2
인 비영합 게임
게임이론과 전략
: 권오헌. 윤태환
지음, 범한서적 주식회사, 2000, Page
1 절 내쉬의 평형점과 비협동적 해
2 절 죄수의 딜레마
이론적인 반복게임
메타게임의 논리 (metagame argument)
실험적인 반복게임
3 절 전략적인 수
4 절 내쉬의 중재안과 협동적인 해
Dresher 와 Flood (1950) 는 유일한 평형점을 갖지만
Pareto 최적은 아닌 다음과 같은 비영합게임을 고안하였다.
|
행동이
|
열심이
|
|
|
A
|
B
|
|
A
B
|
(0, 0)
(1, -2)
|
(-2, 1)
(-1, -1)
|
|
|
|
|
그 후 Tucker 는 이 게임에 적합한 다음과 같은
상황을 만들었다. 게임의 참여자인 행동이와 열심이는 공범죄로 체포되어 분리된
방에서 심문을 받고 있다. 현명한 검사가 두 사람 각각에게 다음과 같이 말한다.
"두 사람 중에서 한 사람은 자백 (confess,
전략 A) 하고 다른 사람은 부인 (deny, 전략 B) 하면, 자백한 사람은 보상을 받고
(+1) 부인한 사람은 중벌에 처한다 (-2). 두 명 모두 자백하면 두 사람 모두를 경벌
(-1) 에 처한다. 두 명 모두 부인하면 (증거 불충분으로) 두 사람 모두 석방한다."
1950 년 이후 이 게임은 죄수의 딜레마 (Prisoner's
Dilemma) 로 알려졌고
사회과학에서 널리 연구되고 이용되어 왔다.
이 게임에서는 두 사람 모두에게 자백하는 것 B
가 우세전략이므로 (B, B) 가 유일한 평형점이 된다. 그러나 (B, B) 는 Pareto 최적이
아니고, 두 사람 모두에게 더 좋은 (A, A) 가 Pareto 최적이 된다. 위 상황의 관점에서
각 죄수는 다른 죄수가 무슨 선택을 하든지 상관하지 않고 자백하는 것이 유리하다.
하지만 죄수는 다른 죄수가 무슨 선택을 하든지 상환하지 않고 자백하는 것이 유리하다.
하지만 두 죄수가 모두 자백을 하게 되면 둘 다 자백을 하지 않을 때보다 나쁜 결과가
나오게 된다. 이것을 조심스럽게 생각해 보면, 우세의 원리의 형태로 된 개인적 이성주의
(individual rationality) 와 Pareto 의 원리의 형태로 된 집단적 이성주의 (group
rationality) 가 불일치하게 된다. 자신의 가장 좋은 이익을 합리적으로 추구하는
개인들에게 결국에는 그들 각각에게 불행한 결과가 초래하게 된다.
이러한 죄수의 딜레마 게임의 일반적인 형태는
전략 C 를 협력 (cooperate), 전략 D 를 변절 (defect) 이라 하고, R 을 협력에 대한
보상 (reward for cooperation), S 를 속은 자의 소득 (sucker payoff), T 를 유혹
소득 (temptation payoff), U 를 비협력의 소득 (uncoopertive payoff) 이라 할 때
다음 두 조건
|
(1) T > R > U > S
|
|
(2) R >
|
(S + T)
|
|
2
|
를 만족하는 다음 행렬이 된다.
|
행동이
|
열심이
|
|
|
C
|
D
|
|
C
D
|
(R, R)
(T, S)
|
(S, T)
(U, U)
|
|
|
|
|
이 게임에서 조건 (1) 은 두 사람 모두에게 전략
D 가 전략 C 보다 우세함을 의미하지만 유일한 평형점 (D, D) 는 (C, C) 보다 두
사람 모두에게 좋지 않다. 조건 (2) 는 두 사람 모두에게 전략 (C, D) 와 (D, C)
사이의 택일보다 (C, C) 가 더 나은 것을 의미한다. 그러므로 (C, C) 가 Pareto 최적이
된다.
죄수의 딜레마 모델의 중요성은 많은 사회현상이
근본적으로 이것과 비슷한 상황이라는 데 있다. 예를 들어, 두 개의 상점이 가격
경쟁을 하고 있는 경우를 상상해 보자. 한 상점이 가격을 낮추면, 그 상점은 상품당
이윤이 작아지지만 낮은 가격으로 더 많은 고객을 확보할 것이고, 가격을 내리지
않은 상점은 상품당 이윤은 크지만 고객이 줄어 매출 (또는 총이윤) 이 작아질 것이다.
