
문제와 문제 공간
인공지능 : Elaine Rich 저서, 유석인.전주식.한상영 편역, 상조사, 1986 (원서 : Artificial Intelligence, McGraw-Hill, 1983, Artificial Intelligence (2nd ed, 1991)), Page 39~68
(1) 생성 시스템 (Production System)
(3) 경험적 탐색 방법 (Heuristic Search)
(2) 풀이 단계를 무시하거나 행해지지 않은 것으로 간주할 수 있는가?
앞장에서는 인공 지능 분야에서 주로 다루어지는 문제들에 대해 간단히 설명하였고, 이러한 문제들이 어떤 기법에 의해 해결되는지 살펴보았다. 본 장과 다음 장에서는 주어진 문제를 푸는 시스템을 만들 때 필요한 다음 세 가지 중요한 단계에 대해 다루기로 하자 :
1. 문제 정의의 정확성 : 문제의 정의에는 초기 상황 (initial situation) 과 최종 상황 (final situation) 이 정확히 규정되어야 한다. 문제에 대해 받아 들여질 수 있는 해답으로 최종 상황은 구성된다.
2. 문제 해석 : 문제를 풀기 위해 사용될 기법들의 적합성은 중요한 몇 가지 특성에 의해 영향을 받는다.
3. 최적 기법 적용 : 최적 기법을 선택하여 주어진 문제에 적용한다.
체스 (chess) 라 불리는 두 사람이 두는 서양 장기를 살펴보자. 체스를 둘 때, 한 쪽이 의도하는 방향으로 상대방이 체스를 둘 것이라고 말할 수 있으며, 또 상대방이 그렇게 할 것을 기대한다. 그러나, 이것은 풀고자 하는 문제에 대한 완전한 기술은 아니다. 체스 프로그램을 작성하기 위해서, 먼저 체스를 처음 시작할 때의 각 장기말의 위치를 정하고 이 장기말들이 움직일 수 있는 규칙을 정해야 하며, 이 장기말들이 어떤 위치에 있을 때 이길 수 있는 지를 규정해야 한다.
체스의 경우, 문제를 형식에 따라 완전하게 기술하는 것은 쉽다. 체스를 처음 시작할 때의 각 장기말의 위치를 8 × 8 배열에 표시한다. 배열의 각 원소에는 해당하는 장기말을 나타내는 기호가 들어있다. 우리의 목표는 상대방을 더 이상 움직일 수 없게 하거나, 상대방의 왕을 공격할 수 있는 위치에 있는 것이다. 초기 상태에서 목표 상태로 움직일 때 규칙에 따라 장기말을 이동시킨다.
각 장기말의 움직임을 나타내는 규칙은 두 부분으로 구성된 규칙의 집합으로 표기된다 : 좌측의 장기판은 현재 상태와 일치될 패턴을 나타내고, 우측은 그 상태에서 취해질 움직임을 나타낸다. 이러한 규칙들은 여러 가지 방법에 의해 표기된다. 규칙을 표기하는 한 가지 방법이 그림 1 에 소개되었다.
그림 1 체스 말의 올바른 이동
장기를 둘 때 발생할 수 있는 장기판의 상태는 약 10120 개 정도이다. 그림 1 과 같은 방법으로 규칙을 표기할 경우, 각 장기판의 상태에 대해 적용될 규칙이 각각 존재하기 때문에, 이와 같은 그림을 엄청나게 많이 그려야 한다. 이처럼 많은 규칙을 사용할 때, 다음 두 가지 문제가 발생한다.
첫째, 어떤 사람도 완전한 규칙들의 집합을 만들지 못한다. 이런 규칙들의 집합을 완성하기 위해서는 엄청난 시간이 필요하며, 또한 완성되었다 하더라도, 착오가 존재하지 않는다고는 확신할 수 없다.
둘째, 이 모든 규칙을 쉽게 처리할 수 있는 프로그램은 존재하지 않는다. 각 움직임에 대한 적절한 규칙을 찾기 위해서 해슁 방법 (hashing scheme) 을 이용하여 상당히 빨리 처리할 수 있다 할지라도, 이 많은 규칙을 저장하는데 어려움이 뒤따른다.
위 문제를 최소화하기 위해 가능한 한 일반적으로 규칙을 사용하는 방법을 찾아야 한다. 이를 위해, 현재 상태와 뒤따르는 상태를 기술하는 편리한 표기법을 살펴 보자. 예를 들어 그림 1 에 표기된 규칙을 그림 2 처럼 나타낼 수 있다. 일반적으로, 필요한 규칙의 기술이 간결할수록, 이 규칙을 만들 때 반드시 수반되는 일들이 더욱 적어지고, 이 규칙을 사용하는 프로그램 또한 더욱 효율적으로 된다.
|
백의 말이 (i 열, 2 행) 에 있음 AND (i 열, 3 행) 이 비어 있음 AND (i 열, 4 행) 이 비어 있음 |
→ |
말을 (i 열, 2 행) 에서 (i 열, 4 행) 으로 이동함 |
그림 2 체스 말의 이동을 표시하는 또 다른 방법
상태 공간 (state space) 에서 움직이는 문제로 체스 문제를 정의하였다. 상태 공간내의 각 상태는 일어날 수 있는 장기판의 위치와 대응한다. 초기 상태에서 시작하여, 승리라는 최종 상태로 가기 위해 노력하면서, 규칙에 따라 한 상태에서 다른 상태로 이동하며 경기한다. 장기판의 위치에 대응하는 상태들의 집합이 인위적이며, 잘 구성되어 있기 때문에, 이 상태 공간 표기법 (state space representation) 은 체스 게임을 표기하기에 적합하다. 또한 이러한 종류의 표기법은 상당히 덜 구조화된 문제를 표기하는 데도 적합한데, 일반적으로 이런 문제의 상태를 묘사하기 위해서는 배열보다 복잡한 구조가 필요하다. 논의될 모든 인공 지능 분야의 기법들은 상태 공간 표기법을 기초로 하고 있다. 다음 두 가지 방법으로 상태 공간 표기법의 구조가 문제 풀이의 구조에 대응된다 :
상태 공간 표기법은 일반성을 보이기 위해, 체스와는 매우 다른 종류의 문제를 기술하는 데 이 방법을 사용해 보자.
▷▶▷ 물 주전자 문제 (A Water Jug Problem) :
4 갈론 들이 주전자와 3 갈론 들이 주전자가 각각 하나씩 있다. 이 주전자들에는 단위를 나타내는 어떤 표시도 되어 있지 않다. 물 주전자를 채우기 위해 펌프를 사용한다. 이와 같은 조건하에서 어떻게 4 갈론 들이 주전자에 정확히 2 갈론의 물을 담겠는가?
