탐색을 수행하는 데 모두 사용될 수 있다. 너비우선 탐색을 하려면
새 노드를 OPEN 의 끝에 넣고 (first in first out 또는 FIFO), 재정렬하지
않으면 된다. 깊이우선 탐색을 하려면 새 노드를 OPEN 의 앞에 넣으면 된다
(last in first out 또는 FIFO). 최상우선 (휴리스틱) 탐색을 하려면 OPEN
을 각 노드의 휴리스틱값에 따라 재정렬하면 된다.
GRAPHSEARCH 알고리즘을
OPEN 에 있는 노드들을 8 퍼즐에서 보인 것과 같이  값의 오름차순으로 정렬하는 (단계 7) 최상우선 탐색으로 만들어 보자. 이렇게
만든 GRAPHSEARCH 알고리즘을 알고리즘 A* 라고 하자. 곧 설명하겠지만,
A* 가 너비우선 또는 균일비용 탐색을 수행하도록
값의 오름차순으로 정렬하는 (단계 7) 최상우선 탐색으로 만들어 보자. 이렇게
만든 GRAPHSEARCH 알고리즘을 알고리즘 A* 라고 하자. 곧 설명하겠지만,
A* 가 너비우선 또는 균일비용 탐색을 수행하도록  함수를 정의할 수 있다. 앞으로 사용할
함수를 정의할 수 있다. 앞으로 사용할  함수들을 정의하기 위하여 우선 몇 가지 추가적인 용어들을 도입하자.
함수들을 정의하기 위하여 우선 몇 가지 추가적인 용어들을 도입하자.
 을 노드
을 노드  과 목표 노드 사이의 최단 경로 (
과 목표 노드 사이의 최단 경로 ( 에서 모든 목표 노드까지의 모든 가능한 경로 중에서) 의 실제 값이라고 하자.
에서 모든 목표 노드까지의 모든 가능한 경로 중에서) 의 실제 값이라고 하자.
 을 시작 노드
을 시작 노드  에서
에서  까지의 최단 경로의 값이라고 하자. 그러면
까지의 최단 경로의 값이라고 하자. 그러면  은
은  에서 목표 노드까지 노드
에서 목표 노드까지 노드  을 통하여 갈 수 있는 모든 가능한 경로 중에서 최단 경로의 값이 된다. 그리고
을 통하여 갈 수 있는 모든 가능한 경로 중에서 최단 경로의 값이 된다. 그리고
 는
는  에서 목표 노드까지의 (조건 없는) 최단 경로의 값을 나타낸다. 각 노드
에서 목표 노드까지의 (조건 없는) 최단 경로의 값을 나타낸다. 각 노드  에 대하여
에 대하여  (휴리스틱 요소) 을
(휴리스틱 요소) 을  의 추정값이라고 하고,
의 추정값이라고 하고,  (깊이 요소) 을 A* 에 의하여 지금까지 발견된 노드
(깊이 요소) 을 A* 에 의하여 지금까지 발견된 노드  까지의 경로 중에서 최단 경로의 값이라고 하자. 알고리즘 A* 에서는
까지의 경로 중에서 최단 경로의 값이라고 하자. 알고리즘 A* 에서는
 를 평가 함수로 사용한다. 알고리즘 A* 에서
를 평가 함수로 사용한다. 알고리즘 A* 에서  이 0 이면 균일비용 탐색이 된다.
이 0 이면 균일비용 탐색이 된다.
지금까지의 정의들을 그림 3 에 나타내었다.

그림 3 휴리스틱 탐색의 용어
그림 2 에서 보인 8 퍼즐에 대한 탐색 과정은 A*
의 한 응용 예이다. 그 예에서는 모든 아크의 값을 1 로 가정하였으므로,  은 단순히 노드
은 단순히 노드  의 깊이가 된다. 그런데 알고리즘 A* 의 정의에서 짚고 넘어가지
않은 약간 복잡한 문제가 있다. 만일 탐색하고 있는 암시적인 그래프가 트리가 아니면
어떻게 되는가? 즉, 시작 상태에서 특정한 상태로 가는 행동 순서가 하나 이상 있는
경우를 말한다. 예를 들어 8 퍼즐의 경우, 모든 행동이 역방향으로 갈 수 있으므로
어떤 노드
의 깊이가 된다. 그런데 알고리즘 A* 의 정의에서 짚고 넘어가지
않은 약간 복잡한 문제가 있다. 만일 탐색하고 있는 암시적인 그래프가 트리가 아니면
어떻게 되는가? 즉, 시작 상태에서 특정한 상태로 가는 행동 순서가 하나 이상 있는
경우를 말한다. 예를 들어 8 퍼즐의 경우, 모든 행동이 역방향으로 갈 수 있으므로
어떤 노드  의 각 자식 노드들은
의 각 자식 노드들은  을 자신의 자식 노드로 가진다. 따라서 8 퍼즐의 암시적인 그래프는 분명히 트리가
아니다. 8 퍼즐의 탐색 트리를 만들 때는 이러한 루프 (loop) 를 무시하였다. 8 퍼즐의
경우에는 이것이 간단하였다. 즉, 어떤 노드의 부모 노드는 그 노드의 자식 노드들
중에 포함시키지 않았다. GRAPHSEARCH 의 단계 6 을 실제로 다음과 같이 수행했다.
을 자신의 자식 노드로 가진다. 따라서 8 퍼즐의 암시적인 그래프는 분명히 트리가
아니다. 8 퍼즐의 탐색 트리를 만들 때는 이러한 루프 (loop) 를 무시하였다. 8 퍼즐의
경우에는 이것이 간단하였다. 즉, 어떤 노드의 부모 노드는 그 노드의 자식 노드들
중에 포함시키지 않았다. GRAPHSEARCH 의 단계 6 을 실제로 다음과 같이 수행했다.
물론 이러한 큰 루프를 검사하려면 어떤 노드  의 각 자식 노드가 노드
의 각 자식 노드가 노드  의 조상 노드와 일치하는지 보아야 한다. 자료 구조가 복잡할 경우, 이 단계
때문에 알고리즘의 복잡도 (complexity) 가 커질 수 있다.
의 조상 노드와 일치하는지 보아야 한다. 자료 구조가 복잡할 경우, 이 단계
때문에 알고리즘의 복잡도 (complexity) 가 커질 수 있다.
단계 6 을 수정하면
알고리즘이 목표까지의 경로를 탐색할 때 반복적인 루프에 빠지는 것을 막을 수 있다.
그러나 아직도 다른 경로를 통하여 같은 상태에 도달할 가능성이 남아 있다. 이 문제를
처리하는 한 가지 방법은 이 경우를 무시하는 것이다. 즉, 알고리즘이  에 있는 어떤 노드가 이미 OPEN 또는 CLOSED 에 있는지 검사하지
않는 것이다. 이렇게 되면 알고리즘은 다른 경로로 같은 노드에 도달했을 가능성에
대해서는 상관하지 않는다. 이 "같은 노드" 는 알고리즘이 서로 다른 경로를
찾은 수만큼
에 있는 어떤 노드가 이미 OPEN 또는 CLOSED 에 있는지 검사하지
않는 것이다. 이렇게 되면 알고리즘은 다른 경로로 같은 노드에 도달했을 가능성에
대해서는 상관하지 않는다. 이 "같은 노드" 는 알고리즘이 서로 다른 경로를
찾은 수만큼  에 반복될 것이다. 만일
에 반복될 것이다. 만일  의 두 노드가 같은 자료 구조를 갖고 있다면 이 두 노드는 각자 똑같은 서브트리를
갖게 될 것이다. 따라서 알고리즘은 필요없는 탐색을 반복하게 된다. 뒤에 가서
의 두 노드가 같은 자료 구조를 갖고 있다면 이 두 노드는 각자 똑같은 서브트리를
갖게 될 것이다. 따라서 알고리즘은 필요없는 탐색을 반복하게 된다. 뒤에 가서  에 대한 적당한 조건하에서는 A* 가
에 대한 적당한 조건하에서는 A* 가  에서 어떤 노드
에서 어떤 노드  을 처음 확장할 때 이미
을 처음 확장할 때 이미  값이 최소인
값이 최소인  까지의 경로를 발견한 것임을 보일 것이다.
까지의 경로를 발견한 것임을 보일 것이다.

그림 4 탐색과정에서 만들어지는
탐색 그래프와 트리
앞으로 설명할  에 대한 조건이 전제되지 않는 경우, 중복된 탐색을 막으려면 알고리즘 A*
에 약간의 수정을 해야 한다. 탐색이 서로 다른 경로로 같은 노드에 도달할 수 있으므로
알고리즘 A* 는 그래프를 만들어내게 된다. 이 그래프를
에 대한 조건이 전제되지 않는 경우, 중복된 탐색을 막으려면 알고리즘 A*
에 약간의 수정을 해야 한다. 탐색이 서로 다른 경로로 같은 노드에 도달할 수 있으므로
알고리즘 A* 는 그래프를 만들어내게 된다. 이 그래프를  라고 하자.
