
규칙 과 생성 시스템
( Rule & Production System )
인공지능의 기법과 응용 : 김재희, 교학사, 1988, Page 219~245
1. 생성 시스템 (production system) 의 예
(2) 충돌 해결 (conflict resolution)
(5) 지식 전달 (knowledge transfer)
(6) 확신율 (certainty factor) 에 의한 답변의 신뢰성
생성 시스템 (production system ; PS) 은 최초로 [Pos. 43] 에 의하여 제시되었으나, 인공지능에서 많은 이론적, 응용적 발전을 이루어 현재는 초기의 Post 가 제안하였던 것으로부터 많은 변화를 갖게 되었다.
실제로 의미회로 (semantic nets) 가 노드와 아크의 연결로 이루어진 기본구조에 근거를 두어 여러 변화된 형태의 지식 표현 방법을 구사하듯이, 생성 시스템은 기본적으로 조건과 행동의 쌍 (condition-action pair) - 이를 규칙 (법칙 ; rule), 생성규칙 (생성법칙 ; production rule), 혹은 생성 (production) 이라고 부른다 - 에 근거를 둔 표현방법을 사용하는 여러 다른 형태의 시스템을 총괄한다. 여기에서는 이러한 PS 의 기본구조 및 예를 설명하고, 추론 방법, PS 의 설계 및 운영시의 문제점, 그리고 주지사항을 논의하며, 규칙을 이용한 시스템의 장단점과 이의 응용분야에 관하여 서술한다.
PS 는 3 부분으로 구성된다.
(1) 생성규칙들의 모임인 생성 메모리 (production memory).
(2) 현재의 상태를 나타내는 버퍼 (buffer) 와 비슷한 데이터 구조로써의 작업 메모리 (working memory 또는 context).
(3) 시스템의 운영을 관장하는 인터프리터 (interpreter).
이들 각 부분에 관하여 간단히 서술한 뒤 생성 시스템의 동작을 설명하기 위한 예를 들겠다.
생성규칙 (production rule) 은 "If this condition hold, then this action is appropriate." 와 같은, 조건과 이 조건의 만족시 수행되는 행동의 쌍이다. 예를 들어 다음의 규칙을 생각해 보자.
|
You can turn right when the stoplight is red and you have stopped. (적신호일 때라도 일단 정지 후에는 우회전이 허용된다.) |
이것은 다음과 같은 생성규칙으로 나타낼 수 있다.
|
IF stoplight is red AND you have stopped, THEN right turn OK. |
생성규칙에서의 IF 부분은 조건부 (condition part, antecedent) 혹은 LHS (Left-Hand Side) 라고 하는데, 이는 생성규칙이 적용되기 위한 조건을 나타낸다. THEN 부분은 행동부 (action part, consequent), 혹은 RHS (Right-Hand Side) 라고 하는데 생성규칙이 선택되었을 때 취하여야 할 행동을 나타낸다.
생성 시스템을 운영하는 동안 조건부가 만족되는 규칙이 수행 (execute) 될 수 있는데 이를 화이어 (fire) 한다고 하고, 인터프리터에 의한 행동부의 수행을 의미한다.
생성 메모리에 있는 규칙의 수는 실용적인 인공지능 시스템에서는 수백 개 이상이 될 수 있다.
작업 메모리는 단기 메모리 (short-term memory ; STM) 라고도 불리우는데 선택할 규칙의 조건과 비교될 대상으로써 현재의 상태를 나타낸다. 각 규칙의 조건부는 이것이 작업 메모리에 의하여 만족되어야만 선택되어질 수 있다. 즉, 앞의 규칙에서, 우회전을 하기 위하여서는 신호등이 적색이더라도 일단 정지한 후면 좋다는 요구조건을 나타낸다. 규칙의 행동부는 작업 메모리의 내용을 변화시킬 수 있으며, 이렇게 됨으로써 다른 규칙의 조건부가 만족될 수 있는 것이다. 작업 메모리의 구조는 단순한 리스트 (list) 일 수도 있고, 혹은 큰 배열 (array) 등 여러 데이터 구조 중의 하나가 될 수 있다.
마지막으로 인터프리터는 다른 컴퓨터 시스템과 같이 일종의 프로그램으로써 차후에 할 일을 결정한다. 이러한 이유는 작업 메모리에 의하여 동시에 만족되는 규칙의 수가 한 개 이상일 수 있기 때문이다.
다음은 식품 구분을 위한 생성 시스템의 예를 생각해 보자. 문장구조를 IF, THEN 부분으로 쉽게 구분하기 위하여 영문을 사용하였다. 이 시스템에서 작업 메모리의 구조는 심볼 (symbol) 들의 단순한 리스트인데, 이를 Context List (CL) 라고 하였다. "ON-CL X" 는 작업 메모리에 심볼 X 가 있음을 의미한다.
|
[규칙] P1. IF ON-CL green THEN Put-On-CL produce P2. IF ON-CL packed in small container THEN Put-On-CL delicacy P3. IF ON-CL refrigerated OR On_CL produce THEN Put-On-CL perishable P4. IF ON-CL weighs 15 lbs AND On-CL inexpensive AND NOT On-CL perishable THEN Put-On-CL staple P5. IF ON-CL perishable AND On-CL weights 15 lbs THEN Put-On-CL turkey P6. IF ON-CL weights 15 lbs AND On-CL produce THEN Put-On-CL watermelon [인터프리터] 1. 조건부가 TRUE 인 모든 규칙을 찾아서 수행 가능 (applicable) 하도록 한다. 2. 만일 하나 이상의 규칙이 수행 가능하면, 이미 CL 에 포함된 심볼을 추가시키려는 행동부를 갖는 규칙은 수행시키지 않도록 한다. 3. 수행가능한 규칙 중 가장 적은 번호의 규칙을 수행시킨다. 수행 가능한 규칙이 없다면 시스템의 운영을 중지한다. 4. 모든 규칙의 수행 가능성을 원래 상태대로 지우고 1 의 상태로 되돌아 간다. |
이 시스템은 가상적인 것이며 여기서 구성된 인터프리터가 다른 시스템과 동일할 이유는 없음을 잘 알아두기 바란다.
각 규칙의 조건부는 "스무고개" 문답에서 질문과 비슷한 것이다. 즉, 물건이 녹색 (green) 인가, 조그만 용기 (small container) 에 들어갈 수 있는가 등이다. 규칙의 행동부는 미지의 물건에 대한 정보를 작업 메모리에 첨부시킨다. 또, 생성 시스템은 주기의 반복으로 운영된다. 각 주기마다, 인터프리터는 규칙을 조사하여 작업 메모리에 의해 만족, 수행될 수 있는 것을 파악한다. 그 다음에 하나 이상의 규칙이 만족될 시에는 그 중에 하나를 선택한다. 마지막으로 선택된 규칙을 수행한다. 각 주기의 이러한 3 단계를 각각 매칭 (matching), 충돌 해결 (conflict resolution), 그리고 수행 (execution) 이라고 한다.
