p (B = b) =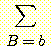 p (B, M, L, G)
p (B, M, L, G)
Reasoning with Uncertain Information
인공지능-지능형 에이전트를 중심으로 : Nils J.Nilsson 저서, 최중민. 김준태. 심광섭. 장병탁 공역, 사이텍미디어, 2000 (원서 : Artificial Intelligence : A New Synthesis, Morgan Kaufmann, 1998), Page 343~367
자신이 하는 일과 환경에 대해 불확실한 정보를 가지고 있는 경우가 많다. 지금까지 설명한 방법으로는 불확실한 지식을 표현하고 추론하는 데 제한이 많았다. P ∨ Q 와 같은 문장으로 P 또는 Q 가 참이라는 불확실성을 표현할 수 있지만 P 또는 Q 가 참일 가능성이 어느 정도인가를 표현할 수는 없다.
기존 방법으로는 P 와 P ⊃ Q 로부터 Q 를 추론할 수 있었다. 즉, P ⊃ Q 라는 것을 알고 있을 때 나중에 P 라는 사실을 알게 된다면 Q 라고 추론을 할 수 있었다. 주어진 정보가 불확실한 경우에도 유사한 추론 방법이 있을까? 불확실한 정보를 표현하고 추론하는 여러 가지 방법이 제시되었다. 앞에서 이미 MYCIN 과 PROSPECTOR 에서 사용되는 방법에 대하여 조금 언급한 바 있다. 가장 발전된 방법은 확률론에 기초를 두고 있다. 이러한 방법에 대하여 설명하기 전에 먼저 확률론에 대하여 간단하게 살펴보기로 한다.
V1, V2, ..., Vk 를 확률변수 (random variable) 라고 하자. 확률변수 Vi 의 값은 vi 로 나타낸다. 확률변수는 여러 가지 유형의 값을 나타낼 수 있다. 예를 들어 이 변수가 명제를 나타낸다면, 이 변수의 값은 참 또는 거짓 (또는 0 이나 1) 일 것이다. 이 변수가 (크기, 무게, 속도 등과 같은) 치수를 나타낸다면, 이 변수의 값은 수치가 될 것이다. 이 변수가 (색상, 글자 등과 같은) 범주를 나타낸다면 이 변수의 값은 범주명이 될 것이다. 예를 들어, 동전을 던졌을 때의 결과를 하나의 변수 C 로 표현할 수 있다. 이 변수의 값 c 는 앞면을 나타내는 H 또는 뒷면을 나타내는 T 가 될 것이다. 동전을 k 번 던지는 경우라면 k 개의 변수 (C1, ..., Ck) 로 표현할 수 있다. 각 변수 ci 는 역시 H 또는 T 값을 가질 수 있다.
확률변수 V1, V2, ..., Vk 의 값이 v1, v2, ..., vk 일 때 결합 확률 (joint probability) 은 p (V1 = v1, V2 = v2, ..., Vk = vk) 로 나타낸다. p (V1, V2, ..., Vk) 는 변수 V1, V2, ..., Vk 상에서의 결합 확률 함수 (joint probability function) 라고 한다. 이 함수는 변수의 집합을 0 과 1 사이의 실수로 사상한다. p (V1, V2, ..., Vk) 의 각 변수를 특정값으로 치환한 것은 p (V1 = v1, V2 = v2, ..., Vk = vk) 로 표현하며, 이를 간단히 p (v1, v2, ..., vk) 로 표현하기도 한다. 동전을 던지는 경우 p (H) = 1 / 2 일 것이다. 동전을 5 번 던지면 p (H, T, T, H, T) = 1 / 32 일 것이다. p (H, T, T, H, T) 는 첫번째에 앞면, 두번째에 뒷면, 세번째에 뒷면, 네번째에 앞면, 다섯번째에 뒷면이 나왔을 때의 결합 확률을 의미한다.
확률함수는 다음과 같은 성질을 만족한다.
(a) 0 ≤ p (V1, V2, ..., Vk) ≤ 1
(b) Σ p (V1, V2, ..., Vk) = 1
(b) 는 모든 변수의 값에 대해서 합을 구하는 것을 나타낸다. 그러므로 동전 던지기 예에서 p (H) = 1 / 2 이라는 것은 (a) 를 만족한다. 한편 (b) 에 의해 p (T) = 1 / 2 이 될 것이다. 여기서는 확률변수의 각 값에 대하여 어떤 확률값을 부여할 것인가에 대해서는 별로 할 이야기가 없다. 명제논리 정형식으로 표현된 각 명제의 참 거짓값은 사람의 주관적인 판단에 따라 주어지듯이 각 확률변수의 확률값도 사람의 주관적인 판단에 따라 주어진다. 우리의 주 관심사는 이러한 확률값을 어떻게 계산할 것인가하는 것이다.
이 장에서 사용되는 확률변수는 주어진 도메인의 명제를 나타낸다. 이러한 명제는 참 또는 거짓값을 가질 수 있다. 따라서 이러한 명제를 나타내는 확률변수 또한 참 또는 거짓값을 가질 것이다. 그런데 명제의 참 거짓에 대해 확실하게 알지 못하는 경우도 있을 수 있다. 이러한 불확실성은 해당 변수의 값에 대한 확률로 표현한다. 이장에서 설명할 방법은 13장 명제논리와 14장 명제논리에서의 논리융합에서 설명한 명제를 이용한 추론 방법에 확률론을 적용한 것이다 (일차 술어논리에 확률론을 적용하는 방법에 대한 연구가 한창 진행중이다. 이에 대해서는 [Nilsson 1986, Glesner & Koller 1995] 를 참조하라).
명제논리에서의 추론에 대하여 설명하면서 사용했던 예를 다시 보자. 이 예에서 BAT_OK, MOVES, LIFTABLE 은 각각 배터리가 충분히 충전되었음, (블록을 쥐고 있는 로봇의) 팔이 움직임, 블록을 들 수 있음을 나타내는 아톰들이다. 여기에 배터리의 상태를 나타내는 계기가 배터리가 충분히 충전되었음을 알려 주는 것을 의미하는 GAUGE 라는 아톰을 추가하자. 표기를 좀 간단하게 하기 위하여 이들 아톰을 각각 B, M, L, G 로 줄여서 표현하기로 한다. 이제 이들 아톰이 참인지 거짓인지 잘 모른다고 가정하자. 계기를 읽기 전에 이들 변수의 다양한 조합에 대한 선험적 확률 (priori probability) 을 미리 알고 있다고 하자. 예를 들어, 우리는 M 을 제외한 다른 것들이 모두 참이면 M 이 거짓이 될 가능성이 매우 낮다는 것을 사전에 알 수 있다.
이진값을 갖는 변수가 4 개 있기 때문에 p (B = b, M = m, L = l, G = g) 와 같은 형태의 결합 확률은 총 16 개이다. 여기서 b, m, l, g 는 참 또는 거짓을 나타낸다. 로봇 설계자는 이들 결합 확률값이 0 과 1 사이이며 이들을 전부 더했을 때의 값이 1 이라는 제약조건하에 16 개의 확률값을 지정할 수 있다. 예를 들면 다음과 같다.
|
(B, M, L, G) |
결합 확률 |
|
(참, 참, 참, 참) |
0.5686 |
(물론 이 설계자가 위와 같은 정밀도로 확률값을 지정하지 않을 수도 있다. 여기서는 단지 이 장의 뒷부분에 나오는 확률값의 정밀도와 일관성을 유지하기 위하여 위와 같은 정밀도로 확률값을 나타내었을 뿐이다.)
확률변수 집합이 있다고 하자. 이 집합에 대한 모든 결합 확률값을 안다면 이들 확률변수의 한계 확률 (marginal probability) 을 계산할 수 있다. 위의 예에서 한계 확률 p (B = b) 는 16 개의 결합확률 중 B = b 인 8 개의 결합 확률을 모두 더한 것으로 정의된다. 즉 다음과 같은 관계가 성립한다.
p (B = b) =p (B, M, L, G)
위 식을 이용하면 한계 확률 p (B = 참) 을 계산하면 (B 가 참인 8 개의 결합 확률을 전부 더한 값인) 0.95 가 된다.
차수가 낮은 (즉, 확률변수의 개수가 적은) 결합 확률도 차수가 높은 (즉, 확률변수의 개수가 많은) 결합 확률값을 더하는 방법으로 구할 수 있다. 위의 예에서 결합 확률 p (B = b, M = m) 은 B = b, M = m 인 4 개의 결합확률을 더한 값과 같다. 즉, 다음과 같은 관계가 성립한다.
p (B = b, M = m) =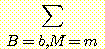 p (B, M, L, G)
p (B, M, L, G)
마찬가지로 p (B, M, L) 과 p (B, M, L) 로부터 p (B = b), p (B = b, M = m) 을 다음과 같이 구할 수 있다.
p (B = b) =![]() p
(B, M)
p
(B, M)
p (B = b, M = m) =![]() p
(B, M, L)
p
(B, M, L)
이 책에서는 참 또는 거짓을 취하는 명제변수를 사용할 때 p (B = 참, M = 거짓) 대신 p (B, ¬ M) 과 같이 간단하게 표현하는 방법도 사용할 것이다. 이 표현 방법에서 부정 부호 (¬) 가 없는 것은 참, 있는 것은 거짓을 나타내는 것으로 한다. 이러한 약식 표현 방법은 문맥상 확률 함수 (probability function) 인지 특정 확률값인지 분명한 경우에만 사용될 것이다.