라고 하자.  는 A* 가 시작 노드에서부터 자식 노드와 그 자식 노드들을 차례로
확장하면서 만들어낸 노드와 아크의 구조이다. A* 는 또한 탐색트리
는 A* 가 시작 노드에서부터 자식 노드와 그 자식 노드들을 차례로
확장하면서 만들어낸 노드와 아크의 구조이다. A* 는 또한 탐색트리  을 저장하고 있다.
을 저장하고 있다.  의 서브그래프인
의 서브그래프인  은 탐색 그래프에서 모든 노드까지의 지금까지 찾아진 최단 경로로 구성된 트리이다.
그림 4 에 아크값이 모두 1 인 그래프의 예를 보였다. 탐색의 초반은 그림 4a 와
같다. 탐색 그래프에서 탐색트리 부분은 진한색 아크로 표시되어 있고, 회색 아크는
탐색트리에 포함되지 않는 부분이다. 진한색 아크는 해당 노드까지의 지금까지 발견된
경로 중 최소값을 갖는 경로를 나타낸다. 그림 4a 에서 노드 4 는 두 개의 경로를
따라 도달할 수 있다. 두 경로 모두 탐색 그래프에 있지만 탐색트리에는 하나만 포함된다.
이전 탐색 과정에서 탐색트리에 있지 않았던 아크를 포함하는 더 짧은 경로가 나중에
찾아질 수 있기 때문에 탐색 그래프를 저장하고 있어야 한다. 예를 들어, 그림 4b
에서 노드 1 을 확장하면 노드 2 와 그 후손들 (노드 4 등을 포함한) 까지의 더 짧은
경로가 찾아지므로 탐색트리가 변하게 된다.
은 탐색 그래프에서 모든 노드까지의 지금까지 찾아진 최단 경로로 구성된 트리이다.
그림 4 에 아크값이 모두 1 인 그래프의 예를 보였다. 탐색의 초반은 그림 4a 와
같다. 탐색 그래프에서 탐색트리 부분은 진한색 아크로 표시되어 있고, 회색 아크는
탐색트리에 포함되지 않는 부분이다. 진한색 아크는 해당 노드까지의 지금까지 발견된
경로 중 최소값을 갖는 경로를 나타낸다. 그림 4a 에서 노드 4 는 두 개의 경로를
따라 도달할 수 있다. 두 경로 모두 탐색 그래프에 있지만 탐색트리에는 하나만 포함된다.
이전 탐색 과정에서 탐색트리에 있지 않았던 아크를 포함하는 더 짧은 경로가 나중에
찾아질 수 있기 때문에 탐색 그래프를 저장하고 있어야 한다. 예를 들어, 그림 4b
에서 노드 1 을 확장하면 노드 2 와 그 후손들 (노드 4 등을 포함한) 까지의 더 짧은
경로가 찾아지므로 탐색트리가 변하게 된다.
완벽을 기하기 위해서, 탐색 그래프를
유지하는 A* 알고리즘을 쓰도록 하겠다. 그러나 대개의 경우, 알고리즘
A* 가 어떤 노드를 확장할 때 언제나 그 노드까지의 최단 경로를 찾도록
 에 대한 조건을 줄 수 있으므로, 이 형태의 알고리즘은 거의 쓰이지 않는다.
에 대한 조건을 줄 수 있으므로, 이 형태의 알고리즘은 거의 쓰이지 않는다.
단계 7 에서는 만일 탐색 과정에서 어떤 노드에
대해 현재의 포인터가 가리키는 경로보다 더 작은 값을 갖는 경로가 발견되면 포인터를
변경한다. 이미 CLOSED 에 있는 노드의 모든 후손 노드의 포인터를 변경하면
탐색이 줄어들 게 되지만, 계산량이 지수 함수적으로 늘어날 가능성이 있다. 따라서
단계 7 의 이 부분은 대개 구현하지 않는다. 이러한 포인터의 대부분은 탐색이 진행되면서
결국 변경되게 되어 있다.
알고리즘 A*
가 항상 최단 경로를 찾는 것을 보장하는 그래프와  에 대한 조건이 있다. 그래프에 대한 조건은 다음과 같다.
에 대한 조건이 있다. 그래프에 대한 조건은 다음과 같다.
이러한 하한 (lower-bound) 조건을 만족하는  함수를 찾는 것은 그렇게 힘든 일이 아니다. 예를 들어, 노드가 도시들을
나타내는 그래프의 경로 찾기 문제에서는, 어떤 도시
함수를 찾는 것은 그렇게 힘든 일이 아니다. 예를 들어, 노드가 도시들을
나타내는 그래프의 경로 찾기 문제에서는, 어떤 도시  에서 목표 도시까지의 직선 거리가
에서 목표 도시까지의 직선 거리가  에서 목표 노드까지의 최적 경로의 길이에 대한 하한값이 된다. 8 퍼즐 문제에서는,
제자리에 있지 않은 타일의 수가 목표까지 남은 타일 이동 개수에 하한값이 된다.
에서 목표 노드까지의 최적 경로의 길이에 대한 하한값이 된다. 8 퍼즐 문제에서는,
제자리에 있지 않은 타일의 수가 목표까지 남은 타일 이동 개수에 하한값이 된다.
이러한
세 개의 조건을 만족하면 알고리즘 A* 는 목표까지의 경로가 있기만 하다면
항상 최적 경로를 찾는다는 것을 보장한다. 이것을 하나의 정리 (theorem) 로 표현할
수 있다 (아래에 이 정리에 대한 새로운 증명을 제시하였다. 원래의 증명을 보려면
[Hart, Nilsson, & Raphael 1968] 을 참고하라).
정리
1
앞에서 언급한 그래프와  에 대한 조건이 만족되고, 시작 노드
에 대한 조건이 만족되고, 시작 노드  에서 목표 노드까지 유한값을 갖는 경로가 존재하면, 알고리즘 A* 는
항상 목표까지의 최단 경로를 찾고 끝나게 된다.
에서 목표 노드까지 유한값을 갖는 경로가 존재하면, 알고리즘 A* 는
항상 목표까지의 최단 경로를 찾고 끝나게 된다.
증 명 … 증명의 주 요소는 다음에
있는 중요한 보조정리이다. 어떻게 알고리즘 A* 가 최적 경로를 찾는
것을 보장하는가에 대한 직관을 얻기 위해서는 이 보조정리를 완전히 이해하는
것이 중요하다.
보조정리
1
A* 가 끝날 때까지의 모든 단계에, 아래의 특성을
만족하는 노드  가 항상 OPEN 에 존재한다.
가 항상 OPEN 에 존재한다.
1.  는 목표까지의 최적 경로상에 있다.
는 목표까지의 최적 경로상에 있다.
2. A* 는  까지의 최적 경로를 찾았다.
까지의 최적 경로를 찾았다.
3. 
보조정리의 증명 … 이 보조정리의 결론이
A* 의 모든 단계에서 성립한다는 것을 증명하려면, 다음의 두 가지를
증명해야 한다. (1) 알고리즘이 시작할 때 결론이 성립한다. (2) 어떤 노드를
확장하기 전에 결론이 성립한다면 노드를 확장한 후에도 결론이 성립한다. 이런
증명 방법을 수학적 귀납법 (mathematical induction) 이라고 한다. 증명은 다음과
같다.
번째노드.gif)
그림 5  번째 노드가 확장될 때의 상황
번째 노드가 확장될 때의 상황
이렇게 하여 정리가 완전히 증명되었다. 목표까지의
최적 경로를 찾는 것을 보장하는 알고리즘을 허용 가능 (admissible) 하다고 한다.
따라서 정리에서의 세 가지 조건을 만족하면 A* 는 허용 가능하다. 나아가
 를 과대평가 (overestimate) 하지 않는 모든
를 과대평가 (overestimate) 하지 않는 모든  를 허용 가능하다고 한다. 지금부터는 A* 를 적용한다고 할 때 항상
정리에 있는 세 가지 조건이 만족된다고 가정한다.
를 허용 가능하다고 한다. 지금부터는 A* 를 적용한다고 할 때 항상
정리에 있는 세 가지 조건이 만족된다고 가정한다.
만일 두 개의 서로 다른 A* 알고리즘
A*2 와 A*1 가 목표 외의 모든 노드에
대하여  인 점만 다르다면, A*2 가 A*1 보다
정보가 많다 (more informed) 고 한다. 여기에 대한 다음의 정리는 증명하지 않겠다
([Hart, Nilsson, & Raphael 1968, Hart, Nilsson, & Raphael 1972, Nilsson
1980] 을 참조).
인 점만 다르다면, A*2 가 A*1 보다
정보가 많다 (more informed) 고 한다. 여기에 대한 다음의 정리는 증명하지 않겠다
([Hart, Nilsson, & Raphael 1968, Hart, Nilsson, & Raphael 1972, Nilsson
1980] 을 참조).
정리
2
A*2 가 A*1 보다
정보가 많다면 (more informed),  에서 목표 노드까지 경로가 있는 모든 그래프에 대해서, 탐색이 종료되었을 때
A*2 에 의해 확장된 노드는 A*1 에
의해서도 확장된다.