예로써, 어떤 알려져 있지 않은 식료품의 색깔이 녹색 (green) 이고 무게가 15 lbs 라고 하자. 다시 말하면 최초의 주기가 시작되기 전에 작업 메모리에는 다음의 내용이 들어 있다.
CL = (green, weighs 15 lbs)
인터프리터에서의 1 단계가 시작된다. 즉, 모든 규칙의 조건부를 시험하여 수행 가능한 규칙들을 선택한다. P1 만이 수행 가능하므로 2 단계는 생략하고, 3 단계에서 P1 의 행동부가 수행된다. 결과로 작업 메모리에 심볼 produce 를 첨부하여 미지의 물건에 새로운 사실을 첨가하게 된다.
CL = (produce, green, weights 15 lbs)
4 단계에서 첫번째 주기를 끝낸 후, 1 단계로 가서 다시 수행 가능한 규칙을 찾는다. 두번째 주기에서는 규칙 P1, P3 와 P6 가 수행 가능하다. 따라서 2 단계에서 이 규칙들 중에 이미 작업 메모리에 존재하는 심볼을 중복 저장하는 것이 있나 살핀다. P1 은 produce 를 추가로 첨부시키므로 이를 제거한다. 다음 3 단계에서 P3 가 수행되고 (P6 보다는 작은 번호이므로) 결과로,
CL = (perishable, produce, green, weighs 15 lbs)
가 남는다. 세번째 주기에서는 P1, P3, P5 와 P6 가 수행 가능하게 되고, 2 단계에서 P1 과 P3 가 중복된 기호를 저장하는 관계로 제거된다. 3 단계에서 P5 가 P6 보다 앞서므로 이것이 선택되어 수행된 결과는,
CL = (turkey, perishable, produce, green, weighs 15 lbs)
가 된다 (그런데 이 단계는 분명히 잘못되었다. 즉, green 과 produce 인 성격을 갖는 것이 turkey 일 수는 없기 때문이다). 계속하여 두 주기를 더 수행하면 이 예는 끝나게 된다. 네번째 주기에서 작업 메모리에 watermelon 이 추가되고, 마지막 주기에서는 중복되지 않는 규칙이 없으므로 인터프리터는 결국 다음과 같은 작업 메모리의 내용으로 끝내게 된다.
CL = (watermelon, perishable, produce, green, weighs 15 lbs)
만일 작업 메모리의 처음 것을 시스템의 답으로 정한다면 두번째 놓은 잘못된 turkey 는 무시할 수 있다. 독자는 아마도 보다 나은 오답 처리 방법을 생각해 낼 수 있겠는데, 예로써 생성 메모리나 인터프리터의 내용을 변경하거나 규칙의 순서를 바꾼다든지 인터프리터의 수정 및 새로운 규칙의 첨가 등이 있다. 또 행동부에서는 작업 메모리에 새로운 것의 첨가 외에도 제거의 능력을 부여할 수 있다. 이러한 생성 메모리의 운영 능력이 생성 시스템을 지식 표현 방법으로 사용하는 큰 이유 중의 하나일 것이다.
이제 보다 흥미로운 예로써 규칙간의 연관을 이용한 추론에 관심을 둔 다음의 예를 생각해 보자. 여기서는 작업 메모리나 인터프리터의 동작을 생략하고 규칙들만 생각한다. 로보트인 Robbie 가 동물원을 방문한다고 가정하여 보자. Robbie 는 여러 동물들을 인식할 수는 없지만 색이나 크기 등의 기본적인 특징은 알아볼 수 있고, 따라서 문제는 이러한 기본적인 특징들로부터 동물의 이름을 알아내는 것이다. 이 시스템의 이름을 앞으로 IDENTIFIER 라고 부른다.
이 문제를 해결하는데 있어서 각 동물에 대하여 하나의 규칙을 줄 수 있지만 이는 상당히 둔한 방법이다. 이 경우 각 규칙의 행동부는 동물 이름이 될 것이고, 조건부는 해당되는 동물을 구분하기 위해, 많은 특징들을 충분히 나열하게 될 것이다. 그리고 시스템이 동작할 때는 현재상태에서 주어진 모든 사실을 모아 생성 메모리의 각 규칙과 비교하여 단 한 번의 주기로써 동물 이름을 찾아낼 것이다. 더 나은 방법은 중도의 결과를 얻게하여 추론 과정을 보다 흥미롭게 하는 것이 있다. 이 경우의 이점은 사용되는 규칙의 크기가 작아지고, 쉽게 이해되고, 쉽게 사용되며, 또 쉽게 만들 수 있다. 이 방법을 사용함으로써 IDENTIFIER 는 일련의 결과를 생성, Robbie 가 시험하는 동물의 이름을 알아내는 결론에 도달하게 된다.
Robbie 가 동물원의 작은 방에 있는 7 마리의 동물에만 관심이 있다고 가정하자. 이는 IDENTIFIER 가 갖는 생성규칙의 수를 줄이기 위한 것이다. 규칙 중 4 개는 포유동물 (mammal) 인가 조류 (bird) 인가를 구분하기 위한 것이다.
|
규칙 P1. IF the animal has hair THEN it is a mammal 규칙 P2. IF the animal gives milk THEN it is a mammal 규칙 P3. IF the animal has feathers THEN it is a bird 규칙 P4. IF the animal flies AND it lays egg THEN it is a bird |
이 중에 P4 는 조건부에 2 개의 조건을 갖고 있고, 이들은 AND 로 연결되므로 그 조건이 모두 만족되어야 이 규칙이 수행 가능하다. 일단 동물이 포유류 (mammal) 로 밝혀지면 이것이 육식동물 (carnivore) 인가를 규정하기 위해 두 개의 법칙이 필요하다. 즉,
|
규칙 P5. IF the animal is a mammal AND it eats meat THEN it is a carnivore 규칙 P6. IF the animal is a mammal AND it has pointed teeth AND it has claws AND its eyes point forward THEN it is a carnivore |
동물원에 있는 포유류 중 다른 동물들은 유제류 (ungulate) 라고 생각해 보자. 유제류는 발굽 (hoof) 이 있는 동물이다.
|
규칙 P7. IF the animal is a mammal AND it has hoofs THEN it is an ungulate |
유제류의 다른 특징은 되새김 (cud) 을 하는 것으로 이를 규칙화하면 다음과 같다.
|
규칙 P8. IF the animal is a mammal AND it chew cud THEN it is an ungulate AND it is even-toed |
여기서의 행동부는 두 가지 행동을 포함한다. 지금까지 포유류를 육식류와 유제류로 구분하였으므로 이제는 특정한 구분법칙을 만들도록 한다. 육식류에서는 두 가지가 존재한다.
|
규칙 P9. IF the animal is a carnivore AND it has a tawny color AND it has dark spots THEN it is a cheetah 규칙 10. IF the animal is a carnivore AND it has a tawny color AND it has black stripes THEN it is a tiger |
엄밀히 말하면 색 (color) 은 소용이 없는데, 이는 두 육식동물이 모두 황갈색 (tawny) 이기 때문이다. 그러나 규칙에 있는 정보의 중복이나 과다의 정보가 포함되더라도 자연스러움을 강조하는 것이 나은 경우가 있으므로 지금은 정보의 최소를 목표로 하지는 않는다. 이는 차후 시스템의 확장을 대비하는 이유에서이다.