확률변수들이 있다고 하자. 이들 변수 전체에 대한 결합 확률 함수 (joint probability function) 가 주어지면 원칙적으로 모든 한계 확률과 이보다 차수가 낮은 결합확률을 계산할 수 있다. 그런데 확률변수의 개수가 많은 경우 이들 변수 전체에 대한 결합 확률을 전부 명시하는 것이 매우 어렵다. 그러나 다행히도 대개의 경우 결합 확률은 이들을 명시하고 계산할 수 있도록 하는 특수 조건을 만족한다. 이 조건에 대해서는 이 장의 뒷부분에서 설명할 것이다.
어떤 변수값에 대한 정보를 이용하여 다른 변수값에 대한 확률을 계산하려는 경우도 있을 것이다. 예를 들어, 블록을 들어올리는 로봇의 팔이 움직이지 않을 경우 배터리가 충전되어 있을 확률이 얼마인지 알고자 하는 경우이다. 논리적 추론 방법과 유사한 관점에서 보아 이러한 계산을 확률 추론 (probabilistic inference) 이라고 한다. 확률 추론이 어떻게 수행되는가에 대하여 설명하기 전에 조건부 확률 (conditional probability) 에 대하여 먼저 정의하고 넘어가자.
Vj 가 주어졌을 때 Vi 에 대한 조건부 확률 함수 (conditional probability function) 는 p (Vi | Vj) 로 나타낸다. 확률변수 Vi, Vj 의 값에 관계없이 다음 관계가 성립한다.
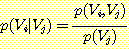
여기서 p (Vi, Vj) 는 Vi 와 Vj 의 결합 확률을 p (Vj) 는 Vj 의 한계 확률을 나타낸다. 이 식을 변형하면 다음과 같은 관계가 성립한다.
p (Vi, Vj) = p (Vi | Vj) p (Vj)
위의 예로 다시 돌아가면, 로봇의 팔이 움직이지 않을 때, 배터리가 충전되어 있을 확률은 다음과 같이 계산할 수 있다.
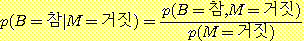
이 식에서 분자와 분모 둘 다 앞에서 설명한 방법대로 결합 확률을 더하여 구할 수 있는 것들이다.
확률을 실험 횟수로 해석하면 조건부 확률을 쉽게 이해할 수 있다. 예를 들어, p (M =거짓) 은 로봇의 팔이 움직이지 않은 횟수를 총 (무한번 수행한 가상의) 실험 횟수로 나눈 비율을 의미한다. 따라서 로봇의 팔이 움직이지 않는다는 조건이 주어졌을 때 배터리가 충전되어 있을 확률은 로봇의 팔이 움직이지 않고 동시에 배터리가 충전되어 있는 휫수를 로봇의 팔이 움직이지 않은 총 횟수로 나눈 값이 된다. 이런 의미에서 조건부 확률은 결합 확률을 정규화한 것으로 볼 수 있다.
그림 1 과 같은 벤 (John Venn 은 영국 논리학자이다 [Venn 1880].) 다이어그램은 결합 확률과 조건부 확률을 이해하는 데 도움을 준다. 이 다이어그램을 보면 중첩된 두 개의 타원이

그림 1. 벤 다이어그램
있는데 각각 로봇의 팔이 움직이지 않는 (즉, M = 거짓) 경우와 배터리가 충전되어 있는 (B = 참) 경우를 나타낸다. 각 타원의 면적은 (한계) 확률에 비례한다. 두 타원 바깥 부분은 로봇의 팔이 움직이고 동시에 배터리가 충전되어 있지 않다는 것 (p (M = 참, B = 거짓)) 을 나타낸다.
이 그림에서 두 타원의 각 부분은 왼쪽부터 차례로 로봇의 팔이 움직이지 않고 배터리가 충전되어 있지 않은 상태, 로봇의 팔이 움직이지 알고 배터리가 충전되어 있는 상태, 로봇의 팔이 움직이고 배터리가 충전되어 있는 상태를 나타낸다. 각 부분의 면적은 결합 확률에 비례한다. 이 그림에서 한계 확률 p (B) 는 결합 확률의 합 즉 p (B, M) + p (B, ¬ M) 으로 주어짐을 알 수 있다.
2 개 이상의 변수에 의한 조건부 결합 확률 (joint conditional probability) 도 정의할 수 있다. 예를 들어
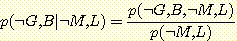
조건부 확률을 계산하는 데 필요한 결합 확률과 한계 확률은 이미 앞에서도 설명한 것처럼 모든 변수를 다 가지고 있는 결합 확률로부터 계산할 수 있다.
결합 확률을 일련의 조건부 확률로 나타낼 수 있다. 예를 들어
p (B, L, G, M) = p (B | L, G, M) p (L | G, M) p (G | M) p (M)
이것을 연쇄 법칙 (chain rule) 이라고 하는데 이 규칙의 일반적인 형태는 다음과 같다.
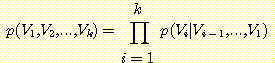
연쇄법칙은 Vi 가 나열되는 순서와 상관이 있다. 이 변수의 순서가 달라지면 연쇄 법칙의 모양은 달라지겠지만 변수의 값이 같다면 확률값도 같다.
결합 확률 함수에서 변수의 순서는 중요하지 않으므로 다음 관계가 성립한다.
p (Vi, Vj) = p (Vi | Vj) p (Vj) = p (Vj | Vi) p (Vi) = p (Vj, Vi)
윗식을 변형하면,
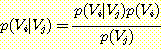
위와 같은 식을 얻게 되는데 이것을 베이지안 규칙 (베이지안 규칙은 Thomas Bayes 에 의해 체계가 세워졌다 [Bayes 1763].) 이라고 한다.
여러 변수에 대한 결합 확률 또는 여러 변수에 의한 조건부 확률이 주어졌다고 하자. 이런 경우 집합을 이용한 표기를 하면 편리하다. 예를 들어 V = {V1, V2, ..., Vk} 라고 했을 때 p (V1, V2, ..., Vk) 대신 p (V) 라고 간단하게 표기할 수 있다. 마찬가지로 Vj 를 변수들의 집합이라고 했을 때 조건부 확률을 p (V | Vj) 와 같이 간단하게 표기할 수 있다. 변수 V1, V2, ..., Vk 가 각각 v1, v2, ..., vk 란 값을 취한다고 했을 때 이것을 V = v 로 간단히 표기한다. 여기서 V 와 v 는 순서가 있는 리스트를 나타낸다.
집합 V = V1, V2, ..., Vk 를 명제 변수들의 집합이라고 하고, ε 를 V 의 부분 집합이라고 했을 때 ε 에 속하는 변수들이 일정한 값 (참 또는 거짓 값을 가지며 ε = e 로 표기함) 을 취한다는 사실이 증거 (evidence) 로서 주어졌다고 하자. 로봇 관련 응용에서 주어지는 변수는 통상적으로 지각 과정을 통해 얻은 값을 가지게 된다. 주어진 증거에 대하여 변수 V1 가 vi 란 값을 가질 조건부 확률 p (Vi = vi | ε = e) 를 계산하려고 한다. 이러한 계산을 하는 과정을 확률 추론 (probabilistic inference) 이라고 한다.
Vi 는 참 또는 거짓 값을 가질 수 있으므로 p (Vi = 참 | ε = e) 와 p (Vi =거짓 | ε = e) 를 구해야 한다. 사실은 이 둘 중의 하나만 구하면 된다. 왜냐하면 ε 의 값에 상관없이 p (Vi = 참 | ε = e) + p (Vi =거짓 | ε = e) = 1 이 되어야 하기 때문이다. 간단한 방법으로 p (Vi =참 | ε = e) 값을 계산함으로써 이 사실을 입증해 보자. 조건부 확률의 정의에 따라
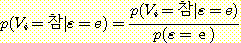
차수가 높은 결합 확률로부터 차수가 낮은 결합 확률을 계산하는 규칙을 사용하여 p (Vi = 참 | ε = e) 를 계산하면,
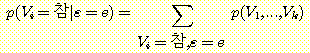
여기서 V1, V2, ..., Vk 는 명제변수를 나타낸다. 이 식에서 알 수 있듯이 V1 = 참이고 ε = e 인 모든 결합 확률을 더하면 된다. p (ε = e) 의 계산도 마찬가지 방법으로 할 수 있다.
