지능을 위한 기호적 처리
통합인지이론 : Allen Newell 저, 차경호 옮김, 아카넷 , 2002 (원서 : Unified Theories of Cognition, Harvard Univ. Press, 1990), Page 225~323
1.5. 막다른 상태와 어려움들을 해소하기 위한 하위목표
4. R1 소어 <지식-집약적, 그리고 지식-비집약적 연산>
이 장에서는 주로 지능을 위해 요구되는 기호적 처리 —— 실제 세계에서 지능적일 수 있는 기호적 시스템의 세부사항들 —— 를 다룬다. 앞의 장들은 완전한 인지 시스템이 나타내야만 하는 일반적 특성들의 집합을 제시했다. 그러나 세부사항들이 중요하다. 인지이론이 설명해야만 하는 특성이 있다면 그것은 바로 지능이 실제적으로 어떻게 가능한가 라는 점이다. 필요한 특성들도 좋고 중요하지만, 그것들은 본질적으로 이야기의 반에도 못미친다. 충분성이 절대로 중요하다. 지능 그 자체가 능력의 충분성이다. 지능적이라는 것은 어떤 일을 할 수 있다는 것, 말하자면 현재 유기체가 갖고 있는 어떤 (부호화된) 목표를 달성하기 위해 (부호화된) 지식을 활용하는 것이다. 이론이 실질적으로 이러한 능력들을 증명할 수 없다면, 그 이론은 지능을 설명한다고 주장할 수 없다. 그리고 충분성을 증명하는 것은 모든 세부사항들을 요구한다. 그러므로 이번 장의 초점은 일반적 고려사항을 컴퓨터에서 실현시키고 지능행동의 범위를 나타낼 수 있는 하나의 시스템으로 변경함에 있다.
설명될 시스템인 소어는 통합인지이론의 후보자를 위한 기초를 제공하는 구성이다. 첫 번째 장에서도 분명히 했던 것처럼 통합인지이론들을 주장하는 유일한 방법은 특정한 후보이론을 제시해서 그것의 능력을 시험하는 것이다. 그렇게 하는 것이 특정한 후보이론이 완전히 발전된 이론으로서 과학적 탐구의 모든 노력을 대표할 수 있음을 뜻하는 것은 아니다. 그러나 그러한 예는 필요하며, 소어는 그러한 본보기이다.
여전히 연결은 결여되어 있다. 나는 필요한 것이 통합인지이론의 본보기라는 주장을 해왔고, 이제 이 장에서 하나의 구성, 소어에 대해 이야기하려 한다. 그 속에 함축적인 것은 통합인지이론을 명세화하는 것이 바로 구성을 명세화하는 것이라는 주장이다. 그것이 이론 전체는 아닐 수 있지만, 구성은 이론의 중심이다. 인간이 앞의 두 장에서 말했던 시스템의 종류라고 했을 때, 행동에서 시스템이 보일 공유성의 배후에 있는 것이 바로 구성 —— 고정된 (또는 느리게 변하는) 구조 —— 이다. 구성은 기억에 저장된 외부세계에 대해 부호화된 지식에 접근하고, 목표를 위한 행위들을 결정하는 데 지식을 사용하는 기제들의 시스템이다. 만약 그것이 완벽하게 작동한다면 행위들은 단지 이러한 외적인 지식들만을 반영한다 —— 그 시스템은 지식-수준 시스템처럼 행동한다. 그러한 시스템은 심리학을 갖고 있지 않다. 심리학은 부호화된 기억구조의 처리가 나타날 때 정확히 개입한다. 이러한 처리 모양을 결정하는 것이 바로 구성이다.
이 장의 주요한 초점은 어떻게 전체 시스템이 지능적 행동을 실질적으로 실현할 수 있는가 하는 문제로 주어질 것이다. 우리는 먼저 중앙 central 인지, 즉 구성의 기호적 부분에 대한 구성에 대한 논의와 모든 중앙인지에 스며들어 있는, 경험으로부터의 학습현상에 대해 논의할 것이다. 그 다음 우리는 약간 뒤로 돌아가 중앙 시스템이 포함되어 있는 전체 인지 시스템, 즉 지각적 처리와 운동처리를 기술할 것이다. 이런 전체적인 맥락 아래에서 우리는 중앙 시스템이 어떻게 기능하는지를 예시하고, 그것의 능력을 묘사하려고 시도할 것이다. 이런 일들을 하면서도 우리는 이러한 세부사항들이 어떻게 인간행동과 일치하는지에 대해서는 주의를 기울이지 않을 것이다. 물론 그 구성은 앞에서 기술했던 모든 제약들을 구체적으로 설명했기 때문에 일반적으로 말해서 그것은 올바른 것일 터이다. 이미 제시되었던 기초들을 생각하자면 소어에 대한 많은 것들은 매우 친숙한 것처럼 보일 것이다. 이장의 마지막에서 완전한 명세화가 만들어지면, 우리는 소어를 인간인지에 대응시키는 것을 고려할 것이다. 그러한 대응의 세부사항과 결과를 검토하는 것은 이 책의 나머지 부분이 감당해야 할 과제이다. 그러나 우리는 이 장을 끝내면서 소어가 인간으로 인식될 수 있는 인지적 동물을 기술하는지를 물어볼 수 있을 것이다.
중앙구성은 인지의 기제를 나타내지만 지각이나 운동행동의 기제를 나타내지는 않는다. 1 장에서 이미 살펴본 것과 같이, 인지에 대한 많은 이론화에서 한 가지 잘못된 것은 한편으로는 지각에, 다른 한편으로는 운동행동에 많은 주의가 주어지지 않았다는 것이다. 그러한 이론들은 이들 두 시스템을 빼 버린다. 그 결과, 그 이론은 이러한 시스템들이 제공할 수도 있는 중앙 기호적 인지에 대한 제약을 포기한다. 이러한 손실은 심각한 것이다 —— 그것은 이론들이 자극으로부터 반응에 이르기까지 완전한 연결을 포함하지 못하도록 한다. 즉 어떤 특정한 반응에 대해서도 완전한 이야기를 절대 할 수 없다.
이러한 기제들에 대해 인지심리학이 주의를 기울이지 않는 이유는 자각이 부족하거나, 욕망이 부족해서가 아니다. 우리 모두는 특히 진화론적 입장에 서서 지각, 인지, 그리고 운동행동의 관계가 얼마나 밀접한지를 이해하고 있다. 인지는 의심할 여지없이 지각-운동 활동에 기여하기 위한 시스템으로 성장한 것이다. 2 장에서 마음을 통제장치로 보는 관점은 이러한 일반적인 시각에 응답하는 것이다. 어려움이 있다면 동시에 다루기에는 전체 시스템이 너무 복잡하다는 것이고, 지각이나 운동 활동에 대한 고려사항들은 통합되기에는 너무나 본질적으로 다른 것 같이 보인다는 것이다. 그렇기 때문에 좋은 방법은 조금씩 나누어서 정복하는 것이다.
첫 번째로 중앙 인지를 기술함으로써, 나는 이 절에서 그와 똑같은 잘못을 저지르고 있다. 나는 이 장을 끝마치기 전에 이 상황을 적어도 약간은 수정할 것이다. 그러나 사실 소어의 지각, 그리고 운동 시스템들은 아직도 초기의 상태이다. 이 장은 소어에 대해 확고하고 실제적인 것에 가능한 한 가깝게 유지하려고 할 것이다.
|
1. 문제공간들은 모든 과제들을 표상한다 • 문제-해결 구성 (처리과정 계층들이 아님) 2. 산출들은 모든 장기기억 (기호들) 을 제공한다 • 탐색 통제, 연산자들, 서술적 지식 3. 속성 / 값 표상은 모든 것들에 대한 매체이다 4. 선호-기반적 절차가 모든 의사결정에 사용된다 • 선호 언어 : 수용 / 거부, 더 좋다 / 차이 없다 / 더 나쁘다 5. 목표들 (그리고 목표 스택) 이 모든 행동을 지배한다 • 하위 목표들은 수행시 막다른 상태들로부터 자동적으로 만들어진다 6. 모든 목표-결과들 (막다른 상태의 해결책들) 의 청킹은 계속해서 발생한다 |
그림 1 중앙 인지의 주요 특성들
그림 1 은 소어의 중앙 인지의 주요 특성들을 목록화한 것이다. 1 절의 나머지 부분은 이것들 중 처음의 5 개를 제시하고, 이것들은 소어가 과제들의 수행을 할 수 있도록 해주는 구성적 구조를 이룬다. 나는 6 번째 항목에 대한 기술, 즉 소어의 학습기제는 2 절로 미룰 것이다.
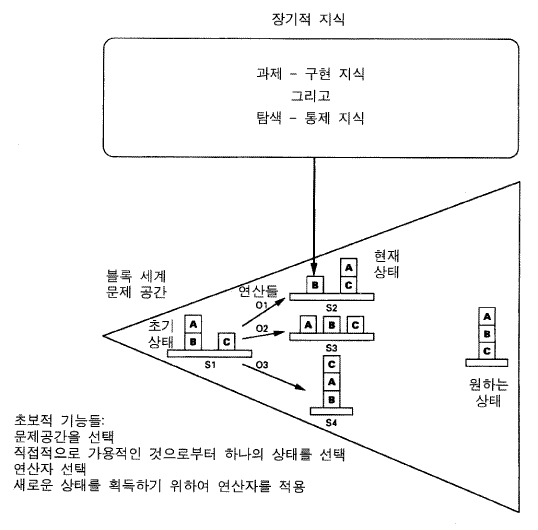
소어는 그것의 모든 과제들을 문제공간들로 형식화한다. 모든 시스템은 그것이 작용하는 과제들을 어떤 식으로든 표상해야 한다. 표상은 지식이 사용되고 또 과제의 달성이 평가되는 틀을 제공한다. 그러므로 소어는 모든 인지활동은 탐색공간에서 일어난다.
그림 2 소어 문제-공간 구성
그림 2 는 문제공간의 그림을 제시하는데, 이것은 그림 2-16 의 것과 유사해 보인다 (동일한 블록-세계 영역에 대한 것이다). 과제를 달성하기 위해서 —— 요구되는 기호적 대상을 구성하기 위해서 —— 문제공간은 탐색된다. 여기에서의 과제는 탁자 위에 블록 B 와 C 가 있고 A 가 B 위에 있는 초기상태 (S1) 에서 시작해서, 희망하는 상태 (S4), 즉 C 위에 B 가 있고 B 위에 A 가 있는 상태로 구성하는 것이다. 문제공간에서 작동할 때, 시스템은 항상 어떤 현 상태에 위치해 있다. 시스템은 문제 공간의 어떠한 연산자들이라도 현 상태에 적용할 수 있다. 그림은 초기상태에 적용될 수 있는 가능한 연산자들로서 o1, o2, 그리고 o3 의 세 개의 연산자들을 보여준다. 이러한 연산자들은 여러 블록들을 이동시키는 것들과 일치한다-연산자 o1 은 블록 A 를 C 위로 이동시키고, o2 는 A 를 탁자로 이동시키고, o3 은 C 를 A 위로 이동시킨다. 이 문제공간은 블록 세계에서의 문제 해결에 유용한데, 이는 정확히 현상태인 자료구조에 연산자들이 하는 것과 외부세계의 실제 블록에 실제 이동들이 하는 것을 연결시키는 표상법칙 때문이다.
문제공간에서의 연산은 연산자를 구현하는 지식과, 탐색을 안내하는 지식을 모두 요구한다. 이러한 지식은 시스템의 장기기억에 보관되어 있으며 현 상태에서 사용된다 (그러므로, 그림은 실제로 현 상태가 S2 임을 보여주는데, 이것은 초기상태인 S1 에 연산자 o1 이 적용된 후에 발생한 것이다). 장기기억은 시스템이 수용가능한 모든 문제공간들을 통해 탐색을 구현하고 안내하는 지식들을 보유하고 있다 —— 이러한 장기기억의 탐색은 이 공간과 현 상태에 관련이 있는 지식들을 찾기 위해 요구되는 것이다.이것은 지식 탐색이며, 이것은 새로운 상태들을 구성하기 위해 한 상태에 연산자들을 적용하는 문제-공간 탐색과는 다르다. 특히 지식탐색은 물리적으로 존재하는 기억을 통해서 이루어지며, 문제-공간 탐색은 한번에 하나의 상태만을 만들어내기 때문에 한 시점에 단지 하나만의 물리적 상태가 존재한다. (주석 : 물론, 생성되어진 옛 상태들은 나중의 인출을 위해서 기억에 저장될 수 있다 (그러나 이것은 물리적 공간에서 모든 상태들을 미리 존재하도록 만들기보다는 하나의 상태씩 생성된다는 문제 공간의 특성을 변화시키지는 않는다.).)
소어가 하는 모든 인지과제는 문제공간에 의해 표상된다. 그러므로 소어가 수행해야 하는 초보적인 기능들은 그것이 문제공간들을 갖고 어떻게 작동할 것인지를 결정하는 것들이다. 이러한 것들이 그림에 열거되어 있다. 그것들은 작용할 문제공간을 선택하고, 문제공간에서 하나의 상태를 선택하고 (만약 사용가능한 것이 하나 이상이라면), 선택된 상태에 적용될 공간의 연산자를 선택하고, 그리고 공간에서 한 단계 나가기 위해 그 연산자를 그 상태에 적용한다. 이러한 초보적 기능들은 이 시스템이 취해야만 할 숙고의 행위들이다. 소어 구성은 이러한 기능들을 직접적으로 달성하도록 만들어졌다. 그것이 바로 행동을 생성하기 위해 소어가 해야 하는 모든 것이다. 그러므로 그것은 문제-공간 구성 problem-space architecture 으로 특징지워질 수 있다.
이러한 조직화는 표준적인 컴퓨터 구성의 조직화와 대비될 수 있는데, 이는 그것들이 컴퓨터 과학에서 발전된 것이기 때문이다. 표준적 컴퓨터 구성들은 기억의 자료-구조 (프로그램) 에 의해 결정되는 연산들의 연쇄를 따르는 것을 기본적인 과제로 받아들인다. 초보적 기능들은 수행된 연산 (곱하기와 같은) 을 조합하고, 연산에서 입력으로 쓰일 피연산자 (승수와 피승수) 를 조합하고, 피연산자들에게 연산을 적용하고, 결과 (산출물) 를 저장하고, 그리고 다음의 연산을 결정하기 위해서 프로그램 구조를 선택하는 것이다 (그림 2-13 을 회상하라). 전통적인 종류의 어떤 가용한 연산-피연산자 조직화에서 구성을 프로그램으로 작성함으로써 다른 처리 조직화들을 실현하는 것은 컴퓨터 과학에서 일반적인 것이다. 문제-공간 조직화에 대해서도 이것은 분명히 이루어질 수 있고, 이것이 바로 현재의 컴퓨터들에서 작동되도록 소어 시스템 소프트웨어를 만든 방식이다. 그러나 만약 문제공간이 기본적 조직화이고 여기의 문제공간에서 단지 연산만이 일어난다면, 초보적인 기능들은 어떤 다른 방식으로 조직된 또 다른 계산적 엔진에 의존하지 않고, 그림 4-2 에 제시된 것들일 수 있다. 그림 2 의 4 가지 기능들은 정말로 초보적인 것임에 틀림없다 —— 그리고 구성의 나머지의 대부분이 이러한 기능들을 달성하기 위해 사용된다.
문제가 어려울 때 탐색공간들을 사용하는 것은 AI 의 표준적인 것이다 (Rich, 1983). 그러나 과제들이 일상적인 것 routine 일 때, 표준적인 관행은 그것들을 연쇄적이고 절차적인 통제를 허용하는 언어로 된 프로그램에 의해 명세화된 행동으로서, 다른 말로 하면, 연산-피연산자 조직화를 사용하는 것으로 형식화하는 것이다. 그러나 소어에서는 모든 행동, 일상적인 것이라 할지라도, 문제공간을 통한 이동으로 표상된다. 탐색이 나타나는가 하는 문제는 어떤 지식이 가용적이며 사용 되어지는가에 달려 있다. 만약 많은 지식이 사용된다면, 소어는 목표에 직접 도달하고 일상적인 행동을 보인다. 만약 지식이 거의 가용적이지 않다면, 소어는 비방향적이고 조합적인 탐색을 많이 할 것이다.
과제표상으로서의 문제공간을 이렇게 획일적으로 사용하는 것은 문제공간 가설 problem space hypothesis (Newell, 1980c) 이라고 불린다. 이것은 하나의 획일적인 구조 또는 과정이 채택되는 소어의 여러 측면들 중의 하나일 뿐이다. 그러한 획일성 uniformities 의 효과들은 단지 그것들이 가능하게 하는 시스템 전반에 걸친 문제들에 대한 해결의 관점에서만 적절하게 평가될 수 있다. 문제공간의 획일적 사용은 두가지의 그러한 문제들에 강력한 영향을 준다. 첫째 통제정보의 결합은 연산자가 적용되기 바로 전인 실행시간에 일어나는 반면에, 표준적인 (연쇄적이고 절차적인) 언어들에서의 결합은 프로그램이 만들어질 때 일어난다.그러므로 문제공간은 그 순간에 가용적인 지식의 관점에서 각 상황에 대해 반응할 수 있는 기회를 제공한다. 이것은 AI 가 최소-관여 방략 minimum-commitment strategy —— 선택이 강요될 때까지 절대로 관여하지 않는다. —— 이라고 부르는 형식이다. 둘째 소어처럼 계속적으로 학습하는 시스템에서는, 문제상황 (많은 탐색) 에서 루틴 (적은 탐색) 으로의 이동은 연속적이다. 그것은 결코 표상의 비연속적 변화에 대한 요구를 직면하지 않는다. 이러한 이득들을 상쇄하는 것은 실행시간에 반복적으로 결합결정을 하는 데 필요한 추가적인 처리이다.
중앙 인지구성의 두 번째 특징은 그것의 모든 장기기억은 단일한 산출 시스템으로서 구성되어 있다는 것이다. 모든 것에 대한 기억은 동일한 구조, 동일한 쓰기 과정, 그리고 동일한 읽기 (또는 접근) 과정들에 의해서 다루어진다 —— 탐색통제에 대해, 연산을 구현하는 방법에 대해, 서술지식에 대해, 역사적 (일화적) 지식에 대해, 모든 것들에 대해. 이것은 또 하나의 획일적 가정이다. 이것은 가장 논쟁을 많이 불러일으키는 소어 구성의 특징이다. 컴퓨터 과학, AI , 그리고 인지과학에서 사람들은 대부분 서술기억과 절차기억은 근본적으로 별개의 구조에 의해 유지되는 별개의 기억이라는 견해를 유지하고 있다. 예를 들면, 이것은 엑트스타의 핵심이고 아주 강조되는 특징이다 (Anderson, 1983). 많은 사람들은 또한 일화기억과 의미기억에 대한 개별적인 기억구조를 만들려고 한다 (Tulving, 1983). 소어는 단일한 획일적인 기억을 갖고 살아갈 수 있는지에 대한 하나의 탐구이다.
|
산출 기억 (재인 기억)
P1 c1 그리고 C2 그리고 C3 → A1' A2 P2 C4 그리고 C5 → A3 P3 C6 그리고 C3 그리고 → C5 그리고 C7 → A1' A4 |
|
↓ ↓ |
|
작업 기억 E1' E2' E3' ??? |
그림 3 소어 산출 시스템
대부분의 인지과학자들은 병렬적 규칙-기반 시스템 parallel rule-based systems 또는 패턴-지향적 추론 시스템 pattern-directed inference systems 이라고도 불리는 산출 시스템에 친숙하다 (Waterman & Hayes-Roth, 1978). 그림 3 은 그 구조를 보여준다. 산출들의 영구적인 기억이 존재한다. 그림에는 3 개의 산출들 (P1, P2, P3) 만 있지만, 그것들은 3,000 또는 30 만 개일 수도 있다. 자료요소들 (E 들) 의 모임인 작업기억이 있다. 각 산출은 조건들 (C 들) 의 하나의 집합을 갖고 있다. 각 조건은 작업기억의 어딘가에 있는 작업-기억 요소와 대응된다. 만약, 모든 조건들이 만족되면, 산출은 만족된다. 그러면 그것은 그것의 행위들 (A 들) 을 점화시키고, 이것들은 새로운 작업-기억 요소들로서 작업기억에 들어간다.
산출에 대한 표준적 관점은 그것들이 적용가능성을 결정하는 조건들과, 조건들이 만족되었을 때 발생하는 행위들을 갖고 있는 연산자와 같은 실체라는 것이다. 이 관점에서는 추가적인 탐색통제가 그 산출을 실행하는 것이 바람직한 것인지를 결정하는 데 사용될 수 있다 (Nilson, 1980). 그러나 산출 시스템은 또한 단순히 내용-주소화 content-addressed 기억으로 여겨질 수도 있다. 오른편 (그림의 A 들) 은 내용이며 기억에 부호화된 지식이다 [그리고 왼편 (그림의 C 들) 은 접근 구조인 인출 단서들이다)] . 그러므로 산출 시스템은 단순히 일종의 재인 시스템 recognition system 이다 —— 그것은 기억에서 패턴을 재인하고 그것의 내용을 제공함으로써 반응한다. (여기서의 용어는, 재인의 결과는 단지 <예> 또는 <아니요> 라고 가정하는 심리학과 컴퓨터 과학의 대부분에서의 사용법과는 다소 차이가 있다.) 그것은 절차적 기억에 대한 방식처럼 서술적 정보에 접근하고 인출하기 위한 방식이다. 소어에서 산출 시스템은 그 두 역할 모두를 한다.
소어 산출 시스템은 Ops5 (Forgy, 1981) 에서 실현되는데, Ops5 는 1970 년대 후반에 개발된 것으로 전문가-시스템 영역에서 표준적 산출 시스템이 되어온 언어이다 (Brownston, Farrell, Kant, & Martin, 1985). 그러므로 산출들의 세부사항은 Ops5 로부터 얻어진다. 조건들은 임의적인 검사가 아니고 대응되어야 할 패턴들이다. 패턴들은 특정한 변수들을 가질 수 있고 동일한 변수가 한 조건 이상에서 일어날 수도 있는데, 이 경우 그 변수는 모든 발생조건에서 동일한 값을 취해야만 하며, 사실상 동일성 equality 검사를 제공한다. 조건들은 작업기억에서 한 요소가 존재하는 것은 물론, 존재하지 않는 것에 대해서도 검사할 수 있다. 모든 가능한 실례화들 instantiations 은 각 주기마다 찾아진다 (즉 변수들의 결합들과 함께 각 산출을 만족시키는 작업-기억 요소들의 모든 가능한 집합들).
|
영어판 산출 Propose-operator' comprehend : If the problem space is the base-level-space, and the state has a box with nothing on top, and the state has input that has not been examined, then make the comprehend operator acceptable, and note that the input has been examined. 한글판 산출 제안-연산자' 이해 만약 문제공간이 기본수준 공간이고, 상태가 위에 아무것도 없는 하나의 블록을 가지고 있고, 상태가 검토되지 않은 입력을 가지고 있다면, 그러면 이해 연산자가 수용되도록 만들고, 그 입력이 검토되었음을 주목하라. 소어판 산출 (sp propose-operator' comprehend : (goal <g> ^problem-space <p> ^state <s>) (problem-space <p> ^name base-level-space) (state <s> ^object <b> ^input <i>) (box <b> ^on table ^on-top nothing) - (signal <i> ^examined yes) → (operator <o> ^name comprehend) (preference <o> ^role operator ^value acceptable ^goal <g> ^problem-space <p> ^state <s>) (input <i> examined yes)) 산출 점화 전의 작업-기억 요소들 (goal g3 ^problem-space p14 ^state s51) (problem-space p14 ^name base-level-space) (state s51 ^object b80 b64 ^input i16 ^tried o76) (block b80 ^on table ^on-top-nothing) (block b70 ^on table ^on-top b61) (block b64 ^on b61 table ^on-top-nothing) (input i16 advice a31) 산출 점화 후에 추가된 작업-기억 요소들 (operator o82 ^name comprehend) (preference o82 ^role operator ^value acceptable ^goal g3 ^problem-space p14 ^state s51) (input i16 ^advice a31 ^examined yes) |
그림 4 점화 전, 그리고 후의 소어 산출과 작업기억의 예
그림 4 는 블록-세계 과제에 대한 정보를 받아들이는 데 사용되는 연산자를 제안하는 소어 산출의 한 예를 보여준다. 영어 (한글) 구문이 제일 상단에 제시되어 있고 그 밑에 실제의 산출, 그 다음에는 그 산출이 대응시키는 작업-기억 요소들, 그리고 하단에는 산출이 점화되었을 때 작업기억에 추가되는 새로운 요소들이 제시되어 있다.
각각의 작업기억 요소는 대상의 단일한 속성 attribute 과 값 value 이다. 예를 들어, 산출이 점화되기 전의 작업기억을 기술하는 첫 번째 줄에서 목표대상 g3 은 문제공간 p14 를 한 요소로 갖고 있다 —— 목표 g3 은 상태 s51 을 또 하나의 요소로 갖고 있다 —— 대상이 만들어질 때 대상들은 소어에 의해 할당되는 임의적 확인자 identifier (g3) 를 갖는다 (접두사, g 는 사용자를 도와주기 위한 단순한 기억보조장치이다) ; 모든 속성들은 ^ 에 의해 표시되고 그것들의 값들이 바로 그것들을 뒤따른다. 또한, 사용자를 위한 것으로서, 동일한 대상 (여기서는 g3) 에 대한 모든 요소들은 함께 모여 있다 —— 요소들은 작업기억에서 어디라도, 그리고 어떠한 순서에 의해서라도 분산될 수 있다.
그 산출의 이름은 제안-연산자'이해 propose-operator' comprehend 이다-그것은 5 개 조건과 3 개의 행위를 갖고 있다. 첫 번째 조건은 목표대상 (goal ···) 을 대응시키고 그것의 확인자 g3 은 변수 <g> 와 묶여진 것이다 (산출에서의 모든 변수들은 산형 괄호 <> 에 의해 표시된다). 목표요소는 속성 ^problem-space 를 갖고 있어야만 하며, 그것의 값은 변수 <p> 와 묶여질 것이다 —— 그리고 속성 ^ state 의 값은 변수 <s> 와 묶여질 것이다. 이 첫 번째 조건은 활동적인 목표요소에 연결시키는 것을 명세화하는 것 이외의 대응을 제약하지 않는데, 이는 모든 값들이 단순히 변수들과 묶여지는 것들이기 때문이다. 그러나 그 다음 조건은 문제 공간요소 <p> 가 기본-수준-공간 base-level-space 이라는 이름을 갖아야만 함을 명세화한다. 세 번째 조건은 상태 <s> 를 두 가지로 제약한다. 첫째 (네 번째 조건) <s> 는 탁자 위에 있고, 그 위에는 아무것도 없는 블록이어야 한다. 둘째 (다섯 번째 조건) 그것은 검사되지 않은 입력을 갖고 있어야만 한다. 이 후자의 것은 부정조건 (-에 의해 표시되는) 으로 주어졌는데, 이것은 단지 조건 그 자체가 작업기억의 어떠한 요소에 의해서도 만족되지 않을 때만 만족된다. 상태 s51 은 사실상 여러 개의 블록들 (b80, b70, b64) 을 갖고 있지만 단지 하나만이 탁자에 있고, 그 위에 아무것도 없다는 조건을 만족시킨다. 그러므로 조건들은 특정한 요소들 —— 즉 대상의 속성과 값 —— 과 대응되며 하나의 전체 대상과 대응되는 것은 아니다. 그 상태는 또 다른 요소 (^ tried o76) 역시 갖고 있고 이것은 그 산출의 대응에는 전혀 개입을 하지 않음을 주목하라.
