인지과학의 기초
통합인지이론 : Allen Newell 저, 차경호 옮김, 아카넷, 2002 (원서 : Unified Theories of Cognition, Harvard Univ. Press, 1990), Page 77~164
4. 기계와 계산 (Machine and Computation)
8. 탐색과 문제공간 (Search and Problem Space)
9. 준비와 숙고 (Preparation and Deliberation)
여기에서는 인지 시스템의 기초구조를 어떻게 설명할 것인가라는 기초적인 문제들로 시작한다. 우리는 이 책을 읽어 나감에 따라 지식이나 표상의 본질에 대해서 혼동되지 않기 위해 어느 정도의 공통적인 기초를 필요로 한다. 이러한 개념들에 대한 관심이 많이 있어 왔기 때문에, 우리는 친숙한 영역을 다루는 것이다. 개념들 중 몇 가지는 전통적인 철학적 문헌을 갖고 있고, 모든 개념들은 지난 10 년 사이, 특히 철학자들이 드디어 이 주제에 대해 관심을 갖기 시작했던 때, 인지과학에서 지속적인 관심을 끌어왔었다. 친숙한 것들을 재정리하는 것은 아직도 유용하다. 그러나 기초들에 대해서는 결코 많은 합의가 있을 수 없다는 것을 인식해야 한다 —— 기초들은 항상 그것이 지지하는 것보다 지적으로 덜 확고한 것이다.
이러한 부인에도 불구하고, 나는 이러한 개념들을 개관하면서 이루고자 하는 것이 있다. 나는 그것들과 물리적 세계를, 일반적인 경우에서 그랬던 것보다 더 밀접하게 연결시키기를 원한다. 우리가 다루게 될 다양한 모습을 갖춘 시스템들의 추상적 특징을 강조하기보다는, 나는 그것들이 어떻게 역동적 세계에서의 물리적 시스템인 인간 안에서 만들어지는지를 강조하고 싶다. 인간 인지에 관한 이론들은 궁극적으로 물리적이고 생물학적인 시스템에 대한 이론이다. 다른 어떤 방법이 아니라 하나의 특정한 방법으로 인간 인지를 설명할 수 있는 우리의 능력은 궁극적으로 인간의 물리적이고 생물학적인 본질에 의존한다. 더 나아가 인간이 이 세계 안에서 만들어졌다는 사실은 우리가 이론들을 구성하는 데 있어 고려해야만 하는 추가적인 제약들이 있다는 것을 의미한다.
편의상 우리는 필요한 예비 단계인 행동 시스템의 개념으로부터 시작해 계속해서 나타날 중요한 용어들을 순서대로 살펴볼 것이다. 행동 시스템, 지식, 표상 representation, 계산 시스템 computational systems, 기초 symbols (주석 : symbol 을 심리학에서는 주로 상징으로 번역하며 전산학에서는 기호로 번역한다. 본 글에서는 symbol 을 기호로 번역한다.) 와 기호 시스템, 구성, 지능, 탐색 search 과 문제 공간, 그리고 준비 preparation 와 숙고 deliberation 등을 우리는 다루게 될 것이다. (주석 : 원래의 강연에서는, 전적으로 시간 때문에, 마지막의 두 주제들 —— 탐색과 문제 공간, 그리고 준비와 숙고 —— 은 강연 3 의 앞부분에서 다루어졌다. 여기서는 모든 기초적 재료가 하나의 장에 포함되어 있다.
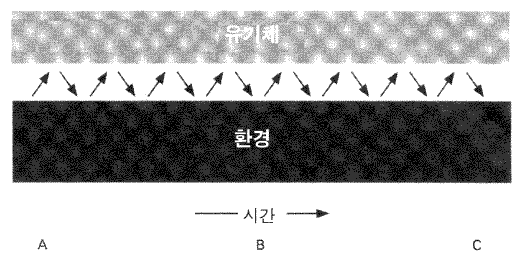
나는 마음을 역동적인 실제 세계와 복잡한 상호작용을 하는 유기체의 행동을 안내하는 통제 시스템으로 취급하기를 원한다. 그림 1 은 시간에 따라 행동하는 환경과 유기체, 그리고 이 둘 간의 연쇄적인 상호작용을 보여주고 있다. 하나의 상호거래 —— 환경은 제시하고 유기체는 반응하는, 또는 그 반대의 경우 —— 는 분석적으로 고립시킬 수 있지만, 거래들은 각 거래가 다음 행위가 뒤따라오는 맥락의 일부가 되는 연쇄 속에 포함된다. 그렇다면 마음이란 유기체의 이익을 위한, 또는 궁극적으로 그 종의 생존을 위한 상호작용을 수행하기 위해 유기체로부터 진화되어온 통제 시스템에 우리가 붙여준 단순한 이름이다.
그림 1 행동 시스템의 통제장치로서의 마음에 대한 추상적 견해
어떠한 더 심오한 견해가 타당하다고 해도 마음은 반응함수들 response functions 을 제공한다고 볼 수 있다. 즉 유기체는 환경의 함수 (수학적 의미에서) 에 따라 행위를 한다. 만약 환경이 다르다면, 동일한 반응함수를 갖고 있다고 할지라도 유기체는 다르게 행동할 수 있다. 이것이 바로 상호작용한다는 것이 의미하는 바이다. 그러나 유기체는 시간이 지남에 따라 다양한 함수들을 만들어낸다. 그림에서 A 라고 이름 붙여진 기간 동안에 유기체는 하나의 반응함수, B 에서는 다른 반응함수, C 에서는 또 다른 반응함수를 갖고 행동한다. 상황의 유형이 다르면 반응함수들도 다르다.
하루를 지낸다고 생각해 보라. 아침에 일어날 때, 옷을 가지러 갈 때, 거울을 볼 때, 아침을 먹으러 갈 때, 배우자와 이야기할 때, 차에 탈 때, 그리고 직장으로 운전하고 갈 때와 같이 이 모든 상황에서는 서로 다른 반응함수가 있다. 그러한 상황들 각각은 모두 다르며 각각의 상황은 환경에 대해 반응을 어떻게 할 것인지에 대해서 많이 다른 함수를 요구한다. 하나의 반응함수는 침대, 마루, 그리고 덮개를 포함하고 —— 다른 것은 거울과 수도꼭지 —— 또 다른 것도 역시 완전히 다른 것들을 포함한다. 당신이 동일한 상황에 다시 처했을 때도 당신은 다른 반응함수를 사용할 수도 있다. 당신이 차에 타고, 어떤 일들이 다르게 발생하고, 당신은 열쇠가 어디 있는지 기억할 수 없고, 그리고 이제 당신은 다른 어떤 일을 한다. 세상은 초소형 단위들로 나누어져 있고, 이것들은 충분히 독특하고 독립적이라서 통제 시스템 (즉, 마음) 은 각각에 대해 다른 반응함수를 생성한다.
뒤로 물러서서 마음을 하나의 커다란 괴물 같은 반응함수로 취급하는 것은 분명히 가능하다. <즉 유기체의 모든 과거에 걸친 모든 환경으로부터 미래의 행위를 만들어내는 하나의 단일한 함수로서 마음을 취급하는 것 (주어진 시간에서의 출력은 미래의 입력에 결코 의존하지 않는다는 제약 아래서).> 행동들을 다중의 반응함수들로 기술하는 것은 유기체가 어떠한 방식으로 나누어져 있음을 의미한다. 사실 유기체는 종종 함수에 유입되는 측면들 (행동은 이것들의 함수로 만들어진다) 이 거의 공통점이 없을 정도로 환경을 충분히 다르게 취급한다. 그러므로 유기체가 각 상황에 대해 각각의 개별적인 함수들을 사용하는 것처럼 기술하는 것은 가능하다. 반응함수라는 용어는 이 책에서 반복해서 나올 것이기 때문에 기억하라.
그렇다면 우리는 시스템을 어떻게 설명해야 하는가? 우리는 그것들의 반응함수들을 어떻게 설명해야 하는가? 마음을 제어장치로 취급한다는 것은 즉각적으로 통제 시스템의 언어 —— 피드백, 증폭 gain, 진동 oscillation, 감쇠 damping 등 —— 를 제안한다. 우리가 시스템을 목적적 purposive 이라 기술할 수 있게 해주는 것은 바로 언어이다 (Rosenbleuth, weiner, & Bigelow, 1943) . 그러나 우리는 인간 행동과 반응의 모든 범위에 관심이 있다 —— 길을 걸어가고, 날아가는 새를 추적하는 것뿐만 아니라, 새에 관한 책을 읽고, 보행을 계획하고, 어느 특정한 위치에 도달하기 위한 지시를 받고, 특정한 종을 확인하고, 지금까지 보아온 새들의 목록에 새로운 이름을 더하고, 나중에 그것에 관한 대화를 하는 것도 포함한다. 행동의 범위가 이처럼 폭넓게 확장되었을 때, 통제 시스템의 언어가 하나의 특정한 환경이나 과제의 특정한 범주에 —— 지적하거나 따라하려는 의도를 갖고 있는 연속적인 운동 동작에 —— 정말로 고정되어 있음이 분명해진다. 그 밖의 것에 대해 그것은 은유적 표현이 된다.
광범위한 능력을 갖고 있는 시스템의 행동을 기술하는 한 방법은 그것들의 지식을 갖고 있고, 그 지식에 비추어 행동한다는 관점에서 보는 것이다. 그것을 어떻게 하는지를 보기 전에 그것이 무엇을 의미하는지 먼저 살펴보자. 그림 2 는 단순한 상황인 블록 세계를 보여주고 있는데, 그것은 지식을 갖고 있는 것으로 특징지워지는 시스템에 대한 적합하고 전형적인 예이다. 탁자가 있고, 그 위에 3 개의 블록 A, B, 그리고 C 가 있다. A 는 B 위에 있다. 어떤 행위자 X 는 그 상황을 관찰한다. 그러므로 우리는 A 가 B 위에 있다는 것을 X 가 알고 있다고 말할 수 있다. 그 상황을 관찰하지 못한 다른 행위자 Y 가 B 위에는 아무 것도 없는지 X 에게 묻는다. 별다른 생각없이 우리는 X 는 Y 에게 B 위에 무언가 있다고 말할 것이라고 믿는다. 우리는 사실상 X 반응에 대한 예측을 한 것이다. 이와 같은 상황이 정확히 발생했다고 가정하자 (정말로 그럴 듯한 이야기이지 않은가?) . 우리는 어떻게 X 의 행동을 예측할 수 있는가?

그림 2 단순한 블록 세계
직접적인 분석은 다음과 같다. 우리는 X 가 Y 에게 진실을 말할 목적을 갖고 있다고 가정한다. 목적이 포함되어 있어야만 한다. 만약 우리가 이 행위자의 어떠한 목적도 가정할 수 없다면, X 가 방 밖으로 나가든지 또는 다른 어떤 일을 하지 않고 질문에 대답한다는 예측을 하기 위한 기초가 존재하지 않는다. 행위자의 목적은 (이 사례에서) 다음과 같은 것이다 ; 만약 어떤 사람이 단순한 질문을 하면 정직하게 대답한다. 우리는 만약 X 가 어떤 것을 알고, 어떠한 목적이든지 그가 선택한 목적을 위해 그 지식을 사용할 수 있다고 받아들인다. 결론적으로 우리는 다음과 같이 추정한다.
X 는 B 위에 A 가 있다는 것을 안다.
X 는 질문에 정직하게 대답하길 원한다.
X 는 대답할 능력이 있다 (X 는 의사소통할 수 있다)
결과적으로 X 는 Y 에게 B 위에 무언가 있다고 말할 것이다. 그러므로 우리는 X 가 무엇을 할 것인지 예측할 수 있다. 그 예측이 항상 옳을 필요는 없다 —— 우리는 X 의 목적 또는 X 가 알고 있는 것에 대해 틀릴 수도 있고, 예상치 못했던 상황이 발생해 그 행위를 금지시킬 수도 있다. 그러나 여전히 이것은 시스템의 행동을 예측하는 유용한 방법이다.
지식의 분석은 오랜 철학적 역사를 갖고 있으며, 사실 인식론의 표준적 하위영역을 이루고 있다 .이것은 인지과학 안에서도 지속되고 있다 (Goldman, 1986) . 그 분석은 지식을 독특한 그 무엇 —— 시스템이 지식을 갖고 있다는 것이 의미하는 것은 무엇인지, 그리고 특히 지식이 확실하다는 것이 의미하는 것은 무엇인지, 그리고 특히 지식이 확실하다는 것이 의미하는 것은 무엇인지에 관한 독특한 문제를 갖는 특별한 어떤 것 —— 으로 취급한다. 반면 인지과학이 필요로 하는 것이라고 내가 주장하는 것은 단지 시스템의 반응함수를 기술하고 예측하는 데 사용되는 지식의 개념이다. 물론 모든 목표와 모든 지식 체계에 대해 각기 다른 반응함수가 있지만 블록들이 있는 그 상황은 우리들의 그 개념의 사용법에 대한 전형적인 예이다. 그것은 시스템의 특징을 결정짓는 한 방법이고, 그래서 우리는 시스템의 행동을 (다양한 정도의 성공을 갖고서) 예측할 수 있다.
그러므로 어떤 것이 지식이 있다고 취급하는 것은, 그것을 특정한 종류의 시스템으로 여기는 것이다. 시스템을 조금이라도 다루려고 한다면 우리는 시스템을 어떤 방식으로든 설명한다. 한 시스템은 이러한 방법으로, 또 다른 시스템은 또 다른 방법으로 우리는 설명한다. 또 우리는 자주 동일한 시스템을 여러 가지 방법으로 설명한다. 한 시스템을 지식 시스템으로 기술하는 것은 단지 가능한 대안들 중 하나이다. 어떠한 기술 description 을 사용할 것인지 선택하는 것은 우리의 목적과 그 시스템과 그것의 특성에 대한 우리의 지식에 의존한 실용적인 문제이다. (주석 : 지식의 본질을 설명하기 위해 <우리의 목적들과 우리 자신의 지식> 이라는 구절을 사용하는 것은 유리한 것이며 어떠한 악순환을 암시하지는 않는다. 행위자가 주어진 유형의 기술을 사용하는 때를 논의하기 위해, 우리는 그 행위자를 기술해야만 한다. 이 경우 그 행위자 —— 바로 우리들 —— 에 대한 적절한 기술은 지식 시스템으로 기술하는 것이다.)
|
지식 - 수준 시스템 매체 : 지식 법칙 : 합리성의 원리
프로그램 - 수준 시스템 매체 : 자료 구조, 프로그램 법칙 : 프로그램의 연쇄적 해석
레지스터 - 전송 시스템 매체 : 비트벡터 법칙 : 병렬적 논리
논리회로 매체 : 비트 법칙 : 불린 대수
전자회로 매체 : 전압 / 전류 법칙 : 옴의 법칙, 커크호프의 법칙
전자장치 매체 : 전자 법칙 : 전자물리학 |
그림 3 컴퓨터 시스템의 위계
그림 3 에 제시된 친숙한 컴퓨터 - 시스템의 위계를 고려해 보자. 우리는 이 책에서 그것을 계속해서 보게 될 것이다. 하나의 컴퓨터 시스템은 많은 방법으로 설명될 수 있다. 그것은 전자 장치의 시스템, 전기회로, 논리회로, 레지스터-전송 register-transfer 시스템, 또는 프로그래밍 시스템으로 설명될 수 있다. 또한 다른 방법들도 있다. 예를 들면 예산에서의 한 항목의 비용, 바닥의 하중에 기여하는 것, 또는 첨단 기술의 기호와 같이 그것의 주요 기능과 상관없는 방법들도 있다. 행동하는 시스템으로서의 컴퓨터에 기초한 모든 기술들은 기계 machines 의 유형이다. 각 경우마다 처리되는 일종의 매체 medium 가 있다. 밑에서부터 시작하면 매체는 전자, 전류, 비트 bits, 비트벡터 bit vectors, 그리고 자료 구조 data structures 들이다. 언제든지 시스템의 상태는 그 매체의 일정한 배열로 이루어진다. 시스템의 행동을 예측하는 데 사용될 수 있는 행동법칙이 있다. 전자는 전압이 가해진 전자기력 아래서 움직이는 입자다 ; 전기회로는 옴의 법칙 Ohm's law 과 커크호프의 법칙 Kirchhoff's law를 따른다. <프로그램에서의 처리는 규정된 프로그램 언어를 따른다.> 각 경우에 우리가 시스템의 상태와 그것의 행동에 대한 법칙들을 안다면, 우리는 미래의 한 시점에 있는 시스템의 상태를 얻을 수 있다. 이들 기술 각각은 시스템의 행동에 관한 예측을 하는 다른 방법들을 제공한다.
명확한 설명이 필요하며, 나는 지금까지 예측에 대해 언급해왔다. 이것은 기술의 다양한 사용들, 예를 들면 행동을 설명하기, 행동을 통제하기, 또는 이런 특정한 행동을 하는 어떤 것을 구성하기에 대한 단순한 편법이다. 이러한 활동에는 차이가 있고 어떤 기술은 특정 활동에 더 적합한 경우가 있기도 하지만, 그것을 항상 명백히 한다는 것은 피곤한 일이다. <예측> 이 모든 것을 포함할 것이다.
컴퓨터 시스템의 기술들은 수준들의 위계를 형성하는데, 이는 상위 수준의 기술은, 그것 밑에 있는 수준이 추상화된 것인 동시에 특수화된 것이기 때문이다. 전기회로 경우를 생각해 보자. 그것의 매체인 전류는 전자의 흐름이다. 전자기 법칙인 옴의 법칙과 커크호프의 법칙은 전도체들의 연결망에 특수화된 전자기 이론으로부터 유도될 수 있다 .프로그램 경우를 생각해 보자. 자료 구조들은 다양한 연산 operation 에 의해 고정된 방식으로 해석되는 비트벡터들의 집합들이다. 프로그램의 해석은 실행될 연산을 결정하는 자료 구조에 의해 기술될 수 있는 것처럼, 연산들은 특수한 레지스터 - 전송 시스템의 결과들로서 기술될 수 있다. 각 수준은 하위수준의 많은 세부사항들에서 추상화된 것이다.
시스템들은 위계의 위로 올라갈수록 점점 특수화된다. 전기 회로로 기술될 수 있는 모든 시스템이, 논리 회로로도 역시 기술될 수 있는 것은 아니다. 레지스터-전송 시스템으로 기술될 수 있는 모든 시스템이 프로그램을 짤 수 있는 시스템은 아니다. 수준들 간의 관계성이 때로는 상당히 투명하다. 예를 들면, 단순한 집합이 논리 수준과 레지스터-전송 시스템을 연결해주는데, 레지스터-전송 시스템에서는 비트들은 고정된 길이의 벡터로 단순히 조직화되고, 몇 가지의 특수한 연산 (올림이 있는 경우의 더하기와 곱하기 같은) 을 제외하고는 일정한 방식으로 처리된다. 종종 그 관계성은 덜 명확하다. 불린 Boolean 의 논리법칙을 따라 비연속적으로 행동하는 전기 회로의 발명은 좀더 상당한 발전이 필요했으며 레이더의 펄스 시스템에 대한 연구에 의해 더욱 발전했다.
지식 시스템은 시스템을 기술하는 또 하나의 방법으로서, 동일한 위계에서의, 단순히 또 하나의 다른 수준이다. 위계에서의 하나의 수준으로서, 그림 3 에서 보는 바와 같이 지식은 프로그램 수준 위에 있다 .지식 수준은 내적 처리과정과 내적 표상으로부터 완전히 추상화된 것이다. 그러므로 남겨진 것은 표상들의 내용과 목표들이고, 그 내용들은 그 목표들을 위해 사용될 것이다. 하나의 수준으로서 그것은 매체, 즉 지식을 갖고 있다. 그것은 다음과 같은 행동의 법칙을 갖고 있다. 만약 시스템이 목표 G 를 달성하기를 원하고, 행위 A 를 하면 G 를 달성할 것이라는 것을 안다면 그것은 A 를 할 것이다. 이 법칙은 합리성의 단순한 형태이다 —— 다시 말해 행위자는 자신이 알고 있는 것에 따라 자신의 이익을 극대화하기 위해 행동할 것이다.
그림 3 의 위계에서 단지 하나의 수준으로서 지식 수준에 대해 매우 기본적인 생각 또는 철학적 의미로 고려해 보더라도 특별한 것은 없다. 물론 지식 수준은 다른 수준들과는 분명히 다르다. 그것은 자신의 매체와 법칙을 갖고 있으며, 또 그것들은 그 나름대로 특성을 갖고 있다. 그러나 동일한 방법으로 각 수준들은 다른 모든 수준들과 다르고, 저마다 독특한 특성을 갖고 있다. 물론 수준들은 다양한 방법들, 예를 들면 비연속적 대 연속적, 또는 순차적 대 병렬적으로도 분류될 수 있다. 그러나 분류법이 시스템을 어떻게 기술하느냐, 그리고 그것의 효과적인 사용을 도와주는 분석과 종합의 특징적 양식이 무엇인가라는 점에서, 각 수준의 개별적 특이성과 비교해서 본다면 그 분류법은 그리 중요한 것은 아니다.
그림 3 에 제시된 것처럼 시스템을 기술하는 방법 그 자체만으로는 분명한 과학적 주장들을 갖고 있지 않다. 그것들은 단순히 자연의 부분들을 기술하는 방법들처럼 보인다. 그러나 그것들은 이론적으로 중립적인 것은 아니다. 그러한 기술방식이 주어진 실재 시스템이나 시스템의 유형에 대해 성공적으로 또는 어느 정도 추정을 가지고 실제 사용될 수 있다는 사실을 우리가 발견할 (또는 주장할) 때 과학적 주장들은 제기된다. 성공의 준거는 그 시스템이 연산적으로 완전하다는 것이다 —— 그것의 행동은 그 수준에 대해서 형식화된 것처럼 행동 법칙에 의해 결정되며, 그 수준에서 기술된 것처럼 그것의 상태에 적용된다. 이 주장은 관련된 특정한 수준에 대한 추상화는 여전히 그 추상화의 수준에서 기술되는 미래의 행동과 관련 있는 모든 것들을 유지한다는 것이다. 그러한 주장들의 효력은 어떤 사람이 당신에게 닫혀 있는 작은 상자를 주면서 <이 속에는 프로그램을 짤 수 있는 컴퓨터가 있다> 라고 주장하는 것을 상상해 봄으로써 쉽게 이해될 수 있다. 그것은 당신이 프로그램을 짤 수 있는 컴퓨터라고 성공적으로 기술될 수 있는 무언가를 상자 속에서 찾을 것임을 의미한다. 그러므로 당신은 그것을 그렇게 취급하고, 그것의 프로그램을 짤 수 있고, 로드된 loaded 프로그램을 사용하여 그것을 실행하는 일 등을 기대할 것이다. 그 추상화를 주어진 것으로 받아들이고 당신의 기대에 따라 행동한다면, 당신이 지금까지 알지 못했던 세계의 영역에 대해 성공적인 예측을 (또는 예측의 실패를) 하나하나 경험하게 될 것이다.
그러므로 인간이 지식 수준에서 기술될 수 있다고 주장하는 것은 인간을 지식과 목적이 있는 행위자로 설명할 수 있으며, 그래서 그들의 행동은 다음과 같은 법칙 —— 인간의 모든 지식은 항상 자신의 목표 달성을 위해 사용된다 —— 에 의해 성공적으로 예측될 수 있다는 것을 주장하는 것이다. 물론 그 주장은 완벽하게 성공적인 예측을 위해 필요한 것이 아니라 다만 어떤 추정을 위해 필요한 것이다.
왜 시스템을 지식 수준에서 기술하는 것이 필요한지를 아는 것은 쉽다. 본질적인 특징은 실제적인 내적 처리과정의 자세한 사항들이 요구되지 않는다는 것이다. 만약 시스템의 목표와 환경에 대해 시스템이 무엇을 알고 있는지를 당신이 알고 있다면, 존재하는 그 시스템의 행동은 예측될 수 있다. 목표와 지식 모두 직접적인 관찰 —— 한편으로는 환경, 다른 한편으로는 시스템의 과거 행동의 관찰 —— 에 의해 빈번히 결정될 수 있다. 지식 수준은 내적인 작용이 아직 결정되지 않은 시스템을 설계하는 데에도 역시 필요하다. 지식 수준은 시스템의 바람직한 행동 또는 그것이 무엇을 포함해야 하는가 (즉, 필요한 지식과 목표들) 하는 문제들에 대해 적당한 진술방법을 제공한다. 시스템들의 명세사항들은 지식 수준에서 자주 제공된다. 물론 모든 수준이 그것의 하위 수준에 대한 명세화로써 사용될 수도 있고 또 사용된다. 지식 수준의 특별한 특징은 시스템의 내적인 작용이 결정되기 전에 명세화를 제공할 수 있다는 점이다.
