Bruce G. Buchanan Richard O. Duda 1982
An expert system is a computer program that provides expert-level solutions to ˇ®important problems and is:
The
key ideas have been developed within Artificial Intelligence (AI) over the last
fifteen years, but in the last few years more and more applications of these
ideas have been made. The purpose of this article is to familiarize readers
with the architecture and construction of one Important class of expert systems,
called rule-based systems. In this overview, many programs and issues are necessarily
omitted, but we attempt to provide a framework for understanding this advancing
frontier of computer science.
Because
computers are general symbol manipulating devices, the non-numeric and heuristic
aspects of problem solving can be encoded in computer programs as well as the
mathematical and algorithmic aspects [Newel176].Artificial Intelligence research
has focused on just this point. Work on expert systems is, in one sense, the
applied side of AI, in which current techniques arc applied to problems to provide
expert-level help on those problems. However, there is more to building an expert
system than straightforward application of AI techniques. In this early stage
of development, each new application challenges the current stock of ideas,
and many applications force extensions and modifications.
We
focus on rule-based systems in this survey because they clearly demonstrate
the state of the art in building expert systems and illustrate the main issues.
In a rule-based system, much of the knowledge is represented as rules, that
is, as conditional sentences relating statements of facts with one another.
Modus ponens is the primary rule of inference by which a system adds new facts
to a growing data base:
IF B IS TRUE B
AND B IMPLIES C, OR B --> c
THEN C IS TRUE. --------
C
Conceptually,
the basic framework of a rule-based. system is simple; the variations needed
to deal with the complexities of real-world problems make the framework interestingly
more complex. For example, the rule B-X is often interpreted to mean ˇ°B suggests
Cˇ±, and strict deductive reasoning with rules gives way to plausible reasoning.
Other methodologies are also mentioned and briefly discussed.
In an expert system
the fundamental assumption is ˇ°Knowledge is Powerˇ±. Specific knowledge of
the task is coupled with general problem solving knowledge to provide expert-level
analyses of difficult situations. For example, MYCIN (described below) analyzes
medical data about a patient with a severe infection, PROSPECTOR [Duda79] analyzes
geological data to aid in mineral exploration, and PUFF [Kunz78] analyzes the
medical condition of a person with respiratory problems. In order to provide
such analyses, these systems need very specific rules containing the necessary
textbook and judgmental knowledge about their domains.
The key idea is
to separate knowledge of the task area as much as possible from the procedures
that manipulate it. This promotes flexibility and transparency because the store
of knowledge -- called the knowledge base -- can then be manipulated and examined
as any other data structures. Separation does not guarantee flexibility or transparency,
nor does it guarantee high performance. But if a packaged framework of inferences
and control procedures can be used, the design of a new system properly focuses
on the expertise needed for high performance.
For many years,
AI research has focused on heuristic reasoning. Heuristics, or rules of thumb,
arc an essential key to intelligent problem solving because computationally
feasible, mathematically precise methods are known for only a relatively few
classes of problems. A large part of what an expert system needs to know is
the body of heuristics that specialists use in solving hard problems. Specialists
in science, mathematics, medicine or any discipline do not confine their everyday
reasoning to the axiomatic, formal style of stereotyped textbook accounts. An
expert system can also benefit from reasoning with informal knowledge. There
is no explicit attempt .to simulate a specialistˇŻs problem solving behavior
in an expert system. However, the system derives power from integrating the
same heuristic knowledge as experts USC with the same informal style of reasoning.
The first expert systems, DENDRAL [Lindsay80] and MACSYMA [Moses71], emphasized
performance, the former in organic chemistry and the latter in symbolic integration.
These systems were built in the mid-1960ˇŻs, and were nearly unique in AI because
of their focus on real-world problems and on specialized knowledge. In the 1970ˇŻs,
work on expert systems began to flower, especially in medical problem areas
(see, for example [Pople77, Shortliffe76, Szolovits78, Weiss79b]). The issues
of making the system understandable through explanations [Scott77, Swartout81]
and of making the system flexible enough to acquire new knowledge [Davis79,
Mitchell79] were emphasized in these and later systems.
In the early work,
the process of constructing each new system was tedious because each was custom-crafted.
The major difficulty was acquiring the requisite knowledge from experts and
reworking it in a form fit for machine consumption, a processˇŻ that has come
to be known as knowledge engineering. One of the most important developments
of the late 1970ˇŻs and early 1980ˇŻs is the construction of several knowledge
engineering frameworks designed to aid in building, debugging, interpreting,
and explaining expert systems. ˇŻ Engineering an expertˇŻs knowledge into .a
usable form for a program is a formidable task. Thus computer-based aids for
system builders are important. Current tools -- including EMYCIN [vanMelle80]
ROSIE [Fain81], KAS[Reboh81], EXPERT [Weiss79a], and OPS [Forgy77] -- provide
considerable help. For example, working prototypes of new expert systems with
one or two dozen rules have been constructed in a few days using EMYCIN [Bennett81a].
Considerable effort is then required to refine the knowledge base, but the effort
is focused on the knowledge and not on the code. Much research remains, however,
before broad, powerful systems can be constructed quickly.
![]()
MYCIN is a rule-based
system developed in the mid-late 1970ˇŻs at Stanford University. Its representation
and architecture are described in detail in [Davis77b] and [Shortliffe, 1976].
Although it is now several years old, it is representative of the state of the
art of expert systems in its external behavior, which is shown in the following
excerpt from a dialogue between the MYCIN program and a physician. It illustrates
the interactive nature of most rule-based systems and provides a single example
for the rest of the discussion.
The task of MYCIN
is to help diagnose the likely causes of a patientˇŻs infection and to help
recommend the best therapy for that individual patient. The consultation is
driven by a knowledge base of about 450 rules and a thousand facts about medicine,
mostly about meningitis infections. In the example, we see the system asking
questions to obtain a description of a new case, and we see the system providing
an explanation of its line of reasoning.
The main point
of this example is that a simple representation of knowledge as rules, and a
relatively simple control structure, are adequate for constructing a consultation
system in a domain as complex (but narrow!) as meningitis diagnosis and therapy.
Appendix A shows answers to userˇŻs questions about this consultation and about
the knowledge base.
The level of expertise
MYCIN exhibited on meningitis test cases in a double-blind evaluation study
equalled the level of expertise of faculty members in Infectious Diseases [Yu79].
However, the program was never put into routine use in hospitals. Factors other
than the programˇŻs competence, such as human engineering and exportability,
were the main barriers to routine use. There are two ways of overcoming these
kinds of problems. First, some follow-on research to MYCIN addresses the human
engineering problems directly, for example, by integrating high quality graphics
with user-oriented forms and charts for input and output [Shortliffe81]. Second,
some MYCIN-like programs finesse many human engineering problems by collecting
data from on-line instruments rather than from users [Kunz78]. Exportability
can be gained by rewriting [Carhart79, Kunz78] or by designing for export initially
[Weiss79a].
The example showed
some of the characteristic features of an expert system-- the heuristic nature
of MYCINˇŻS rules, an explanation of its line of reasoning, and the modular
form of rules in its knowledge base. We postponed a discussion of the general
structure of a system until after the example, and defer entirely specific questions
about implementation. For discussing the general structure, we describe a generalization
of MYCIN, called EMYCIN [vanMelle80] for ˇ°essential MYCINˇ±. It is a framework
for constructing and running rule-based systems, like MYCIN.
Generally speaking,
an expert system requires a knowledge base and an inference procedure. The knowledge
base for MYCIN is a set of rules and facts covering specialized knowledge of
meningitis as well as some general knowledge about medicine. The inference procedure
in MYCIN (and all systems constructed in EMYCIN) is a large set of INTERLISP
functions that control the interaction and update the current state of knowledge
about the case at hand. The sections below on Representation and Inference discuss
these two main parts. A system also requires a global database of facts known
or inferred about a specific case, the working dataset, in other words. And
it requires an interface program that makes the output understandable to users
and translates usersˇŻ input into internal forms. MYCIN uses a technical subset
of English in which there is little ambiguity in the language of communication
with users.
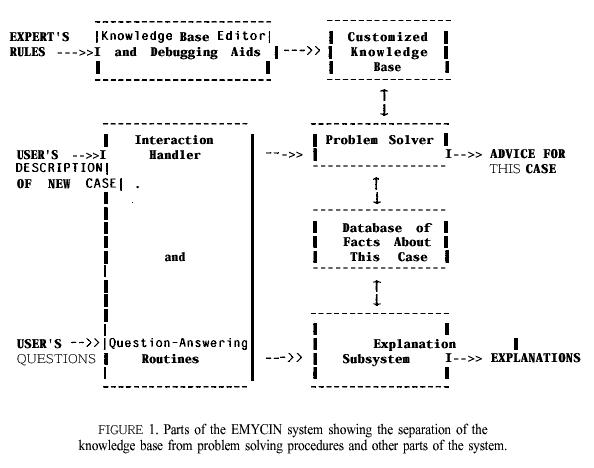
In addition to
these four parts, the EMYCIN system contains an explanation subsystem to answer
questions about a consultation or about the static knowledge base. It also contains
a knowledge base editor to aid in the construction of new knowledge bases (and
thus new systems) and to aid in debugging an emerging knowledge base. All of
these components are shown schematically in the figure below.