유제류에서는 두 가지 구분을 한다.
|
규칙 P11. IF the animal is an ungulate AND it has long legs AND it has a long neck AND it has a tawny color AND it has dark spots THEN it is a giraffe 규칙 12. IF the animal is an ungulate AND it has a white color AND it has black stripes THEN it is a zebra |
포유류는 이상의 4 가지이고, 나머지는 3 가지의 조류에 관한 것이다.
|
법칙 P13. IF the animal is a bird AND it does not fly AND it has a long legs AND it has a long neck AND it is black and white THEN it is an ostrich 규칙 P14. IF the animal is a bird AND it does not fly AND it swims AND it is black and white THEN it is a penguin 규칙 P15. IF the animal is a bird AND it is a good flyer THEN it is an albatross |
이상의 동물들 중에서 어떤 것들은 서로 같은 특징을 지니고 있음을 잘 알아두기 바란다. 얼룩말 (zebra) 과 호랑이 (tiger) 는 검은 띠 (back stripe) 를, 호랑이, 치타 (cheetah) 와 기린 (giraffe) 은 황갈색 (tawny color) 을 갖는다. 기린과 타조 (ostrich) 는 긴 다리 (long legs) 와 긴 목 (long neck) 을 갖는다. 또 타조와 펭귄 (penguin) 은 검은색 (black) 과 하얀색 (white) 을 갖는다.
한 가지 예로 Robbie 가 동물원에 가서 알려져 있지 않은 다음 동물을 IDENTIFIER 로써 분석한다고 생각하자.
|
1. 관측된 동물은 황갈색과 검은 점 (dark spot) 을 지닌다. 규칙 P9 과 P11 의 조건부 중 일부가 만족되지만 더 만족되어야 할 부분이 있으므로 수행할 수는 없다. 2. 새끼를 돌보는 도중, 동물은 되새김을 하였다. 분명히 동물은 젖 (milk) 을 주는데 이 규칙 P2 를 수행시켜 포유류임을 알아낸다. 동물이 포유류이고 되새김을 하므로, P8 에 의하여 유제류이며 발가락이 둘 혹은 넷 (even-toed) 을 갖는다고 생각한다. P11 의 조건부는 거의 만족된다. 3. 동물은 긴 다리와 긴 목을 갖는다. 따라서 P11 이 수행되고, 결론은 기린임을 알게 된다. |
그림 1 에서와 같이 이상의 관측된 사실로부터 결론까지 과정을 알 수 있다.
그림 1 생성 시스템의 수행 예
추론 (inference) 은 이미 알고 있는 사실들로부터 새로운 사실을 추리하여 내는 것인데 인공지능 시스템이 기존의 시스템과 다른 점이 바로 이렇게 추론할 수 있는 능력을 갖고 있는 것이다.
추론은 크게 연역법 (deduction), 유도법 (abduction), 귀납법 (induction) 의 3 가지로 구분된다 (이 중 유도법은 abduction 을 번역한 것인데, 적당한 의미의 우리말이 없으므로 이의 사용에 주의를 하기 바란다).
여지껏 우리가 논의한 논리, 의미회로 및 생성 시스템에서의 추론방식은 모두 연역법에 의한 것이었다. 즉 'IF A THEN B' 와 'A' 라는 2 개의 사실로부터 'B' 이라는 사실을 알아내는 것이 연역법에 의한 추론이다. 연역법에 의하여 얻은 새로운 사실은 원래 주어져 있는 것들이 모두 참 (true) 이면 항상 참이 된다. 즉 다시 말하면 면역에 의한 추론은 항상 옳다. 이를 추론의 건전성 (soundness) 이라고 한다.
유도법은 'IF A THEN B' 와 'B' 로부터 'A' 을 얻어내는 것으로 항상 옳은 결과가 얻어지지는 않는다. 예로써
|
IF someone is a mother THEN someone is a woman, Sue is a woman. |
여기서 얻어내는 'Sue is a mother' 가 꼭 옳다고 볼 수는 없다. 유도법은 일종의 추측이고 다수의 경우에 옳지만 항상 그런 것은 아니다. 따라서 유도법을 유사추론 (plausible inference) 이라고 한다. 유도법은 후에 논의될 전문가 시스템 (expert system) 에서 가끔 이용되는 추론방법이다.
귀납법 (induction) 은 관측된 사실로부터 새로운 법칙을 만들어 내는 것으로
|
IF something is a sparrow THEN it can fly. IF something is a dove THEN it can fly. IF something is a eagle THEN it can fly. : : : |
으로부터 'IF something is bird THEN it can fly.' 을 얻어낸다. 이 역시 항상 옳은 추론은 아니다. 이러한 귀납법은 학습 (learning) 과 관계되고 이는 제 11 장에서 다시 논의된다.
여기서는 연역법에 의한 추론 방법에 관하여 논의하겠다. 생성 시스템에서 연역법에 의한 추론 중 규칙을 사용하는 방법에 따라 전향연결 (forward chaining) 과 후향연결 (backward chaining) 의 두 가지로 나눌 수 있다. 앞의 2 가지 예는 전향연결을 이용한 것인데 보다 자세히 하기 위하여 그림 2 의 예를 살펴 보자.

그림 2 전향연결 (forward chaining) 의 예
여기서 'FACTS' 는 '작업 메모리' 에 해당하는 것이고 'RULES' 는 '생성 메모리' 에 해당하는 것이다. 또, 간단히 나타내기 위하여 'IF F AND B THEN Z' 를 'F & B → Z' 로써 표시하였다 (아직 인공지능에서는 표기법들이 통일되어 있지 않은 관계로 여러 가지 방법으로 표현하는 수가 있으니 여러 가지를 익혀 두는 것이 필요하다).
전향연결은 주어진 상황에 해당하는 FACTS, 즉 작업 메모리 내용에 의하여 만족되는 규칙을 찾아 이를 수행시키는 것이다. 따라서 첫번째 주기에는 'A → D' 가 수행되어 'D' 라는 새로운 내용을 작업 메모리에 첨부시키게 되고 'D' 가 첨부됨에 따라 두번째 주기에는 'C & D → F' 가 만족되어 'F' 가 첨가되며, 세번째 주기에서는 최종적으로 'F & B' 가 만족되어 'Z' 라는 결과를 낳는다. 이 방법을 전향연결이라고 하는데 이는 새로운 사실을 추론하여 나가는 방향이 IF 에서 THEN 으로, 즉 조건부에서 행동부로 진행되어 나간다. 이에 대한 추론사슬 (inference chain) 이 그림 3 에 나타나 있다. 상황 F 와 D 는 물론 Z 도 추론되었다.