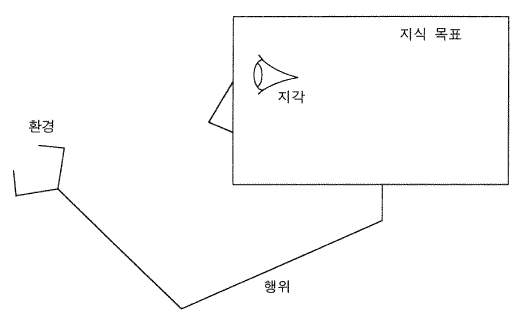
그림 4 지식-수준 시스템
지식 시스템이 무엇인가 (그림 4) 를 좀 더 신중하게 다시 진술함으로써 정리해 보자. 지식 시스템은 외부환경에 포함되어 있는데, 그것은 가능한 행위의 집합에 의해 환경과 상호작용을 한다. 시스템의 행동은 시간이 지남에 따라 환경에서 취해지는 행위들의 연쇄이다. 시스템은 환경이 어떻게 변해야만 하는지에 대한 목표들을 갖고 있다. 내적으로 시스템은 매체, 즉 지식을 처리한다. 시스템의 지식체계는 그것의 환경, 목표들, 그것의 행위들, 그리고 그것들 간의 관계에 대한 것이다. 그것은 단일한 행동법칙을 갖고 있다. <시스템은 그것이 갖고 있는 모든 지식을 사용해서 그 목적을 달성할 행위를 취한다.> 그 법칙은 지식이 처리되는 방법의 결과들을 기술한다. 시스템은 그것의 행위 (이것은 지각적 행위라 불릴 수도 있다) 를 통해 외부의 지식 출처로부터 새로운 지식을 획득할 수 있다. 일단 지식이 획득되면 그것은 영원히 사용될 수 있다. 시스템은 하나의 동질적인 지식체이고, 모든 것은 행위를 결정하는 데 사용된다. 지식은 물론 다른 시스템에게로 전달될 수 있지만, 시간에 따른 지식의 손실은 없다.
지식을 하나의 시스템 수준 —— 많은 것들 중 단지 하나의 시스템 수준 —— 의 매체로 특징짓는 것은 지식의 본질에 관한 특이한 이론을 만들어낸다. 지식에 대해 현존하고 있는 광범위한 철학적 문헌들은 이러한 방법으로 지식을 기술하지 않는다. 일반적으로 그것은 지식을 시스템의 관점에서 기술하지 않고 단순히 지식의 타당성과 확실성에 대한 탐구만을 지속한다. 그러나 다니엘 데닛 Daniel Dennett (1978, 1988a) 의 지향적 체계 intentional system 라는 개념은 실질적으로 지식체계와 동일하다. 사실상, 데닛이 말하는 핵심적인 개념은 지향적 입장 intentional stance 의 개념인데, 이것은 관찰자가 행위자를 바라보거나 개념화하는 방법이다. (주석 : 그러므로 데닛은 관찰되는 것의 성질이라기보다는 관찰자의 본질에 강조점을 둔다. 이러한 문제들을 다루는 철학자들의 방식을 이해하기를 원하거나 지식 수준과 지향적 입장과의 관계에 관심이 있는 독자는 데닛 (1988b) 와 뉴웰 (1988) 을 참조할 수 있다.)
이 지식수준 시스템 이론은 진정한 지식의 이론이지만, 사실 이것은 어느 누구의 이론도 아니다. 분명히 나의 이론도 아니다. 나는 내가 발견하거나 발명한 그 어떤 것도 제시하지 않았다. 반면 지식 시스템의 이러한 사용방식은 컴퓨터 과학이나 AI 에서는 사실상 표준적 관행이다. 내가 한 것은 지식의 그러한 개념을 우리가 사용하는 방식은 단지 관찰하고 그것을 명시적으로 만들었을 뿐이다.
지식의 이 이론이 특별한 저자 —— 특별한 발명가나 발견자 —— 없이 만들어졌다는 것은 주목할 만한 일이다. 이것은 주위에 있는 지식의 다양한 개념들을 정리하는 데 도움을 줄 것이다. 과학의 사회학적 구조, 그리고 더 광범위한 학문적 연구에서는 저명한 개인들에 의해 개념들 ideas 이 만들어지고 그 개인들은 그러한 개념들을 생산하고 전파하는 것에 대해 존경을 받고 보상을 받는다는 견해를 견지하고 있다. 개념들 자체에 대해 어떠한 견해가 있느냐 하는 문제와 관계없이 실제 발명된 것인지, 아니면 단지 발견된 것인지에 관계없이 개념들은 특정한 사람들의 중개 없이는 과학이나 사회의 일부가 되지 않는다. 누가 이 개념 또는 저 개념을 먼저 발견했느냐를 결정하는 데 어려움이 있을 수도 있다. 동시에 발견되는 진정한 사례들도 있을 수 있지만 (Merton, 1973) , 몇몇 특수한 과학자나 학자들의 집단이 여전히 그 공적을 얻게 된다. 그러나 현재의 사례는 이 틀에 맞지 않으며, 이 책에서 나중에 나타날 다른 것들, 즉 기호와 구성에 대해서도 마찬가지이다.
컴퓨터 과학자와 공학자들이 한 집단으로서 내가 주장했던 지식이론을 발전시켰다. 그 이론에 대해 어느 누구하나 제시하지 않았음에도 불구하고 그들은 그렇게 했다. 분명히 컴퓨터나 컴퓨터를 어떻게 다루어야 하는지에 대해 많은 글들 —— 고도의 전문적이고 창의적인 글에서부터 취미로 읽는 일반적인 글까지, 그리고 대중화시키거나 광고를 하는 글까지 —— 이 씌어졌다. 이러한 글들 중 얼마나 <저술> 로서 평가될 만한 새로운 개념들을 만들어놓는다. 이러한 경우는 과학의 표준적 견해와 완벽하게 일치하는 것이다. 저장된 프로그램 개념 stored program concept 은 일반적으로 존 폰 노이만 John von Neumann 의 공적으로 생각된다 (에니악 Eniac, 엑컬트 Eckert, 맥클리 Mauchly, 그리고 무어 학파 Moore school 와 관련된 사건들 때문에 이 점에 대해서는 약간의 논쟁이 있지만) . 그러나 저장된 - 프로그램 개념 (또는 구체화된 다른 개념들) 이 지식수준 시스템의 개념을 말하는 것은 아니다.
나의 1980 년 AAAI 회장 취임사 전에는 전산과학에서 명확하게 구체화된 지식수준의 개념이 없었다고 나는 알고 있다 (Newell, 1982). (주석 : 지향적 입장에 관한 데닛의 글은 1960 연대 후반까지 거슬러올라가지만, 적어도 이 점에 대해 컴퓨터 과학의 영향을 많이 받은 것 같지는 않다. 데닛 (1988a) 의 참고문헌을 보아라.) 그러나 그러한 개념의 사용이 보편화된지 —— 컴퓨터 과학자들이 그들의 프로그램들의 무엇을 알아야 하며, 그들이 무엇을 알아야 하는지에 대해 원칙적이고도 유용하게 말한지 —— 거의 20 년이 지났다. 내 논문의 역할은 그러한 관행에 목소리를 부여한 것이다 (그리고 논문에서도 그렇게 기술되어 있다). 물론 나는 1950 연대 중반부터 컴퓨터 과학과 AI 에 관계하고 있으면서 이 개념의 사용을 발전시키는 데 참여해왔다. 그리고 분명히 나도 과학적 논문을 저술하고 이론들과 개념들을 발표하는 역할을 해왔다. 그러나 그러한 개념들로서 지식을 사용하는 방법을 배웠다는 점에서 나는 공동체의 단순한 일부였다. 초기 논문으로부터 인용한 한 문장과 그것을 설명하는 주석이 여기 제시되어 있다 (Newell, 1962, p. 403) .
기계 안에서 어떤 것이 발생하기 위해서는 어떤 과정을 겪든지 그것을 발생시킬 수 있을 정도로 충분히 알고 있어야만 한다.
우리는 루틴 routines 의 <앎 knowing> 에 대해 이야기한다. 이것은 <이 루틴에서는 이러이러한 것이 사실이다라는 것을 가정할 수 있다> 라는 말을 바꿔 말할 것이다. 그것의 타당성은 프로그램 작성자가 부호화하는 방법에서부터 유래한다 —— 그 당시 프로그램 작성자가 알고 있는 것에 기초해서 연속적인 명령문들을 적어나간다. 루틴의 특정한 시점에서 프로그램 작성자가 알고 있는 것이 바로 그 루틴이 알고 있는 것이다. 다음의 대화는 이와 같은 것을 잘 보여준다.
(프로그램 작성자 A 는 루틴을 부호화하고 있는 B 의 어깨 너머로 쳐다보고 있다)
"너는 왜 적산기 accumulator 에 Z 5 를 더했냐?"
"나는 ??? 을 원했기 때문에."
"아니, 내가 말하는 것은 그것이 숫자인지를 네가 어떻게 알았냐는 것이야."
"모든 Z 는 숫자들이다. 내가 그렇게 만들어 놨다."
(B 는 이제 다음 명령어를 쓴다)
"너는 어떻게 그렇게 했지?"
"나는 루틴이 시작하는 곳에서 기억소자 (cell) 를 0 으로 만들었기 때문이야."
"그런데, 프로그램은 네 앞에 있는 이 곳으로 다시 돌아올 수 있는데!"
"아, 네가 맞다. 그 곳이 0 인지를 몰랐다."
물론 철학자들도 그들 자신의 전문적인 지식의 개념을 발전시켰지만, 내가 알기에 그 개념들은 컴퓨터 과학이나 AI 에서의 개념에 기여하지 않았다. 분명히 그들의 개념들은 특별한 것들이다. 여기서 지식이라 부르는 것을 철학자들은 신념 belief 이라 부른다는 점에서 분명한 차이가 있고, 철학자들은 지식이란 용어를 정당화된 참인 신념 justified true belief 을 표현하는 데 사용한다. 전문적인 공동체들이 그들의 관행에 의해 중요한 새로운 개념들을 획득할 때, 학문에 특이한 문제들이 제기된다. 예를 들면 철학자들은 통속 심리학 folk psychology 이라는 개념 (아마도 기발한 착상) 을 갖고 있다. 이것은 통속 —— 가르침을 받지 않은 대중 —— 적인 심리학과 과학에 의해 제공되는 심리학을 구분한다. 그렇다면 컴퓨터 과학자들이 사용하는 지식은 통속 철학 folk philosophy 의 일부인가? 중요한 것은 컴퓨터 과학자들이 글로 쓴 것이 아니라, 그들의 관행에 의해 그들의 그 개념을 사용하는 방식이라는 것은 명확하다. 똑같은 방식으로 철학자들이 사용하는 지식의 개념을 통속 전산과학이라고 생각할 수도 있다. 다른 경로를 통해서이지만, 철학자들이 먼저 그러한 개념을 갖고 있었다는 것을 제외하고는 상황은 동일하다. 이제 철학은 인지과학에 가짜 발 psudopod 을 들여놓았기 때문에 지식에 대한 이러한 두 관점은 다소 이상한 방법으로 혼합된다.
지식은 표상에서 추출되지만, 지식이 사용되고, 말해지고, 또 생각되기 위해서는 어떠한 방식으로든 표상되어야 한다. 그것은 어떤 특이한 주장에 의해 정당화된 하나의 특수한 철학적 진술처럼 보인다. 그러나 그렇지 않다. 이것은 지식수준 시스템들이 더 낮은 수준들에서도 동시에 기술이 가능하며, 물리적 세계에 존재하는 시스템들은 물리적 기술들을 갖는다는 단순한 명제이다. 그림 3 에 의하면 물리적 세계에 존재하는 지식수준 시스템은 프로그램 시스템, 레지스터 전송 시스템, 논리 시스템, 전자회로, 전자장치로서도 역시 기술될 수 있다. 물론 그림에서의 위계가 지식 시스템을 최상위에 놓는 유일한 위계는 아니다. 그림은 지식 시스템들을 포함한다고 우리가 알고 있는 하나의 위계를 보여준다. 다른 위계들도 역시 존재할 수 있다. 사실 우리가 알고 있는 어떤 컴퓨터 시스템보다도 지식수준 시스템으로서 더 잘 기술될 수 있는 인간의 경우에 있어서, 위계가 생물학적 계층들로 내려가야 한다는 점에서, 그 위계가 매우 다르다는 것은 확실하다. 현존하는 시스템들의 분석에 의해 그러한 위계를 발견하느냐, 아니면 지금까지 존재하지 않았던 시스템을 구성하고 설계함으로써 그러한 위계를 발명하느냐에 따라, 지식 수준을 지원하는 대안적 위계들의 존재를 확립하는 것은 과학적 과제 또는 공학적 과제가 된다.
|
가정
추론 |
그림 5 논리로 표현된 블록 세계
그러면 인지과학의 또 다른 기초적 개념인 표상의 본질에 대해 살펴보자. 명확한 것부터 시작하자. 지식을 표상하는 표준적 방법은 논리학에 의한 것이다. 그림 5 는 블록 세계에 대한 논리적 표상을 제시한다. 표상은 그림에 제시된 표현들로 구성된다. block 이라는 하나의 술어 predicate 가 있고, 그것은 A 는 블록이다, B 는 블록이다, C 는 블록이다, 그리고 탁자 T 는 블록이 아니다를 주장하는 데 사용될 수 있다. 또 하나의 술어 on 은 B 는 탁자 T 위에 있다, A 는 B 위에 있다, 그리고 C 는 T 위에 있다를 주장하는 데 사용될 수 있다. 또 하나의 술어, clear 는 block 과 on 에 의해 정의된다. 만약 x 가 블록이고, y 가 어떠한 블록이고, 그리고 y 가 x 위에 없다면 x 위에는 아무 것도 없다. 이 정보로부터 블록 B 위에는 아무 것도 없는 것이 아니라는 것을 추론할 수 있다. 그리고 만약 우리가 이것과 X 의 목표, Y 의 요구, 그리고 의사소통하는 X 의 능력에 대한 지식을 연결시킨다면, 우리는 X 가 Y 에게 B 위에는 아무 것도 없는 것이 아니라고 말할 것이라고 예측할 수 있다.
어떤 사람은 X 가 추론을 통해 간접적으로 아는 것이 아닌 관찰을 통해 직접적으로 not (clear B) 를 안다고 주장하고 싶을지도 모른다. 그러나 이것은 X 가 갖고 있는 지식과 X 가 이 지식에 대해 갖고 있는 표상을 혼동하는 것이다. 분명히 X 는 이 지식에 대한 어떤 표상을 갖고 있다. 그러나 그것이 그림 5 에 제시된 논리적 표상인지는 우리는 모른다. 사실상 만약 X 가 사람이고 당신이 심리학자라고 한다면 당신은 그렇지 않다고 확신할 것이다. 우리가 주장하는 것은 단지 이 논리적 표상이 X 가 갖고 있는 지식을 우리에게 말해준다는 것이다. 그 표상의 형태에 관한 것이나 또는 그림 5 의 개개 표현들이 X 의 표상에서의 어떤 특정한 것과 일치한다는 것을 말하는 것은 더더욱 아니다.
논리학은 단지 지식을 표상하는 하나의 방법임을 명확히 하는 것이 중요하다. 그것이 지식 그 자체는 아니다. 이 점을 알아보기 위해 그림의 표현 1 에 의해 표상된 지식을 K(1) 이라 하자. 그러면 X 가 갖고 있는 지식에 대한 표현 1, 2 그리고 K(3) 을 갖고 있다는 것을 명확히 알 게 된다. 어떤 사람은 우리가 표현이나 또는 지식에 대해 이야기하는 것이 아무런 차이를 만들지 못한다고 생각할 수도 있다. 그것들은 일 대 일 대응 one-to-one-correspondence 된다. 그러나 그것이 X 가 갖고 있는 지식의 전부는 아니다. X 는 K(4) 도 갖고 있다. K(4) 는 분명히 우리가 처음에 적었던 어떤 표현들 (즉, 1, 2, 그리고 3) 과도 대응되지 않는다. 표현 4 는 표현 1, 2, 그리고 3, 그리고 논리규칙들에서부터 추론될 수 있기 때문에 X 는 K(4) 를 갖고 있다.
논리학에 대한 일반적 상황은 쉽게 진술될 수 있다. 만약 X 가 표현들 K(1, 2, ???, M) 의 하나의 결합에 의해 표상된 지식을 갖고 있고, 표현 N 이 1, 2, ???, M 에 뒤따른다면, X 는 표현 N 의 지식인 K(N) 을 갖는다. 일반적으로 표현들의 결합을 뒤따르는 표현들의 수는 무한대가 되기 때문에, X 의 지식도 따라서 무한대가 된다. 그것 모두를 적을 수가 없다는 것은 분명한 일이다. 그러므로 X 의 지식을 그 지식의 표상으로서 확인할 수 있는 방법은 없다. 반면에, 논리를 사용해 우리는 X 의 지식을, 표현들의 유한집합과 더불어 X 의 모든 지식을 이루고 있는 다른 표현들의 무한집합을 생성하기 위한 과정 (논리의 추론규칙들) 으로써 표현한다.
논리학은 지식을 표상하는 많은 방법들 중 한가지라는 것을 아는 것 역시 중요하다. X 의 지식을 표상하기 위해 논리학을 사용하는 것은 의도적인 선택이다. 그것은 X 가 알고 있는 것을 표상하는 좋은 방법일 수도 있고 그렇지 않을 수도 있다. X 는 그것의 행동으로써 K(1), K(2), 그리고 K(3) 은 알고 있다는 것을 보여주지만 K(4) 의 지식을 나타내지 않을 수도 있다. 그렇다면 이 논리표상은 X를 기술하지 않는다. 그것은 X 가 모르고 있는 것을 X 가 알고 있다고 함의 할 정도로 너무 강력한 것이다. X 는 적혀진 표현의 집합에 정확히 표현된 것만을 안다는, 즉 부가적인 추론들이 허락되지 않는 표상만을 갖고 있다고 가정함으로써, 우리는 X 의 지식에 대한 새로운 표상을 만들려고 시도할지도 모른다. 어떤 목적을 위해서 이것이 유용할지도 모르지만 논리학은 추론규칙들의 집합을 갖고 있고, 그 규칙들의 자유로운 활용이라는 개념을 갖고 있기 때문에 논리학에 있어서 그것은 유용하지 않다. (주석 : 추론을 하는 시간에 제한을 줄 수 있도록 추론의 제한된 규칙들만을 갖고 있는 논리학을 이용하는 것에 최근 들어 약간의 관심이 나타났다 (Levesque, 1986).) 만약 앞서 한 이야기, 즉 X 는 K(4) 를 모른다는 것을 우리가 수용한다면 이 경우에서 수정된 방식은 X 가 알고 있는 것을 모르고 있는 것으로 함의하기 때문에 너무 약한 것이다. 그래서 우리는 X 의 정확한 지식 수준의 기술을 제공하는 다른 지식표상 방법들을 찾아내려고 할지도 모른다. 물론 그러한 표상을 우리가 찾을 수 있다는 보장은 없다 —— X 는 지식수준 시스템으로 표상이 가능하지 않을지도 모른다.
논리학이 많은 표상 방법 중 단지 하나에 지나지 않지만, 그것은 지식체계들의 일반적인 특성들을 반영하는 좋은 특성들을 많이 갖고 있다. 어떤 지식이 기존의 시스템에 포함되는 것 같이 두 개의 지식체계가 합쳐져 하나의 지식체계를 형성할 수도 있다. 이것은 논리학에서 표현들의 두 집합들의 연언 conjunction 과 일치한다. 만약 하나의 지식 체계에 정확히 동일한 지식에 더해진다면, 새롭게 만들어지는 지식은 없다. 그것은 동치 idempotent 인 연언에 반영된다 —— (A and A) , 만일 그리고 오직 A 인 경우 if and only if A. 특히 중요한 하나의 특징은 폭넓은 표상 범위의 암시이다 —— 일차 술어 계산법 first-order predicate calculus 과 같은 논리학에서 본질적으로 모든 지식은 표상될 수 있다. 이것이 암시하는 것은 다른 강력한 표상들 —— 특히, 집합이론 —— 이 논리학으로 형식화될 수 있다는 것이다. 그러한 충분성 sufficiency 은 그 지식에 표상되는 방법의 대가로 얻어진다. 실질적으로 논리적 계산법에서 표상되는 방법에 대해 많은 AI 연구들과 몇몇 철학적 연구들이 진행되어왔다. 연구를 진행하면서 부딪히는 많은 어려움은 우리가 표상하는 1 차 방법을 찾을 수 없다는 것이 아니라, 우리가 무엇을 표상학기를 원하는지 우리 스스로 이해하지 못함에 있다는 것이다. 또 다른 어려움은 표상이 빈번히 매우 다르기 불편하고 간접적이라는 것이다. 그렇기 때문에 많은 연구들은 사용하기 쉽고 좀 더 명확한 논리학의 대안적 형태들 (모형논리학 model logics, 고차논리학 higher - order logics, 정렬논리학 sorted logics) 을 찾으려고 시도한다.
단순한 블록 세계를 표상하는 다른 방법을 모색함으로써 표상에 관련된 것에 대해 우리는 좀더 명확해질 수 있다. 일반적 상황은 그림 6 에 제시되어 있다. 블록 세계가 발생하는 외부세계가 존재한다. 이 예에서는 블록 B 위에 있는 블록 A 를 블록 C 위로 이동하는 행위가 취해진다 (변환, T) . (주석 : 블록 B 위에 어떤 것이 있는지의 여부에 대한 앞의 예에 대해 나는 충실히 남아 있을 수 있었지만, 그것이 그 세계가 아니라 단지 알고 있는 행위자 안에서만 변경을 포함하기 때문에 그것이 다소 혼란스러웠을 것이다.) 외부세계말고도 다른 시스템이 존재하는데, 그것의 내부에 다른 하나의 상황, 블록 세계의 표상이 존재한다. 물론 이 내부상황도 똑같이 전체 세계의 일부이며 또 다른 내부 상황을 만들기 위해 변환되는 어떤 물리적 시스템으로 이루어진다. 문제는 여기에 있다. 내부 시스템이 외부세계에 있는 특정한 블록 상황의 표상이 되기 위해서 내부 시스템의 본질이 무엇과 같아야 하는 가이다.
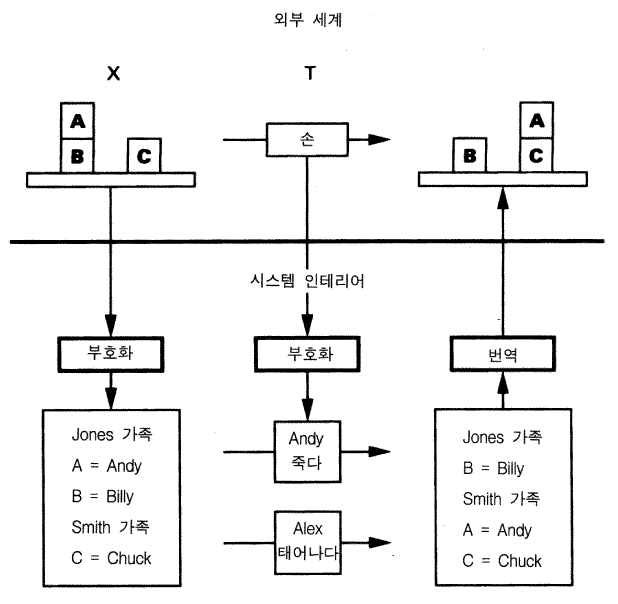
그림 6 블록 세계의 표상
나는 그림 6 에 있는 블록 세계를 표상하는 데 덜 익숙한 방법을 선택했다. 블록의 각 구성은 가족 —— 존스 가족과 스미스 가족 —— 과 일치하며 가족의 구성원들은 가장 어린 사람이 맨 위에 있도록 나이순으로 정리한 블록들이다. 변환은 사람이 죽고 또는 태어나는 것이다. 만약 앤디 존스는 죽고 알렉스 스미스가 태어나면 존스 가족은 단지 빌리만 있고 스미스 가족은 알렉스와 처크가 있다. 주어진 블록 B 위에 아무 것도 없는가라는 질문을 하는 것은 그 가족의 가장 어린 사람이 누구인지 물어보는 것과 같다. 초기 상황에서는 빌리가 가장 어린 사람이 아니었지만, 앤디가 죽은 다음에는 그가 가장 어린 사람이 된다.
외부 블록 세계와 가족 상황의 사이에는 분명한 일치가 있다. 특성의 일부는 일치하지만 (위에 아무 것도 없다, 그리고 가장 어린 사람이다), 모두 일치하는 것은 아니다 (블록은 정육면체냐, 어린이가 여자 또는 남자냐?). 변환의 일부는 일치하지만 (블록의 이동, 그리고 탄생 / 죽음) 모두 일치하는 것은 아니다 (블록은 떨어진다, 그리고 사람이 성장한다).