에서 목표 노드까지 경로가 있는 모든 그래프에 대해서, 탐색이 종료되었을 때
A*2 에 의해 확장된 노드는 A*1 에
의해서도 확장된다.
즉 A*1 은 최소한 A*2 가
확장하는 것보다 많은 노드를 확장하며, 따라서 정보가 많은 알고리즘인 A*2 가
일반적으로 더 효율적이다. 그러므로 실제  를 넘지 않으면서 (허용성을 갖기 위해서),
를 넘지 않으면서 (허용성을 갖기 위해서),  에 가장 근접한 값을 갖는
에 가장 근접한 값을 갖는  함수를 찾는 것이 좋다 (탐색의 효율을 높이기 위하여). 물론, 전체 탐색
효율을 측정하는 데 있어서는
함수를 찾는 것이 좋다 (탐색의 효율을 높이기 위하여). 물론, 전체 탐색
효율을 측정하는 데 있어서는  를 계산하는 비용도 고려해야만 한다. 가장 정보가 많은 알고리즘은
를 계산하는 비용도 고려해야만 한다. 가장 정보가 많은 알고리즘은  인 경우이겠지만, 일반적으로 이런
인 경우이겠지만, 일반적으로 이런  함수는 수행하려고 하는 탐색 그 자체를 완료함으로써만 얻어질 수 있는
것이다!
함수는 수행하려고 하는 탐색 그 자체를 완료함으로써만 얻어질 수 있는
것이다!

그림 6 탐색 알고리즘 사이의 관계
그림 6 은 지금까지 논의했던 탐색 알고리즘들
사이의 관계를 정리한 것이다. 모든 노드에 대하여  이면 균일비용 탐색 (uniform-cost search) 이 된다 (탐색은 같은 값의 등심선을
따라 진행된다).
이면 균일비용 탐색 (uniform-cost search) 이 된다 (탐색은 같은 값의 등심선을
따라 진행된다).  이면 같은 깊이의 등심선을 따라 진행되는 너비우선 탐색 (breadth-first search)
이 된다. 균일비용 탐색이나 너비우선 탐색 모두 A* 의 특수한 경우
이면 같은 깊이의 등심선을 따라 진행되는 너비우선 탐색 (breadth-first search)
이 된다. 균일비용 탐색이나 너비우선 탐색 모두 A* 의 특수한 경우  이므로 역시 허용 가능 (admissible) 하다.
이므로 역시 허용 가능 (admissible) 하다.
 가
가  의 자식 노드인 노드 쌍을 생각해 보자. 탐색 그래프 안의 모든 노드 쌍이 다음의
조건을 만족하면 일관성 조건 (consistency condition)을 만족한다고 한다.
의 자식 노드인 노드 쌍을 생각해 보자. 탐색 그래프 안의 모든 노드 쌍이 다음의
조건을 만족하면 일관성 조건 (consistency condition)을 만족한다고 한다.

여기서  는
는  에서
에서  까지 아크의 값이다. 이 식을 다음과 같이 쓸 수도 있다.
까지 아크의 값이다. 이 식을 다음과 같이 쓸 수도 있다.



그림 7 일관성 조건
이 조건은, 탐색 그래프의 어떤 경로를 따라서도,
목표까지의 (남은) 최적값의 추정치는 그 경로상의 아크값 이상으로 감소하지는 않는다는
것이다. 즉, 휴리스틱 함수는 아크의 알려진 값을 고려할 때 국부적인 일관성을 갖는다는
것이다. 일관성 조건은 그림 7에 있는 것과 같이 일종의 삼각 부등식 (triangle inequality)
이라고 생각할 수 있다.
또한 일관성 조건은 탐색트리 노드에서의  값이 시작 노드에서 멀어짐에 따라 단조적으로 증가한다 (monotonically nondecreasing)
는 것을 암시한다.
값이 시작 노드에서 멀어짐에 따라 단조적으로 증가한다 (monotonically nondecreasing)
는 것을 암시한다.  와
와  를 A* 에 의해 생성된 탐색트리의 두 노드로써
를 A* 에 의해 생성된 탐색트리의 두 노드로써  가
가  의 자식 노드라고 하자. 만일 일관성 조건이 만족된다면
의 자식 노드라고 하자. 만일 일관성 조건이 만족된다면  이다. 다음의 일관성 조건으로부터 이 사실을 증명하자.
이다. 다음의 일관성 조건으로부터 이 사실을 증명하자.

양변에  를 더하면,
를 더하면,

그런데  이다 (
이다 ( 에
에  를 통하는 것보다 작은 값을 갖는 경로를 따라 도달할 수도 있으므로
를 통하는 것보다 작은 값을 갖는 경로를 따라 도달할 수도 있으므로  가 이 값보다 작을 수도 있지 않을까 하고 생각할지 모른다. 그러나 그렇다면
가 이 값보다 작을 수도 있지 않을까 하고 생각할지 모른다. 그러나 그렇다면
 는 탐색트리에서
는 탐색트리에서  의 자식 노드가 아닐 것이다). 따라서,
의 자식 노드가 아닐 것이다). 따라서,

가 된다.
이런 이유 때문에 ( 에 대한) 일관성 조건을 (
에 대한) 일관성 조건을 ( 에 대한) 단조성 조건 (monotone condition) 이라고도 한다.
에 대한) 단조성 조건 (monotone condition) 이라고도 한다.
일관성 조건과
관련 있는 중요한 정리를 소개한다 ([Hart, Nilsson, & Raphael 1968]).

그림 8 정리 3 의 증명에 사용된
그래프
정리
3
일관성 조건은 만족되기만 하면 A* 가
(단계 7 에서) 전혀 포인터를 변경할 필요가 없게 되므로 매우 중요한 조건이다.
이렇게 되면 그래프의 탐색은 트리의 탐색과 차이가 없게 된다.
일관성 조건이
만족되면 A* 의 허용성에 대하여 다음과 같은 방법으로 단순하고 직관적인
결론을 내릴 수 있다.
많은 휴리스틱 함수들이 일관성 조건을 만족한다.
예를 들어, 8 퍼즐에서의 "제자리에 있지 않은 타일" 함수도 이 조건을
만족한다. 휴리스틱 함수가 일관성 조건을 만족하지는 않지만 허용 가능 (admissible)
하다면, (Mérõ[Mérõ 1984] 가 제안한 아이디어를 사용하여)
그 함수를 일관성 조건을 만족하는 것으로 (탐색 도중에) 조정할 수 있다. 가령,
A* 의 모든 단계에서 막 확장된 노드  의 자식 노드들의
의 자식 노드들의  값을 검사한다고 하자. 이들 중
값을 검사한다고 하자. 이들 중  값이
값이  에서
에서  으로부터 자신까지의 아크값을 뺀 것보다 작은 노드가 있으면,
으로부터 자신까지의 아크값을 뺀 것보다 작은 노드가 있으면,  값을
값을  에서 아크값을 뺀 값으로 (탐색 도중에) 조정한다 (CLOSED 에 있는 노드의
에서 아크값을 뺀 값으로 (탐색 도중에) 조정한다 (CLOSED 에 있는 노드의
 값이 이와 같이 변경되면 그 노드를 OPEN 으로 다시 옮겨야 할
수도 있다. 이러한 조정을 하여도 알고리즘이 허용 가능하다는 것을 증명하는 것은
독자의 몫으로 남겨두겠다).
값이 이와 같이 변경되면 그 노드를 OPEN 으로 다시 옮겨야 할
수도 있다. 이러한 조정을 하여도 알고리즘이 허용 가능하다는 것을 증명하는 것은
독자의 몫으로 남겨두겠다).
무정보 탐색에서 너비우선 탐색의 메모리 요구량은
탐색공간에서 목표 노드의 깊이에 비례하여 지수적으로 증가한다고 하였다. 좋은
휴리스틱이 분기 계수를 감소시키기는 하지만, 휴리스틱 탐색도 같은 단점을 가지고
있다. 무정보 탐색에서 소개한 반복적 깊이증가 탐색 (iterative deepening search)
을 이용하면 메모리 요구량이 목표 노드의 깊이에 비례하여 선형적으로 증가하면서
최단 경로를 찾을 수 있다. [Korf 1985] 가 제안한 반복적 깊이증가 A* (iterative-deepening
A*, IDA*) 방법을 사용하면 휴리스틱 탐색에서도 비슷한
효과를 얻을 수 있다. IDA* 를 병렬 알고리즘으로 구현하면 효율을 더욱
높일 수도 있다 ([Powley, Ferguson, & Korf 1993] 을 참조).
이 방법은 보통의
반복적 깊이증가 탐색과 비슷한 방식으로 수행된다. 첫 번 탐색에서는 값 한계 (cost
cut-off) 를  로 설정한다.
로 설정한다.  은 시작 노드이다. 알다시피, 목표까지의 최적 경로값은 이 값보다 크거나 같다
(만일
은 시작 노드이다. 알다시피, 목표까지의 최적 경로값은 이 값보다 크거나 같다
(만일  이면 같게 된다.
