
적대 탐색
(Adversarial Search)
인공지능-지능형 에이전트를 중심으로 : Nils J.Nilsson 저서, 최중민. 김준태. 심광섭. 장병탁 공역, 사이텍미디어, 2000 (원서 : Artificial Intelligence : A New Synthesis 1998), Page 205~223
최대최소 방법 (The Minimax Procedure)
알파 베타 방법 (The Alpha-Beta Procedure)
알파 베타 방법의 탐색 효율 (The Search Efficiency of the Alpha-Beta Procedure)
기타 중요한 사항들 (Other Important Matters)
평가 함수의 학습 (Learning Evaluation Functions)
참고문헌 및 토론 (Additional Readings and Discussion)
계획, 행동 그리고 학습에서 어려운 문제 중 하나는 다른 능동적인 에이전트들이 존재하는 환경에서 계획하고 행동하는 것이다. 다른 에이전트들이 어떻게 행동할 것인지에 대한 지식이 없다면, 예측 불가능한 미래에 대해 멀리 계획하지 않고 감지/계획/행동(sense/plan/act) 구조를 사용할 수밖에 없다. 그러나 그러한 지식이 있다면, 에이전트는 다른 에이전트들의 행동 결과를 명시적으로 고려하는 계획을 수립할 수 있다. 두 개의 에이전트가 있는 특수한 경우를 생각해 보자. 이들이 서로 상대방의 행동을 고려할 수 있는 이상적인 설정은 에이전트의 행동이 서로 번갈아 일어나는 것이다. 우선 한 에이전트가 행동하고, 다음 다른 에이전트가 행동하는 식으로 진행하는 것을 말한다.
예를 들어 그림 1 에 있는 격자 공간을 생각해 보자. "흑" 과 "백" 이라는 이름의 두 로봇은 각자 행과 열의 인접한 칸으로 이동할 수 있다. 이들은 번갈아 가며 이동하고 (예를 들어 흑이 먼저 이동하고 이어서 백이 이동한다), 자기 차례가 되면 반드시 이동해야 한다. 백의 목표는 흑과 같은 칸에 위치하는 것이라고 하자. 흑의 목표는 그것을 막는 것이다. 백은 하나 건너마다의 단계에서 흑의 이동도 고려하는 탐색트리를 만들어 계획을 수립할 수 있을 것이다. 이런 탐색트리의 일부를 그림 2 에 나타내었다.
그림 1 격자 공간에서의 두 로봇

그림 2 두 로봇의 행동에 대한 탐색트리
최상의 첫 번째 행동을 선택하기 위해서 백은 가능한 결과를 알아내기 위해 흑이 백의 목표를 저지하는 방향으로 행동할 것이라는 것을 고려하면서 트리를 분석해야 한다. 이와 같이 대립하는 상황하에서 어떤 경우에는 한 에이전트가 상대방 에이전트가 다음에 어떤 행동을 하더라도 자신의 목표를 이룰 수 있는 상태로 가는 행동을 찾을 수도 있다. 일반적으로는, 메모리와 시간상의 제한 때문에 어느 에이전트도 자신의 성공을 보장하는 행동을 찾을 수 없다. 이러한 경우에 대하여는 휴리스틱하게 적절한 행동을 찾는데 유용한 시계 제한 (limited-horizon) 탐색 방법을 사용할 것이다. 어느 경우든 에이전트는 첫 번째 행동을 결정한 다음, 그 행동을 실행하고, 상대 에이전트가 어떤 행동을 취했는지를 인식한 다음, 감지/계획/행동 형식으로 계획 과정을 반복한다.
여기에 제시한 격자 공간 문제는 두 에이전트 (two-agent), 완전 정보 (perfect information), 제로섬 (zero-sum) 게임이라는 문제의 한 예이다. 여기서 다룰 형태에서는 플레이어 (player) 라고 하는 두 개의 에이전트가 둘 중 하나가 이기거나 (따라서 다른 쪽이 지거나) 또는 비길 때까지 번갈아 행동한다. 각 플레이어는 환경과 자신에 관한 완전한 모델과 상대방의 가능한 행동 및 그 결과에 대한 완전한 모델을 가지고 있다 (물론 어느 쪽도 상대방이 어떤 상황에서 실제로 무슨 행동을 할 것인지에 대해 완벽한 지식을 가지고 있는 것은 아니다). 이런 종류의 게임에 대한 연구를 수행함으로써, 에이전트 사이의 목표가 상호 충돌하지 않더라도, 다수의 에이전트가 있는 상황에서 계획을 수립하는 보다 일반적인 문제에 대해 통찰할 수 있다.
체스 (chess) 나 체커 (checker), 바둑 등 일반적인 게임들이 이 범주에 들어간다는 것을 알 수 있을 것이다. 실제로 이러한 게임을 할 수 있는 프로그램들이 만들어져 있으며, 어떤 경우에는 챔피언 수준의 능력을 가진 것도 있다. Tic-Tac-Toe 게임은 흥미 있는 계산 문제는 아니지만, 단순하기 때문에 탐색 기법을 설명하는 데 아주 유용하므로 이 게임을 사용할 것이다. 어떤 게임들은 (Backgammon 과 같은) 확률적인 요소가 포함되어 분석하기가 더 어렵다. 많은 게임들, 특히 체스와 같이 판 위에서 하는 게임들의 상태공간을 설정하는 데는 아이콘 표현이 자연스럽다. 8 × 8 격자 공간에서 흑과 백 두 로봇의 다양한 위치를 표현하기 위하여 8 × 8 배열을 사용한 바 있다. 게임에서의 행동은 한 상태 표현을 다른 상태 표현으로 바꾸는 연산자에 의해 나타내어진다. 게임 그래프는 시작 노드와 각 플레이어의 연산자에 의하여 암시적으로 정의된다. 첫 번째 행동을 선택하는 데는 여러 가지 기법이 사용될 수 있지만, 탐색트리를 만드는 것은 이전에 했던 것과 같은 방법으로 할 수 있다. 이제 이러한 기법들을 설명하겠다.
게임에 대한 지금부터의 설명에서는 두 플레이어를
MAX 와 MIN 이라고 할 것이다. 주어진 임무는 MAX 가 먼저
행동하고나서 두 플레이어가 번갈아 행동한다고 가정하자. 따라서 깊이가 짝수이면
MAX 가 행동할 차례에 해당한다. 이들을 MAX 노드라고 한다. 깊이가
홀수이면 MIN 이 행동할 차례에 해당한다. 이들을 MIN 노드라고
한다. 깊이가 홀수이면 MIN 이 행동할 차례에 해당하며 이들을 MIN
노드라고 한다 (게임트리의 제일 위 노드가 깊이 0 이다). 게임 트리에서 겹 깊이
(ply-depth)  의 한 겹 (ply) 은 깊이
의 한 겹 (ply) 은 깊이  와
와  에 있는 노드들로 정의된다. 게임트리에서의 탐색 범위는 보통 앞을 미리 보는
정도를 MAX 와 MIN 의 행동 쌍을 단위로 하여 나타낸 겹 깊이로
표현된다.