표상이 다소 이상하지만 —— 컴퓨터나 종이 위에다 우리가 그러한 표상들을 만들어낼 때 사용하는 명백한 방법들을 피하기 위해 나는 이 방법을 택했다 —— 사실상 그것은 당신이 생각한 것처럼 무리한 것은 아니다. 인류학의 오랜 전통에 의하면 (Laboratory of Comparative Human Cognition, 1982), 원시부족 사람들에게 분리된 isolated, 추상적인 논리적 과제들에 대해 추론하라고 하면, 그들은 추상적인 상황들을 다루려 하지 않고 단지 그들에게 완전히 익숙한 구체적인 상황들만을 다루려고 한다. 정말로 우리 자신의 사회에 속한 사람들에게도 그것은 사실이다. 삼단논법이 추상적으로 표현되어 있을 때, 좀더 구체적 용어로 표현되어 있을 때, 사람들은 삼단논법에서 더 잘한다. 예를 들면, 삼단논법 추리에 관한 실험을 보고하면서 존슨-레어드 Johnson-Laird 와 바라 Bara (1984, p. 20) 는 한 여자는 특정한 삼단논법과 일치하는 특정한 구체적 상황을 상상할 수 없었고, 그래서 그녀는 그 과제를 (실제로 그 각본은 가족을 포함했다) 다룰 수조차 없었기 때문에 그녀의 자료를 파기시켜야만 했음을 언급했다.
그림 6 에서 어떤 일이 진행되는지 추상적으로 기술해 보자. 초기의 외부 상황이 내적 상황으로 부호화된다. 외부 변환도 내부 변환으로 역시 부호화된다. 그 다음 내부 변환이 새로운 내부 상황을 획득하기 위해 내부 상황에 적용된다. 마지막으로 새로운 내부 상황이 외부상황으로 번역된다. 결과로 나타난 외부 상황이 외부 변환에 의해 생성된 상황과 동일하다고 가정하라. 그렇다면 내부 시스템 —— 부호화 과정, 내부 상황, 내부 변환, 그리고 번역 decoding 과정 —— 은 외부 상황의 표상으로서 성공적으로 사용된 것이다.
이것이 표상의 가장 근본적인 특성이다 —— 실물들이 가용하지 않을 때, 다른 경로에 의해 어떤 것에서 다른 것으로 갈 수 있는 것. 우리는 이것을 일반적 법칙으로 표현할 수 있다.
표상법칙 :
decode [encode (T) (encode (X)] = T (X)
여기서 X 는 실제 외부 상황이며, T 는 외부 변환이다.
이것은 일반화된 형태이기 때문에 유일한 표상법칙이라 불린다. 사실상 외부경로를 표상하는 수많은 특정한 부호화-적용-번역 경로에 대해 각각 하나씩 수많은 표상법칙들이 있다. 각각의 부호화-적용-번역 경로는 정확히 그것이 표상하는 외부경로의 측면들을 반영하기 위해 요구되는 것처럼 특이하다. 부호화와 번역과정들은 경로의 일부이기 때문에 그것들은 법칙의 본질적 부분이 된다. 부호화된 동일한 상황을 만들어내는 많은 다른 상황들이 존재하기 때문에 부호화의 다중 형태들이 존재할 수 있다. 동일한 외부 상황은 (때때로) 보이고, 들리고, 읽히고 또 느껴진다. 이와 마찬가지로 외부 상황과 상호작용하는 많은 다른 방법들이 있기 때문에, 번역에도 다중의 형태들이 존재할 수 있다. 동일한 외부 상황이 다른 것으로 확인될 (즉 검사될) 수도 있고 선택되고, 구성되고, 또는 기술될 수도 있다 (다른 어떤 것과 실제적 접촉은 남겨둔 채). 표상법칙 배후에 있는 중심적 주장은 만약 어떤 것이 표상으로써 사용된다면 위의 형태의 법칙은 내부 상황이 외부 상황을 표상하는 이유를 설명하는 필수적인 구성성분이 될 것이다.
표상 시스템은 또 하나의 다른 요건을 갖고 있다. 즉 내부 시스템은 어떤 방식으로든 통제되어야만 한다. 부호화, 내부 변환, 그리고 번역의 적용은 유기체의 목적을 만족시키기 위해 언제나 마음대로 또는 적어도 의지에 따라 충분히 실행이 가능해야 한다. 완전한 자유로움이 필요하지는 않아도 표상들은 유기체의 다른 활동에 도움을 주어야 한다. 그러므로 그것들은 적절한 시간과 장소에서 불러내어질 수 있어야만 한다. 만약 그림 6 의 가족 표상이 회상된 또는 현재 지각된 진짜 가족들에 의존한다면 (또는, 더 심하게 그것이 사람이 실제로 태어나거나 죽거나 할 때까지 기다릴 것을 요구한다면) 그것은 이 조건을 만족시키지 못한다. 반면 그림 6 은 표상 시스템이 유기체의 내부에 존재하지만 표상 시스템이 유기체의 내부에만 존재해야 할 필요성은 없다. 통제될 수만 있다면 표상은 어떤 외부 영역 —— 메모장, 주판, 컴퓨터, 또는 친구에게조차 —— 에서도 역시 발생할 수 있다.
표상에 대한 이와 같은 견해는 자연적으로 표상 시스템에 대한 다음과 같은 접근을 만들 게 한다. 유기체에게 표상을 요구하는 하나의 과제를 생각해 보자 —— 즉 그 과제는 즉시적으로 가용하지 않은 환경의 측면들에 의존하는 반응함수를 유기체가 생성할 것을 요구한다. 유기체에게 있어서의 (또 진화에 있어서도 차이가 없다) 문제점은 부호화의 번역을 위한 적합한 특성들과 변환을 위한 적합한 동역학을 갖고 있는 적합한 재료를 찾는 것이다. 만약 그러한 것들이 찾아지고 유기체의 통제 안으로 들어올 수 있다면 과제를 수행하는 데 요구되는 역할을 할 특수한 표상 시스템이 구성될 수 있다. 이것은 표상에 대한 유비적 관점 analogical view 이다 —— 각 표상 시스템은 그것이 표상하는 것의 하나의 유사물 analog 이다. 각 유비적 관점은 특수하다 —— 특정한 표상 요구에 대한 특정한 적응. 이 접근방법은 표상법칙을 적용함으로써 직접적으로 제기된다.
그러나 이 접근방법에는 어려움이 있다. 유기체가 더 많은 능력을 갖고 있을수록 (궁극적으로 우리 자신들) 더 많은 표상 방법들이 요구된다. 블록 세계에서 우리는 단지 블록에 대해서만이 아닌 그것의 색깔과 크기, 그것의 안정성과 모양, 그것의 면들의 패턴과 그 패턴들 간의 관계에 대해서도 반응하기를 원한다. 우리는 특성이나 관계에 대해서 뿐 아니라 변환들 transformations —— 한 블록을 다른 블록 위에 놓든지 또는 한 블록을 치우는 것을 넘어서서 블록들이 쓰러지는 것, 그것들이 서로를 지지하는 것, 그리고 그것들의 회전까지 포함한 —— 에도 반응하기를 원한다. 우리는 변환들의 연쇄들을 함께 합치고, 블록들을 타인에게 주고, 그것들을 색칠하고, 판매하고, 판매를 장부에 기재하고, 판매세금을 걷어서 지불함으로써 새로운 표상의 영역으로 들어가기를 원한다. 우리는 대리적으로 (우리의 머릿 속에서) 상호작용과 연쇄에서 이 모든 것들을 하기를 원한다. 더 많은 것들이 요구되면 적합한 역학을 갖고 있는 재료를 찾는 데 제약들이 더 엄격해진다. 표상되는 것들이 점점 다양해질수록, 그리고 그것들이 취할 연산적 변환들의 종류가 많으면 많을수록, 가능한 표상들을 찾는 일은 점점 더 어려워진다. 더욱더 많이 연결된 표상법칙들이 만족되어야 한다.
사실, 이것이 단순한 세상의 방식일 수도 있다 —— 바늘구멍이 좁아지면 좁아질수록, 성공적인 유기체들은 더 높은 표상능력들을 갖고 그 바늘구멍을 뚫고 나간다. 그것은 다른 고등유기체들이 크게 분리된 표상능력들을 갖고 있는 세계로 귀결될 수 있다. 종의 성공에 대한 문제의 수많은 교묘한 진화적 해결책들을 갖고 있는 생물학 세계의 다양성 안에는 그와 같은 것에 대한 단순한 암시 이상의 것이 있다. 하등유기체의 적응적 특성에 관해 말하는 생태학자들의 고전적 이야기는 그러한 묘사에 적합해 보인다 (Tinbergen, 1969) . 불행히도, 모든 적응은 표상을 요구하지 않고 나나니벌에서부터 큰 가시고기까지에 대한 예들은, 정확히 무엇이 표상적이고 무엇이 표상적이 아닌지를 쉽게 알 수 있게 구분되어 있지 않다.
이러한 방법일 수도 있었겠지만 그렇지는 않다. 그 대신 중대한 이동 Great Move 이라고 부를 수 있는 고도의 복잡한 적응 시스템을 획득하기 위한 대안적 경로가 존재한다. 표상적 요구들의 증가하는 다양성과 복잡성을 지원하기 위해 특수화된 동역학을 갖고 있는 점점 더 특수화된 재료들로 이동하는 것 대신 완전히 다른 방법이 가능하다. 그것은 다양성을 기록할 수 있고 요구되는 표상법칙들을 만족시키는 데 필요한 어떠한 변환들을 구성할 수 있는 중성적이고 안정적인 매체를 사용하는 것으로의 이동이다. 표상적 제한과는 달리 그 경로는 무제한의 다양한 표상들의 전체 세계를 개방시킨다.
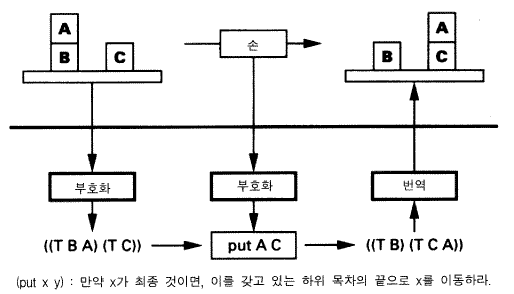
그림 7 블록 세계에 대한 목차 표상
그림 7 은 이 경로를 보여준다 .그것은 분명히 친숙하지만, 그렇다고 해서 그것의 중요성을 인식하지 못하면 안 된다. 표상매체는 하나의 목차 구조 list structure 이고 그 구조는 블록의 각 더미들에 대해 테이블 T 로 시작된 하위목록들을 갖고 있다. 그 표상 경로를 다시 한번 살펴보자. 우리는 외부 상황의 한 더미에 대해서는 T 와 C 를 갖고 있는 목록구조로 부호화함으로써 시작한다. 손의 동작은 목록구조를 변경시키는 내적 과정 (put A) 으로 부호화된다. <만약 x 가 그것의 하위목록의 마지막 항목이면, y 를 포함하고 있는 목록의 끝으로 그것을 옮겨라.> 일상적인 언어로 씌어졌지만 많은 독자들은 이 명령을 Lisp 로 즉시 기록할 것이다. 이 Lisp 프로그램은 외부 변환을 만족시키는 정확한 변환을 수행하도록 고정된 해석 방식 (Lisp 의 해석) 에 따라 구성된 하나의 표현이다. 물론 이 구성된 변환은 상황의 부호화가 어떻게 수립되느냐에 의존한다. 만약 맨 위의 블록들이 목록의 첫 번째 항목이고 테이블 T (불필요하게 됨) 가 생략된 것으로 만들어졌다면 (put x y) , 프로그램은 더 이상 표상법칙을 만족시키지 못한다 (정확히 못한다!) . 그러나 만족시키는 새로운 Lisp 함수는 쉽게 씌어질 수 있다. 기본적인 표상매체 —— 목록구조 —— 에서 블록 세계와 직접적으로 필요한 관계를 갖고 있는 것은 아무 것도 없다. 표상매체가 하는 것은 블록 세계 상황들의 각각에 대해 부호화하는 무한한 다양한 방식들을 제공하는 것이다. Lisp 함수들은 적합한 표상법칙들을 만족시킬 수 있도록 작성될 수 있다.
조합 가능한 변환들 composable transformations 에 관해 이야기하는 것이 무엇을 의미하는지를 우리는 잘 이해하기 때문에 이제 우리는 친숙한 기초 위에 있다. 그러나 50 년 전에는 그것이 멀게만 느껴졌었다. 사실 프로그램할 수 있는 시스템을 몰랐던 때는 적어도 50 년 전이다. 필요한 것은 매체 —— 그림 7 에서 그것은 목록구조이고, 상황들과 동일한 매체이다 —— 와 매체에 있는 구조를 받아들이고 명세된 과정을 수행하기 위해서 그것을 해석하는 해석기 interpreter 이다. 그것이 수행되는 방식은 상당히 자유롭다. 변환들을 구성하는 매체들은 상황들을 부호화하는 매체들과 동일할 필요가 없으며, 변환이 요구되었을 때 행위를 생성하는 매체와도 동일할 필요가 없다. 그것은 시작되었을 때 단순히 변환을 수행하는 특수-목적기계 —— 여기서는 (put x y) ——를 조합하기 위한 지시문들의 매체와 같을 수도 있다.
이 중대한 이동은 표상들과 조합 가능한 반응함수들 간의 연결을 만들어낸다. 만약 시스템이 함수들을 조합할 수 있고, 그것의 통제하에 한 영역에서 내적으로 그것을 할 수 있다면 그 시스템은 표상할 수 있다. 그것이 표상을 얼마나 잘하는지를 요구되는 표상법칙들을 따르는 함수들을 조합하는 그것의 능력이 얼마나 융통성이 있느냐에 의존한다 —— 조합 가능성 composabillity 에 대한 제한들이 있을 수 있다. 그러나 표상과 조합 가능성이 근본적으로 같이 연결된 것은 아니다. 만약 특수한 매체 안에서 적절한 (유비적) 변환들을 갖고 표상들이 실현된다면 조합 가능성이 전혀 필요하지 않다. 단지 중대한 이동을 하는 유기체에 대해서만 그 연결을 존재한다. 그러므로 그 연결은 완전하다.
조합 가능한 표상 시스템들은 충분히 중요하기 때문에 우리는 그것들의 요건들을 검토해야 한다. 첫째, 처리되는 매체는 적절한 다양성을 갖아야 한다 또한 그것들은 조합적으로 많은 상태들로 있을 수 있어야 한다. 그렇지 않다면, 그것은 충분한 범위를 제공하지 못하는데, 이는 세계가 다양성에 있어서 조합적이기 때문이다. 즉 세계에 존재하는 다양성은 많은 가능한 값을 갖는 많은 독립적인 속성들로 이루어져 있다 : 빨간 꽃들이 노란 꽃 옆에 있을 수 있고, 그 옆에는 파란 것이, 그리고 그것들의 키는 작거나 클 수 있고, 그리고 그것들은 산들 바람에 흔들릴 수도 있고, 가만히 있을 수도 또는 강하게 날릴 수도 있으며, 그리고 날씨가 더울 수도 추울 수도 있고, 지금 있는 것들이 한 시간 전과는 다르다는 것 등등. 그러므로 유기체의 세계는 조합적으로 많은 다른 상태들로 있을 수 있다. 기술된 것들 간에 상관관계가 있다고 해도 또 유기체가 환경에 단지 선택적으로 주의를 한다고 하더라도 (주석 : 선택적 주의는 다양성을 제한하는 역할을 하는 동시에, 세계의 상태와는 독립적으로 시스템이 이 곳 또는 저 곳에 초점을 집중시킬 수 있도록 허용함으로써 조합적 다양성에 기여하며, 그러므로 총 다양성은 (주의에서의 가능성) X (환경에서의 가능성) 이 됨을 주목하라.) 어떤 상황에서 부호화되어야만 하는 가능성들의 결과적 집합은 여전히 조합적이다. 그리고 만약 부호화되는 세계가 조합적이라면 매체 그 자체도 똑같이 조합적인 다양성을 보일 수 있어야만 한다 —— 이 말은 독립적으로 변할 수 있는 부분들의 집합이 있어야만 함을 의미한다.
둘째, 매체는 처리되는 것이 유지될 수 있도록 매우 높은 안정성 stability 을 갖고 있어야 한다. 그러나 그것이 변환될 때에는 변환이 의지에 따라 이루어질 수 있도록 낮은 안정성을 갖고 있어야 한다. 더 나아가, 유기체의 다른 행동들을 돕기 위해 의지에 따라 변환시키는 것은, 빈번히 그 변환 작업의 비용이 고려되지 않음을 함의하기 때문에 에너지 비용이 궁극적으로 행해질 행위에 비해 적절해야만 한다.
셋째, 가능한 변환들에 대해 완전성이 있어야 한다. 얼마나 많은 또는 어떠한 종류의 다양성이 변환에서 가능한지는 어떤 표상법칙들이 만족될 수 있는지의 문제로 직접적으로 연결된다. 그러나 질적인 다양성의 문제를 무시한다 해도 변환에서의 잠재적인 조합적 다양성의 문제가 (최소한) 그것들의 입력과 출력의 조합적 다양성에서 또다시 제기된다.
넷째, 이러한 변환들이 어떠한 시점에서 만들어져야만 되기 때문에 조합 compositions 을 결정하는 용이성은 중요하다. 새로운 행위에 대한 필요성이 다소 연속적으로 제기될 때, 특히 자세히 고려될 때 표상들의 요구는 제기된다. 좋은 표상 시스템은 표상이 요구하는 특성이 아니라 유기체가 원하는 것을 유기체가 그 시스템을 통해 할 수 있도록 하는 특성을 갖고 있다. 말하자면 유기체는 아무 것도 하지 않는 유추적 표상의 특징과는 반대되는 것이다. 그리고 표상이 요구하는 것이 바로 유기체가 필요로 하는 것이다. 그러므로 매체의 순응성 malleability 과 변환가능성 transformability 의 자유로움이 표상 시스템의 중요한 특질이다.
변환은 어떤 매체에 기록되고 그 매체는 그림 7 에서처럼 표상을 위해 사용되는 매체와 동일할 수도 있지만, 꼭 그럴 필요는 없다. 그것의 핵심적 특성은 실행가능성 executability 이다. 매체 그 자체는 피동적일 수 있고, 그러면 그것은 어떤 다른 과정에 의해 해석 가능해야만한다. 이것은 프로그래밍 언어에 있어서 친숙한 상황이다. 대안적으로 매체는 활동적일 수 있고 그러면 불러내어질 수 있어야 한다. 이 두 가지 경우 모두 두 개의 측면이 있는데, 조합되는 동안에 매체는 피동적이고 그 후에 통제 가능한 시기에는 활동적으로 바뀐다. 추가적으로 변환들은 조합되어야 하기 때문에, 매체는 표상매체의 좋은 모든 특성들을 필요로 한다. 변환을 조합하기 위해 조합 가능한 방식이 필요하고, 이것은 또 그것 자신의 매체를 요구하고, 그러므로 변환의 또 다른 하나의 수준이 요구되고 ··· 등이 되기 때문에, 여기에는 무한회귀가 있는 것처럼 보인다. 그러나 변환에 사용되는 매체와 표상에 사용되는 매체가 동일하다면 이 회귀는 즉시 중지된다. 그러므로 단지 하나의 매체만 있고 그것은 자기-적용적 self-application 이다. 이것은 표준적 프로그래밍 언어에 있어서 우리 모두에게 친숙한 상황이며 우리는 근본적인 어려움이 없다는 것을 안다. 다시 한번 50 년 전에는 중요했던 개념의 문제들이, 그러한 모든 생각들과 그것들의 기본적 결과들을 친숙하게 만드는 컴퓨터화된 세계에 우리가 살고 있기 때문에 지금은 그 중요성이 사라졌다.
우리는 표상을 위해 필요한 특성들에 초점을 맞춤으로써, 뒷문을 통해 계산 시스템에 도달하는 경로를 찾아왔다. 계산 시스템은 변환들의 조합가능성을 제공하는 바로 그러한 것으로 밝혀진다. 계산의 본질에 대한 논의를 내가 지금까지 당연하게 생각해왔던 기계의 개념을 가지고 시작하자. 일반적인 용어에 대해 자주 그런 것처럼, 하나의 표준적인 정의는 없다 할지라도 그것에 대한 이해는 충분히 일반적이어서 우리의 목적을 위해 적당한 정의가 만들어질 수 있다. 그림 8 의 A 에 상자로 간단히 제시된 것처럼, 상호작용하는 변인들의 한 집합에 의해 기술될 수 있는 물리적 세계의 한 영역이라는 시스템의 일반적 개념으로 시작하자. 만약 그 시스템이 입력과 출력을 다룰 수 있다면, 우리는 그것을 기계라고 부르는 경향이 있다. 그러므로 기계란 그것의 입력으로부터 출력으로서의 함수 (대응이라는 수학적 의미에서) 를 정의하는 어떤 것이며, 그것은 입력되었을 때 출력을 생성할 것이다. 입력이 주어지면, 출력이 결정된다. (때때로 출력은 단지 확률적으로만 결정된다. 그러나 그것은 우리의 목적에 대해서는 동일한 것이다.) 이것은 그림의 B 에 제시되어 있다. 처리되는 어떤 종류의 매체가 있고 입력되는 것과 출력되는 것이 있다. 물론, 이것은 시스템을 기술하는 —— 그것들에게 기술적인 descriptive 관점을 부여하는 —— 한 방법이다. 그러므로 우리가 일상적으로 하는 것처럼, 기계로서의 자동차에 대해 이야기할 때, 매체는 물리적 공간이고 입력은 한 위치에서의 탑승자들이고 그리고 출력은 또 다른 위치에서의 탑승자들이다. 우리는 시스템을 항상 기계로 보지는 않는다. 태양계는 분명히 시스템의 합당한 정의에 적합하지만, 우리는 일반적으로 그것의 어떤 측면은 입력으로, 또 다른 출력으로 나누지 않는다. 그래서 우리는 태양계를 기계로 보지는 않는다. 물론 기계로 볼 수도 있고 태양계를 인공위성들을 우주 멀리 내던지는 투석기로서 사용하는 것도 그럴 듯한 관점이다.
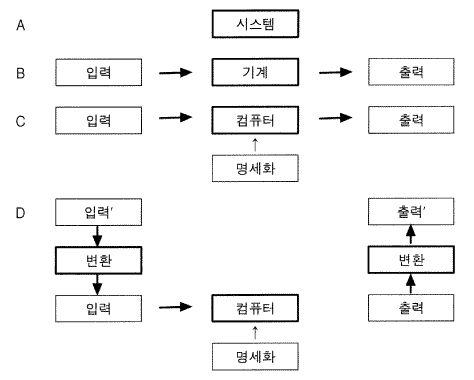
그림 8 시스템, 기계, 그리고 컴퓨터
기계의 그러한 개념을 가정한다면, 계산 시스템의 많은 함수들을 산출할 수 있는 기계로서 정의될 수 있다. 다시 한번 관점의 변화가 있다. 어떤 기계는 그것의 입력과 출력 간의 하나의 고정된 함수를 결정한다.어떤 기계는 입력이 주어졌을 때 함수에 의해서 함의된 것이 아닌 단순히 입력과 일치하는 출력을 산출한다. 그러므로 선험적으로 컴퓨터는 많은 함수가 아니라 하나의 함수를 산출한다. 그것이 많은 함수들을 산출하는 것으로 간주되기 위해서는 몇 가지 입력들은 생산되는 함수의 명세사항을 제공하는 것으로 여겨져야 한다. 이것은 그림의 C 에 제시되어 있다. 변환은 직접적이다. z = F (x,y) 인 기계로부터 z = f [y] (x) 인 컴퓨터가 형성되는데, 여기에서 y 는 이제 하나의 매개 변수이지 함수의 두 번째 논항 argument 은 아니다. 각각의 y 에 대해 시스템은 x 에서 z 로의 각기 다른 함수를 산출한다.
단순하지만 명확한 예는 소형계산기, 특히 HP 의 계산기와 같이 접미사 postfix 를 사용하는 소형계산기이다. 2 개의 숫자들 말하자면, 3 과 5 는 입력이다. 출력은 아직 결정되지 않았다. 그런 후에 또 하나의 단추가 눌러지면 연산 (주석 : (역주) operation 을 심리학에서는 조작으로, 전산학에서는 연산으로 번역한다. 본 글에서는 연산으로 번역한다.) —— 더하기, 빼기, 곱하기, 또는 나누기 —— 이 선택되고 이제 출력 —— 각각 8, -2, 15 또는 0.6 —— 이 계산된다. 계산되는 함수를 기계에게 알리는데 많은 다른 도식들 —— 접미사 (3 5 +), 접두사 (+ 3 5), 또는 삽입사 (3 + 5) —— 이 사용될 수 있기 때문에 이 예는 부호화의 임의적 본질도 명확히 해준다.