예를 들어 결합 확률이 다음과 같이 주어졌다고 하자.
p (P, Q, R) = 0.3
p (P, Q, ¬ R) = 0.2
p (P, ¬ Q, R) = 0.2
p (P, ¬ Q, ¬ R) = 0.1
p (¬ P, Q, ¬ R) = 0.05
p (¬ P, ¬ Q, R) = 0.1
p (¬ P, ¬ Q, R) = 0.05
p (¬ P, ¬ Q, ¬ R) = 0.0
R 이 증거로 주어졌다고 하고 p (Q | ¬ R) 을 계산해 보자. 위에서 설명한 방법에 따라 다음을 계산한다.
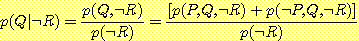
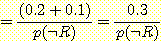
윗식의 값을 구하려면 p (¬ R) 값을 구해서 대입하면 된다. 한편, 위와 같은 방법으로 p (¬ Q | ¬ R) 값을 계산하고 p (Q | ¬ R) + p (¬ Q | ¬ R) = 1 이라는 성질을 이용하여 p (Q | ¬ R) 의 값을 구할 수도 있다. 후자의 방법으로 p (Q | ¬ R) 값을 구해 보자.
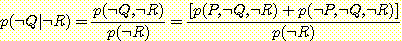
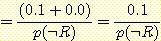
p (Q | R) + p (Q | ¬ R) = 1 이므로 p (Q | ¬ R) = 0.75 가 된다.
일반적으로 이러한 방법으로 확률 추론을 하는 것은 별로 좋은 방법이 아니다. 왜냐하면 k 개의 변수가 주어진 경우 총 2k 개의 결합 확률 p (V1, V2, ..., Vk) 를 나열해야 하기 때문이다. 대개의 경우 우리가 이들 확률값을 모두 알 수 있다 하더라도 이것을 전부 나열하기란 매우 어렵다.
이러한 어려움을 생각하면 도대체 인간은 불확실한 정보로 어떻게 그렇게 효율적으로 추론을 할 수 있는가? 라는 의문을 갖지 않을 수 없다. 인간은 주어진 도메인에 대한 지식을 특수한 방법으로 형식화하기 때문에 특정 증거가 주어진 상황에서 어떤 변수에 대한 조건부 확률값 계산을 매우 단순화시킬 수 있다고 Pearl 은 추측하였다 [Pearl 1986, Pearl 1988, Pearl 1990]. 이러한 형식화는 여러 변수들 사이의 조건부 독립 (conditional independency) 이라는 개념과 관련이 있다.
Vi, Vj 를 변수 집합이라고 하고 V 를 하나의 변수라고 하자. p (V | Vi, Vj) = p (V | VVj) 가 성립한다면 Vj 가 주어졌을 때 V 는 Vi 로부터 조건부 독립이라고 하며 이것을 I (V, Vi | Vj)로 나타낸다. 직관적으로 I (V, Vi | Vj) 이면 이미 Vj 에 대하여 알고 있는 상황에서 Vi 를 안다고 하는 것은 V 에 아무런 영향도 미치지 않는다. 다시 말해서 Vj 를 알고 있다면 Vi 를 무시할 수 있다는 의미다. 블록 들기 예에서 배터리가 충전되어 있다는 것 (B = 참) 을 알고 있다면 로봇의 팔이 움직인다 (M) 는 것과 관련해서 G (계기는 배터리가 충전되어 있음을 알림) 에 대해서 알 필요는 없다. 즉, p (M | B, G) = p (M | B) 가 성립한다.
집합 V 가 주어졌을 때 변수 Vi 가 변수 Vj 로부터 조건부 독립이라면 정의에 의하여 p (Vi | Vj, V) = p (Vi | V) 가 된다. 조건부 확률의 정의에 의해 p (Vi | Vj, V) p (Vj | V) = p (Vi, Vj | V) 가 된다. 이 둘을 결합하면 I (Vi, Vj | V) 인 경우에 다음과 같은 관계를 얻을 수 있다.
P (Vi, Vj | V) = p (Vi | V) p (Vj | V)
Vi 와 Vj 가 대칭적으로 나타남에 주목하라. 이 식에서 알 수 있듯이 V 가 주어졌을 때, Vi 가 Vj 로부터 조건부 독립이라는 것은 Vj 가 Vi 로부터 조건부 독립이라는 것과 같은 의미이다. 따라서 V 가 주어졌을 때 Vi 와 Vj 는 조건부 독립이라고 말할 수 있다. 집합의 경우에도 마찬가지로 말할 수 있다. 따라서 V 가 주어졌을 때 두 집합 Vi 와 Vj 가 조건부 독립이라면 [즉, I (Vi, Vj | V) 이면] p (Vi, Vj | V) = p (Vi | V) p (Vj | V) 가 성립한다. V 가 공집합이라면 그냥 Vi 와 Vj 가 독립이라고 한다.
변수 V1, ..., Vk 가 있다고 하자. 집합 V 가 주어졌을 때 각 변수가 이를 제외한 다른 모든 변수와 조건부 독립이라면 V1, ..., Vk 는 상호 조건부 독립 (mutually conditional independence) 이라고 한다.
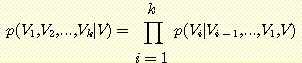
이 성립한다. V 가 주어졌을 때 Vi 가 다른 변수와 조건부 독립이라면 다음 관계가 성립한다.
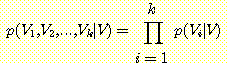
V 가 공집합이라면
p (V1, V2, ..., Vk) = p (V1) p (V2) ... p (Vk)
가 성립하며 이 경우 각 변수는 무조건부 독립 (unconditionaly independence) 이라고 한다.
조건부 독립은 베이지안 네트워크 또는 믿음 네트워크 (belief network) 라고 하는 구조로 표현될 수 있다. 이 구조는 확률 추론을 하는 데 매우 유용하다. 조건부 독립을 이러한 구조로 표현하면 확률 추론에 필요한 계산을 경제적으로 할 수 있다.
Bayesian Network 는 방향성 비순환 그래프 (directed
acyclic grafph, DAG) 이다. 이 그래프의 각 노드는 확률변수를 나타낸다. Bayesian
Network 에서 각 노드 Vi 는 (이 노드의
부모가 주어졌을 때) Vi 의 후손이
아닌 노드들과 조건부 독립이 된다. 주어진 그래프에서 A(Vi)
는 Vi 의 후손이 아닌 노드들을 나타내고,
(Vi) 는 Vi 의
부모를 나타낸다고 하자. Bayesian Network 는 모든 Vi 에
대하여 I(Vi, A(Vi)
| (Vi)) 즉 (Vi | A(Vi),
(Vi)) = (Vi | (Vi)) 가 성립함을 의미한다.
V1, V2, ..., Vk 를 Bayesian Network 를 이루고 있는 노드라고 하자. 이 네트워크가 조건부 독립이라는 가정하에 이 네트워크의 모든 노드에 대한 결합 확률은 다음과 같이 주어진다.
(V1, V2,
..., Vk) = (Vi | (Vi))
Bayesian Network 가 의미하는 부분 순서 (partial order) 와 일관성을 유지하는 연쇄 법칙 순서를 사용하는 모든 변수의 결합 확률을 구하는 연쇄 법칙에 조건부 독립을 적용함으로써 윗식을 쉽게 유도할 수 잇따.
노드를 연결하는 아크를 직접적인 인과 관계를 나타내는 것으로 생각할 수 있기 때문에 때로는 Bayesian Network 를 인과 네트워크 (causal network) 라고 부르기도 한다. Bayesian Network 에서의 조건부 독립이 드러날 수 있도록 원인과 결과를 연관 시킬 수 있는 경우가 종종 있다. 인과 관계에 대한 직관적인 개념으로 Bayesian Network 를 구성하면 내재된 조건부 독립 가정에 적합한 네트워크가 된다. [Heckerman 1996, p.14] 주어진 변수들의 집합들을 위한 Bayesian Network 를 만들려면 원인변수로부터 이의 직접적인 결과로 가는 아크를 그린다. 대개의 경우 이런 방법으로 Bayesian Network 를 만들 수 있다 [이 네트워크의 조건부 독립 함의 (implication) 는 정확하다] 라고 하였다.
블록 들기 예를 이용하여 Bayesian Network 를
만들어 보자. 먼저 이 도메인에서 최초의 원인이라고 생각되는 것 즉 "배터리가
충전되어 있다" 는 명제를 의미하는 B 와 "블록을 들 수 있다" 는
명제를 의미하는 L 이라는 변수로부터 시작하자. B 와 L 은 M (팔이 움직인다)
의 원인이 되며 B 는 G (계기는 배터리가 충전되어 있음을 보여준다) 의 원인이 된다.