만약 모든 조건들이 만족되면 (여기서 그런 것처럼) 산출은 세 가지 행위를 점화시키고, 이것은 세 개의 요소들을 작업기억에 추가시킨다. 첫 번째 요소는 이해 comprehend 라 불리는 새로운 연산자 o82 를 만든다. 이것은 새로운 연산자인데, 이는 행위요소에 있는 <o> 가 조건 편에서는 일어나지 않았고, 그러므로 작업기억에서 기술된 이미 존재하는 대상에 이미 결합된 것은 아니었기 때문이다. 작업기억에 추가되는 두 번째 요소는 o82 가 목표맥락 (g3, p14, s51) 에서 허용될 수 있는 연산자임을 주장하는 선호 preference 요소인데, 여기서 목표, 문제공간, 그리고 상태들은 작업기억에 이미 있는 요소들을 대응시키는 목표조건 (goal g3 ^problem-space p14 ^state s51) 에 의해 결정되는 것들이다. 선호 요소들의 역할은 잠시 후에 기술될 것이다. 세 번째 요소는 존재하는 입력에 대한 추가적인 속성과 값 (^attention yes) 이다.
어떤 것들은 더 많은 조건들과 행위들을 갖고 있지만, 이것이 전형적인 소어 산출이다. 하나의 산출은 여러 종류의 계산들을 달성할 수 있다 (Newell, Rosenbloom, & Laird, 1989). 그것은 단지 그것의 조건들이 대응될 때만 발생하는 조건적 계산이다. 그것은 새로운 속성들과 값들을 추가함으로써 기존의 대상을 수정할 수 있고 기존의 작업기억에 의존하는 방식으로 그렇게 한다. 그것은 새로운 대상을 만들 수도 있고 그 대상들을 작업-기억 요소들을 가지고 기술할 수도 있는데 또 다시, 기존의 작업기억에 의존하는 방식으로 그렇게 한다. 계산적 능력의 이러한 집합은 기호 시스템의 기능들 (그림 2-11) 을 수행하기에 충분하다. 예외는 장기기억을 변화시키는 방법이 없다는 것이다. 청킹 (2 절에서 기술될) 이 그 능력을 제공하는 기제이다.
Ops5 나 많은 다른 산출 시스템과 비교해 볼 때 소어 산출들은 두 가지 특수한 성질을 갖고 있다. 첫째 소어 산출이 취할 수 있는 유일한 행위는 작업기억에 요소들을 추가하는 것이다. 그것은 요소들을 삭제하거나 수정할 수 없고 또한 다른 행위들도 할 수 없다. 그러므로 소어 산출 시스템은 하나의 기억과 같이 행동하는데 여기에서는 정보가 접근되고 (조건들을 통해), 인출되며 (행위들을 통해), 작업기억에서 새 정보가 오래 된 정보를 파괴하거나 대체하지 않으며, 일정하게 작업기억에 추가된다. 물론 궁극적으로는 요소들이 작업기억에서 사라져야만 한다. 이것은 그것들이 문제해결의 역학 (결정 자치가 소개된 후, 밑에서 기술될) 때문에 접근이 어려워질 때, 자연스럽게 발생한다.
소어 산출의 두 번째 특수한 성질은 갈등 해소 conflict resolution 가 없다는 것이다. 일반적으로 작업기억에 요소들의 집합이 주어졌을 때, 단지 하나의 산출만이 단지 하나의 실례화와 대응될 것이라는 보장이 있을 수 없다. 다중의 실례화들을 갖는 다중의 산출들이 발생하는 것은 가능하다 (그리고 일반적으로 이러한 것이 발생한다). Ops5 는 이것을 갈등집합이라고 부른다. Ops5 와 대부분의 다른 산출 시스템들은 이런 갈등을 해결하기 위해, 그리고 단일한 산출 실례화가 실행될 것을 명세화하기 위해서, 고정된 규칙의 집합을 적용한다. 소어는 갈등해소를 하지 않고 만족된 모든 실례화들을 실행한다. 그렇기 때문에 산출시스템은 완전히 병렬적이고 통제되지 않는 시스템이다. 이러한 점과 산출 시스템이 단지 작업-기억 요소들을 추가한다는 점에서, 소어 산출 시스템은 내용-주소화 기억같이 작동한다.
그림 4 가 보여주는 것처럼 소어는 속성과 값의 집합을 갖고 있는 대상들의 매우 기본적인 표상을 갖고 있다. 속성과 값 모두 다른 대상들일 수 있으며, 그러므로 임의적인 속성-값 구조들이 발생할 수 있다. 표상의 최소 크기는 대상의 속성의 값이다. 이것은 하나의 산출에 의해서 독립적으로 읽혀지고 쓰일 수 있는 단위이다. 조건, 행위, 그리고 작업-기억요소는 대상-속성-값의 3 개가 한 조로 되어 있다. 결과적으로 하나의 대상은 그러한 요소들의 집합이다. 이것이 2 장에서 요구되었던 것처럼 조합적 다양성을 가능하게 해주는 매체이며 연산하기 쉬운 매체이다. 그것은 모든 표상을 위해 사용된다.
대상들은 그것들의 속성과 값의 집합에 의해 정의되므로, 동일한 속성과 값을 갖는 두 개의 대상은 동일한 것으로 취급된다. 확인자들 (g3, p14, 그리고 이와 같은 것) 은 산출이 동일한 대상을 언급할 때 확인하기 위한 단순히 잠정적인 명칭들이다. 그러므로 그림 4 에서 이해 comprehend 라는 새로운 연산자를 확인하기 위해 o82 가 만들어졌을 때 발생했던 것처럼, 확인자들은 산출들의 행위들에 의해 임의적인 기호들로 만들어진다.
그 표상은 객체-지향적 object-oriented 표상들과 틀 (또는 도식) 표상들과 유사한 점이 있지만 (Minsky, 1975), 그것은 가장 단순한 종류이다. 거기에는 기정치나, 첨부된 철자나, 그리고 자동적인 전승 inheritance 구조가 없다. 그것은 만약 표상이 틀과 같은 방향으로 확장된다면 존재해야 할 장치를 하나도 갖고 있지 않다.
그림 2 에서 보는 바와 같이 소어의 구성은 문제공간을 기초로 만들어진다. 그러므로 이루어져야만 하는 결정들은 어떤 문제공간이 사용되어야 하는가 (목표를 달성하기 위해), 어떤 상태가 사용되어야 하는가 (문제공간 안에서), 그리고 마지막으로 어떤 연산자가 사용되어야 하는가 (다음 상태로 진행하려면) 이다. 이것들이 구성의 기본적 연산들이다. 그것들은 모두 결정주기 decision cycle 라 불리는 획일적인 결정과정에 의해 이루어진다. 이것은 그림 5 에 제시되어 있다 (그것은 3 개의 연속적인 주기를 보여준다). 각 결정주기는 정교화 단계 elaboration phase 와 이에 뒤이은 결정절차 decision procedure 를 갖고 있다. 정교화 단계는 현재상황에 대해 가용적인 지식을 획득한다. 조건들이 만족된 모든 산출들은 작업기억요소들 (수직화살표들) 을 자유롭게 추가한다. 갈등해소가 없기 때문에 어떤 것이라도 자유롭게 추가된다. 이것은 모든 것들을 끌어들이기 위한 하나의 수집연산이다. 일찍 도착한 요소들은 추가적 요소들에 접근하기 위해서 사용될 수도 있다. 요소들은 어떠한 종류라도 가능하다 —— 블록, 탁자, 또는 그것들의 관계에 관한 것, 어떤 연산자가 어떤 블록이 과거에 이동하였는지에 관한 것, 그리고 기대되는 또는 희망되어지는 미래의 블록들의 배열에 관한 것. 좀더 추상적으로 진술하면, 지능적 시스템은 과거, 현재, 그리고 미래에 걸친 상황들과 행위들에 대한 지식을 표현할 수 있어야만 한다.
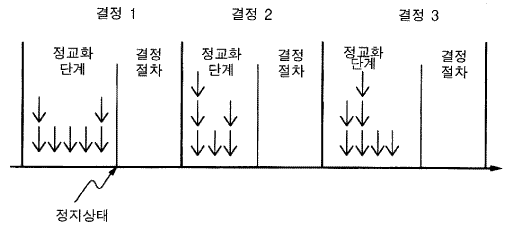
그림 5 소어 결정주기
또한 지능적 시스템은 어떠한 행위들이 취해져야만 하는지에 대한 지식을 표현할 수 있어야 한다. 그것은 행위를 취하지 않으면서 행위를 표상할 수 있어야 하며, 또한 취해져야만 하는 행위를 표상할 수 있어야 한다. 후자의 것은 약간 덜 분명하지만 만약 그것이 가능하지 않다면, 무엇이 발생해야 하는가에 대한 숙고가 어떻게 일어날 수 있겠는가? 더 나아가 최종적으로 행위 (연산자조차도, 그것은 내적인 행위이다) 를 실제적으로 취하는 것은 구성이기 때문에, 어떠한 행위가 취해지는가에 대해 구성적으로 정의되고 이해되는 의사소통이 존재해야 한다. 선호는 그러한 의사소통을 위한 소어의 수단이다. 또한 선호들은 정교화 단계 동안에 누적될 것이다.
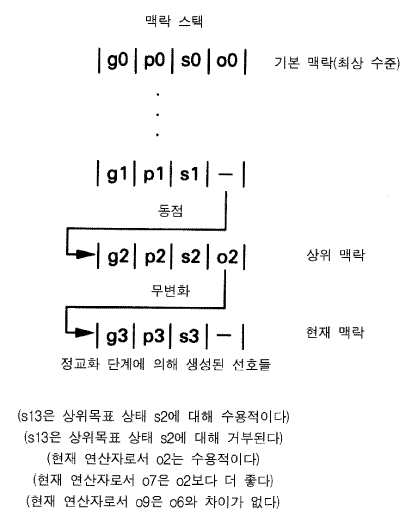
그림 6 소어 수행 요소들과 맥락 스택
그림 4 의 산출은 점화되었을 때 작업기억에 투입되는 선호들을 그것의 오른쪽에 가지고 있다. 그림 6 은 주어진 정교화 단계가 끝났을 때 작업기억에 존재할 수 있는 가능한 선호들의 집합을 보여준다. 그림 상단에 보이는 것처럼 하나의 결정주기가 목표, 공간, 상태, 그리고 연산자들에 관한 초기결정들의 맥락들의 스택 (맥락스택 context stack 이라고 불리는) 에서 발생한다 (스택 안에서의 맥락들 간의 화살표들은 잠시 후 명확해 질 것이다). 현재 맥락은 목표 g3, 공간 p3, 상태 s3, 그리고 연산자는 없다 (즉 아직 연산자가 결정되지 않았다). 상위맥락 super context 은 g2, p2, s2, 그리고 o2 로 구성되며, 최상수준 (이것은 기본-수준 맥락 base-level context 이라고 불린다) 까지 이렇게 이루어진다. 첫 번째 선호는 상태 s13 이 상위목표맥락에 대해 수용가능하다고, 다시 말하자면 상태 s13 이 상태 s2 를 대체해야 한다고 주장한다. 두 번째 선호는 상위 목표에 대해서 동일한 상태를 거부한다. 그러므로 한 선호가 제안하는 것을 다른 선호는 부정한다. 세 번째 신호는 연산자 o2 가 현재의 연산자로 수용가능하다고 주장한다. 그 다음의 선호는 o7 이 현재의 연산자로 수용가능하다고 말한다. 그러므로 두 연산자들 모두 후보자들이다. 그 다음 선호는 이 특정한 결정에서 o7 이 o2 보다 더 좋다고 말한다. 마지막으로 또 하나의 선호는 연산자 o9 가 연산자 o6 과 차이가 없다고 주장한다. o6 과 o9 에 대한 다른 참조는 없지만, 만약 어떤 산출이 그 선호를 주장하게 되면, 그것에 대한 제약은 존재하지 않는다. 맥락스택에서 어떠한 슬롯 slot 에 대해 어떤 대상에 관해 어떠한 선호들의 집합이라도 가능하다.
이 특정한 정교화 단계가 정지상태 quiescence 로 되었을 때, 이 선호들의 집합을 작업기억에 있는 것으로 보자. 추가적인 요소들이 작업 기억으로 들어오는 동안에는 정교화 단계가 계속 진행된다. 가용적인 모든 정보가 수집된다. 정교화 단계가 정지상태로 되었을 대, 결정 절차는 일어난다. 그것의 기능은 누적된 선호들의 집합에서 가용적인 정보로부터 결정을 하는 것이다. 그와 동시에 작업기억에는 바로 지금 들어왔거나 또는 앞선 주기에서 들어온 많은 비선호적 요소들이 존재할 것이다. 사실상 선호들을 작업기억에 투입시키는 산출들을 만족시키는 것은 바로 이러한 다른 작업-기억 요소들 (현 상태, 가능한 연산자들 등을 표상하는) 이다. 그러나 단지 선호들만이 결정절차에 의해 사용되며, 결정절차는 현 정교화 단계에서 입력된 것이든 또는 앞선 주기에서 입력된 것이든 상관없이, 그것들 모두 사용한다.
결정 절차는 단순히 선호 주장의 의미를 실행한다. 하나의 선호는 항상 현존하는 결정 맥락에서 주어진 슬롯에 어떤 대상을 채택하는 하나의 결정을 지시한다. 그것은 단지 결정개념들의 작은 집합만을 사용한다 —— 수용가능 acceptable, 거부 reject, 더 좋다 better (더 나쁘다 worst), 가장 좋다 best (가장 나쁘다 worst), 그리고 차이 없다 indifferent. (구성에 의해 이해되는 초보적 결정 개념들의 집합을 결정하는 이론을 우리가 아직은 가지고 있지 않기 때문에 실험이 지속되고 있다. 예를 들어, 소어 4. 5 는 목표달성에 대해서 즉시적인 필요성을 지칭하는 요구 require 와 금지 prohibit 선호들을 포함한다.) 이것들은 명확한 의미를 갖고 있다. 선택되기 위해서, 하나의 결정이 수용가능 해야만 한다. 그것이 무엇이든지 거부된 결정은 선택될 수 없다. 만약 하나의 결정이 다른 결정보다 더 좋다면 (동일한 슬롯에 대해), 다른 조건이 같다고 할 때 그것이 선택될 것이다 —— 그리고 더 나쁜 결정들에 대해서도 유사하다. 가장 좋다 또는 가장 나쁘다는 단지 선호 순위에서 극단적인 점들이다 (가장 좋은 것보다 더 좋다는 것이 더 나은 것은 아니다). 차이가 없는 결정들 사이의 선택은 임의적으로 정해진다.
기정치로, 생성된 선호들은 고려되어져야만 할 전체 자료로 가정되어진다. 다른 선호들이 적용될 수도 있고 생성될 수도 있다. 그러나 정교화 단계가 정지상태로 되고 그래서 어떻게 실행할 것인지에 대한 결정이 없이 가용적인 모든 선호들이 획득된다. 그러므로 이 결정절차는 그것이 갖고 있는 것을 가지고 작동해야만 한다. 이것이 폐쇄된 세계의 가정 closed world assumption 이며, 쉽게 빠져나갈 수 없는 것이다.
만약 결정절차가 명확한 선택을 만들어낸다면 (그림 6 에서 연산자 o7 이 현재의 연산자로 선택되어져야 한다) 그 선택이 실행되며 (o7 이 현재 맥락의 연산자 슬롯에 채워진다), 소어는 새로운 결정주기를 시작한다. 맥락은 지금 변경되었고 (이제 o7 이 현재 맥락의 연산자 슬롯에 있다), 그러므로 다음의 정교화 단계는 새로운 지식에 접근할 수 있고 또 다른 결정을 위한 선호들을 제안한다. 이 경우 o7 을 실행하는 산출들, 즉 o7 이 현재의 연산자인가를 검사하는 조건을 갖고 있는 산출들이 가능해지고 점화된다. 그러므로 소어는 한 단계씩 이동하면서 적절한 지식들을 축적하고 다음 결정을 한다. 예를 들어, 새로운 하위목표 —— (g, -, -, -) 로 구성된 맥락 —— 를 갖고 시작해서, 소어는 첫 번째로 문제공간 (g, p, -, -) 을, 그 다음에는 초기상태 (g, p, s, -) 를, 그 다음에는 연산자 (g, p, s, o) 를 선택한다.
연산자를 채워 넣는 것은 그 연산자를 실행시키는 지식을 방출하고 작업기억에 새로운 상태 (s') 를 생성하는데, 이것은 다음의 결정주기에서 다음 상태 (g, p, s', -) 로 선택될 수 있다. 그런 후 다음의 연산자 (g, p, s', o') 가 선택되고 그 다음에는 다음의 상태 등등으로 희망하는 상태를 달성하기 위한 문제공간을 이동한다.
결정 주기는 항상 동일하다. 어떠한 결정 —— 현재 맥락, 상위맥락, 상위상위 맥락 등의 모든 목표 맥락에서 어떠한 슬롯에 대한 어떠한 문제공간, 상태, 또는 연산자를 선택하는 —— 이라도 제안될 수 있다. 출현한 실제의 선호들을 제외하고는 어떤 것도 어떠한 특정한 선택의 연쇄에 대한 행동, 즉 방금 기술한 상태-연산-상태의 경로를 따라 이동하는 행동을 제약하지 않는다. 예를 들어 6 에서 만약 상태 s13 을 거부하는 선호가 나타나지 않는다면, 결정절차는 연산자 o7 을 채워 넣는 대신에 상위목표에서 상태 s2 를 변경시킬 것을 선택할 것이다. 그래서 어떤 경우라도, 다양한 선택이 이루어질 수 있다.
문제 해결을 안내하는 모든 지식은 산출들 안에 존재한다. 결정절차는 그것 자체에 관한 지식을 추가하지 않는다 —— 그것은 단지 개념들의 고정된 의미만을 실행한다 (수용하고, 거부하고, 더 좋고, 가장 좋고, 더 나쁘고, 가장 나쁘고, 그리고 차이 없고). 물론 행동은 방향 지어질 필요가 있다. 목표들과 목표스택이 그것이 발생되도록 하는 맥락을 제공한다. 스택의 각 수준은 위 수준의 하위목표를 명세화하고, 그러므로 목표 스택은 목표-하위목표 위계를 생성한다. 이러한 점에서 소어는 가장 복잡한 AI 문제-해결 시스템들과 유사하다. 사실 AI 에서 학습된 주요한 것들 중 하나는 지능적 수행을 달성하기 위해 행동을 통제하기 위한 목표, 하위목표, 그리고 대안적 하위목표를 갖고 있는 목표위계의 효과성과 명백한 필요성이다.
지금까지 우리는 맥락 스택 (목표-하위목표위계) 을 주어진 것으로 취급해왔다. 소어구성은 진행해감에 따라 목표들을 역동적으로 만들어낸다. 이것은 현재의 기술수준과 중요한 대조를 보이는 소어의 중요한 특징이다. 본질적으로 모든 AI 시스템들에서 하위목표들은 역동적으로 만들어지지만, 단순히 미리 결정된 것이고 그것은 기억에 저장된 것으로서 그렇다. 산출들의 관점에서 생각해 보면, 그 상황은 그림 7 에 제시된 것과 유사하다. 산출은 읽는다 —— 만약 당신이 목표 g 를 달성하려고 시도하고 다른 조건들, c1, c2 등이 만족된다면, 달성해야 할 하위목표들로 g1, g2, 그리고 g3 을 만들어라.
|
창조-하위 목표들 : 만약 목표 g0 이 희망되고, 그리고 조건 c1 이 만족되고, 그리고 조건 C2 가 만족되면, 그러면 목표 g1, 그리고 목표 g2, 그리고 목표 g3 을 달성하라 |
그림 7 전형적인 AI 목표-설정 산출의 예 (소어에서 사용되지 않음)
그 하위목표들은 시스템이 사용가능 한 방법들에 의해 숙고적으로 만들어진다.
소어는 막다른 상태 impasses 에 부딪치면 하위목표들을 역동적으로 만든다. 위에서 기술한 결정주기에 대해 어딘가 이상한 점이 있다고 독자들은 느낄 수도 있다. 임의적인 선호들의 집합이 주어졌을 때, 결정절차가 다음에 취할 명확한 선택을 생성할 것이라고 무엇이 보장하는가? 그것을 방해하는 여러 종류의 것들이 발생할 수 있다. 다만 극단적으로 새로운 선호를 제안하는 산출이 하나도 없다고 가정해 보라! 그렇다면 어떤 일이 발생할까? 상당히 복잡한 것들이 여전히 고려되어야만 하기 때문에 결정주기의 극단적인 단순성은 환상인 것처럼 보인다.
사실상, 하나의 명확한 선택이 항상 존재할 필요는 없다. 정당치 못한 모든 것들이 발생할 수도 있다. 그것들은 결정절차가 하나의 유일한 결정을 선택하는 것을 막고, 그러므로 그것들은 소어가 앞으로 이동하는 것을 막는다. 그것들은 막다른 상태를 해소하기 위해서 하위 목표를 만든다. 그래서 소어가 진행할 수 없기 때문에, 하위목표들이 역동적으로 생긴다. 이것이 바로 하위목표들이 생길 수 있는 유일한 방법이다.
막다른 상태가 발생할 가능성들은 결정절차가 실패할 수 있는 다른 방법들로부터 제기된다. 결정절차는 선택될 수 없는 모든 결정들을 제거하는 것처럼 생각되어질 수 있다. 첫째 그것은 단지 수용가능 한 결정들에만 주의를 기울인다. 그 다음 그것은 거부되는 모든 결정들을 제거한다. 그것은 남아 있는 것들 중에서 수용가능하고 거부되지 않은 다른 결정들보다 더 나쁜 것들은 모두 제거한다. 결국 그것은 가장 상위의 하위목표와 관계된 결정들만을 고려한다. 어떤 수준에서 하나의 목표안에서 어떤 변화 —— 문제공간, 상태, 또는 연산자에서의 변화 —— 라도 하위목표들에 대한 모든 변화들에 완전히 우선하는데, 이는 후자의 것들 모두가 더 높은 수준에서의 막다른 상태에 대한 반응으로 만들어지기 때문이다.
최종적으로 남겨진 결정들의 집합이 주어졌을 때, 막다른 상태가 발생하는 방법은 단지 4 가지가 존재한다. 첫째 동점에 의한 막다른 상태 tie impasse 가 있을 수 있다. 선택되지 않은 모든 것들이 제거되었을 때, 구별할 수 없는 대안들의 집합이 남아 있을 수 있다. 그것들은 모두 수용가능하며 아무것도 거부되지 않고 더 선호되는 것도 없고, 그리고 그것들은 차이가 없는 것도 아니다. (차이가 없다는 것은 차이가 없는 요소들의 그 어떠한 것이라도 선택된다는 명확한 선호이다.)
둘째 무변화에 의한 막다른 상태 no-change impasse 가 있을 수 있다. 모든 것들이 말해지고 행해진 후에, 가용적인 선택들이 없다. 그것들이 모두 거부되었거나 어떤 것도 수용 가능하다고 선언된 것이 없다. 이것은 보기 드문 상황처럼 보이지만 항상 발생한다. 예를 들면, 하나의 연산자가 선택되었지만, 새로운 상태를 결과로서 생성하는 데 충분할 정도로 즉각적으로 알려진 것 immediately known 이 없다 (즉각적으로 알려진 것이란 요구되는 산출들이 정교화 단계에서 점화되지 않음을 의미한다). 그러므로 많은 것들이 발생할지라도 (새로운 대상이 만들어지고 그리고 이전 대상이 새로운 속성-값을 갖도록 확대하고), 연산자의 결과로서 다음 상태를 선택하기 위한 선호를 만들어내는 산출이 없다. 더 나아가, 다른 연산자들 또는 더 상위의 맥락에서의 새로운 선택을 제안함으로써 그 상황이 버려져야 한다고 제안하는 산출들도 없다. 그 결과는 무변화에 의한 막다른 상태이다.
셋째 거부에 의한 막다른 상태 reject impasse 가 있을 수 있다. 이미 만들어진 결정의 하나를 거부하는 것이 유일한 선호일 수 있다. 예를 들어, 그림 6 에서 상위목표 상태에서 s2 를 거부하는 선호가 역시 있을 수 있다. 물론, 거부는 추가적 지식을 얻기 위해서 무엇을 할 것인지에 대해서는 아무 말도 하지 않기 때문에 막다른 상태가 발생한다.
마지막으로 갈등에 의한 막다른 상태 conflict impasse 가 있을 수 있다. 한 산출은 연산자 o1 이 연산자 o2 보다 좋다는 선호를 제공할 수 있고, 또 다른 산출은 연산자 o2 가 연산자 o1 보다 좋다는 선호를 제공할 수 있다. 그리고 애매한 것이 모두 사라졌을 때에도 여전히 남아 있는 것이 바로 그것이다. 어떤 선호들이 생성되는지에 대한 제약이 존재하지 않기 때문에, 그러한 우발적인 사건은 충분히 발생 가능하다 (우리들의 경험으로는 그것은 단지 보기 드문 현상이었지만). 선호들의 의미가 주어졌을 때, 진행할 방법이 없고, 그러므로 막다른 상태가 발생한다.
단지 위와 같은 4 개의 다른 일반적 상황들만이 막다른 상태를 만든다. 임의적인 선호들의 집합에서 출발한 모든 가능한 상황들의 분석은 이러한 것들이 막다른 상태에 이르게 하는 발생 가능한 유일한 상황들임을 보여준다. 나머지 상황들에서는, 단일한 선택이 만들어진다. 물론, 막다른 상태 그 자체는 이러한 4 가지 유형의 하나로서 완벽하게 특징된다고 볼 수는 없다. 막다른 상태는 전체의 재인 기억과 결합해서 작업기억의 모든 상태에 의해 만들어진다. 시스템의 전체 상태 이외에 그 상황을 기술하는 것은 존재하지 않는다. 그러므로 막다른 상태는 시스템이 사용할 수 있는 지식의 다양한 모든 결함들을 나타낸다.
막다른 상태는 소어가 좌절되어 중지됨을 의미하지는 않는다. 소어는 그것을 해결하기 위해 하위목표를 만들어냄으로써 막다른 상태에 반응한다. 막다른 상태를 해결하는 것은 소어가 그 결정 시점에서 그 막다른 상태를 만들지 않도록 하는 지식이다. 그러한 지식이 발생할 수 있는 방법들이 있다. 그것들이 무엇이며, 또는 무엇일 수 있는가 하는 문제는 현재 작업기억뿐만 아니라 장기기억에 있는 모든 지식에도 의존한다. 그러나 그것은 막다른 상태를 만들었던 결정상황이 이제 명확한 선택을 만들어내도록 하는 어떤 선호들을 포함해야만 한다. 이것은 무엇이 막다른 상태를 해결할 수 있는지에 대한 가능성들의 집합의 어떤 형식화도 요구하지 않는다. 결정절차 자체가 그것을 결정한다. 또한 그것은 결정상황의 어떠한 특수한 재고려도 요구하지 않는다. 모든 결정주기에서, 어떠한 대안적 선택들이 제안된 맥락에서라도 모든 선택들이 만들어질 수 있으며, 고려될 수 있다. 막다른 상태 전의 어떤 위치에서 선택을 만드는 선호들은 언제든지 만들어질 수 있다. 그러면 그 선택은 단순히 취해질 것이고 처리는 그곳에서부터 이동하기 시작한다. 대안적으로, 맥락스택의 더 높은 곳에서 선택을 만들어, 사실상 낮은 곳에서의 모든 처리들을 폐기시키는 선호들이 만들어질 수도 있다. 그리고 더 높은 곳에서의 막다른 상태에 의해 생성된 하위목표들, 그리고 하위목표들의 모든 처리는 실제적인 가치가 없어지고 단지 중도에서 멈추어질 수 있다.