We turn now to two basic issues that have become the central foci of work on expert systems: (a) how knowledge of a task area is represented in the computer program, and (b) how knowledge is used to provide expert-level solutions to problems.
![]()
A representation
is a set of conventions for describing the world. In the parlance of AI, the
representation of knowledge is the commitment to a vocabulary, data structures,
and programs that allow knowledge of a domain to be acquired and used. This
has long .been a central research topic in AI (see [Amarel81, Barr81, Brachman80,
Cohen82] for reviews of relevant work).
The results of
25 years of AI research on representation have been used to establish convenient
ways of describing parts of the world. No one believes. the current. representation
methods are the final word.
However, they
are well enough developed that they can be used for problem solving in interesting
domains. As pointed out above, a central concern is separation of the choice
of vocabulary and data structures from the choice of program logic and language.
By separating a programˇŻs knowledge base from the inference procedures that
work with the knowledge, we have attained some success in building systems that
are understandable and extendable.
Three basic requirements
on a representation scheme in an expert system are extendability, simplicity
and explicitness.
Extendability -- the data structures and access programs must be flexible enough to allow extensions to the knowledge base without forcing substantial revisions. The knowledge base will contain heuristics that are built out of expertsˇŻ experience. Not only do the experts fail to remember all relevant heuristics they use, but their experience gives them new heuristics and forces modifications to the old ones. New cases require new distinctions. Moreover, the most effective way we have found for building a knowledge base is by incremental improvement. Experts cannot define a complete knowledge base all at once for interesting problem areas, but they can define a subset and then refine it over many weeks or months of examining its consequences. All this argues for treating the knowledge base of an expert system as an open-ended set of facts and relations, and keeping the items of knowledge as modular as possible.
Simplicity -- We have all seen data structures that were so baroque as to be incomprehensible, and thus unchangeable. The flexibility we argued for above requires conceptual simplicity and uniformity so that access routines can be written (and themselves modified occasionally as needed). Once the syntax of the knowledge base is fixed, the access routines can be fixed to a large extent. Knowledge acquisition, for example, can take place with the expert insulated from the data structures by access routines that make the knowledge base appear simple, whether it is or not. However, new reasons will appear for accessing the knowledge base as in explanation of the contents of the knowledge base, analysis of the links among items, display, or tutoring. With each of these reasons, simple data structures pay large benefits. From the designerˇŻs point of vi& there are two ways of maintaining conceptual simplicity: keeping the form of knowledge as homogeneous as possible or writing special access functions for non-uniform representations. There is another sense of simplicity that needs mentioning as well. That is the simplicity that comes ,from using roughly the same terminology as the experts use. Programmers often find ingenious alternative ways of representing and coding what a specialist has requested, a fact that sometimes makes processing more ˇ°efficientˇ± but makes modifying the knowledge base a nightmare.
Explicitness
-- The point of representing much of an expertˇŻs knowledge is to give the
system a rich enough knowledge base for high-performance problem solving. But
because a knowledge base must be built incrementally, it is necessary to provide
means for inspecting and debugging it easily. With items of knowledge represented
explicitly, in relatively simple terms, the experts who are building knowledge
bases can determine what items are present and (by inference) which are absent.
To achieve these
goals, three types of representation framework have been used in expert systems.
Although we concentrate on r&-based systems in the sections below, we also
mention frame-based and logic-based systems by way of contrast. Such frameworks
are often called representation languages because, as with other programming
languages, their conventions impose a rigid set of restrictions on how one can
express and reason about facts in the world. In all of these languages, one
can express conditional expressions and causal dependencies. In rule-based systems,
however, one sacrifices the ability to express many other general kinds of relations
in favor of the homogeneity and simplicity of conditional rules. These frameworks,
also, often include inference and control routines making them even more like
languages.
![]()
Rule-based expert
systems evolved from a more general class of computational models known as production
systems [Newel173]. Instead of viewing computation as a prespecified sequence
of operations, production systems view computation as the process of applying
transformation rules in a sequence determined by the data. Where some rule-based
systems [McDermott80] employ the production-system formalism very strictly,
others such as MYCIN have taken great liberties with it. However, the. production
system framework provides concepts that are of great use in understanding all
rule-based systems.
A classical production
system has three major components: (1) a global database that contains facts
or assertions about the particular problem being solved, (2) a rulebase that
contains the general knowledge about the problem domain, and (3) a rule interpreter
that carries out the problem solving process.
The facts in the
global database can be represented in any convenient formalism, such as arrays,
strings of symbols, or list structures. The rules have the form
IF <condition> THEN <action> .
In general, the
left-hand-side (LHS) or condition part of a rule can be any pattern that can
be matched against the database. It is usually allowed to contain variables
that might be bound in different ways, depending upon how the match is made.
Once a match is made, the right-hand-side (RHS) or action part of the rule can
be executed. In general, the action can be any arbitrary procedure employing
the bound variables. In particular, it can result in addition of new facts to
the database, or modification of old facts in the database.
The rule interpreter
has the task of deciding which rules to apply. It decides how the condition
of a selected rule should be matched to the database, and monitors the problem-solving
process. When it is used in an interactive program, it can turn to the user
and ask for information (facts) that might permit the application of a rule.
The strategy used
by the rule interpreter is called the control strategy. The rule interpreter
for a classical production system executes rules in a ˇ°recognize-actˇ± cycle.
Here the rule interpreter cycles through the condition parts of the rules, looking
for one that matches the current data base, and executing the associated actions
for (some or all) rules that do match. As we point out in Section 3, there are
many other ways to control the application of rules, but in all cases the result
of executing actions is to change the data base, enabling the application of
some rules and disabling others.
At this level
of generality, production systems are capable of arbitrarily complex behavior.
The many ways in which conditions might be matched and variables might be bound,
the many factors that might be important for rule selection, and the complicated
effects of executing the rule actions can quickly lead to very difficult
control problems. As one specific example, in many problem solving systems the
application of one rule can invalidate conditions needed for the application
of a previously applied rule; to cope with such possibilities, the rule interpreter
may have to employ backtracking strategies, or may have to maintain and starch
detailed records of the interdependencies between facts in the database.
Many of the expert
systems constructed to date are have controlled this complexity by sacrificing
the ability to perform general problem-solving tasks. They have achieved their
competence by specializing -- by exploiting the fallible but effective heuristic
methods that human experts bring to a particular class of problems. Many of
the high-performance systems (including MYCIN) can be characterized as simple
deduction systems, programs in which a fact once entered in the global
database (whether by the user or by the application of a rule) is never subsequently
deleted. .Their actions are typically limited to the addition of new facts to
the database. In the remainder of this section, we use EMYCIN as a concrete,
specific example of a rule-based approach to expert systems. While other rule-based
systems have made other design tradeoffs, EMYCIN illustrates well the issues
that arc involved.
![]()
To see how EMYCIN
uses the production system formalism to represent knowledge, we must see how
it represents facts about the current problem in its database, and how it represents
general knowledge in its rules.
In all EMYCIN
systems, facts are associative triples, that is, attribute-object-value triples,
with an associated degree of certainty (called a certainty factor, or CF). More
generally, the EMYCIN syntax for statements of fact (both within the database
and within rules) is:
The <attribute> of <object> is <value> with certainty <CD>
In
the MYCIN dialog shown above, fact triples are shown in the explanations as
individual clauses of rules. For example, after Question #35, one fact that
has been established is ˇ°the type of the infection is bacterial". It can,
also be seen that each question is asking for a value to be associated with
an attribute of an object. In Question # 35, for example, MYCIN is asking whether
or not the infection of the patient is hospital-acquired.
A
rule is a conditional sentence relating several fact statements in a logical
relation. The nature of the relation varies from rule to rule. Often rules record
mere empirical associations -- rules of thumb based on past experience with
little theoretical justification. Other rules are statements of theoretical
associations, definitions, or causal laws.
The
condition part of an EMYCIN rule is called its premise. In general, an EMYCIN
premise is the conjunction of a number of clauses. Each clause is a simple statement
concerning the facts, such as ˇ°the age of the patient is greater than 10 days",
or ˇ°the identity of the infection is unknown. ˇ± To enable EMYCIN to query
the database to determine to what degree a clause might be true, each
clause includes a matching predicate that specifies how the statement is to
be compared against the database of facts. In particular, a matching predicate
is. not required to return a binary answer, but may return a number between
0 and 1 indicating how much evidence there is that the predicate is satisfied.