이면 같게 된다.  이므로 더 작을 수는 없다). 탐색은 어떤 노드를 확장했을 때 자식 노드의
이므로 더 작을 수는 없다). 탐색은 어떤 노드를 확장했을 때 자식 노드의  값이 한계값을 넘으면 되추적 (backtracking) 하면서 깊이우선 형태로
진행한다. 이 깊이우선 탐색이 목표 노드를 찾고 끝난다면, 분명히 목표까지의 최단
경로를 찾은 것이다. 만일 그렇지 않으면, 최적 경로의 값은 이 한계값보다 크다고
할 수 있다. 따라서 한계값을 증가시키고 다시 깊이우선 탐색을 시작한다. 최적 경로의
다음으로 가능한 값은 얼마인가? 그 값은 이전의 깊이우선 탐색에서 방문했던 (하지만
확장되지는 않은) 노드들의
값이 한계값을 넘으면 되추적 (backtracking) 하면서 깊이우선 형태로
진행한다. 이 깊이우선 탐색이 목표 노드를 찾고 끝난다면, 분명히 목표까지의 최단
경로를 찾은 것이다. 만일 그렇지 않으면, 최적 경로의 값은 이 한계값보다 크다고
할 수 있다. 따라서 한계값을 증가시키고 다시 깊이우선 탐색을 시작한다. 최적 경로의
다음으로 가능한 값은 얼마인가? 그 값은 이전의 깊이우선 탐색에서 방문했던 (하지만
확장되지는 않은) 노드들의  값 중 최소값보다 크거나 같을 것이다.
값 중 최소값보다 크거나 같을 것이다.  값이 최소인 노드가 최적 경로상에 있을 수 있는 것이다 (이전의 한계값과 같은
값을 갖는 최적 경로가 없다는 것은 이미 알고 있다). 이
값이 최소인 노드가 최적 경로상에 있을 수 있는 것이다 (이전의 한계값과 같은
값을 갖는 최적 경로가 없다는 것은 이미 알고 있다). 이  의 최소값이 다음 번 깊이우선 탐색에서 한계값으로 사용된다. 직관적으로 IDA* 가
목표까지의 최단 경로를 찾는 것을 보장한다는 것을 쉽게 알 수 있다 ([Korf 1985]
와 [Korf 1993] 에 여기에 대한 증명이 나와 있다. 두 번재 논문에서는 단조성
조건이 만족되지 않는 경우에 있어서 반복적 깊이 증가의 한계에 대하여 논하고 재귀적
최상우선탐색 (recursive best-first search) 이라는 새로운 알고리즘을 제시하였다).
의 최소값이 다음 번 깊이우선 탐색에서 한계값으로 사용된다. 직관적으로 IDA* 가
목표까지의 최단 경로를 찾는 것을 보장한다는 것을 쉽게 알 수 있다 ([Korf 1985]
와 [Korf 1993] 에 여기에 대한 증명이 나와 있다. 두 번재 논문에서는 단조성
조건이 만족되지 않는 경우에 있어서 반복적 깊이 증가의 한계에 대하여 논하고 재귀적
최상우선탐색 (recursive best-first search) 이라는 새로운 알고리즘을 제시하였다).
IDA* 가
노드의 확장을 반복해야 하지만 (보통의 반복적 깊이증가와 마찬가지로) 메모리 요구량의
감소와 깊이우선 탐색의 구현상의 효율성 (너비우선 탐색에 비하여) 과 관련하여
트레이드오프가 있는 것이다. 그런데 탐색공간에서 모든 노드의  값이 다른 경우에는 어떤 일이 발생하는지 생각해 보자. 반복의 회수가
값이 다른 경우에는 어떤 일이 발생하는지 생각해 보자. 반복의 회수가  값이 최적 경로의 값보다 작은 모든 노드의 수와 같게 된다 (허용성을 포기하는
대가로 이 문제를 개선할 수 있는 방법들이 있다. 어떻게 하면 되는지 생각해 보는
것은 독자의 몫으로 남겨두겠다)!
값이 최적 경로의 값보다 작은 모든 노드의 수와 같게 된다 (허용성을 포기하는
대가로 이 문제를 개선할 수 있는 방법들이 있다. 어떻게 하면 되는지 생각해 보는
것은 독자의 몫으로 남겨두겠다)!
Korf 가 제안한 재귀적 최상우선 탐색 (recursive
best-first search), RBFS ([kORF 1993]), 이라는 탐색 방법은 IDA* 보다
약간 많은 메모리를 사용하지만 IDA* 에 비하여 적은 수의 노드를 만들어낸다.
어떤 노드  이 확장될 때 RBFS 는
이 확장될 때 RBFS 는  의 자식 노드들의
의 자식 노드들의  값을 계산한 다음,
값을 계산한 다음,  과
과  의 모든 조상 노드들의
의 모든 조상 노드들의  값을 다시 계산한다. 이 재계산 과정을
값을 다시 계산한다. 이 재계산 과정을  값의 전달 (backing up) 이라고 한다. 전달 과정은 다음과 같이 수행된다.
지금 확장된 노드의 자식 노드들의 전달값은 그 노드의
값의 전달 (backing up) 이라고 한다. 전달 과정은 다음과 같이 수행된다.
지금 확장된 노드의 자식 노드들의 전달값은 그 노드의  값이다. 자식 노드들이
값이다. 자식 노드들이  인 노드
인 노드  의 전달값
의 전달값  은 다음과 같다.
은 다음과 같다.

여기서  는 노드
는 노드  의 전달값이다.
의 전달값이다.
만일 (지금 확장된) 노드  의 자식 노드 중 하나가 모든 OPEN 에 있는 노드들 중에서 가장 작은
의 자식 노드 중 하나가 모든 OPEN 에 있는 노드들 중에서 가장 작은
 값을 가지고 있다면 그 노드를 다음으로 확장한다. 그렇지 않고 노드
값을 가지고 있다면 그 노드를 다음으로 확장한다. 그렇지 않고 노드  의 자식 노드가 아닌 OPEN 에 있는 다른 노드
의 자식 노드가 아닌 OPEN 에 있는 다른 노드  가 최소의
가 최소의  값을 가지고 잇다고 하자. 이 경우 알고리즘은
값을 가지고 잇다고 하자. 이 경우 알고리즘은  과
과  의 가장 가까운 공통 조상
의 가장 가까운 공통 조상  까지 되추적한다.
까지 되추적한다.  을
을  쪽으로 가는 경로상에 있는
쪽으로 가는 경로상에 있는  의 자식 노드라고 하자. RBFS 는
의 자식 노드라고 하자. RBFS 는  을 루트로 하는 서브트리를 OPEN 에서 제거하고,
을 루트로 하는 서브트리를 OPEN 에서 제거하고,  의
의  값을 전달값으로 변경하여 OPEN 에 넣은 뒤, 최소의
값을 전달값으로 변경하여 OPEN 에 넣은 뒤, 최소의  값을 가지고 있는
값을 가지고 있는  에서부터 탐색을 계속한다.
에서부터 탐색을 계속한다.
이 알고리즘의 주요 개념을 그림 9 에 나타내었다.
탐색트리는 항상 하나의 경로와 그 경로상에 있는 노드들의 형제 (sibling) 노드들로만
구성된다. 따라서 메모리 요구량은 지금까지 탐색한 최상의 경로 길이에 선형적으로
비례하게 된다. 단말 (leaf) 노드들은 모두 OPEN 에 있으며, 탐색트리의 모든
노드들은 전달된  값을 가지고 있다.
값을 가지고 있다.

그림 9 재귀적 최상우선
탐색
휴리스틱 함수의 선택은 A* 의 효율성에
결정적인 영향을 미친다.  를 사용하면 허용성은 보장되지만 균일비용 탐색이 되어 일반적으로 효율성이
없다.
를 사용하면 허용성은 보장되지만 균일비용 탐색이 되어 일반적으로 효율성이
없다. 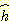 를
를 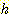 의 하한값 중에서 가장 큰 값으로 하면 허용성을 유지하면서 가장 적은 수의
노드들을 확장하게 된다. 예를 들어 8 퍼즐에서
의 하한값 중에서 가장 큰 값으로 하면 허용성을 유지하면서 가장 적은 수의
노드들을 확장하게 된다. 예를 들어 8 퍼즐에서  (
(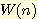 은 제자리에 있지 않은 타일 수) 은
은 제자리에 있지 않은 타일 수) 은 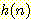 의 하한값이지만, 어떤 타일 배치의 난이도 (목표까지 남은 스텝 수) 에 대한
좋은 추정값을 제공하지는 못한다. 보다 나은 추정값은
의 하한값이지만, 어떤 타일 배치의 난이도 (목표까지 남은 스텝 수) 에 대한
좋은 추정값을 제공하지는 못한다. 보다 나은 추정값은  으로서,
으로서, 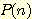 은 각 타일의 제자리로부터의 (중간의 타일들은 무시한) 맨하튼 거리 (Manhattan
distance) 의 합이다.
은 각 타일의 제자리로부터의 (중간의 타일들은 무시한) 맨하튼 거리 (Manhattan
distance) 의 합이다.