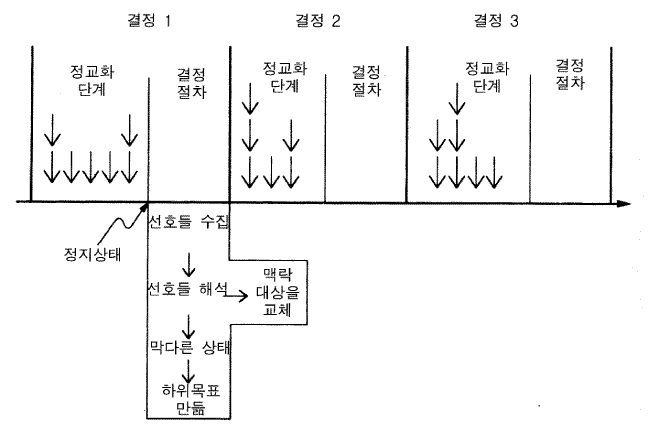
그림 8 소어 결정주기 완성
이제 우리는 결정주기의 그림을 완성할 수가 있다. 막다른 상태의 기제를 추가한 것을 제외하고 그림 5 와 동일한 모습의 그림 8 은 목표 스택이 어디로부터 왔는지를 보여준다. 각각의 막다른 상태에서 하나의 새로운 하위목표 맥락이 만들어지는데, 이것은 목표를 갖고는 있지만 문제공간, 상태, 또는 연산자를 갖고 있지 않다. 결정이 하위목표 스택에서 상위의 어떤 것을 변경시켜서 그것 밑에서 진행 중인 하위목표 처리가 관련성이 없게 되었을 때, 그 하위목표 맥락들은 맥락스택에서 제거된다.
목표맥락들의 제거는, 제거된 맥락들과 전적으로 연합된 작업-기억의 요소들의 소멸을 일으킨다. 단지 목표맥락의 요소들과 연결된 작업기억 요소들만이 접근될 수 있다. 접근될 수 있는 요소는 맥락의 일부 (확립된 목표, 문제공간 상태, 또는 연산자) 여야만 하며, 또는 접근 가능한 대상의 속성의 값으로서 발생해야만 한다 (하나의 요소는 여러 다른 방식으로 목표 맥락과 연결될 수 있다). 맥락 스택에서의 산출들은 대상에서 시작하는 작업-기억요소들의 연쇄를 따라 대응시킴으로써 이러한 연결성 connectivity 제약을 따른다. 그림 4 의 산출은 이러한 제약을 만족시킨다. 그것의 첫 번째 조건은 목표요소를 대응시킨다 —— 문제공간과 상태에 대한 그 다음의 두 요소들은 첫 번째 조건에 연결된다 (확인자 <P> 와 <s> 는 두 조건에 모두 나타난다) (블록과 입력에 대한 마지막 두 요소들은 상태에 연결된다) (확인자 <b> 와 <i> 는 두 조건에서 모두 나타난다). 그러므로 목표맥락에서 대상을 제거하는 것은 다른 대상들을 잘라내어 접근할 수 없게 만들기 때문에, 그것들은 작업-기억에서 사라진다. 이것은 산출 시스템이 하는 모든 일은 작업기억에 지식을 추가하는 것뿐이라는 사실의 또 다른 측면이다 —— 제거는 자동적으로 일어난다. (주석 : 소어 소프트웨어 시스템에서, 이러한 접근 불가능한 요소들은 수집된 불필요한 정보 garbage 이다.)
목표맥락 스택이 전적으로 내적으로 생성되며, 막다른 상태가 하위목표의 유일한 출처라는 것은 소어의 핵심적인 특질이다. 이러한 방식은 AI 시스템에서 친숙한 모든 종류의 하위목표들을 생성할 수 있다. 동점에 의한 막다른 상태는 연산자들 사이 또는 상태들 사이의 선택을 하는 하위목표들을 생성한다. 그것들은 또한 문제공간들 간의 선택, 즉 과제를 형식화하는 또는 표상하는 방법을 선택하는 하위목표들을 생성한다. 이 후자의 것은 AI 시스템에서는 거의 나타나지 않고 사실상 지금까지 그것들은 단지 소어에서 매우 제한적인 방식으로만 발생한다. 연산자들에 관한 무변화에 의한 막다른 상태는 연산자를 구현하는 하위목표들을 생성할 수 있다. 그것들은 또한 사전조건 하위목표들 precondition subgoals 또는 연산자 하위목표 설정 operator subgoaling 이라 불리는 것, 즉 연산자가 적용되는 상태를 찾는 목표를 만들 수 있다. 그것들은 또한 연산자를 명세화하거나 구체화하는 하위목표들을 만들 수도 있다. 잠깐만 숙고해 보면, 이와 같은 3 가지의 일반적인 상황들 —— 연산자의 적용의 결과를 즉시적으로 알지 못하는 상황, 연산자가 적용될 상태가 없는 상황, 그리고 현 상황에 대해 일반화된 구체적 연산자가 없는 상황 —— 이 모두 연산자의 무변화에 의한 막다른 상태로 귀결된다. 다른 한편, 상태에 대한 무변화에 의한 막다른 상태는, 아무런 연산자도 제안되지 않았기 때문에, 연산자를 찾거나 구상하는 하위목표들을 생성한다. 그래서 그것은 진행된다. 상황이 앞으로 이동하는 것을 막는 어떠한 지식의 부족도 막다른 상태로 귀결되며, 그러므로 그 막다른 상태를 해결하기 위한 하위목표로 귀결된다.
내적인 하위목표들은 소어가 일단 어떤 것을 추구하기 시작했을 때 그것이 할 것을 결정한다. 그러므로 그것은 목표를 갖고 있으며 그 목표를 달성하는 데 어떠한 지식의 부족도 (막다른 상태를 통하여) 그 지식을 획득하기 위한 시도들로 귀결된다. 그러나 이 결정주기는 처음부터 왜 소어가 블록 쌓기를 원했고 체스하기를 원했는지 등에 대한 설명을 하지 않는다. 더 나아가, 그것은 소어가 어떻게 그러한 희망사항을 자신에게 표상시켰는지에 대해서도 설명하지 않는다. 소어에서 숙고적 목표들은 연산자들의 형태를 취하는데, 그것은 연산자가 생성되었을 때 가용적인, 부분적으로는 절차적인 명세화와 최종-상태의 명세화의 어떠한 조합에 의해서 정의된다. 그러므로 처음에는 특정한 배열로 블록을 쌓는다는 목표는, 블록들을 쌓는 하나의 연산자이다. 이렇게 불완전하게 결정된 연산자는 무변화에 의한 막다른 상태를 생성하며, 이것은 문제해결이 이루어지는 문제공간의 선택으로 귀결되는 하위목표를 만든다. 사실상, 블록을 쌓는 것이 무엇인지 아니면 소어가 단순히 할 수 있는 어떤 일인지 (즉시적으로 수행 가능한 연산자) 의 여부는 만들어져가는 과제에 본질적인 면은 아니지만, 그것은 블록을 쌓으려는 시도를 할 바로 그 당시에 알려진 것들의 관점에서 결정된다. (주석 : AI 시스템들은 전형적으로 연산자들과 목표들 간의 기본적인 구조적 구분을 만들어왔고, 이것은 오랫동안 명료화가 필요했던 것이었다. 실제적으로, 어떤 측면들이 주어진 것으로, 그리고 어떤 것들이 찾아질 것으로 취급하느냐는 단순히 설계자의 결정이었다. 그러나 이것은 분명히 불만족스러운 것이다. 연산자들과 숙고적 목표들은 동일한 것이다 ; 연산적으로, 지식이 요구될 당시, 지식의 부족으로부터 목표는 제기된다.)
소어에 대한 추가적인 통찰은 소어와 표준적 컴퓨터를 대조시킴으로써 얻어질 수 있다. 막다른 상태는 표준적 컴퓨터에서도 역시 발생한다. 예를 들어, 0 으로 나누는 것은 막다른 상태를 생성한다. 그러나 0 으로 나누기가 발생하면 무엇이 잘못되었는지 누가 알겠는가? 오류 메시지를 생성하고 처리를 중단하는 것 이외의 구성이 이 막다른 상태에 반응할 수 있는 방법은 없다. 이것은 컴퓨터 구성이 계산되는 것과는 관련이 없기 때문이다. 그것의 연산-피연산자 구조는 기억에서의 프로그램에 따라서 그것과 단지 하나의 과제만을 관련시킨다. 반면 소어 구성은 문제-해결 요건들의 관점에서 구조화된다. 그것의 초보적인 행위들 —— 나누기와 0 에서의 분기 branch-on-zero 와 일치하는 것 —— 은 소어의 전반적인 행동 —— 문제공간을 선택하기, 상태를 선택하기, 연산자를 선택하기, 그리고 연산자들을 적용하기 —— 의 관점에서 기능적으로 중요한 행위들이다. 막다른 상태가 발생했을 때, 구성이 기능적으로 취할 수 있는 적절한 행위가 있다. 막다른 상태의 유형을 기록하고 관련된 대상들을 찾아내는 하위목표를 만드는 일은 오류 메시지와 유사하다. 그러나 그것이 취하는 형태는 그것을 갖고 행해져야 할 필요가 있는 것 —— 그것을 해결하려는 시도 —— 을 구성이 알고 있다는 것과 그것을 실행하는 방법 —— 그런 시도를 안내할 수 있는 지식을 시스템에서 발생시킬 수 있는 하위목표를 만드는 일 —— 을 구성이 알고 있다는 점을 보여준다. 표준적 컴퓨터 구성은 막다른 상태를 해결하는 과제를 형성하기 위해서 사용될 수 있는 목표구조를 갖고 있지 않다 —— 그것을 갖고 있다 하더라도, 행해져야 할 과제를 형식화할 방법이 없는데, 이는 그 형식화가 해석되는 프로그램의 의미 안에 묻혀 버리기 때문이다. 하위목표를 정의하는 소어의 능력은 연산과 피연산자가 아니라 문제공간의 관점에서 구성을 만들어 봄으로써 얻게 되는 하나의 이득이다.
AI 에서 전형적인 문제-해결 시스템들은 문제를 해결하기 위해 문제공간들에서 탐색을 사용한다 (전체 시스템 조직화에 따라, 다소 다른 모습과 용어로 자주 나타난다). 전형적인 배열은 문제공간에서 연산자들은 Lisp 와 같은 표준적 · 절차적 또는 기능적 언어로써 명세화된다. 마찬가지로, 연산자를 선택하는 탐색통제는 평가함수의 가중치와 같은, 본질적으로 매개변수적인 입력에 의해 표준적 프로그램에서 실현된다. 그러한 시스템들은 두 개의 계층이 있다 —— 문제해결층과 프로그램층. 소어가 이러한 조직화와 어떻게 다른지 아는 일은 중요하다. 그림 9 는 소어가 항상 문제공간에서 작동됨을 강조하기 위한 것이다. 소어가 상단의 문제공간 (p1) 에서 과제에 대한 작업을 시작한다고 가정하자. 변별될 수 없는 여러 연산자들이 제안될 수도 있다 —— 동점에 의한 막다른 상태. 이것은 소어로 하여금 선택을 하기 위해 문제공간 (p2) 을 만들도록 한다. 이 공간에서의 연산자들은 대안적인 연산자들을 평가한다. 하나가 선택되었지만, 즉시적인 지식에 의해 그것을 구현하는 것이 가능하지 않을 수도 있다 —— 무변화에 의한 막다른 상태. 이것은 평가 연산자들을 실행하는 것과 관련이 있는 문제공간 (p3) 으로 귀결된다. 그러므로 소어는 계속해서 막다른 상태에 부딪히고 그것들을 해결하기 위해 하위문제 공간들로 내려간다. 궁극적으로 공간에서 즉시적으로 가용적인 지식이 소어가 행동할 수 있을 정도로 충분해졌을 때 —— 결과가 실제적으로 생성되었을 때 —— 그것은 바닥에 이른다. 물론, 그것은 완전히 지식이 부족할 수도 있다. 그것은 최상 공간에서 연산자들을 시도하게 된다 (이것은 만약 과제-특수적 지식이 가용적이지 않을 때, 무엇을 해야 하는지에 관한 탐색-통제 지식을 그것이 가지고 있음을 의미한다).
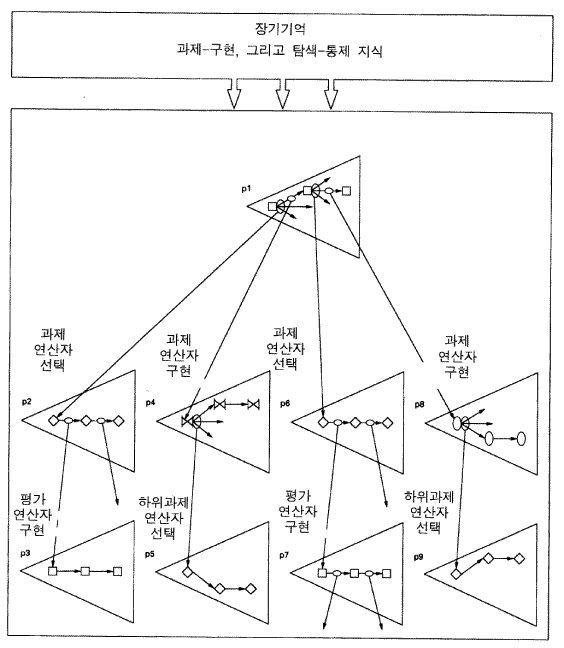
그림 9 모든 곳에서의 문제 공간들
무변화에 의한 막다른 상태에서의 연산자들은 절차호출들과 유사한데, 연산자를 선택하는 것은 절차를 호출하는 것과 유사하고, 문제공간에서 탐색하는 것은 부호본문 code body 을 실행하는 것과 유사하고, 맥락 스택은 절차 스택과 유사하다. 이러한 유추는 소어에는 없는 두 가지 연산들을 즉시 강조한다 —— 작동하는 절차본문의 맥락에 입력 매개변수들을 전달하는 것 —— 그리고 초기 (호출하는) 맥락에게 계산의 결과들을 전달하는 것. 표준적 프로그래밍 언어들에서, 이런 의사소통은 해당되는 규칙 (값에 의한 호출 또는 이름에 의한 호출과 같이) 을 갖고 있는 매우 형식화된 연산들이다. 이와는 대조적으로, 소어에서는 이런 종류의 의사소통 연산들이 없다. 맥락의 어떠한 수준에서도 결정들이 만들어질 수 있다는 사실에 의해 증명되듯이 하나의 큰 개방된 맥락에서 모든 처리가 이루어진다. 추가적인 지식이 연산자를 실례화하기 위하여 상태에 자주 추가되어야만 하고 이것은 기능적으로 매개변수들을 명세화하는 것과 동등한 것이다. 이와 같이 지식은 요구될 때, 상위 수준에서 간단하게 인출된다. 마찬가지로 표준적인 형태로 결과들을 묶는 일도 없다. 목표맥락 스택에서 상위수준과 연결된 모든 것들은 그 수준에서의 결과인데, 이는 그것이 그 수준에서 접근될 수 있고, 막다른 상태가 해결되었을 때 더 낮은 수준과 함께 사라지지 않을 것이기 때문이다.
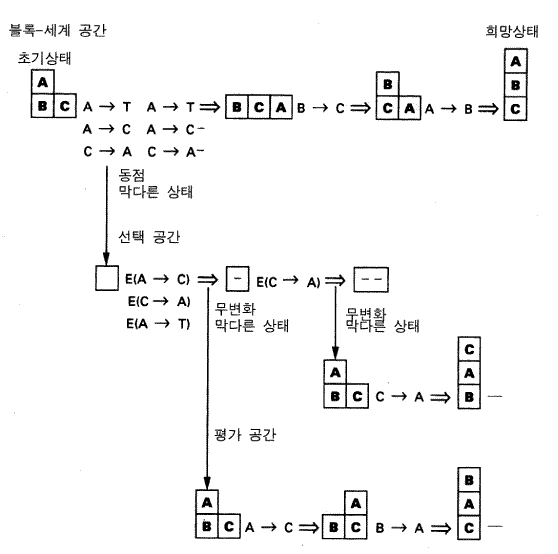
그림 10 단순한 블록-세계 과제에서의 소어의 행동
이 모든 것들을 구체적으로 제시하기 위해서, 그림 10 은 소어가 그림 4-2 의 단순한 블록 쌓기 과제를 수행할 때의 기록을 보여주고 있다. 초기 상황에서는 블록 B 와 C 가 탁자 위에 있고 블록 A 는 블록 B 위에 있다. 과제는 C 위에 B 가 있고 B 위에 A 가 있는 목표상태를 얻어내는 것이다 —— 특수한 순서대로 모든 블록들을 쌓는 것이 목표이다. 초기에 몇몇 지식들이 소어에게 제공된다. 소어는 블록 세계의 문제 공간에 대해, 즉 그것의 연산자들이 무엇이며 그것들을 어떻게 수행하는지를 알아야만 한다. 그것은 또한 여러 가지의 막다른 상태에 대해 반응하는 방법 예를 들어, 동점에 의한 막다른 상태에서, 그 해결을 시도하기 위해 선택 문제공간 자체에 관한 지식도 갖고 있어야 한다. 그것은 몇몇의 단순한 발견법 heuristics 들을 알고 있다 —— 방금 행해진 것을 즉각적으로 취소시키는 연산자를 제안하지 않는 것 —— 이미 목표 위치에 있는 상태들의 부분을 이동시키는 것을 제안하지 않는 것. 후자의 것을 수단-목표 means-ends 행동의 단순한 형태이다. 이러한 지식체계는 모두 산출에 존재한다 —— 이것은 소어의 장기기억의 초기내용이다. (주석 : 블록 세계의 과제-특수적 지식을 제외하고, 이 지식은 항상 어떠한 과제에서라도 주어진 것으로 여겨진다 —— 그것은 소어의 기정치 지식의 부분이다.)
소어는 문제공간에서 수용 가능한 3 가지 연산들을 모두 제안한다 —— A 를 탁자 위로 이동 (A → T), A 를 C 위로 이동 (A → C), 그리고 C 를 A 위로 이동 (C → A) —— 소어는 이 3 가지 이동들 중 어떤 움직임이 목표를 위해 가치가 있는 것인지에 대한 지식이 없기 때문에, 이것은 동점에 의한 막다른 상태로 귀결된다. 구성은 이 막다른 상태의 하위 목표를 만들고, 다음의 결정주기는 선택 문제 공간을 선택한다. 동점을 해결하는 것이다. 이 특정한 공간은 항목 (이동 연산자 move operator) 을 평가하는 연산자 E 를 갖고 있다. 3 개의 모든 이동 연산자들이 평가되기 때문에, 평가 연산자 evaluation operator 가 3 번 적용된다. 그러나 소어는 이동 연산자들 모두를 평가하기 때문에 어느 이동 연산자에 평가 연산자가 먼저 적용되는지에 대해서는 차이가 없다. 그러므로 소어는 세 개의 평가 연산자들 간에서는 동점에 의한 막다른 상태에 부딪치지 않고, 단순히 임의적으로 하나를 선택한다. A 를 C 위로 이동시키는 것을 평가하는 것이 우연히 발생한다. 소어는 선택 공간에서 가용적인 산출들을 사용해서 그 이동을 평가하는 방법을 모르기 때문에, 무변화에 의한 막다른 상태가 발생한다. 선택공간은 과제-특수적이지 않고 단지 평가 연산자를 모든 동점 항목들에 적용하고 그 결과를 고려하는 것에 대해서만 알고 있다.
무변화에 의한 막다른 상태는 소어로 하여금 A → C 에 적용되는 E 를 구현하는 평가 공간을 만들도록 한다. 대안적인 평가 공간들이 있을 수 있다. 이 특정한 것은 단지 연산자들의 평가를 위해서만 작동하는 룩어헤드 look-ahead 공간이다. 이것은 결과들을 평가하기 위해서, 원래 공간에서 연산자들을 시도해 무엇이 발생하는지를 살펴보는 개념을 포함한다. 그러므로 이동 연산자들은 원래의 블록 상황에 적용된다. 이것은 처음에 동점에 의한 막다른 상태에 이르기 때문에 회피했던 바로 그 일을 하는 것처럼 보인다 —— 즉 특정한 블록들을 이동시키기. 그러나 여기에는 결정적인 차이가 있다. 상위 공간에서의 이동은 특정한 목표 배열에 도달하기 위한 것이었다 —— 하위 공간에서의 이동은 그 이동의 바람직성 desirability 을 평가하기 위한 것이다. —— 이러한 공간들의 구조는 이 두 개의 구별되는 기능들을 깔끔하게 구별시켜 주며, 블록 세계 공간에서 함축적으로 탐색을 생성한다. A → C 이동을 한 후에는 단지 하나의 이동만이 가능하다. 다른 이동들은, 즉시 되돌아가지 않고 이미 적절한 결과의 부분들을 유지한다는 발견법들에 의해 제거된다. 그러므로 동점에 의한 막다른 상태는 제기되지 않고 소어는 목표상태가 아닌 상태에서 끝마친다. 목표 상태에 도달하지 않았다는 재인은 직접적으로 가용적이며, 그러므로 소어는 평가 연산자의 결과로서 정보를 선택 공간에 기록한다 (- 표시).
그런 다음 소어는 평가할 다음 연산자를 선택한다. 그것은 C 를 A 위로 이동시키는 것이고, 이것은 정확하게 나쁜 위치로 귀결된다. 이 시점에서, 원래 3 개의 이동들 중에서 좋지 못한 결과로 얻은 2 개의 이동이 좋은 것이 아님이 확실해졌다. 부정적 평가들 (-) 은 그것들이 제안되었던 원래의 맥락에서 그 연산자들을 거부하는 선호들 (선택 공간의 지식의 일부) 로 변화된다. 이것은 동점에 의한 막다른 상태를 곧바로 해결하는데, 이는 남아 있는 유일한 선택이 강요되기 때문이다. 그래서 이 이동 (A → T) 이 평가 공간이 아니라 상위 공간에서 실제 만들어진다 (그것은 모든 임의선택 option 들 —— 이 경우에는, 선택공간에서 이동을 평가하는 임의선택과 상위 공간에서 이동을 선택하는 임의선택 사이 —— 에서 선택하는 결정절차의 연산에 의해 발생한다). A 를 탁자 위로 이동시킨 후에, 가용적인 초보적 발견법적 탐색-통제 지식은 하나의 이동, 즉 B 를 C 위로 이동시킴으로써 목표상태에서 명세화된 것처럼, 목표한 것들 중 하나를 달성할 수 있음을 안다. 이 시점에서, 즉시 취해졌던 이동을 되돌리는 것을 제외하고는 단지 하나의 이동이 적용 가능하기 때문에 소어는 마지막 상태에 도달하고, 이것이 바로 목표상태이다.
이 예는 단순한 과제를 수행할 때 소어의 전형적인 행동을 약간 제공한다. 소어는 과제를 수행하기 위해 단순히 연산자들을 적용해나가며, 진행하는 방법에 대한 지식의 부족은 소어로 하여금 다양한 하위 목표들을 해결하게 하며, 이것은 룩어헤드 탐색과 같은 행동 패턴으로 귀결된다. 이러한 행동은 물론 구성에 의해 결정되지는 않는다. 많은 지식이 사용된다.
지금 우리가 소어가 어떻게 수행하는지를 보아왔다 —— 문제 공간을 사용하고, 과제를 달성하기 위해 문제 공간에서 이동하며, 제기되는 막다른 상태를 해결하기 위해 필요한 우회도 한다. 이제 우리는 그림 4-1 의 목록 중 구성의 마지막 구성요소, 즉 청킹 chunking 을 살펴볼 때이다. 청킹은 경험에 의해 학습하는 것이다. 그것은 목표-기반적 문제 해결을 접근 가능한 장기기억 (산출들) 으로 변환시키는 하나의 방법이다. 문제 해결이 어떤 결과를 제공할 때는 언제나 새로운 산출이 만들어지고 그것의 행위들은 바로 얻어진 결과들이며, 그것의 조건들은 문제 해결이 시작되기 전에 존재했던 것들, 즉 결과들을 생성하는데 사용되었던 작업기억 요소들이다. 이렇게 새롭게 만들어진 산출은 장기 기억에 추가될 것이고, 그 후부터는 그것의 조건이 만족되는 미래의 모든 정교화 단계에서 그것의 지식을 단기기억에 추가하는데 사용될 수 있을 것이다. 참고적으로, 그림 4-11 은 청킹의 핵심적인 특성들을 목록으로 제시하고 있으며, 그것들은 우리가 논의해감에 따라 나타나게 될 것이다.
|
1. 청킹은 목표-기반적 문제 해결을 산출들로 전환시킨다 • 행위들은 하위 목표의 결과들에 기초한다 • 조건들은 행위를 생성하는 데 필수적인 사전적-막다른 상태 측면들에 기초한다 2. 청크들은 활동적인 과정들 (산출들) 이며, 서술적 자료는 아니다 • 청킹은 영속적인 목표-기반적 캐싱의 형태이다 3. 청크들은 암묵적으로 일반화된다 • 문제해결이 무시한 것은 무엇이던지 무시한다 4. 학습은 문제 해결 동안 발생한다 • 청크들은 만들어지자마자 곧 효과적인 것이 된다 5. 청크들은 모든 막다른 상태들, 그러므로 모든 하위 목표들에 적용된다 • 탐색 통제, 연산자 구현 ··· • 지식이 불완전하거나 또는 불일치할 때는 언제나 6. 청킹은 단지 시스템이 경험하는 것만을 학습한다 • 체 문제-해결 시스템은 학습 시스템의 일부이다 • 청크 생성자 (chunker) 그 자체는 지능적이 아니고, 하나의 고정된 기제이다 7. 청킹은 준비-숙고 선에서 상향 이동하는 일반적 기제이다 |
그림 11 청킹의 특성들
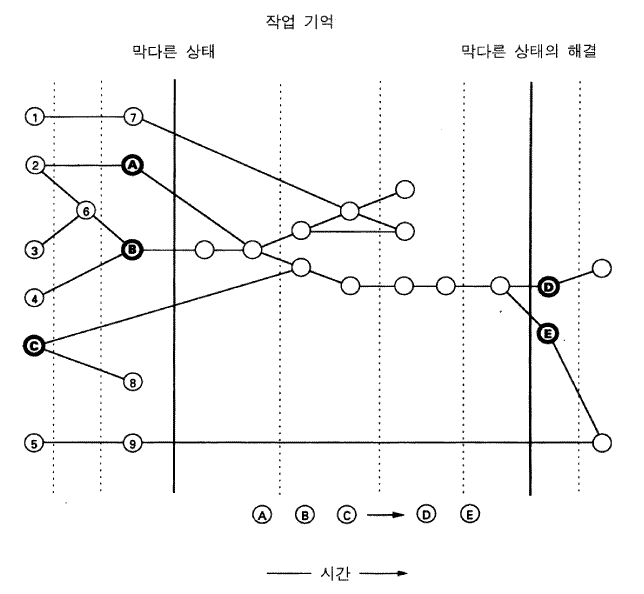
그림 12 청킹 동안 소어의 행동에 대한 도표
그림 12 는 청킹에서 어떤 일이 진행되는지를 보여준다. 그것은 왼쪽에서 오른쪽으로 시간의 흐름에 따른 작업기억을 보여준다. 나는 단지 어떤 일이 일어나는지 알아보기 쉽게 하기 위해서 작업기억 요소 (작은 원들) 들을 수직적으로 펼쳐놓았다. 이것은 산출-시스템 수준에서의 그림이며, 어떤 문제 공간들이 점화되는 산출들을 통제하고 있는가와는 관계없이, 이 수준에서의 요소들은 한 번에 하나씩 작업기억으로 들어온다. 모든 작업기억 요소들은 기존의 작업기억 요소들에 의해 실례화된 산출들에 의해 생성된다. 이러한 인과적 연결들은 그림에서 선들로 표시되어 있다. 예를 들어, 요소 B 는 그림 왼편의 요소 4 와 6 에 의해 실례화된 어느 산출의 결과이다. 현실적으로, 산출들은 많은 조건들을 갖고 있으며, 그러므로, 각 작업기억 요소와 연결된 선들은 많아야만 한다 —— 그러나 그림은 단순한 도식이다. 결정주기들은 점선으로 된 수직선으로 표시되어 있다. 어떤 시점에서 막다른 상태가 발생한다. 이것은 왼편에 있는 실선으로 된 수직선으로 표시되었다. 막다른 상태의 본질은 제시되지 않았는데, 이는 지금의 내용과는 관계가 없기 때문이다. 소어는 새로운 하위목표 맥락을 만들고 (추가적인 작업기억 요소들로서), 더 많은 작업기억 요소들을 생성해간다. 이것들은 물론 막다른 상태 이전에 존재했던 요소들과 막다른 상태 후에 발생한 요소들인 가용적인 요소들에 의존적이다. 문제 해결은 어떤 경로를 따라가다가 (위를 향해서) 그것을 버리고 다른 경로를 (아래를 향해서) 추구할 수도 있다. 궁극적으로 (가정해 보자) 두 개의 요소들 D 와 E 가 막다른 상태를 해결하는 것으로 생성되었다. 그것들은 상위 맥락 (여기에서 막다른 상태가 발생함) 에서 결정에 적용되는 선호요소를 적어도 하나는 포함할 것이고, 그것은 그 곳에서 결정을 하는 데 효과적이다. 그러므로 다음의 결정주기는 오른편의 수직 실선으로 표시된 것처럼, 상위 맥락에서 앞으로 이동할 것이다.