다음 그림은 이 예에 대한 Bayesian Network 이다. 이 네트워크는 (M | G, B, L) = (M | B, L) 을 나타내고 있다. 이 네트워크에 다른 노드 가령 U (블록을 위로
들었다) 가 있다고 하자. 그러면 U 는 M 의 후손이기 때문에 (M | G, B, L, U) = (M | B, L) 이 성립하지 않을 것이다 (위로 들어 올려진 블록은 팔이 움직일
확률에 영향을 미친다. 왜냐하면 팔이 움직이지 않고는 블록을 위로 들어올릴 수
없기 때문이다). 이 네트워크의 모든 노드에 대한 결합 확률 함수를 위한 식이 다음
그림에 나타나 있다.
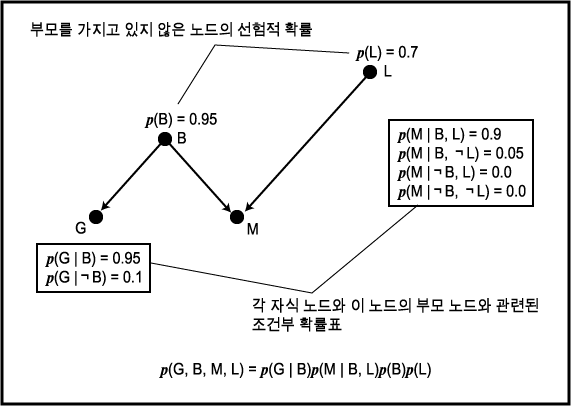
Bayesian Network
Bayesian Network 에 의해 주어진 결합 확률을 계산하기 위해서는 위의 그림과 같이 부모 노드에 의해서만 조건을 받는 노드에 대한 조건부확률 함수에 대해서만 알 필요가 있다. 부모가 없는 노드의 경우에는 다른 노드에 대한 조건부확률 함수에 대해서만 알 필요가 있다. 부모가 없는 노드의 경우에는 다른 노드에 의해 조건을 받지 않는다. 이러한 확률을 이들 변수에 대한 선험적 확률 (prior probability) 이라고 한다. 그러므로 확률변수 집합에 대한 확률을 완전하게 명시하려면 이들 변수에 대한 Bayesian Network 와 네트워크의 각 노드에 대한 조건부 확률표 (conditional probability table, CPT) 를 기술해야 한다.
블록 들기 예에서의 결합 확률 함수에 대한 Bayesian Network 식을 다음과 같이 연쇄 법칙을 사용하여 (조건부 독립이 없음을 가정하고) 얻은 식과 비교하면,
(G, M, B, L) = 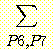 (G | B, M, L)
(G | B, M, L)  (M | B, L)
(M | B, L) 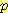 (B | L)
(B | L) 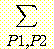 (L)
(L)
Bayesian Network 식이 더 간단함을 알 수 있다. Bayesian Network 에서 가정하고 있는 조건부 독립이 없다면 위와 같은 4 개의 변수에 대한 결합 확률을 나타낼 때 16 개의 결합 확률을 모두 명시해야만 한다 (사실은 15 개만 명시하면 된다. 왜냐하면 16 개의 결합 확률을 전부 더했을 때 합은 1 이 되어야 하기 때문이다). 그러나 위의 그림에서 보듯이 Bayesian Network 에서는 단지 8 개의 확률만 명시하면 된다. 이것은 Bayesian Network 에서 가정하고 있는 조건부 독립성 때문이다. 즉, 주어진 도메인에서 변수들 사이의 조건부 독립이 성립한다면 Bayesian Network 로부터 계산된 결합 확률식은 이러한 조건이 성립하지 않을 때보다 훨씬 적은 수의 확률만을 명시하면 된다. 이와 같이 명시해야 할 확률의 개수가 감소됨으로 인해 전체를 다 명시해야 할 때에는 해결할 수 없었던 문제들도 해결할 수 있게 된다.
Bayesian Network 에서는 다음과 같은 세 가지 중요한 추론 패턴이 있다. 각 추론 패턴에 대해서 예를 들어 설명하기로 한다.
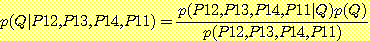 (M | L) 을 계산한다고 하자. 블록을 들 수 있다는 것은 팔이 움직일 수 있다는
것의 원인이 되므로 이러한 계산은 원인 추론 (causal reasoning) 의 한 예가
된다. L 은 추론에 사용된 증거 (evidence) 가 되며 M 은 질의 노드 (query node)
가 된다. 이러한 경우에 어떻게 추론을 수행하는가에 대하여 알아보자. 먼저
(M | L) 을 계산한다고 하자. 블록을 들 수 있다는 것은 팔이 움직일 수 있다는
것의 원인이 되므로 이러한 계산은 원인 추론 (causal reasoning) 의 한 예가
된다. L 은 추론에 사용된 증거 (evidence) 가 되며 M 은 질의 노드 (query node)
가 된다. 이러한 경우에 어떻게 추론을 수행하는가에 대하여 알아보자. 먼저
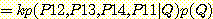 (M | L) 을 M 의 다른 부모인 B 와의 관계에 대해서 나타내기 위하여 다음과
같이 결합 확률에 대한 합으로 확장한다.
(M | L) 을 M 의 다른 부모인 B 와의 관계에 대해서 나타내기 위하여 다음과
같이 결합 확률에 대한 합으로 확장한다.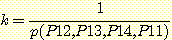 (M | L) =
(M | L) =  (M | B, L) +
(M | B, L) +  (M, ¬B | L)
(M, ¬B | L)
다음, M 이 L 뿐만 아니라 다른 부모에 의해서도
조건을 받도록 하기 위해 연쇄 법칙을 사용하여 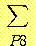 (M | L) 을 다음과 같이 표현할 수 있다.
(M | L) 을 다음과 같이 표현할 수 있다.
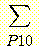 (M | L) =
(M | L) =  (M | B, L)
(M | B, L) 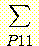 (B | L) +
(B | L) + 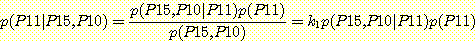 (M, ¬B | L)
(M, ¬B | L) 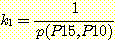 (¬B | L)
(¬B | L)
그러나 네트워크 구조로부터 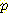 (B | L) =
(B | L) = 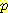 (B) 이며 (B 가 부모를 가지고 있지 않음에 주목하라), 마찬가지로
(B) 이며 (B 가 부모를 가지고 있지 않음에 주목하라), 마찬가지로 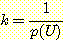 (¬B | L) =
(¬B | L) = 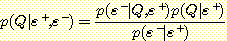 (¬B) 이다.
(¬B) 이다.
따라서 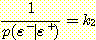 (M | L) =
(M | L) =  (M | B, L)
(M | B, L)  (B) +
(B) + 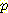 (M | ¬B, L)
(M | ¬B, L) 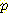 (¬B) 이다. 우항의 값들은 네트워크에 모두 주어져 있으므로 이것을 대입하여
(¬B) 이다. 우항의 값들은 네트워크에 모두 주어져 있으므로 이것을 대입하여
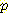 (M | L) 의 값을 계산하면 다음과 같다.
(M | L) 의 값을 계산하면 다음과 같다.
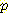 (M | L) = 0.855
(M | L) = 0.855
이 계산법은 보다 복잡한 형태의 문제에 대한 인과 추론을 하는 것으로 일반화할 수 있으므로 주의깊게 살펴 보아야 한다. 위 계산법을 다시 정리하면 다음과 같다.
(a) 질의 노드 V 의 (증거가 주어졌을 때의) 조건부 확률을 V 와 (증거가 아닌) V 의 모든 부모에 대한 (증거가 주어졌을 때의) 결합 확률로 다시 표현한다.
(b) 이 결합 확률을 모든 부모에 의해 조건을 받는 V 의 확률로 다시 표현한다.
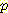 (¬L | ¬M) 를 계산하자. 여기서 질의와 증거는 위와 정반대의 역할을 한다.
원인을 추론하기 위하여 결과 (또는 증상) 를 사용하고 있기 때문에 이러한 유형의
추론을 진단 추론 (diagnostic reasoning) 이라고 한다.
(¬L | ¬M) 를 계산하자. 여기서 질의와 증거는 위와 정반대의 역할을 한다.
원인을 추론하기 위하여 결과 (또는 증상) 를 사용하고 있기 때문에 이러한 유형의
추론을 진단 추론 (diagnostic reasoning) 이라고 한다.|
|
|
(베이지안 규칙) |
|
|
(인과 추론을 사용하여) 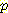 (¬M | ¬L) 을 계산하면 0.9525 가 되므로
(¬M | ¬L) 을 계산하면 0.9525 가 되므로 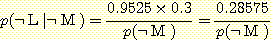 이다. 마찬가지로
이다. 마찬가지로 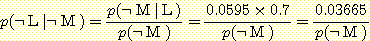 이다. 이 두 식을 더하면 1 이 되어야 하므로
이다. 이 두 식을 더하면 1 이 되어야 하므로 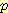 (¬L | ¬M) = 0.88632 이다.
(¬L | ¬M) = 0.88632 이다.