컴퓨터의 이러한 관점은 매우 일반적이지만 그것이 항상 사용되는 것은 아니다. 우리는 기계를 컴퓨터로 변환시키는 수단으로서 그 기계에 추가적 입력들을 항상 취하는 것은 아닌데, 이는 그러한 입력들이 기계를 통제하고 남아 있는 입력과 출력들 간의 관계를 변경시키는 경우에도 마찬가지이다. 예를 들면 TV 에는 명도조절 스위치가 있다. 이것은 분명히 또 하나의 입력이고, 그것의 입력이 비디오 신호이고, 출력은 화면인 TV 의 입력 - 출력 함수를 변경시킨다. 그러나 우리는 이것을 TV 를 조율 또는 조절하는 것으로 간주하지, TV 가 다른 함수를 계산하도록 만드는 것으로 간주하지는 않는다. 유사하게, 우리는 채널을 결정하는 TV 의 입력을 채널을 선택하는 것으로 생각하지, TV 가 계산하는 함수를 결정하는 것으로 생각하지 않는다. TV 가 컴퓨터가 아니라는 견해에 기여하는 몇 가지의 달리 사용되는 측면들을 확인하는 것은 쉽다. 연속성은 분명히 조율의 중요한 측면이다. 출력이 입력의 일부로서 존재한다는 것은 분명히 선택의 중요한 측면이다. 입력될 수 있는 함수의 변이의 폭이 넓으면 넓을수록 기계는 더욱더 컴퓨터 같이 보인다. 물론 그 문제는 언어적 용법의 하나이고, 그러므로 우리는 특징을 기술하는 것이 너무 단순한 것이라도 기대해서는 안 된다.
반응함수들을 구성하는 우리의 과제를 위해 필요한 것이 바로 계산 시스템이다. 다른 입력들이 주어졌을 때 그것들은 다른 반응함수들을 생성한다. 결론적으로 계산 시스템들은 표상과 연결되어 있다 —— 표상 법칙을 유지하기 위해 조합되는 변환에 의해 표상들이 형성된다고 가정한다면, 그러나 계산 시스템들이 본질적으로 표상하는 것은 아니다. 그것들은 표상하는 데 이용될 수 있는 장치들이다. 계산 시스템들이 표상 시스템들을 만드는 수단들을 제공한다는 것은 본질적인 것이다. 단지 조합된 변환들이 표상 법칙들을 따르기만 하면 표상이 만들어진다. 그리고 그 표상은 수행될 계산들을 결정하는 것에 의존한다.
계산 시스템에 관한 주요한 질문은 그것이 어떤 함수들을 생성해낼 수 있느냐이다. 그것은 시스템을 컴퓨터로 간주하는 것에 대한 관심이 요구에 의해 다른 함수들을 생성하는 것에 대한 관심이기 때문이다. 조합 가능한 변환들로의 중대한 이동은 바로 특별한 아날로그 표상들의 변이성의 한계들 때문에 필요하다. 그러므로 우리는 보편적 계산 시스템들 universal computational systems —— 보편적 튜링 Turing 기계 (Minsky, 1967) —— 에서 끝이 나는 친숙한 컴퓨터 - 과학 경로에 이르게 된다. 그것은 친숙하지만 표상, 조합 가능한 반응함수들, 그리고 지식 시스템들을 이해하려는 우리 사업의 관점에서 그것을 기술하기 위해 이 경로를 추적하는 것은 중요하다.
완벽한 계산 시스템은 가능한 모든 함수들을 생산해낼 수 있는 것이다. 그러나 약간의 어려움이 있다. 물리적으로 실현된 어떠한 컴퓨터라도 매체를 구체화하기 위해 고정된 배열을 갖고 있는 고정된 장소들인 고정된 입력과 출력 포트들에 구속되어 있다. 그림 8 의 B 와 C 는 추상적 시스템들을 예시한 것이기 때문에 편의상 그것에 관해서는 애매하게 되어있다. 컴퓨터는 모든 함수들을 제공할 수는 없고 기껏해야 단지 그것의 특정한 입력과 출력 간의 모든 함수들만을 제공할 수 있다. 표상, 계산, 그리고 그와 비슷한 것들의 일반적 문제를 논의하는데 있어 추상적인 경향을 띠고 논의된다는 것이다. 그래서 단지 대응 correspondence 에 대해서만 생각하고 특정한 입력과 출력영역들에 관해서는 생각하지 않는 경향이 있다. 물리적 실현은 중요한 제약이기 때문에 이러한 경향성은 확고하게 거부되어야 한다. 어떤 경우라도 그림 8 의 D 에서 보여주는 것처럼 원리상으로는 어려움이 적은 것이다. 형태와 위치에서 임의적인 어떤 입력' 과 출력' 이 주어지면 입력' 은 변환되어 컴퓨터를 위한 입력으로 전송되며 (컴퓨터의 입력 포트로), 그것은 그 다음 요구되는 함수는 제공함으로써 그것의 출력을 생성한다 (컴퓨터의 출력 포트에서). 그 다음 이 출력은 변환되어 원래 명세되었던 출력' 으로 전송된다. 물론 이러한 변환들 자체가 함수들을 제공하지만 그것들은 고정된 함수들이며, 그렇기 때문에 고정된 기계들에서 실현될 수 있다. 입력 변환의 책무는 실재의 입력' 을 그것이 존재했던 곳에서부터 컴퓨터의 입력이 존재하는 곳으로 가져와 모든 필요한 특징들을 유지하고 있는 컴퓨터에 대한 입력을 생성하는 것이다. 출력 변환의 책무는 컴퓨터의 출력을 위해, 그것의 형태를 출력' 의 형태로 전환시키고 그것을 원거리의 출력' 으로 보내는 것이다. 그러므로 그것들은 매체에서 대상들을 선택 select 하고, 이동 transport 시키고, 전환 transduce 시키는 (주석 : 이 맥락에서 전환 transduction 은 내용의 변경 없이 표상적 형태를 변경하는 것이다.) 고정된 변환들이다. 그것들은 컴퓨터가 하는 조합적 변환을 수행하지 않는다.
그러한 도식에도 역시 진정한 어려움이 있다. 입력과 출력영역들이 너무 커지만 모든 함수를 생성할 수 있는 시스템은 없다. 단순히 함수들이 너무 많다. 이것은 가능한 함수들의 수를 계산해 봄으로써 쉽게 알 수 있다. M 개의 다른 입력들과 N 개의 다른 출력들이 있다고 생각해 보자. 하나의 함수는 각 입력에 하나의 출력을 할당한다. 즉 M 개의 입력 각각에 대해 N 개의 가능한 출력으로부터 하나의 특정한 출력이 할당된다. 이것을 만들어낼 수 있는 방법들의 수가 함수들의 수이다. 그것은 NM , 또는 M 개의 입력 값들의 각각에 대해 독립적으로 N 개의 출력값들 하나씩이다. 그것은 특히 M 이 증가함에 따라 매우 빠르게 증가한다. 만약 N = 100 , 그리고 M = 100 이라면 이 둘은 매우 적당하지만 총합은 10200 으로 매우 큰 수이다. 이러한 증가는 하나의 정리 theorem 에 반영되는데, 만약 입력과 출력이 셀 수 있을 정도로 무한하다면 (입력과 출력이 무한히 확장된 과거 역사를 포함하는 값들을 갖는다면) 함수들의 수는 셀 수 없을 정도로 무한히 많아진다고 그 정리는 말한다 (Minsky, 1967) . 그러나 컴퓨터가 제공해주기를 바라는 함수는 또 다른 입력, 단지 셀 수 있을 정도로 무한한 입력에 의해서 명세화되어야만 한다. 그러므로 컴퓨터가 셀 수 없는 많은 수의 함수들을 계산할 수 있는 방법은 없다 —— 계산되어야 할 것이 명세조차 될 수 없기 때문에.
그 정리는 무한한 수를 다루기 때문에 유한한 시간을 갖고 있는 우리의 유한한 세계에는 관련이 없는 것처럼 보인다. 사실상, 계산 가능성 computability 의 이론은 단지 무한한 계산에만 적용되기 때문에 우리의 실제상황에는 관련이 없다는 비평이 자주 있다. 그러나 그 정리는 유한한 사례에 있어서도 존재하는 어려움을 지적하는 하나의 우아한 방법이다 —— 그리고 100 과 10200 의 대비에서 그것은 명백하다. 함수를 명세하기 위해 요구되는 입력의 양은 함수 그 자체에 대한 입력들과 출력들보다 매우 빠르게 증가한다. 그러므로 함수의 명세화는 컴퓨터가 계산할 수 있는 함수의 수를 제한하는 하나의 요소가 된다.
이 결과는 모든 가능한 함수들을 제공하는 컴퓨터에 대한 희망이 헛된 것이라는 것을 보여준다 —— 이것은 어떠한 함수들이 계산될 수 있는가 하는 질문에 가장 단순한 대답을 제공한다. 그러므로 이 질문을 계속 추구하기 위해서 우리는 함수들의 특수한 집합들을 특징지어야 하며 그러한 집합의 모든 함수들을 제공할 컴퓨터가 찾아질 수 있는가를 물어야 한다. 하위 수준에서는 어려움이 없다. 예를 들어 6 개의 기초적 삼각함수인, 사인, 시컨트, 코사인, 코시컨트, 탄젠트, 그리고 코탄젠트를 명세화하고, 그것들 모두를 할 수 있는 컴퓨터를 설계하는 것은 쉽다. 그러나 우리의 관심은 최상위 수준에 있다 —— 가능한 한 함수들의 큰 배열을 제공하는 컴퓨터들에게 있다. 여기에는 또 다시 어려움이 있다. 함수들의 집합을 명세화하는 어떤 방법이라도 결국은 그 집합에 대해 컴퓨터를 명세화하는 것이 될 것이다. 그러므로 계산될 수 없는 집합을 단지 그것이 정의되는 방식에 의해서 명세화하는 방법은 없을 것이다.
컴퓨터 과학이 이러한 명세화의 어려움을 다루기 위해 찾은 경로는 함수들의 집합으로부터 기계들의 집합으로 변경하는 것이다. 한 집합의 각 기계는 하나의 다른 특정한 함수를 실현한다. 그러므로 우리는 기계의 한 집합에 의해 실현된 함수들의 집합에 대해 이야기할 수 있다. 만약 기계들이 그것들의 성격에 있어서 매우 일반적이라면, 그것들은 그것에 대응되는 함수들의 일반적 집합을 정의할 것이다. 그러므로 이러한 집합에서의 하나의 기계가 그 집합의 다른 모든 기계들에 의해 실현되는 모든 함수들을 실현할 수 있는지를 물을 수 있다. 그러한 기계는 그 집합에 대해 보편적이라 불린다 —— 명세화에 따르면, 그 집합의 모든 기계들이 그렇다. <물론, 그러한 기계에 대한 입력들을 치하고 명세화를 제공하기 위하여 그것들을 사용하는 것이 필요하다.>
이 방법은 두 가지 좋은 특성을 갖고 있다. 첫째 논의하에 있는 함수들은 하나의 중요한 의미에서 현실적이다. 각 함수는 적어도 그 집합의 하나의 특정한 기계에 의해서 실현된다. 둘째 기계들을 구성하는 원리들에 따라 그것들은 매우 일반적으로 명세화될 수 있기 때문에 함수들의 집합들은 아주 클 수 있다. 예를 들어 물리적으로 생각하면, 화학적 분자들이 모여서 만들어진 모든 기계들을 정의할 수 있다. 이러한 화학적 기계들에 의해 정의되는 모든 함수들에 대해 이야기할 수 있을 정도로 그러한 개념을 갖고 정확히 작업하기 위해, 우리는 고전적인 화학 원자가 모형과 같은 분자에 관한 잘 정의된 개념을 채택할 필요가 있다. 또한 우리는 어떤 장소에서 어떤 분자가 입력이고 어떤 분자가 출력인지를 확인하는 어떤 개념적 방법을 역시 선택해야만 한다. 이것은 상당히 큰 함수들의 집합을 만들어내지만, 우리가 분자의 더 풍부한 화학적 개념을 선택했을 때, 얻을 수 있는 것만큼 그렇게 크지는 않다. 그러나 우리는 이러한 기계들의 집합들도 역시 생각해 볼 수 있다. 그러므로 우리는 매우 큰 함수의 집합들을 고려하는 최상위 수준에서도 작업할 수 있다.
그러한 큰 집합들에 대한 보편적 기계들이 존재한다고 밝혀졌다. 그 일이 우리에게 놀라운 것은 아닌데 이는 우리가 사실상 보편적 기계들인 일반적인 디지털 컴퓨터들에 익숙하기 때문이다. 물론 개념적으로 이것은 앞뒤가 맞지 않는다. 우리는 많은 다른 함수들을 만들어내는 디지털 컴퓨터들에 대해 우리가 믿어야 하는 것들에 관심이 있다. 우리는 사실상 컴퓨터는 엄청나게 다양한 함수들을 실현시킬 수 있다는 것을 입증하기 위해서 컴퓨터에 대한 우리의 직관들을 사용해서는 안 된다. 달리 말하면 보편적 기계의 존재는 우리에게 매우 큰 함수들의 집합들을 제공하는 컴퓨터가 존재할 수 있다는 확신을 준다.
이러한 결과들의 한계는 보편적 기계의 개념이 기계의 집합에 상대적이라는 것처럼 보인다는 것이다. 말하자면 기어와 도르래로 구성된 기계에 대한 보편적 기계가 있고 또 원자가 - 형태 분자들에 대한 보편적 기계가 있다. 이 두 보편적 기계들은 분명히 다르다. 그러나 이것은 제한점이 전혀 아님이 밝혀진다. 보편성의 연구들은 기계들을 정의하는 많은 다른 방식들에 대해 수행되어왔다 —— 여기에서 기계의 개념에 있어서 가능한 한 일반적이 되려고 한다. 컴퓨터 과학자들은 튜링 기계들, 마코프 Markov 알고리듬, 포스트 Post 산출 시스템들, 회귀적인 함수들 (이것은 기계의 한 형태로 볼 수 있다) , 디지털 컴퓨터의 많은 변형들 (임의 접근 random-access 기계들의 모형들과 같은 것) 등등을 분석해왔다. 이러한 매우 일반적인 기계들의 집합들에 대하여 보편 기계들은 항상 존재한다. 더 나아가 함수들의 집합들은 그림 8 의 D 에서처럼 일단 입력' 을 입력으로, 그리고 출력을 출력' 으로 변환시키는 능력이 주어지면, 항상 동일한 것으로 밝혀졌다. 결론은 물리적 장치 (기계들) 에 의해 실현될 수 있는 하나의 가장 큰 함수들의 집합에 있다는 것이다. 놀랄 일은 아니지만, 이것들은 계산 가능한 함수들 computable functions 로 불리게 되었고 그것들을 계산하는 기계들은 보편적 컴퓨터라고 말한다. 그러므로 어떤 함수들이 계산될 수 있는가라는 질문에 대한 답은 그리 간단하지는 않아도 매우 적당한 것으로 밝혀진다.
이론적인 컴퓨터 과학에서 이 문제가 형식화되는 방법은 가장 일반적인 기계의 집합에 대한 정의들의 다양한 집합으로 귀결되었다. 이러한 모든 것들이 함수들의 동일한 집합, 즉 계산 가능한 함수들을 만들어낸다는 것은 주목할 만하다. 이것은 처치-튜링 논제 Church-Turing thesis 라고 알려져 있다. 이것은 기계들의 집합을 특징짓는 비형식적 과정에 관한 것을 주장하기 때문에 정리가 아니라 논제로 남아 있다. 단지 형식화된 것에 관한 정리들만을 증명할 수 있다. 그러나 처치-튜링 논제가 정리로 되는 것을 막는 유일한 것은 물리적으로 실현 가능한 기계라는 것이 의미하는 것의 본질적인 특성들을 확정하는 데에 대한 거리낌인 것 같다.
우리는 보편적 컴퓨터의 이야기를 추적하기 위해 다소 긴 여행을 해왔다. 그것은 컴퓨터 과학이 이 주제에 관하여 당신에게 말할 것을 많이 갖고 있기 때문이고, 마음-같은 행동에서 그것은 융통성 있는 반응함수들을 획득하는 것이 역할 때문에 중요하다 (그림 1- 7 을 회상하라) . 우리는 극단적인 유연성 flexibility 을 생성할 수 있는 가능한 기제들이 어떤 종류인지를 이해할 필요가 있다. 보편적 컴퓨터들은 물리적으로 실현 가능한 시스템들 중 절대적으로 최대의 유연성을 제공한다.
표상과 계산의 논의에서, 기호들은 한번도 언급되지 않았다. 그것은 단순히 용어들의 선택으로서 받아들여질 수 있다. 기호적은 표상적과 본질적으로 동일한 의미를 갖는다고 정의될 수 있다. 표상하는 것은 무엇이나 기호적 기능을 나타낸다. 나는 이렇게 사용하지 않기로 선택했는데 이는 이 용법이 표현들이 나 다른 매체들에서 나타나는 일반적으로 기호라 불리는 것들과 밀접한 관계를 갖고 있는 중요한 문제를 흐리게 하기 때문이다. <The cat is on the mat> 에서 <cat> 은 특수한 고양이를 표상하기 위해 사용되는 것처럼 기호는 분명히 표상하기 위해 사용된다. 그러나 단지 그런 것 이상의 무엇이 있다.

그림 9 기호 토큰들은 처리되는 구조들의 부분들이다
기호들보다는 기호 토큰들 symbol tokens 에 먼저 초점을 두자. 기호는 토큰들의 집합에 대한 추상적 동치집합들이다. 토큰은 처리되는 매체의 부분들로서 —— 표현들이나 구조들 안의 영역들로서 나타난다. 몇 개의 예들이 그림 9 에 제시되어 있다. 특정한 단어들은 특정한 문장들의 부분들이다. 숫자, 문자, 그리고 연산-기호 operation-mark 토큰들은 방정식의 부분이다 ···. 앞의 두 절에서 살펴본 표상이나 계산에 대한 분석에서는 기호토큰과 같은 것에 대한 필요성이 없었다. 우리가 표상들을 만들 때 우리는 왜 토큰들을 포함한 배열들을 그렇게 자주 만들어낼까?
어떤 일이 진행되는지에 대한 단서로서 기호는 어떤 것을 나타내고, 구조의 어떤 위치에 나타난 토큰은 그 위치 때문에 규정된 맥락에서 어떤 것을 나타낸다는 해석을 수반한다는 표준적인 견해를 고려해보자. 적어도 그것은 구조를 처리하기 위해 요구되는 지식이 그 시점에서 부분적으로 가용하지 않음을 뜻한다. 토큰은 그 지식체계의 대응물이다. 지식 자체는 다른 어떤 곳에 있다. 그 지식이 어떻게 그 시점에서 사용되는지는 국소적 맥락과 지식 자체의 함수이며, 그 사용은 단지 그 지식이 획득되었을 때 결정될 수 있다. 확실한 것은 지식이 접근되고 인출되어야 한다는 것이다.
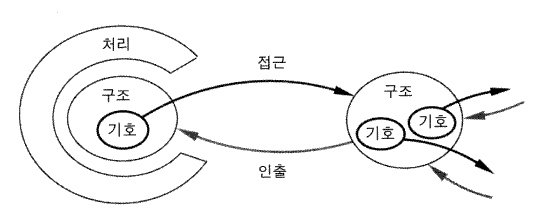
그림 10 기호들은 원거리 접근을 제공한다
그림 10 은 일반적 상황을 제시한다. 물리적 세계에서의 처리는 언제나 국소적이다. 즉 항상 물리적 공간의 제한된 지역에서 이루어진다는 것은 자연의 법칙이다. 이것은 원거리에서는 행위가 없다는 것 좀더 명확히 말하자면, 인과관계의 효과가 진동에서의 빛의 속도인 최고속도 C 로 전파된다는 것과 동일한 것이다. 결과적으로 어떠한 계산 시스템이라 하더라도 궁극적으로는 공간의 제한된 영역에서 제한된 처리에 의해 작업을 한다. 그 처리과제를 안내하고 결정하는 것도 역시 국소적이어야 한다. 만약 과제가 충분히 작고 간단하다면, 과정들은 국소적 영역 안에서 조합될 수 있고 과제는 달성될 수도 있다. 궁극적으로 이러한 방식 이외의 대안은 없다. 그러나 처리가 충분히 복잡하다면 처리 중 어떤 시점에서는 국소적 영역밖에 있는 추가적인 구조가 요구될 것이다. 만약 그것이 요구되면 그것은 획득되어야 한다. 만약 그것이 획득되어야만 한다면 어떤 과정들이 언제 어떻게 밖으로 나갈 것인지를 결정하기 위해 국소적 영역 내에 있는 구조를 사용해 그것을 실행해야 한다.
기호 토큰은 더 많은 구조를 획득하기 위해 국소적 영역 밖의 어느 곳으로 가야 하는지를 결정하는 매체에 있는 장치이다. 그 과정은 두 단계를 갖고 있다. 첫째 요구되는 원거리의 구조에 대한 접근의 단계, 그리고 두 번째로 그 구조를 원거리에서 국소적 위치로 인출 (이동) 해서 그것이 실제적으로 처리에 영향을 줄 수 있도록 한다. 밖으로 나가는 시기는 처리가 결여된 구조를 요구하는 방식으로 기호 토큰을 만나는 시기에 의해 결정된다. 그러므로 <The cat is on the mat> 를 처리할 때 (이 자체가 하나의 물리적 구조이다) 국소적 계산은 어느 시점에서 <cat> 을 만난다. 그것은 <cat> 으로부터 <cat> 과 연결된 (부호화된) 지식체로 가서 지시된 것은 고양이이다. 또는 단어 <cat> 은 <명사이다> (그리고 아마도 다른 가능성들) 등을 표상하는 어떤 것을 가지고 돌아와야만 한다. 어떤 지식이 인출되고 그것이 어떻게 조직화되느냐는 처리 방식에 정확히 의존한다. 모든 경우에 있어서 토큰 <cat> 의 구조는 정확히 요구되는 모든 지식을 포함하고 있지 않다. (주석 : 물론, 그것은 그 지식의 일부를 포함할 수 있다 —— 기호 토큰들은 부호 codes 일 수도 있다. 지식을 토큰으로 부호화하는 장점은 그림 10 에서 명백한데, 이는 그것이 접근과 인출의 필요성을 회피하기 때문이다.) 그것은 다른 곳에 있고 접근을 통해 인출되어야 한다.
이러한 설명에 숨겨져 있는 것은 정보이론 배후에 있는 기본적 명제, 즉 주어진 기술에 있어서 물리적 공간의 주어진 영역을 차지할 수 있는 부호화의 양은 제한된다는 것이다. 정보이론에서 그것은 통로 channel 또는 기억용량으로 표현되고 그것은 비트로 측정된다. 그러나 구조에서의 차이를 탐지하는 데 사용될 수 있는 에너지의 양에 제한이 있다면 (이것은 관련된 부호화 기술의 측면이다) 그것의 기초는 물리적 구조에 있어서의 다양성의 일이다. 이 제한은 비연속적이든 연속적이든, 모든 시스템들에 적용된다 (Shannon, 1949). 그러므로 다양성에 대한 요구가 증가할수록 —— 궁극적으로, 조합되는 함수들에 있어서 다양성에 대한 요구에 대응해 —— 국소적 용량이 초과될 것이고 다른 곳에 존재하는 다양성에 대한 원거리 접근이 요구될 것이다. 추가적 지식이 필요함을 지적하고 그것을 어떻게 획득하는지에 대한 단서를 제공하는 것이 국소적 위치에 있어야 한다. 원거리 접근을 제공하는 기호 토큰들이 포함된다는 의미에서 복잡한 시스템들은 기호 구조들을 요구한다는 이 요건은 표상의 개념과는 분리된 것이다. 이것은 처리의 제약들로부터 제기된 것이지, 외부세계와의 관계를 수립하는 제약들에서부터 제기된 것은 아니다.