About two dozen matching predicates are a standard part of EMYCIN, including
is the same as, is not the same as, has already been established, is not known,
is greater than (for comparing numerical values), and so forth.
The basic EMYCIN syntax for a rule is:
PREMISE: ($AND (<clause1 . . . <clause-n>))
ACTION: (CONCLUDE <new-fact> <CF>)
where the ˇ°$" prefix indicates that the premise is not a logical conjunction, but a plausible conjunction that must take account of the certainty factors associated with each of the clauses. The action taken by this rule is merely the addition of a new fact to the database (or, if the fact were already present, a modification of its certainty). EMYCIN also provide some mechanisms to allow the execution of more complicated actions. For example, in MYCIN we find the following rule (stated in English):
RULE160
If: 1) The time frame of the patient's headache is acute,
2) The onset of the patient's headache is abrupt, and
3) The headache severity (using a scale of 0 to 4; maximum is 4) is greater than
Then: 1) There is suggestive evidence (.6) that the patient's meningitis is bacterial,
2) There is weakly suggestive evidence (.4) that the patient's meningitis is viral, and
3) There is suggestive evidence (.6) that the patient has blood within the subarachnoid space
Thus, this rule has three conclusions. It is represented internally in LISP as follows:
PREMISE : ($AND (SAME CNTXT HEADACHE-CHRONICITY ACUTE)
(SAME CNTXT HEADACHE-ONSET ABRUPT)
(GREATERP" (VAL1 CNTXT HEADACHE-SEVERITY 3)))
ACTION : (DO-ALL (CONCLUDE CNTXT MENINGITIS BACTERIAL-MENINGITIS TALLY 600)
(CONCLUDE CNTXT MENINGITIS VIRAL-MENINGITIS TALLY 400)
(CONCLUDE CNTXT SUBARACHNOID-HEMORRHAGE YES TALLY 600))
These examples illustrate the basic techniques for representing facts and knowledge within the EMYCIN framework. Similar examples could be given for each of the several framework systems that have been developed to facilitate the construction of rule-based expert systems, including:
OPS Carnegie-Mellon University [Forgy77]
EMYCIN Stanford University [vanMelle80]
AL/X University of Edinburgh
EXPERT Rutgers University [Weiss79a]
KAS SRI International [Reboh81]
RAINBOW IBM Scientific Center (Palo Alto) [Hollander79]
These framework systems provide important tools (such as editors) and facilities (such as explanation systems) that are beyond the scope of this paper to discuss. They also vary considerably in the syntax and the rule interpreters they employ. For example, in some of them all attributes must be binary. In some, uncertainty is expressed more formally as probabilities, or less formally as ˇ°majorˇ± or ˇ°minorˇ± indicators, or cannot be expressed at all. And in some, additional structure is imposed on the rules to guide the rule interpreter. Despite these variations, these systems share a commitment to rules as the primary method of knowledge representation. This is at once their greatest strength and their greatest weakness, providing uniformity and modularity at the cost of imposing some very confining constraints.
![]()
There are alternatives
to representing task-specific knowledge in rules. Naturally, it is sometimes
advantageous to build a new system in PASCAL, FORTRAN, APL, BASIC, LISP, or
other language, using a variety of data structures and inference procedures,
as needed for the problem. Coding a new system from scratch, however, does not
allow concentrating primarily on the knowledge required for high performance.
Rather, one tends to spend more time on debugging the procedures that access
and manipulate the knowledge.
The nature of
the task sometimes requires more flexibility or more rigor than the rule-based
frameworks provide. In those cases the frameworks mentioned below may provide
satisfactory starting points. It should be noted that all of these frameworks
easily allow specification of conditional rules; a sign of the times, however,
is that the most restrictive frameworks (rule-based) arc currently the easiest
to use.
There has been
some experimentation with mixed representation as well [Aikins80, Reinstein81].
The basic idea is to increase the breadth of what one can represent easily while
maintaining the advantages of having stylized representations (albeit more than
one).
One approach to representing knowledge that allows rich linkages between facts is a generalization of semantic nets [Brachman77] known as frames [Minsky75], A frame is an encoding of knowledge about an object, including not only properties (often called. ˇ°slotsˇ±) and values, but pointers to other frames and attached procedures for computing values. The pointers indicate semantic links to other concepts, e.g., brother-of and also indicate more general concepts from which properties may be inherited and more specialized concepts to which its properties will be manifested. Programming with this mode of representation is sometimes called object-centeredprogramming because knowledge is tied to objects and classes of objects.
Some well-known frame-based representation languages are
KRL Xerox PARC [Bobrow77]
OWL M.I.T. [Szolovits77]
UNITS Stanford University [Stefik79]
FRL M.I.T. [Roberts77]
AIMDS Rutgers University [Sridharan80]
KL-ONE Bolt, Beranek & Newman [Brachman78]
A logic-based representation scheme is one in which knowledge about the world is represented as assertions in logic, usually first-order predicate logic or a variant of it. This mode of representation is normally coupled with an inference procedure based on theorem proving. Logic-based languages allow quantified statements and all other well-formed formulas as assertions, The rigor of logic is an advantage in specifying precisely what is known and knowing how the knowledge will be used. A disadvantage has been dealing with the imprecision and uncertainty of plausible reasoning.
To date there have been few examples of logic-based expert systems, in part because of the newness of the languages. Some logic-based representation languages are:
PLANNER M.I.T.[Hewitt72]
PROLOG Edinburgh University [Warren77]
ALICE University of Paris [Lauriere78]
FOL Stanford University [Weyhrauch80]
There is research in progress on general tools for helping a designer construct expert systems of various sorts. Designers specify the kind of representation and control and then add the task-specific knowledge within those constraints. The main advantage of such an approach is freedom -- designers specify their own constraints. The main disadvantage is complexity -- designers must be very knowledgeable about the range of choices and must be very patient and systematic about specifying choices. These tools look even more like high-level programming languages, which they are. The best known are:
ROSIE Rand Corp [Fain81]
AGE Stanford University [Nii79]
RLL Stanford University [Greiner80]
HEARSAY-III USC/ISI [Erman81]
MRS Stanford University [Genesereth81a]
![]()
Regardless of
the particular choice of representation language, a number of issues are important
in the construction of knowledge bases for expert systems. We mentioned extendability,
simplicity and explicitness as three global criteria. In addition the issues
of consistency, completeness, robustness and transparency are major design considerations
for all systems. For specific problems, it may be essential to represent and
reason with temporal relations, spatial models, compound objects, possible worlds,
beliefs, and expectations. These are discussed below.
Consistency in
the knowledge base is obviously desirable. Because much of the knowledge coming
from an expert is previously uncodified, and much of it comes with uncertainty,
however, it is unrealistic to assume that the knowledge base can be sufficiently
cleansed to withstand a logicianˇŻs scrutiny. In rule-based systems, there are
syntactic checks made at the time new ,rules are entered to see if there is
potential conflict between a new rule and existing rules. For example, two rules
with the same premises but with different conclusions may be incompatible if
the conclusions arc mutually exclusive. On the other hand, there arc many such
pairs of rules that are perfectly acceptable because both conclusions are warranted.
In MYCIN, for example, we find the same evidence ˇ°pointing toˇ± different causes
of an infection, with other rules invoking additional evidence to discriminate
among likely causes.
Syntactic Completeness
of the representation language is a logical requirement that many rule-based
languages fail to satisfy. There are assertions, e.g., quantified statements,
that are difficult or impossible to express. In DENDRAL, for example, it was
difficult to express the proposition that if there exists a pair of data points
bearing a complex relationship to one another then they constitute evidence
for one class of interpretations of the data [Lindsay80].
Semantic Completerzess
of the knowledge base for a problem area is also desirable. Because of the nature
of the knowledge base and the way it is built, however, it will almost certainly
fail to cover some interesting (sometimes important) possibilities. In a very
narrow problem area, for example, there may be 100 attributes of interest, with
an average of 4 important values for each attribute. (Only in extreme cases
will all attributes be binary.) Thus there would be 79,800 possible rules relating
two facts (400 items taken two at a time), over 10 million possible rules relating
three facts, and so on. While most are semantically implausible, e.g., because
of mutually exclusive values, the cost of checking all combinations for completeness
is prohibitive. Checking the inferences made by a system in the context of carefully
chosen test cases is currently the best way to check the completeness of coverage
of the rules.
Precision in specialized
domains is achievable for many of the facts and rules, but not all. There is
a temptation to make overly-precise assertions for the knowledge base, even
though there is no justification for fine precision. For example, although there
are hospital-specific statistics about the incidence of a disease, one has to
extrapolate to other (or all) hospitals very carefully. Representing degrees
of imprecision is an important part of every representation methodology.