에 있는 노드들로 정의된다. 게임트리에서의 탐색 범위는 보통 앞을 미리 보는
정도를 MAX 와 MIN 의 행동 쌍을 단위로 하여 나타낸 겹 깊이로
표현된다.
이미 언급한 대로, 대부분의 게임에서 완전한 탐색 (승패에 대한) 은 실질적으로 불가능하다. 체스의 경우 완전한 게임 그래프에는 1040 개의 노드가 있는 것으로 추정된다. 자식 노드들을 1/3 나노 초마다 하나씩 생성할 수 있다고 가정해도 체스에 대한 완전한 탐색 그래프를 만들어내는 데는 약 1022 세기가 걸린다 (참고로, 우주의 나이는 약 108 세기로 추정된다). 더욱이, 휴리스틱 탐색 기법도 실질적인 분기 계수를 도움이 될 만큼 충분히 줄이지는 못한다. 따라서 복잡한 게임에 있어서는 게임의 끝까지 탐색한다는 것은 (게임의 마지막 부분에서는 가능할 수도 있지만) 불가능하다는 것을 받아들여야만 한다. 대신 계획, 행동 그리고 학습에서 설명한 시계 제한 (limited-horizon) 탐색과 같은 방법을 사용해야 한다.
종료 조건이 바뀌어야 한다는 것을 제외하고는 깊이우선이나 너비우선 또는 휴리스틱 방법 등을 사용할 수 있다. 몇 가지 인위적인 종료 조건이 시간 제한, 메모리 제한, 또는 탐색트리에서 노드의 깊이에 대한 제한 등을 기반으로 정해질 수 있다. 또한 예를 들어 체스 같은 게임에서는 만일 경계에 있는 노드가 즉각적으로 유리한 교환을 할 수 있는 라이브 (live) 위치를 표현하고 있다면 탐색을 중단하지 않는 것이 일반적이다.
탐색이 끝나면 탐색트리로부터 최상이라고 추정되는 행동을 찾아내야 한다. 이러한 추정값은 탐색트리의 단말 (leaf) 노드에 정적 평가 함수 (static evaluation function) 를 적용하여 얻을 수 있다. 평가 함수는 단말 노드의 가치를 계산한다. 이러한 계산은 노드의 가치에 영향을 미친다고 생각되는 다양한 특징을 기반으로 이루어진다. 예를 들어 체스에서 유용한 특징들은 상대적인 말의 이점, 중심의 제어권, 킹에 의한 중심의 제어 여부 등을 들 수 있다. 게임트리를 분석할 때 MAX 에 유리한 상태에서는 평가 함수값이 양수, MIN 에 유리한 상태에서는 평가 함수값이 음수, 그리고 MAX 나 MIN 어느 편에 특별히 유리하지 않은 상태에서는 0 에 가까운 값을 갖도록 하는 것이 보통이다.
좋은 첫 번째 행동은 최대최소 절차 (minimax procedure) 라고 하는 방법에 의해 선정될 수 있다 (단순화하기 위해서 게임 그래프가 트리인 것으로 가정하고 관련된 절차들을 설명한다). 만일 MAX 가 탐색트리의 단말 노드 중에서 하나를 선택한다면 평가 값이 가장 큰 것을 선호한다고 가정하자. MAX 는 자신의 차례가 되면 실제로 그 노드를 선택할 것이기 때문에 MIN 단말 노드의 부모 노드인 MAX 노드의 전달값 (backed-up value) 은 단말 노드들에 대한 평가값 중 최대값이 된다. 반대로 만일 MIN 이 단말 노드 중에서 하나를 선택한다면 가장 작은 값 (음수로 가장 큰 값) 을 가진 노드를 선택할 것이다. MIN 은 자신의 차례가 되면 실제로 그 노드를 선택할 것이기 때문에 MAX 단말 노드의 부모 노드인 MIN 노드는 단말 노드들에 대한 평가값 중 최소값을 전달값으로 받게 된다. 모든 단말 노드의 부모 노드들에 전달값이 지정된 다음에는, MAX 는 자식 MIN 노드들 중에서 전달값이 최대인 노드를 선택하고, MIN 은 자식 MAX 노드들 중에서 전달값이 최소인 노드를 선택한다는 가정하에서 이 값들을 한 단계 위로 다시 전달한다.
이 전달 과정을 시작 노드의 자식 노드들이 모두 전달값을 받게 될 때까지 한 단계씩 진행한다. 시작은 MAX 의 차례라고 가정하였으므로, MAX 는 가장 큰 전달값을 가진 자식 노드에 해당하는 행동을 선택한다.
이와 같은 과정의 정당성은 시작 노드의 자식들로부터 전달되는 값들이 각 상황에 대하여 직접적으로 정적 평가 함수를 적용하여 계산하는 것보다 궁극적인 가치를 좀 더 정확하게 나타낸다는 가정하에서 성립되는 것이다. 결국 전달값이라는 것은 게임트리에서 앞을 내다보는 것을 기반으로 하고 있기 때문에, 보다 중요하다고 여겨지는 게임의 끝 부분에 더 가까운 상황에서의 특징들에 의지하는 것이다.
Tic-Tac-Toe
게임을 이용한 간단한 예로 최대최소 방법을 설명한다 (Tic-Tac-Toe 는 번갈아 가면서
3 × 3 배열에 표시를 하는 게임이다. 한 사람은 X 를 표시하고, 상대방은 0 를
표시한다. 행이나 열, 또는 대각선을 먼저 자신의 표시로 채운 사람이 이긴다). MAX
가 X 를 표시하고, MIN 은 0 를 표시하며, MAX 가 먼저 시작한다고
가정하자. 깊이 제한이 2 인 경우, 레벨 2 의 모든 노드가 생성될 때까지 너비우선
탐색을 수행한 다음, 이들 노드에 대하여 정적 평가 함수를 적용한다. 상태  에 대한 평가 함수
에 대한 평가 함수  가 다음과 같이 주어진다고 하자.
가 다음과 같이 주어진다고 하자.