이와 같은 간단한 진단 추론에 대한 예에서 사용된 계산법을 일반화할 수 있다. 일반화에 가장 중요한 단계는 베이지안 규칙을 사용하여 주어진 문제를 인과추론 문제로 변환하는 것이다.
|
|
|
(베이지안 규칙) |
|
|
|
= |
|
(조건부 확률의 정의) |
|
|
|
= |
|
(Bayesian Network 의 구조) |
|
|
이 식으로부터 네트워크에서 주어진 확률을
사용하고 통상적인 방법으로 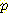 (¬B, ¬M) 을 구함으로써
(¬B, ¬M) 을 구함으로써 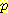 (¬L | ¬B, ¬M) = 0.030 이라고 계산할 수 있다. 이 값은 예상대로 위에서
계산한
(¬L | ¬B, ¬M) = 0.030 이라고 계산할 수 있다. 이 값은 예상대로 위에서
계산한 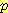 (¬L | ¬M)보다 훨씬 작다. 설명 과정에서 중요한 역할을 하는 베이지안
규칙에 대하여 다시 한번 주목해 볼 필요가 있다.
(¬L | ¬M)보다 훨씬 작다. 설명 과정에서 중요한 역할을 하는 베이지안
규칙에 대하여 다시 한번 주목해 볼 필요가 있다.
V 를 질의 노드, ε 를 증거라고 하자. ε 자체가
불확실한 경우 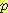 (V | ε) 은 우리에게 적절한 확률값을 주지 못한다. Bayesian Network 계산에서
증거노드가 주어지려면 이것이 나타내는 명제의 진리값을 확실하게 알아야 한다.
이러한 요구조건을 충족시키기 위해 우리는 각각의 (불확실한) 증거 노드가 (확실하게
진리값을 알고 있는) 자식 노드를 갖도록 배치한다. 바로 위의 예에서 (로봇 관절의
각도를 측정하는 센서의 신뢰도가 떨어지는 경우) 로봇은 자신의 팔이 움직이지 않았는지에
대하여 확신을 가지지 못할 것이다. 이런 경우 증거는 노드 M' (팔에 붙어 있는
센서가 팔이 움직였음을 알려줌) 에 의해 주어질 수 있다. 센서가 알려주는 내용에
따라 이 명제가 참인지 거짓인지 확신할 수 있을 것이다. 그러면
(V | ε) 은 우리에게 적절한 확률값을 주지 못한다. Bayesian Network 계산에서
증거노드가 주어지려면 이것이 나타내는 명제의 진리값을 확실하게 알아야 한다.
이러한 요구조건을 충족시키기 위해 우리는 각각의 (불확실한) 증거 노드가 (확실하게
진리값을 알고 있는) 자식 노드를 갖도록 배치한다. 바로 위의 예에서 (로봇 관절의
각도를 측정하는 센서의 신뢰도가 떨어지는 경우) 로봇은 자신의 팔이 움직이지 않았는지에
대하여 확신을 가지지 못할 것이다. 이런 경우 증거는 노드 M' (팔에 붙어 있는
센서가 팔이 움직였음을 알려줌) 에 의해 주어질 수 있다. 센서가 알려주는 내용에
따라 이 명제가 참인지 거짓인지 확신할 수 있을 것이다. 그러면 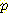 (¬L | ¬B, ¬M) 대신 Bayesian Network 를 사용하여
(¬L | ¬B, ¬M) 대신 Bayesian Network 를 사용하여 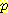 (¬L | ¬B, ¬M') 를 계산할 수 있다. 물론 센서의 신뢰도를 나타내는
(¬L | ¬B, ¬M') 를 계산할 수 있다. 물론 센서의 신뢰도를 나타내는 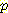 (M', ¬M) 값도 필요하다.
(M', ¬M) 값도 필요하다.
위의 그림의 네트워크는 배터리가 충전되어 있는지
아닌지에 대하여 불확실하다는 사실을 이미 제공하고 있음에 주의하라. 노드 B 는
자식 노드 G 를 가지고 있으며 계기의 신뢰도는 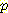 (G | B) 와
(G | B) 와 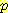 (G | ¬B) 로 나타낸다. 각자
(G | ¬B) 로 나타낸다. 각자 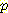 (¬L | ¬G, ¬M') 의 값을 계산해 보기 바란다.
(¬L | ¬G, ¬M') 의 값을 계산해 보기 바란다.
비록 Bayesian Network 로 단순화를 할 수 있었지만 대규모 네트워크의 경우 일반적으로 지금과 같은 방법으로 결합 확률로부터 여러 가지 조건부 확률을 계산하는 것은 별로 바람직하지 못하다. 이 계산법의 최악 시간복잡도는 명제변수의 개수에 지수적으로 비례한다. 다행히 특수한 형태의 네트워크에 대하여 조건부 확률을 간단하게 계산할 수 있는 방법이 있다. 이 방법에 대해서는 Bayesian Network 에서의 조건부 독립에 대한 다른 결과에 대하여 언급한 후에 설명하기로 한다.
위의 그림에서 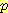 (M | G, B) =
(M | G, B) =  (M, B) 이다. 즉, B 가 주어지면 (M 의 두 부모 모두 주어지지 않더라도) M 은
G 와 조건부 독립이다. 직관적으로 위의 그림의 네트워크에서 (결과) G 에 대한 지식은
(원인) B 에 대한 지식에 영향을 미칠 수 있으며, 이는 (또 다른 결과) M 에 대한
지식에 영향을 미칠 수 있다. 그러나 원인 B 는 G 와 M 을 d-분리 (d-separate) 한다고
말한다.
(M, B) 이다. 즉, B 가 주어지면 (M 의 두 부모 모두 주어지지 않더라도) M 은
G 와 조건부 독립이다. 직관적으로 위의 그림의 네트워크에서 (결과) G 에 대한 지식은
(원인) B 에 대한 지식에 영향을 미칠 수 있으며, 이는 (또 다른 결과) M 에 대한
지식에 영향을 미칠 수 있다. 그러나 원인 B 는 G 와 M 을 d-분리 (d-separate) 한다고
말한다.
Bayesian Network 에서는 같은 종류의 다른 조건부 독립도 존재한다. 이에 대한 증명은 [Pearl 1988, pp. 117-122] 를 참조하기 바란다.
Bayesian Network 에서 두 노드 Vi 와 Vj 사이의 모든 무방향성 경로 위에 다음 세조건을 만족하는 노드 Vb 가 있다면 노드 집합 ε 가 주어진 상황에서 Vi 와 Vj 는 조건부 독립 (즉, I(Vi , Vj | ε)) 이다 (다음 그림참조).
1. Vb 는 ε 에 속하며 이 경로상의 두 아크는 Vb 에서 나간다.
2. Vb 는 ε 에 속하며 이 경로상의 한 아크는 Vb 로 들어가며 나머지 한 아크는 Vb 에서 나간다.
3. Vb 와 Vb 의 어떤 후손도 ε 에 속하지 않으며 이 경로상의 두 아크는 Vb 로 들어간다.
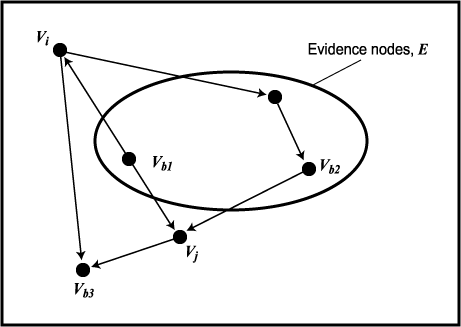
Vi 와 Vj 사이의 세 경로 모두 차단되어 있으므로 증거 노드가 주어지면 Vi 는 Vj 와 독립이다. 차단 노드의 종류는 다음과 같다.
(a) Vb1 은 증거 노드이며 두 아크는
Vb1 으로부터 나온다.
(b) Vb2 은 증거 노드이며 한 아크는
Vb2 로 들어 가고 다른 아크는 Vb2 로부터 나온다.
(c)
Vb3 나 이 노드의 어떤 후손도 증거 노드가 아니고 두 아크는 Vb3
로 들어 간다.
차단 노드를 통한 조건부 독립
어떤 경로가 위 조건 중 어느 하나를 만족하면 우리는 ε 가 주어졌을 때 Vb 가 그 경로를 차단 (block) 한다고 말한다. 여기서 말하는 경로는 무방향성 경로를 의미함에 주의하기 바란다. 여기서 말하는 경로는 무방향성 경로를 의미함에 주의하기 바란다. Vi 와 Vj 사이의 모든 경로가 차단된다면 ε 가 Vi 와 Vj 가 조건부 독립이라고 결론을 내린다. 맨 위의 그림에서 d-분리에 의한 조건부 독립의 다른 예로 아래와 같은 것들이 있다.