Default knowledge
is important protection against incompleteness. If you know that devices manufactured
by XYZ Corp are generally very reliable, then you might assume that the XYZ
disk drive in your system is not the source of problems if you have no evidence
to the contrary. Frame-based methods are designed to use their inheritance mechanisms
to propagate default knowledge through parent-daughter links. In a rule-based
system, default knowledge can certainly be represented but generally requires
explicitly stating defaults for each class of actions.
Causal models
provide a detailed specification of how a complex device works, whether it be
biological or mechanical. For man-made devices, the models can be made more
precise. Representing something like a circuit diagram, and reasoning with it,
is difficult although there have been successful research projects in which
causal knowledge is central.
Temporal relations,
as causal ones, are still difficult to represent and USC in generally satisfactory
ways. Again, there has been good research, but expert systems generally do not
reason well with continuous flows of data, or about continuous processes.
Strategies for
problem solving are an important part of expertise. How ever, they are difficult
to represent and use efficiently. Strategies are discussed in more detail in
the section on control below.
The current state
of the art of representing knowledge about technical domains is adequate for
many simple problems but requires considerably more research on these major
issues, and more. (For comparisons among systems see [Brooks81, Ennis82].) Although
rule-based frameworks have been used successfully for building several expert
systems, the limitations are significant enough that researchers everywhere
are looking for extensions or alternatives.
![]()
Although the performance of most expert systems is determined more by the amount and organization of the knowledge possessed than by the inference strategies employed, every expert system needs inference methods to apply its knowledge. The resulting deductions can be strictly logical or merely plausible. Rules can be used to support either kind of deduction. Thus, a rule such as
Has(x, feathers) OR (Able(x, fly) & Able(x, lay-eggs)) -->
Class(x, bird)
amounts to a definition, and can be used, together with relevant facts, to deduce logically whether or not an object is a bird. On the other hand, a rule such as
State.(engine, won't turn over) & State(headlights, dim) -->
State(battery, discharged)
is a ˇ°rule-of-thumbˇ± whose conclusion, though plausible, is not always correct.
Clearly,
uncertainty is introduced whenever such a judgmental rule is employed. In addition,
the conclusions of a logical rule can also be uncertain if the facts it employs
arc uncertain. Both kinds of uncertainty are frequently encountered in expert
systems applications. However, in either case we arc using the rule to, draw
conclusions from premises, and there are many common or analogous issues. In
this section we temporarily ignore the complications introduced by uncertainty,
and consider methods for using rules when everything is certain.
In
terms of the production-systems model of r&-based expert systems, this section
is concerned with the rule interpreter. As we mentioned in Section 2, the rule
interpreter for a production system for unrestricted problem solving may have
to employ complicated procedures to handle such things as pattern matching,
variable binding, rule selection, and backtracking. To simplify our problem
further, we shall restrict our attention to simple deduction systems, programs
whose actions are essentially limited to adding new facts to the global database.
Our intent is to describe the general characteristics of the commonly used rule
interpreters without becoming entangled in the detailed mechanisms they employ;
control strategies for more general problem solving systems are described in
[Nilsson80].
In this section we describe three commonly used control strategies: (1) data-driven, (2) goal-driven, and (3) mixed. Since control concerns are procedural, we shall describe these strategies semi-formally as if they were programs written in a dialect of PASCAL, a ˇ°Pidgin PASCAL.ˇ± It is important to note at the outset, however, that these procedures are formal, employing no special knowledge about the problem domain; none of them possesses an intrinsic power to prevent combinatorial explosions. This has led to the notion of incorporating explicitly represented control knowledge in the rule interpreter, and idea that we discuss briefly at the end of this section.
With data-driven control, rules are applied whenever their left-hand-side conditions are satisfied. To use this strategy, one must begin by entering information about the current problem as facts in the database. The following simplified procedure, which we shall call ˇ°Respond,ˇ± can then be used to execute a basic data-driven strategy.
Procedure Respond;
Scan the database for the set S of applicable rules;
While S is non-empty and the problem is unsolved do
begin
Call Select-Rule(S) to select a rule R from S;
Apply R and update the database;
Scan the database for the set S of applicable rules
end.
Here we assume
that a rule is applicable whenever there are facts in the database that satisfy
the conditions in its left-hand side. If there are no applicable rules, there
is nothing to be done, except perhaps to return to the user and ask him or her
to supply some additional information. (And, of course, if the problem is solved,
there is nothing more to do.)
If there is only
one applicable rule, the obvious thing to do is to apply it. Its application
will enter new facts in the database. While that may either enable or disable
previously inapplicable rules, by our assumption it will never disable a previously
applicable rule.
If there is more
than one applicable rule, we have the problem of deciding which one to apply.
Procedure Select-Rule has the responsibility for making this decision. Different
data-driven strategies differ greatly in the amount of problem-solving effort
they devote to rule selection. A simple and inexpensive strategy is to select
the first rule that is encountered in the scan for S -- ˇ°doing the first thing
that comes to mind.ˇ± Unfortunately, unless the rules are favorably ordered,
this can result in many useless steps. Elaborations intended to overcome such
shortcomings can make data-driven control arbitrarily complex.
Data-driven control
is very popular, as is evidenced by the fact that it is known by so many different
names (bottom-up, forward chaining, pattern-directed, or antecedent reasoning).
R1 is an excellent example of an expert system that employs this strategy [McDermott80].
The popularity of data-driven control derives largely from the fact that such
a program can respond quickly to input from the user, rather than forcing the
user to wait until the program gets around to what the user wants to talk about.
We have already
mentioned the potential inefficiency of this strategy. Other problems that are
often overlooked can arise for programs intended to be used by naive users.
For example, as a data-directed program fires off one rule after another, its
behavior can appear to be aimless, undermining a userˇŻs confidence in its soundness.
Also, since the user must begin by entering a set of facts, some kind of a language
is needed to convert facts as expressed in the userˇŻs terms into the appropriate
internal representation; menu systems may provide an acceptable solution, but
a need for greater flexibility is frequently encountered. Both of these problems
can be circumvented by using goal-driven control.
A goal-driven
control strategy focuses its efforts by only considering rules that are applicable
to some particular goal. Since we are limiting ourselves to rules that can add
simple facts to the database, achieving a goal G is synonymous with showing
that the fact statement corresponding to G is true. In nontrivial problems,
achieving a goal requires setting up and achieving subgoals. This can also lead
to fruitless wandering if most of the subgoals are unachievable, but at least
there is always a path from any subgoal to the original goal.
Suppose that the
user specifies a goal statement G whose truth is to be determined -- typically
a fact that the user would like to have present in the database. Then the following
simplified procedure, which we shall call ˇ°Achieve,ˇ± carries out a basic goal-driven
strategy.
Procedure Achieve(G);
Scan the knowledge base for the set S of rules that determine G;
If S is empty then ask the user about G else
While G is unknown and rules remain in S do
begin
Call Choose-Rule(S) to choose a rule R from S;
G' <-- condition(R):
If G' is unknown then call Achieve(G');
If G' is true then apply R
end.
Thus, the first
step is to gather together all of the rules whose right-hand-sides can establish
G. If there is more than one relevant rule, procedure Choose-Rule receives the
problem of making the choice. Once a rule R is selected, its left-hand-side
GˇŻ is examined to see if R is applicable. If there is no information in the
database about GˇŻ, the determination of its truth or falsity becomes a new
subgoal, and the same procedure Achieve is applied to GˇŻ recursively.
The starch continues
in this fashion, working systematically backward from the original goal, until
a subgoal is encountered for which there are no rules. At this point the system
turns to the user and asks for the relevant facts. If the user cannot supply
the needed information, then the rule the system was working on at the time
cannot be used, but other lines of reasoning can still be explored. If the information
supplied shows that GˇŻ is true, then R is applied. The process continues in
this manner until either G is established to be true or false, or no applicable
rules remain.
Since the left-hand-side
of the selected rule becomes the next subgoal, the choice of a rule is equivalent
to subgoal selection. Different goal-driven strategies differ greatly in the
amount of effort they devote this problem. A simple and inexpensive strategy
is to select the first rule that is encountered in the scan for S. Unfortunately,
unless the rules are favorably ordered, this can lead to exploring unpromising
subgoals. As in the case of data-driven control, elaborations intended to overcome
such shortcomings can make goal-driven control arbitrarily complex.
Goal-driven control
has also been used in many systems, and is variously known as top-down, backward-chaining,
or consequent reasoning. A primary virtue of this strategy is that it dots not
seek information and does not apply rules that are unrelated to its overall
goal. Furthermore, as we have seen in the excerpt from a MYCIN session, a rule-based
system using this strategy can provide illuminating explanations of its behavior
merely by telling the user what goal it is working on and what rule it is using.
Probably the chief
disadvantage of a goal-driven strategy is that it does not allow ˇ®the user
to steer it by volunteering relevant information about the problem. This can
make goal-driven control unacceptable when rapid, real-time response is required.