만일  가 양쪽 모두에게 이기는 상태가 아니라면,
가 양쪽 모두에게 이기는 상태가 아니라면,
 = (MAX 에게 가능한 행, 열, 대각선의 수) - (MIN 에게 가능한
행, 열, 대각선의 수)
= (MAX 에게 가능한 행, 열, 대각선의 수) - (MIN 에게 가능한
행, 열, 대각선의 수)
만일  가 MAX 가 이기는 상태라면,
가 MAX 가 이기는 상태라면,
 (
( 는 아주 큰 양수를 의미함)
는 아주 큰 양수를 의미함)
만일  가 MIN 이 이기는 상태라면,
가 MIN 이 이기는 상태라면,

즉, 만일  가 다음과 같다면,
가 다음과 같다면,
|
|
0 |
|
|
|
x |
|
|
|
|
|
 가 된다.
가 된다.
자식 노드들을 생성할 때는 대칭성을 고려한다. 그러면 다음의 상태들은 모두 동일한 것으로 간주된다.
|
0 |
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
x |
|
|
|
x |
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
0 |
|
|
|
(게임 초기에는 대칭성 때문에 분기 계수가 작게 되고, 나중에는 가능한 상태가 적기 때문에 분기 계수가 작게 된다.)
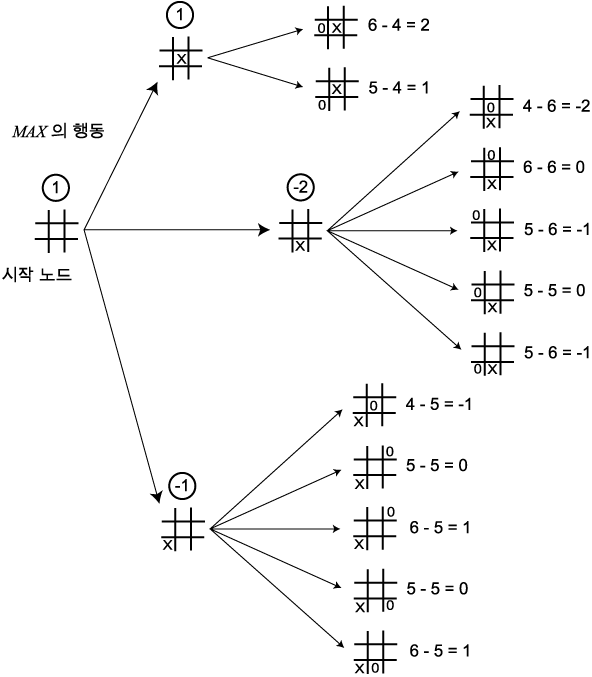
그림 3 Tic-Tac-Toe 탐색의 첫 번째 단계
그림 3 에 깊이 2 까지 탐색했을 때 생성되는 트리를 나타내었다. 정적 평가값은 단말 노드의 오른쪽에 나와 있고, 전달된 값들은 동그라미 안에 있다. 아래의 상태가 가장 큰 전달값을 가지고 있으므로, 이 상태로 가는 것이 첫 번째 행동으로 선택된다.
|
|
|
|
|
|
x |
|
|
|
|
|
(우연히도, 이것은 완전한 탐색이 수행되어도 역시
MAX 의 최상의 행동이다.)
이제 감지/계획/행동 주기에 따라 MAX
가 위의 행동을 취하고 MIN 은 여기에 대해 X 의 왼편에 0 를 표시했다고
하자 (이것은 서투른 행동으로, MIN 은 좋은 탐색 전략을 가지고 있지 않은
것이 틀림없다). 그 아래로 깊이 2 만큼 다시 MAX 가 탐색을 수행하고, 그
결과 그림 4 에 있는 것과 같은 탐색트리가 만들어진다. 여기서는 두 가지의 최상의
행동이 가능하다. MAX 가 그림에 표시된 행동을 취했다고 하자. MIN
은 다음과 같이 즉각적인 패배를 피할 수 있는 행동을 할 것이다.
|
0 |
|
|
|
0 |
x |
|
|
|
|
x |
MAX 는 탐색을 다시 수행하여 그림 5 와
같은 트리를 생성한다.
이 트리의 일부 단말 노드는 (예를 들어  라고 표시된 노드) MIN 이 이기는 경우이며 따라서 평가값이
라고 표시된 노드) MIN 이 이기는 경우이며 따라서 평가값이  이다. 이 평가값들이 전달되면, MAX 의 최상의 행동도 역시 즉각적인
패배를 피하는 것이라는 것을 알 수 있다. 이제 MIN 은 다음 번에 MAX
가 무조건 이긴다는 것을 알 수 있고, 따라서 MIN 은 항복한다.
이다. 이 평가값들이 전달되면, MAX 의 최상의 행동도 역시 즉각적인
패배를 피하는 것이라는 것을 알 수 있다. 이제 MIN 은 다음 번에 MAX
가 무조건 이긴다는 것을 알 수 있고, 따라서 MIN 은 항복한다.
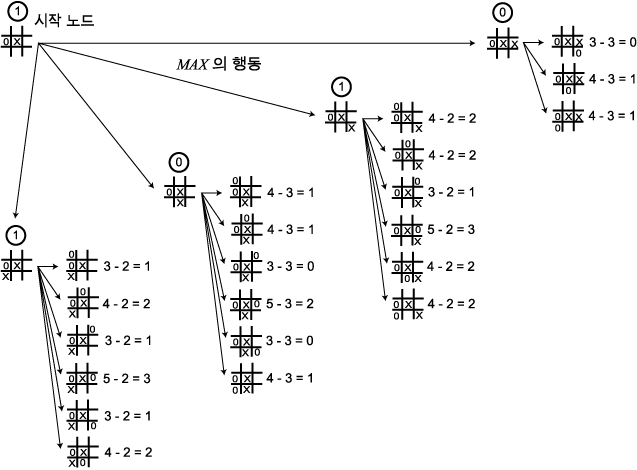
그림 4 Tic-Tac-Toe 탐색의 두 번째 단계
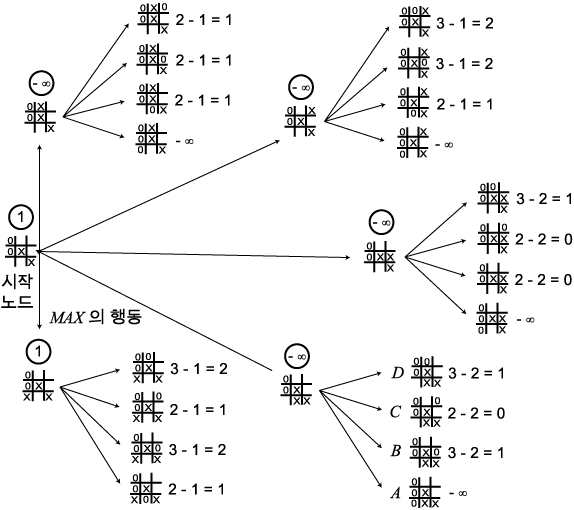
그림 5 Tic-Tac-Toe 탐색의 마지막 단계
방금 설명한 탐색 방법은 탐색트리를 생성하는
과정과 상태를 평가하는 과정을 완전히 분리한 것이다. 트리 생성이 끝난 다음에야
비로소 상태 평가가 시작된다. 그러나 이러한 분리는 대단히 비효율적인 전략이다.