AI 의 초창기에 [Newell, Shaw, & Simon 1959, Newell
1964] 는 탐색을 안내하기 위해 계획을 작성하는 간단한 모델을 제시한 바 있다.
비슷한 개념을 좋은 휴리스틱 함수를 찾는 문제에 적용한 것이 [Gaschnig 1979] 와
[Pearl 1984, 4장] 에 기술되어 있다. 예를 들어, 타일의 이동에 대한 제한을 줄임으로써
8 퍼즐의 조건을 완화시킬 수 있다. 만일 각 타일이 목표 지점까지 직접 (한 스텝에)
움직일 수 있다고 하면, 목표 상태까지의 스텝 수는 제자리에 있지 않은 타일의 수,
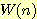 이 된다. 약간 덜 악화된 (그러므로 더 좋은) 모델은 타일들이 이미 다른 타일이
있더라도 인접한 자리의 목표 자리로부터의 거리의 합 P(n) 이 된다. 이러한 모델들은
사람이 직관적으로 추측하는
이 된다. 약간 덜 악화된 (그러므로 더 좋은) 모델은 타일들이 이미 다른 타일이
있더라도 인접한 자리의 목표 자리로부터의 거리의 합 P(n) 이 된다. 이러한 모델들은
사람이 직관적으로 추측하는 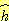 함수를 에이전트가 어떻게 자동적으로 계산해낼 수 있는가를 보여준다.
Pearl 은 타일이 빈자리로 한번에 이동할 수 있다는 모델을 사용하면
함수를 에이전트가 어떻게 자동적으로 계산해낼 수 있는가를 보여준다.
Pearl 은 타일이 빈자리로 한번에 이동할 수 있다는 모델을 사용하면 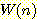 보다 약간 더 좋은
보다 약간 더 좋은 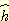 함수를 계산할 수 있다는 점을 지적하였다. 또 다른 조금 덜 완화된 모델은
타일이 인접한 자리를 따라 빈자리로 이동할 수 있다고 하는 것이다. 이때 인접한
한 자리로 움직이는 것을 한번의 이동으로 계산한다.
함수를 계산할 수 있다는 점을 지적하였다. 또 다른 조금 덜 완화된 모델은
타일이 인접한 자리를 따라 빈자리로 이동할 수 있다고 하는 것이다. 이때 인접한
한 자리로 움직이는 것을 한번의 이동으로 계산한다.
지도에서 길을 찾는 문제에서
유클리드 거리 (직선 거리) 를 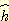 함수로 사용하는 것도 조건을 완화시킨 모델이라고 말할 수 있다. 존재하는
길을 따라 여행해야 하는 대신에, 완화된 모델에서의 여행자는 어느 도시로나 직선
거리로 직접 "이동" 할 수 있다. 완화된 모델에서의 답은 원래 문제에서의
답보다 절대값이 더 크지 않으므로, 이렇게 선택된
함수로 사용하는 것도 조건을 완화시킨 모델이라고 말할 수 있다. 존재하는
길을 따라 여행해야 하는 대신에, 완화된 모델에서의 여행자는 어느 도시로나 직선
거리로 직접 "이동" 할 수 있다. 완화된 모델에서의 답은 원래 문제에서의
답보다 절대값이 더 크지 않으므로, 이렇게 선택된 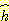 함수는 항상 허용 가능한 것이다! 이런 함수들은 또한 일관성이 있으며,
따라서 이런 함수들을 이용한 알고리즘은 이전에 확장했던 노드를 다시 방문할 필요가
없다.
함수는 항상 허용 가능한 것이다! 이런 함수들은 또한 일관성이 있으며,
따라서 이런 함수들을 이용한 알고리즘은 이전에 확장했던 노드를 다시 방문할 필요가
없다.
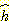 함수를 선택할 때는 그 함수를 계산하기 위해 얼마만큼의 노력이 필요한지를
반드시 고려해야 한다. 덜 완화된 모델일수록 일반적으로 계산하기는 어렵지만 더
좋은 휴리스틱 함수가 된다.
함수를 선택할 때는 그 함수를 계산하기 위해 얼마만큼의 노력이 필요한지를
반드시 고려해야 한다. 덜 완화된 모델일수록 일반적으로 계산하기는 어렵지만 더
좋은 휴리스틱 함수가 된다. 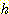 와 완전히 같은 휴리스틱 함수를 사용하면 확장하는 노드의 개수를 최소로 줄일
수 있으나, 그러한
와 완전히 같은 휴리스틱 함수를 사용하면 확장하는 노드의 개수를 최소로 줄일
수 있으나, 그러한 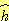 를 계산하려면 원래의 문제를 풀어야만 할 것이다. 일반적으로 정확한
를 계산하려면 원래의 문제를 풀어야만 할 것이다. 일반적으로 정확한
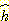 함수에 의해 얻어지는 이득과 그 함수를 계산하는 비용 사이에는 트레이드오프가
있다.
함수에 의해 얻어지는 이득과 그 함수를 계산하는 비용 사이에는 트레이드오프가
있다.
많은 경우에 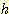 의 하한 (lower bound) 이 아닌
의 하한 (lower bound) 이 아닌 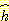 함수를 사용하면 허용성을 포기하는 대신 탐색의 효율성을 높일 수 있다.
즉, 최적임을 보장하는 경로보다 최적이 아닐 수도 있는 경로가 더 찾기 쉬운 것이다.
또한
함수를 사용하면 허용성을 포기하는 대신 탐색의 효율성을 높일 수 있다.
즉, 최적임을 보장하는 경로보다 최적이 아닐 수도 있는 경로가 더 찾기 쉬운 것이다.
또한 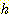 의 하한이 아닌
의 하한이 아닌 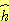 함수가 반드시 하한이 되는 함수보다 계산하기도 쉬울 수 있다. 확장되는
노드의 수도 줄어들고 (허용성은 없어지지만), 계산량도 줄어들기 때문이다.
함수가 반드시 하한이 되는 함수보다 계산하기도 쉬울 수 있다. 확장되는
노드의 수도 줄어들고 (허용성은 없어지지만), 계산량도 줄어들기 때문이다.
또
한 가지 가능성은 평가 함수에서 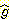 와
와 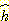 의 상대적인 가중치를 조정하는 것이다. 즉,
의 상대적인 가중치를 조정하는 것이다. 즉, 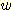 가 양수일 때
가 양수일 때  를 사용하는 것이다.
를 사용하는 것이다. 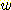 아주 큰 값이면 휴리스틱 요소가 강조되고,
아주 큰 값이면 휴리스틱 요소가 강조되고, 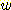 가 아주 작은 값이면 탐색이 너비우선 특성을 많이 갖게 된다. 실험에 의하면
가 아주 작은 값이면 탐색이 너비우선 특성을 많이 갖게 된다. 실험에 의하면
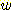 의 값을 노드의 깊이에 역비례하게 변화시키면 탐색의 효율이 높아지는 경우가
많다고 되어 있다. 깊이가 얕은 부분에서는 탐색이 휴리스틱 요소에 주로 의존하고,
깊이가 깊어지면 탐색이 점차 너비우선이 되어, 목표까지의 경로 중 하나가 결국
발견되는 것이다.
의 값을 노드의 깊이에 역비례하게 변화시키면 탐색의 효율이 높아지는 경우가
많다고 되어 있다. 깊이가 얕은 부분에서는 탐색이 휴리스틱 요소에 주로 의존하고,
깊이가 깊어지면 탐색이 점차 너비우선이 되어, 목표까지의 경로 중 하나가 결국
발견되는 것이다.

그림 10 양방향 탐색
시작 노드와 목표 노드 양쪽에서 동시에 탐색을
수행함으로써 탐색의 효율을 높일 수도 있을 것이다. 일반적으로 이러한 효율의 향상은
너비우선 탐색에서만 얻어질 수 있다. 너비우선 탐색이 양방향으로 수행되면 탐색의
전방이 시작과 목표 사이에서 만나게 될 것이며 (그림 10a 참조) 너비우선 양방향
탐색이 최적 경로를 찾는 것을 보장해 주는 종료 조건이 설정된 바 있다 [Pohl 1971].
그러나 휴리스틱 탐색이 시작과 목표 노드 양쪽에서 시작되는 경우, 만일 휴리스틱이
탐색을 옳지 않은 방향으로 인도하게 된다면, 두 탐색의 전방은 최적 경로에서 만나지
않을 수도 있다 (그림 10b 참조).
탐색의 효율성에 대한 유용한 기준 가운데 하나는
실질 분기 계수 (effective branching factor) 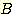 이다. 이것은 탐색 과정이 얼마나 정확하게 목표를 향해 집중되었는지를 나타낸다.
어떤 탐색이 길이가
이다. 이것은 탐색 과정이 얼마나 정확하게 목표를 향해 집중되었는지를 나타낸다.
어떤 탐색이 길이가 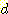 인 경로를 찾으면서 총
인 경로를 찾으면서 총 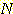 개의 노드를 생성했다고 하자.
개의 노드를 생성했다고 하자. 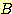 는 다음의 성질을 만족하는 트리에서의 각 노드의 자식 노드 수와 같다.