(X, Y) 는 순서쌍의 집합으로 이 문제의 상태 공간을 나타낸다. 정수 X 는 0, 1, 2, 3 그리고 4 의 값을 가지며, 4 갈론 들이 주전자에 들어 있는 물의 양을 나타낸다. 정수 Y 는 0, 1, 2, 그리고 3 의 값을 가지며, 3 갈론 들이 주전자에 담겨 있는 물의 갈론 수를 표시한다. 처음 상태는 (0, 0) 이며, 목표 상태는 (2, n) 이다. 여기서 n 은 0, 1, 2, 3 의 하나인데, 3 갈론 들이 주전자에 담겨져야 할 물의 양이 명시되지 않았기 때문이다.
|
1. (X, Y | X < 4) → (4, Y) |
4 갈론 들이 주전자를 채운다. |
|
2. (X, Y | Y < 3) → (X, 3) |
3 갈론 들이 주전자를 채운다. |
|
3. (X, Y | X > 0) → (X-D, Y) |
4 갈론 들이 주전자 물의 일부를 퍼낸다. |
|
4. (X, Y | Y > 0) → (X, Y-D) |
3 갈론 들이 주전자 물의 일부를 퍼낸다. |
|
5. (X, Y | X > 0) → (0, Y) |
4 갈론 들이 주전자를 비운다. |
|
6. (X, Y | Y > 0) → (X, 0) |
3 갈론 들이 주전자를 비운다. |
|
7. (X, Y | X + Y > = 4 ∧ X > 0) → (4, Y - (4 - X)) |
4 갈론 들이 주전자가 다 찰 때까지 3 갈론 들이 주전자의 물을 4 갈론 들이 주전자에 붓는다. |
|
8. (X, Y | X + Y > = 3 ∧ X > 0) → (X - (3 - Y), 3) |
3 갈론 들이 주전자가 다 찰 때까지 4 갈론 들이 주전자의 물을 3 갈론 들이 주전자에 붓는다. |
|
9. (X, Y | X + Y > = 4 ∧ Y > 0) → (X + Y, 0) |
3 갈론 들이 주전자의 물을 모두 4 갈론 들이 주전자에 붓는다. |
|
10. (X, Y | X + Y > = 3 ∧ X > 0) → (0, X + Y) |
4 갈론 들이 주전자의 물을 모두 3 갈론 들이 주전자에 붓는다. |
그림 3 물 주전자 문제에 대한 생성 규칙
문제를 풀기 위해 사용되는 작용자 (operator) 는 그림 3 처럼 나타낼 수 있으며, 이 작용자의 좌측은 현재 상태와 비교될 패턴을 나타내고, 우측은 규칙의 적용으로 얻어지는 새로운 상태를 나타낸다. 작용자의 완벽한 기술을 위해, 문제를 설명한 문장 중에 나타나지 않은 가정을 명백히 해야 할 필요성이 있음을 주지하라. 여기서는 다음 사항을 가정하였다 :
이와 같은 부가적인 가정은 일상 언어로 기술된 문제를 프로그램에 의해 사용되기 적합한 형식으로 변환시킬 때 거의 항상 필요하다.
물 주전자 문제를 풀기 위해서는 위에 주어진 문제의 표기뿐만 아니라 제어 구조 (control structure) 가 필요하다. 현재 상태와 일치되는 좌측을 가진 규칙을 선택, 적용하여 상태를 적절히 변환시킨 후, 만들어진 새로운 상태가 원하는 목표 상태인지 조사하는 사이클을 반복 실행하는 일은 제어 구조에 의해 행해진다. 원하는 상태가 아닐 경우 사이클을 계속 반복 수행한다. 다음에 수행될 작용을 선택하는 기법에 의해 문제를 푸는 속도가 결정된다. 선택을 결정하기 위해 사용되는 기법들이 3 장에서 다루어진다. 이것은 적합한 작용자들로부터 얻은 선택은 어떤 것이든지 게임의 규칙에 어긋나지 않는 상태를 유도하지만, 이들 중 소수만이 승리로 이끄는 선택이 되는 체스의 동일한 상황과 대응한다.
다른 많은 문제들처럼, 물 주전자 문제의 경우에서도, 문제를 해결하는 일련의 작용자가 여러개 존재한다. 그중 하나가 그림 4 에 나타나 있다.
|
4-갈론 들이 주전자에 들어 있는 갈론 수 |
3-갈론 들이 주전자에 들어 있는 갈론 수 |
적용된 규칙
|
|
0 0 3 3 4 0 2 |
0 3 0 3 2 2 0 |
2 9 2 7 5 9 |
그림 4 물 주전자 문제의 한 풀이
흔히 가장 짧은 일련의 연산자를 찾는 것이 문제 속에 명확하게 기술되어 있거나 내포되어 있다. 만약 이런 것이 존재한다면, 이 요구는 문제 풀이를 위한 탐색 방향을 정하는 적절한 기법의 선택에 커다란 영향을 미친다. 2 절에서 이에 대해 다루었다.
일상 언어로 기술된 문제를 형식에 맞는 문제로 바꾸어 표기하여 적용할 적당한 규칙의 집합을 찾아 문제를 풀 때 발생하는 심각한 문제점중의 하나가 그림 3 의 규칙 3 과 규칙 4 에 나타나 있다. 이용 가능한 작용자의 리스트에 규칙 3 과 규칙 4 를 포함시켜야 하는가? 아니면, 생략해야 하는가? 기술된 문제에서, 측정되지 않은 양의 물을 쏟아 버린다는 것을 확실히 허용하였다. 그러나 이렇게 하면 문제의 풀이에 더 가까이 접근할 수 없다는 것이 피상적이고 임시적인 문제의 분석에 의해 명백해졌다. 실제 상황하에서 이러한 규칙은 생략될 것이다. 문제를 푸는 동기가 제공된 추론 (적응할 규칙을 선택하는 일) 의 유용도를 증명하는 상황이라면, 이런 규칙을 포함하여, 프로그램 자체에서 어떤 지능도 보여지지 않는다는 비평이 가해지지 않도록 한다. 또한 일반성을 유지하기 위해 이러한 비효율적인 규칙을 포함시키기도 한다. 한편으로 많은 규칙을 사용하면, 비록 수행은 느리지만, 어떠한 문제라도 풀 수 있다. 그러나 다른 한편으로 특정한 문제를 택하여 이것의 풀이를 완전히 결정할 수 있을 정도까지 문제를 분석하고, 직접 완벽한 풀이를 규정하는 규칙의 집합을 기술할 수 있다. 제 1 장에서 소개된 삼목놀이 (tic-tac-toe) 게임의 프로그램을 다시 살펴 보자. 첫 번째와 두 번째 프로그램은 이러한 규칙 기록 방법 중 후자의 예이다. 어떠한 탐색도 필요하지 않으며, 정확하고 정당한 이동이 미리 계산된다. 세번째 프로그램은 첫 번째 규칙 기록 방법에 가깝다. 이 경우 융통성과 일반성은 감소했지만 효율성은 향상되었다.