그러므로 두 상점 모두 가격을 내리게 되어 모두가 보다 작은 이윤을 얻게 되고,
결국에는 두 상점 모두 가격을 내리지 않은 경우보다 이윤이 더 작게 된다. 두 국가간의
군비경쟁도 비슷한 경우이다. 각 국의 '무장' 과 '비무장' 이라는 두 개의 전략에
대하여 같은 이유로 설명이 가능하다.
이와 같이 개인적 합리성과 집단적 합리성
사이에 대립이 지대하므로 죄수의 딜레마의 모델의 해를 구하려는 많은 시도가 있어
왔다. 대부분의 시도는 우세의 원리에도 불구하고, Pareto 최적인 (C, C) 가 해가
되는 협력적인 전략을 정당화할 수 있는 논리를 찾고자 한다. 아래와 같은 세 가지
시도를 고찰해 보자.
죄수의 딜레마 모델을 해결하려는 가장 명백한
방법은 게임을 단 한 번만 겨룬다고 하지 않고 여러 번 반복하는 경우를 생각해 보는
것이다. 게임을 여러번 반복하는 경우에는, 서로에게 이롭지 않은 (D, D) 를 여러
번 맞는 것보다, 서로에게 이로운 (C, C) 에 도달할 수 있도록 일찍 협동할 수 있을
것이다. 그러나 불행하게도 이와 같은 착상은 논리적 도미노형태의 논쟁의 희생이
된다.
예를 들어, 죄수의 딜레마 게임을 100 번 반복하여
시행하는 경우를 가정해 보자. 두 참여자가 마지막 번째에서 어떤 전략을 택할 것인가를
생각해 보면, 두 참여자 모두에게 이것이 마지막 기회이고 (단 한번 하는 것과 같은
상황), 전략 D 가 전략 C 보다 우세하므로, 그들은 (D, D) 를 택할 것이다. 이것을
인식한 두 참여자 모두는 99 번째에서도 100 번째와 같은 마지막 기회로 생각하여
다시 (D, D) 를 택할 것이다. 이와 같은 상황을 알 게 된 두 참여자는 모두 같은
논리를 계속 적용하여, 마치 도미노가 계속하여 넘어지는 것과 같이, 첫 번째에도
그들은 (D, D) 를 택할 것이다. 즉 엄격한 논리가 처음부터 끝까지 두 사람 모두
협력하지 못하도록 할 것이다.
이와 같은 논리를 벗어날 수 있는 한가지 가능한
방법은, 실제에 있어서는 실질적인 참여자가 이와 같은 엄격한 일련의 논리적 시행에
집착하지 않는다는 것을 주목하는 것이다 (후에 다시 언급).
또 다른 가능한 방법은, 죄수의 딜레마 모델과
유사한 게임이 반복적으로 생기는 경우에 두 참여자가 이와 같은 게임이 몇 번 반복될지를
알지 못한다는 것이다. 언제 게임이 끝날지를 알지 못하는 상황에서는 마지막 도미노가
없으므로 유한 번의 시행과는 다른 상황이 될 것이다. 이와 같은 경우를 좀 더 자세히
살펴보자.
확률 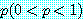 를 갖고 다음 번 시행이 생기는, 죄수의 딜레마 게임이 반복되는 상황을 살펴보자.
첫 번째 시행의 확률은 1 이고, 두 번째 시행의 확률은
를 갖고 다음 번 시행이 생기는, 죄수의 딜레마 게임이 반복되는 상황을 살펴보자.