여기에서 막다른 상태가 해결될 때 새로운 산출 (청크) 이 생성되는데, 이것은 하단에 표시되어 있다. 그것의 행위들은 결과들인 D 와 E 로부터 형성된다. 그것의 조건들은 결과들을 발생시켰고, 막다른 상태 이전에 존재했던 3 개의 요소들, A, B, 그리고 C 로부터 형성된다. 이것들은 후진적으로 작동해서 얻어진다 —— 기계 학습에서는 후진추적 backtracing 이라고 불리는 것에 의해 결과들로 시작해서 결과를 발생시킨 요소들이 확인되고, 그 다음에는 그것들을 발생시키는 것들이 확인되고 ···. 후진 탐색은 사전 맥락의 요소들, 여기에서는 A, B, 그리고 C 가 찾아졌을 때 종결된다. 이것이 성공하지 못한 경로를 탐색하는 데 사용되었던 요소들 (최 상단의 요소 7) 이 선택되지 않았음을 주시하라. 새로운 청크는 산출들의 전체 집합에 추가되며, 이 때부터 다른 산출들과 같이 그 기능을 한다. (주석 : 청킹에 관한 위의 기술은 여러 측면에서 단순화된 것이다 (Laird, 1986). 첫째 각 독립적 결과는 하나의 독립적인 청크로 귀결되므로, 하나의 막다른 상태로부터 여러 개의 청크들이 만들어질 수 있다. 둘째 청크들은 그것들이 포착한 결과가 만들어질 때는 언제든지 만들어진다. 이러한 결과들은 어떤 경우에서라도 결코 수정되거나 또는 취소될 수 없으므로, 청크들은 곧바로 만들어질 수 있다. 셋째 청크들은 더욱 효과적이고 효율적으로 만들기 위해, 다양한 과정들이 청크에 대하여 수행된다 (항상 만족될 수 있기 때문에 어떠한 제약도 제공하지 못하는 조건들은 제거된다. 실례화된 변수들을 독특하게 유지하기 위해서 추가적인 검사들이 삽입된다. 때때로 하나의 청크가 두 개의 독립적인 청크들로 분리될 수 있다.그리고 하나의 청크의 조건들은 대응의 효율성을 높이기 위해 정렬된다).
소어가 정확하게 이 경로를 따른다고 가정해 보자. 특정한 시기에, 원래 발생했던 막다른 상태가 다시 발생하려 할 때 (왼편의 수직실선) 청크의 조건들이 가용적인 요소들 A, B, 그리고 C 에 의해서 모두 만족되기 때문에, 그 청크는 점화될 것이다. 그것은 두 개의 행위, D 와 E 를 작업기억에 투입시킬 것이다. 그것들은 결정절차에 개입할 것이고 막다른 상태는 발생하지 않을 것이다. 원래의 막다른 상태를 궁극적으로 해결했던 바로 그 선호요소들이 (오른편 수직실선에서) 지금은 사전에 모두 조합되어 있기 때문에, 문제 해결은 단순히 진행될 것이다. 결과적으로, 하나의 산출의 행위가 최초의 상황에서 요구되었던 문제해결의 모든 것들을 대체할 수 있다. 그림은 단지 약간의 처리과정만을 보여주지만, 그림 4-10 에서처럼 추가적인 막다른 상태들이 발생할 수도 있고 더 많은 하위 공간들이 탐색될 수도 있다. 시간에서의 이득은 (즉 효율성) 상당히 클 수도 있다 —— 사실상 무한히 크다. 그러므로 청킹은 경험에 의한 학습의 한 형태이며, 문제 해결의 결과들이 동일한 문제를 다시 해결할 때 접근될 수 있도록 그 안에 기억된다.
|
청크 1 : 만약 문제 공간이 단순한-블록들-세계이고, 그리고 그 상태가 목표로부터 하나의 명제만 차이가 있고, 그리고 그 상태가 블록 1, 그리고 위에 아무것도 없는 블록 2 를 가지고 있고, 그리고 탁자 위에 블록 1 이 있고, 그리고 원하는 상태는 블록 2 위에 블록 1 을 갖고 있다면, 그러면, 블록 1 을 블록 2 위로 이동시키는 연산자를 위한 최선의 선호를 만들어라 |
그림 13 그림 10 의 블록들-세계 흔적으로부터의 한 예시적 청크
그림 13 은 그림 10 의 블록 세계 과제를 수행하는 동안 학습된 실제 하나의 청크를 한글로 제시한 것이다. 청크는 다른 산출과 유사하게 보인다 (그림 4 와 비교하라). 만약 소어가 어떤 특정한 상태에 있고, 그리고 목표상태로부터 단지 한 단계 떨어져 있다면, 적용되어야 할 연산자가 무엇인지 그것은 정확히 알고 있다. 조건들은 초기의 형식화로부터 도출된 방식으로 그것을 표현한다. 첫 번째 조건은 문제공간이 단순한 블록 세계라는 것이다. 그것은 하나의 공통적인 명령문처럼 보이지만 이 지식은 과일반화 overgeneralization 하지 않도록 하는데, 즉 그것은 블록 세계 문제공간에 특수한 것임을 나타내는 데 결정적인 것이다. 두 번째 조건은 그 시스템이 목표상태로부터 한 단계 떨어져 있음을 명세화한다. 그것은 얼마나 많은 명제들이 만족되지 않았는지를 기초하여 명세화한다. 그것은 (onto B C) 와 같은 작은 명제들과 이러한 명제들을 변경시키는 연산자들에 기초한 블록 세계에 대한 특정한 표상을 함축한다. 이 조건은 역시 문제공간에 의존적이다. 세 번째와 네 번째 조건들은 현 상태와 목표상태의 실제적 내용들을 명세화한다.
위의 분석은 정확히 동일한 상황이 다시 발생할 것임을 가정했다. 그러므로 청킹은 단순히 처리의 속도를 증가시키는 하나의 방식으로 보인다. 그러나 정확히 동일한 상황이란 왼편의 수직실선에서 작업기억의 모든 요소들이 동일하다는 것을 의미한다. 그러나 단지 결과를 생성하는 데 관련이 있는 요인들만이 그 청크를 만드는 데 사용된다. 다른 나머지 것들은 관련이 없다. 청크 산출은 그것들에 대한 검사를 하지 않는다. 그러므로 청크의 조건들 (A, B, C) 에 대응되는 요소들을 갖고 있는 상황에서는 언제나, 그 상황의 다른 측면들이 다르다고 해도 청크는 점화될 것이다. 그러므로 청킹은 암묵적 일반화 implicit generalization 를 생성한다. 이 산출은 정확히 동일한 상황에서뿐만 아니라 많은 다른 상황에서도 작동할 것이며, 그러므로 학습의 전이를 생성한다. 이 산출은 작업기업에 부적절한 요소들을 투입시킬 수도 있고, 그러므로 문제 해결을 미궁에 빠뜨릴 수도 있다. 만약 그렇게 된다면, 그것은 부적 전이 negative transfer, 달리 말하면 과일반화를 생성할 것이다. 함축적 일반화가 얼마나 효과적이고 안전한지는 한번에 쉽게 결정될 수는 없다. 이 책의 나머지 부분을 통해 명확히 되겠지만, 그것은 매우 강력한 것으로 나타난다. 그러나 과일반화와 과특수화 overspecialization 는 항상 존재하는 중요한 문제들로 남아 있다.
이제 청킹이 기술되었으므로, 그림 11 의 추가적인 요점들을 살펴보자. 특히 컴퓨터 과학자들을 위해, 청킹에 대해 생각하는 하나의 간편한 방법은 그것이 목표결과들의 영속적인 캐싱 caching 이라는 것이다. 캐시 cache 를 만드는 것은 캐시를 생성하는 데 사용되는 처리를 피할 수 있다. 새로운 상황들에 대한 일반화가 발생하는 것 —— 이것은 캐시의 개념적 부분은 아니다 —— 을 제외하고 이러한 기술은 매우 정확하다. 무시되는 것은 문제해결의 하나의 기능이며 또한 표상의 기능이라는 것을 깨닫는 것은 중요하다. 결과에 도달하는 데 고려되지는 어떠한 사전 지식일지라도 모두 조건들에 포함될 것이다. 만약 문제 해결이 그것을 고려하지 않는다면, 그것은 무시될 것이다. 반면 만약 어떤 지식이 사실상 불필요하지만, 그 표상이 피상적이라고 할지라도 고려되어야 하는 것이라면, 그 결과는 그것에 의존해 얻어질 것이다. 그러므로 문제해결과 과제표상에 대한 학습의 매우 강한 의존성이 존재한다.
학습이 문제해결에 밀접하게 의존할 뿐 아니라 문제해결도 학습에 똑같이 강력하게 의존한다. 결과가 획득되자마자 청크들은 만들어지고 작동하게 된다. 그러므로 학습은 항상 진행되며, 다음의 결정주기에 효과적일 수 있다. 행동은 두 개의 명확한 단계로 나누어지지 않는다 —— 첫째로는 수행단계, 그 다음은 학습단계, 이 두 활동들은 완벽하게 뒤섞여 있다.
청킹은 모든 하위 목표들에 적용된다. 기제는 완전하게 일반적이다. 사실상, 청킹 기제는 문제 공간들이나 그것들의 기능에 기초하는 것이 아니라 산출들의 수준에서 작동한다. 예를 들면, 그것은 막다른 상태의 해결을 다루는 것이지 의미적으로 정의된 성공과 실패를 다루는 것은 아니다. 그러므로 그것은 성공한 경험과 실패한 경험 모두에서 학습한다. 소어가 하는 모든 일들은, 가장 복잡한 일에서부터 가장 단순한 선택에 이르기까지, 모두 하위 목표들에 의해 발생하기 때문에 소어는 자신의 수행의 모든 측면들에 대해 학습할 수 있다. 소어가 수행하는 모든 새로운 활동은, 처음에는 막다른 상태에 부딪칠 것인데 이는 소어가 어떻게 진행해야 하는지를 모르기 때문이다. 그 때 그것은 하위목표들에서 문제해결을 요구할 것이다 —— 때로는 광범위하게, 때로는 조금. 모든 경우에 있어서 그것은 결과들을 청크로 만들고, 그러므로 그것들에 대해 학습할 것이다. 그러므로 소어는 연산자들을 실행하는 방법, 탐색통제, 새로운 문제 공간들을 획득하는 방법에 관하여 학습할 것이고, 어떤 것이든지 소어가 그것을 위한 하위목표를 만들었다면 그것을 학습할 것이다. 이러한 일반적인 기술은 액면 그대로 완전하게 받아들여질 수는 없다 —— 청킹이 얼마나 잘 작동할 것인지는 명확하지 않다. 그러나 우리는 이 책을 통해 이러한 기술에 믿음을 주는 많은 증거들을 보게 될 것이다.
소어가 어떤 것이든 학습할 수 있다는 것은 소어가 모든 것을 학습할 것이라는 것을 의미하지는 않는다. 소어는 단지 시스템이 경험하는 것으로부터 학습한다. 그것은 경험-기반적 학습이다. 그러므로 핵심적인 질문은, 소어는 무엇을 경험할 것인가이다. 그러나 이것은 본질적으로 명확하게 하기가 어렵다. 소어가 어떤 과제들을 시도할 것인가? 이 질문은 외적인 측면과 내적인 측면, 또는 더 잘 표현하면, 대형 macro 측면과 소형 micro 측면 모두를 포함한다. 대형수준에서, 환경으로부터 소어에게 어떤 과제가 주어지는지는 중요하며, 또한 사용자가 소어에게 어떤 과제를 투입하느냐 하는 것과 같이, 소어의 외적인 측면들에 의해 강력하게 영향을 받는다. 그러나 소어가 어떻게 그 과제들을 받아들이고 그것들을 어떻게 문제 공간들로 (소형수준) 분해하는지도 역시 중요하다. 최종적으로 발생할 학습 (청킹) 은 이러한 공간들의 소형구조에 밀접하게 의존하며, 이것은 또한 모든 사전 경험에 의해 만들어진 지식에 의존한다. 더 나아가, 이러한 측면들은 서로에게 투입되는데, 이는 발생한 학습이 후속해서 발생하는 공간들을 결정하기 때문이다. 요약하면, 소어가 무엇을 학습할 것인지에 대한 어떤 이론이라도, 소어가 포함되어 있는 환경, 과제들의 발생하는 방식, 그리고 그것들이 정의되는 방식에 대한 좀더 큰 이론 —— 간단히 말하면, 그 세계의 행위자로서의 소어에 관한 전체 이론 —— 안에서 만들어져야 한다.
그림 14 3-블록 세계에서 학습을 구성하는 12 개의 청크들
그림 14 는 청킹이 이루어지는 과정을 부분적으로 제공한다. 그 그림은 3-블록 세계의 문제공간을 보여준다. 공간에서의 각 위치는 세 블록의 주어진 배열을 표상한다. 블록 세계 문제들은 어떤 초기 배열에서 어떤 목표 배열로 이동하는 것이다. 블록들은 A, B, 그리고 C 로 이름지어졌기 때문에, 어떤 블록이 어떤 위치로 이동해야만 하는지 보여질 수 있다. 거기에는 단지 3 개의 목표 배열들 (그림에서 두꺼운 테두리가 있는 것들) 만이 있다. (3 개의 블록이 있는 하나의 스택, 두 블록이 있는 하나의 스택과 한 블록이 있는 하나의 스택, 그리고 한 블록이 있는 세 개의 스택. 다른 모든 배열들은 단지 그것들의 이름표에서만 차이가 있다) 그러나 이름표 그 자체는 임의적인 것이므로, 우리는 이름표를 고정된 방식으로 지정하기 위해 그 목표 배열을 사용할 수 있다. 그러므로 공간에서 13 위치 중 한 위치를 초기 위치로 선택하고 목표 상태로 3 개의 목표 위치 중 하나를 선택함으로써 모든 가능한 블록 세계문제들이 주어질 수 있다 (그러므로 한 위치에서 다른 위치로 가는 것으로 정의되는 13 × 13 = 169 개의 문제들 중 3 개의 동일한 문제들을 포함해서 단지 3 × 13 = 39 개의 다른 문제들이 있다). 더 많은 수의 블록들에 대해서는, 그에 따른 더 많은 문제 공간들이 있고, 또한 그 안에 많은 3-블록 하위공간들이 있을 것이다.
소어가 이 공간에서 과제를 수행할 때, 그것은 청크를 만든다. 하나의 청크는 목표배열을 나타내는 작은 세 점을 앞부분에 갖고 있는 화살표로 그림에 표시되어 있다. 그림 13 의 청크는 1 번 청크이다. 이것은 두 곳에서 나타나지만, 상태 A / B/ C (C 위에 B, 그리고 B 위에 A) 를 나타내고 있는 맨 왼쪽의 것을 생각해 보자. 그것은 그것의 꼬리 부분에 있는 상태, 즉 상태 A, B / C 에서 점화될 것이다. 그 상태에서 어느 방향으로 갈 것인지에 대한 선택이 존재한다. 그 청크는 만약 목표 상태가 세 블록의 하나의 스택 (A / B / C) 이라면 목표 배열을 향해서 왼쪽으로 가라고 말하는 탐색-통제 청크인데, 물론 이 상태에서는 목표배열이 보일 수는 없다.
그림에는 모두 12 개의 청크들이 있다 —— 10 개는 단지 하나의 상황에서 발생되며 ; 2 개 (청크 1 과 3) 는 두 개의 상황에서 발생된다 —— 이러한 12 개의 청크들은 그 공간을 완전히 학습하고, 그 공간에서 그것들은 소어가 어떤 상태에서 어떤 다른 상태로의 직접적인 경로를 따라 이동할 수 있게 해준다. 청크들은 블록들에서 사용되는 실제적인 이름표에 의존하는 것이 아니라 단지 관련이 있는 출발점-목표점 source-destination 관계들에만 의존한다. 그러므로 만약 과제들이 문제 해결자에 의해 실제적으로 마주치게 되었을 때처럼 우리가 그 과제들을 고려한다면, 이와 동일한 청크들은 사실상 많은 다른 상황들에서 점화될 것이며 그것들은 어떠한 과제에 대해서도 직접적인 경로를 소어에게 안내할 것이다.
이러한 청크들은 그 청크들이 적용될 선택시점을 소어가 통과 할 때면 언제나 만들어진다. 예를 들어 A / B / C 로 향하는 어떠한 과제에서도, 소어는 궁극적으로 A, B / C 에 이를 것이며, 마지막 단계를 행할 때 소어는 청크 1 을 만들 것이다. 일단 만들어지면 그 청크는 다른 모든 장소에서, 그리고 이 경로를 통과하는 모든 과제에서 적용될 것이다. 그러므로 우리는 이 블록 세계에서 학습의 전이가 의미하는 것에 관한 개요를 갖는다. 소어는 모든 공간을 학습하기 위해 12 개의 청크들을 축적할 필요가 있고, 이들 12 개를 모두 포함만 한다면, 12 개의 청크들을 학습하는 데 사용되는 과제들이 무엇인가는 아무런 차이를 만들지 않는다. 물론, 개별적인 과제의 관점에서 보면, 청크들의 축적은 한 과제에서 다른 과제로의 학습의 전이를 함축한다.
마지막으로, 그림 2-19 의 준비 대 숙고의 교환을 살펴보는 것은 유용하다. 캐싱 기제로 여겨지는 청킹은 지속적으로 탐색을 하며, 탐색을 좀더 직접적으로 사용할 수 있는 지식, 즉 재인될 수 있는 준비된 패턴들로 바꾸어나감으로써, 선에서 상향 이동하는 일반적인 방법이다. 그렇게 함으로써, 그것은 ~~10 초 수준을 ~~1 초 수준으로의 계속적인 압축에 대한, 3 장에서 분석된 요건을 만족시키는 기제를 제공한다. 흥미롭게도 재인 지식을 포기하고 더 많은 탐색을 하는 선에서 하향으로 이동하는 대응되는 획일적 기제는 존재하지 않는 것 같다. 캐싱의 경우와 마찬가지로, 이 그림은 전이의 가능성을 제외하고는 만족스러울 것이다. 학습의 전이는 그 상황을 상당히 복잡하게 만든다. 그러나 캐싱을 선을 따라 상향으로 이동하는 것으로 생각하는 일은 여전히 유용하다.
우리는 지금 소어의 중앙 인지구조를 기술해왔다 (그림 1) : <문제공간, 재인 기억 (산출 시스템), 속성-값 표상, 결정주기, 선호, 막다른 상태, 하위목표, 그리고 청킹> 이러한 구조는 지각과 운동 행동을 포함하는 더 큰 시스템 안에 위치하고 있다. 우리는 인지와 지각과 운동 행동을 대립시키기를 원하지 않기 때문에, 그것을 전체 인지 시스템이라고 부를 것이다. 그것은 통합인지이론에 대해 결정적인 것이기 때문에, 우리는 그것의 구조를 기술할 필요가 있다. 단순한 자극-반응 연결조차도 지각, 인지, 그리고 운동행동을 포함하지 않고는 다루어질 수 없다.
이 시점에서 전체 인지 시스템은 간단하고 피상적으로 다루어질 것이다. 중앙인지를 완전히 이해하기 위해서 우리의 주의의 초점을 중앙인지에 맞출 필요가 있다. 그러므로 중앙인지를 전체 시스템에 포함시킨 후에, 우리는 이 장의 나머지 부분에서, 곧바로 중앙 기제들을 예시하고 탐구하는 것으로 돌아갈 것이다. 우리가 자극에서 반응까지의 완전한 연결을 고려할 때인 7 장에 가서, 전체 인지 시스템에 대해 다시 더 많은 주의가 주어질 것이다. 그러나 그 곳에서도 제한적으로만 다루어질 것이다. 연산 상으로 보면, 소어는 여전히 중앙인지에 대부분의 초점을 맞춘다. 이것은 소어가 마음의 모든 부분을 완전하게 다룰 것을 요구하는 통합인지이론에 대한 불완전한 본보기를 제공한다는 점을 보여준다.
그러므로 전체 시스템에 대한 설명은 대부분 이론적일 것이며 작동하는 소어 시스템에 의해 상세한 지지를 받지는 못할 것이다. 이 점의 양쪽 측면을 인식하는 것은 중요하다. 한편으로, 통합인지이론은 하나의 이론-인간 마음의 본질에 관한 하나의 지식체계 —— 이다. 일반적인 이론들과 마찬가지로, 그것은 마음에 관한 주장들로서 단지 문서의 형태로 존재할 필요가 있다. 그러므로 아래에서나 5 장에서 제시될 완전한 인지 시스템의 개요는 완벽하게 합당할 것이며, 어떠한 통합 인지이론이라 할지라도, 일정 부분은 단지 서술적 형태로 존재할 것이다. 다른 한편으로, 마음과 같은 복잡한 시스템에 관해 어떤 연산적 형태로 구체화되지 않은 이론에 많은 믿음을 부여하기는 어려운 일이다. 이것은 본질적으로 다른 측면들과의 관계를 중요하게 만드는 통합이 증가할수록, 특히 어려울 것이다. 결과적으로, 이 책 내내 소어의 연산적인 핵심을 넘어서서 확대되거나, 그것을 여러 방식으로 수정하는 이론적 가지들을 나는 계속해서 제시할 것이지만, 나는 항상 이론적 생각들 그 자체의 본질에 대해 어느 정도의 망설임과 불확실성을 가진 채 (이러한 생각들과 그것들이 설명하려고 하는 경험적 현상들과의 관계를 제외할 때조차도) 그렇게 할 것이다.
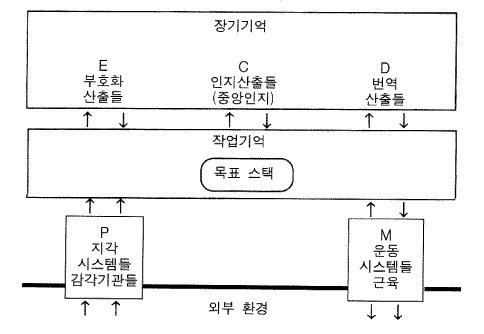
그림 15 전체 인지 시스템 (지각, 인지, 그리고 운동 시스템)
그림 15 는 전체 인지 시스템을 보여준다. 우리는 마음이 동적인 외부환경과 상호작용하는 하나의 동적 시스템의 통제장치 (그림 15 의 하단에 걸쳐서 위치해 있는) 라는 2 장의 관점으로 되돌아왔다. 전체 시스템에서 설계의 많은 부분은 이러한 통제장치 과제의 요건들에 의해 도출된다. 환경에서의 에너지들을 시스템에 대한 신호들로 변환시키는 어떤 과정들이 존재해야만 한다. 이러한 것들은 단지 감각적 측면에만 연결되어 있지만 (환경으로부터의 변환), 집합적으로 지각 시스템 (P) 이라고 불린다. 이와 유사하게 환경에 영향을 주는, 말하자면 유기체의 에너지를 환경에 주입시키는 어떤 과정들이 존재해야만 한다. 이러한 것들은 단지 물리적-행위 측면에만 연결되어 있지만, 운동 시스템 (M) 으로 불린다. 환경은 예측할 수 없는 사건들의 연속을 생성하는 동적 시스템이기 때문에, 인지 시스템이 처리를 위한 시간적 여유를 갖기 위해 완충기억이 존재해야만 한다. 그것이 작업기억이다 —— 중앙인지 (C) 가 작업을 하는 동일한 기억. 그러므로 작업기억은 전체 시스템의 모든 구성요소들을 위한 의사소통 장치가 된다. 그것은 완충장치이면서 버스 bus 이다.
버스와 완충장치로서의 작업기억의 배열은, 이미 그 장치가 중앙인지를 위해 주어진 것으로, 가장 단순한 구조적 가정이다. 그러나 이 가정은 검토할 가치가 있다. 그 기능적 필요성은 완충작용이 일어나야만 하며 궁극적으로 인지와 연결이 이루어져야 한다는 것이다. 지각적 측면에는, P 에 포함된 다른 완충기억 장치들이 있을 수도 있다. P 는 어떤 특수한 기억에 요소들을 투입시키고, 다른 특수한 장치가 그것들을 작업기억으로 이동시킬 수도 있다. 그림은 이것에 대해서 아무 말도 하지 않는다. 인지가 그러한 구조적으로 개별적인 완충기억 장치를 직접적으로 검토할 수 있다고 생각될 수도 있다. 그러나 인지가 모든 것들을 검토하는 유일한 방법이 산출이며, 산출들이 검토하는 것은 작업기억이라 불리기 때문에, 이러한 제안이 식별이 되는 꼬리표와 작업-기억 요소들과 대응시키는 조건들을 갖고 있는 산출들을 갖고 있다는 것과 다르다는 것은 의심스럽다.
운동의 측면에서는, 적절한 시간에 M 의 내적 구성요소들이 정보를 사용할 수 있게 만들어주기 위해 M 안에는 추가적인 완충작용이 존재할 수 있다. 그림 15 는 이것에 대해서도 역시 아무 말이 없다. 그러나 운동행위들은 작업기억에 나타남이 없이, 그러한 운동 기억들에 연결되는 산출들의 직접적 행위들 direct actions 일 수도 있다. 이러한 직접-행위 방식은 운동시스템과의 의사소통을 위해 인지가 요소들을 작업기억에 투입시키는 그림 15 에서와 같은 간접적인 행위보다 더 간단해 보일 수 있다. 사실상 현존하는 거의 모든 산출 시스템들 (Ops5 를 포함하여) 은 일반적으로 직접적 방식을 사용하며, 간접적 방식을 사용하지는 않는다. 그러나 직접행위는 치명적인 결함을 갖고 있다. 그것은 급사 sudden death 의 가능성을 함축하고 있다. 만약 위험한 운동명령 (예를 들면, 자신을 죽여라!) 을 포함하고 있는 산출이 점화되었을 때, 그것을 감지해서 취소시킬 수 있는 방법이 없다. 물론 운동명령은 외부세계에 영향을 주며, 그런 것들은 궁극적으로 되돌릴 수는 없다. 그러므로 문제는 그 실행이 완전히 회피될 수 있는지가 아니라 어떤 종류의 안전장치가 그러한 연산들에 대해 제공되느냐이다. 직접행위는 급사를 일으키는 산출이 결코 점화되지 않거나 또는 결코 만들어지지 않을 것이라는 확신에 그 책임이 있음을 의미한다. 그러나 소어에서의 중앙인지의 설계를 생각했을 때, 그것은 지지받을 수 없는 것이다. 소어에 있어서, 안전장치는 내적인 행위를 포함해 취소할 수 없는 행위들에 대한 방어를 제공하기 위해 신중하게 만들어진 결정주기에 존재한다. 정교화 주기는 전적으로 허용적이지만, 그것은 즉시 알려진 것들이 사용되는 것을 허용하지 위해 정지상태가 된다. 결정절차는 불량한 행위를 생성하는 어떤 불량한 산출이 적어도 점화될 가능성이 낮게 되도록 보증하는 경비원이다. 그러므로 형식적인 근거에서는 산출행위로부터의 직접적인 운동행위가 좀더 간단해 보이지만, 소어에서 그러한 설계는 수용되지 않는다.