그림 10 에 제시된 방식은 기호 토큰들을 우리가 일반적으로 생각하는 것처럼 그 위치에서 처리가 일어날 때 요구되는 원거리 자료에 접근하기 위해 사용되는 구조의 영역들로서 나타낸다. 다른 대안들도 가능하다. 예를 들어 드럼 기계의 방식에서처럼 요구에 의한 개별적인 접근들 대신 기억을 전체적으로 둘러보기가 정기적으로 일어날 수도 있다. 이런 종류의 균일한 접근 과정은 필연적으로 개별적 접근들에 비해 덜 효율적인 것처럼 보이지만, 효율성은 기초를 이루는 기술에 의존한다 (일례로 드럼 기계는 그러한 방식을 강요한다). 어떤 경우에서도 그러한 기호 시스템들은 윌에게 친숙한 기호 시스템들의 종류와는 다소 다르게 보일 수 있다.
|
기억 기호 토큰들을 포함하고 있는 구조를 포함한다 어떤 최소 (grain) 크기로 독립적으로 수정 가능하다
기호들 원거리 구조들에 접근을 제공하는 패턴들 하나의 기호 토큰은 하나의 구조에서 하나의 패턴의 출현이다
연산들 기호 구조들을 입력으로 받아들이고 기호 구조들을 출력으로 생성하는 과정들
해석 기호 구조들을 입력으로 받아들이고 연산들을 실행하는 과정들
용량들 충분한 기억과 기호들 완전한 조합 가능성 완전한 해석 가능성 |
그림 11 기호 시스템
우리는 드디어 인지과학의 친숙한 개념인 기호 시스템에 도착했다 (Newell & Simon. 1976 ; Newell, 1980a) (주석 : 그것들의 기원이 철학이나 인문학에서의 일반적 사용법이 아니라 컴퓨터 과학과 인공지능에 있음을 강조하기 위하여, 그것들은 물리적 기호 시스템이라고 자주 불린다. 현 맥락에서는 더 짧은 구절도 관계가 없을 것이다.). 그림 11 은 필수적인 구성 요소들의 목록이다. 기호 시스템은 일종의 보편적 계산 시스템이다. 이 특정한 형태는 계산 시스템의 명세화에 일반적으로 수반되는 매우 특정한 배열들 즉, 순차적 테이프, 판독 헤드 reading head, 그리고 튜링 기계의 다섯-튜플 five-tuple 과 같은 것들을 피하면서 그러한 시스템에서 주요한 가정들을 명확히 하고 있다 (Minsky, 1976).
기호 토큰을 포함한 구조를 갖고 있는 기억이 있다. 기억이 조합적 다양성을 다룰 수 있어야 한다는 요구 때문에, 기억은 구조의 어떤 최소 단위 크기에서 독립적으로 수정될 수 있다. 최소 단위 크기 안에서 구조들은 여러 가지 의존성을 보일 수 있으므로, 구조의 일부분에서의 변경은 다른 변경을 일으킨다. 언어적 표현들과 자료구조들의 형태에 관한 제약들은 바로 이러한 국소적 의존성이다. 기호 토큰들은 원거리 구조들, 즉 기억의 다른 구조들에 접근을 제공하는 기호구조들에서의 패턴들이다. 그것들은 추가적인 Lisp 표현들의 획득을 가능하게 하는 주소 addresses 인, Lisp 에서의 기호들과 유사하다. 다른 구조들로부터 구조들을 조합하는 기호 연산들 symbol operations 이 있다. 어떤 것은 새로운 구조를 만들고 다른 것들은 옛 구조를 변경하는 것처럼, 이러한 연산에는 많은 변형들이 있다.
어떤 기억구조들은 (필연적으로 모두는 아니다) 기호연산의 연쇄가 특수한 기호구조들에 대해 발생하는 것을 결정하는 특성을 갖고 있다. 이러한 구조들은 프로그램 programs, 계획 plans, 그리고 절차 procedures 등 다양하게 불린다. 연산을 적용하는 과정을 기호구조를 해석한다라고 부른다. 해석은 다양한 방법으로 일어날 수 있다. 프로그램은 각 순차적인 연산을 결정하기 위해서 읽혀질 수 있고 그러면 각 연산은 호출된다. 대안적으로 프로그램은 다른 프로그램으로 번역될 수 있고 이것은 해석된다. 또 하나의 대인은 연산들을 포함하고 있는 특별한 특수-목적 기계를 구성한 다음 이것을 실행시키는 것이다. 이 모든 것들은 동일한 것으로 귀결된다 —— 기호구조로부터 행동으로 전환시키는 능력, 이러한 행동은 행동을 안내하는 다른 기호구조들을 형성할 수 있기 때문에 이것은 기호구조들로 구체화된 표상법칙들을 따르는 능력과 요구되는 표상법칙을 구체화하는 새로운 기호구조들을 만들어내는 능력을 제공한다. 그러므로 기호연산들을 표상하는 구조들의 해석은 함수들을 조합하고, 그러므로 표상하는 능력을 제공한다.
이러한 매우 일반적인 처리구조에서, 유일하게 추가되는 요건들은 충분성과 완전성 completeness 의 특성들이다. 충분성의 측면에서는 충분한 기억과 충분한 기호들이 있어야 한다. 자원이 불충분하면, 단순히 시스템의 자원이 부족하기 때문에 시스템이 수행할 수 없는 복잡한 변환들이 생성될 수 있다. 완전성의 측면에서는 두 가지의 요건이 있다. 첫째 완전한 조합 가능성이 있어야 한다. 연산들은 어떠한 기호 구조라도 구성할 수 있도록 가능하게 만들어야만 한다. 둘째 완전한 해석 가능성 interpretability 이 있어야 한다 —— 연산행위의 어떠한 배열이라도 결정할 수 있는 기호구조들이 가능해야 하고 해석과정들은 기호구조들에 의해 주어진 연산들을 호출할 수 있어야 한다. 이러한 형태의 완전성 없이는 기호 시스템이 할 수 없는 다양한 것들이 있을 것이고, 그래서 그것은 보편적 기계가 되지 못할 것이다. 이 두 가지 형태의 완전성은 어떤 의미에서라도 즉각적일 필요는 없고 길고 우회하는 처리를 필요로 할지도 모른다 —— 단순히 기계가 결국 그 곳에 이를 때까지.
명세화가 매우 명확하지 않은 것처럼 보여도 그것이 기호 시스템에 대한 모든 것이다. (주석 : 나는 기호 시스템들의 기능적 특성들을 강조했다. 그러나 여기에는 취급하지 않은 구현 implementation 요건들도 여기 있다. 중요한 것은 신뢰성이다. 구조들은 안정적이어야만 하며 연산들은 항상 동일한 것을 해야만 한다. 신뢰성의 어떤 실패는 치명적이지는 않지만, 그것은 용장도 redundancy 와 검증을 포함하는 연산의 형식을 함의할 수 있다.) 기호 시스템은 모든 계산 가능한 함수들을 생성할 수 있을 정도로 충분하다 (그것은 보편적이다) . 그것은 그것이 가능한만큼의 유연성을 갖는다. 그러나 만약 표상되는 지식이나 목표들의 다양성이 충분히 크다면, 기호 시스템도 역시 보편성을 획득하고 원거리 접근을 획득해야 한다.
아직 기호 시스템에 대한 하나의 문제가 남아 있는 것 같다. 기호 시스템에서의 기호는 기호 시스템의 외부세계의 대상을 지시하는, 의미적 기능 semantic function 을 어떻게 획득하는가? 기호 시스템에서의 접근은 내적 연산이다 —— 기호는 여전히 시스템의 내적 기억에 있는 또 다른 기호구조에 접근하게 한다. 기호가 실제적으로 시스템 그 자체의 외부에 있는 어떤 것을 지시하고, 표시하고, 나타내고, 의미하고, 또는 그것에 관한 일이라는 것이 도대체 어떻게 발생하는 것인가? 철학에서는 브렌타노 Brentano (1874) 이래로 그것을 지향성 intentionality 의 문제라고 부르고 있다. 이것은 여전히 인지과학에서 우리와 함께 있다. 이 장에서의 계산과 기호 시스템에 대한 견해와 근접한 견해에 동의하는 필리신 Pylyshyn (1984) 조차도 기호들이 어떻게 외부 대상들에 관계되는지 불명확하다는 입장을 여전히 유지하고 있다. (주석 : 그러나 기초들에 관한 포더와 필리신 (1988) 에서의 최근의 거리는, 필리신은 더 이상 이것을 문제로 여기지 않음을 보여주는 것 같다)
여기서 만들어진 틀에서의 문제는 직접적인 것처럼 보인다. 지식 시스템들부터 시작하자. 지식은 특징된 시스템의 외부에 존재하는 영역에 대한 것이다. 블록이 탁자 위에 있다는 지식을 갖고 있다는 것은 블록과 탁자에 관한 지식을 갖고 있다는 것이다. 지식은 그것의 행동을 외부환경과 관련해서 계산할 수 있는 (관찰자에 의해) 시스템을 기술하는 한 방법이다.기호 시스템은 지식 시스템을 실현한다. 적어도 그것들중 일부는 그렇고, 여기에서의 관심은 그러한 것들이다. 그것들은 물론 단지 근사적으로 그러하다 —— 우리는 이 문제를 다시 다룰 것이다. 그러므로 기호 시스템은 그것이 실현하고 있는 지식 시스템들이 관여하고 있는 동일한 외부 대상들에 관여한다. 결국 이것은 단순히 두 가지의 다른 방식으로 기술된 동일한 시스템이다. 기호 시스템은 표상법칙들을 실행함으로써 지식 시스템을 실현하고 기호구조들은 외부 세계에 관한 지식을 부호화한다.
지식 시스템을 충분히 면밀하게 추정하는 기호 시스템을 만드는 방법에 대한 자세한 사항들을 제외하고는 그것이 지향성에 관해 말해지는 전부이다. 세부사항들도 분명히 중요하지만 그것들은 어쨌든 세부 사항들이다. 단지 기호 시스템이 지식 시스템을 실현하는 것이 가능하지 않을 때만 문제가 있는 것이다.
그러나 지식 시스템이 외부세계에 관한 특수한 지식을 어떻게 획득하는지 질문해 보자 —— 이러한 특수한 지식이 대응되는 기호 시스템에서의 기호들이 된다. 지식수준에서의 답은 정보를 제공해주지 못한다. 지식은 필요한 외부세계에 대해 알고 있는 다른 지식의 출처들로부터 얻어진다. —— 그 밖에 다른 방법이 있을까? 그러나 기호수준에서 이 질문에 답한다면, 그 답은 좀더 유용하다. 그림 2 의 블록 세계의 상황에서 Y 는 블록 B 위에는 무언가 있다는 것을 알 게 된다. Y 의 내부에는 그 지식을 지지하는 표상이 있다. 그 표상은 B 에 대한 기호와 B 위에는 무엇이 있다는 표현을 포함한다. 그리고 B 에 대한 기호는 B 에 관한 것, 적어도 B 에 관해서 충분한 것이므로 B 위에 무엇이 있다는 Y 의 지식은 B 에 관한 것이다. 더 많이도 더 적게도 아니다. Y 는 B 위에 무엇이 있다는 것을 어떻게 알아차렸을까? X 가 Y 에게 말했기 때문에 Y 는 그것을 알았다. X 는 B 위에 무언가 있다는 것을 어떻게 알았나? X 는 B 를 관찰했기 때문에 그것을 알았다. 그 관찰이 어떻게 X 에게 지식을 제공했는가? 블록 B 에서 반사된 빛이 X 의 눈에 도달해서 ···. 궁극적으로 대상과의 어떤 물리적 접촉이 있다. 그것은 물리적 법칙들과 사실들에 대한 다양한 다른 지식에 의해 지지되는 행위자들의 모임을 통해 제공된다. 그러나 우리의 물리적 세계의 법칙들은 물리적 영향력이 (주석 : 물리적 법칙들과 다른 귀납법들에 의해 추측한다면, 그것은 물론 선행사건의 영향일 수 있다.) 있어야 함을 의미하고 있다. 만약 한 행위자가 완전한 물리적 고립상태에 있다면 궁극적으로 아무 것도 알 수 없게 된다. 또한 신뢰와 가정의 문제도 제기된다. 왜 Y 는 X 가 Y 에게 말한 것을 믿었나? Y 는 그 신념에 대한 근거가 있었나? 이러한 문제들은 실재적인 것이고 또 지식이 타당하거나 신뢰할 수 있는지에 영향을 주지만, 그것들은 때때로 지식이 전달되는지, 그리고 그 지식에 기호들의 의미적 기능이 포함되어 있는지의 여부에는 영향을 주지 않는다.
지식수준의 추정 approximation 과 실현 가능성 realizability 의 문제로 되돌아가자. 컴퓨터 - 시스템 위계의 모든 수준에서 (그림 3), 하위 수준으로부터의 기술은 그것의 상위 시스템의 실현에 대해 정확하지 않다. 그것은 지식수준을 실현하는 기호수준, 프로그래밍 수준을 실현하는 레지스터 - 전송 수준 또는 그 어떤 것에 대해서도 그렇다. 그래서 기호 시스템은 단지 지식수준을 추정한다. 결과적으로 그것은 외부세계에 관한 것에 대해서는 완벽하지 못한 작업을 한다. 이 점은 중요할 수 있다. 예를 들면 컴퓨터 산술은 특정한 반올림 방식을 갖는 제한된 - 정확률 소수점 산술이다. 우리는 일반적으로 기계산술이 실제 산술을 나타내는 것처럼 기계산술을 사용한다. 물론 이것은 단지 실제산술을 추정하며 중요한 계산 작업에 대해서는 반올림 오류와 그것의 전파에 대한 분석이 요구된다.
지식수준 시스템과 관련된 추정은 다소 특수한 것처럼 보일 수도 있다. 이러한 느낌이 드는 이유 중 하나는 지식은 그것의 표상에서 논리적 표현들의 집합의 함축적 종결에 의해 함의되는 것처럼, 거의 항상 무한하다는 것이다. 제한된 장치가 무한한 집합을 실현할 수 없기 때문에, 지식 시스템은 본질적으로 기호수준 시스템에 의해서 실현될 수 없다고 말해질 수도 있다. 그것은 사실이지만 다른 수준들도 충실하게 실현될 수 없는 본질적 이유들도 사실이다 —— 실패율이 0 인 컴퓨터는 왜 있을 수 없는가 또는 디지털 회로의 결정 시간 settling time 이 제한된다는 것은 왜 보장되지 않는가. 추정에 대한 긴급한 질문은 특정한 사례나 실례에서 어떻게 좋은 추정을 달성하느냐 이다. 이 문제에 대해 간단하거나 단일한 답은 있을 수 없다. 어떤 의미에서는 AI 의 전영역이 지식수준의 면밀한 추정을 허락하는 기호수준 기제들을 발견하는 데 전념하고 있다.
구성 architecture 은 이 책에서 핵심적인 개념이다. 통합인지이론들은 구성으로서 형성될 것이다. 왜 그런가는, 심사숙고하지 않는다면 명백하지 않을지도 모르지만 우리가 앞으로 진행해 나감에 따라 좀더 명백해질 것이다. 마음의 구성은 한 사람 안에서 그리고 사람들 간에 행동의 공유성을 보이도록 하는 중요한 원인이다. 그러므로 우리는 구성이 무엇인지에 대해 더더욱 명확히 할 필요가 있다.
구성은 기호 시스템을 실현하는 고정된 구조이다. 컴퓨터 - 시스템 위계 (그림 3) 의 맨 위에 지식수준이 있고 그 밑에 기호수준 또 그 밑에 레지스터 - 전송 수준이 있다. 그러므로 레지스터 - 전송 수준에서의 시스템 기술이 구성이다. 좀더 정확히 말하면 기호수준에서 무엇이 고정된 기제 (하드웨어) 이고 무엇이 내용 (소프트웨어) 인지가 레지스터 - 전송 수준에서의 시스템의 기술에 의해 설명된다. 물론 컴퓨터에 대해 개발된 친숙한 시스템 위계와는 다른 시스템 위계가 존재할 수도 있고, 그렇다면 구성은 그것에 따라서 정의되어야 한다. 이 문제를 일반적으로 진술하면 기호 시스템이 주어졌을 때, 구성은 어떠한 시스템-기술 방식에서든지 기호수준 바로 밑에 존재하는 수준에서의 시스템의 기술이다.
|
생애 109 초 발달 106 초 구성 변화? 기술 획득 103 초 지식 획득 10 초 ——————————————————————————————————— 수행 1 초 잠정적 저장 10-1 초 고정된 구조 초보적 행위들 10-2 초 |
그림 12 고정된 구조는 비교적 느린 변화를 의미한다
위에서도 살펴본 바와 같이, 구성은 고정된 구조이고 진실로 변하지 않는 것처럼 통상 말해지고 있다. 표준적 디지털 컴퓨터의 경우, 이것은 거의 진실이지만 미시코드 microcode (주석 : (역주) 중앙처리장치나 각종 제어 장치의 제어를 하기 위한 미시 프로그램이나 그 미시 프로그램을 기술하기 위한 미시 명령을 말한다. 기계어 명령을 해석하고 처리 장치 내의 데이터 전송 등을 한다.) 의 수준들을 갖고 있는 시스템들에서처럼 그렇지 않은 경우에는 그 변화들은 의도적인 것처럼 취급된다. 컴퓨터 과학은 그러한 시스템들을 기술하는 적절한 방법들로 가상기계 virtual machine, 펌웨어 firmware, 그리고 동적 구성 가능성 dynamic configurability 의 개념들을 만들어왔다. 자연 시스템 (인간 인지) 에 대해서는 좀더 일반적인 관점이 요구되는데 즉 중요한 것은 변화의 상대적 속도이다. 그림 12 는 그 상황을 예시하고 있다. 독자의 직관을 사용할 수 있게 하기 위해서, 그것은 인간의 시간 척도를 사용하는데 과제수행은 초 단위에서 일어난다. 중요한 것은 절대적인 숫자가 아니라 상대적인 시간의 척도이다.
시스템의 기초 원자 행위들은 1 / 100 초가 소요된다. 적당히 복잡한 과제를 달성하기 위해서는 몇몇 자료들이 중간단계의 잠정적인 값으로서 저장되어야 한다. 이것은 약 1 / 10 초의 속도로 일어난다. 약 1 초에 일어나는 과제 수행을 생성하기 위해 몇 개의 기초원자 행위가 요구된다. 구성은 시스템이 과제수행을 생성하는 동안 고정되어 있는 구조이다. 수행의 과정 동안 모든 구조가 고정되어 있는 것은 분명히 아니다. 몇몇의 구조는 각 0.01 초에 연산되는 각각의 초보적 행위에 대한 입력과 출력을 유지한다. 다른 몇몇 구조는 과제 달성을 위해 저장된 잠정적인 자료를 0.1 ~ 1 초간 유지한다. 다른 몇몇 구조는 변해야 한다. 이렇게 순간적으로 변하는 구조들을 기억 내용 memory content 이라고 부른다.
다른 과정들은 시스템을 좀더 천천히 변화시킬 수 있다. 만약 수행으로부터 피드백이 있는 경우, 기억의 내용들은 변경될 것이지만 더 늦은 속도 (10 초) 로 변한다. 기술 획득은 좀더 늦은 속도 (100 ~ 1,000 초) 로 진행되며 발달적 변화는 더욱 느리게 (105 초) 일어난다. 이러한 모든 시간 척도에서의 변화는 중요하다. 어떤 장기적 변화들은 단순히 내용의 변화, 즉 저장 구조에 대한 변화 (0.1 초) 일 수도 있다. 그러나 다른 것들은 수행 동안 (1 초) 고정되어있던 구조들을 변화시킬 수도 있다. 이러한 것들의 몇몇 또는 모두가 구성적 변화로 간주될 수 있다. 분명히 수행을 하는 동안 고정되어 있던 것이 이제 변화될 수 있는 것으로 된다. 그러나 지식 획득과 같은 어떤 장기적 변화들은 여전히 기억 변화로 구분되는 것이 더 적당해 보이고, 단지 기술획득이나 다른 더 장기간의 변화들만이 구성변화로 간주된다. 이것은 거의 대부분 용어법의 문제이다. 이해하는 데 중요한 것은 자연 시스템들은 모든 시간 척도에서 동시에 변화한다는 것이다. 이러한 계속적인 가소성 plasticity 은 고정된 구조로서의 구성의 개념을 타당하지 않게 만드는 것은 아니다. <이것은 단지 고정적 fixed 이라는 용어를 시간척도의 상대적인 개념으로 만든다.> (주석 : 이 그림은 너무 단순화된 것이다. 세 가지의 다른 지속시간이 관련되어 있다 : 읽기 시간 read time, 쓰기 시간 write time, 그리고 거주 시간 residence time, 만약 지식이 유용해야 한다면, 읽기 시간은 항상 비교적 짧다. 거주시간은 거의 항상 쓰기 시간보다 더 길지만, 쓰기 시간과는 독립적이다. 구성의 고정은 거주 시간에 상대적이다.)
구성에 관한 중요한 질문은 고정된 구조가 어떠한 기능들을 제공하느냐와 관련된다. 구성은 구조와 내용을 구분하는 경계선을 제공한다. 구성인 고정된 처리구조, 즉 구성에 따라 처리되고 변화하는 내용에 의해서 행동은 결정된다. 고정된 구조는 처리의 광범위한 배열에 대한 공유성을 나타낸다. 그러므로 자연스런 질문은 무엇이 구성에 포함되며 무엇이 내용으로 옮겨가야 하는가이다.
|
고전적 구성적 기능들 반입-실행 주기 • 연산자들과 피연자들을 조합 • 연산자를 피연자들에게 적용 특수한 초보적 연산들 • 나중의 사용을 위한 결과들을 저장 접근 구조들의 지원 입력과 출력 역사적 추가물들
계산력, 기억, 그리고 신뢰성을 위한 기술의 활용 • 병렬주의, 캐시 ··· 연산의 자율성의 획득 • 차단, 동적 자원 할당, 보호 |
그림 13 구성의 알려진 기능들
그림 11 에 명세화된 것처럼 구성은 기호 시스템을 지지해야 한다. 그러나 그것은 구성의 명세화에서 아주 작은 부분만을 차지한다. 구성이 제공하는 추가적 기능들뿐 아니라 실행의 문제가 존재한다. 구성에 대한 우리 경험의 대부분은 수년 동안 구성적 탐구가 많이 이루어진 컴퓨터 과학에서 나온다. 그림 13 은 그런 노력에 대한 주요 결과들의 목록이다. 모든 컴퓨터 구성이 수행하는 고전적 기능들이 있다. 모든 컴퓨터들은 연산자 operator 와 피연산자 operands (주석 : (역주) operator 와 operand 를 심리학에서는 주로 조작자와 피조작자로 번역하며 전산학에서는 연산자와 피연산자로 번역한다. 본 글에서는 연산자와 피연산자로 번역한다.) 의 구분을 사용한다. 행동의 다음 단계를 결정하기 위해서, 컴퓨터는 연산자와 피연산자를 조합하고, 연산자를 피연산자에게 적용하고, 그 다음 미래의 사용을 위하여 결과들을 저장해야 한다. 이것은 고전적인 반입-실행 주기 fetch-execute cycle 이다. 가용한 특수연산들은 항상 특정한 기능들을 포함한다. 자료를 기억에서 기억으로 옮기기, 논리적이고 산술적인 자료연산을 수행하기, 검사를 수행하기, 그리고 입력과 출력을 위해 외부장치들을 활성화시키기, 실제적인 연산들은 사용의 편이성과 효율성을 증대시키기 위해서 자꾸 정교화된다. 자료-전소 date-transmission 연산에 함축된 것은 컴퓨터가 기억구조로부터 정보를 접근하고 인출할 수 있도록 해주는 자료구조의 지원이다. 이러한 것들이 기호 시스템을 실현하기 위한 기본기능들을 제공한다. 그것들에 관한 중요한 많은 것들은 앞에서의 분석에서 살펴보았다. 역사적으로 이러한 기능들은 초기부터 컴퓨터에 포함되어 있었다 —— 그것들 없이는 작동하는 일반 - 목적 컴퓨터를 만들 수가 없었기 때문이다.
더욱 흥미로운 점은 수 년에 걸쳐 구성에 추가된 것들이다. 그것들에는 두 종류가 있다. 하나는 계산력 power (초당 연산 수), 기억 (주어진 시간에 가용한 총 비트), 그리고 신뢰도 (오류 간의 평균 시간) 를 얻기 위해, 그리고 비용, 공간, 에너지의 요구를 줄이기 위해 가용한 기술을 이용할 수 있는 기회와 필요성으로부터 제기되었다. 예를 들어 병렬주의, 대규모의 병렬주의조차도, 새로운 기능을 소개한 것이 아니라 새로운 기초 기술을 이용한 장치이다. 물론 구성에서의 변화는 급진적일 수도 있고 기술이 계산의 모든 형태를 강요할 수도 있다. 더 나아가 계산력, 속도, 그리고 기억은 연속적인 매개변수이지만, 그것들은 모든 크기의 변화에 따라 질적으로 다른 계산들로 귀결될 수도 있다. 특히 실시간 제약은 특수한 시간 제약 안에서 가용한 계산의 양의 효과를 나타낸다.