첫 번째 시행의 확률은 1 이고, 두 번째 시행의 확률은 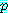 , 세 번째 시행의 확률은
, 세 번째 시행의 확률은 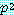 , 그리고
, 그리고 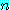 번째는
번째는 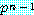 의 확률로 시행이 계속될 것이다. 한 참여자 1 의 상대방은 전략 C 를 택함으로
시작하여 참여자 1 이 전략 D 를 처음으로 택할 때까지 계속 C 를 택하고, 그 이후로는
모두 (D, D) 를 택하는 경우를 가정해 보자. 한 참여자가 결코 D 를 택하지 않은
경우 (협력하는 경우) 의 그의 소득은
의 확률로 시행이 계속될 것이다. 한 참여자 1 의 상대방은 전략 C 를 택함으로
시작하여 참여자 1 이 전략 D 를 처음으로 택할 때까지 계속 C 를 택하고, 그 이후로는
모두 (D, D) 를 택하는 경우를 가정해 보자. 한 참여자가 결코 D 를 택하지 않은
경우 (협력하는 경우) 의 그의 소득은
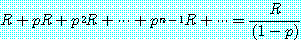 (1)
(1)
이다. 그러나 한 참여자가 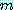 번째에서 그의 전략을 D 로 바꾸는 경우에 그의 소득은
번째에서 그의 전략을 D 로 바꾸는 경우에 그의 소득은
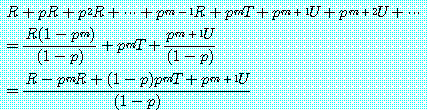 (2)
(2)
가 된다. 그러므로 그는 (1) 이 (2) 보다 큰 경우에는
결코 전략 D 를 택하지 않을 것이다. 즉 모든 m 에 대하여 부등식
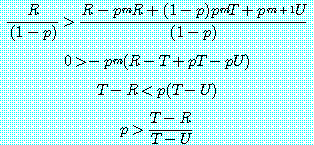
이 성립하는 경우에 결코 전략 D 를 택하지 않을
것이다. 이 때
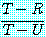
을 초입치 (threshold value) 라고 하며, 게임이
계속될 확률이 초입치보다 커야지만, 상대방도 그럴 것이라는 가정하에 이들은 협력하는
전략을 택할 것이다. 위에서 예로 든 게임의 초입치는
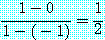
이고, 앞 절에서 예로 살핀 죄수의 딜레마 게임
2 의 초입치는
|
행동이
|
열심이
|
|
|
A
|
B
|
|
A
B
|
(3, 3)
(5, -1)
|
(-1, 5)
(0, 0)
|
|
|
|
|
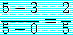
이다.
메타게임의 논리
(metagame argument)
죄수의 딜레마 게임이 단 한 번 시행되는 경우에,
두 참여자 모두 전략 C 를 택하게 할 논거가 있는가? 우선 열심이를 생각해 보자.
그는 협력하는 전략인 C 를 택하는 것을 원할 수도 있다. 그러나 열심이가 그렇게
했을 경우에, 상대방인 행동이가 협력하지 않을 경우에는, 속은 자의 소득을 얻게
된다. 그러므로 행동이가 어떻게 할 것이라는 그의 생각에 따라 그의 전략 선택을
결정할 것이다.
예를 들어 열심이는, 행동이가 협력할 것이라고
생각되면 협력할 것이고 (행동이가 C 를 택한다고 생각되면 열심이도 C 를 택할 것이고),
행동이가 변절할 것이라고 생각되면 그도 변절할 것이다 (행동이가 D 를 택한다고
생각되면 열심이도 D 를 택할 것이다). 불행하게도 이와 같은 희망적 착상은 비록
행동이가 협력하는 경우라도 열심이에게 변절하는 것이 더 나은 소득을 얻게 된다는
사실에 직면한다. 그러나 이와 같은 착상을 한 단계 더 나아가 보자. 열심이는 (행동이가
어떻게 할 것이라는 열심이의 생각에 따른) 부수전략 (contingent strategy) 을 택하고,
행동이는 (열심이가 행동이의 전략을 생각한) 열심이의 부수전략에 대한 행동이의
부수전략을 택한다고 가정하자. 이와 같은 착상을 메타게임의 논리 (metagame argument)
라고 한다.
이제 메타게임을 자세히 살펴보자. 우선 행동이의
선택에 대한 열심이의 부수전략을 생각하는 제 1 위 메타게임 (first level matagame)
의 경우는, 행동이는 A 와 B 의 두 개의 전략을 갖고 열심이는 다음과 같은 네 개의
전략을 갖는다.
AA : 행동이가 어떤 전략을 사용할 것이라고
생각되는 것과 무관하게 C 를 택함.
AB : 행동이가 어떤 전략을 사용할 것이라고
생각되는 것과 같게 택함.
BA : 행동이가 어떤 전략을 사용할 것이라고
생각되는 것과 반대로 택함.
BB : 행동이가 어떤 전략을 사용할 것이라고
생각되는 것과 무관하게 D 를 택함.
이것을 행렬게임으로 나타내면 다음과 같다.
|
행동이
|
열심이
|
|
|
AA
|
AB
|
BA
|
BB
|
|
A
B
|
(0, 0)
(1, -2)
|
(0, 0)
(-1, -1)
|
(-2, 1)
(1, -2)
|
(-2, 1)
(-1, -1)
|
|
|
|
|
|
|
위 게임에서는 더 이상 행동이 B 가 행동이 A 보다
우세하지 않고, 열심이의 BB 가 그의 다른 세 개의 전략보다 우세하다. 그러므로
(행동이 B, 열심이 BB) 가 유일한 평형점인데, 이 결과도 두 참여자가 협력하는 경우를
뜻하지는 않는다. 즉, 제 1 위 메타게임의 해는 협력적인 전략이 아니다.