만일 단말 노드의 평가와 전달값 계산을 트리를 생성하면서 동시에 진행하게 되면
(같은 수준의 좋은 노드를 발견하기 위해) 필요한 탐색의 양을 놀랄 만큼 ( 경우에
따라서는 자리 수가 많이 차이날 만큼) 줄일 수 있다. 이 방법은 계획, 행동 그리고
학습에서 설명한 알파 절단 (alpha pruning) 과 비슷하다.
Tic-Tac-Toe 탐색의
마지막 단계에 있는 탐색트리를 생각해 보자 (그림 5). 여기서 단말 노드를 생성하자마자
평가한다고 가정하자. 그러면  라고 쓰여진 노드가 생성되고 평가된 다음에는 노드
라고 쓰여진 노드가 생성되고 평가된 다음에는 노드  ,
,  ,
,  를 생성 (그리고 평가) 하는 것이 아무 의미가 없다. 즉, MIN 이
를 생성 (그리고 평가) 하는 것이 아무 의미가 없다. 즉, MIN 이  를 선택할 수 있고,
를 선택할 수 있고,  보다 더 선호하는 노드가 있을 수 없기 때문에, MIN 은
보다 더 선호하는 노드가 있을 수 없기 때문에, MIN 은  를 선택할 것이라는 것을 즉각 알 수 있다. 그리고 나면
를 선택할 것이라는 것을 즉각 알 수 있다. 그리고 나면  의 부모 노드에 전달값
의 부모 노드에 전달값  를 지정할 수 있고, 노드
를 지정할 수 있고, 노드  ,
,  ,
,  를 생성하고 평가하는 수고를 하지 않고도 탐색을 진행할 수 있다 (만일 이것보다
더 깊이 탐색을 수행하고 있었다면 줄어드는 탐색의 양은 훨씬 더 클 수도 있다는
것을 주목하라. 그런 경우에는 노드
를 생성하고 평가하는 수고를 하지 않고도 탐색을 진행할 수 있다 (만일 이것보다
더 깊이 탐색을 수행하고 있었다면 줄어드는 탐색의 양은 훨씬 더 클 수도 있다는
것을 주목하라. 그런 경우에는 노드  ,
,  ,
,  의 모든 자손들도 생성되지 않을 것이기 때문이다). 노드
의 모든 자손들도 생성되지 않을 것이기 때문이다). 노드  ,
,  ,
,  를 생성하지 않아도 MAX 의 최상의 행동이 무엇이 되는가에 전혀 영향을
줄 수 없음을 깨닫는 것이 중요하다.
를 생성하지 않아도 MAX 의 최상의 행동이 무엇이 되는가에 전혀 영향을
줄 수 없음을 깨닫는 것이 중요하다.
이 예에서는 노드  가 MIN 이 이기는 상태를 나타내기 때문에 탐색을 줄일 수 있었다.
그러나 탐색트리의 어떤 노드 MAX 나 MIN 이 이기는 상태를 나타내지
않는 경우에도 같은 방식으로 탐색을 줄일 수 있다.
가 MIN 이 이기는 상태를 나타내기 때문에 탐색을 줄일 수 있었다.
그러나 탐색트리의 어떤 노드 MAX 나 MIN 이 이기는 상태를 나타내지
않는 경우에도 같은 방식으로 탐색을 줄일 수 있다.

그림 6 Tic-Tac-Toe 탐색의 첫 번째 단계의 일부
앞서 보인 Tic-Tac-Toe 탐색의 첫 번째 단계를
생각해 보자 (그림 3). 이 트리의 한 부분을 그림 6 에 다시 나타내었다. 탐색은
깊이우선 형태로 진행되고, 단말 노드가 생성되자마자 정적 평가 함수가 계산된다고
가정하자. 또한 어떤 노드가 전달값을 받을 수 있게 되자마자 전달값이 지정된다고
하자. 이제 깊이우선 탐색에서 노드  와
와  의 모든 자식 노드들이 생성된 직후,
의 모든 자식 노드들이 생성된 직후,  가 생성되기 전에 일어나는 상황에 대해 생각해 보자. 노드
가 생성되기 전에 일어나는 상황에 대해 생각해 보자. 노드  는 현재 전달값이 -1 이다. 이 시점에서 시작 노드의 전달값은 -1 이상으로 제한된다는
것을 알 수 있다. 다른 자식 노드들로부터 전달되는 값에 따라서 시작 노드의 최종
전달값은 -1 보다 더 클 수는 있지만 더 작을 수는 없는 것이다. 이 하한을 시작
노드의 알파값 (alpha value) 이라고 한다.
는 현재 전달값이 -1 이다. 이 시점에서 시작 노드의 전달값은 -1 이상으로 제한된다는
것을 알 수 있다. 다른 자식 노드들로부터 전달되는 값에 따라서 시작 노드의 최종
전달값은 -1 보다 더 클 수는 있지만 더 작을 수는 없는 것이다. 이 하한을 시작
노드의 알파값 (alpha value) 이라고 한다.
이제 깊이우선 탐색이 노드  까지 진행하여 첫 번째 자식 노드
까지 진행하여 첫 번째 자식 노드  가 생성되었다고 하자. 노드
가 생성되었다고 하자. 노드  의 평가값은 -1 이다. 여기서 노드
의 평가값은 -1 이다. 여기서 노드  의 전달값은 -1 이하로 제한된다는 것을 알 수 있다. 나머지 자식 노드들의 평가값에
따라서 노드
의 전달값은 -1 이하로 제한된다는 것을 알 수 있다. 나머지 자식 노드들의 평가값에
따라서 노드  의 최종 전달값은 -1 보다 작을 수는 있지만 더 클 수는 없다. 노드
의 최종 전달값은 -1 보다 작을 수는 있지만 더 클 수는 없다. 노드  에 대한 이러한 상한을 베타 값 (beta value) 이라고 한다. 그러므로 이 시점에서
노드
에 대한 이러한 상한을 베타 값 (beta value) 이라고 한다. 그러므로 이 시점에서
노드  의 최종 전달값은 시작 노드의 알파값을 넘을 수 없다는 것을 알 수 있고, 따라서
노드
의 최종 전달값은 시작 노드의 알파값을 넘을 수 없다는 것을 알 수 있고, 따라서
노드  아래로의 탐색을 중단할 수 있다. 노드
아래로의 탐색을 중단할 수 있다. 노드  가 노드
가 노드  보다 선호되는 노드일 수는 없는 것이다.