그림 3 그림 2 의 예에 대한 추론사슬
한편 이 시스템을 사용하여 상황 Z 가 존재하는지 여부를 알아보자. 얼핏 생각하기에 Z 가 세 번에 걸친 반복주기 후에 쉽게 유도될 것으로 생각하기 쉽다. 그러나 불행히도 현재 그림 2 의 예는 인위적으로 간단히 만든 것이다. 현실적인 생성 시스템의 경우에는 수백 혹은 수천 개의 규칙을 지니게 된다. 만일 이렇게 큰 시스템의 경우, 단지 Z 를 찾기 위해 전향연결을 이용한다면 Z 와 관계없는 수 많은 규칙을 수행하게 될 것이다. 즉, 수많은 상황과 큰 추론사슬이 나타나는 것이다. 이들 모두가 옳기는 (valid) 하지만 Z 와는 무관할 것이다. 따라서 목표가 단순히 Z 와 같은 하나의 주어진 사실만을 추론하는 것이라면 전향연결은 많은 시간과 메모리 용량을 낭비하게 된다.
이런 경우는 후향연결 (backward chaining) 이 더욱 효율적이다. 이 추론방법에서는 시스템이 증명하고자 하는 것, 즉 Z 가 존재하는지의 여부로부터 출발하여 Z 를 얻기 위한 규칙만을 수행할 수 있다. 그림 4 는 동일한 문제에 대하여 후향연결에 의한 방법을 보인다.

그림 4 후향연결 (backward chaining) 의 예)
1 단계에서 시스템은 상황 Z 가 존재하는지를 증명하도록 한다. 우선 Z 가 작업 메모리에 있는가를 보고 그렇지 못한 경우는 Z 를 규칙의 행동부에서 찾는다. 규칙 F & B → Z 를 찾아 Z 를 얻으려면 F 와 B 를 구해야 한다는 것을 안다.
2 단계에서 시스템은 'F' 를 얻으려 하고, F 는 그 자체가 작업 메모리에는 없으나 규칙 C & D → F 를 발견, F 를 얻기 위하여 C 와 D 를 얻어야 한다는 것을 안다.
3 단계로부터 5 단계 사이에서 시스템은 C 를 작업 메모리 내에서 찾아내나 D 를 얻기 위해서는 A 를 얻어야 한다는 것을 알게 되고, A 를 작업 메모리에서 찾아낸다.
6 단계에서 8 단계까지에서 시스템은 세번째 규칙을 수행하여 D 를 얻고 두번째 규칙을 수행하여 F 를 얻고, 마지막으로 첫번째 규칙을 수행하여 주어진 원래의 목표 Z 를 얻어낸다.
여기서의 추론사슬은 전향연결에 의하여 얻어진 것과 동일하다. 두 방법은 작업 메모리의 데이터와 생성 메모리의 규칙을 찾는 방법에서 차이가 있다. 이때 후향연결과 유도법 (abduction) 에 의한 추론과의 차이를 명심하여야 한다. 후향연결은 'IF A THEN B' 와 'A' 가 주어져 있을 때 'B' 를 추론할 필요가 있는가를 살펴보고, 필요시에 'A' 로부터 'B' 를 얻어내는 연역법이다. 반면 유도법은 'IF A THEN B' 와 'B' 로부터 'A' 를 유도하는 것으로 규칙의 조건부를 추측하여 내는 것인데 연역법에 의한 후향연결과 근본적으로 다름을 알아두기 바란다.
앞에서 우리는 추론사슬을 아무런 설명없이 사용하였다. 이제 추론사슬에 대하여 보다 상세히 살펴 보기로 하자. 그런데 추론사슬보다 추론회로 (inference net) 가 더 일반적으로 우선 추론회로에 대하여 생각해 보겠다.

그림 5 추론회로를 나타내는 그림
추론회로란 규칙들의 연결상태를 나타내는 것으로 한 규칙의 행동부에 있는 사실들이 어떤 산출의 조건부에 포함되는가를 회로로 나타낸다. 그림 5 는 이전에 예로 든 동물인식 시스템 IDENTIFIER 의 규칙 부분을 나타낸 것인데 조건부의 여러 조건이 동시에 만족되어야 함을 논리회로 (logic circuit) 에서 사용되는 AND 게이트 심볼로써 나타내었다. 하얀 막대는 다른 규칙으로부터 얻어지지 않는 사실들을 나타내고, 검은 막대는 유도된 사실을 나타낸다 (여기서 규칙 Pn 을 In 으로 표시하였다).
추론회로를 나타내는 다른 방법은 4 장에서 논의한 AND/OR 트리를 이용한 것이 있다. 바닥은 최초의 작업 메모리에 저장된 사실들이고, 이들로부터 생성규칙에 의하여 얻어질 수 있는 결론은 꼭대기에 나타난 바와 같이 두 가지가 된다. 어느 생성규칙들의 모임이라도 이러한 트리를 구성하게 된다. 보통 AND/OR 트리의 경우와 마찬가지로, 끝 (tip) 노드로부터 만족되는 AND/OR 트리를 얻을 수 있다면 최상 노드 (top node) 에 해당되는 결론은 증명되는 것이다.
그림 6 에서 노드와 노드를 연결하는 각 가지 (branch) 들은 하나의 규칙에 해당된다. 단, AND 로 연결된 경우에는 연결된 가지들이 하나의 규칙을 나타낸다. 빈 원 (끝 노드) 은 규칙으로부터 유도되지 않은 사실을, 검은 원은 유도된 사실을 나타낸다. 점선으로 연결된 노드는 같은 내용임을 나타낸다. 이 회로는 그림 5 의 추론회로로부터 얻어진다.

그림 6 산출법칙들의 모임으로써 암시되어진 AND/OR 트리를 명백히 하기 위하여 그려진 추론회로
생성 시스템의 크기 및 복잡성이 점차적으로 증가함에 따라 생성 메모리 내에 있는 규칙의 조건부와 행동부도 따라서 확장되었다. 아울러 많은 시스템에서는 규칙의 조건부가 임의의 복잡한 조건을 검토하기 위한 LISP 프로그램인 경우도 있다.
한편, 어떤 시스템에서는 조건부를 검토하는 것이 일종의 부수적 효과 (side effects), 를 나타내어, 실제 이 규칙의 미수행에도 불구하고 작업 메모리의 내용이나 인터프리터의 내용을 변화시키는 경우도 있다. 또는 행동부에 변수 (variable) 들을 포함, 이 변수의 값이 각 주기에서 조건 검토시에 주어져 (bounding) 단순히 작업 메모리를 변화시키는 이상의 임의의 프로그램을 수행시키도록 하는 것도 있다. 이러한 프로그램은 종종 문제분야에서 정하여진 개념적 원시묘사 (conceptual primitive) 를 이용하여 행동을 지정하게 된다. [Rie. 75b] 나 [Ryc. 76] 에서는 이러한 행동이 다른 생성을 수행시키거나 금지시키기도 한다. 이런 것들은 모두 초기의 생성 시스템의 형태로부터 많은 변화를 보여준다.