Data-driven and goal-driven strategies represent two extreme approaches to control. Various mixtures of these. approaches have been investigated in an attempt to secure their various advantages while minimizing their disadvantages. The following simple procedure combines the two by alternating between the two modes.
Procedure Alternate;
Repeat
Let user enter facts into global database:
Call Respond to deduce consequences;
Call Select-Goal to select a goal G;
Call' Achieve(G) to try to establish G
until the problem is solved..
Here Respond and
Achieve are the data-driven and goal-driven procedures described previously.
Select-Goal, which we do not attempt to specify, uses the partial conclusions
obtained from the data-driven phase to determine a goal for the goal-driven
phase. Thus, the basic idea is to alternate between these two phases, using
information volunteered by the user to determine a goal, and then querying the
user for more information while working on that goal.
A variant of this
procedure is used in the PROSPECTOR program [Duda79]. In this case, Select-Goal
uses a heuristic scoring procedure to rank the goals in a prespecified set of
ˇ°top-levelˇ± goals, but the user is allowed to see the results and to make
the final selection. Furthermore, a modified version of Achieve is used which
ceases working on a goal whenever (a) its score drops and (b) it is not the
highest-scoring top-level goal. Thus, PROSPECTOR works in a goal-driven mode
when it seems to be making progress, but returns to the user for help in goal
selection when serious trouble is encountered.
![]()
The advantages
of making the task-specific knowledge modular and explicit extend to control
knowledge as well. The strategy by which an expert system reasons about a task
depends on the nature of the task and the nature of the knowledge the system
can USC. Neither data-driven, goal-driven, nor any particular mixed strategy
is good for every problem. Different approaches are needed for different problems.
Indeed, one kind of knowledge possessed by experts is knowledge of procedures
that are effective for their problems.
In most expert
systems, the control strategy is encoded in procedures much like the ones we
exhibited in pseudo-PASCAL. Thus, control knowledge is not explicitly represented,
but is buried in the code. This means that the system cannot easily explain
its problem solving strategy, nor can the system builder easily modify it. Several
interesting attempts have been made to extract this knowledge and represent
it explicitly. In his work on TEIRESIAS, Davis included the USC of meta-rules,
rules that determined the control strategy [Davis77a]. TEIRESIAS essentially
implements the procedure Select-Rule as a rule-based system. That is, strategic
knowledge is used to reason about the most appropriate rules to invoke during
problem solving or the most appropriate order in which to invoke them. Because
the strategy rules can be context-specific, the result is a system that adapts
its rule selection strategy to the nature of the problem. Other important work
on explicit control of reasoning in expert systems can be found in [Aikins80,
Barnett82, Clancey81, deKleer77, Genesereth8la, Georgeff82].
![]()
The direct application of these methods of deduction to real-world problems is complicated by the fact that both the data and the expertise are often uncertain. This fact has led the designers of expert systems to abandon the pursuit of logical completeness in favor of developing effective heuristic ways to exploit the fallible and but valuable judgmental knowledge that human experts bring to particular classes of problems. Thus, we now turn to comparing methods that have been used to accommodate uncertainty in the reasoning.
Let A be an assertion about the world, such as an attribute-object-value triple. How can one treat the uncertainty that might be associated with this assertion? The classical formalism for quantifying uncertainty is probability theory, but other alternatives have been proposed and used. Among these are certainty theory, possibility theory, and the Dempster/Shafer theory of evidence. We shall consider all four of these approaches in turn;with emphasis on the first two.
With probability
theory, one assigns a probability value P(A) to every assertion A. In expert
systems applications, it is usually assumed that P measures the degree to which
P is believed to be true, where P = 1 if A is known to be true, and P = 0 if
A is known to be false! In general, the degree of beˇŻlief in A will change
as new information is obtained. Let P(A) denote our initial or prior belief
in A, and let the conditional probability P(AŁüB) denote our revised belief
in A upon learning that B is true. If this change in probability is due to the
application of the rule B --> A in a rule-based system, then some procedure
must be invoked to change the probability of A from P(A) to P(AŁüB) whenever
this rule is applied.
In a typical diagnosis
situation, we think of A as a ˇ°causeˇ± and B as an ˇ°effect,ˇ± and view the
computation of P(AŁüB) as an inference that the cause is present upon observation
of the effect. The expert often finds it easier to estimate P(BŁüA) -- the probability
of observing the effect B when the cause A is active. In medical situations,
this is further justified by the argument that the probability of a disease
given a symptom may vary with time and place, while the probability of a symptom
given a disease remains invariant [Lusted68]. Thus, BayesˇŻ Rule is commonly
employed to compute P(AŁüB) from P(BŁüA).
It turns out that
the important information that is needed to employ BayesˇŻ Rule is the prior
probability P(A) and the likelihood ratio L defined by
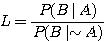
where P(BI-A) is the probability of observing effect B when cause A is absent.
If we think of
the link between B and A as being expressed by a rule of the form B -4 A, then
we can think of the logarithm of the likelihood ratio L as representing the
strength or weight of the rule; rules with positive weights increase the probability
of A, and rules with negative weights decrease it.
Two generalizations
are needed to employ this result in practice. First, we need a way to combine
the effects of several rules, particularly when they are in conflict. Second,
we need a way to employ uncertain evidence. While a thorough treatment of these
topics is beyond the scope of this paper, it is useful to explore this topic
sufficiently to reveal the problems that are encountered and the general nature
of their solutions.
Suppose that we have n plausible rules of the form
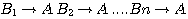
each
with its own weight. Formally, the generalization of BayesˇŻ Rule is simple.
We merely consider B to be the conjunction  , and use the likelihood ratio
, and use the likelihood ratio
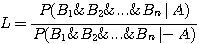
The
problem with this solution is that it implies that we not only have weights
for the individual rules connecting the  , to A, but that we also have weights for the pairs
, to A, but that we also have weights for the pairs  and B,, and so on, not to mention combinations involving negations when
the evidence is known to be absent. This not only leads to extensive, nonintuitive
computations, not directly related to the rules, but also requires forcing the
expert to estimate a very large number of weight values.
and B,, and so on, not to mention combinations involving negations when
the evidence is known to be absent. This not only leads to extensive, nonintuitive
computations, not directly related to the rules, but also requires forcing the
expert to estimate a very large number of weight values.
A
major simplification can be achieved if it is possible to assume that the 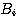 are statistically independent, both when A is present (true) and when A
is not present (false). In,that case, the conditional probabilities shown above
factor, and L simplifies to the product of the separate likelihood ratios. In
other words, under that assumption, we need only have one weight associated
with each rule, and we can combine the effects of several pieces of evidence
by adding the separate weights.
are statistically independent, both when A is present (true) and when A
is not present (false). In,that case, the conditional probabilities shown above
factor, and L simplifies to the product of the separate likelihood ratios. In
other words, under that assumption, we need only have one weight associated
with each rule, and we can combine the effects of several pieces of evidence
by adding the separate weights.
In
general, of course, this assumption is not justified. In fact, it can be shown
that the assumption cannot be made repeatedly when there are multiple assertions.
In its extreme form, this approach suggests designing an expert system by gathering
all the evidence that bears in any way on a final conclusion A and going in,
one step from the observations to the conclusion. Such an approach typically
founders on the complexity of the interactions among observations that are not
even approximately independent.
The
pragmatic solution to this problem places the responsibility on the knowledge
engineer to see that the rules are properly structured. Many problems caused
by interactions can be solved by employing a hierarchical structure, with several
levels of assertions between the direct observations and the final conclusions.
The goal is to localize and limit tic interactions, and to have a relatively
small number of clauses in a condition and a relatively small number of rules
sharing a common conclusion. Note that this limitation on the number of rules
does not reduce the amount of evidence considered in reaching a conclusion,
but rather controls the ways in which the observations are allowed to interact.
A hierarchical structure is typically employed by the experts themselves to
reduce the complexity of a problem. Wherever the remaining interactions still
prevent the assumption of local independence, the rules have to be reformulated
to achieve the desired behavior. For example, in the strongly interacting situation
where 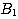 , suggests A and
, suggests A and 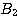 suggests A, but the simultaneous presence of both
suggests A, but the simultaneous presence of both 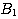 and
and 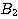 rules out A one may have to augment the rule set
rules out A one may have to augment the rule set
{(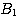 --> A with weight Ll)
--> A with weight Ll)
(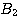 --> A with weight L2) }
--> A with weight L2) }
with
the rule (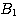 &
& 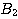 --> A with weight-m). Thus, rather than viewing probability theory as
a paradigm that prescribes how information should be processed, the knowledge
engineer employs it as a tool to obtain the desired behavior.
--> A with weight-m). Thus, rather than viewing probability theory as
a paradigm that prescribes how information should be processed, the knowledge
engineer employs it as a tool to obtain the desired behavior.