보다 선호되는 노드일 수는 없는 것이다.
이러한 탐색의 감소는 전달값의
한계를 기억함으로써 이루어지는 것이다. 일반적으로 어떤 노드의 전달값의 한계는
자식 노드들의 전달값이 지정되면서 수정될 수 있다. 그러나 다음의 사실을 보자.
이러한 제약조건 때문에, 다음과 같은 규칙에 의하여 탐색을 중단할 수 있다.
1. 조상 MAX 노드의 알파값보다 작거나 같은 베타값을 갖는 MIN 노드 아래에서는 탐색을 중단할 수 있다. 이 MIN 노드의 최종 전달값은 현재의 베타값으로 지정한다. 이 값은 완전한 최대최소 탐색을 수행했을 때 얻어지는 값과는 다를 수도 있지만, 그 값을 사용해도 결과는 같은 행동을 최상으로 선택하게 된다.
2. 조상 MIN 노드의 베타값보다 크거나 같은 알파값을 갖는 MAX 노드 아래에서는 탐색을 중단할 수 있다. 이 MAX 노드의 최종 전달값은 현재의 알파값으로 지정한다.
탐색이 진행되는 동안 알파값과 베타값은 다음과 같이 계산된다.
탐색이 규칙 1 에 의해 중단되면 알파 절단 (alpha
cut-off) 이 일어났다고 말한다. 탐색이 규칙 2 에 의해 중단되면 베타 절단 (beta
cut-off) 이 일어났다고 말한다. 알파값과 베타값을 기억하면서 절단을 수행해 가는
모든 과정을 일반적으로 알파 베타 방법 (alpha-beta procedure) 라고 한다. 이 과정은
시작 노드의 모든 자식 노드들이 최종적인 전달값을 갖게 되면 종료하며, 그리고
나면 최상의 행동은 가장 높은 전달값을 갖는 자식 노드를 만드는 것이 된다. 이
방법을 적용하면 항상 같은 깊이까지 기본적인 최대최소 방법으로 탐색을 수행했을
때 찾아지는 행동과 같은 수준의 행동을 찾게 된다. 유일한 차이는 알파 베타 방법을
사용하면 일반적으로 훨씬 적은 탐색을 하고 최상의 행동을 찾는다는 것이다.
지금까지
설명한 알파 베타 방법을 간결한 의사코드 (pseudocode) 에 의해 귀납적 알고리즘으로
나타낼 수 있다. 아래에 있는 절단값  및
및  와 관련하여 노드
와 관련하여 노드  의 최대최소값을 계산하는 알고리즘은 [Pearl 1984, p.234] 에서 가져온 것이다.
의 최대최소값을 계산하는 알고리즘은 [Pearl 1984, p.234] 에서 가져온 것이다.
|
|
|
|
1. |
|
|
2.
3.
4.
|
2'. 3'. 4'. |
알파 베타 탐색은  가 시작 노드일 때,
가 시작 노드일 때,  를 호출하여 시작한다. 알고리즘이 진행되는 동안
를 호출하여 시작한다. 알고리즘이 진행되는 동안  이다. 단계 1에서 노드의 순서는, 앞으로 보겠지만, 효율에 중요한 영향을 미친다.
이다. 단계 1에서 노드의 순서는, 앞으로 보겠지만, 효율에 중요한 영향을 미친다.

그림 7 알파 베타 탐색의 예
알파 베타 방법의 응용 예를 그림 7 에 나타내었다. 여기에는 깊이 6 까지의 탐색트리가 나와 있다. MAX 노드는 네모로 그려져 있고, MAX 노드는 동그라미로 그려져 있다. 단말 노드에는 평가값이 쓰여 있다. 이제 알파 베타 방법을 써서 깊이 우선 탐색을 수행한다고 하자 (여기서는 바닥 쪽의 노드가 먼저 생성되는 것으로 하였다). 알파 베타 방법에 의해 생성되는 부분트리가 진하게 나타나 있다. 절단되는 노드들에는 X 가 그려져 있다. 원래의 41 개 단말 노드 중에서 18 개만 평가하면 된다 (이 예에 대한 알파 베타 탐색을 따라해 보면 이 방법을 잘 이해했는지 시험해 볼 수 있을 것이다).
알파 및 베타값은 단말 (leaf) 노드의 정적 평가값을
기반으로 하는 것이기 때문에, 알파 및 베타 절단을 수행하기 위해서는 최소한 트리의
한 부분이 최대 깊이까지 생성되어야만 한다. 따라서 일반적으로 알파 베타 방법을
이용하는 데는 깊이우선 형태의 탐색이 사용된다. 또한 탐색이 진행되는 동안 이루어지는
절단의 수는 초기의 알파 및 베타값이 최종적인 전달값을 얼마나 가깝게 추정하는가에
달려있다.
트리의 깊이가  이고 모든 노드 (단말 노드를 제외한) 가 정확히
이고 모든 노드 (단말 노드를 제외한) 가 정확히  개의 자식 노드를 가지고 있다고 하자. 이런 트리에는 정확히
개의 자식 노드를 가지고 있다고 하자. 이런 트리에는 정확히  개의 단말 노드가 있을 것이다. 알파 베타 탐색이 자식 노드, 그리고 MAX 노드에서는
높은 값을 갖는 자식 노드, 그리고 MAX 노드에서는 높은 값을 갖는 자식 노드의
순으로 생성한다고 해보자 (물론 자식 노드들을 생성할 때는 보통 이 전달값들을
알 수 없으므로, 이러한 순서는 우연이 아니고는 실제로 지켜질 수 없다).
개의 단말 노드가 있을 것이다. 알파 베타 탐색이 자식 노드, 그리고 MAX 노드에서는
높은 값을 갖는 자식 노드, 그리고 MAX 노드에서는 높은 값을 갖는 자식 노드의
순으로 생성한다고 해보자 (물론 자식 노드들을 생성할 때는 보통 이 전달값들을
알 수 없으므로, 이러한 순서는 우연이 아니고는 실제로 지켜질 수 없다).
이러한
순서가 절단의 수를 최대화하고, 생성되는 단말 노드의 수를 최소화하게 된다. 이러한
최소의 단말 노드 수를  라고 하자. 그러면 다음을 증명할 수 있다 [Slagle & Dixon 1969, Knuth
& Moore 1975].
라고 하자. 그러면 다음을 증명할 수 있다 [Slagle & Dixon 1969, Knuth
& Moore 1975].