전체 시스템은 P 에서 C, 그리고 C 에서 M 보다 더 많은 것으로 구성된다. 부호화 산출들 encoding productions (E-산출) 이라 불리는 산출들과 번역 산출들 decoding production (D-산출) 이라 불리는 산출들이 있다. 이러한 산출들은 형태나 구조에 있어서 중앙인지의 산출들 (이것들을 C-산출이라 부를 수 있다) 과 동일하다. 그것들은 목표맥락 스택에서부터 완전히 자유롭다는 점에서 다르다. 그것들에게는 결정주기, 정지상태로 되기, 그리고 막다른 상태와 같은 것들이 없다 —— 그것들은 자유자재로 점화된다. 이와 대조적으로, 인지산출은 연결성 제약에 의해서 목표맥락 스택과 묶여져 있다. 각 조건은 목표맥락 요소와 대응되든지 또는 목표-맥락 요소와 연결되어 있는 (아마도 명시적인 연쇄에 의해) 요소와 대응되어야만 한다. 부호화 산출과 번역 산출은 단지 그것들이 수행하는 기능에 의해 구별된다.
입력의 측면에서, 지각 시스템으로부터 요소들이 자동적으로 도착했을 때, 부호화 산출은 지각적 분석 parsing 이라고 하는 것, 즉 [요소들을 중앙인지가 고려할 수 있는 형태로 만들어 주는 것] 을 제공한다. 출력의 측면에서도 마찬가지로, 번역 산출은 인지 시스템에 의해 생성된 운동명령을 운동 시스템이 사용하는 형태로 번역하거나 확장시켜주어야 한다. 운동 시스템 그 자체는 작업기억으로 요소들을 돌려보낼 수도 있는데, 이는 운동 시스템이 명령으로서 실행하고 있는 과정들이 행위로 나타남을 의미한다. 그러한 자기수용기적 proprioceptive 요소들 자체도 인지에 의해 고려되기 전에 지각적 분석을 받을 수 있다.
이러한 모든 활동이 통제 하에 있는 것은 아니다 —— 이러한 산출들은 여러 가지가 동시에, 그리고 중앙인지와 동시에 자유자재로 인식되고 실행된다. 통제는 중앙인지에 의해 수행되는데, 중앙인지는 이제 결정장치로 구성되어 있는 것으로 볼 수 있으며, 그러한 결정장치들로부터 결정주기, 막다른 상태, 목표맥락 스택, 그리고 문제-공간 조직화가 만들어져 나온다. 요소들이 작업기억으로 자동적으로 유입될 뿐만 아니라 부호화 산출과 번역 산출들이 혼란스럽게 활동하기 때문에 중앙인지는 본질적으로 관리통제의 형태로서 작동하는 것으로 여겨질 수 있다.
중앙인지는 사실상 순차적 —— 이것은 결정기제가 강요하는 것이다 —— 이기 때문에 그것은 작업기억에서 진행되는 것의 일부분만을 고려할 수 있다. 사실상, 부호화 산출들의 기능적 요건은 새로운 정보의 도착을 잘 진전시켜서 중앙인지의 제한된 노력이 잘 사용되도록 하는 것이다. 위에서 언급한 급사의 문제에 대해, 운동 행위들이 명령의 번역에서 근육의 점화까지 발전하는 데 시간이 소요된다. 중앙인지는 번역의 산출물들과 운동 시스템이 작업기억에 남긴 모든 것들 (다른 부호화 산출들에 의해 정교화된 것들) 을 사용해서, 이것들에 대한 관리통제에 영향을 미칠 수 있다. 중앙인지는 처리중간에 수정이나 행위를 중도에 멈추게 하는 새로운 명령들을 내릴 기회를 갖는다.
당신은 이 그림에서 부호화 산출들이 중앙인지가 작업하고 있는 대상들을 왜 더 정교화시킬 수 없는지 의아하게 생가할 수도 있다. 그러나 그 답은 명확한데, 이는 정교화 단계 동안에 계속 발생하는 산출들은 부호화 산출과 번역 산출들과 구별되지 않기 때문이다. 즉 [정교화 단계는 개방된 기간이고 점화될 수 있는 어떠한 산출이라도 점화될 것이다] . 중요한 요점은 결정기제는 인지 산출들의 산출물들의 정지상태를 결정단계로 이동하라는 신호로 감지하며, 계속 진행되는 부호화와 번역을 무시한다는 것이다.
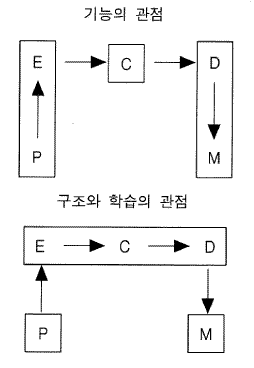
그림 16 전체 인지 시스템에 대한 두 가지 견해들
전체 시스템은 기능적 또는 구조적 관점으로 살펴볼 수 있다. 그림 16 의 상단은 기능적 관점을 보여준다. 거기에서, 지각은 사실상 P + E 이다. P 는 감각적 구성요소이고 E 는 그것의 지각적 부호화이다. (P 모듈을 감각기관이라 부르려는 유혹은 강력하지만, 감각과 지각간의 구분은 기초에 매우 복잡하게 깔려 있기 때문에 그 문제들을 해결하는 것은 불가능하며 감각 대 지각과 같이 명칭을 붙이는 것은 회피하는 것이 최선책이다. 소어구성의 관점에서, 이 시점에서는 P 와 E 사이의 인터페이스 (즉 P 가 무엇을 전달하여 E-산출들이 정교화시키는가) 는 본질적으로 논쟁 중인 문제이다.) 운동 시스템은 사실상 D + M 이다. D 는 번역, 그리고 국소적-통제 구성 요소이고 M 은 작동장치이다. 그러므로 C 는 관리 시스템이다. 그림의 하단은 구조적 관점을 보여준다. 여기서, P 와 M 은 적어도 인지의 장치들과는 몇 가지 방식에서 매우 다른 기제들의 불특정한 집합들로 구성된다 —— 한편 그것은 에너지를 표상으로 변환시켜야만 하고, 다른 한편으로 그것은 실제적인 노력을 필요로 하는 행위들을 취해야만 한다. E + C + D 는 모두 유사한 것들, 즉 산출들로, 그것들은 내용에 의해서 구별된다. 이 두 개의 도식은 전체 시스템의 구성요소들을 매우 다르게 분류한다.
이러한 두 대안적 관점들의 중요성은 하나의 흥미로운 가설에 의해 나타난다. 그것은 진정한 가설이지만, 전체인지 시스템이 아직 완전히 연산적으로 발전되지 않았기 때문에, 그것은 소어에서 아직은 검토될 수가 없다. 그 가설은 부호화와 번역 산출의 기원에 관한 것이다. 그 가설은 그것들이 중앙인지의 산출들과 마찬가지로, 청킹으로부터 발생한다고 주장한다. 결국 E-산출이나 D-산출은 단지 산출들이다. 왜 그것들이 다른 산출들이 발생하는 방법, 즉 청킹과는 다른 방법으로 발생해야만 할까? C-산출들을 구별 짓는 유일한 특징은 그것들이 연결성 제약에 의해 간접적으로 목표 스택과 묶어져 있다는 것이다.
새로운 청크가 만들어지는 것을 생각해 보자. 만약 그것의 조건들이 목표-맥락 요소들을 명세화하거나 또는 연결되어 있는 요소들과의 연결을 명세화한다면, 그것은 C-산출일 것이다. 그러나 만약 그것의 생성과 관련된 암묵적 일반화가 목표-맥락 스택을 제거한다면, 그것은 다른 종류의 산출, 이를테면 E-산출이나, D-산출이 될 수도 있다. 무엇이 발생하는가는 청크가 만들어질 때 (암묵적 일반화에 의해) 발생하는 추상화 abstraction 에 달려 있다. 그리고 이것은 2 절에서 청킹의 논의에서 강조되었던 문제해결과 표상의 상세사항들에 의존한다. 적어도 적절한 조건들 아래에서 청크들이 목표 맥락으로부터 자유로워질 것이고 자유롭게 점화되는 E-산출이나 D-산출이 될 가능성은 있다. (이것이 가능성이 없는 것처럼 가정되지 않도록 하기 위해서, 그러한 극단적인 무맥락 context-free 산출들은 일반적으로 과일반화 오류들을 나타내지만 이미 제기된다.) 다음 장에서 다루어질 전체 시스템의 측면들을 포함한 많은 상세한 사항들이 이 문제에 영향을 주며, 상세사항들의 일부는 단지 지각에만 적용되거나 또는 단지 운동행동에만 적용된다. 큰 차이를 만들어내는 구성의 작고 세심한 고안들이 발견되어서, 그 가설이 현재의 소어 구성에서 정확히 구체적으로 만들어진 것이 아닐 가능성도 역시 있다. 만약 그 가설이 진실임이 증명된다면, 그 가설의 중요성은 주목할 만한 것이다. 그것은 한번에 지각적학습과 운동학습 모두에 대한 이론을 제공하며, 그것은 그것들과 숙고적인 인지학습과의 관계를 정의한다. 그 가설은 전체 소어구성의 통합적 구조를 강조하기 때문에, 그 가설을 여기서 시작하는 것은 가치가 있다.
이제 우리는 전체 인지 시스템을 한쪽으로 치우고 중앙인지의 작동과 범위를 확실히 이해하기 위해 중앙인지로 되돌아간다. 그러나 지금부터는 중앙 인지기제가 진공 안에서 자유롭게 떠다니는 —— 또는 구스리 (Guthrie, 1953) 가 인지도를 갖고 있는 톨먼 Tolman 의 쥐에 대해 말했듯이 생각 속에 영원히 파묻혀 버리는 —— 것으로 가정되어져서는 안 된다. 그 대신, 중앙인지는 행동하는 유기체의 통제구조이다.
소어가 어떻게 행동하는지에 대한 예들을 살펴보자. 블록 세계는 소어가 작동하는 기제들에 대한 이해에 유용한 조그마한 예이지만, 그것은 이러한 기제들이 지능 시스템을 구성하는지에 대해서는 많은 것을 보여주지 못한다. 사용할 수 있는 가장 좋은 예는 지능을 가장 많이 요구하는 과제들이다. 이러한 것은 소어를 하나의 AI 시스템으로 개발하려는 노력에서 나온다.
R1 (엑스콘 XCON 이라고도 불리는) 은 CMU 의 맥더모트 McDermott 와 Digital Equipment Corporation 이 함께 개발한 전문가 시스템이다 (McDermott, 1982). R1 은 상업적으로 가장 성공한 전문가 시스템의 하나가 되었다 (Bachant & McDermott, 1984). 모든 Digital Vax 컴퓨터의 주문은 R1 을 통해 처리되고, 이 시스템은 Vax 컴퓨터의 판매와 제조를 통제하고 구조화하는 Digital 의 전문가 시스템들의 집합의 중심에 위치한다.
R1 은 입력으로서 Vax 를 주문하는 고객과 함께 판매사원으로부터의 주문을 받는다. R1 은 그 주문이 올바른가, 즉 일치하는지를 검토한 다음 그 주문에 응한다. 고객이 명세화한 주요 항목들 예를 들면, 케이블의 길이 또는 전원장치 같은 것들 이외에 명세화되어야 할 것들이 많이 있다. R1 은 구성요소들을 캐비닛이나 모듈 안에 설계한다. 그것의 출력은 시스템에 관한 모든 세부 사항들과 그것이 조립되는 방법을 기술하는 하나의 설계도이다. 이 배열을 명세화하는데, 그것은 많은 수의 사실들과 사항들을 고려한다 —— 구성요소들의 비용, 전력 요구량, 케이블 길이, 구성요소들 간의 호환성 제약 등등.
Vax 를 배열 configuration 하는 것은 인간 전문가가 비교적 잘 하는 지식-집약적 과제의 좋은 예이다. 적당한 지능, 일반적인 전문교육, 그리고 부지런한 어떠한 사람도 Vax 를 배열할 수 있다. 그러나 그 사람은 Vax 에 관한 모든 것을 알아야 하고, 그것에 관한 세부사항들을 알아야 한다. 많은 연습과 안내책자, 도표, 상품명세서, 그리고 Digital 의 생산조직을 통해 Vax 에 관한 정보들에 접근이 주어진다면, 사람은 그 과제에 숙달될 수 있다. 적당히 친숙해졌을 때조차도, 사람들은 어느 정도의 탐색을 한다 —— 적절한 배열을 찾기 위해 시간을 소비한다. 단지 시간이 지남에 따라, 기술이 축적되고 탐색을 거의 요구하지 않게 된다.
R1 은 전문가 수준의 수행을 할 수 있는 AI 전문가 (또는 지식-기반적) 시스템의 좋은 예이다. 그러나 R1 은 전형적인 전문가 시스템은 아니다. 배열은 단순한 유형의 설계과제이며, 대부분의 전문가 시스템들은 진단적 과제를 수행한다. 더구나 R1 은 가장 규모가 큰 전문가 시스템 중 하나이다. 그것은 소어 연구가 수행되었을 때 (1984) 약 1 만개의 구성요소들의 데이터 베이스를 갖고 있고 3, 300 개의 규칙들로 이루어 졌었고 그 후로도 많은 성장을 하고 있다.
R1-소어는 소어의 경력 초기에 실제적인 과제를 갖고 작업한 첫 번째 시도로서 만들어졌다 (Rosenbloon, Laird, McDermott, Newell, & Orciuch, 1985 ; Van de Brug, Rosenbloom, & Newell, 1986). R1-소어는 Vax 배열과제의 주요한 구성요소를 수행한다. 그것은 R1 이 하는 동일한 방법으로 그것을 하는 것은 아니다. 그 연구는 R1 을 소어에서 모의실험한 것이 아니라, 정확히 동일한 지식을 사용해 정확히 동일한 배열들을 얻어내는 것이었으며, 이렇게 하는 것은 R1-소어와 R1 을 비교함으로써 학습하는 기회를 극대화시키는 것이었다. R1-소어는 R1 의 전체 기능성의 약 25 % 를 제공했는데, R1 에서 상당히 어려운 부분이라고 여겨지는 단일버스 unibus 를 배열하는 것을 주로 제공했다. 이것은 많은 노력을 들인다면 R1 의 기능의 모든 것들이 제공될 수도 있다는 확신을 갖기에 충분한 적용범위이다. (주석 : RIME (Bachant, 1988) 라 불리는 하나의 방법론은 R1 의 수정판을 만들어낸 Digital 에서 개발되었다. RIME 는 R1 —— 소어의 몇 가지 과제 —— 구조 특징들, 즉 문제 공간들, 그리고 몇 가지의 방법론적 방식들을 채택하지만, 막다른 상태들 또는 청킹을 채택하지는 않는다. 한편, RIME 는 전체 R1 시스템이 R1-소어에 따라 구성될 수 있다는 것에 대한 약간의 타당성을 제공한다. 다른 한편 Digital 의 현재의 R1 / XCON 시스템은 크기, 가능성, 유지능력, 그리고 수정능력에서 성장하였으며, 그러므로 원래의 R1-소어는 현재의 전체 시스템의 매우 적당한 일부분으로 나타난다.)
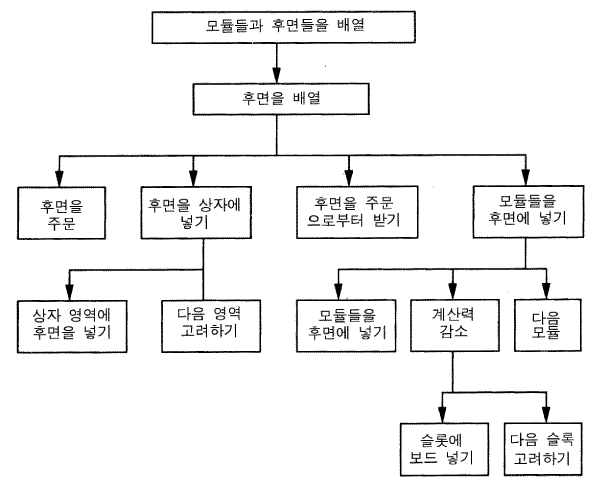
그림 17 연산자 구현 문제공간
그림 17 은 R1-소어의 문제공간들의 위계를 보여준다. 이 구조는 두 번째의 좀더 완전한 수정판 version 으로부터 나온 것이다 (Van de Brug, Rosenbloom, & Newell, 1986). 이것들은 연산자-구현 operator-implementation 공간들이다. 다른 (상위) 공간에서 연산자가 선택되고 그것의 과제를 직접적으로 가용적인 (즉 상위 공간에서의 산출들에 있는) 지식에 의해 완성할 수 없을 때, 각 연산자-구현 공간들은 발생하게 된다. 그러면 무변화에 의한 막다른 상태가 발생하고, 연산자를 위해 처리를 할 적당한 공간이 선택된다. 이 위계는, 시스템의 지식이 문제 공간들의 이러한 집합들에 포함된다는 점에서, 표준적인 서브루틴 subroutine 위계와 일치한다. 예를 들면, 그림에서의 최상위 공간은 모듈과 후면 backplanes 을 배열함으로써 전체 배열과제를 하는 공간이다. 후면을 배열하는 연산자는 동일한 이름의 공간으로 귀결된다. 그 공간에서 상자 안에 후면을 넣는 연산자들이 발생되거나 주문으로부터 후면을 얻는 연산자 또는 다른 연산자들이 발생될 수 있다. 각 공간은 과제의 일부를 수행하는 방법에 대한 어떤 지식을 포함한다.
R1 자체는 많은 전문가 시스템들에서 보이는 전형적인 것처럼, 비교적 평평한 조직에서 실현된다. 맥락이라 불리는 (소어의 목표맥락과 혼동하지 말라) 하나의 하위구조가 있는데, 그것은 본질적으로 단일한 하위 과제를 조직화한다. R1 의 기능성의 증가는 인간 전문가의 전반적 지식 (R1 과 Vax 배열에 관한 지식) 으로부터 더욱 많이 구별되는 맥락들과 이와 연합된 규칙들을 더함으로써 발생한다. 3, 300 개의 규칙들은 200 개의 그러한 맥락상황들을 포함한다. 전문가 시스템의 전문용어로 R1 은 비교적 얕은 shallow 시스템이며, 이 시스템에서는 무엇이 궁극적으로 유용한 행위이어야 하는지에 대한 전문가의 판단을 반영하기 위하여 규칙들이 될 수 있는 한 많이 만들어지지만, 그 시스템에게는 과제의 구조의 관점에서 그 과제에 대해 추리하는 능력이 주어지지 않는다.
R1 을 R1-소어에 대응시키는데, 우리는 그 척도의 반대편 끝으로, 즉 깊은 deep 구조 쪽으로 이동했다. 우리는 소어가 컴퓨터를 배열하는 과제의 기본적인 연산들을 수행할 수 있도록 기본적인 공간들의 집합을 제공했다. 어떠한 발견법적인 지식 없이 단지 탐색에 의해서 R1 처럼 동일한 과제를 소어가 해결할 수 있도록 해주는 형식화를 제공하는 것은 중요했다. 그것은 그 영역의 지식 —— 이러한 깊은 공간들 —— 을 필요로 했다. 그것은 또한 그 과제에 관한 지식 —— 잘 형성된 배열에 대한 제약들, 그리고 비용, 전력한계, 등과 같은 배열의 다른 측면들에 관한 평가 기능들 —— 도 필요로 했다. 이 깊은 형식화는 개념적으로 난해한 것은 아니다. 그것은 본질적으로 조잡한 연산과 연결의 블록들 세계이다 —— 캐비닛이나 후면과 같은 용기를 선택하기, 구성요소들과 케이블과 같은 여러 가지 물건들을 용기에 집어넣기, 그 결과를 제약과 비용의 관점에서 평가하기. 그것은 만들어진, 그러므로 불연속적이고 믿을 수 있는 환경이다. 그럼에도 불구하고, 그것은 전문가 시스템에 있어서 얕은-깊은 과제의 연속선상의 깊은 쪽 끝의 특징을 정확히 갖고 있는 하나의 형식화이다. 배열들은 임시적으로 구성될 수 있고 평가될 수도 있다.
|
|
무학습 |
학습 중 |
학습 후 |
|
기본 : 탐색-통제 지식이 없음 |
1731' [232]'' |
485 [+59] |
7 [291] |
|
불완전한 : 2 개의 핵심적인 탐색-통제 규칙들 |
243 [234] |
111 [+14} |
7 [248] |
|
완전한 : R1 과 동등한 탐색 통제
' 결정 주기들 '' [규칙들의 수] |
150 [242]
|
90 [+12]
|
7 [254]
|
그림 18 R1-소어에 의한 수행과 학습 (Laird, Newell, & Rosenbloom, 1987 에서 인용)
그림 18 은 작은 배열 과제에서의 R1-소어의 행동을 보여준다. 무학습 행을 생각해 보자. 기본 시스템은 어떠한 발견법적 탐색통제도 갖고 있지 않고, 연산자를 갖고 있는 공간들에 기초한 과제의 기본적 정의와 평가 기능들만을 갖고 있는 것이다. 소어는 본질적으로 약간의 후퇴도 하는 언덕-오르기 hill-climbing 탐색에 의하여 1,731 번의 결정주기 후 배열을 얻는다. (사람에 의한) 이 수행의 분석은 탐색-통제 지식의 두 가지 산출들을 제안하는 것으로 귀결되고, 그것들은 불완전한 partial 시스템을 만들기 위해 추가될 수 있다. 이 두 개의 추가적인 산출들을 갖고, R1-소어는 단지 243 번의 결정주기 후에 배열을 달성할 수 있다 (동일한 최종의 배열을 달성함). 8 개의 탐색-통제 산출들을 R1-소어에 추가함으로써, R-1 소어는 R1 이 갖고 있는 정확하게 같은 지식을 갖게 되고 완전한 full 시스템으로 만들어진다. 우리는 R1 산출들의 실제적인 집합으로부터 작업을 했기 때문에, <R1 과 정확히 동일한 지식> 을 갖고 있다는 특성화는 합당한 근거가 있는 것이다. 이 시점에서, R1-소어는 150 번의 결정주기 후에 (하단 왼쪽 숫자) 동일한 배열을 달성할 수 있다. 그것은 R1 이 하는 것과 거의 비슷하게 주문으로부터 승인까지 직접적으로 이동한다. 1,731 번의 결정주기에서부터 150 번의 결정주기까지의 ~10 의 계수는 R1 에 포함되어 있는 탐색-통제 지식의 가치를 표시해 준다.
무학습 행은 3 가지를 증명한다. 첫째 그것은 소어가 적당한 크기의 과제들에서 작동할 수 있음을 보여준다. Vax 배열은 대형과제는 아니지만 실제적인 과제이다. (주석 : 이 실행은 단지 R1 의 ~ 15 % 만을 포함하는 R1-소어의 초기 수정판을 가지고, 작은 과제에 대하여 이루어진 것이다. 두 번째 수정판은 ~ 25 % 를 포함했고, 15 개의 일반적-크기 과제들의 집단에 대해서 실행되었다 ; 그 자료의 표를 위해서 레어드, 뉴웰, 그리고 로젠블룸 (1987) 을 보아라.) 둘째 그것은 소어가 지식-집약적 시스템처럼 행동할 수 있음을 보여준다. 전문가 시스템 영역에서 자주 표현되는 이분법이 있는데, 하나는 지식-집약적 knowledge-intensive 시스템이고 다른 하나는 지식-비집약적 knowledge-lean (또는 일반적 문제-해결) 시스템이다 (Chandrasekaran & Mittal, 1983 ; Hart, 1982). 소어는 말하자면, 공장에서 바로 나왔을 때는 일반적 문제-해결자 형태이다. 그러므로 그것이 지식-집약적 시스템처럼 행동할 수 있는지는 흥미로운 것이다. 셋째 왼편의 행은, 단지 산출들을 추가함으로써 소어는 문제 해결자 (상단) 의 유형에서 다른 유형 (하단) 으로 부드럽게 이동할 수 있음을 보여준다. 경우에 따라 소어는 일반적인 문제해결 행동과 지식-집약적 행동을 혼합할 수도 있다. 이러한 세 가지 요점들은 소어의 구조를 검토함으로써 모두 명확해질 수 있다. <그러나 그것의 경험적인 실증도 환영해야 할 것이다.> 이러한 실증들 이외에도, 전체적인 크기에서나 (R1-소어와 동등한 것에 대하여 242 개), 소어를 기본 시스템에서 완전한 시스템으로 만들기 위한 작은 증가에 (단지 10 개의 산출들이 추가됨) 있어서, 규칙들의 수가 비교적 적다는 것은 흥미롭다. R1-소어의 현 수정판과 동등한 R1 시스템은 약 500 개의 규칙들을 갖고 있다.
왼편 행에서 밑으로 이동함에 따라 소어는 실제적으로 그림 2-19 의 준비 대 숙고 공간에서 선을 따라 뒤로 후퇴하고 있다. 그것은 232 개의 규칙의 가치가 있는 즉시 사용이 가능한 지식을 갖고 1, 731 번의 결정주기를 취함으로써 시작한다. 그 다음 그것은 234 개 규칙의 가치가 있는 지식을 갖고 243 번의 결정주기들을 취하는 것으로 이동한다. 마지막으로 그것은 242 개의 규칙을 갖고 단지 150 번의 결정주기만을 취한다. 모든 경우에서 시스템은 정확히 동일한 과제를 수행하기 때문에, 그것은 사실상 선을 따라 움직인다. 그러므로 그림 2-19 와 같은 도식은 단순한 개념적 장치 이상의 것이다. <적어도 때때로는, 실제적으로 그 도식 위에 시스템을 위치시키는 것이 가능하다.>
다음은 학습에 관한 질문이다. R1-소어 노력이 시작되었을 때, 소어는 청킹을 할 수가 없었는데, 청킹은 초기설계의 일부가 아니었다. 그러나 R1-소어가 작동될 때에는, 청킹이 소어에서 실현될 수 있음이 발견되었다 (Laird, Rosenbloom, & Newell, 1984). 만약 청킹이 작동한다면 소어는 이 과제에서 기본 시스템 (이것은 1,731 번의 결정주기를 취한다) 으로 시작해 무엇을 할 것인가? 맨 위의 열은 그 자료를 보여준다. 놀라운 일이 일어났는데, 특히 사전검사 / 사후검사 학습설계에 익숙한 심리학자들에게는 더욱 그렇다. 중간 행은 학습하는 중이라고 불리는데, 이는 학습이 작동되면서 수행이 측정된 것이기 때문이다. 소어가 이 과제를 시작할 때 그것은 정확히 기본 시스템이다. 그런 후 그것은 청크들을 만들기 시작하고, 이러한 청크들은 소어가 이 첫 번째 배열을 끝마치기 전에 실제로 사용된다. 1,731 번의 결정주기를 취하는 대신 R1-소어는 상당히 감소한, 단지 485 번의 결정주기만을 취한다. 즉 시행 내 전이 within-trial transfer 가 있다. 이 실행 동안에 소어는 59 개의 산출들을 학습했다.
그림 18 은 단일한 과제에 대한 자료를 보여준다. 결과적으로, 만약 표준적인 사후검사 posttest 가 학습시행이 끝난 후에 실시된다면, 소어는 학습할 수 있는 모든 것을 학습했고, 이제 단지 7 번의 결정주기만을 취함 (학습 후 행) 을 우리는 발견한다. 이것들은 최상의 수준에서의 이동인데, 이것들은 더 높은 수준에서의 막다른 상태에 대한 반응으로 발생하지 않기 때문에 청크가 될 수 없다. 그림은 다른 두 개의 열들은 시작점이 다르다는 것을 제외하고는 맨 위의 열과 일치한다. 그것들은 만약 시스템에게 몇 가지 다른 산출들 (여기서는 손으로 생성된) 이 미리 주어질 때에도, 청킹은 여전히 추가적인 시행 내 전이를 제공함을 보여준다. 모든 경우에서, 학습은 [단일한 시행에서 완성되며, 동일한 7 번의 결정주기로 끝난다.] 마지막 열에서 시스템에게 R1 에 있는 모든 지식을 미리 주어질 때조차 그것은 여전히 학습에 따라 더 빨라진다. 그 이득은 미리 주어진 양에 따라 점진적으로 72 % 에서 54 % 로 또 40 % 로 감소하지만, 이것은 기대되는 것이다.