체스와 물 주전자 문제라는 전혀 다른 성질의 두 문제에 대해서 지금까지 논의하였다. 이 논의로부터, 문제를 푸는 프로그램을 작성하는 첫번째 단계는, 형식에 맞고, 또한 처리될 수 있도록 문제를 기술하는 것이라는 점이 명백해졌다. 물 주전자 문제와 체스의 경우, 문제 자체가 매우 구조화되어 있기 때문에 이 과정은 그다지 어려운 작업이 아니다. 그러나 인공 지능 분야에서 다루어 지는 다른 문제들의 경우, 이 단계는 상당히 어려운 작업이다. 예를 들어, 이상 언어로 기술된 문장을 이해하기 위해 그 문장이 의미하는 것을 정확히 설명 표기하는 작업을 생각해 보자. 문제를 푸는 프로그램을 작성하기에 앞서 문제를 표기하는 작업이 반드시 행해져야 한다. 비록 어렵고 구조화되지 않은 문제를 푸는 것이 궁극적인 목표라 하더라도, 기초가 되는 방법을 정확히 이해하여야만, 이 어려운 문제들을 풀 수 있다. 이를 위해서는 물 주전자와 같이 쉽고 간단한 문제를 살펴보는 것이 효과적이다.
지금까지 상태 공간 표기법과 관련하여 문제들을 논의해 왔지만, 이러한 표기법을 작성하는 방법에 대해서는 언급하지 않았다. 일상 언어로 기술된 문제를 상태 공간 표기법으로 변환시키는 프로그램은 어떻게 작성할까? 이것은 만족할 만한 해답이 알려지지 않은 문제이다.
지금까지 언급한 것을 요약해 보면, 형식에 맞게 문제를 기술하기 위해서 다음 사항이 필요함을 알 수 있다.
1. 관련된 물체들 간의 가능한 모든 배치 구조를 포함하는 상태 공간을 정의한다. 물론, 상태 공간 내의 모든 상태를 일일이 열거하지 않고도 상태 공간을 정의할 수 있다.
2. 문제 풀이 과정이 시작되는 하나 혹은 그 이상의 상태를 상태 공간 내에 규정해야 한다. 이 상태를 초기 상태 (initial state) 라 한다.
3. 문제의 해답으로 적합한 하나 혹은 그 이상의 상태를 상태 공간내에 규정해야 한다. 이 상태를 목표 상태 (goal state) 라 한다.
4. 이용될 수 있는 움직임을 표기한 규칙들의 집합을 규정해야 한다. 이를 위해 다음 문제점을 고려해야 한다 :
초기 상태에서 목표 상태로 가는 경로를 발견할 때까지, 문제의 상태 공간을 움직여가는 규칙과 적절한 제어 방법을 함께 사용하여 문제에 대한 답을 찾는다. 문제 풀이 과정에서 탐색의 과정은 중요한 기초를 이룬다. 그러나 이것이 그 외의 직접적인 다른 방법을 이용할 수 없다는 것을 의미하지는 않는다. 가능하다면 그 방법을 규칙의 일부로 포함시켜 탐색의 한 단계로 사용한다. 예를 들어, 물 주전자 문제에서 표준 산술 연산이 규칙의 한 단계로 사용되었다. Y-(4-X) 라는 성질을 가진 숫자를 찾기 위해 탐색할 필요가 없다. 물론 복잡한 문제의 경우, 더욱 복잡한 계산이 수행되어야만 한다. 탐색은 더 이상 직접적인 방법이 알려지지 않았을 때 사용되는 일반적인 기법이다. 또한 탐색은 문제의 일부분에 대한 풀이를 찾는데 적합한 직접적인 방법이 넣어질 수 있는 틀을 제공하기도 한다.
탐색은 지능적인 처리 과정이 핵심을 이룬다. 따라서 탐색 과정을 쉽게 기술할 수 있도록 인공 지능 분야의 프로그램을 작성하는 것이 효과적이다. 이러한 구조를 제공하는 것이 생성 시스템이며, 이에 대한 정의가 다음에 주어져 있는데, 공장에서 사용되는 '생성' 이라는 단어와 혼동하지 않기 바란다.
생성 시스템은 다음과 같이 구성되어 있다.
위와 같은 생성 시스템의 정의는 매우 일반성을 띤다. 이것은 체스 프로그램과 물 주전자 문제를 푸는 프로그램의 기술 등 여러 많은 시스템을 포함한다. 특수 시스템의 인터프린터를 만들고 있는 사람들은 생성 시스템을 좀 더 특별하게 제약으로 부터 기인되었다. 즉 주어진 특정 문제에 적합하도록, 생성 시스템을 그 문제에 맞게 정의하여 사용한다. 일반성을 띤 생성 시스템의 정의는 앞으로 논의될 탐색과 같은 문제 풀이 기법의 훌륭한 모델을 제공한다. 계산 가능한 과정은 어느 것이든지 생성 시스템에 의해 표기될 수 있다는 것은 매우 흥미로운 일이다.
생성 시스템은 탐색을 표기하는 방법으로서의 유용성뿐만 아니라, 인공 지능 분야의 형식론으로서도 다음과 같은 장점을 가지고 있다 :
주어진 문제를 풀기 위해서는 이 문제를 정확히 기술해야 한다. 문제의 상태 공간과 그 공간 내에서의 움직임을 나타내는 작용자들의 집합을 정의함으로써 문제를 정확히 기술할 수 있다. 문제를 풀기 위해, 초기 상태로 부터 목표 상태로 가는 경로를 상태 공간 내에서 찾아야 한다. 문제를 푸는 과정은 생성 시스템으로 나타내 진다. 탐색을 가능한 한 효과적으로 수행하기 위해서, 생성 시스템을 위한 적당한 제어 구조를 선택하는 문제가 이 절의 나머지 부분에서 다루어 진다.
문제의 풀이 과정을 탐색하는 동안 적용될 다음 규칙을 결정하는 방법에 대해서는 지금까지 전혀 언급되지 않았다. 이 문제는 현재 상태와 일치되는 좌측을 가지고 있는 규칙이 둘 이상 존재할 때 발생한다. 이 결정은 문제의 풀이를 얻는 방법이나 문제를 풀 수 있는 지의 여부를 결정하는 데 매우 커다란 영향을 미친다.