다음은 열심이는 부수전략을 취하고 행동이는 열심이의
부수전략에 대한 부수전략을 취하는 경우인 제 2 위 메타게임 (secondlevel matagame)
을 살펴보자. 이 경우에 행동이는 다음과 같은 16 개의 전략이 있다.
|
AAAA,
|
AAAB,
|
AABA,
|
AABB
|
|
ABAA,
|
ABAB,
|
ABBA,
|
ABBB
|
|
BAAA,
|
BAAB,
|
BABA,
|
BABB
|
|
BBAA,
|
BBAB,
|
BBBA,
|
BBBB
|
예를 들어 행동이의 BABB 는, 열심이가 전략 AB
를 택한다고 생각되는 경우에는 A 를 택하고, 그렇지 않은 경우에는 모두 B 를 택하는
전략을 뜻한다. 위의 결과를 행렬게임으로 나타내면 게임 3 과 같다.
위 행렬게임에서 열심이의 전략 중에는 우세한
것이 없으나, 행동이의 BABB 는 그의 다른 모든 전략보다 우세하다. 그러므로 이
사실을 아는 두 참여자에게 (BABB, AB) 가 평형점이 된다. 이것은 행동이는 열심이가
전략 AB 를 택한다고 생각되는 경우에는 A 를 택하고, 그렇지 않은 경우에는 B 를
택하는 전략을 뜻하게 되어, 결과적으로 두 게임의 참여자가 협력하는 상황을 나타낸다.
즉 행동이의 최선책은 열심이가 행동이와 같은 전략을 택한다고 믿고 협력적인 전략을
택하는 것인데, 이와 같은 것을 알고 열심이가 행동이와 같은 전략을 택해야만 한다.
이 같은 결과는 시사하는 바가 없다. 즉 상대방이 협력하면 협력할 것이라는 것을
서로 믿고, 서로가 협력하는 전략을 택하는 경우가 죄수의 딜레마 모델의 해가 된다.
|
행동이
|
열심이
|
|
|
AA
|
AB
|
BA
|
BB
|
|
AAAA
AAAB
AABA
AABB
ABAA
ABAB
ABBA
ABBB
BAAA
BAAB
BABA
*BABB
BBAA
BBAB
BBBA
BBBB
|
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(1,
-2)
(1,
-2)
(1,
-2)
(1,
-2)
(1,
-2)
(1,
-2)
(1,
-2)
(1,
-2)
|
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(-1,
-1)
(-1,
-1)
(-1,
-1)
(-1,
-1)
(0, 0)
(0, 0)
(0, 0)
(0, 0)
(-1,
-1)
(-1,
-1)
(-1,
-1)
(-1,
-1)
|
(-2,
1)
(-2,
1)
(1,
-2)
(1,
-2)
(-2,
1)
(-2,
1)
(1,
-2)
(1,
-2)
(-2,
1)
(-2,
1)
(1,
-2)
(1,
-2)
(-2,
1)
(-2,
1)
(1,
-2)
(1,
-2)
|
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
(-2,
1)
(-1,
-1)
|
|
|
|
|
|
|
실험적인 방법으로 시행하여 보자. 우선 두 사람씩
짝지어 각자의 전략을 택한 후 소득을 기록하고, 다시 각자의 전략을 택하는 시행을
여러 번 실험한 결과를 종합해 본다.
죄수의 딜레마 게임의 반복적 실험에서 상당히
우수한 전략으로 Axelrod 의 TIT FOR TAT (맞받아 쏘아주기, 오는 말에 가는 말)
를 들 수 있다. Axelrod 의 TIT FOR TAT 는
|
C 로 시작한다.
이후로는 상대방이
바로 직전에 택한 전략을 택한다.
|
는 것 (Do unto your opponent whatever your opponent
has just done unto you !) 으로 다음과 같은 네 가지 성질이 있다.
친절 (Nice) : 협력으로 시작하며 먼저 변절하지
않는다.
보복 (Retaliatory) : 상대방의 변절에 대해서는
(변절로) 보복한다.
용서 (Forgiving) : 변절에 대하여 보복한
이후에는 다시 협력하려고 한다.
투명 (Clear) : 경기의 방식은 일관적이어야
하고 예측이 쉬어야 한다.