는 다음의 성질을 만족하는 트리에서의 각 노드의 자식 노드 수와 같다.
- 단말 노드가 아닌 각 노드는 같은 수
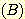 의 자식 노드를 가진다.
의 자식 노드를 가진다.
- 단말 노드의 깊이는 모두
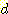 이다.
이다.
- 트리에 있는 노드의 총 수는
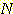 이다.
이다.
따라서 경로의 길이 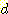 및 생성된 노드의 총 수
및 생성된 노드의 총 수 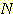 과
과 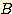 의 관계는 다음의 식으로 나타낼 수 있다.
의 관계는 다음의 식으로 나타낼 수 있다.
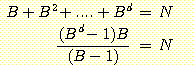

그림 11 여러 가지  값에 대한
값에 대한  대
대  그래프
그래프
 를
를  와
와 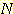 의 함수로 나타낼 수는 없지만, 다양한
의 함수로 나타낼 수는 없지만, 다양한  값에 대한
값에 대한 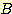 대
대 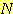 의 그래프를 그림 11 에 보였다. 1 에 근접한
의 그래프를 그림 11 에 보였다. 1 에 근접한 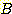 값은 탐색이 다른 방향으로 거의 분기되지 않고 목표를 향해 극도로 집중된 경우에
해당한다. 반대로, 여러 갈래가 있는 탐색 그래프는 높은
값은 탐색이 다른 방향으로 거의 분기되지 않고 목표를 향해 극도로 집중된 경우에
해당한다. 반대로, 여러 갈래가 있는 탐색 그래프는 높은 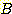 값을 갖는다.
값을 갖는다.
실질 분기 계수가 경로의 길이에 충분히 독립적인 이상, 이
자료를 이용하여 여러 경우의 탐색에서 얼마만큼의 노드가 생성될 것인지를 추정할
수 있다. 예를 들어, 그림 11 을 이용하여 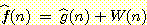 을 평가 함수로 이용하면 그림 2 에 있는 8 퍼즐의
을 평가 함수로 이용하면 그림 2 에 있는 8 퍼즐의 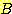 값이 1.2 라는 것을 계산할 수 있다. 30 스텝이 걸리는 더 복잡한 8 퍼즐 문제를
푸는 데 이 평가 함수를 이용하면 몇 개의 노드가 생성되는지를 추정하려 한다고
하자. 실질 분기 계수가 변하지 않는다고 가정하면, 그림 11 로부터 30 스텝이 걸리는
퍼즐은 약 2,000 개의 노드를 생성한다는 것을 알 수 있다.
값이 1.2 라는 것을 계산할 수 있다. 30 스텝이 걸리는 더 복잡한 8 퍼즐 문제를
푸는 데 이 평가 함수를 이용하면 몇 개의 노드가 생성되는지를 추정하려 한다고
하자. 실질 분기 계수가 변하지 않는다고 가정하면, 그림 11 로부터 30 스텝이 걸리는
퍼즐은 약 2,000 개의 노드를 생성한다는 것을 알 수 있다.
요약하면, 알고리즘
A* 의 효율에 영향을 미치는 중요한 요소는 세 가지가 있다.
- 발견된 경로의 값 (또는 길이)
- 경로를 발견할 때까지 확장된 노드의 수
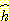 를 계산하는 시간
를 계산하는 시간
적절한 휴리스틱 함수를 선정해야만 이 요소들의
균형을 맞추어 탐색의 효율을 극대화시킬 수 있다.
휴리스틱 탐색을 포함하여
지금까지 이야기한 모든 탐색 방법들의 시간 복잡도 (time complexity) 는 생성되는
노드의 수를 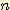 이라 할 때
이라 할 때 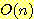 이다 (휴리스틱 함수는 일정한 시간 (constant time) 에 계산될 수 있다고 가정하였다).
특히, 실질 분기 계수가
이다 (휴리스틱 함수는 일정한 시간 (constant time) 에 계산될 수 있다고 가정하였다).
특히, 실질 분기 계수가 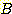 이고, 아크들의 값은 모두 같으며, 목표 노드는 시작 노드로부터 깊이
이고, 아크들의 값은 모두 같으며, 목표 노드는 시작 노드로부터 깊이 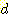 에 있다고 할 때, 너비우선 탐색의 시간 복잡도는
에 있다고 할 때, 너비우선 탐색의 시간 복잡도는 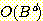 이다. 아크값들이 모두 다른 경우 균일비용 탐색
이다. 아크값들이 모두 다른 경우 균일비용 탐색  의 시간 복잡도는, 최적 해의 값이
의 시간 복잡도는, 최적 해의 값이 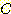 이고 아크의 최소값이
이고 아크의 최소값이  일 때,
일 때, 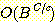 이다 [Korf 1992]. 많은 실제적인 문제들의
이다 [Korf 1992]. 많은 실제적인 문제들의 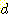 (또는
(또는 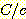 ) 값은 최적해의 탐색 (휴리스틱 탐색을 포함하여) 이 불가능할 정도로 크다.
예를 들어, 목표가 15번의 행동을 취해야 도달할 수 있는 거리에 있을 때 탐색을
이용하여 가장 좋은 다음 행동을 (가령 4 개의 가능한 행동 중에서) 찾는다면, 탐색
알고리즘은 약
) 값은 최적해의 탐색 (휴리스틱 탐색을 포함하여) 이 불가능할 정도로 크다.
예를 들어, 목표가 15번의 행동을 취해야 도달할 수 있는 거리에 있을 때 탐색을
이용하여 가장 좋은 다음 행동을 (가령 4 개의 가능한 행동 중에서) 찾는다면, 탐색
알고리즘은 약 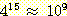 개의 노드를 확장해야 한다. 이런 긴 계산은 에이전트가 몇 분의 일초내에 판단을
내려야 하는 경우에는 실용적이지 못할 것이다. A* 의 공간 복잡도 (space
complexity) 도 확장된 모든 노드들이 트리 구조에 저장되어야 하기 때문에 시간
복잡도와 같다.
개의 노드를 확장해야 한다. 이런 긴 계산은 에이전트가 몇 분의 일초내에 판단을
내려야 하는 경우에는 실용적이지 못할 것이다. A* 의 공간 복잡도 (space
complexity) 도 확장된 모든 노드들이 트리 구조에 저장되어야 하기 때문에 시간
복잡도와 같다.
에이전트는 가지고 있는 자원에 대해 시간상 그리고 메모리상의
제한이 있을 것이므로, 많은 경우에 있어서 최적 해를 찾는 것이 불가능할 것이다.
이런 경우에는 최적은 아니지만 받아들일 수 있는 해 (만족한 (satisfying) 해라고도
한다) 또는 부분 해를 찾는 것으로 만족해야 한다. 계획, 행동 그리고 학습에서는
제한된 자원을 가지고 있는 에이전트가 사용할 수 있는 다양한 방법들을 소개할 것이다.
heuristic search 는 두 종류의 계산을 수행한다. 첫째로,
실제로 노드를 확장하고 경로 자체를 생성하는 객체 레벨 (object level) 의 계산이
있다. 둘째로, 다음에 어느 노드를 확장할 것인지를 결정하는 메타 레벨 (meta level)
의 계산이 있다. 객체 레벨은 실세계에서의 물리적인 행동에 관한 것이고, 메타 레벨은
그래프에서의 계산에 관한 것이다. 객체 레벨과 메타 레벨의 구분은 AI 에서 자주
등장한다. 이들은 [Stuart
Russell & Wefald 1991 (Russell, S., and Wefald, E., Do
the Right Thing, Cambridge, MA: MIT Press, 1991.). Do the Right Thing] 에 철저하게 논의되어 있으며, 계획,
행동 그리고 학습에서는 설명할 단축된 (abbreviated) 탐색 방법에 있어서 특히 중요한
역할을 수행한다.
타일 맞추기 문제는 많은 AI 연구자들에 의해 휴리스틱 탐색
방법을 시험하기 위한 테스트베드 (tastbed) 로 사용되어 왔다. [Doran & Michie
1966 (Doran, J., and Michie, D., "Experiments with the Graph Traverser
Program," Proc. Royal Society of London, vol. 294 (series A), pp.235-259,
1966.). Experiments with the Graph Traverse Program] 의 초기 논문이 8 퍼즐을 사용했고, 그 이후로 사람들이 그래프에서 경로를
찾는 과정에 평가 함수를 사용하기 시작했다.