생성 시스템의 주기는 크게 세 가지의 단계가 있다. 즉, 수행 가능한 생성을 찾는 매칭 단계, 이러한 생성 중 수행할 하나를 고르는 충돌 해결 (conflict resolution) 단계, 선택된 규칙을 수행하는 실행단계이다. 이 세 단계에서 가장 많은 연산시간 및 자원을 소비하는 것이 매칭이다. 생성 시스템이 점차 커지고 복잡하여 짐에 따라 생성 메모리와 작업 메모리의 데이터 구조를 보다 복잡한 구조로 하기 위하여 효율성에 관한 문제가 필요하게 되었다. 예로써 주어진 상황에 만족하는 규칙을 빨리 찾기 위하여 조건에 따라 규칙을 색인 (indexing) 하거나 분할 (partition) 시켜서 관계된 것을 보다 쉽게 선택할 수 있게 한다 [Len. 77]. 혹은 필터 (filter) 를 사용하는 방법도 있는데 각 규칙에서 서술 (predicate) 에 해당하는 주요 특징 (primary feature) 을 정의하여 새로운 주요 특징이 작업 메모리에 삽입되거나 제거될 때 이에 영향을 받는 규칙을 필터를 이용하여 쉽게 찾는 것이다 [McD 78a]. 작업 메모리 내의 구조도 보다 복잡한 상황을 효율적으로 나타내기 위하여 다양하게 되었다 (MYCIN 의 Context tree [Sho 76], HEARSAY 의 Blackboard [Erm. 75], PROSPECTOR 의 semantic nets [Dud. 78] 등에서 그러한 예를 찾아볼 수 있다).
전형적인 큰 생성 시스템의 동작에 있어서 각 주기에서 수행 가능한 규칙이 하나 이상인 경우가 많다. 이들 수행 가능한 규칙들의 집합을 충돌집합 (conflict set) 이라고 하며, 시스템은 이들 중 하나를 선택하여야 한다. 이를 위하여 다음을 포함한 여러 정책이 제시되어 왔다.
|
1. 작업 메모리에 의하여 만족되는 최초의 규칙 : 여기서 최초라 함은 규칙이 생성 메모리에 놓인 순서를 말할 때 제일 앞에 놓인 것이다. 2. 가장 높은 우선순위 (priority) 를 가진 규칙을 선택 : 이를 위하여 프로그래머는 문제 분야의 성격에 따라 각 규칙에 적당한 우선순위를 부여한다. 3. 현재의 작업 메모리에 만족되는 가장 특수한 (specific) 규칙, 즉 가장 세분화된 조건을 갖는 규칙. 다시 말하면 조건부를 구성하는 논리곱요소 (conjunct) 가 가장 많은 규칙. 4. 작업 메모리에 삽입된 가장 최근의 정보에 만족되는 규칙. 5. 가장 새로운 규칙. 즉 이전에 수행되지 않았던, 혹은 수행되었더라도 다른 변수값으로 수행되었던 규칙. 6. 임의의 규칙. 7. 순서에 상관없이 만족되는 모든 규칙을 병행하여 수행. |
여러 다른 생성 시스템은 이렇게 간단한 충돌 해결 방법 중의 서로 다른 조합을 사용하고, 어떤 것은 아주 복잡한 스케쥴링 알고리즘 (scheduling algorithm) 을 사용하기도 한다.
충돌 해결에 관하여 보다 상세한 논의는 [McD 78b] 에서 취급되어 있다.
우리는 생성 시스템이 전향 (forward) 와 후향 (backward) 의 두 가지 방향으로 운영될 수 있음을 논의하였다. 이 중 어느 것이 좋은가 하는 문제는 추론의 목적과 문제분야의 성격에 의하여 결정된다. 목적이 주어진 사실로부터 유도 될 수 있는 모든 것을 찾아내기 위한 것이라면 분명히 전향연결 (forward chaining) 을 사용하는 것이 바람직할 것이다.
반면에 목적이 어떤 특별히 주어진 결론을 입증하거나 부정하고자 하는 것이라면 그러한 결론으로부터 반대방향으로 출발하는 후향연결 (backward chaining) 이 바람직할 것이다. 이는 불필요한 사실의 유도를 막기 위함이다. 주어진 전제로부터 후향연결하는 것은 적당한 규칙이 존재하는 한 주어진 결론이 입증되기까지 계속된다. 만일 더 적용할 규칙이 없을 때는 입력장치를 통하여 정보를 입수하거나 시스템 사용자에게 문의하게 된다.
생성 시스템을 포함한 규칙 (rule) 을 이용한 시스템은 그의 추론 과정을 설명할 수 있는 장점을 지닌다. 즉, 왜 (why) 어떤 사실이 사용되었거나 어떻게 (how) 어떤 사실을 얻어낼 수 있었는가에 대해 답할 수 있는 능력을 갖는다. 이러한 능력의 대부분은 표현구조가 단순하고 또 상당히 제약을 받는 규칙의 형태에 의하여 얻어진다. 주어진 사실에 대한 결론 방법을 설명하려면, 이 사실을 행동부에 포함시킨 규칙을 찾으면 된다.

그림 7 추론 과정에 대한 설명 능력
예로써 그림 7 을 생각해 보자. 이는 1 절에서 두번째로 주어진 예의 일부분이다.
여기서 I6 는 앞선 예의 규칙 P6 로 간주하여라. 만일 질문이 "어떻게 (how) 동물이 육식류임을 알았는가" 였다면 답변은 왼쪽으로 이동하여 얻어진, "규칙 P6 가, 동물이 포유류이며, 날카로운 이와 턱, 전방을 향하는 눈을 가졌다고 알기 때문" 이다. 만일 질문이 "왜 (why) 동물이 포유류인 것을 알려고 하였는가?" 라면, 오른쪽으로 이동하여 "왜냐하면 동물이 육식류임을 보이는 규칙 P6 를 사용하기 위해서" 라고 대답하면 된다. 다시 말하면 "어떻게 (how)" 에 관한 질문은 후향 (backward) 으로 한 단계 추적하여 관계된 규칙들과 조건부들을 언급하면 되고, "왜 (why)" 에 관한 질문은 전향 (forward) 으로 한 단계 진행하여 대답하면 된다.
지식 표현을 조건들과 이에 따른 행동으로 표현하는 생성규칙으로써 나타내었을 때는 문제 해결 능력과 표현의 유연성 (flexibility) 에 제약을 받기는 하지만, 기본적인 문제풀이기구에 흥미로운 여러 가지 기능을 첨가시킬 수 있다. 예로써 왜 (why) 와 어떻게 (how) 를 위한 응답기능은 단순히 규칙과 규칙이 사용된 과정을 기억함으로써 실현되었다.