흥미롭게도, 기능성의 모든 양적인 추가는 컴퓨터의 자율성 autonomy —— 자기 스스로 존재할 수 있는 컴퓨터의 능력 —— 을 증가시키는 데 도움을 준다. 하나의 중요한 예는 차단 interrupt 으로 이것은 컴퓨터의 연산의 중심주기밖에 있는 어떤 행위자가 컴퓨터가 하고 있는 일과는 독립적으로 컴퓨터의 행동에 대한 통제를 즉각적으로 얻는 능력을 의미한다. 차단은 분명히 동적인 외부세계와 상호작용하는 데 있어서 중요한 기능이다 —— 이것은 많은 내적 기능들을 위해서도 역시 유용하다. 차단 기제들은 오랫동안 우리와 함께 있어 왔기 때문에 많은 사람들은 초기의 컴퓨터들이 그러한 기제들을 갖고 있지 않았다는 것을 알지 못할 수도 있다 —— 그 대신, 초기 컴퓨터들은 외부세계를 잘라 버렸다. 그것들은 항상 통제력을 갖고 있었고, 단지 프로그램이 외부세계에 관해 물어올 때에만 그것들은 외부세계에 관한 어떤 것을 찾을 수 있었다. 모든 컴퓨터가 차단기제를 갖는 데는 시간이 오래 걸리지는 않았다는 사실은 놀랄 일이 아니다.
보호 protection 를 위한 기제들은 조금 늦게 등장했다. 그것들은 시스템의 한 부분에서의 활동이 시스템의 다른 부분들에 영향을 주는 것을 방지하기 위한 믿을 만한 내적 방어벽을 제공한다. 다중의 사용자나 복잡한 과제들이 영구적으로 상주하는 하위과제들로 분해되기 때문에 컴퓨터에서 다중의 과제들이 수행되자마자, 곧 보호에 대한 필요성이 제기되었다.
동적 자원 할당 dynamic resource allocation 도 시스템의 자율성을 증가 시켜주는 또 하나의 기능이다. 초기의 시스템에서는 모든 기억이 프로그램 작성자가 명세화하는 방법으로 고정된 배열에 할당되었다. 이것은 프로그램 작성자의 예측에 의하여 특정한 명세화가 됨을 의미한다. 시스템이 가용한 자원들의 목록을 보유하고 시스템 그 자체는 사용되지 않는 자원들을 그 목록에 되돌려놓는 수집연산을 하면서, 요구되는 새로운 자원을 그 목록으로부터 분배할 수 있다는 것은 프로그램 작성자가 이러한 단계들을 계획하는 것을 피할 수 있게 해줄 뿐 아니라 프로그램이 설계될 때 요구되는 공간을 예측할 수 없는 추정조차도 할 수 없는 과제들을 컴퓨터가 수행할 수 있도록 해준다. 흥미롭게도 동적 자원 할당은 하드웨어의 지원을 요구한다고 하더라도, 많이 요구하지는 않는 것 같다. 그 기제들은 (본질적으로 목차 처리) 소프트웨어로 매우 적절하게 실현된다. 그러나 그것들은 한 위치에 남아 있으면서 계속적이고 연속적으로 작동해야 한다. 그러므로 그것들은 고정된 구조, 즉 <구성에 추가된다.>
동적 기억 할당은 고정된 구조로서의 구성과 변화하는 자료로서의 내용간의 구분이 하드웨어와 소프트웨어 간의 구분과는 똑같은 것이 아님을 강조하는 좋은 예이다. 즉 많은 고정된 기제들은 소프트웨어처럼 만들어질 수 없다 —— 가용적인 자원의 목록을 유지하는 데 사용되는 여러 가지 자료구조들과 함께 우리 예에서 할당을 하는 프로그램들. 소프트웨어 기제가 변경될 수 있다는 것은 그것이 변경되어야만 한다는 것을 의미하는 것은 아니다. 그러므로 모든 종류의 소프트웨어 시스템들과 소프트웨어 구성들이 만들어지고, 그것은 한 구성을 다른 구성으로 변환시킨다. (주석 : 예를 들면 이 책에서 사용될 구성인 소어는 또 다른 소프트웨어 구성인 Common Lisp 로 프로그램된 소프트웨어 구성으로서 실현되는데, Common Lisp 자체는 하드웨어 구성에서 작동한다.) 변함없이 남아 있는 것은 근본적인 순수 하드웨어 구성이다 (기계 구성 machine architecture 또는 기계 언어 machine language 라고 자주 불리는 것) . 주어지는 고정된 기제가 결국 하드웨어로 또는 소프트웨어로 될 것인지에 많은 요인들이 영향을 준다 —— 얼마나 빨리 그것이 작동해야 하는지, 그것의 하드웨어 구현이 얼마나 비싼지, 또는 그것이 얼마나 복잡한지. 하드웨어를 컴퓨터처럼 조직하여서 복잡성을 소프트웨어로 돌릴 수 있게 하지 않는다면 하드웨어에 직접적으로 실현될 수 있는 복잡성에는 기술적 한계가 있다.
컴퓨터의 역사를 보면, 더 많은 자율성을 향한 컴퓨터의 진화는 경탄을 자아낸다. 사실 컴퓨터는 관리를 받고 있는 시스템들이다. 컴퓨터는 자기 스스로는 할 수 없는 모든 일들을 대신 해주는 인간 관리자 —— 훈련자, 그리고 조작자 —— 를 갖고 있다. 컴퓨터가 중지되었을 때, 그들의 관리자는 그것을 고쳐서 다시 돌아가게 한다. 컴퓨터가 다른 장소에서부터 정보를 가져오는 것과 같은 어떤 과제를 수행하지 못하면, 그들의 훈련자는 그 정보를 가져다가 컴퓨터가 사용할 수 있는 형태로 컴퓨터에 제공한다. 이것은 심리학자들 사이에 늘 있어온 농담, 쥐 한 마리가 다른 쥐에게 자신들이 실험자로 하여금 자신들에게 치즈를 가져오도록 실험자를 어떻게 훈련시켰는지에 대해 이야기한다는 농담을 회상시킨다. 컴퓨터의 자율성이 부족한 이유를 알아내는 것은 어렵지 않다. 중요한 기준들은 언제나 경제적인 것이다. 어떤 과제가 인간이 수행하기에 매우 드물게 나타나면서도 용이하다면, 그 과제를 자율적으로 수행하는 컴퓨터를 만들어야 한다는 압력은 거의 없다. 점점 더 컴퓨터에 대한 신뢰감이 높아지고 값이 저렴해짐에 따라, 그리고 우리가 더욱더 다양한 과제를 수행하는 방법을 발견할수록 컴퓨터는 점점 자율적인 것으로 진화되고 있다.
자연 시스템들의 구성에 대한 어떠한 분석에서도, 컴퓨터 구성으로부터 나온 가용한 개념들이 모든 일을 하는 것은 아니지만 유용한 것이다. 자연적 시스템들, 특히 인간의 자율성은 컴퓨터의 그것보다 훨씬 높다 —— 사실, 이것이 인간이 컴퓨터의 관리자가 될 수 있는 이유이다. (주석 : 우리는 그림 1 - 7 의 자율성 자원의 예매성을 잊어서는 안 된다. 인간들도 역시 그들의 속해 있는 사회 시스템에 매우 의존적이다.) 차단, 보호, 그리고 동적 자원할당의 문제들은 인간의 기능에 의하여 제기되며 이러한 기능들을 위하여 컴퓨터에서 사용되는 기제들과 해결책들은 인간의 구성이 구조화되어 있는 방식을 탐구하기 위한 틀을 제공한다. 그러나 자율성을 향한 컴퓨터의 진화는 아직도 완전한 것은 아니다. 지능을 지원하는 구성들을 위해 요구되는 추가적인 기능들이 무엇인지를 이해하는 것은 우리의 과학적 과제의 일부이다. 예를 들어 구체적으로 말하면, 학습이 자율적으로 발생하기 위해서는 기억의 특정한 모듈성이 필요한지도 모른다.
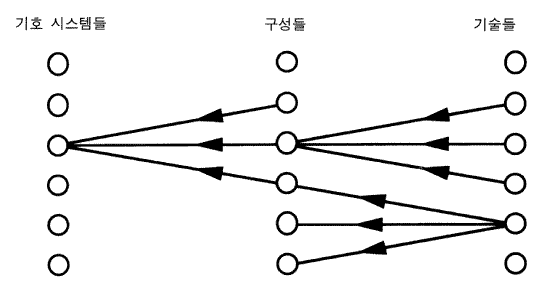
그림 14 구성적 다양성에 대한 가능성
구성들이 수행해야 할 기능들의 수가 많아지고 구성들을 위한 명세 사항들이 축적될수록 우리는 모든 세부사항에 있어서 하나의 특수한 구성으로 수렴하는 것처럼 보였다. 그림 1 - 7 의 모든 제약들이 동시에 적용되었을 때 어떤 것이 진실인지는 모르지만, 현재의 단계에서는 분명히 그 일이 이루어지지는 않았다. 시스템들은 유연성과 엄청난 다양성을 다룰 수 있다. 그림 14 가 도식적으로 예시하는 바와 같이, 많은 다른 기호 시스템들이 가능하고, 다른 많은 구성들과 많은 기술들 역시 가능하다. 단지 다양성이 있는 것이 아니라 극단적인 다양성이 존재한다. 거의 모든 종류의 재료들이 어떤 종류의 기술에 의해서 일반계산을 위한 것으로 만들어질 수 있다 —— 자기, 정전기, 유체, 생물, 기계 (고무줄로 연결된 블록세계 조차도). 더 나아가 이들 수준들 사이의 관계는 일 대 일 대응이 아니다. 많은 다른 구성들이 주어진 하나의 기호 시스템을 실현할 수 있다. 다른 많은 기술들이 주어진 동일한 구성을 실현할 수 있다. 동일한 기술이 많은 다른 구성들은 실현하는 데 사용될 수 있다 (유일한 제약은 정의에 의해, 하나의 주어진 구성은 하나의 특수한 기호 시스템을 실현해야 한다는 것 같다). 다양성이 너무 크기 때문에 우리는 그것의 한계에 대한 어떠한 구조적 특성화도 갖고 있지 않다. 그림 11 로 귀결되는 기호 시스템들의 분석처럼, 모든 특성화는 기본적으로 기능적인 것이다. 그것들이 그러한 기능들은 제공해야 한다는 것을 제외하고는 본질적으로 기계의 성질을 특성화하는 데에 대해 알려진 것은 아무 것도 없다.
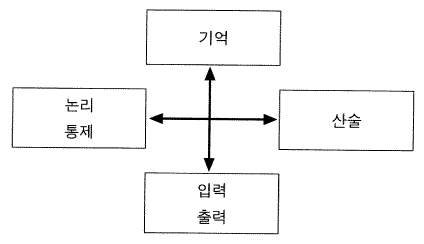
그림 15 초기의 4-상자 표준 구성
내가 알고 있는 유일한 구조적 불변성은 경험적인 것 —— 그림 3 의 컴퓨터 - 시스템 위계 —— 이다. 컴퓨터 과학과 공학에서 우리가 무엇을 하든지 그 위계는 확고하다. 그 위계가 즉각적으로 나타난 것은 아니다. 원래는 본질적으로 고정된 구조, 즉 웨어 Ware (1962) 와 같은 모든 초기 교과서에서 찾아 볼 수 있는 그림 15 에 제시된 것과 같은 유명한 4 개의 상자들이 있었다. 여기서 기술된 것과 같은 구성들은, 하드웨어의 가격이 떨어지고 그것의 신뢰도가 높아졌기 때문에 결과적으로 시스템의 복잡성이 증가하던 1960 년대에서나 나타났다 (Bell & Newell, 1971) . 이것을 가능하게 했던 핵심적인 요인은 레지스터-전송 수준의 발달이었다. 이것은 복잡한 구성을 기술하는 데 사용될 수 있는 하나의 시스템 수준이다. 처음에는 단일한 두 개의 변수 (0 또는 1) 를 중심으로 만들어진 조합적이고 순차적인 회로의 간단한 논리수준이었다. 1960 년대에 레지스터-전송 수준이 만들어진 이후, 그것의 기본적인 형태는 아직까지 유지되고 있다. 컴퓨터 분야는 개별적인 논리 구성요소들로부터 집적회로 ICS (integrated circuits), 그리고 MSI, LSI, 그리고 VLSI 에 이르기까지 (주석 : 각각 중규모 집적 medium-scale integration, 대규모 집적 large-scale integration, 초고밀도 집적 very large-scale integration.) 기술적인 면에서 급진적인 변화를 겪어 왔다. 마지막 것인 VLSI 는 영역 제약 area constraints 과 기하학적 배치와 같이 많은 새로운 개념들을 소개해왔다. 그럼에도 불구하고 레지스터-전송 시스템은 조금도 변하지 않았다. 계산 시스템에서의 구조수준의 부분에서는 전혀 발전이 없었다.
우리는 이러한 불변성이 유지되는 이유를 알지 못한다. 사실 그것은 우리가 만든 공학적 기술과 또는 경제성에 의해 강요되는 상향적 호환성 upward compatibility 에 대한 관심과 함께 컴퓨터 분야에 현존하는 보수주의와 관계 있을지도 모른다. 분명히 생물학적인 것과 같이 극단적으로 다른 기술들은 그 위계를 다소 변경시킬 것이다. 대규모 병렬 연결주의 시스템들의 발전에 있어 주요한 도전 중의 하나는 그것들이 다른 위계 조직을 찾을 것인가 하는 문제이다. 어쨌든, 유일한 것처럼 보이지만, 중요한 것은 컴퓨터-시스템 위계는 불변하는 구조적 특성을 갖고 있다는 것이다.
지능은 인지과학의 또 하나의 중심적 개념이다. 다른 개념들과 마찬가지로 지능도 인지과학의 특정한 요구에 따라 그것을 만들려는 시도들과 관계없는 긴 역사를 갖고 있다. 불행히 지능 개념의 역사는 다른 개념들과 다른 형태의 논쟁들로 가득 채워져 있다. 그 논쟁은 지능검사의 발전과 소수민족과 특권이 없는 사람들의 노력에 있어서 가정되는 지능의 중요성 때문에 좀더 큰 정치적으로 사회적 세계로부터 흘러나온 것이다. 지식과 표상처럼, 우리가 살펴본 다른 기초적인 개념들을 둘러싼 논쟁들의 대부분은 철학과 같은 지적인 학문의 틀 안에서 유지되어왔다.
지능의 개념은 논쟁을 불러일으킬 뿐만 아니라 지능은 그 자체가 개념의 다중성 multiplicity 이 있음을 나타내고 있다 (Sternberg, 1985a ; Sternberg & Detterman, 1986). 이러한 개념들 모두는 가족 유사성을 갖고 있지만 그 차이들은 지능을 다른 목적에 봉사하도록 하는 필요성을 나타낸다. 그렇기 때문에 통합이나 혼합은 허용되지 않는 것이다 —— 그것이 지속되는 시도들 (Sternberg, 1985b) 을 막지는 못한다. 단일한 보편적 지능에 대한 개념은 학교 교육과 학교 이외의 삶에 대한 교육의 적절성에 대한 주장을 위한 구분인 학업지능과 실세계 (또는 실용) 지능 (Neisser, 1979) 과 같은 다중지능과 반대되는 것이다. 단일한 보편적 지능에 대한 개념 역시 서양적 사고방식의 지배성에 관한 주장을 위한 구분인 (Cole & Scribner, 1974), 지능을 정의하는 문화에 대한 상대적 개념과도 반대되는 것이다. 지능검사를 만들기 위한 기술에 의해 완전히 정의된 과학적 구성개념으로서의 지능개념은 인지이론들과 실험을 통해 정의된 지능개념과는 반대되는 것이다. 적어도 이 마지막의 경우에서는, 아직 완전한 성공이 이루어지지는 않았지만, 그 두 개념을 통합하려는 강력하고 지속적인 움직임이 있어 왔다 (Sternberg, 1985a) .
이와 같은 이유로 우리는 이 개념을 그냥 지나칠 수 없다. 사실 그냥 지나칠 아무 이유도 없다. 과학은 사회의 다른 곳에서 사용되는 개념들을 사용하고 정교화시키는 지속적인 과정이다. 차등이 있는 graded 능력 또는 마음-같은 시스템의 계산력에 대해 어떤 개념이 요구되는데, 어떤 마음이 어떤 과제를 수행할 수 있는지를 나타내기 위해 그 개념은 과제들의 범위나 집합들 또는 마음의 범위나 집합들에 어떤 방법으로든 적용된다. 그러한 개념의 유용성에 대해서 거의 의심의 여지가 없다. 마음의 이론은 그러한 개념을 포함해야만 하는 것 같다. 그렇지 않다면 그 이론은 왜 그러한 개념이 정의될 수 없는지 또는 왜 특정한 한계 안에서만 정의될 수 있는지를 우리에게 말해주어야만 한다.
사실 이 장에서 기술된 이론, 그것의 핵심 개념들이 지식, 표상, 계산, 기호, 그리고 구성인 이론은 그것 자체에 지능에 대한 자연스런 정의를 포함하고 있다 —— 한 시스템은 그것이 지식수준 시스템을 추정하는 정도만큼 지능적이다.
만약 우리가 기술했던 이러한 다른 개념들이 수용된다면 이 정의가 바로 지능의 개념의 요건에 대한 답이다. 이것은 이론에 기초한 정의이며, 독립적으로 동기화된 개념은 아니다. 사실 그것이 바로 마음의 이론으로부터 기대되는 것이다 —— 즉 그것은 지능이 무엇인가를 결정해야 하는 것이지, 지능이 독립적으로 동기화되어야 한다는 것은 아니다. (주석 : 지능에 관한 논쟁의 많은 부분은 인지의 일반이론과의 관련성이 없이 심리측정학에서 그것이 발달했기 때문에 제기되었다고 나는 주장한다. 20 세기 전반부 동안에 인지 이론들을 억압하는 역할을 했던 그 당시 행동주의의 주도권을 생각한다면, 그것이 지능이론이 발달할 수 있는 유일한 방법이었는지도 모른다. 그러나 그 결론은 유효하다.)
이와 같이 지능의 형식화는 매우 압축된 것이다. 그것을 이해하기 위해서, 다음의 3 개의 주장을 고려해보자.
1. 만약 시스템이 자기가 갖고 있는 모든 지식을 사용하다면 그것은 완벽히 지능적이다. 더 효과적인 수행을 생성할 수 있는 지능이라고 불리는 것은 없다. 만약 시스템이 갖고 있는 모든 지식이 그것의 목표를 위해 사용된다면 행동은 완벽한 지능이 생성한 것과 동일해야 한다.
2. 만약 시스템이 어떤 지식을 갖고 있지 않다면, 그것을 사용하지 못하는 것을 지능의 실패라고 할 수 없다. 지능은 단지 시스템이 갖고 있는 지식에 대해 작동할 수 있다.
3. 만약 시스템이 어떤 지식을 가지고 있고 그것을 사용하지 못한다면, 분명히 어떤 내적 능력의 실패가 존재한다. 시스템 내부의 어떤 것이 자신의 목표, 즉 자신의 이익을 위해 지식을 사용하는 것을 허용하지 않았다는 것이다. 이러한 실패는 지능의 부족이라도 확인될 수 있다.
그러므로 지능이란 자신의 목표를 위해 자신이 갖고 있는 모든 지식을 활용하는 능력이다. 시스템을 지식수준에서 기술하는 것은 시스템이 자신의 목표에 도달하기 위해 자신이 갖고 있는 모든 지식을 사용할 것을 가정하는 것이다. 순수한 지식수준의 생물들은 지능에 의해 등급이 매겨질 수 없다 —— 그것들은 자신이 알고 있는 것을 할 뿐이지, 더 많이 또는 더 잘 할 수는 없다. 그러나 실재의 생물들은 자신들의 지식을 사용하는 데 어려움을 갖고 있으며, 지능은 그것들이 그것을 얼마나 잘 하는지를 기술한다.
하나의구체적인 예를 생각해 보자. 한 사람이 매우 제한된 예산을 갖고 식료품점에 물건을 사러 왔다고 상상해 보자. 그는 자신이 원하는 각 항목에 대해 대안적인 상품들의 가격을 비교한다.그는 비교하기 위해 정해진 가격들을 동일한 단위당 가격으로 전환시킨다. 그리고 그는 가장 싼 것을 선택한다. 이것은 지능적인 수행이다. 이것은 그의 목표를 위해서 자신이 갖고 있는 지식 (산술방법, 동일한 단위에 대한 가격은 주어진 음식량의 총 가격에 대한 그 항목의 기여도를 나타낸다는 사실) 을 사용한 것이다. 만약 그가 이러한 모든 것을 알고 있지만 단위당 가격 대신 단지 적혀진 가격만을 비교한다면, 그것은 덜 지능적인 수행이 될 것이다. 이것이 완벽한 지능적 행위냐 아니냐를 판단하는 것은 그 사람의 실제적인 목표와 그가 사용할 수 있으며, 알고 있는 어떤 다른 지식에 대한 분석을 요구한다. 아마 그는 열량에 대해 알고 있었고, 그러므로 열량당 가격을 계산할 수도 있었을 것이다. 그런 경우에, 그는 더 지능적일 수 있었다. 그는 자신의 지식을 일부 사용했지만 전부 사용한 것은 아니었다. 열량이 항목들에 적혀 있지 않은 경우를 생각해 보자. 그럴 경우에는 무게당 또는 부피당이 아니고 열량당 가격을 계산하지 못한 것은 지능의 실패가 아니라 지식의 실패이다. 마찬가지로 만약 제조업자가 내용물의 열량에 대해 거짓말을 하고, 그 사람이 틀린 답을 얻었다면, 그것도 지식의 실패이지 지능의 실패는 아니다. 물론 그 사람이 회사의 불성실성을 알고 있다면 —— 회사가 거짓광고에 대한 벌금을 물었고 그는 신문에서 그것에 관해 읽었고 논의했다 —— 그가 회사의 주장에 기초해서 결정하는 것은 덜 지능적으로 행동하는 것이다.
나는 이 예에 대해서 얼마든지 자세하게 말할 수 있다 (이것은 내 자신의 예이기 때문에 이 예에 대한 실제 상황은 존재하지 않는다) . 이를 테면, 우리는 그 사람의 목표를 정교하게 만들 수 있고 —— 그는 바빴다 또는 그는 특정 상표의 복숭아를 좋아하기 때문에 추가비용은 가치가 있다 —— 또는 그 사람이 알고 있는 것을 변경시킬 수도 있다 —— 그는 건강한 식사법 (단백질, 비타민) 의 다른 측면들에 대해서도 알고, 적당한 최적화를 위한 선형 프로그래밍에 대해서도 역시 알고 있다. 그 과제의 수행에 관여하는 지능을 평가하는 것은 작용하는 실제적인 목표들과 지식을 고려할 것을 요구한다. 이것이 바로 그러한 방식이다. 정말로 그 사람이 어떤 지식을 모르고 있다는 것을 우리가 알고 있으면서 그 사실을 고려하지 않은 채 그가 덜 지능적이라고 평가한다면 오히려 우리 자신이 지능적이지 못한 것이다.
지능의 이러한 개념은 많은 특성을 갖고 있으며 이 특성들은 지능이 갖고 있다고 기대되는 바로 그 특성들이고 몇몇은 새로운 것들이다.
지능은 목표에 상대적이고, 지식에 상대적이다. 시스템은 어떤 목표를 실현하고 어떤 지식을 사용한다는 점에 관련해서 완벽하게 지능적일 수 있지만, 다른 목표와 다른 지식에 관련해서는 전혀 지능적이지 못할 수도 있다. 정의된 지능은 측정되는 것이 아니라 시스템의 목표와 지식이라는 두 개의 복잡한 영역들의 연결부위에 대한 적절성의 기술이다.
지능의 상대적 본질에 따른 중요한 결과는 다른 어떤 과제의 수행을 위해 지식을 획득하는 과제를 독특한 것으로 유지할 필요성을 제기한다. 예를 들어 어떤 과제, 이를 테면 식료품점에서 물건들을 구입하는 문제를 생각해 보자. 한 사람은 T 를 수행하는 순간에 특정한 지식체계를 갖고 있고 지능의 평가는 이 지식과 관련해서 이루어진다. 만약 그 사람이 추가적 지식을 갖고 있었다면 평가는 달라질 것이다. 이를테면 산술계산을 하는 방법을 모르는 사람은 수행을 잘 하지 못할 것이다. 그러나 그것은 지능이 낮다는 것을 의미하지는 않는다. 그 사람은 산술계산을 알아야 하며 그러므로 지능의 실패가 있다고 생각될 수도 있다. 이 경우에는 평가되는 과제가 T 가 아니라 산술계산을 획득하는 과제 —— 이것을 AA 라 하자 —— 이다. 달리 말하자면 AA 에서의 수행이 지능적이 않았거나 또는 산술계산을 학습할 것인지 아닌지 (즉 AA 를 할 것인지 아닌지) 를 결정하는 과제가 지능적이지 않게 수행된 것이다. 그러한 모든 과제에서 행해지는 지능의 평가는 그 당시 가용되는 지식을 알고 있을 것을 요구한다. 인간의 삶은 과제들로 채워져 있고 그러한 것들은 저마다 어떻게 지능적으로 수행될 수 있는가에 대한 각자의 문제를 제기한다.