There
are two reasons why an assertion B might be uncertain: (1) the user might have
said that B is uncertain, or (2) the program might have deduced B using a plausible
rule. If we want to use B in a rule to compute P(AŁüB), the question then arises
as to how to discount the conclusion because of the uncertainty associated with
B.
Let
E symbolize whatever evidence was used to determine B, and let P(BŁüE) denote
the current probability of B. Then our problem is to compute P(A]E), the current
probability of A given this same evidence. It is shown in [Duda76] that under
certain reasonable assumptions we should be able to compute P(AŁüE) by the formula
P(AŁüE) = P(AŁüB)*P(BŁüE) + P(AŁüˇB)*[1 - P(BŁüE)]
This
formula certainly works in the extreme cases of complete certainty. That is,
if we know that B is true we obtain P(AŁüB), and if we know that B is false
we obtain P(AŁüˇB). Unfortunately, a serious problem arises in intermediate
cases. In particular, suppose that E actually supplies no information about
B, so that P(BŁüE) is the same as the prior probability P(B). While the formula
above promises to yield the prior probability P(A), when the computation is
based on numerical values obtained from the expert, the resulting value for
P(AŁüE) will usually not agree with the expertˇŻs estimate for the prior probability
P(A). That is, the four quantities P(A), P(B), P(AŁüB) and P(AŁüˇB) are not
independent, and the expertˇŻs subjective estimates for them arc almost surely
numerically inconsistent.
In
this particular case, the problem can be solved in various ways (such as by
not asking the expert for P(A), but by computing it from P(A) = P(AŁüB)P(B)
+ P(AŁüˇB)P(ˇB)). However, that only makes the parameters for one rule consistent,
and the solution is not at all obvious when there is a network of rules that
have inconsistent values for probability parameters. The solution adopted in
the PROSPECTOR system was to replace the above expression for P(AŁüE) by a piecewise
linear function of P(BŁüE) that yields the expertˇŻs estimate for P(A) when
P(BŁüE) is numerically equal to the expertˇŻs estimate for P(B) (see [Duda76]).
Interestingly, the resulting formulas turn out to be closely related to the
certainty measure used in MYCIN, which we consider next.
![]()
We
have seen several problems that arise in using traditional probability theory
to quantify uncertainty in expert systems. Not the least of these is the need
to specify numerical values for prior probabilities. While an expert may be
willing to say how certain he or she feels about a conclusion A when evidence
B is present, he or she may be most reluctant to specify a probability for A
in the absence of any evidence, particularly when rare but important events
are involved. Indeed, some of the problems that are encountered in obtaining
consistent estimates of subjective probabilities may well be due to the fact
that the expert is not able to separate probability from utility or significance,
and is really expressing some unspecified measure of importance.
To
accommodate this reality, the designers of the MYCIN system developed a theory
of certainty that provides a simple and effective alternative approach [Shortliffe75].
The central notion is that we can associate a certainty measure C(A) with every
assertion A, where C = 1 if A is known to be true, C = -1 if A is known to be
false, and C = 0 if nothing is known about A. A similar certainty factor CF
is associated with every rule. The theory consists of procedures for updating
certainties as rules are applied, and an analysis of the properties of these
procedures.
The
procedures for updating certainties are easily stated. Initially, the certainty
associated with any assertion
is 0. If a rule says that B --> A with a certainty factor CF, then the certainty
of A is changed to CF when B is observed to be true. Only two things remain
to be specified: (1) the procedure for combining evidence when more than one
rule concludes A, and (2) the treatment of uncertain evidence. We consider each
of these in turn.
Suppose that (1) the present certainty of an event A is CA (which may be non zero because of the previous application of rules that conclude A), (2) there is an unused rule of the form B --> A with a certainty factor CF, and (3) B is observed to be true. Then the EMYCIN formula for updating C(A) to C(AŁüB) is
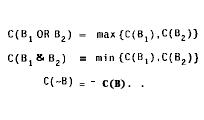
This is the EMYCIN
analog of the procedure of multiplying likelihood ratios to combine ˇ°independentˇ±
evidence. By applying it repeatedly, one can combine the conclusions of any
number of rules 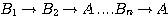 . Aside from being easy to compute, it has several other desirable properties.
First, the resulting certainty C(AŁüB) always lies between -1 and 1, being +l
if CA or CF is +l, and -1 if CA or CF is -1. When contradictory conclusions
are combined (so that CA = -CF), the resulting certainty is 0. Except at the
singular points (1, -1) and (-1, l), C(AŁüB) is a continuous function of CA
and CF, increasing monotonically in each variable. The formula is symmetric
in CA and CF, and the results it yields when more than two pieces of evidence
are combined are independent of the order in which they are considered.
. Aside from being easy to compute, it has several other desirable properties.
First, the resulting certainty C(AŁüB) always lies between -1 and 1, being +l
if CA or CF is +l, and -1 if CA or CF is -1. When contradictory conclusions
are combined (so that CA = -CF), the resulting certainty is 0. Except at the
singular points (1, -1) and (-1, l), C(AŁüB) is a continuous function of CA
and CF, increasing monotonically in each variable. The formula is symmetric
in CA and CF, and the results it yields when more than two pieces of evidence
are combined are independent of the order in which they are considered.
Of course, none
of these properties prove that this is the ˇ°correctˇ± way to combine the conclusions
of rules. Indeed, the results will be wrong in strongly interacting cases such
as our previous example in which  ,suggests A and
,suggests A and 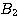 , suggests A, but the simultaneous presence of
, suggests A, but the simultaneous presence of 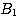 , and
, and 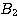 , rules out A. As with the use of Bayesian methods, the knowledge engineer
should view certainty theory as a tool to be employed to produce the desired
behavior.
, rules out A. As with the use of Bayesian methods, the knowledge engineer
should view certainty theory as a tool to be employed to produce the desired
behavior.
When the evidence
B for a rule B --> A is itself uncertain, it is clear that the strength of
the conclusion must be reduced. The EMYCIN procedure is to multiply the certainty
factor CF for the rule by the certainty of B, provided that the certainty
of B is positive. If the certainty of B is negative, the rule is considered
to be inapplicable, and is not used. EMYCIN assumes that a rule cannot be employed
unless the certainty of its antecedent is greater than a threshold value of
0.2. This heuristic -- which implies that the certainty of a conclusion is not
a strictly continuous function of the certainty of the evidence -- saves time
by inhibiting the application of many marginally effective rules, and saves
confusion by making explanations provided by the system more understandable.
One more effect
of uncertain evidence remains to be mentioned. In general, the antecedent B
of a rule is a logical function of predicates or relations on associative triples.
Since these functions or relations can return certainty values rather than truth
values, there is a question as to how the certainty of their logical combination
is determined. The answer is that it is computed through the recursive application
of the following formulas:

These formulas are essentially the same as the corresponding formulas of possibility theory, which is discussed briefly in the next section.
![]()
Probability theory
captures only some of the important aspects of uncertainty, and a variety of
alternative approaches, such as certainty theory, have been developed to overcome
its limitations. One of the most interesting of the recent alternatives is ZadehˇŻs
theory of possibility [Zadeh78]. It is based on his earlier development of the
theory of fuzzy sets [Zadeh65], much as probability theory is based on measure
theory.
Zadeh asserts
that although the random model of probability theory may be appropriate for
problems involving the measure of information, it is inappropriate for problems
concerning the meaning of information. In particular, much of the uncertainty
surrounding the USC of English terms and expressions concerns vagueness rather
than randomness. Possibility theory provides a formalism for treating vagueness
that is analogous to probability theory as a formalism for treating randomness.
The theory of
fuzzy sets expresses this kind of imprecision quantitatively by introducing
characteristic or membership functions that can assume values between 0 and
1. Thus, if S is a set and ifs is an element of S, a fuzzy subset F of S is
defined by a membership function 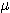 F(s) that measures the degree to which s belongs to F. To use a standard
example, if S is the set of positive integers and F is the fuzzy subset of small
integers, then we might have
F(s) that measures the degree to which s belongs to F. To use a standard
example, if S is the set of positive integers and F is the fuzzy subset of small
integers, then we might have 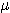 F(1) = 1,
F(1) = 1, 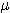 F(2) = 1,
F(2) = 1, 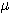 F(3) = .8, . . . ,
F(3) = .8, . . . , 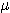 F(20) = .01, and so on. Let X be a variable that can take values in S. The
statement ˇ°X is Fˇ± (for example, the statement ˇ°X is a small integerˇ±),
induces a possibility distribution on X, and the possibility that X = s is taken
to be
F(20) = .01, and so on. Let X be a variable that can take values in S. The
statement ˇ°X is Fˇ± (for example, the statement ˇ°X is a small integerˇ±),
induces a possibility distribution on X, and the possibility that X = s is taken
to be 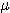 F(s).
F(s).