비교적 손쉬운 다른 기능으로써 생성 메모리 (production memory) 구성시에 필요한 새로운 규칙을 만들기 위한 지식 전달 기능을 생각할 수 있다. 예로써, '왜' 와 '어떻게' 를 이용한 질문을 충분히 한 결과, '살그머니 접근하는 (stalking) 동물은 육식류이다.' 라는 또 하나의 규칙이 필요하다는 것을 알게 되었다고 하자. 이에 다음과 같은 새로운 생성 규칙을 제시하게 되었다.
|
규칙 P16a. IF the animal stalks a different kind of animal THEN it is a carnivore |
그러나 무엇인가 빠진 것이 확실하다. 동물이 육식류임을 추론하는 다른 여러 규칙과 비교하여 볼 때, 여기서 동물이 포유류이어야 한다는 조건이 빠진 것을 알 수 있다. 지식 전달 프로그램은 이를 알아차리고 이 조건이 의도적을 빠진 것인가의 여부를 물어볼 수 있다. 결과로 보다 세분화된 규칙인
|
규칙 P16b. IF the animal is a mammal AND the animal stalks a different kind of animal THEN it is a carnivore |
을 얻을 수 있다. 이상을 이해하면, 보다 더 일반화된 지식 획득 프로그램을 가상해 볼 수 있다. 이는 새로운 규칙을 기존의 규칙과 비슷한 형태로 만들도록 권장한다. 예로써, 현재까지 얻어진 규칙들을 이들이 유도하는 결론에 따라 구분한다. 우리의 예에 대하여 분류한 경우가 그림 8 에 주어져 있는데, 각 분류된 그룹은 상호 종적으로 연결되어 있다.

그림 8 생성 시스템에서의 법칙들은 행동부에 포함된 결론에 따라 그룹을 형성한다.
각 규칙 그룹에 대하여, 이에 포함되는 요소 (member) 는 이 그룹에 속한 규칙의 모든 조건 및 행동이, 예로써 30 % 이상 나타난 것들을 모아서 형성한다. 이렇게 함으로써, 이 그룹에 속하여지는 규칙들의 전형적인 형태를 알 수 있다. 동물의 육식류임을 추론하는 규칙 그룹에서는 이러한 조건으로써 동물이 포유류일 것과 또 이러한 행동으로써 동물이 육식류일 것이 해당된다.
|
법칙 : 전형적인 육식류 : IF the animal is a mammal THEN it is a carnivore |
이러한 전형적인 규칙의 형태를 구성한 후, 새로운 규칙의 형태와 비교하여 차이가 있다면 그 차이가 의도적인지의 여부를 새로운 규칙을 삽입하는 이에게 묻는 규칙 비교 기능을 추가시킬 수도 있다.
현실적인 응용에서의 생성 시스템이 유도하여 내는 결론은 항상 100 % 옳지는 않다. 따라서 종종 기본적인 생성 시스템의 구조에는 확신 정도를 계산하여 내는 부분이 준비된다.
일반적으로 확신 정도는 0 부터 1 사이의 값을 각 사실에 대하여 부여한다. 이 수치를 확신율 (certainty factor) 이라 하고, 관계된 사실이 얼마나 확실한가를 반영하는데, 0 은 완전히 그릇된 것을, 1 은 완전히 확실한 것을 나타낸다 (어떤 시스템에서는 -1 로부터 +1 까지의 값을 쓰기도 하는데 이 경우에는 -1 이 완전한 잘못, +1 이 완전한 확신, 그리고 0 이 알 수 없음을 나타낸다).
확신율의 계산이 실용적으로 매우 중요하므로 잠시 이에 대하여 생각하여 보기로 한다. 앞으로 논할 어떤 방식도 완전한 것은 아님을 잘 알아두기 바라며, 여기서는 무엇을 해야한다는 것보다 무엇을 할 수 있다는 예를 제시하는 것으로 만족하려 한다.
알아두어야 할 점은 확신율을 계산하는 프로그램이 다음의 세 가지 질문에 대한 답변을 수용하여야만 한다는 것이다.
첫째, 각 규칙 조건부의 각 조건에 부여된 확신율이 규칙의 전체조건의 확신율 (입력확신율 : input certainty) 에 어떻게 관계되는가?
둘째, 규칙 그 자체에 있어서 어떻게 입력확신율이 행동부의 확신율 (출력확신율 : output certainty) 에 영향을 주는가?
셋째, 여러 규칙의 결론이 같은 사실을 추론할 때, 이 사실의 확신율은 어떻게 결정되는가 하는 것이다 (이 경우, 소위 말하는 복합 논의 확신율 (multiply argued certainty) 이다.
그림 9 어떤 생성 시스템은 각 유도된 사실의 확신을 평가하기 위한 부분을 갖는다. 여기서는 이를 위한 간단한 예이다. (a) 에서는 전체 조건부의 확신율을 제일 작은 값으로 간주한다. (b) 에서는 산출의 행동부에 대한 확신율을 입력확신율에 감쇠율을 곱한 값으로 처리한다. (c) 에서는 유도된 사실의 확신율 이를 뒷받침하는 가장 큰 값으로 한다. 이러한 세 가지 방식은 기본적인 확률이론에는 위배되는 부적합한 것으로 간주될지도 모른다.
이에 대한 간단한 임기응변식의 방법으로 다음과 같은 것을 생각할 수 있다.
그림 10 은 확신율을 동물원의 예에서 얻어진 추론회로에 대하여 계산하였다. 이 경우는 분명히 호랑이 (tiger) 에 대한 가설 (hypothesis) 이 얼룩말 (zebra) 에 대한 가설보다 신뢰성이 높다.

그림 10 이 예에서 얼룩말은 확신율이 0.16 으로 신뢰성이 호랑이의 경우인 0.4 보다 낮다.
다른 방법으로 확률론적 접근방법을 생각할 수 있는데, 이는 확률이론에 대한 기본지식이 필요하므로, 여기서는 간단히 이러한 접근방법의 내용만을 요약하도록 한다.
이 개념의 가장 간단한
실현 방법은 각 조건의 확신율의 곱을 전반적인 입력확신율로써 사용하는 것이다.
이 생각은 여러 사건이 동시에 일어나는 복합사건 (joint event) 의 확률은,
여기에 참여하는 각 사건들이 서로 영향을 미치지 않는 한 각 사건의 확률을 곱한
것과 같다는 이론에서 나온 것이다. 동전을 던져서 앞면이 두 번 나올 확률은, 한
번 던져 앞면이 나올 확률을 두 번 곱한 것과 같다. 즉, 조건의 수가 n 개이고 각
조건의 확률을 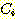 라고 하면, 전체확률은
라고 하면, 전체확률은
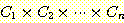
으로 나타낼 수 있다. 이 방법에서의 문제는 각 조건들이 서로 독립적 (independent) 이어야 한다는 예비조건이다. 동전던지기의 예를 들면, 두 번 던질 때 각각은 서로 독립적이어서 한 번 던졌을 때의 결과가 다음 번에 아무런 영향을 미치지 않는다. 그러나, 생성 규칙의 조건들은 종종 서로 의존하며 비독립적이므로 곱하는 방법이 적당치 않는 수가 많다. 이런 경우 확률이론에 의해 정당화 되지 못한다.
일단 입력확신율이 얻어지면 다음에는 출력확신율을 얻어야 한다. 이를 위해서는 보통 관계된 문제분야의 전문가에게 의뢰하여 입ㆍ출력을 관계짓는 그림 11 (a) 와 같은 함수를 얻는다. 보여진 바와 같이 이 경우 입력확신율이 1 일 때 출력은 0.8 이고, 입력이 0 일 때 출력도 0 이며, 입력이 그 사이일 때는 출력이 (0, 0) 과 (1, 0.8) 을 연결하는 직선상에 놓인다.