좋은 제어 방법이 되기 위한 첫번째 조건은, 제어 방법이 움직임을 일으켜야 한다는 것이다. 물 주전자 문제를 다시 한 번 살펴보자. 시작할 때는 항상 규칙의 리스트 중 첫번째 규칙으로부터 시작하고 적용할 수 있는 규칙이 여러 개 존재할 경우, 이 중 첫번째로 나오는 규칙을 택하는 간단한 제어 방법을 사용한다고 하자. 만약 이 방법을 사용한다면, 4 갈론 들이 물 주전자를 채우는 행위만 끊임없이 계속되어 이 문제를 결코 풀 수 없다. 움직임을 일으키지 않는 제어 방법이 사용될 경우 문제는 결코 풀리지 않는다.
좋은 제어 방법이 되기 위한 두번째 조건은 제어 방법이 체계적이어야 한다는 것이다. 물 주전자 문제를 위한 또 다른 간단한 제어 방법을 생각해 보자. 각 사이클에서 적당한 규칙 중 하나를 임의로 택한다고 가정하자. 이 방법은 움직임을 일으키고, 언젠가는 문제를 풀 수 있기 때문에 첫번째 방법보다는 효과적이다. 그러나 수행동안 같은 상태가 여러 번 반복되고, 필요 이상의 단계가 사용될 수 있다. 즉 제어 방법이 체계적이지 않기 때문에, 문제에 대한 풀이를 얻기 위해 비효율적이고 쓸모없는 특정한 일련의 작용자를 여러 차례 반복 실행하게 된다. 물 주전자 문제를 위한 체계적인 제어 방법중의 하나를 다음에 소개한다. 초기 상태를 루트로 하는 트리를 만든다. 초기 상태에 규칙을 작용하여 얻어질 수 있는 모든 새로운 상태를 루트의 자손 루트로 노드로 나타낸다. 이로부터 만들어진 트리가 그림 5 에 나타나 있다. 다시 각 자손 노드에 적절한 모든 규칙을 적용하여, 이때 얻어질 수 있는 모든 상태를 이 노드의 후계 노드로 한다. 이로부터 만들어진 트리가 그림 6 에 보여진다. 규칙에 따라 목표 상태에 도달할 때까지 이 과정을 계속 수행하면 되는데, 이 방법을 나비 우선 탐색 (breadth-first search) 이라 한다. 이외에도 이용될 수 있는 체계적인 제어 방법이 여러 개 있는데, 여기서는 깊이 우선 탐색을 소개한다. 문제에 대한 풀이를 얻을 때까지 혹은 미리 규정된 깊이까지 트리의 한 가지만 따라가며 조사한다. 만약 풀이를 얻지 못하면, 되돌아가 다른 가지의 조사를 시작한다. 이 방법을 깊이 우선 탐색 (depth-first search) 이라 부른다. 제어 방법이 체계적이어야 한다는 조건은 각 단계에서 발생하는 국부적인 움직임뿐만 아니라, 여러 단계에서 발생하는 전제적인 움직임에 있어서도 필요하다.
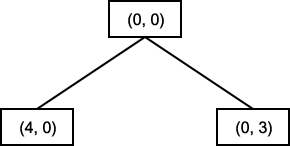
그림 5 나비 우선 탐색 (BFS) 트리의 한 레벨
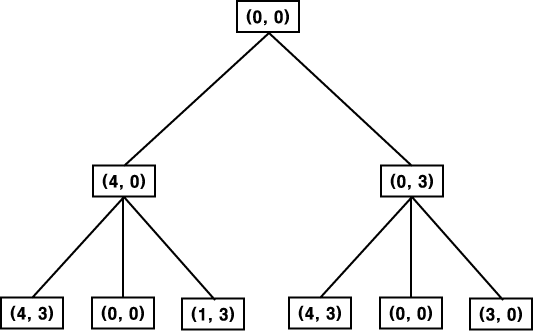
그림 6 나비 우선 탐색 (BFS) 트리의 두 레벨
물 주전자 문제와 같이 단순한 문제는 움직임을 야기하는 체계적인 제어 방법이 사용되면, 대부분 문제의 풀이를 얻을 수 있지만, 반드시 그런 것은 아니다. 일부 문제들을 풀기 위해서는 효율적인 제어 구조가 필요하다.
다음 문제를 살펴 보자.
▷▶▷ 세일즈 맨의 방문 문제
한 세일즈 맨이 반드시 한 번 방문해야 할 도시의 리스트를 가지고 있다. 선택된 어느 도시든지 나머지 다른 도시로 곧장 직행할 수 있는 길이 있다. 세일즈 맨은 방문을 시작할 도시를 임의로 선택할 수 있으며, 나머지 다른 도시를 모두 방문한 후 다시 이 도시로 되돌아 와야 한다. 이때, 최단 거리로 왕복 여행을 하기 위해 따라야 할 경로를 찾아라.
원칙상, 간단하고 움직임을 야기하는 체계적인 제어 구조를 사용하여 이 문제를 풀 수 있다. 즉, 가능한 모든 경로의 트리를 조사하여 이 중 가장 짧은 거리를 가진 트리를 찾으면 되는데, 이 방법은 방문할 도시의 수가 작을 경우에 효과적이다. 그러나 방문해야 할 도시가 많아지면, 이 방법을 이용해 해답을 얻는 것은 쉬운 일이 아니다. N 개를 방문하기 위해서, 왕복 여행시 생길 수 있는 경로는 (N-1)! 개나 된다. 하나의 경로를 조사하기 위해 소요되는 시간은 N 에 비례하므로, 서로 다른 (N-1)! 개의 경로를 모두 탐색하기 위해 필요한 시간은 O(N!) 이다. 10! 은 3,628,800 이라는 매우 큰 수이다. 그런데 세일즈 맨이 25 개 정도의 도시를 방문하는 것은 매우 흔한 일이다. 이 세일즈 맨이 문제를 풀기 위해 걸리는 시간은 그냥 기다려야 하는 시간보다 더 많이 요구된다. 이러한 현상은 폭발적 급증 (combinatorial explosion) 이라 하는데, 이것을 해결하는 새로운 제어 방법이 필요하다.
분기와 한계 (branch-and-bound) 라 불리는 제어 기법을 이용하여 위 문제를 해결해보자. 이 방법은 지금까지 발견된 최단 경로를 기억하면서 완전한 경로를 만들어 가는 것으로써, 현재 조사중인 경로의 부분적 길이가 지금까지 얻어진 최단 경로의 길이보다 더 길 경우, 이 경로의 조사를 중단하고 다른 경로를 택하여 조사를 계속한다. 이 방법을 사용하면 최단 경로를 얻을 수 있기 때문에 첫 번째 방법보다 효율적이기는 하지만, 이 문제를 풀기 위해 요구되는 시간도 역시 지수 함수에 비례한다. 이 방법을 사용해 문제를 풀 때 걸리는 시간은 경로들을 조사하는 순서에 의해 결정되므로, 대형문제를 풀기에는 부적당한 방법이다.