R1-소어가 단일한 시행에서 완전히 학습된다는 것은 Vax 를 배열하는 것과 같은 복잡한 과제에 대해서는 약간 이상하게 보인다. 그러한 속도에 대한 이유가 있으며, 그것은 인간의 학습에 관한 이론들과 일치한다.인간 인지에서의 청킹 이론은 (1 장에서 간략히 기술된 것처럼) 즉각적인 경험에서 가용적인 기호들의 기호화된 집합들인 청크들을 인간은 지속적으로 구성한다라고 가정한다. 그러면 그 청크들은 나중에 즉각적인 경험에서 가용적이 되며, 추가적으로 청크들을 만든다. 그러므로 청크 위계는 세계의 동일한 부분에 대한 다중의 경험에 의해 한 번에 한 수준씩 만든다. 그러나 소어는 모든 수준들에서의 청크들을 동시에 학습한다. 그것은 가능한 일인데 이는 그것이 막다른 상태가 해결될 때까지 그 막다른 상태에 대한 선행하는 조건들을 기억에 유지할 수 있기 때문이다. 이것은 무한히 긴 지연을 요구할 수도 있고, 결과적으로 큰 용량의 중간 단계의 기억을 요구한다. 소어는 상향적 bottom-up 청킹이라 불리는 것을 갖고도 역시 실행될 수 있다. 그것은 하위의 막다른 상태 subimpasses 를 갖고 있지 않은 막다른 상태들에 대해서만 청크들을 만든다 —— 만약 어떠한 것이라도 학습경험을 차단하면 청킹은 일어나지 않는다. 이러한 방식은 작은 단기기억을 요구하지만 완전한 행동을 학습하기 위하여 다중 시행들을 요구한다.
그림 18 의 두 개의 학습 행은 두 가지를 보여준다. 첫째 그것들은 소어가 청킹에 의해서, 즉 학습에 의해 지식-집약적이 될 수 있음을 보여준다. 이러한 학습은 적당히 복잡한 실제의 과제에서 발생한다. 소어가 손으로 만든 2 개의 산출과 동일한 많은 청크들을 획득하는 것은 명백하지만, 청크들에 의해 정확히 무엇이 학습되었는지 그 그림에서는 알 수가 없다. 둘째 문제해결과 학습은 혼합되어 있다. 사람이 경험으로부터 계속해서 학습하는 방식과 유사하게 시스템이 항상 청킹을 갖고 작동한다고 한다면, 청킹으로부터 즉각적으로 뒤따르는 수행으로의 지속적이고 즉각적인 전방투입 feedforward 이 있을 것이다. 그러므로 우리는 일반적인 시행 간 전이에 대조되는 시행 내 전이를 기술하게 된다. 심리학 연구들에서는 시행 내 전이는 거의 나타나지 않는데, 이는 비교를 위해 요구되는 학습이 없는 행동의 기저선을 얻는 간편한 방법이 없기 때문이다. 인간의 학습은 중단될 수 없다.
R1-소어는 수행과 학습에 관한, 소어의 많은 특성들의 훌륭한 실증을 제공한다. 그러나 이것은 시스템의 여러 측면들의 중요성에 대한 기초를 제공하기 위해 전문가 시스템을 사용하는 전형적인 AI-지향적 분석이다. 우리는 이 예가 통합인지이론에 대해 어떠한 의미를 갖는가 하는 문제를 숙고해 볼 필요가 있다. 소어는 인간인지구성의 한 모형이다 —— 즉 그것은 그 이론을 구체화한다. 그러한 모든 이론들의 하나의 중심적 예측은 사람들이 지능적으로 행동할 수 있다는 것이다. 이론으로부터 이 예측을 얻어내는 <우리가 알고 있는> 유일한 방법은 이론에 따라 설계된 시스템 (소어) 이 지능적으로 행동함을 구체적으로 보여주는 것이다. 만약 어떤 사람이 지능을 설명하는 충분한 기제들에 대해서 독립적으로 확립된 이론을 갖고 있다면, 제안된 통합이론이 지능적 행동을 예측한다는 것을 보여주기 위해 여러 가지의 대안적인 증거들이 사용 가능할 것이다. 그러나 그러한 이론은 아직 발견되지 않았고, 어떤 것이 그와 같은 것이 될 것인지도 명확하지 않다. 그러므로 우리는 일반적인 지능적 행동을 생성하기 위해 이러한 기제들의 충분성을 직접적으로 실증해야만 한다. 이러한 증명은 가능한한 많은 지능적 능력을 보여주는 것이 중요하다. 탁자 위에서 블록들을 이동시키는 것과 같은 작은 과제를 수행하는 것으로는 충분하지 않다. 좀더 일반적이고 어려운 상황들에서의 지능의 실증들이라는 (이러한 실증들이 포함하고 있는 진실의 핵심을 우리가 잘 이해하고는 있지만) 확신을 주지 못하는 그러한 과제들을 수행하는 많은 방식들을 우리는 알고 있다. 소어는 실제적인 과제들을, 그리고 사실상 다양한 실제적인 과제들을 다룰 수 있어야만 한다. R1-소어는 이러한 방향에 긍정적인 기여를 한다.
실제적 지능의 방향이지만 R1-소어와는 다소 다른 소어의 행동에 대한 또 하나의 예를 고려해 보자. 그 시스템은 설계자-소어 Designer-Soar (Steier, 1989) 라고 불리는 것이다. 그것의 과제는 알고리듬을 설계하는 것이다. 이것은 지적인 과제로, 컴퓨터 과학에서 상급학년의 코스에서 가르치는 것이다 (Sedgewick, 1983). 하나의 단순한 예시적 과제는 하나의 요소가 주어진 집합의 구성원인지를 알아내는 알고리듬을 설계하는 것이다. 조금 더 어려운 과제는 숫자의 집합을 오름차순으로 정렬하는 알고리듬을 설계하는 것이다. 즉 숫자 (5, 8, 6, 3, 7, 3, 2) 가 입력이라면, 정렬 알고리듬은 (2, 3, 3, 5, 6, 7, 8) 을 생성해야 한다. 문제 해결자에 대하여 그 과제는 이런 특정한 숫자들을 정렬하는 것이 아니고, 주어진 다른 숫자의 열을 정렬할 수 있는 것도 아니다. 그 과제는 어떠한 숫자 열이라도 정렬하는 알고리듬 —— 프로그램이나 절차의 본질적인 단계들 —— 을 찾는 것이다.
설계자-소어는 데이비드 스타이어 David Steier 의 연구이다. 그것은 알고리듬을 설계하는 두 개의 초기의 소어와는 다른 AI 시스템들에 그 뿌리를 두고 있다. 하나는 엘레인 칸트 Elaine Kant, 스타이어, 그리고 내가 몇 년 전에 개발한 Designer 였다 (Kant & Newell, 1983 ; Steier & Kant, 1985). 다른 하나는 더그 스미스 Doug Smith 에 의해 개발된 Cypress 였다 (Smith, 1985). 소어의 수정판은 그 시스템들 각각에 대해 만들어졌다 (Cypress-소어에 대해서는 Steier, 1987 을 보라). 현재의 설계자-소어 (Steier & Newell, 1988 ; Steier, 1989) 는 이러한 두 개의 시스템들의 많은 중요한 특질들을 혼합시킨 하나의 후속물이다. (주석 : 내가 윌리엄 제임스 강연을 한 1987 년 봄 나는 이러한 초기 시스템들을 논의했다. <현재의 설계자-소어는 1987 년 여름에 만들어진 것이다.>)
알고리듬 설계의 과제를 형식화하는 방법에 관해서 흥미로운 문제들이 있다. 첫 번째 문제는, 무엇이 희망되느냐이다. 실제적인 컴퓨터 프로그램과 대조적으로 알고리듬은 단지 수행되어야 하는 본질적 단계들을 제공한다. 알고리듬이 주어졌을 때, 프로그램은 특정한 프로그래밍 언어 (Lisp 또는 Pascal) 로 여전히 작성되어야 한다. <그러나 일반적인 계획이 이제는 가용적이다.> 그러므로 프로그래밍 과제는 잘 명세화된 희망되는 대상 (코드 code) 을 갖고 있는 반면, 알고리듬 설계는 그것을 갖고 있지 않다. 그러나 여전히 알고리듬은 어떤 표상으로 만들어져야만 한다. 그것이 어떤 것이어야 하는지에 대해서 컴퓨터과학에서는 합의가 없는데, 이는 대부분 희망되는 결과가 사실상 진행하는 방법에 관한 설계자 측의 지식이며 이것은 많은 다른 방식으로 표상될 수 있기 때문이다. 이 문제는 한 사람이 한 문단을 이해하기 위해 그것을 읽을 때, 희망되는 것이 무엇인가라는 것과 유사하다. 설계자-소어는 항상 매우 일반적인 기능적 연산들의 집합을 사용한다 : [생성하기 generate, 선택하기 select, 검사하다 test, 인출하기 retrieve, 저장하기 store (기억에 투입하기), 폐기하기 discard (그 항목을 무시하기), 적용하기 apply (연산), 그리고 알고리듬의 끝에 결과를 출력하기 return.] 알고리듬을 만든다는 것은 이러한 연산자들을 기초로 기술되는 절차를 만드는 것이다. 그림 19 는 숫자들의 집합에서 양수들의 부분집합을 찾기 위한 알고리듬 (부분집합-검사) 이다. 이것은 생각할 수 있는 알고리듬 설계의 가장 단순한 예이다.
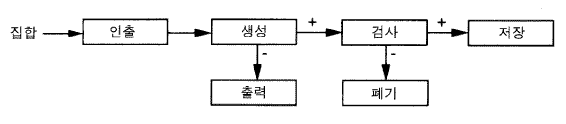
그림 19 부분집합-검사 알고리듬
두 번째 문제는 무엇이 주어졌는가 하는 문제이다. 이 문제는 좀더 심각하다. 사실상, 이 문제는 희망하는 결과가 명확하게 진술될 수 있는 프로그래밍이나 코딩의 가제에 대해서도 역시 문제가 된다. 한 사람이 프로그램을 구성할 때 주어진 것이 무엇인가? AI 와 이론적 컴퓨터 과학에서의 연구들은 이 점에 대해, 어떤 형식적 언어로 입력 / 출력의 명세화에서부터 입력 / 출력의 예들의 집합, 특정한 프로그램 흔적들 traces 의 집합, 좀더 효율적인 프로그램으로 변형되는 일반적인 프로그램에 이르기까지, 매우 다양하다. 주어진 것들의 각 유형은 다른 과제를 만들 게 된다.
하나의 중요한 구분은 설계자가 알고리듬이 만들어지는 대상, 즉 그 과정을 이미 기본적으로 이해하는가라는 점이다. 부분집합 검사가 무엇인지 모르고, 특정한 입력이 주어질 때 부분집합에 대해 검사하는 방법을 처음부터 모르면서 그 검사에 대한 알고리듬을 설계하는 사람은 없다. 알고리듬 설계자의 과제는 이 지식을 인지적 기술로서 단지 소유하는 것이 아니라 이 지식을 명시적 알고리듬으로 표현하는 것이다. 이러한 구분은 자동적 프로그래밍이나 알고리듬 발견에 관한 AI 의 연구들에서는 관찰되지 않는데, 이는 그 시스템들이 사전에 존재하는 실제적인 지식의 저장소로서 절대 생각될 수 없기 때문이다. 결과적으로, AI 시스템들은 사실상 두 가지 과제를 한다 —— 부분집합에 대한 검사를 하는 방법을 발견하고, 부분집합에 대한 검사를 하는 알고리듬을 발견한다. 소어는 부분집합을 검사하는 방법에 관한 지식을 이미 주어진 것으로 받아들인다. 이것은 연쇄들을 연산하기 위한 기본적인 연산자들의 집합과, 그리고 부분집합 검사를 하기 위해 연산자들을 선택하는 탐색통제를 갖고 있는 과제-영역 task-domain 문제공간으로 표현되다.
그러한 알고리듬을 설계하기 위해서 소어는 그것을 문제공간에서의 탐색으로 만들어야 한다. 소어는 연산들의 조건적 연쇄를 찾으려고 한다 (그림 19). 그러한 것을 찾는 것은 부분적 알고리듬들 —— 그림 19 의 조각들이나 부분들 —— 의 문제공간을 요구한다. 초기상태는 알고리듬이 없는 것 (알고리듬이 전혀 없는 것) 이고 희망하는 상태는 그림의 알고리듬 —— 한 집합에서 양수들의 부분집합을 찾는다고 검증된 —— 이다. 연산자들은 알고리듬의 부분들을 구성하고, 수정하고, 그리고 결합시킨다. Designer 와 Cypress 둘 다 그 과제를 이런 방식으로 형식화하며, 그리고 소어 시스템들도 그것들에 기초한다.
그러나, 또 하나의 임의선택이 있다. 이것은 알고리듬의 추상적 연산들 —— 생성하기, 검사하기, 그리고 정지시키기 rest —— 을 공간의 연산자들로 취급한다. 이 공간에서의 상태들은 부분적으로 검사된 항목들의 집합들이다. 초기 상태는 초기 집합이고 희망하는 상태는 완전히 검사된 집합이다. 만약 희망하는 상태를 생성하기 위해 연산자들의 연쇄가 초기상태에 적용될 수 있다면, 그 연쇄는 분명히 그 집합을 검사하는 방법을 제공한다. 만약 초기상태에서의 특정항목들 때문에 소어가 연산자들을 선택했다면, 소어는 단지 특정한 검사를 수행할 것이다. 그러나 상태들이 일반적인 항목들의 집합의 표상하고 소어가 여전히 그것을 검사할 수 있다면, 소어가 사용한 연산자들의 연쇄는 일반적인 알고리듬임에 틀림이 없을 것이다. 물론, 단순한 미리 정해진 연산자들의 연쇄는 충분치 않을 것이다. 거기에는 조건문들 conditionals 이 있어야만 하는데, 이것이 바로 알고리듬이 의미하는 것, 즉 이미 입력된 실제적인 자료들에 기초해 조건에 따른 단계들을 명세화하는 것이다. 사실상, 검사하기와 비교하기 compare 와 같은 일반적 연산자들은 항목들의 집합에 대해서는 실제 아무것도 하지 않고, 단지 그것들은 나중에 적용될 연산들을 결정하는 데 기초가 되는 것에 관한 정보를 획득한다. 그러므로 이 공간에서의 실제적인 상태들은 단지 부분적으로 검사된 항목들의 부분집합들이 아니다. <그것들은 부분집합에 관해 알려진 것에 대한 표상도 역시 갖고 있다. 즉 항목들에 그것들의 지위 또는 그것들에 대해 이미 수행되어진 연산자들에 관한 주장 —— 다음에 적용될 연산자를 결정하는 데 기초가 되는 지식 —— 들이 덧붙여진다.>
설계자-소어는 이 두 번째 임의선택을 사용한다. 그것은 기술된 것처럼 약간은 신비로운 듯 보이지만, 그것은 인간이나 AI 시스템 모두에 있어서 매우 일반적인 방략이다. 예를 들어, 많은 컴퓨터 프로그램들이 만들어진, 논리에서의 정리를 증명하는 것을 생각해 보라 (Loveland, 1978). 만약 과제가 증명을 찾는 것이라면, 작업이 이루어지는 자연스런 문제공간은 증명들의 문제 공간이다. 초기 상태는 증명이 없는 것이고 희망하는 상태는 완전히 문서화된 증명이다 —— Designer 와 Cypress 에 의해 사용된 문제공간과 매우 비슷한, 그러나 모든 정리 증명가들 theorem provers 은 거의 그렇게 하지 않는다. 그 대신, 그것들은 바로 두 번째 임의선택을 사용한다. 증명되어야 하는 정리에 도달하기 위해 그것들은 전제들 또는 공리로 시작하고, 증명되어질 정리에 도달하려는 시도로서 타당한 논리규칙들을 적용한다. (Resolution 과 같은 일명 반증-형식화들 refutation-formulations 이라고 불리는 것들은 원하는 정리보다는 모순을 찾으려 한다. <그러나 이러한 두 개의 다른 유형의 공식화들에 관한 한, 그것은 모두 동일한 것으로 귀결된다 (Loveland, 1978).> 그것들이 실제로 희망하는 것은 취해지는 단계들의 성공적인 연쇄이지 도달하게 되는 마지막 상태가 아니다. 바로 우리의 두 번째 임의선택처럼, 최종적 구조는 단순한 연쇄가 아니라 하나의 트리 또는 연결망이다. 나는 이것을 요소 전략 element strategy (Newell, 1983) 이라고 불렀는데, 이는 그것이 공간의 상태들을 요소들의 연쇄 또는 연결망이 아니라 요소들로 취급하기 때문이다.
|
dc 2. 당신의 문제가 무엇인가? 부분집합 명세화는 : 3. 알고리듬에 대한 입력은 정수들의 집합이고, 출력은 구성요소들이 모두 양수들인 입력집합의 가장 큰 부분집합이다. 17. 하나의 일반적 해결책은 : [기호적 실행] 21. 입력을 인출 [명세화 참조] 103. 정수들의 집합 106. 다음에 할 것은? [동점에 의한 막다른 상태] 111. 이것을 시도해 보자 : [평가] 112. 그 집합에서 하나의 정수를 생성 118. 그것이 출력집합의 구성원인지 검사 [명세화 참조] 158. 그 계획은 좋아 보인다 160. 그 집합에서 하나의 정수를 생성 [기호적 실행] 162. 그것이 출력집합의 구성원인지 검사 172. 그러나 이 검사를 어떻게 구현하는가? 173. 어떤 예시적인 입력에 그것을 실행하라 [검사-사례 실행] 177. 입력을 인출 250. 구성요소로 1, 0 을 갖는 크기가 2 인 하나의 집합 252. 그 집합에서 하나의 정수를 생성 261. 항목들을 생성하는 순서는 임의적이다 261. 생성된 항목의 값은 1 이다 266. 그것이 출력집합의 구성원인지 검사 277. 그것이 양수라는 것에 대한 검사로서 구현 [영역에서의 검사] 278. 그 검사는 참을 출력 280. 그 항목을 출력에 저장 301. 다시 하라 [검사-사례 실행] 302. 입력을 인출 303. 구성요소로 1, 0 을 갖는 크기가 2 인 하나의 집합 305. 그 집합에서 하나의 정수를 생성 305. 항목들을 생성하는 순서는 임의적이다 313. 생성된 항목의 값은 0 이다 317. 그것이 출력집합의 구성원인지 검사 317. 그것이 양수라는 것에 대한 검사로서 구현 [영역에서의 검사] 328. 그 검사는 거짓을 복귀 330. 그 항목을 폐기 331. 다시 하라 [검사-사례 실행] 332. 입력을 인출 333. 구성요소로 1, 0 을 갖는 크기가 2 인 하나의 집합 335. 그 집합에서 하나의 정수를 생성 335. 항목들을 생성하는 순서는 임의적이다 335. 생성할 항목이 남아 있지 않다 336. 그 결과를 출력 336. 구성요소 1 을 갖고 있는 하나의 집합 337. 그리고 우리는 그 답을 가졌다 343. 그러나 나는 모든 사례들을 가졌는가? [검사-사례 실행] 349. 우리는 단계 2 에서 생성자가 구성요소들을 생성할 수 있는 경우와 그것이 종결되는 경우의 사례들을 살펴보았다. 351. 우리는 출력집합의 구성원에 대한 검사가 참을 출력하는 경우와 거짓을 출력하는 경우의 사례들을 살펴보았다 354. 모든 사례들이 고려된 것처럼 보인다 357. 그러므로 우리는 이 문제를 완성한다 358. 목표인 설계-알고리듬이 달성되었다 |
그림 20 부분집합 검사에서의 설계자-소어의 상위-수준 흔적
그림 20 은 부분집합 검사에 대한 설계자-소어의 상위수준에서의 흔적을 보여준다. 설계자-소어는 여러 가지 결정적인 것을 할 때는 언제나 미리 정해진 메시지를 출력한다. 많은 정보가 은폐되었지만, 그것은 설계자-소어가 문제해결을 하는 방식에 우리가 초점을 맞출 수 있게 해준다. 설계자-소어는 그 문제를 요구하고 단순히 그것을 출력함으로써 시작한다 (결정주기 2, 또는 dc2). 그것은 처음에 그 문제를 완전히 기호적으로 처리하려고, 즉 [기호적 입력을 가정] 하고 그것의 일반적 연산자들에 의해 그것에 연산을 가하려는 시도를 한다. 그것은 입력집합을 어떤 식으로든 인출하고, 그런 후, 다음에 할 것을 선택하기 위해 충분하게 명세화 된 것이 없기 때문에 움직이지 못하게 된다. 인출하기는 일반화된 기능적 연산자들 중의 하나이고 그런 것들은 알고리듬의 구성요소들이 될 것이므로, 인출하기는 두껍게 인쇄되어 있다. 어떤 대안이 선택될 것인지를 평가하는 과정에서, 그것은 생성하기와 그런 후 검사하기 (dc112, dc118) 를 고려하면, 이것은 그 명세화를 만족시키는 것으로 나타난다. 이 모든 것은 입력에 대하여 모든 것이 기호적으로 이루어지며, 그 입력에 대해 그것은 단지 명세화가 말해 준 것, 즉 [그것이 정수들의 집합] 이라는 것만을 알고 있다. 그것은 생성하기와 검사하기의 값들을 제거하고 단지 그것들의 입력과 출력의 유형만을 고려함으로써 어떠한 실제적인 계산을 수행하는 것을 회피한다 (Unruh, Rosenbloom, & Laird, 1987). 이러한 추상적 평가처리가 생성하는 것은 하나의 계획 plan 인데, 이는 소어가 그것이 상황을 추상화했고 이제는 완전히 상세하게 그것을 행해야만 한다는 것을 알고 있기 때문이다 (dc158).
평가로부터 돌아와서, 소어는 집합으로부터 하나의 정수를 생성한 다음, 그것을 여전히 기호적으로 검사한다. 이제 그것은 실제적으로 그 검사를 수행해야만 한다. 기호적 요소들의 값에 대해 특별히 알려진 것도 없고, 그 검사에 대해서도 특별히 알려진 것이 없다. 소어는 이 문제를 인식하고 (dc172), 하나의 특정한 사례를 시도해야 한다는 것을 안다 (dc173). 그것은 입력을 인출함으로써 다시 시작한다 (dc177). 그러나 이번에는 그것은 악화되지 않는 가장 단순한 사례의 발견법을 이용해 소어는 하나의 사례를 결정한다 —— 요소 0 과 1 을 갖고 있는 크기가 2 (크기가 1이 아니고) 인 하나의 집합이 정수들의 시작으로부터 선택된다 (dc250). 이제 그것이 하나의 요소를 생성할 때, 그것은 실제적으로 하나를 선택하고 그것은 1 로 밝혀진다 (dc261). 그것이 검사를 그 요소에 적용할 때, 그것은 명세화로부터 그 검사가 요소는 양수이다라는 것을 검사해야 한다는 것을 알 수 있다. 소어는 이 검사를 그것의 영역지식으로부터 알고 있기 때문에, 그것은 영역검사를 갖고 있는 알고리듬에서 기능적 검사를 구현할 수 있다 (dc277). 그러나 더욱 그것은 그 검사의 결과가 진실임을 안다 (dc278). 그 시점에 그것은 명세화로부터 그 요소를 출력집합에 저장할 필요가 있음을 알 수 있다 (dc280). 이러한 저장 연산을 단지 생성하기와 검사하기만 있는 그 계획에는 존재하지 않았는데, 이는 실제적인 다음 단계를 결정하기 위해 평가가 미리 앞을 내다볼 것을 요구하지 않기 때문이다.
저장 연산자는 그 계산을 완성한다. 그러나 검사사례들을 사용하는 것에 관한 지식은 단일한 검사사례가 완전한 알고리듬을 확립할 수 없다는 사실을 포함한다. 그러므로 소어는 모든 것들을 다시 시작한다 (dc301). 그것은 입력을 인출하고, 동일한 검사사례를 얻고, 그리고 하나의 요소를 생성한다. 검사사례를 사용하는 것에 관한 지식의 추가적인 부분은 다른 선택이 가능하다면 그것을 선택하는 것이므로, 그것은 항목 0 을 (처음에 보았던 1 에 반대되는 것으로) 생성한다. 소어는 소속성 membership 검사를 적용하고 거짓임을 얻었다 (0 은 양의 정수가 아니다). 그것은 명세서로부터 이 항목은 결과의 부분이 아니고, 그렇기 때문에 폐기되어야 하는 것을 알 수 있다. 이것은 하나의 기호적 실행과 두 개의 검사-사례 실행들을 포함한, 과제를 통한 세 번째 실행을 종료한다. 소어는 동일한 경로 —— 인출, 생성, 검사 —— 를 반복적으로 따라가는데, 이는 그것이 따라야 할 자료구조를 갖고 있기 때문이 아니라 그렇게 하는 동안에 소어 스스로 탐색통제를 배우기 때문이다. 이것은 그것이 최초에 발전시킨 계획에 있어서 조차도 사실이며, 계획은 서술적 declarative 계획으로서가 아니라 어떤 조건들 아래에서 어떤 단계들이 선호되는 것으로서 기억된다.
소어는 입력을 인출하고 요소를 생성 (dc301 에서 dc305 까지) 하는 행동을 반복한다 (dc331 에서 dc335 까지). 그것은 입력집합의 모든 구성원들을 살펴보았기 때문에 (두 경우 모두), 결과를 출력한다 (dc336 에서 dc337 까지). 이것은 그 계산을 완성하지만, 소어는 알고리듬을 획득하기 위해서 이 계산을 수행했다. 후자에 대한 준거는 존재하는 알고리듬에서 분기가 발생할 수 있는 모든 잠재적 장소들이 조사되었는가이다. 그것은 이것을 하는 방법을 알고 (dc343), 그렇게 하고 (dc349 와 dc351), 그리고 더 검토할 것이 없다고 결론을 내린다 (dc354). 그러므로 그것은 알고리듬이 설계되었다고 결론을 내린다 (dc358). 일반적으로 특정한 사례들의 한정적인 집합을 검토함으로써 하나의 알고리듬을 검증할 수 없기 때문에, 이것은 그 알고리듬의 옳고 바름을 증명하는 것은 아니다.
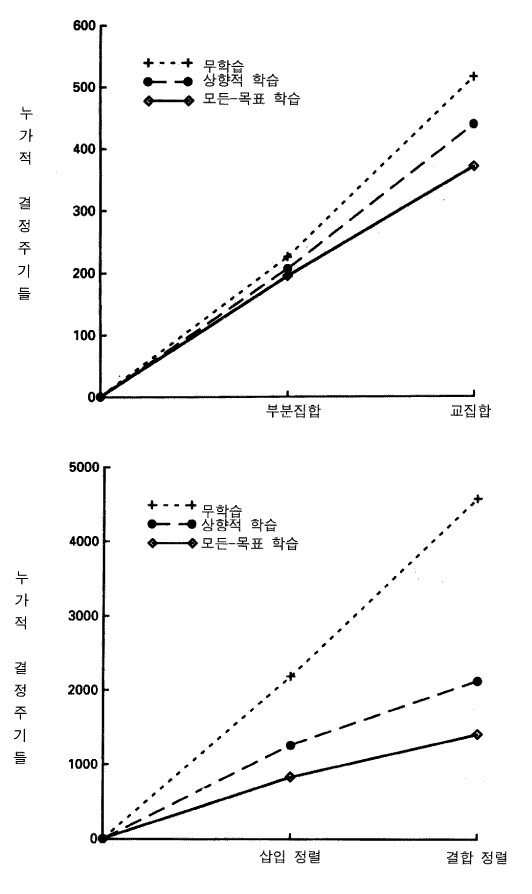
그림 21 설계자-소어에서의 학습과 전이
우리가 말했던 것처럼, 소어는 그것이 하는 모든 것에 대해 학습한다. 그러므로 우리는 그것이 알고리듬을 설계하려고 할 때, 무언가 학습했을 거라는 기대를 할 것이다. 그림 21 은 두 쌍의 알고리듬에 관한 요약 그림을 보여준다 [단순한 알고리듬의 한 쌍은 한 집단에서 양수인 요소들의 부분집합을 찾는 것 (이것은 예시를 위해 사용되었던 것) 과 두 집합의 교집합 intersection 을 찾는 것이며, 약간 더 복잡한 것들의 한 쌍은 결합정렬 merge sort 과 삽입정렬 insertion sort 이다] . 각각의 경우에서, 쌍 중 하나가 먼저 수행되고 다음 것은 나중에 수행된다. 각쌍에 대해 상위 선은 학습이 없는 행동 (전체 결정주기) 이고 두 개의 하위 선들은 학습을 갖고 있는 행동이다.