이 정의는 지능과 지식을 분명히 구분한다. 그것들은 전혀 같은 것이 아니다. 지능에 대한 많은 일반적 직관들은 이 둘을 혼합한다. 우리는 지능적인 사람은 어떤 특정한 것들을 알고 있으리라 기대한다. 모든 지능적인 사람들은 더하는 방법, 시내를 돌아다니는 방법, 학교에서 가르친 것들은 물론, 모든 상식적인 것들을 알아야 한다고 우리는 믿는다. 다른 한편으로 많은 일반적 직관들은 지능과 지식을 구분한다. 아무리 지능이 높다고 해도 알 기회가 없었던 사실들, 예를 들어 로베르토 클레멘트 Roberto Clemente 의 전생애를 통한 평균타율과 같은 것들을 알 수는 없다. 물론 사회는 그것의 구성원들을 지식획득의 과제들에 많이 직면시키고, 지능적인 사람들은 그러한 과제에서 성공하며 그러므로 연결된 지식체계들을 획득하기 때문에, 사회적 공동체의 지능적인 구성원들의 대부분은 공통적인 지식체계를 알고 있다. 지식과 지능이 강력하게 연결되어 있다는 것이 지식과 지능이 동일한 것임을 의미하지는 않는다.
일반적으로 지능이 더 높을수록 수행은 더 좋아진다. 즉 시스템의 지식이 더 많이 고려되면 될수록, 그것은 더 많은 목표들을 달성할 것이다. 추가적인 지식은 도움을 주지 못할 수도 있지만 —— 그것들은 무관한 것들이다 —— 손해를 입히지는 않는다. 이것은 추가적인 지식을 찾거나 적용하는 처리비용을 무시한다 —— 그것이 바로 지식수준이 제거해 버린 것이기 때문이다. 물론 지식의 조그마한 추가가 시스템을 혼란스럽게 만든다는 반대의 예를 만들기는 쉽다. 이러한 것은 지식이 사실상은 실제 상황을 반영하지 못하기 때문에 발생할 수 있다. 때때로 일어나는 일들은 지식이 틀리다는 것은 불확실한 상황에서 행위를 생성하기 위해 시스템이 사용해야만 할 기정치 default 가정이다.
지능은 단순히 지식-수준 시스템에만 적용되는 개념이다. 그것이 모든 기계에 적용되는 것은 아니다. 어떤 임의적인 기계가 지능적인가, 아닌가의 물음은 이 이론 안에서 형성될 수는 없다. 모든 기호 시스템이 지식수준 시스템을 추정하는 것이 아니기 때문에 (모든 레지스터 - 전송 시스템이 기호 시스템을 추정하는 것이 아닌 것처럼) 지능은 모든 기호 시스템에조차도 적용되는 것이 아니다.
지능은 모든 지식수준 시스템에 적용된다 —— 그것이 아무리 단순하다 할지라도. 이 진술은 직관에 반대되는 결과로 귀결된다 —— 단순한 시스템들은 완벽한 지능을 가질 수 있다. 만약 목표가 충분히 작고 지식 역시 자세히 기술되어 있다면 시스템은 그것의 목표를 위한 모든 지식을 사용하기 위해 많은 것을 할 필요가 없다. 열전쌍 thermocouple 은 한 예를 제공한다. 열전쌍은 단지 하나의 목표 (방 온도를 정상으로 유지하기) , 하나의 행위 (난로를 켜거나 끄는 것) , 그리고 단지 두 항목의 지식 (일반적인 것 —— 켜면 온도가 상승하고 끄면 온도가 떨어진다. 그리고 순간적인 것 —— 온도가 정상보다 높거나 낮다) 을 갖고 있는 것처럼 정의된다고 하자. 그러면 그것의 일반적인 연산양식에서, 열전쌍을 지식수준 시스템으로 기술될 수 있다. 그것은 완벽한 지능을 갖는다. 이것은 열전쌍의 단순성에서 제기된 것이지 그것의 어떤 높은 지위에서 제기된 것은 아니다. 그것은 예전부터 항상 있어 왔던 동일한 옛날의 단순한 열전쌍이다. 변화는 단지 기술에 있다. 돌은 자신의 마땅한 위치를 찾기 때문에 지능적이라고 기술하는 오래 된 (그러나 여전히 사용되는) 언어적 술책에 대해서도 마찬가지다 (Baar, 1986, p. 99, 사실상 참조 대상은 의식이지만) .
지능에는 강력한 시간적 측면이 있다. 이 특징은 양화 논리의 표준적 형식에서 분명히 알 수 있다. 지식에 대한 일반적 표상은 논리학에서 문장들의 타당성을 수립하려는 목적을 갖고 있는 일차 논리학에서의 문장들의 연언의 함축적 종결이다. 그러한 지식체계의 전체 지식은 일반적으로 무한하다. 제한된 시간에 그러한 지식체계의 모든 지식을 접근하는 것은 불가능하다. 본질적으로 이것이 일차 논리학의 비결정가능성 undecideability 에 관한 정리가 선언하는 것이다 —— 지식의 임의적인 항목이 그 지식의 일부인지 아닌지를 보장할 방법은 없다. 다른 한편으로 만약 무한한 시간이 주어지면, 그것은 결정될 수 있다. 그러므로 무한한 시간이 주어졌을 때 커다란 지식체계들과 커다란 목표의 집합들을 갖고 있는 완벽한 지능 시스템을 만드는 것은 가능하다. 그러나 단지 제한된 시간만 주어졌기 때문에 그러한 완전한 지능 시스템을 만드는 것은 불가능하다. 완벽한 지식을 갖고 있는 시스템을 만들기 위해 시스템의 지식과 목표에 있어서 매우 제한된 시스템으로 (열전쌍의 예에서처럼) 축소시켜야 한다.
지능의 단순한 측정치가 있을 수 없다는 것은 목표와 지식의 특수한 성격에 대한 지능의 의존성으로부터 나온다. 변이성과 다양성이 너무 크다 .국민총생산 지수나 경제생산성 지수와 유사하게 지능의 양을 반영하는 지수들을 만드는 것이 가능해야 한다. 국민총생산은 경제에서 무엇이 일어났는지를 반영하지만 단지 어떤 수치까지만 정확할 수 있을 뿐 좀더 자세한 수치에서는 정확하지 않다. 상품이나 서비스는 매우 다양하며 가치평가 (시장가격) 방법 또는 많은 요인들을 반영한다. 정확하다고 밝혀질 수 있는 국민총생산이라는 것은 단순히 존재하지 않는다. 마찬가지로 실제의 지능지수 IQ 측정치는 많은 다른 이유들 때문에 완벽하지 못하다. 하나의 중요한 것은 그것들은 지식과 지능을 혼합시킨다는 것이다. 그러나 그것말고도 그것들은 너무나도 다양한 것들을 하나의 숫자로 요약하려고 한다.
지식과 지능의 관계에 대한 문제는 지능의 이와 같은 정의에 대해 특히 중심적인 것이기는 하지만 새로운 것은 아니다. 지능검사의 분야는 지식과 독립적인 지능의 개념을 발전시키려는 시도를 지속해왔다. 그것들 중 가장 잘 알려진 것은 g 로서, 그것은 지능검사의 요인분석에서 (찾으려고 하면) 항상 존재하는 일반요인이다 (Spearman, 1927). 그 구분은 결정 지능 crystallized intelligence (주어진 형태로 영구적으로 만들어진 것) 에 반대된 유동 지능 fluid intelligence (다양한 상황에서 사용될 수 있는 것) 에서도 역시 볼 수 있다 (Cattell, 1971). 이 개념에 대한 보다 깊은 반영은 문화-공정 culture-fair 검사의 개념에서 나타나는데, 그 검사들은 개인의 문화에 따라 변할 수 있는 어떠한 지식에도 의존하지 않는 검사들이다. 사실상, 동일한 구분이 전문가 시스템 분야에서의 영역지식과 영역 독립적 지식의 직관적인 구분 배후에도 깔려 있다.
g 나 유동 지능과 같은 공유성에 대한 하나의 기초는 동일한 기초적 기제들을 반복적으로 사용한다는 점에서 나온다. 만약 다른 기제들이 다른 과제들을 위해 무한정 사용될 수 있다면, 다른 과제들을 수행하는 사람의 능력들에서 공통적인 것이 있을 필요가 없다. 물론 공통적 기제의 존재는 구성으로부터 시작된다. 그러므로 종들에 걸쳐서 또는 광범위하게 변하는 지능적 행위자들에 걸쳐서보다는, 공통된 구성을 갖고 있다고 가정되는 한 종 안에서 더 큰 공유성을 기대할 수 있다. 그리고 공통된 지식체계들을 갖고 있는 사람들 간에 좀더 큰 공유성을 기대해야 한다.
이 지능이론은 사회가 지능이론으로부터 기대하는 것, 즉 지능을 개발하는 방법, 그리고 지능이나 능력을 나타내는 척도상에 사람을 할당하는 능력검사를 개발하는 방법을 곧바로 제공하지는 못한다. 여기서의 이론은 그것을 수치적으로 측정하는 방법이 아니라 지능이 무엇인지를 기술한다. 이 이론으로부터 새로운 측정방법이 바로 나오지는 않는다 —— 아무 것도 나타날 수 없음을 의미하는 것은 아니다.
요약하면, 지능의 이러한 개념은 독립적으로 가정된 이론이나 분석을 위한 기초처럼 독특한 것은 아니다. 이것은 이 목적 또는 저 목적을 위해 유용하도록 만들어진 것이 아니다. 반면 이것은 인지과학의 기초적인 틀로부터 흘러나온 것이고, 그러한 틀 안에서 그것은 유용한 구성개념을 제공한다. 전통적인 심리측정적 지능의 개념과 이것과의 관계는 불확실하지만 그것은 최근의 많은 연구에도 불구하고 대부분 심리측정과 인지심리학의 관계가 불확실하기 때문이다.
지능적 행동을 위해 어떠한 처리가 요구되는가? 목표달성을 위해 지식을 활용하기 위해서는 시스템은 어떻게 행동해야 하는가? 가장 일반적인 답 —— 시스템은 지식을 포함하고 있는 표상을 처리하고 그에 따라서 행동한다 —— 은 유익을 주지 못한다. 그러나 그러한 처리가 취하는 형태에 대해 무엇을 말할 수 있을까? 비교적 어려운 과제에 대해서는 하나의 답이 있다 —— 행위자는 탐색을 수행할 것이다.
탐색은 지능적 행위의 근본적인 것이다. 이것은 단순히 또 하나의 방법 또는 인지 기제가 아니고 하나의 근본적인 과정이다. 만약 지능에 대한 우리의 이해에 인공지능 AI 이 기여한 것이 있다면, 그것은 탐색이 목적 달성을 위해 사용될 수 있는 많은 방법들 중의 하나가 아니고 가장 근본적인 방법임을 발견한 것이다. (주석 : 사실상, 패턴-대응 과정들도 똑같이 근본적인 것으로 만들어질 수 있다. 그것들이 바로 산출 시스템들에서처럼 저장된 기억구조와 잠정적으로 가용적인 과제구조들 간의 접촉을 허용하는 것이다.) 1950 년 중반인 AI 의 출현 전, 사고, 추론, 그리고 지능을 포함한 심리적 과정들에 대한 논의들은 탐색에 대하여 특별한 강조를 하지 않았다 (Johnson, 1955 ; Vinacke, 1952) .
두 가지의 고려사항이 탐색의 특수한 역할 배후에 있다. 하나는 지능시스템의 실존적 상황 existential predicament 이라고 부를 수 있다. 행위를 시도할 때 지능 시스템은 불확실하다. 사실 이것이 바로 문제를 갖고 있다는 것이 본질이다 —— 다음에 무엇을 해야 할지 모른다. 한 문제를 직면한 시스템은 역사적 시간 안에 존재한다. 그것의 실존적 상황은 지금 행동은 해야 하지만 무엇을 해야 할지 불확실하다는 것이다. 여기서 사고는 행위이다 —— 한 가지를 생각하는 것은 다른 것들을 생각하지 않는 것이다. 그 시스템이 행동하지 —— 생각하지 —— 않은 채로 시간이 지나가고 동일한 상황이 유지됨을 상상해 보자. 그것은 더 이상 추가적으로 알게 된 것이 없고 (말하자면, 그것은 그 문제에 대하여 아무 생각도 하지 않았다) , 그것은 단지 시간을 흘려보내는 것이다. 그러므로 그것이 불확실하다 할지라도 그것은 행위하도록 강요된다.
그 자체에 의해서 이 실존적 상황은 탐색, 사실상 조합적 탐색을 생성한다. 불확실한 상황에서 행위한다는 것 —— 다음 생각을 사고한다는 것 —— 은 때때로 틀릴 수 있다는 것을 의미한다. (불확실하다는 것이 다른 어떤 뜻이 있을까?) 만약 행위가 틀렸다면 복구 recovery 가 필요하다 —— 복구, 그리고 다시 시도. 그러나 이 상황은 단계적으로 일어난다. 시스템이 여전히 틀린 경로에 있는 동안은 틀린 행위가 취해지며 오류의 그 점으로부터 여전히 또 다른 틀린 경로가 취해진다. 이것이 바로 종합적 탐색의 행동 패턴이다.
탐색은 고전적인 (시간적인) 후진추론 backtracking 의 패턴을 보일 필요는 없다. 시스템은 어떤 앞의 기준 anchor 점으로 돌아갈 수도 있고, 또는 일종의 의존-지향적 dependency-directed 후진추론을 수행하던가 또는 오류 행위의 결과들을 고치려고 시도할 수 있다. 이러한 모든 변형들도 시스템은 해결책을 위한 탐색을 해야만 하며, 과거의 오류들이 탐지되고 해결되기 전 새로운 오류가 행해지기 때문에 탐색은 조합적이 된다는 근본적인 사실을 변경시키지 못한다. 문제 해결을 위해 어떠한 방법이 사용되더라도 탐색은 일어나며 상황은 불확실하면 불확실할수록 더욱더 많은 탐색이 필요하다. 그러므로 지능적 행동은 어떠한 공간을 탐색할 것인지를 결정하는 과정과 그러한 공간들에서 탐색을 통제하는 과정들과 밀접하게 관련될 것이다. 어떤 특정한 탐색의 특성은 가용한 기억 또는 가능한 탐색 단계의 형식들과 같은 많은 것들에 의존할 것이다.
지능적 행동에서의 탐색을 함의하는 두 번째 고려사항은 막다른 골목에서의 최후의 수단 the court of last resort 이라고 부를 수 있다. 만약 한 지능적인 행위자가 어떤 목적 —— 말하자면, 어떤 대상 X 를 찾는 것—— 을 달성하기를 원한다면 그것은 그 과제를 어떠한 방법으로든 형식화해야 한다. 그것은 X 를 찾는 것과 합리적으로 관련된 어떤 방법으로 그것의 활동을 배열해야 한다. 그것은 자신의 가용한 지식을 기초로 그렇게 해야만 한다 —— 사실 그것은 단지 그렇게 할 수밖에 없다. 활동하기 전에 더 많은 지식을 찾는 것조차도 이미 그 과제를 형식화하는 하나의 특정한 방식을 선택한 것이다. 상황이 더욱 불확실할수록, X 를 찾는 방법을 말해주는 가용한 지식은 더욱 적어진다 —— 그것이 바로 불확실하다는 것이 의미하는 것이다. 특수한 지식에 최소의 요구를 하는 과제의 형식화는 다음과 같다.
최후 수단의 형식화 : 만약 X 를 얻는 방법을 알지 못하면, X 를 포함하고 있다고 알고 있는 공간을 만들고, 그 공간에서 X 를 탐색하라.
이 형식화는 적용하기 위해 항상 만들어질 수 있다는 특징을 갖고 있다. 찾으려고 하는 대상을 포함하고 있는 공간은 항상 찾아질 수 있다. 가용한 지식이 적으면 적을수록 포함하고 있는 공간은 점점 더 커지고 탐색은 점점 더 어려워지고 많은 비용이 소요됨은 확실하다. 그러나 어쨌든 첫 번째 단계는 달성된 것이다 —— 그 과제 달성과 합리적으로 관련된 과제 형식화가 채용된 것이다.
사실, 이 형식화는 막다른 골목에서의 최후의 수단이다. 그것과 함께 작동하기 위한 부합되는 방법은 보통 생성과 검사 generate and test 라고 불린다. 이 방법은 너무나 간단해서 관심을 둘 가치가 없다고 생각하기 쉽다. 그러나 이것을 무시하는 것은 물리학자가 유체흐름에서 연속성 방정식을 무시하는 것과 같다. 그것은 기초로서 그것 안에서 다른 모든 활동들이 이해된다. 예를 들어 AI 에서 사용되는 모든 방법들의 근본은 탐색 방법들로서, 생성과 검사에 대한 좀더 자세한 명세화로 만들어진다. 수단-목표 분석 means-ends analysis, 언덕 오르기 hill climbing, 점진적 심화 progressive deepening, 제약 전파 constraint propagation —— 모든 것이 일종의 탐색 방법이다. 그리고 이것들 모두 생성과 검사의 기초 위에서 만들어진다.
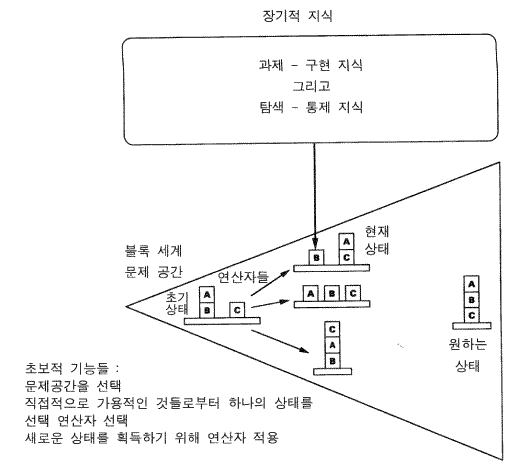
그림 16 문제공간과 두 가지 탐색들 : 문제 탐색과 지식탐색
탐색은 지능적 행위자는 언제나 문제공간에서 연산을 한다는 관점으로 귀결된다 (그림 16). 그것은 행위자가 만든 공간이며, 현재 해결하려고 하는 문제에 대한 해결책을 탐색하는 공간이다. 그것은 그 문제에 대해 작업이 가능해질 수 있도록 문제를 제한하려는 행위자의 시도이다. 그러므로 행위자는 문제를 해결하기 위한 어떤 문제공간을 채용한다. 그 다음 그 행위자는 그 공간에서 현재의 상태에 위치하게 된다. 새로운 상황들을 찾기 위한 가용한 연산자들의 집합이 있다. 예를 들어 블록 세계에서 블록들은 탁자 위에 어떤 초기의 배치로 있고 행위자는 위에 아무 것도 없는 블록들을 이동시킬 수 있다. 과제 달성은 인식할 수 있는 바람직한 상태에 도달하는 것으로 형식화된다 (많은 그러한 바람직한 상태들이 있을 수 있다). 공간에서의 탐색은 단지 그 공간의 연산자들이 적용되는 한, 어떤 방법으로든 만들어질 수 있다 (그리고 각각의 연산자는 허용성 admissibility 에 대한 각자의 조건들을 갖고 있을 수 있다).
문제를 해결하는 것은 공간에서의 무작위적 탐색은 아니다. 공간은 하나의 틀이며 그것 안에서 행위자는 원하는 목적을 탐색하기 위해 지식을 사용한다.만약 행위자가 충분한 지식을 갖고 있다면 탐색할 필요가 전혀 없다. 행위자는 공간을 통해서 단순히 해결책에 직접적으로 이동한다. 어쨌든, 크던 작던 간에, 문제공간에서의 탐색을 통제하고 연산자들을 실행하기 위한 가용한 어떤 지식체가 있다.
지능에는 두 가지의 개별적인 탐색이 진행된다. 하나의 문제 탐색 problem search 으로 설명되었던 것과 같은 문제공간의 탐색이다. 다른 것은 지식 탐색 knowledge search 인데 문제 탐색을 안내할 지식을 시스템의 기억에서 탐색하는 것이다. 이러한 지식 탐색이 항상 요구되는 것은 아니다. 하나의 일반적 탐색 알고리듬 algorithm (이를 테면, 분기와 경계 brand and bound) 을 갖고 단지 하나의 과제에만 작용하는 특수 - 목적 지능 시스템이 주어진다면 아주 적은 지식만이 사용되어야만 하며 (평가지능과 분기와 경계의 논리) , 공간의 모든 상태에서 그것이 사용된다. 절차가 시스템의 구조에 직접 만들어질 수 있으므로 단지 문제 탐색만 일어난다. 다른 한편으로 광범위한 과제들에 작용하는 행위자 —— 즉 인간 —— 는 커다란 지식체계들을 갖고 있다. 새로운 과제가 제기되었을 때, 그 지식체가 과제에 관계가 있는 지식을 찾기 위해 탐색되어야 한다. 더 나아가, 일반적으로 그 탐색은 과제에 적절한 하나의 적은 지식체계를 초기화하는 단 한번의 인출이 아니다. 어떤 과제들은 그러한 특성을 갖고 있지만 일반적으로 문제 공간의 모든 상태들에서 마음에서는 가용하나 아직까지 인출되지 않은 어떤 새로운 지식이 적절한 지식이 될 가능성이 있다. 그러므로 지식 탐색은 지속적으로 진행된다 —— 그리고 상황이 더욱 불확실할수록 그것에 대한 필요는 더 오래 지속된다. 지식 탐색은 문제 탐색의 내부 루프에서 일어난다. 지식은 문제 탐색을 위한 연산자의 선택을 위해 사용되고 그것들의 결과들을 평가하기 위해 사용된다. <그러므로 지식은 각 상태에서 요구된다.>
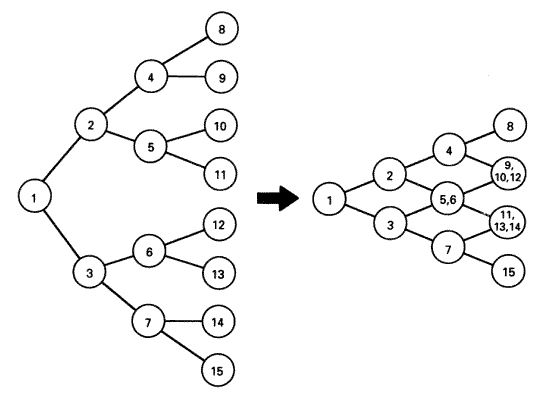
그림 17 조합적 공간은 마디들의 일체화를 통해 유한한 크기로 된다.
지식 탐색과 문제 탐색은 그것들의 특성에서 극단적으로 다르다. 문제 탐색은 그것의 공간을 구성한다. 서술적 자료구조로서 존재하는 유일한 상태들은 현재 상태와, 현재까지의 탐색에서 생성되어서 기억 연산들에 의해 접근 가능하도록 저장된 상태들의 몇몇이 그럴 가능성이 있다. 각각의 새로운 연산자의 적용은 행위자가 전에는 전혀 보지 못했던 새로운 상태를 생성한다. 문제 공간은 필연적으로 조합적이다 (더 많거나 더 적은 분기 요인에 따라) . 단지 그림 17 에 보이는 것처럼, 새로운 상태들이 서로 수렴할 경우에만, 문제공간의 위상 topology 은 차원에서 축소될 수 있다. 수렴은 단지 상태들의 비교와 확인 identification 에 의해서 발생할 수 있는데, 이는 새롭게 구성되는 상태가 어떤 다른 상태와 동일할 것인지를 사전에 알 수 없기 때문이다. 그러므로 상태들은 생성되고, 그 다음 중복 duplication 에 대해 처리되어야 한다.
다른 한편으로, 지식 탐색은 고정된 이미 존재하는 구조에서 일어난다. 탐색되는 항목들 (문제공간에서의 상태의 유사물) 은 자료 구조들로서 이미 존재한다. 그 공간의 구조 (그것의 연결성과 그것을 통한 경로들이 기술되는 방식) 는 이미 구성된 것이다. 사실, 그것은 탐색을 촉진시키기 위해 미리 만들어진다. 동일한 장소가 다른 경로들을 통해 접근될 수 있으며 중복은 즉각적으로 —— 문제공간에서는 불가능하지만, 처음에 만났을 때 그 장소에 표시를 함으로써 탐지될 수 있다. 물론 지식탐색을 문제 공간에서 발생한 것처럼 취급하여 문제 공간에서의 탐색과 동일한 조합적 탐색 방법으로써 지식을 탐색하는 것이 가능하다. 그러나 그것은 일반적인 선택이 아니며 일반적으로는 특수화된 구조를 활용한다 (색인 indexes, 해시 테이블 hash table, 이진법 트리 binary trees, 균형 트리 balanced tree) . 정리해서 말하자면 두 개의 공간과 두 개의 탐색은 다르다.