어려운 많은 문제를 효율적으로 풀기 위해, 제어 방법의 이동성과 단순성에 대한 조건을 완화하는 대신, 비록 최적 해답을 얻을 수 없지만, 거의 모든 문제에 대해 효율적인 풀이를 찾을 수 있는 제어 구조를 구성할 필요가 있다. 이를 위해 경험적 방법이라는 개념을 소개한다. 경험적 방법 (heuristics) 은 제어 방법의 완전성이라는 조건을 완화하는 대신 탐색 과정의 효율성을 증가시키는 기법으로써, 여행 안내 책자와 같은 역할을 한다. 여행 안내 책자는 흥미있는 방향을 알려주는 장점을 지니고 있는 반면, 그다지 구경거리가 없는 장소로 안내하는 결점이 있다. 과정에서 요구되는 완전성을 희생하지 않고 탐색 과정을 유도하는 경험적 방법뿐만 아니라, 때때로 최적 경로를 찾지 못하고 다른 경로를 찾는 경험적 방법도 있다. 그러나 평균적으로 볼 때, 경험적 방법은 조사해야 할 경로의 질을 향상시킨다. 좋은 경험적 방법을 사용하여, 문제를 풀기 위해 요구되는 시간이 지수 함수에 비례하지 않고, 그보다 적은 시간 내에 세일즈 맨의 방문 문제와 같이 어려운 문제를 (비록 이 풀이가 최적 해는 아닐지라도) 효율적으로 풀 수 있다. 광범위한 문제의 분야에 대한 풀이를 찾는 범용 경험적 방법뿐만 아니라, 특정한 문제를 풀기 위해 영역 특성에 대한 지식을 사용하는 특수 목적의 경험적 방법을 만들 수 있다.
최단 이웃 알고리즘 (nearest-neighbor algorithm) 은 탐색 시간이 폭발적으로 급증하는 성격을 가진 문제를 효과적으로 푸는 범용 경험적 방법의 한 예이다. 이 방법은 각 단계에서 국부적으로 우선권을 가진 것을 택하는 것이다. 다음은 세일즈 맨의 방문 문제에 최단 이웃 알고리즘을 적용할 때 필요한 과정을 설명한다 :
1. 출발 도시를 임의로 선출한다.
2. 다음 도시를 선택하기 위해, 아직 방문되지 않은 도시들을 조사하여, 현재 도시와 가장 가깝게 위치한 도시를 선택하여 그 도시로 간다.
3. 모든 도시를 전부 방문할 때까지 단계 2 를 반복한다.
이 과정을 수행하는 데 필요한 시간은 N 의 제곱에 비례하며, N! 에 비례하는 수행시간에 비해 매우 감소된 것으로써 발생할 수 있는 착오의 상한이 된다. 최단 이웃 알고리즘과 같은 범용 경험적 범용을 사용하여 착오의 한계를 구할 수 있다. 그러나 많은 인공 지능 분야의 문제에서, 다음 두 가지 이유 때문에, 착오의 한계를 구하지 못할 경우가 있다 :
비 구조적인 상태에서도 탐색 과정의 효율성에 대해 언급할 수 있다. 비록 최단 이웃 알고리즘만큼 일반적이지는 않지만, 광범위한 문제 분야에서 유용하게 사용되는 경험적 방법은 많이 존재한다. 예를 들어 어떤 특수 분야의 중심 개념을 찾는 문제를 살펴보자. 이 문제를 위해 다음 경험적 방법이 사용된다 :
두 개의 변수로 이루어진 f(x, y) 라는 함수가 있다. 변수 x 와 y 가 동일한 것일 때 함수에 발생하는 일을 조사하라.
f 가 곱셈의 작용을 하는 경우, 제곱을 얻는 작용을 하고, f 가 합집합을 구하는 작용을 한다면, 항등 함수의 역할을 한다. 즉,
f(x, y) = x × y 일 때
x = y 이면 f(x, x) = x2
f(x, y) = x ∨ y 일 때
x = y 이면 x ∨ x = x
이다.
일상 생활에서 일어나는 일을 함수 f 로 정의해 보자. 만약 f 가 심사 숙고하는 일을 나타내는 함수라면, 자기 반성의 작용을 하고, f 가 죽이는 일을 나타내는 함수라면, 자살의 개념을 유도한다.
경험적 방법이 없었다면, 폭발적인 급증의 성격을 띤 문제를 해결할 수 없었을 것이다. 경험적 방법은 또한 다음 이유 때문에 유용하게 사용된다.
문제 풀이 과정에서 경험적 방법의 중요성을 가장 잘 설명한 책 중의 하나는 "그것을 푸는 방법" (How to solve it [폴야 (Polya), 1957]) 이다. 이 책에서는 주로 수학적인 문제를 푸는데, 중점을 두었지만, 여기서 소개된 여러 기법들을 사용하여 일반적인 문제를 풀 수 있다. 어떤 새로운 문제 A 가 주어졌을 때 A 를 풀기 위해, 이미 해답을 가지고 있는 A 와 비슷한 문제를 찾는다. 발견된 문제의 해답이나 혹은 그 문제를 풀기 위해 사용되었던 방법을 문제 A 에 적용할 수 있는지 조사한다. 그러나, 인공 지능 분야의 모든 문제들이 이 방법에 의해 해결될 수 있는 것은 아니다. 아래에서 그 이유를 설명한다.
그럼에도 불구하고 폴야 (Polya) 는 초판의 서문에 나타나 있듯이, 이것에 대해 관심을 가졌다. "다음 페이지들은 가능한 한 간단하고 단순하게, 그러나 비교적 정확하게 서술되었으며, 풀이에 대한 길고 진지한 연구를 토대로 하였다. 일부 저자들에 의해 경험적 방법이라 불리우는 이 방법은 비록 현재는 그리 많이 이용되지 않지만, 과거 오랫동안 사용되어 왔고 미래에도 사용될 것이다.
앞 절에서 인공 지능 분야의 문제를 푸는 것을 탐색 과정에 중심을 둔 것으로 설명하였는데, 이 절에서의 논의로부터, 이것을 경험적 방법에 의한 탐색 과정으로 더욱 정확히 나타낼 수 있음을 알았다. 일부 경험적 방법은 제어 구조를 정의하여, 탐색 과정동안 적용될 규칙을 결정하고, 나머지는 지금까지 보아온 바처럼 규칙 자체로 코드화된다. 두 가지 경우 모두 경험적 방법은 어려운 문제에 대한 해답을 찾을 수 있도록 하는 일반적 혹은 특수한 지식을 나타내며, 인공 지능을 정의하는 또 다른 방법이 된다. 인공 지능은 문제 영역에 대한 지식을 이용하여, 지수 함수에 비례하는 해결시간을 필요로 하는 종류의 난해한 문제를 다항 함수에 비례하는 시간 내에 푸는 기법이다.