하위의 학습선 (모든 목표들) 을 먼저 생각해 보자. 두 쌍 모두 동일한 이야기를 한다. 각 과제의 처음에서부터 끝날 때까지 시행 내 학습이 있다. 또한 쌍의 첫 번째 과제에서 두 번째 과제로의 시행 간 학습도 있다. 이것은 정렬 루틴들을 보여주는 하단의 도표에서 가장 잘 나타난다. 만약 삽입 정렬에서 결합 정렬로의 전이가 없다면, 결합 정렬에 대해 단지 시행 내 전이만이 존재할 것이다. 무학습 곡선이 결합정렬이나 삽입정렬 모두에서 거의 비슷한 기울기를 보인다는 사실과 일치되게, 결합정렬은 삽입정렬에서의 학습곡선과 유사한 기울기의 학습곡선을 만들어야만 한다. 그러나 결합정렬에서의 학습곡선은 사실상 더 평평하므로 시행 간 전이의 효과를 보여준다. 이 효과는 결합정렬에서의 시행 내 효과가 더 크기 때문이라고 생각할 수도 있다 —— 결국 시행 내 전이의 양은 과제에 따라 변화한다. 그러나 단독으로 실행된 결합정렬에서의 시행 내 전이의 양 (적절한 통제) 에 대한 직접적인 검토는 그 효과가 실제적인 것임을 보여준다.
두 번째 (상향 bottom up) 학습곡선은 만약 목표가 막다른 상태를 갖고 있지 않은 경우 —— 즉 목표가 최저수준에 있을 경우 —— 에만 소어가 청크를 만들 때 어떠한 일이 발생하는지를 보여준다. 곡선이 더 높이 있다는 사실에서 보듯 학습은 덜 발생한다. 그러나 그것을 제외하고는 그 이야기는 동일하다. 만약 과제가 상향적 학습을 갖고 반복된다면, 궁극적으로 그것은 단일한 시행에서 모든 막다른 상태에 대한 학습처럼 동일한 장소에 도달할 것이다.
지능을 요구하는 두 개의 다른 과제에서 소어의 행동에 대한 예들을 살펴보았다. 첫 번째는 Vax 를 구성하는 것으로 지식-집약적이지만 어느 정도는 일상적인 과제이다. 두 번째 것은 알고리듬을 설계하는 것으로 상당한 지식을 역시 요구하고 지능적으로 더욱 어려운 것이다. 이 두 과제에 대응되는 시스템들, R1-소어와 설계자-소어는 소어 구성, 그리고 여러 가지의 문제 공간들과 탐색 통제로 이루어진다. 이 두 수정판이 합쳐져서 두 과제에 관한 지식을 갖고 있는 단일한 소어 시스템을 만든다고 생각해야 한다. 그것들은 단순히 다른 시기에, 다른 연구자들에 의해서 연구되어 왔기 때문에 구분되는 것이다. 사실상, 설계자-소어에 의한 정렬과 집합의 두 영역에 관한 지식은 그렇게 결합된 시스템의 한 예이다. 두 개의 알고리듬 설계과제들 사이의 공유성은 물론 존재한다. 그것들은 알고리듬 공간과 같은 동일한 공간들의 일부를 사용한다. 그러나 그것들의 공유성에 대한 진정한 측정은 한 과제에서 다른 과제로의 학습의 전이일 수 있는데, 이것은 이 경우 거의 존재하지 않는다 (단지 1 %).
우리는 통합인지이론에 대한 우리의 본보기로서의 소어가 인간이 지능적이라는 것을 예측한다는 증거를 제공하기 위해 이 두 과제들을 사용했다. 물론 구성 그 자체는 지능을 보여주지 않는다. 그것에 문제 공간들과 그것들과 연합된 탐색 통제에 표상된 지식이 덧붙여져야만 한다. 그것이 바로 소어에게 적절한 문제공간들을 제공함으로써 우리가 한 것이다.
하나 또는 두 마리의 제비로는 여름을 만들지는 못한다. 그러므로 소어에 의해 수행된 것들의 요약을 제공하는 것은 유용하다. 이들 각각은 소어가 일반적 지능 행위를 할 수 있다는 증거를 구체화하는 것을 도와준다.
첫째 소어는 AI 에서 일반적인 작은 문제들을 거의 모두 수행한다. <하노이 탑, 선교사와 식인종, 1 ~ 8 가지의 숫자판 배열하기 Eight Puzzle 등.> 이러한 과제를 수행하는데, 그것은 언덕 오르기와 수단-목표 분석과 같이 명칭을 가질 정도로 AI 에서 충분히 중요한 거의 모든 방법들을 보여준다. 그것은 동일한 과제에서 다중의 방법을 자주 사용하고, 또 다중의 과제에서 동일한 방법도 자주 사용한다 —— 바로 기대되는 것처럼. 소어는 Dypar-소어 (Boggs & Carbonell, 1983) 와 같은 분석의 형식, 그리고 Version spaces (Nitchell, 1978) 와 같은 개념 학습을 위한 방식처럼 몇 가지의 대형과제들도 수행했다. 논의했던 R1-소어와 설계자-소어 이외에도 네오마이신 Neomycin-소어 (Washington & Rosenbloom, 1988) 가 있다. 마이신 Mycin 은 의학 진료를 수행하는 시스템이다. <이것은 최초의 전문가 시스템들 중의 하나이다 (Shortliffe, 1976).> 빌 클랜시 Bill Clancey 는 하나의 지능적인 교수 맥락에서 마이신에서의 지식을 사용하기 위하여, 네오마이신으로 불리는 더욱 합리화된 수정판을 만들었다 (Clancey & Letsinger, 1981). 네오마이신-소어는 정확히 동일한 지식을 갖고 동일한 네오마이신의 과제를 수행하도록 함으로써 R1-소어에서처럼 이 두 시스템의 비교로부터 우리는 가능한 한 많은 것들을 배울 수 있다.
학습에 관하여, 소어는 그것이 수행한 모든 것에서 학습하기 때문에, 특정한 과제에 의한 요약은 의미가 없다. 그러나 그것은 자신의 내적 구조의 다른 구성 요소들을 학습한다 —— 연산자 선택, 탐색 통제, 연산자 실행, 새로운 연산자, 문제 공간. 소어는 설명-기반적 일반화 explanation-based generalization (Mitchell, Keller, & Kedar-Cabelli, 1986) 의 형식을 제공하는데, 이것은 소어가 단일한 사례들을 검토하고, 행동을 자세히 분석하고, 그리고 나중의 문제해결에 유용할 수 있는 어떤 발견법들을 그 사례에서 도출하기 위해 그 영역의 기초 이론을 사용함으로써 학습함을 의미한다 (Rosenbloom & Laird, 1986). 소어는 다른 유형의 학습도 하지만 그것들은 학습, 기억, 그리고 기술에 관한 6 장에서 더 많이 논의될 것이다. 소어는 역시 청킹을 사용해서 단순한 형태의 추상화 계획 abstraction planning 을 한다 (Unruh, Rosenbloom, & Laird, 1987 : Unrub & Rosenbloom, 1989). 연산자를 평가하는 데 있어서, 그것은 동점에 의한 막다른 상태를 해결함에 따라 연산자들이 적용되는 것을 막는 상황의 여러 가지 측면들을 제거함으로써, 룩어헤드 평가가 진행되도록 허용한다. 소어는 그렇게 진행해 (물론, 자동적으로 소어는 항상 청킹을 하기 때문에) 청크들을 만든다. 이러한 청크들은 선택하는 것을 도와주기 위해 완전히 자세한 상황으로 전이될 수 있다. 추상화 계획의 일반적 형태과 비교해서 (Sacerdoti, 1974), 소어는 계획을 한다는 숙고적 결정들을 하는 것은 아니다 —— 그것은 단지 추상화한다는 결정에 의해서 자동적으로 계획한다. 더 나아가, 그것은 계획을 구현한다는 숙고적 결정들을 하는 것도 아니다 —— 청크들은 적절한 맥락에서 단순히 점화된다.
제약 편집 constraint compilation 을 위해 소어를 사용하려는 노력은 하나의 흥미로운 점을 제공한다. 최근에, 제약 전파 constraint propagation 를 사용하는 프로그래밍 언어들이 개발되었다. 이 연구의 많은 것들은 MIT 의 AI 연구실의 제럴드 수스맨 Gerald Sussman 에 의해 개척되었고, 참고문헌 중 특히 유용한 것은 그 집단의 가이 스틸러 Guy Steele 의 학위논문이다 (Steele, 1980). 프로그래밍 언어의 관점에서 보면, 사용자는 단순히 제약들의 집합을 적어두고, 시스템은 그 제약들을 만족시키는 변수들의 값을 생성하기 위해 코드를 편집한다. 소어에게는 제약 전파에 관한 지식이 주어질 수 있으므로 제약 전파 문제를 해결할 수 있다. (이것은 올린 시버스 Olin Shivers 의 연구이다.) 만약 그 문제가 올바른 형식화를 갖고 접근되다면, 소어가 만든 청크들은 의도적으로 부호화된 제약 편집기와 동일한 것이다. 즉 만약 산출들이 편집기가 작동하는 표적 언어로 된 것이라 취급한다면 제약 문제를 해결하는 경험이 주어질 때 발생하는 청킹에 의해, 생성되는 그 산출들은 그러한 편집기에 의해서 생성되어야 하는 바로 그 산출들이다. 요점은 청킹이 경험을 미래의 능력으로 변화시키는 강력하고도 자연스러운 방법으로서 나타난다는 것이다.
|
많은, 작은, 그리고 적당한 과제들 (21), 많은 방법들 (19) 1-8 까지 숫자판 배열하기, 하노이 탑, 왈츠 명명 Dypar (NL 분석), Version spaces, 해결책 정리 증명 생성과 검사, 언덕 오르기, 수단-목표 분석 제약 전파
더 큰 과제들 R1-소어 : 3300 규칙 산업용 전문가 시스템 (25%) 설계자-소어 : 알고리듬 발견 (Cypress-소어도 역시) 네오마이신-소어 : 마이신의 개정 Merl-소어 : 교체용 방풍 유리의 생산 계획
학습 (청킹) 그것이 수행하는 모든 과제들에서의 학습한다 • 탐색 통제, 연산자들, 문제 공간들을 학습한다 • 연습을 통해서 향상된다, 다른 과제들로 전이된다 설명-기반적 일반화 추상화 계획하기 (청킹에 의해서) 제약 번역 (청킹에 의해서)
외부 세계와의 상호작용 외부 공간들로부터 새로운 과제들을 획득한다 (청킹에 의해서) 안내를 받는다 (청킹에 의해서) Robo-소어 : 시각 시스템을 갖고 있는 퓨마 팔의 단순한 로봇 통제자 |
그림 22 소어에 의해서 달성된 과제들의 요약
그림 22 의 마지막 항목은 외부세계와 상호작용하는 것인데, 우리는 그것을 얼버무려왔다 —— 어떻게 소어가 과제를 획득하는가, 어떻게 그것이 세계에 영향을 미치는가, 어떻게 그것이 피드백을 받는가 등. 전체 인지 시스템을 기술할 때 (그림 15), 우리는 외부 세계와의 상호작용을 위한 기초적 구성을 논의했다. 그러나 문제 공간들에서 수집되는 상호작용을 달성하는 방법에 관한 실제적인 지식이 역시 존재해야 한다. 소어는 선택을 하는 데 도움을 줄 외부 사용자에게 어떤 정보를 요구하고, 청킹에 의해서 그 정보를 자신에게 포함시킨다. 청킹을 사용함으로써, 외부의 안내를 받을 수 있다 (Golding, Rosenbloom, & Laird, 1987). TAQ-소어라는 소어의 수정판이 있는데, 이것은 과제에 관한 외부의 명세화를 받아서 그 과제를 수행하는 데 요구되는 내적인 문제 공간들을 만든다 (Yost, 1988). 그것은 입력 언어를 해석하고, 그 표현이 의미하는 것에 대한 내적 표상을 만들고, 그리고 해석에 의해 그 과제를 실행함으로써, 어떤 사람이 산출들을 직접 작성하는 것처럼, 이러한 공간들을 구현하는 청크들을 생성한다. (이것이 대부분의 소어 시스템들이 지금까지 구성된 방식이다.) 우리는 TAQ 에 관해 나중에 더 살펴볼 것이다. 마지막으로, 최근의 소어 수정판인, Robo-소어는 TV 카메라를 통해 외부의 블록 집합을 보고 블록들을 이동시키기 위해 퓨마 팔 Puma arm 에게 명령을 하는 단순한 로봇 공학적 과제를 수행한다 (Laird, Yager, Tuck & Hucka, 1989). 시각과 로봇-팔 소프트웨어는 작업기억을 통해 중앙인지와 의사소통을 하는 P 와 M 모듈이다 (그림 15). 이러한 시스템들이 우리에게 보여주는 주요 요점은 외부세계와 상호작용하는 것은, 소어가 다른 과제들을 수행하는 것처럼 소어가 수행하는 것이라는 점이다.
그러므로 소어가 지능적으로 행동을 할 수 있다는 많은 증거가 있다. 그 증거는 현재 AI 에서 사용할 수 있는 증거들만큼 좋은 것인데, 이는 소어가 최고 수준의 AI 시스템이기 때문이다. 사실상, 소어는 학습과 문제해결을 통합하려는 새로운 일을 하고 있다. 그러나 AI 가 지능의 기제에 대해 밝혀내야 할 것들은 많이 있으며, 복잡하고 어려운 과제들에서 지능적인 행위를 생성하기 위해서 그것들이 어떻게 결합되는지에 대해 AI 가 명시해야만 할 것들도 역시 많이 있다. 그러므로 소어가 지능을 보일 수 있다는 증명은 단지 현재의 AI 수준만큼만 가치가 있다. 사실상, 이 질문은 AI 가 발전할수록 반복해서 물어야 할 것들이다. —— 지능의 본질에 관한 발전된 관점에 따라 소어가 인간이 지능적임을 예측한다고 우리가 주장할 수 있기 위해서는 소어와 AI 가 보조를 같이 해야만 한다.
지능을 위한 하나의 구성으로서의 소어를 이해하기 위한 지금까지의 우리의 기법은 과제들의 표본에서 그것의 행동을 살펴보는 것이었다. 2 장에서 우리는 지능이란 지식수준 시스템에 대한 기호수준 시스템의 추정의 정도라는 정의에 도달했다. 그러므로 우리는 소어가 지식수준 시스템을 얼마나 잘 추정하는가 하는 문제도 역시 검토해야 한다.
특정한 목표들, 특정한 행위들, 그리고 행위와 목표를 연결시키는 특정한 지식들과 다양한 형태의 관계를 갖고 있는 지식 시스템의 정의는 추정의 정도에 대해 벡터와 같은 <하나의 숫자 또는 숫자들의 고정된 벡터와 같은> 일반적인 척도법은 존재할 수 없음을 보여준다. 그러나 소어에서의 기제들은 그것들이 소어를 지식수준 시스템에 얼마나 가깝게 만드는가, 아니면 반대로 지식수준 시스템으로 가지 못하도록 막는가를 알아보기 위해 검토될 수 있다.
처음부터 소어는 계산적으로 보편적인 것이다. 이것은 분명 필수적인 특성이지만 보편적이라는 것 이외의 점에서는 일반적 지능의 유용한 모형이라고 볼 수 없는 많은 시스템들이 공유하는 것이기 때문에, 유일한 특성이라고 할 수는 없다. 그림 1-7 이 명확히 보여주듯이, 보편성은 유연성과 기호적 능력 이외의 제약들을 나타내지 않는다. 특히, 그것은 실시간 제약을 언급하지 않는다. 그러나 산출 시스템들은 실시간 제약을 다루려는 직접적인 시도이다. 그것들은 소어를 될 수 있는 한 빨리 그것의 모든 정보를 끌어내려고 시도하는 재인문제의 해결자로 만든다. 청킹은 더 많은 지식을 재인으로 지속적으로 변환시킴으로써 실시간 제약을 이루려는 그러한 시도의 일부이다. 그것은 모든 상황에서 적용 가능하다. <이러한 유연성은 문제 공간들과 막다른 상태의 획일적인 사용으로부터 나오며, 이것은 지식수준을 추정하기 위한 필수적인 조건이다.>
갈등해소를 위한 고정적 기제의 결여는 지식수준을 추정하는 것과 밀접한 관계가 있다. 그것의 장점은 소어가 폐기한 Ops5 의 갈등해소 방법을 생각해 보는 것으로 알 수 있다. Ops5 의 갈등해소는 고정적 기제인데, 그것은 어떤 산출들이 점화되는지 언제나 통제하고, 다만 고정된 지식만을 갖고 있고 (좀더 최근의 요소들을 실례화하는 산출을 선호한다, 다른 것들의 특수한 사례인 산출을 선호한다), 그리고 그것의 지식이 부적합할 때, 그것은 아무 도움도 될 수 없다. 그러나 그것의 지식은 단지 발견법적이고, 그러므로 그것이 실패할 때 (그것이 어떤 상황에 있어야만 할 때처럼), 소어는 그 지식이 시스템의 다른 곳에 부호화되어 있을 때조차 지식 시스템처럼 작동할 수 없다. 소어는 그러한 고정적인 갈등해소 기제를 폐기하고, 지식수준을 더욱더 가깝게 추정하는 방향으로 자유롭게 움직인다. 물론, 그것은 갈등해소를 포기한 것은 아니다. 소어의 결정구조가 바로 갈등해소 기제이다. 막다른 상태가 갈등이며, 하위 목표를 설정하는 것이 갈등해소 과정을 초기화시킨다. 소어의 모든 지식과 문제해결이 갈등을 해결하기 위해 사용될 수 있기 때문에 하위 목표를 설정하는 것은 고정된 기제를 점화시키는 것과는 다른 것이다.
이 논의는 지식수준 시스템에 도달하는 것에 대한 주요한 준거를 보여준다. <함정-상태 trap-state 기제들은 허용되지 않는다.> 국소적이고 (시스템의 작은 지역에 포함되어 있는), 그것의 결과가 받아들여져야 하는 기제를 시스템이 갖추고 있을 때에는 언제나, 그 시스템과 지식 수준 사이에 일정한 격차가 만들어진다. 이는 기제 그 자체는 (가정에 의해서) 단지 유한한 지식의 출처일 수 있기 때문이다. <그리고 그 지식이 실패할 때 (만약 과제들이 충분히 다양하다면, 실패할 수밖에 없는 것처럼), (역시 가정에 의해서) 도움을 받을 곳이 없다.> 그러므로 지식이 시스템의 다른 곳에 존재할 때 조차 그 시스템은 자신의 지식상태에서 빠져나가지 못하게 된다. 우리의 예는 고정된 갈등해소였지만, 연산자 선택을 수행하거나 연산자들이 적용되는 순서를 결정하는 고정된 Lisp 기능들과 같은 다른 것들도 많이 있다.
결정과정에서 산출들은 단일한 주기만 취하거나 고정된 수의 주기 후에 중단되는 것이 아닌, 정지상태에 도달할 때까지 실행되는 것이 허용된다. 이러한 설계적인 특징은 즉시 사용가능한 모든 정보를 얻는다는 것에 대한 명확한 반응이다. 막다른 상태는 시스템이 그것의 모든 지식을 사용하지 않고 작동되는 것을 방지하기 위한 하나의 장치이다. 그것들은 곧 바로 사용할 수 있는 지식이 충분하지 않다는 것을 탐지하고, 그러므로 시스템은 기호적 연산자들을 통해 (즉 숙고를 통해) 가용적인 다른 지식을 축축하려는 시도에 계속해서 개방적으로 유도하는 장치이다. 그것들은 산출 시스템 그 자체가 함정-상태 기제가 되는 것을 방지한다. 이러한 두 개의 기제들은 소어에서 가용적인 모든 지식들이 사용된다고 보장할 수는 없지만, 단지 지식을 제외시키는 어떤 국소적 기제도 없다는 것을 보장한다.
요약해서 정리하면 특히 완전성과 실시간 제약들을 포함하는 관점으로 확장될 때에, 소어의 기제들은 시스템을 지식수준 시스템에 가깝게 만드는 데 그것들이 특수한 기능적 공헌을 한다는 관점에서 고려될 수 있다.
이 논의가 그린 그림은 올바른 방향으로 계속 움직이려는 하나의 시스템에 대한 것이다. 우리는 어떤 형태의 시스템이 실제로 지식과 목표들의 어떠한 합당하고 풍부한 집합을 포함하는 지식수준 시스템이 될 수 있을지 모른다. 그러므로 소어에 함정-상태 기제들이 존재하지 않는다는 어떤 증거도 갖고 있지 않다. 사실상, 청킹은 산출들을 영구적으로 더하기 때문에, 나쁜 청크들의 영향 아래에서 소어의 행동은 어떤 형태의 함정상태를 구성할 수도 있다. 더구나 이러한 분석은 수렴의 속도에 대한, 또는 더 빠르고 더 획일적으로 수렴될 수 있는 대안적인 기제들과 배열들에 대한 정보를 제공하지는 않는다.
지식수준 추정과의 관계가 불명확한 소어의 측면들도 있다. 예를 들면, 소어의 지식은 문제 공간들의 하나의 커다란 집합에 존재한다. 이러한 지식이 공간들 간에 어떻게 공유되는가? 또한 기억-자원 공유에 대해서는 어떠한가? 많은 공간들이 본질적으로 동일한 지식을 갖고 있기 때문에 실재로 중복적인 코딩이 존재하는가? 문제 공간들 간의 지식의 전이는 관련되어 있기는 해도 미해결의 문제이다. 청크들의 암묵적 일반화에서 보았듯이, 소어에서의 청킹은 전이 기제이다. 아마도, 우리가 찾으려고 한다면, 완전한 답이 청킹 기제 안에 이미 포함되어 있을지도 모른다. 청킹의 보편성에 대해서는 어떤가? 그것이 어느 정도로 확장되는가? 만약 다른 학습 기제들이 필요해진다면, 현 상태의 소어는 적응할 수 없는 환경을 갖고 있음이 확실하다. 청킹의 보편성에 대한 이런 문제 —— 소어에서 모든 학습에 대한 청킹의 충분성 —— 는 기계-학습 분야에서 논쟁을 일으키는 문제이다. 기계학습에서의 많은 과학자들은 이 가설은 설득력이 없다고 믿지만, 소어를 만든 우리는 이 가설이 유망한 것이라고 믿는다.
이제 우리는 소어를 인간 인지구성에 대응시킬 필요가 있다. 친숙한 공리적 관점에 따르면, 이론은 그것이 기술하는 영역과는 독립적인 추상적 기호 구조로서 존재한다. 그것은 확인 identification 과정의 한 집합에 의해 완성될 필요가 있고, 그러한 확인 과정들이 발생하는 많은 방법들이 있을 수 있다. 사실 인지분야에서의 오랜 관행은 일반적으로 인지이론들을 그것들의 중립적인 실현과의 관계에서 비교적 자율적인 것으로 취급해왔다. 아무튼 AI 에 뿌리를 둔 독특한 시스템으로 소어를 기술하는 것은 소어 구성의 특징을 인간 인지의 특징과 관련시킬 필요성을 만든다.
지금까지의 발전으로 볼 때, 정확히 대응이 어떻게 이루어지는지를 말하는 것은 독자에게는 단순한 연습일 것이다. 사실상, 대응은 단지 한 가지로만 가능하다. 그림 3-9 에 제시된 인지의 4 가지 수준들은 그 표적을 제공한다. 이 장에서 기술된 소어의 구조를 볼 때, 우리는 그림 23 에 제시된 대응을 하도록 강요된다. 우리는 인간 인지 구조의 분석에서 나온 용어와 소어로부터 나온 용어가 동일할 때라도 구분할 필요가 있다. <그래서 나는 필요하면 용어나 구절 앞에 소어를 덧붙일 것이다> —— 예를 들면, 소어의 장기기억 대 인간장기기억.
|
소어 |
인간 인지 구성 |
특성들 |
|
산출들 |
기호 시스템 • LTM 에 접근 • LTM 으로부터 인출 |
~~10 ms 수준 재인 시스템 (내용 주소화) 병렬 연산 불수의적 개별적 점화들을 자각 못함 지속기간 : 복잡성에 의존 (Ops5 보다 더 단순한 대응) |
|
결정 주기 |
가장 작은 숙고 행위 • 행위를 위한 지식을 축적하고 그 다음 결정함 |
~~100 ms 수준 순차적 연산의 최소 단위 불수의적 (망라적) 산출물은 자각 그러나 과정은 자각 못함 지속시간 : 가장 긴 산출 연쇄 (정지상태까지) |
|
초보적 연산들 |
단순한 선택적 연산들 |
~~1 초 수준 순차적 연산들 초보적 관찰 가능한 사고 행위들 지속기간 : 결정-주기 연쇄 (최소 2 개의 결정 주기들) 목표-지향적 |
|
목표 달성들 |
완전한 문제 공간들 |
~~10 초 수준 목표 달성의 최소 단위 비초보적 연산들의 최소 단위 학습 (청크) 의 최소 단위 |
그림 23 인간 인지 구성에 대한 소어의 기본적 대응
산출들은 기호 구조들과 일치한다. 산출들을 소어의 작업 기억에 있는 요소들에 대응시키는 것은 원거리 구조에 접근하는 과정과 일치한다. 그러므로 인지수준의 기초에서, 그리고 모든 장기기억에서 산출 시스템은 재인 시스템을 형성한다. 이 수준에서 산출 시스템에 대한 갈등해소가 존재하지 않는다는 것이 말해주듯, 연산은 이 수준에서 완전히 병렬적이다. 행위는 무의식적이며 개별적인 점화에 대한 자각은 없다.
산출주기의 지속기간 (병렬적으로 하나 또는 그 이상의 산출들을 대응시키고 실행시키는) 은 ~~10 ms 수준에서 발생한다. ~~10 ms 는 매우 추정적인 양이며 이것은 3 ~ 4 ms 정도로 빠를 수도 있고 30 ~ 40 ms 정도로 느릴 수도 있다는 것을 (그림 3-10 을 보아라) 우리는 마음에 새겨둘 필요가 있다. 이러한 큰 변이의 일부는 단순히 시간 상수들 time constants 이 인간행동의 상세한 자료들과 비교해서 분명하게 정해지지 않았기 때문이지만, 많은 변이는 인간들 사이에, 그리고 때와 장소에 따라 한 개별적 인간 내에서도 존재할 것이다. 개인 내에서의 변이는 여러 출처 —— 과제들, 구성요소를 이루는 하위시스템들, 오래 지속되는 내적 상태들, 또는 잠정적 상태 —— 로부터 제기될 수 있다.
어떤 요인들이 하나의 산출주기의 지속기간을 결정하는지 정확하지 않다. 우리는 단순히 이것이 구성에 대한 소어 모형의 최하위 계층이라고 가정하고, 인간자료에 적합한 어떠한 시간 함수들 timing functions 이라도 할당할 수 있었다. 그러나 대응에 관한 계산적 요건들은 다른 어떤 계산 시스템과 마찬가지로 생물학적 시스템에도 중요한 요건이다. 패턴 대응을 달성하는 가능한 알고리듬들은 그것들이 얼마나 오래 소요되는지, 그리고 그것들이 어떤 의존성을 보이는지 이해하기 위해 탐구될 필요가 있다. 하나의 제약은 확실하다. 패턴 대응은 인지구성과 같은 동일한 계산능력을 갖고 있는 연합기억구조이어야 한다. 현재의 소어 산출 대응 production match 은 너무 강력하며 보다 약화된 대응이 좀더 좋은 결과를 만든다는 몇 가지 증거들을 다음 장에서 우리는 볼 것이다. 이 시점에서 우리가 필요로 하는 모든 것은 산출주기들이 ~~10 ms 를 소요한다는 것이다.