즉, 최적의 알파 베타 탐색에 의해 생성되는 깊이
 의 단말 노드 수는 알파 베타 방법을 쓰지 않았을 때 깊이
의 단말 노드 수는 알파 베타 방법을 쓰지 않았을 때 깊이  에서 생성되는 단말 노드 수와 거의 같다는 것이다. 따라서 알파 베타 방법을
쓰지 않는 탐색이 깊이
에서 생성되는 단말 노드 수와 거의 같다는 것이다. 따라서 알파 베타 방법을
쓰지 않는 탐색이 깊이  에서 중단되는 시간에 알파 베타 탐색은 (완벽한 순서에 따랐을 때) 깊이
에서 중단되는 시간에 알파 베타 탐색은 (완벽한 순서에 따랐을 때) 깊이  까지 진행할 수 있다. 다시 말하면, 완벽한 순서에 의한 알파 베타 탐색은 실질적인
분기 계수를
까지 진행할 수 있다. 다시 말하면, 완벽한 순서에 의한 알파 베타 탐색은 실질적인
분기 계수를  에서 대략
에서 대략  로 감소시킨다.
로 감소시킨다.
물론 완벽한 노드 생성 순서는 이룰 수 없다 (만일 이룰 수
있다면, 탐색이 전혀 필요치 않을 것이다). 최악의 경우에는 알파 베타 탐색이 전혀
절단을 수행하지 못하고, 따라서 실질적인 분기 계수는 변함이 없게 된다. Pearl
은 만일 자식 노드들이 임의의 순서로 생성된다면, 알파 베타 탐색을 수행함으로써
탐색 깊이가 대략 4/3 만큼 증가한다는 것을 증명하였다. 즉, 평균 분기 계수가 약
4
 으로 감소한다는 것이다 [Pearl 1982b] (완전한 분석은 [Pearl 1984, 9장]을
보라). 실제로 자식 노드들의 순서를 정하는 데 좋은 휴리스틱을 쓰면 알파 베타
방법은 일반적으로 거의 최적에 가깝게 실질적인 분기 계수를 감소시킬 수 있다.
으로 감소한다는 것이다 [Pearl 1982b] (완전한 분석은 [Pearl 1984, 9장]을
보라). 실제로 자식 노드들의 순서를 정하는 데 좋은 휴리스틱을 쓰면 알파 베타
방법은 일반적으로 거의 최적에 가깝게 실질적인 분기 계수를 감소시킬 수 있다.
자식
노드들의 순서를 정하는 가장 간단한 방법은 정적 평가 함수를 사용하는 것이다.
또 다른 노드 정렬 기법은 반복적 깊이증가 (iterative deepening) 방법을 사용하면서
부산물로 나타난 것으로써, 체스 프로그램인 CHESS 4.5 에 처음 사용되었다 [Slate
& Atkin 1977]. 이 프로그램은 처음에 한 겹의 깊이 한계까지 탐색을 수행하여
최상의 행동을 계산하는 식으로 동작하였다. 이러한 중복의, 그리고 낭비인 듯한
탐색을 수행한 주된 이유는 게임 프로그램에 대부분 시간 제한이 있기 때문이다.
시간이 얼마나 있는가에 따라 더 깊은 곳까지의 탐색은 언제든지 중단될 수 있고,
바로 이전의 탐색에서 가장 좋다고 판단된 행동을 취할 수 있다.  겹까지의 탐색에서 최상이라고 판단된 자식 노드들을
겹까지의 탐색에서 최상이라고 판단된 자식 노드들을  겹까지의 탐색에서 노드의 순서를 정하는 데 사용할 수 있기 때문에 노드의 정렬이
이 방법의 부산물로 얻어지는 것이다.
겹까지의 탐색에서 노드의 순서를 정하는 데 사용할 수 있기 때문에 노드의 정렬이
이 방법의 부산물로 얻어지는 것이다.
대부분의 게임에서는 게임이 끝나는 상황 이전에 탐색을 중단해야 하기 때문에 (시계 제한) 여러 가지 어려운 문제들이 야기된다. 이런 문제 중의 하나는, 탐색이 MAX (또는 MIN) 가 아주 좋은 행동을 할 수 있는 상태에서 중단될 수도 있다는 것이다. 이 때문에 대부분의 게임 탐색 프로그램은 어떤 상태에서 고요하다는 것은 그 상태가 고요한 (quiescent) 것인지를 확인한다. 어떤 상태가 고요하다는 것은 그 상태의 정적 평가값이 하나 혹은 두 개 앞의 행동을 내다보았을 때의 전달값과 큰 차이가 없다는 것을 말한다.
탐색을 종료하기 전에 고요함을 확인하더라도, 탐색의 시계 (horizon) 바로 저편에 아주 안 좋은 상황이나 혹은 이길 수 있는 상황이 숨어 있는 경우가 있다. 어떤 게임에서는 MIN 이 어떤 행동을 취하더라도 MAX 가 이기는 길로 갈 수밖에 없는 상황이 있는데, 이 경우 MIN 이 MAX 가 이기는 상태를 탐색 시계 밖으로 밀어내도록 고요함을 유지하며 피해 다니는 행동을 할 수도 있다. 이 시계효과 (horizon-effect) 라고 하는 상황은 게임 프로그램들이 가지고 있는 근본적인 문제 중의 하나이다.
최대최소 방법과 그것의 확장인 알파 베타 방법은 상대방이 언제나 자신에게 최상의 행동을 선택한다고 가정하고 있다. 이러한 가정이 적절하지 못할 때도 있다. 예를 들어, MIN 이 최적의 행동을 하면 MAX 가 질 것 같은 상황에 있다고 하자. 그래도, MIN 이 실수를 하기만 한다면 MAX 가 이런 상황에서 빠져 나올 수 있도록 해주는 행동이 있을 것이다. 최대최소 탐색은 MIN 이 실수를 할거라고 도박을 거는 데 추가적인 행동이 있을 것이다. 최대최소 탐색은 MIN 이 실수를 할거라고 도박을 거는 데 추가적인 위험이 거의 없더라도 그러한 행동을 추천하지는 못한다 (어느 경우에도 질 것이므로). 최대최소 방법은 또한 한쪽이 상대방의 전략에 대한 어떤 모델이 있는 경우에도 부적절하다.
Backgammon 과 같은 게임에는 확률적 요소가 포함되어 있다. 예를 들어 주사위를 던졌을 때의 결과에 따라 취할 수 있는 행동이 달라질 수 있다. 이런 종류의 게임의 한 예에 대한 게임트리를 그림 8 에 나타내었다 (트리를 단순화하기 위하여 하나의 주사위를 던졌을 때 나오는 6 개의 서로 다른 결과만을 나타내었다). MAX 와 MIN 의 차례에는 이제 주사위를 던지는 것이 포함된다. 주사위를 던질 때마다 가상의 세 번째 플레이어 DICE 가 행동을 취한다고 생각할 수 있다. 이 행동을 확률적으로 결정된다. 하나의 주사위를 던지는 경우에는 6 개의 결과가 모두 같은 확률을 갖고 있지만, 확률요소는 임의의 확률 분포를 가질 수도 있다.