1990 년에 Korf 는 "IDA*
로 15 퍼즐은 풀 수 있지만 그 이상의 퍼즐 (24 퍼즐 등) 은 현재의 컴퓨터로 처리할
수 없다" 고 하였다 [Korf 1990 ({Korf1990} Korf, R., "Real-Time
Heuristic Search," Artificial Intelligence}, 42, 1990.), Realtime Heuristic search]. 하지만 더 강력한 컴퓨터 (초당 백만
개의 노드를 생성할 수 있는 Sun Ultra Sparc 워크스테이션) 와 더 강력한 (자동적으로
찾아진) 휴리스틱을 사용하여 [Richard
Korf & Taylor 1996 (Korf, R., and Taylor, L., "Finding Optimal Solutions to the Twenty-Four
Puzzle," in Proceedings of the Thirteenth National Conference on Artificial
Intelligence (AAAI-96), pp.1202-1207, Menlo Park, CA: AAAI Press, 1996.). Optimal Solution to 24
puzzles] 는 무작위로 만들어낸 답이
있는 24 퍼즐 문제에 대한 최적해를 2 시간 15 분에서 1 개월 사이의 시간에 찾아낼
수 있었다. [Richard
Korf 1997 (Korf, R., "Finding Optimal
Solutions to Rubik's Cube Using Pattern Databases," in Proceedings of
the Fourteenth National Conference on Artificial Intelligence (AAAI-97),
nl pp.700-705, Menlo Park, CA: AAAI Press, 1997.). Optimal Solution to Rubik's Cube Using Pattern Databases] 는 IDA* 를 3 × 3 × 3 루빅스 큐브
(Rubik's Cube) 퍼즐의 최적 해를 찾는 데도 적용하였다.
탐색 기법들을 시험하고
개선하기 위하여 퍼즐들이 유용하게 사용되어 왔지만, A* 와 기타 휴리스틱
탐색 방법들은 많은 실제 문제에도 성공적으로 적용되어 왔다. 휴리스틱 함수를
찾기 위한 완화된 모델에 대하여 더 자세한 내용은 [Mostow & Prieditis
1989 (Mostow, J., and Prieditis, A.,
"Discovering Admissible Heuristics by Abstracting and Optimizing: A Transformational
Approach," in Proceedings of the Eleventh International Joint Conference
on Artificial Intelligence (IJCAI-89), pp.701-707, San Francisco: Morgan
Kaufmann, 1989.), Prieditis 1993 (Prieditis, A, "Machine Discovery of Effective
Admissible Heuristics," Machine Learning, 12(1-3):117-141, 1993.)] 에 나와 있다. [Pohl 1973
(Pohl, I., "The Avoidance of (Relative) Catastrophe,
Heuristic Competence, Genuine Dynamic Weighting and Computational Issues in
Heuristic Problem~Solving," in Proceedings of the Third International
Joint Conference on Artificial Intelligence (IJCAI-73), pp.20-23, San Francisco:
Morgan Kaufmann, 1973.)] 은 의 휴리스틱 요소에 대한 가중치를 조정하는 실험을 수행하였다.
휴리스틱
탐색에 대한 가장 고전적인 책은 [Judea
Pearl 1984 (Pearl, J., Heuristics: Intelligent Search Strategies for Computer Problem
Solving, Reading, MA: Addison-Wesley, 1984.). Heuristics Intelligent Search Strategies...] 이다. [Laveen
N. Kanal & Kumar 1988
(Kanal, L., and Kumar, V. (eds.), Search in Artificial Intelligence,
Berlin: Springer-Verlag, 1988.).
Search in AI] 은
탐색에 관한 논문들을 모아놓은 책이다. 이 책의 첫 번째 논문은 AI 와 OR (operations
research) 연구자들에 의해 각각 독립적으로 개발된 탐색 방법들을 하나로 통일시킬
것을 제안하고 있다.
 이 있다고 가정하자 (
이 있다고 가정하자 ( 위에 "hat" 을 붙인 이유는 나중에 알 게 된다.
위에 "hat" 을 붙인 이유는 나중에 알 게 된다.  는
는  -hat 이라고 읽는다.
-hat 이라고 읽는다.  값이 작은 것이 더 좋은 노드를 나타내는 것이라고 하자. 이 함수는 특정 문제
영역에 대한 정보를 기반으로 하는 것이다. 이 함수는 각 상태 표현에 대해 실수값을
갖는다.
값이 작은 것이 더 좋은 노드를 나타내는 것이라고 하자. 이 함수는 특정 문제
영역에 대한 정보를 기반으로 하는 것이다. 이 함수는 각 상태 표현에 대해 실수값을
갖는다. 값이 가장 작은 노드를 다음에 확장할 노드로 선택한다. 같은 값을 갖는 노드들은
무작위로 선택한다 (이 장에서는 노드를 확장하면 그 노드의 모든 자식 노드가
생성된다고 하자).
값이 가장 작은 노드를 다음에 확장할 노드로 선택한다. 같은 값을 갖는 노드들은
무작위로 선택한다 (이 장에서는 노드를 확장하면 그 노드의 모든 자식 노드가
생성된다고 하자). 만으로 구성된 탐색트리
만으로 구성된 탐색트리  을 만든다.
을 만든다.  을 순서 있는 리스트인 OPEN 에 넣는다.
을 순서 있는 리스트인 OPEN 에 넣는다. 이라고 한다.
이라고 한다.  이 목표 노드이면
이 목표 노드이면  의 아크를 따라
의 아크를 따라  에서
에서  으로 거꾸로 경로를 추적하여 답을 얻고 끝난다 (아크는 단계 6 에서 만든다).
으로 거꾸로 경로를 추적하여 답을 얻고 끝난다 (아크는 단계 6 에서 만든다). 을 확장하여 자식 노드들의 집합
을 확장하여 자식 노드들의 집합  을 만든다.
을 만든다.  으로부터
으로부터  의 각 원소로 아크를 만들어
의 각 원소로 아크를 만들어  의 자식 노드들을
의 자식 노드들을  에 넣는다.
에 넣는다. 의 자식 노드들을 OPEN 에 넣고 휴리스틱값의 순서 또는 다른 어떤 임의의
순서에 따라 OPEN 을 재정렬한다.
의 자식 노드들을 OPEN 에 넣고 휴리스틱값의 순서 또는 다른 어떤 임의의
순서에 따라 OPEN 을 재정렬한다. 을 확장하여 자식 노드들의 집합
을 확장하여 자식 노드들의 집합  을 만든다.
을 만든다.  으로부터
으로부터  의 각 원소로 아크를 만들어
의 각 원소로 아크를 만들어  의 자식 노드들을
의 자식 노드들을  에 넣는다.
에 넣는다. 을 확장하여 자식 노드 중
을 확장하여 자식 노드 중  에서
에서  의 조상이 아닌 노드들의 집합
의 조상이 아닌 노드들의 집합  을 만든다.
을 만든다.  으로부터
으로부터  의 각 원소로 아크를 만들어
의 각 원소로 아크를 만들어  의 자식 노드들을
의 자식 노드들을  에 넣는다.
에 넣는다.  만으로 구성된 탐색 그래프
만으로 구성된 탐색 그래프  을 만든다.
을 만든다.  을 리스트 OPEN 에 넣는다.
을 리스트 OPEN 에 넣는다. 이라고 한다.
이라고 한다.  이 목표 노드이면
이 목표 노드이면  의 포인터를 따라
의 포인터를 따라  에서
에서  으로 경로를 추적하여 답을 얻고 끝난다 (이 포인터를 탐색트리를 정의하는 것으로
단계 7 에서 만든다).
으로 경로를 추적하여 답을 얻고 끝난다 (이 포인터를 탐색트리를 정의하는 것으로
단계 7 에서 만든다). 을 확장하여 자식 노드 중
을 확장하여 자식 노드 중  에서
에서  의 조상이 아닌 노드들의 집합
의 조상이 아닌 노드들의 집합  을 만든다.
을 만든다.  의 각 원소로
의 각 원소로  의 자식 노드들로
의 자식 노드들로  에 넣는다.
에 넣는다. 에 있지 않은 (즉, OPEN 이나 CLOSED 에 있지 않은)
에 있지 않은 (즉, OPEN 이나 CLOSED 에 있지 않은)  의 각 원소들로부터
의 각 원소들로부터  으로 포인터를 만든다.
으로 포인터를 만든다.  의 이 원소들을 OPEN 에 넣는다. 이미 OPEN 이나 CLOSED 에
있는
의 이 원소들을 OPEN 에 넣는다. 이미 OPEN 이나 CLOSED 에
있는  의 각 원소
의 각 원소  에 대해서는, 지금까지 찾아진
에 대해서는, 지금까지 찾아진  까지의 최단 경로가
까지의 최단 경로가  을 지나오는 것이라면 포인터를
을 지나오는 것이라면 포인터를  으로 변경한다. 이미 CLOSED 에 있는
으로 변경한다. 이미 CLOSED 에 있는  의 각 원소에 대해서는, 모든 후손 노드의 포인터를 지금까지 찾아진 최단경로를
가리키도록 변경한다.
의 각 원소에 대해서는, 모든 후손 노드의 포인터를 지금까지 찾아진 최단경로를
가리키도록 변경한다. 값의 오름차순으로 OPEN 을 재정렬한다 (
값의 오름차순으로 OPEN 을 재정렬한다 ( 값이 같은 경우에는 탐색트리에서 깊이 있는 노드를 우선한다).
값이 같은 경우에는 탐색트리에서 깊이 있는 노드를 우선한다). 보다 큰 값을 갖는다.
보다 큰 값을 갖는다. 에 대한 조건은 다음과 같다.