소어의 결정주기는 초보적 숙고연산과 일치한다. 정교화 주기는 숙고를 구성하는 지식에 대한 반복적인 접근과 일치한다. 그것은 지식을 축적하고 무엇을 할 것인가에 대한 결정을 하는데 그 지식을 사용한다. 소어의 정지상태까지의 실행 run-to-quiescence 주기는 초보적 숙고 연산의 망라적 성격과 일치한다. 그러므로 소어의 결정주기는 무의식적이며 자동적이다. 일단 시작되면, 그것은 단순히 자발적으로 완성된다. 결국에 그것의 산출물들은 작업기억에 나타나기 때문에 지각되지만, 그것들을 생산하기 위해 진행된 것들에 대한 자각은 없다.
결정주기는 ~~100 ms 수준에서 일어난다. 그것의 지속기간은 정지상태에 도달하는 가장 긴 산출연쇄에 의해 결정될 것이다. 이것은 이 시스템 수준의 지속기간에 또 하나의 변산의 출처를 더한다 —— 그것은 단순히 하위수준의 구성요소들의 임의적인 지속기간들의 합이 아니라, 합해지는 수도 역시 변할 수 있다. 정말로 결정 단계는 그 주기가 과제와는 아무 상관없고, 기능적 관계도 갖고 있지 않은 무관한 산출들에 의해 지배될 수도 있다는 독특한 특징을 지닌다.
소어의 단순한 연산자는 숙고적으로 선택된 연산들의 연쇄와 일치한다. 이러한 선택은 순차적 과정이며, 관찰된 사고의 초보적인 수준이다. 그것은 즉시적-반응 행동의 행위들을 구성한다. 그 지속기간은 그 연산자를 수행하는 데 필요한 결정주기들의 연쇄에 의해 결정된다. 최소한 두 가지의 주기가 있다. <하나는 연산자를 선택하는 것이고 다른 하나는 연산자를 적용하는 것이다. 최소의 연산자들은 단지 두 개의 결정주기만을 요구한다면 매우 빠를 수도 있지만, 단순한 연산자들은 ~~1 초를 소요해야 한다.>
일반적인 소어 문제공간들은 연산자들이 조합될 수 있는 문제공간들과 일치한다. 이것은 의도적인 합리적 시간대인 문제공간들의 위계에 들어가기 바로 전인, 인지적 시간대의 최상층이다. 이 수준에서의 시간은 ~~10 초이다. 문제공간은 목표달성의 최소단위이다. <시스템은 공간 안에서 작업하며 해결책을 찾는다.> 청킹은 경험에 따라 발생하는 숙고로부터 준비로의 계속적인 변화와 일치한다.
그림 23 의 일반적인 대응은 소어에 대해 가능한 유일한 것처럼 보인다. 즉 소어의 산출들은 ~~100 ms 또는 ~~1 초 수준에서 발생하는 어떤 것과 일치시키는 것은 불가능하다. 다른 어떤 것도 적당하지 않다. 소어가 옳지 않을 수도 있다 —— 실제세계에 대한 모든 이론들과 마찬가지로, 그것은 조금 틀릴 수도 있고 또는 완전히 틀릴 수도 있다. 양쪽의 어느 것이든 또는 그 중간의 어떤 것이든, 과학적 이론에 대해서 그러한 가능성은 언제나 있다. 그러나 소어가 인간 인지의 합당한 모형이라고 한다면, 어떻게 상세하게 발전해야 하는지에 대한 명확한 지침이 있다. 통합인지이론으로서의 소어에 대한 연결 규칙들이 정해져 있다. 그것들은 이론으로서 소어를 사용하는 방법과, 그리고 소어가 얼마나 좋은 이론인가를 평가하기 위하여 소어와 관련된 특정한 실험자료들을 사용하는 방법을 명확히 해준다.
이러한 대응의 결과들을 자세히 추적하는 것은 다음 장에서 즉시적 반응들에 대해 본격적으로 시작한다. 그 사업을 시작하기 전에, 잠시 뒤로 돌아와, 보다 전반적인 관점을 취해보자. 소어는 인간 인지의 일반적인 형태를 갖는가? 이번 장에서 나타난 것과 같은 그것의 전반적인 특징들은 올바른 것인가? 반대로, 소어는 인간의 어떤 서투른 모방은 제시하는가? 또는 어떠한 점에서 소어는 단순히 엉뚱한 것인가? 통합인지이론은 소규모로는 물론 대규모로서도 좋은 이론이어야 한다.
|
1. 실시간 제약으로부터 도출된 일반적 특질들을 갖고 있다 • 기호 시스템, 자동적 / 통제적 행동, 재인-기반적, 빨리-읽기 / 느리게-쓰기, 재인으로의 계속적인 변경 (경험으로부터의 학습) 2. 지능적으로 행동한다 • 완벽하게 합리적이지는 않다 (단지 지식수준을 추정한다) 3. 목표 지향적 • 그것이 목표들을 학습하기 때문만은 아니다 • 목표들은 그것과 환경과의 상호작용으로부터 제기된다 4. 차단 추진적 • 깊이-두선 국소적 행동, 점진적 심화 5. 기정치 행동은 근본적으로 적응적이다 • 행동하도록 프로그램 될 필요가 없다 6. 병렬주의 중간에 순차적이다 • 자율적인 행동 (그러므로 무의식적 행동) 7. 재인은 강력하게 연합적이다 • 그것이 알고 있는 모든 것에 숙고적으로 접근할 필요가 없다 • 기억하기는 하나의 문제일 수 있지만, 하나의 과제로서 취급될 수 있다 8. 그것은 과제를 어떻게 수행하는지 알지 못한다 • 학습된 절차들은 말로 명확히 표현될 수 없다 ; 청킹은 작업-기억 흔적에 접근하지 산출들에 접근하지 않는다 • 서술적 절차들로부터 해석적으로 작동할 수 있다 9. 상위-자각 또는 반성이 있다 • 뒤로 물러설 수 있고, 그것이 하고 있는 것을 검토할 수 있다 10. 무한히 큰 지식체계를 사용한다 11. 많은 양의 즉시적인 상세 사항을 자각한다 • 그러나 주의를 집중하면 주변부위는 희미해진다 12. 산만해질 수 있다 |
그림 24 인간 인지의 기본적 형태와 일치하는 소어의 특성들
그림 24 는 소어와 인간 인지에 대한 전반적 질적인 특성들의 표본을 보여준다. 불행히도, 그러한 목록에 기초를 둔 확실한 자료들이 사용가능하지는 않다. 분명히 엄청난 양의 글, 관찰, 그리고 통속 심리학이 인간본질의 일반적 특성과 관계가 있지만, 유용한 표준으로서 사용될 수 있는 특성들의 좋은 목록들이 없는 것으로 나는 안다. 사실상, 이러한 것들은 모든 사람이 왕이고 그 하인들은 그 주인만큼의 가치가 있는 상황에서의 현상들과 같은 것들이다. 전반적인 비교를 위해 일정의 객관성과 규칙을 제공하는 이러한 종류의 목록들이 있다면, 매우 유용할 것이다. 그러므로 적어도 질적인 특징에 관한 동일한 질문들이 통합인지이론의 모든 후보자들에게 돌려질 수도 있을 것이다. 그리고 그 목록을 언급하려고 시도하는 사람들이 그것을 만든 사람일 필요는 없을 것이다.
아무튼, 그림 24 는 하나의 목록이다. 편리한 표현형식은 소어가 형식상 인간인 것처럼 그것이 어떤 특성들을 포함한다고 말하는 것이다.이것은 소어에 의해 연산적으로 구체화된 통합인지이론이 사람들이 갖고 있다고 의문시되는 그런 특성들을 갖추었다고 기술 (예측) 하는 완곡한 표현을 간단하게 말한 것이다.
그러한 목록의 중요성을 살펴보기 위해서, 우리는 산만성 distractibility 부터 시작한다. 그것은 마지막 항목 (12) 이지만 그것은 특별한 교훈을 준다. 1960 년대 초기에, 월트 라이트맨 Walt Reitman (1965) 은 인간문제 해결의 초기 모의실험인 GPS (Newell & Simon, 1963) 의 획일적인 마음가짐 single-mindedness 에 대한 반동으로 전체 연구경로를 발전시켰다. GPS 는 인간행동의 특징으로서의 산만성을 전혀 갖고 있지 않을 것 같았다 (우리 모두 증언할 수 있기 때문에 경험적 자료의 필요성은 없다). GPS 의 기본 구조가 그것이 적당히 산만해지는 것을 불가능하게 만든다고 라이트맨은 생각했다. (주석 : 산만성의 부족은 그 시대의 모든 AI 프로그램들의 본질적으로 특성이었지만, GPS 는 심리학적 이론을 구체화한 시스템이기도 했다. 그러므로 그것이 이 비판의 자연스런 초점이었다.) 이것이 라이트맨에게는 치명적 결함으로 보였으며, 그는 알거스트 Argust 시스템을 개발했는데, 이것의 주안점은 적절한 산만성을 보이는 것이었다. 소어의 결정주기는 산만해지기 위해서 구성되지는 않았지만, 산만성이 발생할 수 있도록 구성되어 있다. 기존의 작업기억의 내용을 제외하고는, 어떤 산출들이 점화될 것인지에 대한 제약은 없다. 어떤 결정이라도 항상 만들어질 수 있다 —— 주어진 시점에서, 어떤 결정이 만들어져야 한다는 조건과 기준을 정하는 (지금 상태를 선택하라, 지금 연산자를 선택하라, 또는 지금 결과를 출력하라와 같은) 하향적 양식 top-down mode 은 없다. 사실, 소어는 라이트맨이 추구했던 바로 그 의미에서 산만해질 수 있는 시스템이다. 그러나 소어는 이러한 특징을 라이트맨이 알거스트에 첨가했던 (그 정신에서 다소 오늘날의 연결주의 시스템처럼 보이는 시스템을 만들기 위해) 대대적인 구조적 변경 없이 달성한다. 나는 전반적인 질적인 특성에서의 충분하고 분명한 하나의 실패가 인간행동에 대한 이론의 운명을 결정한다는 점을 지적하기 위해서 이 예를 들었다. 그러므로 우리가 그 이론을 세사한 사항들에 적용하기에 앞서, 전반적 특성들의 목록을 검토하는 것은 가치 있는 일이다.
맨 위의 항목 (1) 부터 시작을 하면, 소어는 2 장과 3 장에서 발전되었던 특성들 모두를 갖고 있다. 소어는 기호들, 자동적 그리고 통제적 행동들 모두, 연산의 기본적인 재인 양식, 빨리-읽고 느리게-쓰는 장기기억, 그리고 경험에 따른 계속적인 재인으로의 변화를 갖고 있다. 우리는 이러한 모든 것들이 인간 인지의 특징이라고 주장했고, 소어는 또한 그것들을 보여준다. 좀더 전반적으로, 주어진 대응에 따라, 소어는 인간의 다른 인지적 세계들을 계층화하는 시간대와 수준들을 갖고 있다. 우리는 의도적인 합리적 시간대 위에서의 소어에 대해서는 아는 것이 없지만, 아무튼 그것은 인간행동에 대한 분석이 이루어지는 수준에 있다.
(2) 소어는 지능적으로 행동한다. 단순한 경우들에서, 그것의 행동은 그것이 알고 있거나 원하는 것에 의해서 예측될 수 있다. 그러나 그것은 아직 완전히 합리적이지 못하고 단지 지식-수준 시스템을 추정한다.
(3) 소어는 목표 지향적이지만, 그것이 기억에 목표들을 학습했기 때문만은 아니다. 그것의 목표들이 환경과의 상호작용에서 제기되기 때문에 그것은 목표 지향적이다. 그것이 단순히 진행될 수 없을 때는 언제나 목표를 만든다.
(4) 소어는 차단에 의해 안내된다 —— 인간행동의 또 하나의 일반적 특성이다. 만약 내가 책상 위에 있는 연필을 잡으려다가, 작은 사진액자를 쓰러뜨릴 때, 나는 즉각적으로 그것에 손을 뻗어서 (우리가 자주 반사적이라고 말하는), 그것이 쓰러지기 전에 잡아 똑바로 놓을 수도 있다 —— 그리고 그런 후에 나는 연필을 다시 잡으려고 팔을 뻗는다. 나는 조금도 실수 없이 차단을 처리한다. 인간행동은 차단에 의해 강하게 안내되며 소어도 같은 방법으로 행동한다. 그것이 바로 숙고주기의 개방적 특성이 의미하는 것이다. 깊이-우선 행동과 점진적-심화 행동은 소어와 인간 모두에게 있어서 연산의 자연스런 양식들이다.
(5) 소어의 기정치 행동은 근본적으로 적응적이다. 그것이 어떤 과제에 직면했다는 것을 제외하고는 그것이 아무것도 모를 때, 그것은 명령받지 않을 때조차도, 그 과제에 대한 작업을 시작한다. 인간과 마찬가지로, 소어는 어떤 것을 수행하도록 프로그램으로 작성될 필요가 없다. 그것의 자연스런 기정 행동은 아무것도 안 하는 것이 아니다. 물론 소어가 과제를 갖고 있다는 것은 소어가 이미 문제 공간에서의 형식화를 갖고 있다는 것이다. 그러므로 이 특성은 과제들의 초기의 형식화를 언급하지는 않는다.
(6) 소어는 병렬적인 것들 중간에 있는 순차적인 것이다. 한 번에 하나의 연산자를 발생시키는 순차적인 중앙인지 구조가 있다. 그러나 이것은밖에 있는 지각적, 그리고 운동 영역들에서의 수많은 자율적인 것들에 포함된다. 분명히 소어는 숙고적으로 통제되는 중앙인지처리 과정 이외에, 진행되는 무의식적 처리과정을 갖고 있다. 이것이 바로 우리가 하는 방식이다.
(7) 소어의 재인 시스템은 내용-주소화 기억처럼 행동하는 강력한 연합적인 것이다. 이러한 특정으로부터 몇 가지 중요한, 인간과 유사한 특성들이 나타난다. 소어는 그것이 알고 있는 모든 것에 숙고적인 접근을 하는 것은 아니다. 연합기억을 작동시키는 유일한 방법은 작업기억에 인출단서를 투입시키고 그것들이 무엇을 이끌어내는지 보는 것이다. 연합기억 안에 무엇이 있는지 확실히 알 수 있는 방법은 없다. 기억하기 —— 과거에 연합기억에 무엇이 투입되었는지를 찾아내는 것 —— 는 진정한 문제일 수도 있다 (소어에서처럼 인간에게도). 그러나 그 과제는 작업기억에 투입되는 단서들을 연산함으로써 장기기억을 탐색하려는 것으로 형식화될 수도 있다.
(8) 소어는 일을 수행하는 방법을 알지 못한다. 학습된 절차들 —— 그것이 청크로 만드는 모든 것들 —— 이 분명하게 설명되지 못한다. 이 특성은 인간행동과 관련해서 자주 언급된다 —— 인간이 자신의 기술을 분명히 말할 수 없다는 것이 논리적이거나 합리적 행동에 관련해서 특별히 언급되는 특징인 것처럼 (Polyani, 1958 ; Mandler, 1985). 이 점에 있어서 청킹은 산출들이나 그것들이 표상되는 방법에 접근 없이, 작업기억에 제시된 흔적에 기초해서 전적으로 실행된다. 소어도 역시 명세화된 명령문으로부터 해석적으로 작동할 수도 있고, 작업기억에 자료구조들을 유지할 수도 있고, 그리고 그것들에 대해서 분명히 말할 수도 있다. 그리고 인간들도 마찬가지다.
(9) 소어는 특정한 반성성 reflectiveness 을 갖는데, 이것은 막다른 상태들로부터 제기된다. 막다른 상태에 도달하면 좀더 큰 맥락을 검토하기 위해 현재 행해진 것으로부터 뒤로 후퇴한다. 막다른 상태를 만나는 것이 구성에 만들어져 있기 때문에, 소어에 있어서 반성은 언제나 가능하다. 이것은 분명 인간들이 갖고 있는 반성의 한 유형이다. 이것이 모든 종류의 반성성과 일치하는지는 명확하지 않다. 인간에 있어서의 반성의 다양성과 종류들에 대해 적당한 분류법은 없는 것 같다. (그러나 계산적 시스템들에서의 다양한 반성성에 관해 메이스 Mace 와 나르디 Nardi (1989) 를 보라.) 그러나 소어의 반성이 부적절성 (막다른 상태에 의한) 에 의해 안내되며, 숙고적 행위로서는 발생하지 않는다는 것은 소어가 갖는 반성의 강력한 특징이다.
(10) 소어는 매우 큰 지식 기반을 갖도록 구조화되어 있다. 그것이 바로 산출 시스템이 제공하는 것이고, 그 설계는 소어가 많은 수 ( ~~106 또는 그 이상) 의 산출들을 갖도록 한다. 그러나 소어를 갖고 탐구된 어떤 과제들도 그렇게 큰 기억을 다루지는 않았기 때문에, 그러한 조건들에서 소어가 그럴 듯하게 행동할 것이라고 우리는 단지 예측만을 할 수 있다.
(11) 소어의 즉시적인 잠정적인 환경 (그것의 작업기억) 은 많은 양의 상세한 사항들을 포함할 수 있지만, 소어는 그런 상세한 사항의 일부에만 항상 초점을 맞추며, 나머지 것들은 대부분 처리되지 않은 상태로 남아 있다.
그림 24 의 목록을 통해 거듭하여 소어가 통합인지이론의 좋은 후보자라는 확신이 생긴다. 물론 그것이 나의 의도이다. 그러나 사람들은 누구든지 가능하다고 하면 완전한 그림을 원하기 때문에, 나는 여기서 소어가 직면한 문제와 논쟁점들의 몇 가지를 열거한다.
소어는 다른 어떤 컴퓨터 시스템들처럼, 항상 어떤 다른 것이 될 수 있는 상태로 존재하는 하나의 시스템이다. 많은 측면들은 아직 연산적이지 않거나, 또는 단지 제한적인 방식으로 연산적이다. 나는 여기서 현재 수정판인 소어 4.5 를 기술하지만, 다음의 주요 수정판인 소어 5 에서 특정한 향상들이 있을 것이라고 즉각적으로 주장한다. 이것들은 어떤 중요한 측면들을 포함하며, 그렇지 않다면 우리는 그것들을 포함하기 위해 소어를 수정하거나 발전시키지는 않을 것이다. 물론 이러한 변화의 일부는 그 때조차도 만들어지지 않을 것이고, 그래서 그것들에 대하여 말하는 것은 시기상조일 것이다. 그것은 진정한 트래스트럼 샌디 Tristram Shandy 상황이다. 내가 윌리엄 제임스 강연을 하고 2 년이 지난 후에, 소어는 상당히 변화했다. 특히 소어 5 는 설계단계에서 구현단계로 와 있고 이제 소개되려고 한다. 소어 5 를 고려하며 이 책을 보충하는 것은 많은 부분을 고치고 새로 써야 할 것이며, 그렇게 하는 동안 소어는 조금 더 변화할 것이다. 그러므로 소어라고 제시된 것은 사실상 2 년의 시간대를 통해 움직이는 평균치이다.
이러한 중간 상태에서 소어의 중요한 측면들에 대한 특정한 예들을 열거하는 것은 어려운 일은 아니다. 소어 5 의 주요한 새로운 측면들은 지각적 그리고 운동 시스템들의 구성요소들이고, 방문했던 모든 상태들을 기억하는 소어 4 의 현재의 능력과 반대로 소어 5 는 어떤 문제공간에서도 단지 하나의 상태만을 기억할 수 있다는 원리의 채택이다. 산출들의 대응능력을 줄이기 위한 수정은 소어 5 를 넘어서는 것이다. Ops5 로부터 이어받은 현재의 것은 다른 측면에서 보자면 단일한 재인에서 수행될 수 있는 것에 비해 분명히 너무 강력하다. 하나의 더 작은 문제는 소어가 무한한 막다른 상태의 구덩이 속으로 떨어지는 것을 막는 어느 산출들에 대한 요건에 관한 것이다. 어떻게든, 기정 행동이 전적으로 그 구성 안에서 정의되어야만 한다고 느끼지만, 아직까지 이것은 이루어지지 않았다.
현재의 우리의 이해로는, 어느 곳에서 어려움들이 제기될 것인지를 지적해주는 것은 아무것도 없지만, 어떤 것들은 소어에 의해서 입증되 지 않는다. AI 의 하나의 오랜 목표는 안정적인 nonbrittle 시스템들을 구성하는 것이었다 —— 미리 정해진 어떤 과제의 범위를 벗어난 곳으로 시스템들이 이동했을 때, 갑자기 실패하지 않는 시스템들. 우리가 과대평가하는 것인지는 모르지만 (철강근로자를 주식거래소로 또는 정신분석학자를 오래 된 수작업으로 하는 Vax-구성과제로 옮겨놓고 어떤 일이 발생하는지 보아라), 인간들은 분명히 어느 정도의 안정성을 보인다. 소어는 일반 지능의 충분한 속성들을 갖고 있어서, 그것은 그러한 방향으로 중요한 일보를 가능하게 했지만, 그것에 대한 직접적인 실증들은 아직 시도되지 않았다. 청킹이 학습의 전체 영역을 포함하는지 여부는 현재의 실증들이 아직은 단순히 나열적이며, 명백하지 않은 또 하나의 문제로 남아 있다
마지막으로 현재까지 발전된 소어의 수정판에서 단순히 빠져 있는 것들을 명명하기는 쉽다 —— 정서, 꿈, 심상. 이러한 현상들은 소어의 현 기제들과 전혀 새로운, 종류가 다른 구조들을 요구할 수도 있다. 그러한 경우가 아니라면, 그것들의 증명은 소어가 어떻게 그러한 현상들을 현 구성에서 설명하느냐에 달려 있다. 이것은 아직 이루어지지 않았다.
소어에 대한 또 하나의 다른 요약은 유용할 수도 있다. 1 장에서 우리는 마음의 본질에 영향을 주는 많은 다른 제약들의 목록을 고려했었다. 우리가 통합이론을 필요로 하는 하나의 이유는 하나의 이론 안에서 그러한 모든 제약들을 사용하기 위해서이다. 먼저 우리는 소어가 고려하기로 설계되어 있는 제약들의 관점에서 소어가 적합한지를 물어보아야 한다. 소어가 다른 제약들에 대해서도 역시 반응적인가는 별개의 물음이다. 설계 의도로부터 시작해 보자. 그림 25 는 그림 1-7 이 제시한 동일한 제약들의 목록이지만, 그 목록에 각각의 주어진 제약을 다루도록 소어가 설계되었는지에 대한 표시들이 덧붙여져 있다.
|
1. 유연하게 행동한다 2. 적응적 (합리적, 목표-지향적) 행동을 보여준다 3. 실시간으로 작동한다 4. 풍부하고, 복잡하고, 상세한 환경에서 작동한다 • 변화하는 상세 사항의 엄청난 양을 지각한다 • 엄청난 양의 지식을 사용한다 • 많은 자유도의 운동 시스템을 통제한다 5. 기호들과 추상물들을 사용한다 6. 자연 언어와 인공 언어를 모두 사용한다 7. 환경과 경험으로부터 학습한다 8. 발달을 통해 능력들을 획득한다 9. 자율적으로 작동하지만 사회적 공동체 안에서 작동한다 10. 자기-자각이 있고 자기에 대한 감각이 있다 11. 신경 시스템으로서 실현 가능하다 12. 발생학적 성장 과정에 의해 구성 가능하다 13. 진화를 통해 제기된다 |
예 예 예
인터페이스만 예 인터페이스만 예 아니오 예 아니오 아니오 아니오 아니오 아니오 아니오 |
그림 25 소어의 설계와 마음에 대한 다중 제약들
유연성은 보편적 계산에 필수적이고 모든 합당한 계산시스템에 의해 공유되는 것이기 때문에, 소어를 유연성 있게 만들려는 많은 노력들이 이루어졌다. 우리는 또한 실시간으로 작동하는 제약에 초점을 맞추었다. 이것은 아마 우리가 반응을 하려고 했던 가장 큰 새로운 제약이다. 동일한 시스템에서 보편성과 실시간 반응을 함께 결합시키는 능력이 없다는 것은 표준적인 정리증명자와 같은 계산 시스템들의 모든 영역들을 통합인지 이론들에 대한 후보자들의 목록에서 제거시킨다.
환경의 풍부함 richness 에 대하여, 우리는 의도적으로 많은 양의 지식을 갖도록 설계했다. 이것은 무한정으로 큰 재인 시스템의 개념 (산출 시스템) 에서 구체화된다. 그러나 환경과의 상호작용의 다른 두 가지 측면들 —— 풍부한 지각적 입력과 큰 자유도를 갖는 출력 —— 은 매우 적은 주의만을 받았다. 전체시스템의 설계에서 (그림 15), 이러한 문제들의 일부를 언급하기 시작하고 정말로 중요한 제약인 척도와 복잡성의 문제들에 대해서는 침묵을 지키고 있다.
소어는 기호들과 추상물들을 갖는 것에 대해 완전히 반응적이다. 이것은 소어 그 자체와는 관계가 없지만, 이러한 두 요건들과 계산적 보편성과의 결합과는 관계가 있다. 그러므로 그것들 셋은 함께 다닌다. 다른 한편, 우리는 자연언어의 요건들에는 주의를 기울이지 않았다. 인지에 대한 제약들의 목록의 관점에서 보면, 자연언어에 관한 주요한 문제는 그것이 목록에 이미 있는 것 —— 보편성, 실시간 연산, 기호들, 추상화, 그리고 학습과 사회화까지 —— 들 이외의 다른 제약들을 제공하느냐의 여부이다. 이것은 현재의 모듈성 가설 (Fodor, 1983) 을 표현하는 한 방법이다. 다른 많은 제약들을 구체화함으로써, 소어는 이것에 관하여 말할 어떤 것을 갖고 있는 것 같다. 그러나 아무튼 특히 언어적 요건들에 의도적으로 반응하는 소어의 설계의 측면들은 없다.
소어 구성은 내장된 청킹 기제들을 통해 학습에 완전히 반응적이다. 그러나 앞에서도 보았듯이, 학습은 최초의 설계에는 전혀 포함되지 않았던 하나의 주요한 제약이었다 (Laird, 1984). <시스템이 완전히 연산적이 되고 난 후에야 그것이 달성되었다.>
나머지의 제약들 —— 발달, 사회적 공동체에서 살기, 자기-자각, 신경 시스템으로서의 실현, 또는 발생학적 과정에 의한, 궁극적으로는 진화에 의한 시스템의 구성 —— 을 만족시키기 위해 소어를 설계하려는 시도는 되지 않았다. 3 장은 실시간 제약이 신경기술을 사용하는 것과 함께 구성의 많은 특성을 결정함 —— 그리고 이러한 특질들이 대부분 소어에 존재함 —— 을 보여주었지만, 그러한 고려사항들은 소어 설계에 개입하지 않았으며 그 때에는 분명히 표현되지 않았었다.
드디어, 통합인지이론에 대한 우리의 후보자에 관한 기술이 완성되었다. 이 후보자는 단지 소어에서 통합된 연산적 형태로 존재하는 그것의 기제들에서 뿐 아니라, 그 구성과 인간 인지와의 대응에서도 역시 매우 명확해졌다. 이 책의 나머지 부분에의 과제는, 다양한 정밀도를 갖고 이 후보자를 인간 인지의 많은 다른 측면들과 접촉시킴으로써, 하나의 통합인지이론이 무엇을 제공해야 하는지를 예시하는 것이다.