그러나 M 이 B 와 L 사이의 경로상에 있더라도 이 경로상의 두 아크가 M 으로 들어가고 M 이 증거 집합에 속하지 않기 때문에 B 와 L 은 조건부 독립이 아니라는 점에 주목하기 바란다. 즉, 이 경우 M 은 그 경로를 차단하지 않는다.
d-분리 개념은 집합에도 적용될 수 있다. 두 노드 집합 Vi 와 Vj 가 ε 에 의해 d-분리되면 ε 가 주어졌을 때 Vi 와 Vj 는 조건부 독립이다. ε 가 주어졌을 때 Vi 에 속하는 모든 노드와 Vj 에 속하는 모든 노드 사이의 모든 무방향성 경로가 차단되면 이들은 ε 에 의해 d-분리된다.
d-분리를 사용하더라도 Bayesian Network 에서의 확률 추론은 일반적으로 NP-hard 문제이다 [Cooper 1990]. 그러나 다중트리 (polytree) 라고 하는 중요한 유형의 네트워크에 대해서는 문제를 단순화시킬 수 있다. 다중트리는 임의의 두 노드 사이의 (두 방향 중 어느 한 방향으로 가는 아크를 따라서) 경로가 하나만 있는 DAG 이다. 다중트리에서 어떻게 확률 추론이 수행되는가를 예를 들어 설명하겠다 (이 방법은 [Russell & Norvig 1995, p.447] 이 제안한 알고리즘에 기초를 두고 있다).
그림 4 에서 본 네트워크는 다중트리의 전형적인 예이다. 이 네트워크에서 Q이외의 다른 노드 중 일부가 주어졌을 때 Q 의 확률을 계산하려고 한다. 노드 중 일부는 Q 의 부모를 통해
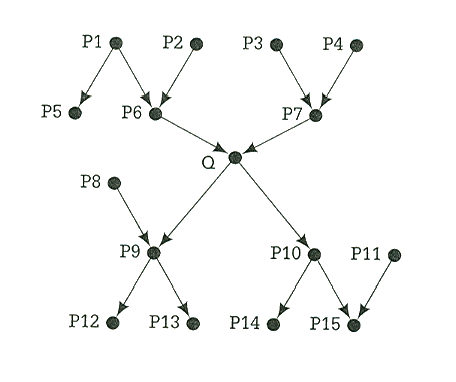
그림 4. 전형적인 다중트리의 예
Q 에 연결되어 있다. 이러한 노드를 Q 위에 있는 노드라고 한다. 다른 노드들은 Q 의 자식들을 통해 Q 에 연결되어 있다. 이러한 노드를 Q 아래 있는 노드라고 한다. Q 를 통해 Q 의 위와 아래를 연결하는 경로는 반드시 Q 를 지나게 된다. 그렇지 않은 경우 주어진 네트워크는 다중트리가 될 수 없기 때문이다. 이것은 다중트리에 있는 모든 노드에 적용된다. 다음과 같은 세 가지 유형에 대하여 살펴보자.
1. 모든 증거 노드가 Q 위에 존재한다. 이러한 유형의 전형적인 예로 p (Q | P5, P4) 에 대한 계산을 들 수 있다.
2. 모든 증거 노드가 Q 아래에 존재한다. 이러한 유형의 전형적인 예로 우리는 p (Q | P12, P13, P14, P11) 에 대한 계산을 들 수 있다
3. Q 의 위와 아래에 증거 노드가 있다.
모든 증거 노드들이 Q 위에 있을 때 p (Q | P5, P4) 를 계산해 보자. 계산 과정은 이 주어진 증거에 도달하거나 Q 의 각 조상 아래에 주어진 증거가 있을 때까지 조상에 대한 확률을 계산하는 상향식 재귀적 알고리즘의 수행 과정과 같다. 알고리즘 전개과정은 다음과 같다.
먼저 다음과 같이 Q 의 "부모를 수반" 하는 식으로 바꾼다.
p (Q | P5, P4) =p (Q, P6, P7 | P5, P4)
(여기서 합의 범위를 나타내는 P6, P7 은 p (Q, P6, P7 | P5, P4) 에서 P6 대신에 ¬ P6 를, P7 대신에 ¬ P7 을 각각 대입했을 때 얻어지는 4 개의 식을 말한다.)
다음, 조건부 독립 정의를 사용하여 Q 의 부모를 증거의 일부로 만든다. 즉,
p (Q, P6, P7 | P5, P4) = p (Q | P6, P7, P5, P4) p (P6, P7 | P5, P4)
치환에 의해
p (Q | P5, P4) = ![]() p
(Q | P6, P7, P5, P4) p (P6, P7 | P5, P4)
p
(Q | P6, P7, P5, P4) p (P6, P7 | P5, P4)
이제 부모가 있는 노드는 후손이 아닌 노드와 조건부 독립이므로
p (Q | P5, P4) = ![]() p
(Q | P6, P7) p (P6, P7 | P5, P4)
p
(Q | P6, P7) p (P6, P7 | P5, P4)
그러면 d-분리에 의해 부모를 분리할 수 있으므로
p (Q | P5, P4) = ![]() p
(Q | P6, P7) p (P6 | P5, P4) p (P7 | P5, P4)
p
(Q | P6, P7) p (P6 | P5, P4) p (P7 | P5, P4)
그리고 마지막으로 d-분리에 의해 다른 부모의 확률을 계산하는 데 하나의 부모 위에 있는 증거를 무시할 수 있으므로
p (Q | P5, P4) = ![]() p
(Q | P6, P7) p (P6 | P5) p (P7 | P4)
p
(Q | P6, P7) p (P6 | P5) p (P7 | P4)
이다. 위에서 더하는 항들은 질의 노드의 부모 (이것의 확률은 베이지안 네트워크를 따라 주어진다) 의 여러 가지 다양한 값이 주어졌을 때 이 질의 노드에 대한 확률과 부모 위의 증거 중 일부가 주어졌을 때 (수행중인 알고리즘을 재귀적으로 호출) 각 부모의 확률이다. 이러한 갈과는 우리들이 다중트리에 대한 계산을 하기 때문에 얻을 수 있는 것이다.
이러한 절차는 하나의 증거 노드를 부모로 가지고 있거나 부모를 가지고 있지 않은 노드 (증거 노드가 아닌 노드) 에 도달할 때까지 재귀적으로 적용된다. p (P7 | P4) 의 계산은 이 두 경우 중 첫번째 경우에 해당한다. 증거 노드 P4 는 질의 노드 P7 의 부모들 중의 하나이다. 이 경우 이들 부모 중 하나가 이미 수반되어 있기 때문에 부모를 수반하는 단계가 훨씬 단순해진다. p (P7, P3 | P4) = p (P7 | P3, P4) p (P3 | P4) 이므로 다음과 같이 쓸 수 있다.
p (P7 | P4) =p (P7 | P3, P4) p (P3 | P4) =![]() p
(P7 | P3, P4) p (P3)
p
(P7 | P3, P4) p (P3)
(I (P3, P4) 이므로 위 식의 마지막 부분이 성립한다.) 윗식에서 모든 항은 베이지안 네트
워크에 의해 주어진다.
p (P6 | P5) 를 계산할 때 다음을 얻는다.
p (P6 | P5) =p (P6 | P1, P2) p (P1 | P5) p (P2)
다음에는 p (P1 | P5) 를 계산해야 한다. 그리고 증거 노드는 질의 노드 위에 있는 것이 아니라 아래에 있음에 주의해야 한다. 이러한 재귀적 절차를 더 이상 사용하지 않고 곧 설명할 "아래에 있는 증거" 절차를 사용해야 한다. 이 예에서는 단순히 베이지안 규칙을 사용하여 p (P1 | P5) = p (P5 | P1) p (P1) / p (P5) 을 구할 것이다. p (P6 | P5) 를 계산하는 데 필요한 모든 값들은 베이지안 네트워크에 의해 주어진다. 이러한 모든 결과를 모아 p (Q | P5, P4) 에 대한 최종 결과를 얻을 수 있다
(2) 아래에 있는 증거
모든 증거 노드들이 Q 아래에 있을 때 p (Q | P12, P13, P14, P11) 을 계산해 보자. 계산 과정은 재귀적 알고리즘의 수행 과정과 같다. 이것은 다음과 같이 진행된다. 먼저 베이지안 규칙을 사용하여 다음과 같이 써 보자.
여기서 는 앞에서 한 것과 같은 방법으로 계산된 표준화 계수이다. d-분리 I ({P12,
P13}, {P14, P11} | Q) 에 의해 다음과 같이 쓸 수 있다.
p (Q | P12, P13, P14, P11) = kp (P12, P13 | Q) p (P14, P11 | Q) p (Q)
집합 {Q | P12, P13, P14, P11} 을 Q 의 각 자식에 해당하는 두 개의 부분 집합으로 분리하였음에 주의하라. p (P12, P13 | Q) 와 p (P14, P11 | Q) 는 질의 노드 위에 하나의 증거노드가 주어진 경우 질의 노드 집합에 대한 확률 계산을 수반한다. 그러므로 우리는 앞에서 본 알고리즘을 사용할 수 있다. 증거 노드가 하나만 있기 때문에 앞에서와 달리 상향식 을 쓰는 대신 하향식 재귀 알고리즘을 쓰는 것이 편리하다.