확률적 행동이 포함된 게임트리에서도 값은 전달될 수 있으나, 확률적 행동이 있는 노드로 값을 전달할 때는 최대나 최소값 대신에 자식 노드의 기대값 (expected value)을 전달할 수 있다. 그림 8에서 각 노드의 옆에 있는 숫자는 전달값의 추정치이다. MIN 의 차례에 해당하는 노드의 자식 노드로부터는 최소값을, MAX 의 차례에 해당하는 노드의 자식 노드로부터는 최대값을, 그리고 DICE 의 차례에 해당하는 노드의 자식 노드로부터는 기대값을 전달한다. 이러한 수정된 전달 방법을 기대값 최대화 (expectimaxing) 라고도 한다.

그림 8 주사위 던지기가 포함된 게임의 게임트리
확률적 행동을 도입하면 대개 게임트리의 분기가 효과적인 탐색을 하기에 너무 많아진다. 이러한 경우에는 좋은 정적 평가 함수를 사용하여 탐색이 너무 깊이 진행하지 않도록 하는 것이 매우 중요하다. 만일 충분히 좋은 정적 평가 함수가 있다면, MAX 의 행동 선택 정책은 한 단계 앞의 상태만을 보고 이들의 정적 평가 함수값이 최대가 되는 행동 취하는 것일 수 있다. 다음 장에서는 행동 정책을 학습하는 방법과 분기 계수가 너무 커서 탐색할 수 없는 게임의 정적 평가 함수를 학습하는 방법에 대해 이야기하겠다.
바둑과 같은 게임은 각 단계에서 너무 많은 행동이
가능하기 때문에 깊은 탐색이 가능하지 않은 것으로 생각된다. 탐색을 하지 않으면,
자식 노드에 대한 정적 평가 값만을 기반으로 하거나, 다양한 패턴인식 기법을 이용해
현재의 상태에 반응하는 방법으로 최상의 행동을 선택해야만 한다. 예를 들어 바둑에서는
현재의 상황을 평가하는 방법과 상황에 반응적으로 대처하는 방법에 대한 연구가
주로 이루어졌다 [Zobrist 1970, Reitman & Wilcox 1979, Kierulf, Chen, &
Nievergelt 1990]. 어떤 경우에는 좋은 정적 평가 함수를 신경망을 이용하여 학습할
수도 있다. TD-GAMMON [Tesauro 1992, Tesauro 1995] 이라는 프로그램은 다층 (layered)
피드포워드 (feedforward) 신경망을 훈련하여 Backgammon을 하는 방법을 학습한다.
신경망의 구조는 그림 9 와 같다. 198 개의 입력 유닛 (Backgammon 의 현재 상황을
표현함) 이 은닉 유닛들에 완전 연결되어 있고, 은닉 유닛들은 다시 출력 유닛들에
완전 연결되어 있다. 은닉 유닛과 출력 출력은 모두 시그모이드 (sigmoid) 이다.
출력 유닛들은 주어진 입력 상황으로부터 여러 가지 가능한 결과들의 확률에 대한
추정값  ,
,  ,
,  ,
,  를 산출하도록 되어 있다. 어떤 상황에 대한 전체적인 가치는 추정된 보상값
(payoff),
를 산출하도록 되어 있다. 어떤 상황에 대한 전체적인 가치는 추정된 보상값
(payoff),  로 주어진다. 이 신경망을 이용하여 Backgammon 을 하면, 우선 주사위가 던져지고,
현재의 상황과 주사위의 값으로부터 가능한 모든 상황들이 신경망에 의해 평가된다.
가장 좋은
로 주어진다. 이 신경망을 이용하여 Backgammon 을 하면, 우선 주사위가 던져지고,
현재의 상황과 주사위의 값으로부터 가능한 모든 상황들이 신경망에 의해 평가된다.
가장 좋은  값을 갖는 상황이 선택되고, 그 상황을 만드는 행동을 수행하게 된다 (백의 차례라면
값을 갖는 상황이 선택되고, 그 상황을 만드는 행동을 수행하게 된다 (백의 차례라면
 값이 높을수록 좋은 것이고, 흑의 차례라면
값이 높을수록 좋은 것이고, 흑의 차례라면  값이 낮을수록 좋은 것이다).
값이 낮을수록 좋은 것이다).
신경망의 시간 차이 (temporal difference)
훈련은 신경망이 자기 자신과 시합을 하면서 이루어진다. 하나의 행동을 하고 나면,
역전파 (backpropagation) 에 의하여, 원래 상황에서 추정된 보상값이 결과 상황에서의
실제 보상값에 접근하도록 신경망의 가중치들이 조정된다. 쉽게 설명하기 위해 이
방법이 순수한 시간 차이 학습을 하는 것으로 하겠다 (실제로는 약간 다르지만, 여기서
그 부분은 중요하지 않다).  가 시간
가 시간  에서의 보상값에 대한 추정치이고,
에서의 보상값에 대한 추정치이고,  이 시간
이 시간  에서의 추정치라면, 전형적인 시간 차이 가중치 조정 규칙은 다음과 같다.
에서의 추정치라면, 전형적인 시간 차이 가중치 조정 규칙은 다음과 같다.

 는 시간
는 시간  에서의 신경망의 모든 가중치에 대한 벡터이고,
에서의 신경망의 모든 가중치에 대한 벡터이고,  는 가중치 공간에서
는 가중치 공간에서  의 기울기 (gradient) 이다 (TD-GAMMON 과 같은 다층 피드포워드 신경망에서
각 층의 가중치 벡터의 변화는 신경망에서 기술한 것과 같은 식으로 나타낼 수 있다).
신경망은 모든
의 기울기 (gradient) 이다 (TD-GAMMON 과 같은 다층 피드포워드 신경망에서
각 층의 가중치 벡터의 변화는 신경망에서 기술한 것과 같은 식으로 나타낼 수 있다).
신경망은 모든  에 대하여 행동이 취해지기 전의 입력에 대한 출력
에 대하여 행동이 취해지기 전의 입력에 대한 출력  가 행동이 취해진 후의 입력에 대한 출력
가 행동이 취해진 후의 입력에 대한 출력  에 가까워지도록 (값 반복에서처럼) 훈련된다. 이러한 훈련 방법에 대한 실험이
신경망이 자기 자신과 수십만 번의 시합을 하도록 함으로써 수행되었다 (훈련과정에서
약 50 만 번의 게임을 수행하였다).