Now probability
theory is not concerned with how the numerical values of probabilities are determined,
but rather with the rules for computing the probability of expressions involving
random variables. Similarly, possibility theory is not concerned with how the
numerical values of the possibility distributions are obtained, but rather with
the rules for computing the possibilities of expressions involving fuzzy variables.
In particular, if Poss{X = s} is the possibility that the fuzzy variable X is
equal to s, then the formulas for disjunction, conjunction and negation are
Poss{ X=s OR Y=t } = rnax[ Poss{X=s}, Poss{Y=t) ]
Poss{ x =s & Y =t } = min[ Poss{X=s}, Poss{Y=t} ]
and
Pass{ x ˇÁs } = 1 - Poss{x=s}.
For
most of the concepts of probability theory there is a corresponding concept
in possibility theory. For example, it is possible to define multivariate possibility
distributions, marginal possibility distributions, and conditional possibility
distributions (see [Zadeh78]). Thus, in principle one can use fuzzy possibility
theory much like probability theory to quantify the uncertainty introduced by
vagueness, whether the vagueness comes from the data or from the rules.
Although
possibility theory is a subject of great interest, it has yet to be exploited
in work on expert systems. This is partly due to the fact that most of the problems
that limit probability theory also arise in possibility theory -- such as the
problem of prior possibilities and the problem of dependence in multivariate
possibility distributions. Furthermore, as with certainty theory, possibility
theory suffers from the problem that the semantics of its measure are not objectively
defined. However, the distinction between uncertainty due to randomness and
uncertainty due to vagueness is both valid and important, and should play a
role in work in expert systems.
![]()
We
conclude this overview of formalisms for treating uncertainty with a brief consideration
of a generalization of probability theory created by Dempster and developed
by Shafer that has come to be known as the Dempster/Shafer theory of evidence
[Shafer76, Barnett81].
Dempster
and Shafer insist that one must make a fimdamental distinction between uncertainty
and ignorance. In probability theory, one is forced to express the extent of
oneˇŻs knowledge about or belief in an assertion A through a single number,
P(A). Dempster and Shafer point out that the classical Bayesian agony concerning
prior probabilities is often due to the fact that one often simply does not
know the values of prior probabilities, and this ignorance may make any particular
choice arbitrary and unjustifiable.
The
Dempster/Shafer theory of evidence recognizes the distinction between uncertainty
and ignorance by introducing belief functions that satisfy axioms that are weaker
than those of probability functions. Thus, probability functions are a subclass
of belief functions, and the theory of evidence reduces to probability theory
when the probability values arc known. Roughly speaking, the belief functions
allow us to use our knowledge to put constraints or bounds on the assignment
of probabilities to events without having to specify the probabilities themselves.
In addition, the theory of evidence provides appropriate methods for computing
belief functions for combinations of evidence.
As
one might expect, a theory that includes probability theory as a special case
suffers from many of the same problems that plague probability theory. The greater
complexity results in an increase in computational problems as well, and the
conclusions that can be reached are necessarily weaker. However, when available.
knowledge does not justify stronger conclusions, this latter fact has to be
accepted. Whether or not the theory of evidence will provide the basis for computationally
effective procedures for treating uncertainty, it deserves attention for exposing
the effects of lack of knowledge on probabilistic reasoning.
![]()
In
the previdus three sections we focused on three central issues in the design
of expert systems, with special attention to rule-based systems. The representation,
inference methods and methods for reasoning under uncertainty are the elements
of the design of rule-based systems that give them power. We turn now to a broader
look at several less technical aspects of building an expert system. These are
observations derived from our own experience and constitute suggestions for
designing an expert system. They also reflect the current state of the art.
In
this section we first list several of these considerations, with very little
explanation. Then we look at the nature of the problem (the first of the considerations)
in more detail from three different perspectives: the types of problems for
which expert systems have been developed (Sec.S.l), the nature of the data encountered
in these problems (Sec.5.2), and the nature of the expertise (Sec. 5.3).
We spoke earlier
of the importance of separating task-specific knowledge from a systemˇŻs inference
methods, and we discussed the representation and inference methods by which
we can realize the truth in the assumption that ˇ°knowledge is power.ˇ± We list
here some of those and other key ideas in putting together an expert system.
NATURE OF THE PROBLEM:
Narrow scope -- The task for the system must be carefully chosen to be narrow enough that the relevant expertise can be encoded, and yet complex enough that expertise is required. This limitation is more because of the time it takes to engineer the knowledge into a system including refinement and debugging, than because space required for the knowledge base.ˇ±
Existence of an expert -- These are problems so new or so complex that no one ranks as an expert in the problem area. Generally speaking, it is unwise to expect to be able to construct an expert system in areas where there are no experts.
Agreement among experts -- If current problem solving expertise in a task area leaves room for frequent and substantial disagreements among experts, then the task is not appropriate for an expert system.
Data available -- Not only must the expertise be available, but test data must be available (preferably online). Since an expert system is built incrementally, with knowledge added in response to observed difficulties, it is necessary to have several test cases to help explore the boundaries of what the system knows.
Milestones definable -- A task that can be broken into subtasks, with measurable milestones, is better than one that cannot be demonstrated until all the parts are working.
REPRESENTATION:
Separation of task-specific knowledge from the rest of the program -- This separation is essential to maintain the flexibility and understandability required in expert systems.
Attention lo detail -- Inclusion of very specific items of knowledge about the domain, as well as general facts, is the only way to capture the expertise that experience adds to textbook knowledge.
Uniform data structures -- A homogeneous representation of knowledge makes it much easier for the system builder to develop acquisition and explanation packages.
INFERENCE:
Symbolic reasoning - It is commonplace in AI, but not elsewhere, to regard symbolic, non-numeric reasoning as a powerful method for problem solving by computers. In applications areas where mathematical methods are absent or computationally intractable, symbolic reasoning offers an attractive alternative.
Combination of deductive logic and plausible reasoning -- Although deductive reasoning is the standard by which we measure correctness, not all reasoning -- even in science and mathematics -- is accomplished by deductive logic. Much of the worldˇŻs expertise is in heuristics, and programs that attempt to capture expert-level knowledge need to combine methods for deductive and plausible reasoning.
Explicit problem solving strategy -- Just as it is useful to separate the domain-specific knowledge from the inference method, it is also useful to separate the problem solving strategy from both. In debugging the system it helps to remember that the same knowledge base and inference method can produce radically different behaviors with different strategies. For example, consider the difference between ˇ°find the bestˇ± and ˇ°find the first over thresholdˇ±.
Interactive user interfaces -- Drawing the user into the problem solving process is important for tasks in which the user is responsible for the actions recommended by the expert system, as in medicine. For such tasks, the inference method must support an interactive style in which the user contributes specific facts of the case and the program combines them in a coherent analysis.
EXPLANATION
Static queries of the knowledge base -- The process of constructing a large knowledge base requires understanding what is (and is not) in it at any moment. Similarly, using a system effectively depends on assessing what it does and does not know.
Dynamic queries about the line of reasoning -- As an expert system gathers data and makes intermediate conclusions, users (as well as system builders) need to be able to ask enough questions to follow the line of reasoning. Otherwise the systemˇŻs advice appears as an oracle from a black box and is less likely to be acceptable.
KNOWLEDGE ACQUISITION:
Bandwidth -- An expertˇŻs ability to communicate his/her expertise within the framework of an expert system is limited by the restrictions of the framework, the degree to which the knowledge is already well-codified, and the speed with which the expert can create and modify data structures in the knowledge base.
Knowledge engineer -- One way of providing help to experts during construction of the knowledge base is to let the expert communicate with someone who understands the syntax of the framework, the rule interpreter, the process of knowledge base construction, and the practical psychology of interacting with world-class experts. This person is called a ˇ°knowledge engineerˇ±.
VALIDATION:
Level of performance -- Empirical measures of adequacy are still the best indicators of performance, even though they arc not sufficient for complete validation by any means. As with testing new drugs by the pharmaceutical industry, testing expert systems may best be accomplished by randomized studies and double-blind experiments.
Static evaluation -- Because the knowledge base may contain judgmental rules as well as axiomatic truths, logical analysis of its completeness and consistency will be inadequate. However, static checks can reveal potential problems, such as one rule subsuming another and one rule possibly contradicting another. Areas of weakness in a knowledge base can sometimes be found by analysis as well.
![]()
The first of the
key concepts listed above was the nature of the problem. We examine this issue
in somewhat more detail in this and the next two sections. While there are many
activities an expert performs, the activities for which expert systems have
been built fall into three categories: analysis, synthesis, and interface problems.