실제로 이 특별한 함수는 감쇠율을 0.8 로 사용한 것과 완전히 같은 결과를 낳는다. 그러나 11 (b) 의 직선이 원점을 통과하지 않으므로 감쇠율을 상요한 것과는 다르다. 명백히 입력이 0 일 경우에도 출력은 0.2 를 갖는다. 이는 결과가 참 (true) 이기 위하여 조건이 참이어야 할 필요가 없음을 의미한다. 그림 11 (a) 나 11 (b) 와는 다르게 대부분의 함수는 두 개의 다른 기울기를 갖는 선분들로 구성된다. 이는 입력확신율과 출력확신율 간의 관계가 끝점 관계만을 반영하는 것이 아니라, 분석 전 평가값 (before analysis estimate) 도 반영해야 하기 때문이다. 분석 전 평가값은 선험값 (a priori value) 이라고도 불리우는데 현재 주어진 특별한 경우에 대하여 아무런 정보도 없을 때의 확신율을 나타낸다. 만일 예로써 모든 동물들에 대하여 머리털 (hair) 을 갖는 확률이나 포유류일 확률을 특수한 동물을 살펴 보기 전에 정한다면 우리는 선험 (a priori) 확신율을 주게 되는 것이다.
선험값의 사용이 그림 11 (c) 에서 설명되는데 여기서는 입ㆍ출력 관계를 나타내는 선이 입력선험값 0.5 와 출력선험값 0.5 를 지닌다. 이러한 두 기울기를 갖는 선은 입ㆍ출력관계를 나타내기 위하여 필요하다. 엄밀히 말해, 고전적인 확률이론에 의하면 인간으로부터 자아내는 모든 점은 직선상에 놓아야 한다. 그러나 분명한 것은, 사람에 관한 것이 항상 수학적으로 모델링될 수 많은 없다.

그림 11 입출력 확신율을 관계짓는 세 함수
마지막으로, 여러 규칙들이 같은 사실을 유도하는 복합 논의 확신율 (multiply argued certainty) 의 경우를 계산하기 위해서는 확신비율 (certainty ratio) 을 사용하여야 한다. 확신율 c 와 확신비율 r 은 다음처럼 관계될 수 있다.

확신율 0.5 는 확신비율 1 에 해당됨을 잘 알아두기 바란다.
각 규칙에서 출력확신율을 확신비율로 변환한 뒤, 복합 논의된 사실의 확신비율은 다음과 같이 주어진다.
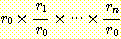
여기서 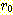 는 사실의 선험확신율을 확신비율로 바꾼 값이고
는 사실의 선험확신율을 확신비율로 바꾼 값이고  는 관여된 규칙의 입ㆍ출력함수로부터 얻어진 확신율에 해당되는 확신비율값이다.
이 수식은 어떤 사실이 0.5 선험 확신율을 (이때는 확신비율
는 관여된 규칙의 입ㆍ출력함수로부터 얻어진 확신율에 해당되는 확신비율값이다.
이 수식은 어떤 사실이 0.5 선험 확신율을 (이때는 확신비율  ) 가질 때는 결국 확신비율의 곱으로 나타남을 잘 알아두기 바란다. 이렇게 하여
얻은 확신비율은 다시 확신율로 변환함으로써 복합 논의확신율을 얻게 된다.
) 가질 때는 결국 확신비율의 곱으로 나타남을 잘 알아두기 바란다. 이렇게 하여
얻은 확신비율은 다시 확신율로 변환함으로써 복합 논의확신율을 얻게 된다.
이 수식을 입증하기 위하여서는 확률이론에 대한 많은 지식이 필요하고 이는 이 책의 범위를 넘는다. 그러나 복합논의 결론의 확신율을 계산하기 위하여 확신비율로 확신율로 바꾼다는 것은 상당히 중요한 것을 생각하게 한다. 즉, 주어진 문제가 현재 표현 방법으로 풀기 어렵다고 생각되면, 문제가 보다 쉽게 풀릴 수 있는 다른 표현으로 변환하여 본다. 확신비율로 변환하는 것은, 곱하기를 편하게 하기 위한 로그 (log) 로의 변환, 콘벌루션 (convolution) 을 하기 위한 푸리에 변환 (Fourier transform) 등과 같은 것이다.
마지막으로 다음 그림 12 를 생각해 보자.

그림 12 확신율을 구하기 위한 추론회로 과정
그림 12 에서 (a) 는 조건부의 확신율을 곱하여 입력확신율을 산정하였고, (b) 는 입출력함수에 의하여 출력확신율을 계산한 것이고, (c) 는 복합 논의 확신을 확신비율로 변환시켜 곱한 뒤 다시 확신율로 환원시켜서 얻은 것이다.
여기서 입력부의 확신율은 조건의 확신율에 대한 곱으로 얻어졌다. 즉, 결과의 값은 조건 중 최소인 0.5 가 아니라 0.45 가 된 것이다. 일반적으로 입력부의 확신율 값은 최소의 값을 갖는 조건 확신율의 값보다 작거나 같게 된다.
그림 12 (b) 에서 출력확신율이 입출력함수에 의하여 결정되었다. 이 경우는 감쇠율을 사용하는 것과 같아져 결과의 출력확신율이 0.4 가 되었다. 그림 12 (c) 에서는 복합 논의 (multiply argued) 결과의 경우인데, 이는 각 확신율을 확신비율로 변환시켜 곱한 뒤, 다시 확신율로 변환시킨 것이다. 결과는 0.9 가 아닌 0.75 가 되었다. 여기서 이 결과는 선험값이 0.5 이다. 확신율 0.5 는 이 사실에 대하여 아직 참, 거짓을 말할 수 없는 중간값이 된다. 새롭게 얻어진 결과의 확신율이 0.75 로써 최대의 것인 0.9 보다 작아진 이유는, 다른 규칙에서는 이 결과가 0.25 의 확신율을 갖고 이는 0.5 보다 작으므로 이 결과에 대하여 부정적인 입장을 취하고 있기 때문이다.
생성 시스템은 음성 이해 (speech understanding), 의료 진단 (medical diagnosis), 광물 탐사 등 사람이 처리하는 특정한 (specific) 현실적인 업무에 관한 지식을 나타내는 인공지능 시스템에서 자주 사용되어 왔다. 심리학 등에서도 생성 시스템은 인간의 행동을 모델링하는 방법으로 사용되어 왔는데, 이는 아마도 생성규칙의 구성 형태가 자극에 대한 응답 (stimulus-response) 형태이기 때문이라 생각된다. 생성 시스템에 기본을 둔 인공지능 시스템은 응용에 따라 여러 측면에서 아주 다양하지만, 이러한 생성 시스템의 형식에는 일반화시켜서 논의할 수 있는 장단점이 있다.