하향식 알고리즘에 대해서는 p (P12, P13 | Q) 를 계산하는 것을 예로 들어 설명하기로 한다. 질의 노드 집합 {P12, P13} 위에 있는 Q 의 유일한 자식 P9 를 수반하는 것이 가장 중요하다. 조건부 독립의 정의에 의해 p (P12, P13, P9 | Q) = p (P12, P13 | P9, Q) p (P9 | Q) 가 성립함에 주목하라. 그러면
p (P12, P13 | Q) =p (P12, P13 | P9, Q) p (P9 | Q)
이며 d-분리 I ({P12, P13}, Q | P9) 에 의해
p (P12, P13 | Q) =![]() p
(P12, P13 | P9) p (P9 | Q)
p
(P12, P13 | P9) p (P9 | Q)
이다. 이 식에서 p (P9 | Q) 는 다음과 같이 P9 의 모든 부모를 수반함으로써 계산할 수 있다.
p (P9 | Q) =p (P9 | P8, Q) p (P8)
p (P9 | P8, Q) 는 네트워크에 의해 주어진다. 다른 항 p (P12, P13 | P9) 는 질의 노드 위에 하나의 증거가 주어졌을 때 질의 노드들의 집합에 대한 확률을 계산하는 것과 같은 하향식 절차를 재귀적으로 부른다. 이 경우 P9 의 자식들은 증거 노드이기 때문에 재귀적 호출은 한 단계 후에 종료된다. P9 가 주어졌을 때 P12 와 P13 은 독립이므로 p (P12, P13 | P9) = p (P12 | P9) p (P13 | P9) 가 성립한다. 이 두 확률은 네트워크에 의해 주어진다.
하향식 절차를 p (P14, P11 | Q) 에 적용하면 다음과 같은 것을 얻을 수 있다.
p (P14, P11 | Q) =p (P14, P11 | P10) p (P10 I Q)
I (P14, P11 | P10) 이므로 이것은 다시
p (P14, P11 | Q) = ![]() p
(P14 | P10), p (P11 | P10) p (P10 | Q)
p
(P14 | P10), p (P11 | P10) p (P10 | Q)
이다. 이 식에서 가운데 항은 네트워크에 의해 주어지지 않는다. 따라서 이것을 구하기 위해 하향식 절차를 다시 적용한다.
p (P11 | P10) =p (P11 | P15, P10) p (P15 I P10)
이다. 여기서
p (P15 | P10) =p (P15 | P10, P11) p (P11)
이다. 그러나 p (P11 | P15, P10) 에서 질의 노드 P11 은 증거 노드 위에 있으므로 베이지안 규칙을 사용하여 이 절차의 첫 부분을 다시 적용하면,
이다. 여기서 이고 p (P11) 은 네트워크에 의해 직접 주어진다. P10 과 P11 은 독립이므로
이 알고리즘은 다음과 같이 종료된다.
p (P15, P10 | P11) = p (P15 | P10, P11) p (P10 | P11) = p (P15 | P10, P11) p (P10)
이제 모든 결과를 모을 수 있고 합계 k, k1 을 모두 계산할 수 있으므로 p (Q | P12, P13, P14, P11) 에 대한 최종 결과를 얻을 수 있다.
위에 있는 증거와 아래에 있는 증거 알고리즘의 복잡도는 (다중트리의 경우) 네트워크에 있는 노드의 개수에 선형적으로 비례한다.
다음과 같이 Q 의 위와 아래에 증거가 있다면
p (Q | {P5, P4}, {P12, P13, P14, P11})
이 증거를 위에 있는 ε+ 와 아래에 있는 ε- 로 나누고 베이지안 규칙을 사용하면 다음과 같이 쓸 수 있다.
이전과 같이 표준화 계수 를 사용하여 다음과 같이 다시 쓸 수 있다.
p (Q | ε+, ε-) = k2p (ε- | Q, ε+) p (Q | ε+)
Q 는 ε+ 와 ε- 를 d-분리하므로
p (Q | ε+, ε-) = k2p (ε- | Q) p (Q | ε+)
이다. 윗식에서 p (ε- | Q) 는 하향식 절차에 따라 p (Q | ε-) 를 구하는 과정에서 이미 계산하였다. p (Q | ε+) 는 상향식 절차를 이용하여 직접 계산할 수 있다.
그림 5 와 같은 좀 작고 추상적인 다중트리를 이용하여 위에서 설명한 방법으로 p (Q | U) 를 계산해 보자.

그림 5. 작은 다중트리
진단 추론에서와 같이 먼저 베이지안 규칙을 적용하여 다음과 같은 관계를 얻는다.
p (Q | U) = kp (U | Q) p (Q)
여기서 이다. 하향식 알고리즘에 의해
p (U | Q) = ![]() p
(U | P) p (P | Q)
p
(U | P) p (P | Q)
p (P | Q) = ![]() p
(P | R, Q) p (R)
p
(P | R, Q) p (R)
= p (P | R, Q) p (R) + p (P | ¬ R, Q) p (¬ R)
= 0.95 × 0.01 + 0.8 × 0.99 = 0.80,
따라서
p (U | Q) = ![]() p
(U | P) p (P | Q)
p
(U | P) p (P | Q)
p (P | Q) = ![]() p
(P | R, Q) p (R)
p
(P | R, Q) p (R)
= p (P | R, Q) p (R) + p (P | ¬ R, Q) p (¬ R)
= 0.95 × 0.01 + 0.8 × 0.99 = 0.80,
따라서
p (¬ P | Q) = 0.20
p (U | Q) = p (U | P) × 0.8 + p (U | ¬ P) × 0.2
= 0.7 × 0.8 + 0.2 × 0.2 = 0.60,
따라서
p (Q | U) = k × 0.6 × 0.05 = k × 0.03
p (¬ Q | U) = kp (U | ¬ P) p (¬ Q)
p (U | ¬ Q) = ![]() p
(U | P) p (P | ¬ Q)
p
(U | P) p (P | ¬ Q)
p
(P | ¬ Q) = ![]() p
(P | R, ¬ Q) p (R)
p
(P | R, ¬ Q) p (R)
= p (P | R, ¬ Q) p (R) + p (P | ¬ R, ¬ Q) p (¬ R)
= 0.90 × 0.01 + 0.01 × 0.99 = 0.019,
따라서
p (¬ P | ¬ Q) = 0.98
p (U | ¬ Q) = p (U | P) × 0.019 + p (U | ¬ P) × 0.98
= 0.7 × 0.019 + 0.2 × 0.98 = 0.21,
따라서
p (¬ Q | U) = k × 0.21 × 0.95 = k × 0.20
이다. 따라서 k = 4.33 이며 p (Q | U) = 4.33 × 0.03 = 0.13 이다
위의 예와 같이 계산함으로써 부속 계산을 반복하는 것을 피할 수 있다. 이러한 방법을 버킷 삭제 (bucket elimination) 라고 한다 [Dechter 1996].
주어진 네트워크가 다중트리가 아닌 경우 노드 사이의 다중 경로로 인해 위에서 설명한 재귀적 방법은 종료되지 않을 것이다. 이와 같이 복잡한 네트워크를 다룰 수있는 다른 방법이 제시되었다. Monte Carlo 방법 (논리 샘플링 (logic sampling) 이라고 불림 [Henrion 1988]) 이 그 중의 하나이다. 이 방법에서 부모를 가지고 있지 않은 노드에 대한 한계 확률은 그러한 노드에 진리값을 할당하는 데 사용된다. 이 값은 후손에 임의의 진리값을 할당하는 데 사용된다. 결국 네트워크의 모든 노드는 값을 가지게 된다. 이 과정은 여러 번 반복되며 이 과정에서 각 노드에 할당된 모든 값들이 기록된다. 무한번 반복을 하면 이 값들은 네트워크와 이의 CPT 에 의해 주어진 결합 확률과 일관성을 유지할 것이다. 여러 번 반복을 하고 나면 Q 와 E 에 참이 할당된 횟수로 나누고, E 가 참인 횟수로 나눔으로써 p (Q | E) 를 추정할 수 있다. 같은 방법으로 증거 노드 집합이 주어졌을 때 질의 노드의 집합에 대한 결합 확률을 계산할 수 있다.
군집화 (clustering) [Lauritzen & Spiegelhater 1988] 라고 하는 방법은 수퍼 노드 (supernode) 로 구성된 그래프가 다중트리가 될 수 있도록 네트워크의 노드들을 수퍼 노드로 그룹화하는 것이다. 수퍼 노드의 가능한 값은 이를 구성하고 있는 노드간들의 모든 조합이다. 이와 같이 하면 각 수퍼 노드마다 많은 CPT 가 있으나 다중트리 알고리즘을 사용할 수 있다.
이 책의 내용을 보완하는 확률론에 관한 책들이 여러 가지가 나와 있다. [Feller 1968. (Feller,W. An Introduction to Probability Theory and Applications , vol.1, New York: John Wiley & Sons, 1968.)] 도 그 중의 하나이다.