Analysis Problems
have been the most successfully solved with the knowledge engineering approach
to date. Many applications programs that have the characteristics of expert
systems have been developed for analysis problems in a diversity of areas including:
chemistry [Buchanan78, Carhart79]; genetics [Stefik78]; protein crystallography
[Engelmore79]; physics [Bundy79, Larkin80, Novak80]; interpretation of oil well
logs [Barstow79b, Davis81]; electronics troubleshooting [Addis80, Bennett81b,
Brown82, Davis82b, Geneserethslb, Kandt81, Stallman77]; materials engineering
[Basden82, Ishizuka81]; mathematics [Brown78, Mosesirl]; medical diagnosis [Chandrasekaran80,
Fagan80, Goriy78, Heisdr78, Horn81, Kaihara78, Lindberg81, Pati181,Pople77,
Reggia78, Shortliffe76, Shortliffe81, Swartout77, Szolovits78, Tsotsos81, Weiss79bl;
mineral exploration [Duda79]; aircraft identification and mission planning [Engelman79];
military situation assessment [McCo1179, Nii82]; and process control wamdani821.
Within these and other disciplines, analysis problems are described using many
different terms, including:
An expert system
working on one of these problems analyzes a description of a situation, and
provides plausible interpretations of what the data seem to indicate. The data
may come from a variety of sources ranging from subjective opinion to precise
readings of instruments.
Synthesis Problems
have the character of constructing a solution to satisfy a goal within stated
constraints. In many cases , solutions to small, local problems need to be synthesized
into a coherent solution that satisfies global constraints. Synthesis problems
arise in many fields including: planning experiments in molecular genetics [Friedland79,
Stefik80], configuring the components of a computer system [McDermott80, McDerrnott81];
scheduling [Fox82, Goldstein79, Lauriere78]; automatic programming [Barstow79a,
McCune77]; electronics design [deKleer80, Dincbas80, Sussman781, and chemical
synthesis [Gelernter77,Wipke77]. These problems have been called:
In addition to analysis and synthesis problems, expert systems have been built to provide advice on how to USC a complex system [Anderson76, Bennett79, Gencscreth78, Hewitt75, Krueger81, Rivlin80, Waterman791 or to tutor a novice in the use or understanding of a body of knowledge [Brown82, Clancey79, OˇŻShea79]. These problems arc partly analytic, since the advice or tutorial must be guided by an analysis of the context, and partly synthetic since the advice must be tailored to the user and the problem at hand.
![]()
One of the central
concerns in choosing a task for an expert system is the nature of the data.
In problems of analysis, the data require interpretation by means of some model
or theory. Yet in many interesting problems, the data are not as complete or
ˇ°cleanˇ± as the theory seems to require. In applying a theory to individual
cases, the data are not always available to ˇ°plug intoˇ± formulas and principles.
In the absence of perfect data, however, experts can still provide good suggestions,
when a novice can not. We have identified several important concerns, briefly
discussed below: incompleteness, noise and non-independence.
Incompleteness
of the data is a common difficulty. In medical diagnosis, for example, a physician
usually must act before all possibly relevant tests have been made. Uncertainty
of the data compounds the difficulty. Decision makers know that their sources
of information arc fallible, whether the sources are instruments or other persons.
Some tests arc notoriously unreliable, some items of information arc so incongruous
with other data that something must be wrong. Yet, in the face of these. uncertainties
in the data, expert decision makers can still integrate the results of many
tests better than novices.
Noise in the data
can be confusing. Spurious data points, or ˇ°red herringsˇ±, can throw the best
problem solvers off the track. However, experts have had more experience in
sorting out good and bad data and arc less likely to remain confused than novices.
The data given to a decision maker can be noisy for a variety of reasons including
electronic noise, misreading dials and indicators, and transcription errors.
By the time the decision maker sees the data, it is often too late to check
the validity of any single data point.
Non-independence
in the data is often a difficulty, particularly for statistical methods that
rely on assumptions of independence to combine pieces of evidence. In most interesting
problems, though, there are processes linking many parts of complex systems,
so that evidence about one part of the system is richly linked with other pieces
of evidence. If the data were known to be error-free, then avoiding redundancy
would simplify the decision making process. However, in the face of possibly
unreliable data, redundancy is beneficial in helping reduce the effects of spurious
data.
The data are often
of uneven grain size, combining gross descriptive reports with minute, precise
statements of fact. Qualitative and quantitative information is mixed. Subjective
reports are mixed with objective statements. There is no uniform theoretical
framework in which information at all these levels can be combined. Yet, decision
makers faced with less than perfect data often welcome more information, regardless
of how heterogeneous it is. The volume of data, however, can get to be confusing.
The combinatorics of considering meaningful clusters of data quickly swamps
a personˇŻs ability to consider combinations of data points systematically.
One of the primary
advantages of an expert system in coping with all of this ambiguity is its ability
to exploit redundancy. Multiple pieces of data can indicate more or less the
same intcrpretation, some more strongly than others, while others indicate mutually
exclusive interpretations. An expert system will work with the data available
using the overlapping contributions to help make up for missing data and incomplete
interpretation rules.
![]()
The proficiency
of an expert system is dependent on the amount of domain-specific expertise
it contains. But expertise about interesting problems is not always neatly codified
and waiting for transliteration into a programˇŻs internal representation. Expertise
exists in many forms and in many places, and the task of knowledge engineering
includes bringing together what is known about a problem as well as transforming
(not merely transcribing) it into the system.
We have already
said that much of the expertise is symbolic, heuristic!, and not well formalized.
That implies that an expertˇŻs knowledge is not always certain, that it is provisional,
without guarantees of correctness. Because it is not well formalized (e.g.,
in neat theoretical formulations in textbooks), a specialistsˇŻs knowledge is
not always easily accessible. In addition, we have to assume that it is incomplete,
since the facts and heuristics change with increased experience.
Because of the
multitude of sources of expertise, an expert articulates what he or she knows
in a mixture of frameworks, using terminology ranging from broad notions of
common sense to precisely defined theoretical terms. As with the data, there
is a mixture in concepts that the knowledge engineer must help the expert map
into the system.
Moreover, these
frameworks are richly intertwined and not neatly separated into distinct subspecialty
areas. Woven into the facts and relations are many examples, exceptions, links
to other specialty areas. They-appear to be well indexed, for experts seem to
have no difficulty in citing examples for every principle and two exceptions
for every example. Finally, an expertˇŻs store of knowledge is large.
Regardless of how one measures the size of an expertˇŻs knowledge base, it is
almost a truism to say that the more a problem solver knows, the better its
advice will be.
As with the data
available for solving interesting problems, the expertise that is available
may be redundant, with rich inter-dependencies in the reasoning network. In
the case of the expertise, as well, the redundancy can be exploited as protection
against being led into blind alleys by spurious data or inappropriate heuristics.
![]()
Expert systems represent an important set of applications of Artificial Intelligence to problems of commercial as well as scientific importance. There appear to be three main motivations for building an expert system, apart from research purposes:
Rule-based systems
arc currently the most advanced in their system-building environments and explanation
capabilities, and have been used to build many demonstration programs. Most
of the programs work on analysis tasks such as medical diagnosis, electronic
troubleshooting, or data interpretation. The capability of current systems is
difficult to define. It is clear, however, that they are specialists in very
narrow areas and have very limited (but not totally missing) abilities to acquire
new knowledge or explain their reasoning.
One of the important
concepts of this style of programming is the throwaway program. The existence
of a framework system in which to construct a new program allows the expert
and knowledge engineer to focus on the knowledge needed for problem solving.
Without a framework, they spend more time on syntactic considerations than on
semantic ones. Because the framework is already in place, however, they can
readily scrap bad conceptualizations of the problem solving knowledge. For programs
that are built incrementally, as expert systems are, throwing away false
starts is important.
Technological
innovations will be incorporated into expert systems as the conceptual difficulties
of representation and inference in complex domains yield to standardized techniques.
These will be most noticeable in the size of the computer and in the input/output
of the system. A portable device for troubleshooting, with voice I/O, for example,
is not out of the question in the near future. Systems will use much larger
knowledge bases than the few hundred to few thousand rules now used. They will
be linked electronically to large dab bases to facilitate inference and avoid
asking questions whose answers are matters of record. ˇ°Smartˇ± interpretation
systems will be directly linked to data collection devices, as PUFF is linked
to a spirometer, to avoid asking about the data for the case at hand.
For the time being,
the major difficult) in constructing an expert system will remain engineering
the knowledge that experts use into a form that is usable by the system. Every
problem area and every expert is unique. Nevertheless, many common features
have been identified and built into knowledge acquisition packages of the major
frameworks. Future systems will integrate several modes of knowledge acquisition:
some rules can be extracted from an expert, some from large data bases, and
some from experience.
Finally, more
powerful system-building frameworks will be developed to reduce the time it
takes to iterate on the build-test-refine cycle and to increase the range of
applications. There is considerable research in AI of interest to designers
of expert systems [Buchanan81], much of it relating to the two central issues
of representation and inference, some of it relating to improving the interface
between system builders and the emerging system. As this work is integrated
into more powerful frameworks, the breadth and depth of applications will increase.