경험적 탐색 방법은 다양한 여러 종류의 문제에 적용되는 매우 일반적인 방법이며, 문제의 특수성을 포함하여 특별히 그 문제를 효과적으로 푸는 데 사용되기도 한다. 주어진 특정한 문제에 대해 가장 적합한 방법 (혹은 방법의 결합) 을 택하기 위해 다음 몇 가지 특성에 따라 문제를 분석할 필요가 있다.
위에 소개된 질문들을 이 절의 나머지 부분에서 자세히 다루었다. 위의 질문 중 일부는 문제 자체의 기술뿐만 아니라, 원하는 풀이의 특성과 풀이가 행해지고 있는 상황도 고려해야 함을 주목하라.
다음 식을 푸는 문제를 살펴 보자 :
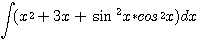
위 식을 세 개의 작은 부분으로 나누어, 각 부분에 특정한 규칙을 적용함으로써, 이 문제를 풀 수 있다. 문제 분해 (problem decomposition) 과정에 의해 얻어진 문제 트리가 그림 7 에 보여지는데, 다음 방법에 따라 작용하는 간단한 순환적인 적분 프로그램을 이용하여 문제를 푼다. 이 프로그램이 적용되고 있는 문제가 이것에 의해 즉시 풀이를 얻을 수 있는지 조사한다. 만약 그렇다면, 곧 바로 풀이를 얻는다. 문제가 쉽게 풀어지지 않는 것이라면 더 작은 부분으로 나누어 이것을 순환적으로 하나씩 푼다. 문제 분해의 기법을 사용하여 매우 커다란 문제를 쉽게 풀 수 있다.

그림 7 분해 가능한 문제
그림 8 에 보여진 문제를 살펴 보자. 이 문제는 인공 지능 분야에서 블럭 세계 (blocks world) 라 불리는 분야에 속한다.

그림 8 간단한 블럭 세계 문제
이 문제를 풀기 위해 다음 작용자가 사용된다 :
1. CLEAR (X) [상자 X 위에 아무 것도 없다] → ON (X, Table) [X 를 찾아 탁자위에 놓는다].
2. CLEAR (X) AND CLEAR (Y) → ON (X, Y) [Y 위에 X 를 놓는다]
위의 간단한 블럭 세계 문제에 문제 분해 기법을 적용하여 얻은 풀이 트리가 그림 9 에 있다. 이미 얻어진 사항에 대해서는 밑줄이 없다. 이것은 C 위에 B 를, 그리고 B 위에 A 를 놓는 문제를 두 개의 독립적인 문제로 분해하여 풀었다. C 위에 B 를 놓는다는 첫번째 문제는 주어진 초기 상태에서 간단히 해결된다. 즉 단순히 C 위에 B 를 놓으면 된다. 그러나 두번째 문제는 쉽게 해결되지 않는다. 허용된 작용자는 한 번에 하나의 상자만을 택해 처리하기 때문에 A 를 찾아 B 위에 놓기 전에, C 를 이동시켜 A 위에 아무 것도 없도록 해야 한다. 비록 이것을 쉽게 풀 수 있지만, 각각 독립적으로 구한 두 개의 풀이를 하나로 결합해 보면, 원래 문제에 대한 원하는 풀이가 아님을 알 수 있다. 어느 것을 먼저 선택해도, 원하는 대로 두번째 문제를 풀 수 없다. 이 독립적인 두 개의 문제는 서로 상호 작용을 하는데, 원래 풀고자 하는 문제의 풀이를 얻기 위해서는 이 상호 작용을 고려해야 한다.

그림 9 블럭 문제에 대한 제안적 풀이
적분과 블럭 세계의 문제로부터, 분해 가능한 문제와 분해 불가능한 문제 간의 차이점을 알 수 있다. 분해 가능한 문제는 문제 분해의 분리에 의한 해결 (divide-and-conquer) 이라는 기법을 사용하여 풀 수 있다. 분해 불가능한 문제의 경우, 비록 근사해를 구해 상호 작용에 의해 발생하는 결함을 보완하는 기법을 사용하여 풀 수 있지만 일반적으로 불가능하다. 제 3 장에서 문제 분해 기법을 다루었고, 제 8 장에서 분해 불가능한 문제를 푸는 기법을 소개하였다.
수학적인 정리를 증명하려 한다. 먼저 유용하다고 생각되는 보조 정리 (lemma) 를 증명하면서 정리의 증명을 시작한다. 이 보조 정리가 정리의 증명에 전혀 도움을 주지 못함을 후에 깨닫게 되는 경우가 있다.
만약, 정리를 증명하기 위해 알아야 했던 것들이 이전에 참이었다면, 이것들은 여전히 데이터 베이스에 존재하며, 또한 현재도 참이다. 즉, 이전에 적용되었던 규칙은 어느 것이든지 이후에 다시 적용될 수 있고, 초기 상태에 있는 것처럼 계속 수행할 수 있다. 이 경우, 풀이가 아닌 것을 조사하는데 소모한 노력만이 손실되었을 뿐, 다시 수행되는 풀이 과정에는 영향을 미치지 않는다.
다음 문제를 살펴 보자.
<8-퍼즐 문제>
8-퍼즐은 아홉 개의 작은 정사각형으로 이루어진 정사각형 판이다. 이중 여덟 개의 정사각형은 1부터 8 까지의 번호를 가진 타일로 채워져 있고 나머지 하나는 비어 있다. 게임은 빈 공간과 접해 있는 타일을 그 곳으로 적절히 옮겨 출발 위치로부터 미리 규정된 원하는 위치에 놓는 것이다.
|
2 |
8 |
3 |
|
1 |
2 |
3 |
|
1 |
6 |
4 |
|
8 |
|
4 |
|
7 |
|
5 |
|
7 |
6 |
5 |
그림 10 8-퍼즐 문제의 한 예
8-퍼즐 게임의 예가 그림 10 에 있다. 8-퍼즐을 푸는 과정에서 원하는 상태로 게임을 이끌지 못하는 부적합한 움직임이 있을 수 있다. 예를 들어 위에 보여진 게임에서 5 번 타일을 빈 공간으로 옮길 수 있다. 일단 이것이 행해지면, 6 번 타일과 빈 공간이 접하지 못하게 되고, 이 6 번 타일을 빈 공간으로 옮기기 위해 6 번 타일과 빈 공간이 접하지 못하게 되고, 이 6 번 타일을 빈 공간으로 옮기기 위해 6 번 타일과 접한 곳에 빈 공간을 다시 만들어 주어야 한다. 5 번 타일을 움직이기 전의 상태로 옮겨 첫번째 이동이 행해지지 않았던 것처럼 원상태로 되돌릴 수 있다. 그리고 나서 6 번 타일을 옮긴다. 잘못된 움직임을 회복시킬 수 있지만, 이를 위해 특별한 부가적인 단계가 수행되어야 하기 때문에, 정리 증명 문제만큼 쉽게 회복시킬 수는 없다. 즉, 무익한 보조 정리를 행해지지 않았던 것처럼 하기 위해서는 어떤 단계도 필요하지 않지만, 8-퍼즐의 경우 행해진 움직임이 행해지지 않은 것처럼 하기 위해서는 부가적인 특별한 단계가 수행되어야 한다. 뿐만 아니라, 8-퍼즐을 푸는 제어 기법은 행해진 작용이 행해지지 않은 것처럼 해야 할 경우를 위해, 행해진 움직임의 순서를 기억해야 한다. 반면 정리 증명을 위한 제어 기법은 그 모든 정보를 기억할 필요가 없다.