문제공간에 대해서 말할 것이 많지만, 여기서는 단지 간단히 언급하기로 한다. 문제공간은 생성자 generator 를 구성하는 연산자들과 검사인 원하는 상태의 재인 recognition 을 갖고 있는 생성과 검사의 형식이다. 그러므로 연산자들의 연쇄에 의해 실현된다. <이것은 블랙-박스 black-box 과정이 아니다.> 지식은 생성과정에서의 많은 다른 시점에서 생성을 중단시킬 수 있으므로 (즉 연산자의 적용 후에) , 생성이 지능적일 수 있는 방법을 열어놓았다. 생성-검사 상황에 관한 AI 로부터 얻는 하나의 중요한 교훈은, 검사로부터 생성자로의 지식의 전이는 항상 이익이 되므로 해결책의 후보자들은 결코 만들어질 필요가 없다는 것이다. 이것이 바로 상상할 수 있는 모든 연산자들을 갖고 있는 단일한 커다란 공간이 아니라 다중의 문제공간들이 존재해야 하는 이유이다. 커다란 공간에서의 연산자들의 연쇄들을 더 큰 연산자들 (대형-연산자들) 로 묶는 것이 지식을 검사로부터 생성자로 이동시키는 한 방법이다. 관련이 없는 것으로 알려진 연산자들을 제거하는 것도 또 하나의 방법이다. 그러므로 많은 문제 공간들 안에서 연산자들을 조직화하는 것은 효율적인 문제해결을 위해 지식을 묶는 하나의 방법이다.
문제공간의 또 하나의 중요한 측면은 연산자들이 자유롭게 적용될 수 있는 조건이다. 즉 사용되는 연산자들이 그 공간의 연산자들이기만 하면, 어떤 연산자들이 사용되거나 어떤 순서로 사용되든 관계없이, 원하는 상태는 그 문제의 해결책으로 수용 가능하다. 그러므로 상태들은 연산자들의 적용에 대한 특정한 특성들의 집합을 유지한다. <그러한 특성들은 유지되는 것이 보장되며, 원하는 상태에 대한 검사에 의해서 검사될 필요가 없다.> 이러한 자유로운 - 적용조건은 간단하고 효율적으로 해결책을 탐색하는 시스템의 능력과 직접적으로 연결되어 있다. 만약 연산자들의 정확한 연쇄가 중요하다면 그 연쇄들은 조절되어야 하고, 그 연쇄를 저장하기 위해 기억이 사용되고, 또 그 기억을 관리하기 위한 처리가 사용되어야 한다 —— 탐색은 복잡한 작업이 될 것이다. 이러한 관점에서, 왜 연산자들이 자신들과 연결된 적용가능성의 조건들을 가질 수 있는지를 알기 쉽다. 그것들은 적용이 고려되는 상태들에 대해 국소적으로 적용되며, 그러므로 기억과 조절의 요구와 같은 복잡한 문제를 일으키지 않는다. 정리하자면 문제공간에 의한 처리의 조직화는 문제 해결의 기본적 효율성에 깊은 뿌리를 갖고 있다.
일반적으로, 지능 시스템들은 지식 탐색과 문제 탐색을 모두 수행한다. 그것은 준비 대 숙고 교환으로 귀결된다. 그것은 저장 대 계산 교환으로 때때로 지식 대 탐색 교환 (준비와 숙고 모두 지식을 제공하기 때문에 이 용어는 잘못된 것이다 —— 단지 다른 출처로부터 제공한다) 이라고 알려져 있다. 무엇이라고 불리든, 그것은 모든 지능 시스템들에 있어서 기본적인 교환이다.
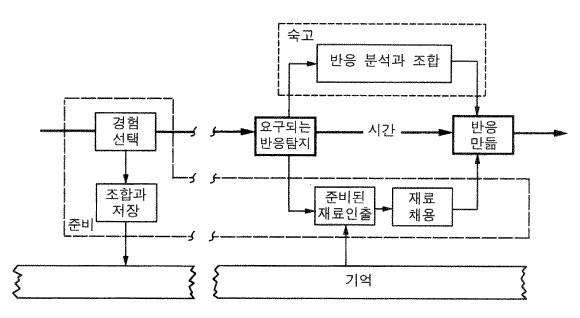
그림 18 준비와 숙고 과정들
그림 18 에 그 상황이 제시되어 있다. 어떤 시점에 반응이 요구된다는 표시가 있다. 그러면 두 유형의 처리가 그 반응의 결정에 관여한다. 시스템은 숙고할 수 있다 —— 상황, 가능한 반응들, 그리고 그것들의 결과들 등의 분석을 위한 활동들을 한다. 우리가 살펴본 것처럼 불확실한 상황에서, 그것은 어떤 공간에서 적합한 반응을 찾기 위한 탐색으로 귀결될 것이다. 시스템은 또한 이미 준비되어 있는 여러 가지 반응들이나 반응들의 측면들을 가질 수도 있다. 물론 그것들은 이미 저장되어 있어야 한다. 그러한 준비된 것들을 사용하기 위해 시스템은 기억에 접근하고, 준비된 재료들을 인출하고, 그리고 현재의 사례에 적합하도록 그것을 고쳐야 한다.
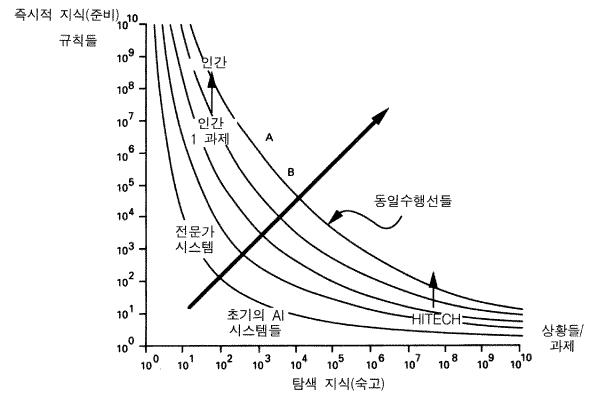
그림 19 준비 대 숙고 교환
한 반응에 이르는 각각의 특수한 상황은 숙고와 준비의 어떠한 혼합을 요구한다. 그러한 혼합은 유기체가 직면하는 전체 상황들의 앙상블 ensemble 에 따라 변화한다. 전반적으로 유기체 그 자체가 활동들의 혼합에 의해 —— 반응이 숙고에서 나올 것인지 또는 준비에서 나올 것인지의 정도에 따라서 ——특징될 수 있다. 그러므로 그림 19 에서처럼 우리는 숙고와 준비를 차원으로 하여 하나의 공간을 생각해 볼 수 있다. (준비-숙고 공간은 일반성-계산력 generality-power 공간과 혼동되어서는 안된다. 일반성-계산력 공간은 문제해결 시스템의 범위를 그것이 해결할 수 있는 과제들의 난이도에 대해 도표화한 것이다. 그 공간도 역시 한 차원 또는 다른 차원에 따라 제한된 발달적 자원들을 분배해야 하는 필요성으로부터 제기되는 교환을 보여준다.) 특정한 시스템들은 그 공간의 특정한 점에 위치한다. 사실상, 한 시스템은 그것이 작업한 각 과제에서 사용한 준비와 숙고에 따라 그 공간에서 점들의 구름을 생성한다. 그 시스템 자체는 그 구름의 중심에 위치하는 것으로 볼 수 있다. 수직축은 기억에 부호화된 지식 —— 준비에 이용된 시스템의 자원의 양 —— 을 표현한다. 현재의 많은 AI 시스템에서, 준비는 그것이 포함하고 있는 규칙 또는 신출들의 수 —— 즉 10, 100, 1,000 또는 그 이상 —— 에 의해 측정될 수 있다. 단위들은 상당히 대수 함수적이다. 더 많은 규칙들이 더해지면 그것들은 특수한 사례들을 포함하는 경우가 생기고 그렇기 때문에 적용범위의 동일한 증가를 위해 점점 더 많은 규칙들이 필요하다. 수평축은 여러 가지 일어날 수 있는 상황들을 고려함으로써 —— 탐색에 의해 —— 얻어지는 지식들을 표현한다. 현재의 AI 시스템에서 숙고는 고려되는 상황들의 수로 측정될 수 있고 단위들은 상당히 대수 함수적이다. 탐색으로부터 지수적인 부채꼴이 나타나기 때문에 적용범위의 추가적 증가를 획득하는 것은 전체 상황들에서 배수적인 증가를 고려할 것을 요구한다.
그림에서의 곡선들은 동일-수행선들 equal-performance isobars 이다. 동일한 선에서 다른 점에 위치만 시스템들 (A, 그리고 B) 은 동일하게 효과적일 것이지만, 그것들은 미리 준비된 바로 사용할 수 있는 지식과 현 상황에 관한 숙고의 다른 혼합에 의해 그 효과를 달성할 것이다. 만약 한 시스템이 한 선의 어떤 점 (이를테면, 점 A) 에 위치한다면, 규칙에 접근하는 데 시간을 좀더 적게 사용하고, 탐색에는 시간을 조금 더 사용하여 결국 동일한 수행을 보이는 다른 시스템이 있다. 선들은 대충 평행적인 곡선들의 한 집합을 만드는데 수행은 위로 올라갈수록, 그리고 오른쪽으로 (큰 화살표를 따라) 갈수록 증가하며, 그 곳에서 즉각적인 지식과 탐색이 모두 증가한다.
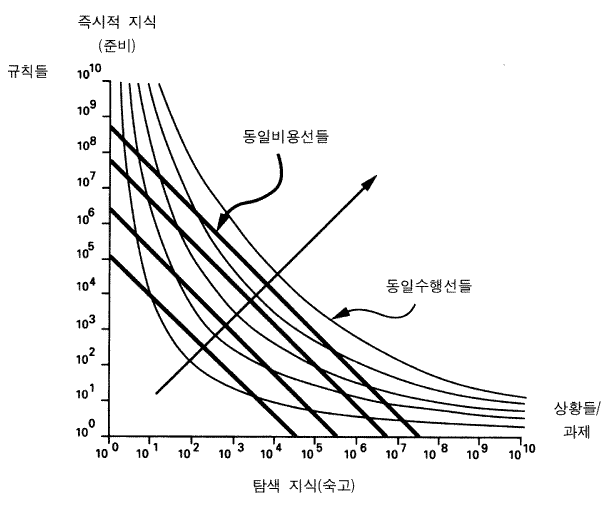
그림 20 동일-비용선들과 동일-수행선들
선들은 동일한 수행을 나타내는 곡선이지 동일한 계산비용을 나타내는 곡선들은 아니다. 지식 탐색이나 문제 탐색을 하는 데 계산 자원들이 사용되기 때문에, 그림 20 에 제시된 것처럼 동일-비용성들 equal-cost isobars 의 집합도 존재한다. 경제적 추론에서와 유사한 형태 (이 상황과 매우 흡사하다) 로 비용선들은 수행선들과 교차한다. 비용선들은 거의 직선일 수도 있다. 한 시스템에 대한 최적의 혼합점이 분명히 있는데, 그곳은 비용선과 최상의 수행선이 만나는 곳이다. 그림의 두꺼운 화살표는 그러한 최적-혼합점들을 통과한다. 그것들이 문제 탐색의 양과 지식 탐색의 양과의 최선의 교환을 구성한다.
특정한 시스템들은 그림 19 에서 특정한 점들에 위치한다. 사실, 그림은 AI 의 역사를 대략적으로 설명하는 데 사용될 수 있다. 초기의 AI 프로그램들은 매우 적은 지식 —— 12 개보다 적은 영역지식 규칙들—— 을 갖고 있었다. 그것들은 100-1,000 마디의 트리들 trees 에서 적당한 양의 탐색을 했다. 그것이 자주 AI 의 탐색 단계 search period 라고 불리는 단계이다. 그 후 많은 지식이 사용될 수 있다는 자각이 생겨났다 —— 전문가 시스템 expert system 또는 규칙-기반 시스템 rule-based system 이라고 불리는 영역에서. 전문가 시스템은 매우 적은 추론이나 숙고, 그러나 즉각적으로 가용한 지식에의 접근에 모든 노력을 쏟아서 획득할 수 있는 것들의 활용이라고 볼 수 있다. 현재의 전형적인 전문가 시스템들은 수백 개의 지식규칙과 숙고적으로 탐색되는 단지 수십 개의 상황들로 이루어진 영역에 존재한다. 가장 큰 전문가 시스템들이 갖고 있는 규칙은 약 5, 000 개에 이르며 많은 추가적인 탐색은 하지 않는다.
인간도 이와 동일한 그림에서 위치될 수 있다. 만약 우리가 비교적 범위가 좁은 과제에 관한 전문가 행동을 생각하면, 우리는 수 만개의 정보의 청크들이 관련되어 있음을 알 것이다 (Simon & Gilmartin, 1973) . 인간은 현재의 전문가 시스템들이 탐색하는 것보다는 많은 탐색을 하지만, 단지 수백 개의 상황들에서 탐색할 뿐, 수천 개의 상황들에서 하지는 않는다. 물론, 한 사람이 많은 영역들에서 전문성을 갖는다. 그러한 영역들을 통합하는 것은 인간을 지식 축에서 약 106 또는 108 의 청크까지로 상향 이동시키지만 탐색의 크기를 증가시키지는 않을 것인데, 이는 외부적으로 고정된 반응시간 (여기서는 최소한 몇 분이 소요됨) 과 구성이 기초연산들을 하는 속도가 일정하게 유지되고, 그것들에 의해서 탐색의 크기가 비교적 고정되어 있기 때문이다. 그러므로 이 도표는 하나의 성격적 특징, 즉 고정된 구성을 갖고 있는 주어진 시스템에서, 향상은 지식을 더함으로써 나타나지, 탐색 양을 더함으로써 나타나는 것이 아님을 보여준다. 그러므로 전형적으로 시스템들은 지식을 확보함에 따라, 수직축에서 상향 이동한다.
지능 시스템의 본질을 이해하는데, 그림 19 의 유용성은 하이텍 Hitech 의 이야기에서 잘 알 수 있다. (주석 : 사실상, 그러한 일반적인 생각은 물론 컴퓨터 과학에서 오랫동안 공유했던 지식이었지만, 여기서의 교환에 관한 특정한 분석은 한스 베를리너에 의한 것이다.) 이것은 한스 베를리너 Hans Berliner 와 칼 에벨링 Carl Ebeling (1988) 에 의해 개발된 체스 프로그램인데, 그것은 현재 인간의 체스 선수권 대회에서 최고수준 (2,360 점) 의 공식적 순위를 갖고 있다. 하이텍은 초당 약 17 만 5, 000 개의 체스 위치를 생성하는, 64 개의 병렬처리 장치를 갖고 있는 특수한 하드웨어 구성이다. 그것은 말의 움직임 당 약 108 개의 상황들을 만들어낸다. 그러므로 하이텍은 대규모의 탐색에 의해 작동하는 시스템이다. 그러한 다른 프로그램과 마찬가지로, 하이텍은 많은 지식을 사용하지 않는다. 초기에 (1985), 그것은 수십 개의 규칙들 —— 알파, 베타와 같은 몇 개의 일반적 규칙들과 위치를 평가하는 몇 개의 좀더 특수한 규칙들 ——을 갖고 있었다. 이 특징은 하이텍을 도표에서 오른쪽 끝에 위치시킬 것이다. 그 수준의 수행에서, 그것은 약 1,900 점으로 본질적으로는 높은 전문가 수준으로 평가되었다. 그 이후 그것의 점수가 약 400 점 증가했다. 물론 그러한 변화 모두는 고정된 탐색 능력을 갖고서 일어났다 —— 지적했듯이, 구성은 본질적으로 탐색의 크기를 고정한다. 하이텍이 1,900 점의 수행을 할 때나 현재 2,350 점의 수행을 할 때나 탐색의 크기는 동일했다. 그러므로 하이텍은 그림에서의 수직 축에서 상향 이동했고, 그것은 더 많은 지식이 하이텍에 넣어졌다는 것을 뜻한다. 그리고 사실상, 그러했다. 그것의 지식은 현재 약 100 여 개의 규칙에 달한다. (주석 : 하이텍은 단순한 규칙-기반적 형태로 조직화된 것은 아니다. 그리고 그것의 저장된 지식에 관한 정확한 계산은 시도되지 않았다.) [위치당 단지 약 5 마이크로초 (100 만 분의 1 초) 인 이동 생성자의 속도로 지식이 적용되어야 하기 때문에, 하이텍에 지식을 더하는 일은 쉬운 일은 아니다]
하나의 마지막 교훈이 그림 19 에서 얻어질 수 있다. AI 와 인지과학에서 인간지능과 하이텍과 같은 지능 시스템을 대비적인 용어로 말하는 것이 일반적이다. 하이텍은 무자비한 계산력을 갖춘 탐색자이고, 그것은 <인간지능과는 완전히 다른 방식> 으로 작동한다. 그림 19 는 다른 관점을 촉구한다. 분명히 다른 종류의 지능 시스템은 준비-숙고 공간의 다른 영역들을 차지하지만 하이텍과 같은 시스템들은 전문가 시스템이나 인간이 분석되는 동일한 방식으로 분석될 수 있다. 그들은 다른 영역을 차지하지만 그 분석은 동일하다. 하이텍은 다른 시스템들과 마찬가지고, 다만 지식이 추가됨에 따라 더 좋은 수행을 보인다. 그러므로 AI 에서의 과학적 목적은 준비-숙고의 전체공간과 그 공간에 있는 시스템들이 서로 관련되는 방식을 이해하는 것이다. 그 공간의 모든 영역들은 아직 연구되지 않은 채 남아 있다.
그림 19 에서 그려진 상황은 유전학에서의 상황을 회상하게 한다. 그것들 사이의 유비는 의심할 여지없이 불완전한 것이지만, 교훈적일 수 있다. 인구생물학에서 종들의 다른 진화론적 전략이 구분될 수 있다 (Wilson, 1975). 두 가지의 극단적인 전략이 r-전략과 K-전략이다. (주석 : 그 이름들은 수량적 인구모형들에서 사용되는 기호논리 방정식에서의 상수들로부터 나온 것이다.) r-전략은 많은 후손을 갖고 그들에게 가능하면 적은 에너지를 사용하는 것이다. 많은 후손은 죽을 것이지만, 그 종은 수로써 극복된다. K-전략은 적은 후손을 갖지만 후손들 각각에게 가능한 한 많은 에너지를 사용한다. 이것은 큰 육식동물들이나 인간들의 전략이다. 이 두 전략이 하나의 공간을 정의하고 그 공간에서 진화적 가능성이 이해된다. 인구 유전학에서의 어떤 문제들은 이러한 다른 전략적 가능성들을 고려했을 때, 더욱 명확해진다. 유사하게, 준비-숙고 공간을 정의하는 많은 지식 전략과 많은 탐색 전략 간의 선택은 지능 시스템을 사용하는 종들의 중요한 선택이다.
이 장에서는 인지과학의 기초를 이루는 핵심적인 용어들을 살펴보았다. 그러한 개념들을 반복하는 것은 이 책의 나머지 부분에 대한 기초를 다지는 합리적인 방법처럼 보인다. 그림 21 과 22 는 나중의 장에서 이 개념들이 다시 나타났을 때 쉽게 참조될 수 있도록 요약해 놓은 것이다. 그림 21 에는 모든 핵심 용어들과 구절들이 그것의 본질적 특성을 제공하는 짧은 진술과 함께 목록으로 만들어져 있다.
|
행동 시스템 환경에 대하여 다중의 반응 함수들에 의해서 특징되는 시스템 지식 지식-수준 시스템의 매체 목표들을 달성하기 위해 사용될 수 있는 것 표상과 처리에서 추상화된 것 지식수준은 단순히 또 하나의 시스템 수준이다 표상 시스템은 표상법칙들을 따른다 변환들 조합하기 표상하기에 대한 일반적 접근 조합적 다양성을 보여주는 특수하지 않은 매체를 사용 표상법칙들을 만족시키기 위해 변환들을 조합 만약 표상의 충분한 다양성이 요구된다면 요구됨 계산 시스템 함수들을 명세하는 다른 입력들을 사용함으로써 어떤 입력들과 출력들에 대한 다중함수들을 획득하는 기계 기호 원거리 접근을 획득하기 이한 기제 시스템의 충분한 다양성이 요구된다면 요구됨 구성 기호-수준 시스템에 대한 추정 정도 지능 지식-수준 시스템에 대한 추정 정도 탐색 문제 탐색 : 과제 해결을 위한 문제공간에서의 탐색 지식 탐색 : 문제 탐색을 안내하기 위한 기억에서의 탐색 문제 공간 상태들의 집합과 상태에서 상태로 이동시키는 연산자들의 집합 • 연산자들은 적용 가능성의 조건들을 가질 수 있다 과제는 연산자들을 자유롭게 적용해서 원하는 상태를 찾는 것이다 상태들은 행위자에 의해 생성되는 것이지, 사전에 존재하는 것은 아니다 숙고 대 준비 교환 숙고 : 과제가 설정된 후의 활동 준비 : 과제가 설정되기 전의 활동 교환 : 두 유형의 활동의 상대적 혼합 |
그림 21 인지과학을 위한 기초적 용어들
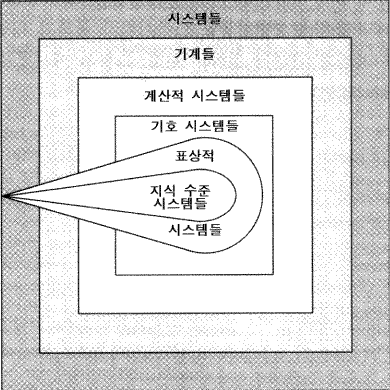
그림 22 시스템의 다른 유형들
이 장을 통해서 여러 가지 시스템들이 소개되었다. 그림 22 는 그것들이 서로 어떤 관계가 있는지 알려준다. 시스템의 내적 구조에 초점을 맞추면 그것은 점점 더 특수화되는 4 개의 포개어지는 시스템의 집합들을 보여준다. 가장 일반적인 것은 단순히 모든 시스템의 집합이다. 시스템들은 기계로 특수화될 수 있는데 기계는 매체를 갖고 있고, 그러므로 모든 기계가 그것의 입력에서 출력으로의 함수에 영향을 주는 것처럼 (사실상은 과거의 모든 입력에서 출력으로) 기계에 대해 입력과 출력이 정의될 수 있다. 계산 시스템들은 다중 함수들을 생성할 수 있는 기계들이다 —— 그것들은 입력과 출력 간에 유지되는 함수들을 명세화하기 위해 그것들의 입력의 일부를 사용함으로써 작동한다. 기호 시스템들은 기호, 즉 원거리 접근을 위한 장치를 갖고 있는 계산 시스템들이다. 그 그림은 계산 시스템들의 다양성이 기호 시스템들의 다양성에 비해 훨씬 크며 기계들의 다양성이 컴퓨터들의 다양성에 비해 훨씬 크며 기타 등등을 적절하게 반영하지는 못했지만, 그 그림은 마음-같은 능력을 지원할 수 있는 시스템에 대한 우리의 관심을 반영하기에 충분하다.
두 개의 혜성 모양의 영역들은 외부 세계와 관련된 적응을 지원하는 시스템들을 나타낸다. 큰 집합이 표상 시스템으로, 그것의 내적 구조는 표상법칙을 따르는 시스템이다. 그러한 법칙들이 적응을 지원한다. (주석 : 나는 적응을 지원하지만 표상적이 아닌 시스템들을 논의하지 않았다. 그것들은 시스템들의 적응적 집합의 또 하나의 외부 계층일 것이다. 그 명백한 후보자들은 진화와 인간 설계자들에 의해 만들어진 것들인 개방-루프 적응들일 것이다. 그 예들은 새의 날개 또는 바퀴일 것이다.) 표상 시스템 안에 지식수준 시스템이 있는데 그것은 그것의 행동이 세계와 그것의 목표들에 대한 표상들의 내용으로부터 직접 도출될 수 있도록 구조화된 시스템이다. 지식수준에서 기술할 수 없는 많은 표상 시스템들이 있다.
표상 시스템들은 어떤 구조에서든 실현되어야만 하기 때문에 두 개의 혜성모양의 영역들은 4 개 유형의 시스템 구조들과 교차한다. 영역과 목표에 대한 충분한 범위를 갖고 있는 표상 시스템들은 실현되기 위해 기호 시스템을 요구하지만, 범위가 축소됨에 따라 더 적은 능력을 갖고 있는 구조들도 역시 사용될 수 있다.
이러한 보다 일반적인 시스템 구조들과의 교차영역들은 점점 작아지는데, 그것은 좀더 특수화된 그들의 특성을 나타낸다. 물론, 각 유형에서 많은 구조들은 표상법칙들을 만족시키지 못하기 때문에, 그러한 것들은 외부 세계와 관련된 것이 아니고, 그렇기 때문에 적극적인 적응을 지원하지 않는다.