에 가까워지도록 (값 반복에서처럼) 훈련된다. 이러한 훈련 방법에 대한 실험이
신경망이 자기 자신과 수십만 번의 시합을 하도록 함으로써 수행되었다 (훈련과정에서
약 50 만 번의 게임을 수행하였다).
잘 훈련된 신경망의 성능은 거의 챔피언
수준이다. 앞을 내다보는 탐색을 약간 사용한 프로그램과의 40 번의 게임 결과를
기초로 하여, Bill Robertie (전 Backgammon 세계 챔피언) 는 TD-GAMMON 2.1 의 수준이
세계 최고 선수와 거의 같은 정도인 strong master 수준이라고 추정하였다 [Tesauro
1995].
퍼즐처럼 게임들도 AI 기법들을 다듬고 시험하는 데 매우 중요한 역할을 해왔다. 예를 들어 [Russell & Wefald 1991 (Russell, S., and Wefald, E., Do the Right Thing, Cambridge, MA: MIT Press, 1991.), 4 장] 는 알파 베타보다 효과적인 방법으로 탐색트리를 줄이기 위해 (계속되는 탐색의 기대값을 이용하여) 메타 레벨 계산을 수행하는 게임트리 알고리즘 (MGSS* 와 MGSS2) 을 제안하였다. Berliner 의 B* 알고리즘도 구간 한계 (interval bound) [Berliner 1979] 를 사용하여 보다 효과적인 절단을 한다. [Korf 1991 (Korf, R., "Multi-Player Alpha-Beta Pruning," Artificial Intelligence}, 48:99-111, 1991.)] 은 알파 베타 방법을 여러 명이 하는 게임에 적용하도록 확장하였다.
수치 평가 함수를 사용하는 대신에, 게임에 대한 일부 연구에서는 하나의 상황이 다른 상황에 비해 더 좋은지 (better than) 혹은 더 나쁜지 (worse than) 를 판단하는 데 패턴인식 (pattern recognition) 기법을 사용하였다. 이러한 기법은 체스의 게임 마지막 부분을 수행하는 프로그램에 사용되었다 [Huberman 1968 (Huberman, B. J., A Program to Play Chess End Games, Stanford University Computer Science Department Report CS 106, August 19, 1968.), Bratko & Michie 1980 (Bratko, I., and Michie, D., "An Advice Program for a Complex Chess Programming Task," Computer Journal, 23(4):353-359, 1980.)].
게임에 대한 가장 성공적인 초기 업적은 체커 (Checker) 게임에서의 기계 학습 (machine learning) 방법을 개발한 Arthur Samuel 의 연구이다 [Samuel 1967 (Samuel, A. L., "Some Studies in Machine Learning Using the Game of Checkers IIm Recent Progress," IBM Jour. R & D, 11(6), 601-617, 1967.) Some Studies in Machine Learning Using the Game of Checkers]. Samuel 의 체커 프로그램은 챔피언에 가까운 수준으로 게임을 수행하였다. 현재는 University of Alberta 에 있는 Jonathan Schaeffer 의 CHINOOK 프로그램 [Schaeffer et al.1992 (Schaeffer, J., Culberson, J., Treloar, N., Knight, B., Lu, P., and Szafron, L., "A World Championship Caliber Checkers Program," Artificial Intelligence, 53(2-3:273-289, 1992.) A World Championship Caliber Checkers Program, Schaeffer 1997 (Schaeffer, J., One Jump Ahead: Challenging Human Supremacy in Checkers, New York: Springer-Verlag, 1997.)] 이 세계 체커 챔피언으로 알려져 있다. 1997년에는 IBM 의 프로그램인 DEEP BLUE 가 챔피언 타이틀전에서 세계 체스 챔피언인 Garry Kasparov 를 이겼다.
[Monty Newborn 1996 (Newborn, M., Computer Chess Comes of Age, New York: Springer-Verlag, 1996.) Computer Chess Comes of Age] 은 컴퓨터 체스에 관한 책으로서, 1996년에 DEEP BLUE 가 Garry Kasparov 에게 패할 때까지의 역사를 열거한 것이다. 이 책에 대한 서평과 AI 를 위한 연구용으로서의 체스의 역할에 대한 설명은 [John McCarthy 1997 AI as Sport] 을 참조하라. McCarthy 는 체스 프로그램이 좀더 인간과 비슷한 추론 방법을 사용한다면 더 적은 탐색으로도 더 나은 성능을 보일 것이라고 하였다. [Michie.D 1966 Game Playing and Game Learning Automata] 는 기대값 최대화 (expectimax) 라는 말을 만들고 이 기법에 대한 실험을 수행하였다.
[Lee & Mahajan 1988 (Lee, K.-F., and Mahajan, S., "A Pattern Classification Approach to Evaluation Function Learning," Artificial Intelligence, 36(1):1-26, 1988.)] 은 강화 학습 (reinforcement learning) 방법을 오셀로 (Othello) 게임에 적용하였으며, [Schraudolph, Dayan, & Sejnowski 1994 (Schraudolph, N., Dayan, P., and sejnowski, T., "Temporal Difference Position Evaluation in the Game of GO," in Cowan, J., et al. (eds.), Advances in Neural Information Processing Systems, 6, pp.817-824, San Francisco: Morgan Kaufmann, 1994.] 는 시간차이 (temporal difference) 기법을 바둑에 적용하였다. 일반적인 게임 탐색 방법에 대해 더 알고 싶다면 [Judea Pearl 1984 (Pearl, J., Heuristics: Intelligent Search Strategies for Computer Problem Solving, Reading, MA: Addison-Wesley, 1984.), Heuristics Intelligent Search Strategies... 9 장] 을 참조하라.

 이 깊이 한계에 있으면
이 깊이 한계에 있으면  의 정적 평가값을 반환한다. 그렇지 않으면
의 정적 평가값을 반환한다. 그렇지 않으면  를
를  의 (순서 있는) 자식 노드들이라고 하고,
의 (순서 있는) 자식 노드들이라고 하고,  로 한다.
로 한다.  이 MAX 노드이면 단계 2 로 가고, 아니면 단계 2' 로 같다.
이 MAX 노드이면 단계 2 로 가고, 아니면 단계 2' 로 같다. .
. 이면
이면  를 반환 ; 아니면 계속.
를 반환 ; 아니면 계속. 이면
이면  를 반환 ; 아니면
를 반환 ; 아니면  로 진행. 즉
로 진행. 즉  로 하고 단계 2 로 감.
로 하고 단계 2 로 감.
 이면
이면  를 반환 ; 아니면 계속.
를 반환 ; 아니면 계속. 이면
이면  를 반환 ; 아니면
를 반환 ; 아니면  로 진행. 즉
로 진행. 즉  로 하고 단계 2' 로 감.
로 하고 단계 2' 로 감.