이제 체스 문제를 다시 살펴 보자. 체스 프로그램이 무익한 움직임을 행한 후, 두 세번 더 움직인 후에야 비로소 이 사실을 알았다고 가정하자. 마치 그 무익한 움직임이 전혀 발생되지 않았던 것처럼 간단히 게임을 진행할 수는 없다. 또한 단순히 그 움직임이 행해지지 않은 이전의 상태로 되돌아가 그곳에서 다시 게임을 시작할 수도 없다. 이 경우에 취할 수 있는 최선의 방법은 현재 상태를 최적으로 만들어 게임을 진행하는 것이다.
이 세 개의 문제 - 정리 증명, 8-퍼즐과 체스 문제 - 는 문제의 종류 간의 중요한 차이를 설명한다.
이 세 개의 정의는 문제의 풀이 과정에 대해 언급한 것으로써, 문제 자체보다 문제를 푸는 특정한 생성 시스템의 특성을 설명한다. 같은 문제를 다른 형식으로 표기한다면, 다르게 특성지어지는 문제로 만들어 질 것이다. 그러나 대부분의 많은 문제들은, 있는 그대로 문제를 기술하는 단 하나의 형식을 사용하여 표기된다. 위에서 예로 사용된 문제의 경우도 마찬가지이다. 이 경우, 문제의 원상태 회복 가능성을, 있는 그대로 묘사하는 형식에 의해 표기된 문제의 원상태 회복 가능성으로 볼 수 있다.
문제의 원상태 회복 가능성은 필요한 제어 구조의 복잡성을 결정하는데 중요한 역할을 한다. 과정을 무시할 수 있는 문제는 되돌아 갈 필요가 없는 간단한 제어 구조를 이용하여 풀 수 있으며, 이러한 제어 구조는 쉽게 구현된다. 원상태로 회복할 수 있는 문제는 때때로 만들어진 실수를 처리할 수 있는 좀 더 복잡한 제어 구조에 의해 풀 수 있다. 행해진 실수를 회복하기 위해서 실수가 발생한 곳으로 다시 되돌아가야 하는데, 이러한 제어 구조는 푸시 다운 스택 (push down stack) 을 사용하여 구현되며, 행해진 움직임을 행해지지 않은 것처럼 해야 할 경우가 발생되었을 때를 처리하기 위해서 만들어진 결정이 스택에 기록된다. 반면, 원상태로의 회복이 불가능한 문제는 하나의 결정을 만들기 위해 많은 노력이 필요한 제어 구조에 의해 풀 수 있다. 왜냐하면, 일단 행해진 결정은 돌이킬 수 없기 때문이다. 일부 원상태로의 회복이 불가능한 문제는 계획 과정 (planning process) 에서 사용된 원상태로의 회복 가능 유형 방법을 사용하여 풀 수 있는데, 이 방법은 실제로 첫번째 단계를 실행하기에 앞서 행해진 일련의 전 단계들이 유도할 장소를 찾기 위해 미리 이 전 단계들을 분석한다. 이 방법을 이용해 풀이를 찾는 종류의 문제들이 다음에서 다루어 진다.
8-퍼즐 문제를 다시 살펴 보자. 하나의 타일을 움직일 때마다, 앞으로 발생할 일을 정확히 예측할 수 있다. 즉, 일련의 전체 움직임을 계획하고, 이것의 결과로 얻어지는 상태를 정확히 알 수 있다. 비록 계획 과정동안 이미 행해진 움직임들을 한번에 하나씩 후진해야 할 필요가 완전히 제거된 것은 아니지만, 실제로 행해진 움직임을 행해지지 않았던 것처럼 해야 하는 것을 피하기 위해 계획을 사용한다. 따라서 후진을 허용하는 제어 구조가 필수적이다.
그러나, 이 계획 과정이 불가능한 게임도 있다. 브리지 (Bridge) 를 한다고 가정하자. 우리가 만들어야 할 결정 중의 하나는 첫번째 판에서 사용할 카드를 결정하는 것이고, 첫번째 카드를 내놓기 전에, 전체 판을 계획하는 일이 필요하다. 그러나 카드가 누구에게 어떻게 분포되어 있는지, 혹은 다른 경기자들이 그들의 차례가 되었을 때 어떻게 반응할지 정확히 알 수 없기 때문에, 확신을 가지고 전체 판을 계획하는 것은 어렵다. 취할 수 있는 최선의 방법은 가능한 여러 계획을 조사하고, 그 판에서 고득점을 얻을 수 있는 확률이 가장 높은 계획을 택하기 위해, 여러 결과에 대한 확률을 사용한다.
위의 두 게임은 확실한 결과를 가진 문제 (예, 8-퍼즐) 와 불확실한 결과를 가진 문제 (예, 브리지) 간의 차이점을 설명한다. 계획 (planning) 은 주위의 사정과 더불어 재고하지 않고 문제를 푸는 방법이다. 확실한 결과를 가진 문제를 푸는 경우, 수행의 결과를 정확히 예측할 수 있기 때문에, 이 열린 루프 방식 (open-loop-approach) 은 효과적으로 작용한다. 따라서 계획을 사용하여, 문제에 대한 풀이를 반드시 찾는 일련의 연산자를 만든다. 그러나 불확실한 결과를 가진 문제의 경우, 계획은 기껏해야 문제의 풀이를 얻을 확률이 높은 일련의 연산자들을 만들 뿐이다. 계획이 실행되고 필요한 피드백이 준비됨에 따라 이 문제를 풀기 위해서, 계획을 수정하는 단계가 반드시 함께 수반되어야 한다. 불확실한 결과를 가진 문제에 대한 계획은 사실상 풀이를 보장할 수도 없을 뿐만 아니라, 결과를 예측할 수 없는 점들의 수가 증가함에 따라 조사할 풀이 경로의 수가 지수 함수에 비례하여 증가하기 때문에, 매우 많은 비용을 필요로 하는 결점이 있다.