에 대한 조건은 다음과 같다. 에 대하여
에 대하여  이다. 즉
이다. 즉  는 절대 실제 값
는 절대 실제 값  를 넘지 않는다 (이러한
를 넘지 않는다 (이러한  함수를 낙관적 추정자 (optimistic estimator) 라고도 한다).
함수를 낙관적 추정자 (optimistic estimator) 라고도 한다). 만이 확장을 위해 선택됐을 때) 노드
만이 확장을 위해 선택됐을 때) 노드  은 OPEN 에 있으며, 목표까지의 최적 경로상에 있고, A* 는
은 OPEN 에 있으며, 목표까지의 최적 경로상에 있고, A* 는
 까지의 최적 경로를 찾은 상태이다. 또한
까지의 최적 경로를 찾은 상태이다. 또한  이므로
이므로  가 성립된다. 따라서 노드
가 성립된다. 따라서 노드  이 보조정리의
이 보조정리의  에 해당된다.
에 해당된다. 개의 노드
개의 노드  가 확장된 상태에서 참이라고 가정하고,
가 확장된 상태에서 참이라고 가정하고,  개의 노드가 확장되었을 때도 참임을 증명한다. 귀납 단계를 증명하는 동안 그림
5 를 참고하면 도움이 될 것이다.
개의 노드가 확장되었을 때도 참임을 증명한다. 귀납 단계를 증명하는 동안 그림
5 를 참고하면 도움이 될 것이다. 가 OPEN 에 있는 노드로써 A* 가
가 OPEN 에 있는 노드로써 A* 가  개의 노드를 확장한 후에 찾아진 최적 경로상에 있는 노드라고 가정하자. 만일
개의 노드를 확장한 후에 찾아진 최적 경로상에 있는 노드라고 가정하자. 만일
 번째 단계에서
번째 단계에서  가 확장되지 않는다면 (그림 5a),
가 확장되지 않는다면 (그림 5a),  는 전과 같은 특성을 그대로 가지고 있으므로 이 경우에는 귀납 단계가 증명된다.
만일
는 전과 같은 특성을 그대로 가지고 있으므로 이 경우에는 귀납 단계가 증명된다.
만일  가 확장된다면 (그림 5b),
가 확장된다면 (그림 5b),  의 모든 자식 노드들이 OPEN 에 들어가고, 이들 중 적어도 하나의 노드
의 모든 자식 노드들이 OPEN 에 들어가고, 이들 중 적어도 하나의 노드
 는 목표까지의 최적 경로상에 있을 것이다 (최적 경로는
는 목표까지의 최적 경로상에 있을 것이다 (최적 경로는  를 지나간다고 가정했고, 적어도 하나의 자식 노드로 이어질 것이므로). 그리고
A* 는
를 지나간다고 가정했고, 적어도 하나의 자식 노드로 이어질 것이므로). 그리고
A* 는  까지의 최적 경로를 찾은 것이다. 왜냐하면
까지의 최적 경로를 찾은 것이다. 왜냐하면  까지 더 나은 경로가 있다면 그 경로는 목표까지도 더 나은 경로가 되기 때문이다
(이것은 A* 가 찾은
까지 더 나은 경로가 있다면 그 경로는 목표까지도 더 나은 경로가 되기 때문이다
(이것은 A* 가 찾은  을 통과하는 경로보다 더 나은 경로는 없다는 가정에 위배된다). 따라서 이 경우에는
을 통과하는 경로보다 더 나은 경로는 없다는 가정에 위배된다). 따라서 이 경우에는
 를
를  번째 단계에서 새로운
번째 단계에서 새로운  라고 하면
라고 하면  라는 특성을 제외하고는 귀납 단계가 모두 증명된 것이다.
라는 특성을 제외하고는 귀납 단계가 모두 증명된 것이다. 에 대하여 증명하자. 최적 경로상에 있고, A* 가 그 노드까지의 최적
경로를 찾은 모든 노드
에 대하여 증명하자. 최적 경로상에 있고, A* 가 그 노드까지의 최적
경로를 찾은 모든 노드  에 대하여 다음이 성립한다.
에 대하여 다음이 성립한다. (정의에 의해)
(정의에 의해) (
( 이고
이고  이므로)
이므로) (정의에
의해
(정의에
의해  이므로)
이므로) (
( 가 최적 경로상에 있으므로
가 최적 경로상에 있으므로  )
) 보다 크기 때문에, OPEN 에 있는 모든 노드의
보다 크기 때문에, OPEN 에 있는 모든 노드의  (따라서
(따라서  도) 값이 결국
도) 값이 결국  를 넘게 된다. 하지만 이것은 보조정리에 위배된다.
를 넘게 된다. 하지만 이것은 보조정리에 위배된다. 인 최적 목표
인 최적 목표  이 있을 때, 탐색이
이 있을 때, 탐색이  인 최적이 아닌 목표
인 최적이 아닌 목표  를 찾고 종료한다고 하자 (그림 5 참조).
를 찾고 종료한다고 하자 (그림 5 참조).  에서 탐색이 종료되었을 때,
에서 탐색이 종료되었을 때,  가 된다. 그러나 보조정리에 의하여 A* 가
가 된다. 그러나 보조정리에 의하여 A* 가  를 확장하기 직전에
를 확장하기 직전에  인 최적 경로상의 노드
인 최적 경로상의 노드  가 OPEN 에 있었을 것이다. 그런데 A* 는 항상
가 OPEN 에 있었을 것이다. 그런데 A* 는 항상  값이 최소인 노드를 선택하며,
값이 최소인 노드를 선택하며,  이므로, 탐색과정에서
이므로, 탐색과정에서  가 먼저 선택될 수는 없다.
가 먼저 선택될 수는 없다. 에 대한 일관성 조건이 만족된다면, A* 가 어떤 노드
에 대한 일관성 조건이 만족된다면, A* 가 어떤 노드  을 확장하면
을 확장하면  까지의 최적 경로가 이미 발견된 것이다.
까지의 최적 경로가 이미 발견된 것이다. 에서 시작 노드
에서 시작 노드  부터 목표 노드까지의 최적 경로를 탐색하는 데 있어서 어떤 노드
부터 목표 노드까지의 최적 경로를 탐색하는 데 있어서 어떤 노드  을 막 확장하려 한다고 하자.
을 막 확장하려 한다고 하자. 를
를  에서
에서  까지의 최적 경로를 구성하는 노드 열 (sequence) 이라고 하자.
까지의 최적 경로를 구성하는 노드 열 (sequence) 이라고 하자.  이
이  중에서 A* 가 마지막으로 확장한 노드라고 하자 (그림 8을 보라).
중에서 A* 가 마지막으로 확장한 노드라고 하자 (그림 8을 보라).
 이
이  중에서 마지막으로 확장된 노드이므로,
중에서 마지막으로 확장된 노드이므로,  은 OPEN 에 있을 것이고, 따라서 다음 번에 확장될 후보 중 하나일 것이다.
은 OPEN 에 있을 것이고, 따라서 다음 번에 확장될 후보 중 하나일 것이다. (
( 까지의 최적 경로) 에 있는 모든 노드
까지의 최적 경로) 에 있는 모든 노드  와 그 자식 노드
와 그 자식 노드  에 대해서
에 대해서  이고,
이고,  이다.
이다. 관계의 이행성 (transitivity) 에 의하여,
관계의 이행성 (transitivity) 에 의하여,  인
인  상의 모든
상의 모든  와
와  에 대하여
에 대하여
 까지의 최적 경로를 찾았으므로
까지의 최적 경로를 찾았으므로  이라 하면
이라 하면
 이 아닌 노드
이 아닌 노드  을 확장하려고 하므로 다음이 성립할 것이다.
을 확장하려고 하므로 다음이 성립할 것이다.

 를 계산하는 방법에 따르면
를 계산하는 방법에 따르면  이므로,
이므로,  이다.
이다. 이거나, 또는 이미 노드
이거나, 또는 이미 노드  까지의 다른 최적 경로를 찾았어야만 함을 보였으며, 증명이 완료되었다.
까지의 다른 최적 경로를 찾았어야만 함을 보였으며, 증명이 완료되었다. 에 단조성이 있으므로 탐색은
에 단조성이 있으므로 탐색은  값이 증가하는 방향으로 등심선을 따라 진행한다.
값이 증가하는 방향으로 등심선을 따라 진행한다. 값을 갖는 목표 노드가 될 것이다.
값을 갖는 목표 노드가 될 것이다. 에 대하여
에 대하여  이다 (만일
이다 (만일  함수가 일관성이 있으면, 그 값은 또한 실제
함수가 일관성이 있으면, 그 값은 또한 실제  함수값을 넘지 않는다는 사실[Pearl 1984, p.83] 을 이용하였다).
함수값을 넘지 않는다는 사실[Pearl 1984, p.83] 을 이용하였다). 값을 갖는 목표 노드가 될 것이다.
값을 갖는 목표 노드가 될 것이다. 가 확장되면
가 확장되면  까지의 최적 경로가 이미 발견된 것이다. 즉
까지의 최적 경로가 이미 발견된 것이다. 즉  이다.
이다.