생성 시스템의 명백한 특성 중 하나는 생성 메모리 (production memory) 내의 규칙이 다른 규칙에 영향을 주지 않고 독립적으로 첨가되거나 제거 또는 변화될 수 있다는 것이다. 이들 규칙은 마치 독립적인 '지식의 조각' 과 같이 다루어진다. 어떤 규칙을 바꾸게 되면 전체 시스템의 성능에는 다소의 변화가 올지 몰라도, 다른 규칙에는 직접적인 영향을 주지 않는다. 이는 규칙들의 연결이 오직 작업 메모리를 통해서만 이루어지고 있기 때문이다 (규칙의 조건은 작업 메모리에 의하여서만 만족되고, 또 수행시 작업 메모리에만 영향을 주는 것이 전형적이다).
즉, 규칙은 서로 다른 규칙을 직접 부르는 일은 없는 것이다. 이런 서로의 독립성을 모듈성 (modularity) 이라 한다. 규칙에 대한 모듈성은 제시된 규칙의 의미와 사용되는 경우를 알아야 하는 인공지능 시스템처럼 큰 생성 메모리가 필요한 경우, 생성 메모리를 훨씬 쉽게 만들 수 있도록 한다. 그러나 시스템이 점차 커질수록 모듈성은 점차로 유지되기 힘들어지는 경향이 있고, 설사 유지된다 하더라도 규칙 간의 제한된 상관관계는 큰 시스템에서는 중요한 문제인 효율성을 저하시킨다.
생성 시스템의 다른 특성은 저장되는 지식의 균일한 구조이다. 모든 정보가 생성규칙 형태의 제한된 구조를 가지므로, 다른 형태의 비교적 자유스러운 표현 방식, 즉 의미회로 등보다, 다른 사람이나 시스템 내의 다른 부분에서 좀 더 쉽게 이해될 수 있다.
생성 시스템 방식의 다른 이점은 지식의 몇 가지 중요한 종류를 쉽게 표현할 수 있다는 것이다. 특별히, 미리 정하여진 '상황 (situation)' 에 대하여 '무엇을 할 것인가 (what to do)' 의 지식은 생성규칙으로써 자연스럽게 표현할 수 있다. 더우기, 전문가들의 문제 해결 방법을 설명하기 위하여 자주 사용되는 종류의 지식이 바로 이런 형태인 것이다.
그러나 생성 시스템에는 선천적으로 중요한 단점이 있다. 이 중에 하나가 프로그램 수행의 비효율성이다. 규칙의 강한 모듈성과 균일성이 문제 풀이에 사용될 때는 많은 비용을 지출하게 된다. 예를 들면, 생성 시스템은 매치-행동 (match-action) 주기에 의하여 수행된다. 그런데 생성 시스템은 개별적인 상황에 대하여 행동을 부여하는 생성규칙에 의하여 구성되므로, 미리 정해진 일련의 상황에 대치하거나 혹은 일련의 상황의 요구시, 보다 큰 단계의 추론은 불가능하거나 상당히 비효율적이게 된다.
생성 시스템 형식의 두번째 단점은 문제 풀이에서 제어 (control) 의 흐름을 추적하기가 어렵다는 것이다. 다시 말하자면, 상황의 반응을 나타내는 지식은 자연스럽게 나타낼 수 있지만, 알고리즘적 (algorithmic) 인 지식은 통상적인 프로그래밍 언어를 사용할 때보다 자연스럽지 못하게 된다. 이는 규칙들이 서로를 부르지 않아 격리되어 있고, 규칙들의 크기가 일정하여 한 규칙이 여러 다른 규칙들로 구성되는 것이 불가능하기 때문이다. 반면에, 프로그래밍 언어에서 제공되는 함수 (function) 나 서브루틴 (subroutine) 같은 것은 제어의 흐름을 이해하기 쉽게 해준다.
앞절에서는 생성 시스템의 성격을 장단점으로 구분하여 설명하였다. 생성 시스템의 유용도를 평가하기 위한 보다 나은 방법은 생성규칙 지식 표현 방법으로 적절히 사용될 수 있는 분야의 규정이다. [Dav. 77] 에서는 다음과 같은 분야를 적당한 것으로 밝혔다.
1. 지식이 많은 사실들로 구성되어 널리 퍼져 있는 분야, 예로써 의료분야, 이에 상반되는 분야로 간결하고 통일된 이론이 있는 물리학 등이 있다.
2. 문제의 처리 과정이 독립된 행위의 모임으로 표현될 수 있는 분야, 예로써 의료의 환자 검사 시스템 분야. 이와 상반된 분야로는 서로 관계된 세부 처리 과정으로 행해지는 급료 계산 등의 프로그램이 있다.
3. 사용하는 법으로부터 쉽게 구분되는 지식을 이용하는 분야, 예로써 생물학에서 사용되는 분류학적 분류법, 이와 상반되는 분야로는 표현과 이의 제어가 합쳐진 처방등이 있다.
[Ryc. 76] 은 이런 적당한 성격을 다음과 같이 인공지능에서 사용하는 용어로 정의하였다.
'만일 문제공간 (problem space) 에서 주어진 업무를 한 상태로부터 다른 상태로 변환되는 일련의 변환으로 간주할 수 있다면, 이런 동작을 생성 시스템으로 나타낼 수 있다. 이는 각 변환을 하나 혹은 그 이상의 규칙 수행에 의해 효과적으로 나타낼 수 있기 때문이다'.
다음의 예는 인공지능에서 연구된 중요한 생성 시스템이다.
[Wat. 70] 은 포커 게임을 위한 적응 생성 시스템 (adaptive production system) 을 실현하였다. 이 프로그램이 적응적인 (adaptive) 이유는 자동적으로 자신의 생성 메모리의 규칙을 변화시키는 능력이 있기 때문이다. 처음에는 포커 게임을 위한 아주 간단한 지식 (휴리스틱한 지식) 을 갖고 시작하나 회가 거듭할수록 실제 게임을 통하여 경험을 쌓아 규칙들을 확장하고 향상시켜 나간다. 이러한 생성 시스템에서는 지식이 제한된 모듈러 (modular) 형태를 취하게 되므로, 프로그램의 형태 분석과 변형이 쉬워 학습 (learning) 이 가능해 지는 것이다. [Sho. 76] 과 [Dav. 77] 의 MYCIN 시스템은 의료 자문용 전문가 시스템 (expert system) 인데 의료진과의 대화를 통해 자신의 추론 과정을 설명할 수 있는 능력을 구비하고 있다. MYCIN 은 또한 TEIRESIAS 라는 지식 획득 (knowledge acquisition) 프로그램을 운영하는데 이는 의료진의 생성 메모리의 내용 확장 및 변경에 도움을 준다. MYCIN 의 생성 메모리는 전문의료인의 지식을 나타내는 수백 개의 규칙을 저장하고 있다. MYCIN 은 특별히 후향연결 (backward chaining) 에 의한 추론을 하고, 확신율을 사용하여 가능한 진단을 결정하여 주기도 한다. 이러한 전문가 시스템에 대하여서는 8 장에서 자세히 논의될 것이다.