어떤 학자들은 비단조 추론 (nonmonotonic reasoning) 은 확률적인 방법으로 다룰 수 있다고 생각한다. 이에 대해서는 [Goldszmidt, Morris & Pearl 1990 (Goldszmidt, M., Morris, P., and Pearl, J., "A Maximum Entropy Approach to Nonmonotonic Reasoning," in Proceedings of the Eighth National Conference on Artificial Intelligence (AAAI-90), pp.646-652, Menlo Park, CA: AAAI Press, 1990.)] 을 보라.
인공지능에서 베이지안 네트워크를 사용한 확률 추론은 트리 및 다중트리 네트워크를 위한 메시지 전달 알고리즘 (message-passing algorithm) 을 개발한 [Pearl 1982a (Pearl, J., "Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach," in Proceedings of the Second National Conference on Artificial Intelligence (AAAI-82), pp.133-136, Menlo Park, CA: AAAI Press, 1982.), Kim & Pearl 1983 (Kim, J., and Pearl, J., "A Computational Model for Combined Causal and Diagnostic Reasoning in Inference Systems," in Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83), pp.190-193, San Francisco: Morgan Kaufmann, 1983.)] 이 처음이다. 다중트리 방법은 [Russell & Norvig 1995 (Russell, S., and Norvig, P., Artificial Intelligence: A Modern Approach, Englewood Cliffs, NJ: Prentice Hall, 1995. (Revised edition to appear in 1998.), pp.447ff] 에 기초를 두고 있다. 베이지안 네트워크는 이산값을 가진 변수로 제한되어 있다. 연속 확률변수에 대한 연구도 있었다. 이에 대해서는 [Shachter & Kenley 1989 (Shachter, R., and Kenley, C., "Gaussian Influence Diagrams," Management Science, 35:527-550, 1989.)] 를 참조하라. [Wellman 1990 (Wellman, M., "Fundamental Concepts of Qualitative Probabilistic Networks," Artificial Intelligence, 44:257-303, 1990.)] 은 정성적 네트워크에 대해서 연구했다.
이 책에서 [Pearl 1984 (Pearl, J., Heuristics: Intelligent Search Strategies for Computer Problem Solving, Reading, MA: Addison-Wesley, 1984.)] 에 의한 확률 추론에 대한 책을 인용한 적이 있다. [Neapolitan 1990 (Neapolitan, R., Probabilistic Reasoning in Expert Systems: Theory and Algorithms, New York: John Wiley & Sons, 1990.)] 은 전문가 시스템에 확률적인 방법을 사용한 것을 다룬 책이다. [Henrion 1990 (Henrion, M., "An Introduction to Algorithms for Inference in Belief Nets," in Henrion, M., Shachter, R., Kanal, L., and Lemmer, J. (eds.), Uncertainty in Artificial Intelligence, 5, Amsterdam: North Holland, 1990.)] 은 베이지안 네트워크에서의 확률 추론에 대한 소개서이다. [Jensen 1996 (Jesen, F., An Introduction to Bayesian Networks, New York: Springer-Verlag, 1996.)] 은 HUGIN 시스템을 중심으로 베이지안 네트워크에 대해서 다룬 책이다. [Neal 1991 (Neal, R., "Connectionist Learning of Belief Networks," Artificial Intelligence, 56:71-113, 1991.)] 은 베이지안 네트워크와 신경망 사이의 관계를 연구하였다. David Hecker-man, Michael Wellman, Abe Mamdani 는 "인공지능에서의 불확실성" 이란 Communications of the ACM 특집호 (38권 3호, 1995년 3월) 의 편집을 맡았다.
베이지안 네트워크는 많은 전문가 시스템에서 응용되었다. 전형적인 예로 병리학자들이 임파절 질병을 진단하는 데 도움을 줬던 PATHFINDER 이다 [Heckerman 1991 (Heckerman, D., Probabilistic Similarity Networks, Cambridge, MA: MIT Press, 1991), Heckerman & Nathwani 1992 (Heckerman, D., and Nathwani, B., "An Evaluation of the Diagnostic Accuracy of Pathfinder," SIAM Journal on Computing, 25:56-74, 1992.)]. 다른 예로 내과 질병 진단을 위한 CPCSBN 이라는 것이 있다 [Pradhan, et al. 1994 (Pradhan, M., Provan, G., Middleton, B., and Henrion, M., "Knowledge Engineering for Large Belief Networks," in Proceedings of the Tenth Conference on Uncertainty in Artificial Intelligence, pp.484-490, San Francisco: Morgan Kaufmann, 1994.)]. 이 시스템은 448 개의 노드와 908 개의 아크를 가지고 있는데 세계적인 내과 질병 진단 전문의와 필적할 만큼 훌륭하다.
베이지안 네트워크 외에도 불확실한 정보를 가지고 추론하는 데 사용될 수 있는 것들이 있다. 의료 진단과 치료에 대한 조언을 하는 MYCIN 이란 전문가 시스템은 확신도 (certainty factor) 라는 개념을 사용하였다 [Shortliffe 1976 (Shortliffe, E. H., Computer-Based Medical Consultations: MYCIN, New York: Elsevier, 1976.), Buchanan & Shortliffe 1984 (Buchanan, B., and Shortliffe, E. (eds.), Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project, Reading, MA: Addison-Wesley, 1984.)]. [Duda, Hart & Nilsson 1987 ] 은 자신들이 개발한 광물 탐사용 전문가 시스템인 PROSPECTOR 에 충분지수 (sufficiency index) 와 필요지수 (necessity index) 라는 개념을 사용하였다.
다른 방법들은 퍼지논리 (fuzzy logic) 와 가능성 이론 (possibility theory) [Zadeh 1975 (Zadeh, L., "Fuzzy Logic and Approximate Reasoning," Synthese 30, pp.407-428, 1975.), Zadeh 1978 (Zadeh, L., "Fuzzy Sets as a Basis for a Theory of Possibility," Fuzzy Sets and Systems, 1:3-28, 1978.), Elkan 1993 (Elkan, C., "The Paradoxical Success of Fuzzy Logic," in Proceedings of the Eleventh National Conference on Artificial Intelligence (AAAI-93), pp.698-703, Menlo Park, CA: AAAI Press, 1993.)] 과 뎀프스터-샤퍼 (Dempster-Shafer) 의 조합 규칙 [Dempster 1968 (Dempster, A. P., "A Generalization of Bayesian Inference," Journal of the Royal Statistical Society, Series B, 30:205-247, 1968.), Shafer 1979 (Shafer, G., A Mathematical Theory of Evidence, Princeton, NJ: Princeton university Press, 1979.)] 를 사용하였다. [Nilsson 1986 (Nilsson, N., "Probabilistic Logic," {Artificial Intelligence}, 28(1):71-87, 1986.)] 은 확률논리 (proba-bilistic logic) 에 대하여 개발하였으며 확률론과 다치논리 (multivalued logic) 에서 관련 연구에 대한 인용을 제시하였다. 베이지안 네트워크에서의 확률 추론은 대부분의 전문가 시스템에서 사용되는 다른 방법보다 우수하다고 생각한다. 그러나 이 부분에 대해서는 논란의 여지가 많다.
불확실성에 직면했을 때 인간은 일관성은 쉽게 잃는다 [Tversky & Kahneman 1982 (Tversky, A., and Kahneman, D., "Causal Schemata in Judgements under Uncertainty," in Kahneman, D., Slovic, P., and Tversky, A. (eds.), Judgements under Uncertainty: Heuristics and Biases, Cambridge: Cambridge University Press, 1982.)]. 따라서 이러한 경우에 인간은 공학적으로 유용한 모형을 제시하지 못한다.
[Shafer & Pearl 1990 (Shafer, G., and Pearl, J. (eds.), Readings in Uncertain Reasoning, San Francisco: Morgan Kaufmann, 1990.)] 은 불확실 추론에 대한 논문을 모아 두었다. Uncertainty in Artificial Intelligence (UAI) 란 국제 학술회의 논문집은 현재 진행중인 연구에 대한 소개가 포함되어 있다. 중요 논문들은 인공지능 관련 논문지와 학술회의 논문집은 물론 International Journal of Approximate Reasoning 이란 논문지를 통해 출판된다.
 (¬L | ¬M) =
(¬L | ¬M) = 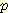 (¬M | ¬L )
(¬M | ¬L ) 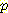 (¬L)
(¬L)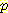 (¬M)
(¬M)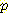 (¬L | ¬B, ¬M) =
(¬L | ¬B, ¬M) =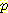 (¬M, ¬B | ¬L )
(¬M, ¬B | ¬L ) 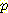 (¬L)
(¬L)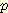 (¬B, ¬M)
(¬B, ¬M)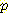 (¬M | ¬B, ¬L )
(¬M | ¬B, ¬L ) 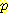 (¬B|¬L)
(¬B|¬L)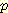 (¬L)
(¬L)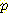 (¬B, ¬M)
(¬B, ¬M)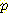 (¬M | ¬B, ¬L )
(¬M | ¬B, ¬L ) 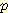 (¬B)
(¬B)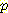 (¬L)
(¬L)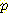 (¬B, ¬M)
(¬B, ¬M)