지금까지 논의한 앞의 두 가지 문제의 특성 - 과정 무시 가능과 원상태 회복 가능과 원상태 회복 불가능의 특성 및 확실한 결과를 가진 것과 불확실한 결과를 가진 것의 특성은 서로 흥미있는 방법으로 상호 작용한다. 이미 언급된 것처럼, 원상태로의 회복이 불가능한 문제를 푸는 한 가지 방법은 계획을 실행하기에 앞서, 전체적인 풀이를 계획하는 것이다. 그러나 이 계획 과정은 확실한 결과를 가진 문제를 푸는데 효과적이다. 원상태로의 회복이 불가능하고 불확실한 결과를 가진 문제는 풀기에 가장 어려운 문제 유형 중의 하나이다. 여기에 속하는 문제의 예가 다음에 있다 :
다음과 같은 간단한 사실을 가지고 있는 데이터 베이스를 기초로 하고 있는 질문에 대해 답을 찾아 보자 :
1. 마커스 (Marcus) 는 사람이다.
2. 마커스 (Marcus) 는 폼페이 사람이다.
3. 마커스 (Marcus) 는 서기 40 년에 태어났다.
4. 모든 사람은 죽는다.
5. 서기 79 년에 화산이 폭발했을 때, 모든 폼페이 사람들이 죽었다.
6. 어떤 생물도 150 년 이상 살 수 없다.
7. 지금은 서기 1986 년이다.
"마커스가 살아있는가?" 라는 문제를 살펴 보자. 서술 논리 (predicate calculus) 와 같은 형식적인 언어를 사용하여 각 사실을 표기하고, 형식적 추론 방법에 의해 이 질문에 대한 답을 얻을 수 있다. 그림 11 에 보여지듯이 두 가지 추론 과정에 의해 이 질문에 대한 답을 구할 수 있다. 중요한 것은 질문에 대한 답이며, 이 답을 이끌어 낸 추론 과정은 중요하지 않다. 추론 과정중 후진하여 답으로 이끌 수 있는 또 다른 경로가 존재하는 지 등을 조사하지 않고, 답을 유도하는 하나의 추론 과정을 계속 따라가면 된다.
|
1 마커스는 사람이다. |
근거 공리 1 |
|
4 모든 사람은 죽는다. |
공리 4 |
|
8 마커스는 죽는다. |
1, 4 |
|
3 마커스는 서기 40 년에 태어났다. |
공리 3 |
|
7 지금은 서기 1986 년이다. |
공리 7 |
|
9 마커스의 나이는 1946 세이다. |
3, 7 |
|
6 어떤 생물도 150 년 이상 살 수 없다. |
공리 6 |
|
10 마커스는 죽었다. |
8, 6, 9 |
|
또는 |
|
|
7 지금은 서기 1986 년이다. |
공리 7 |
|
5 모든 폼페이 사람들이 서기 79 년에 죽었다. |
공리 5 |
|
11 모든 폼페이 사람들은 지금 죽었다. |
7, 5 |
|
2 마커스는 폼페이 사람이다. |
공리 2 |
|
12 마커스는 죽었다. |
11, 2 |
그림 11 마커스가 죽었다는 것을 결정하는 두 방법
그러나 세일즈 맨의 방문 문제를 다시 살펴 보자. 각 도시를 한번씩 모두 방문하는 경로중 최단 거리를 가진 경로를 찾아야 한다. 그림 12 에 방문할 도시와 그들간의 거리가 나타나 있다.
|
|
보스톤 |
뉴욕 |
마이애미 |
달라스 |
샌프란시스코 |
|
보스톤 |
|
250 |
1450 |
1700 |
3000 |
|
뉴욕 |
250 |
|
1200 |
1500 |
2900 |
|
마이애미 |
1450 |
1200 |
|
1600 |
3300 |
|
달라스 |
1700 |
1500 |
1600 |
|
1700 |
|
샌프란시스코 |
3000 |
2900 |
3300 |
1700 |
|
그림 12 세일즈 맨 문제의 예

그림 13 도시 간의 한 가지 경로
세일즈 맨이 보스톤에서 출발하여 각 도시를 방문할 때, 그가 그림 13 에 따라 각 도시를 방문할 경우, 총 8,850 마일을 여행하게 된다. 이 경로가 최적 경로인지 결정하기 위해서는 다른 모든 가능한 경로를 탐색하여, 이 경로보다 더 짧은 거리를 가진 경로가 존재하는 지 조사해야 한다. 이 경우 그림 14 에 보여지듯이 첫번째 경로가 세일즈 맨의 방문에 대해 적합한 답이 아님을 알 수 있다.

그림 14 도시 간의 두 가지 경로
위의 두 예는 임의 경로 문제 (any-path problem) 와 최적 경로 문제 (best-path problem) 간의 차이를 설명한다. 일반적으로, 계산면에 볼 때 최적 경로 문제가 임의 경로 문제보다 어렵다. 임의 경로 문제는 조사하기에 적합한 경로를 제공하는 경험적 방법을 사용하여 적당한 시간 내에 풀 수 있다 (제 3 장의 최적 - 우선 탐색을 참조하라). 경험적 지식이 완벽하지 않을 경우, 풀이에 대한 탐색이 원하는 것만큼 직접적이지는 않지만 이것은 문제가 되지 않는다. 그러나 최적 경로 문제에 있어, 최적해를 놓칠 수 있는 경험적 방법은 어느 것도 사용될 수 없다.
곱셈에 대한 다음과 같은 공리가 주어졌다.
1. 모든 XY 에 대해 XY 가 정의된다.
2. X = Y ∧ Y = Z → X = Z
3. X = X
4. (X Y) Z = X (Y Z)
5. I X = X
6. X-1 X = I
7. X = Y → Z X = Z Y
8. X = Y → X Z = Y Z
"XI = X 를 증명하라." 는 문제는 공리들의 집합들이 일괄성을 가지고 있기 때문에, 수학의 일반적인 증명 과정을 사용하여 풀 수 있다. 그러나 다음 문제를 살펴 보자 :
▷▶▷ 과녘 문제 (The target Problem) :
과녘으로부터 150 피트 떨어진 곳에 한 사람이 서 있다. 과녘을 향해 1500 ft/sec 의 속도로 총알을 발사하는 권총을 쏘았다 과녘으로 얼마나 높이 겨냥해야 할까?
다음 방법에 따라 풀이를 찾을 수 있다. 권총으로부터 발사된 총알이 과녘까지 직선 운동을 한다고 가정할 때, 총알이 과녘을 맞출 때까지 0.1 초 걸리며 이 0.1 초 동안 총알은 0.16 피트 하강한다.
1/2 g t2 ft = 1/2 (32) (.1)2 ft = .16 ft
만약 0.16 피트 위를 겨냥한다면, 총알이 과녘에 닿을 때까지 걸리는 시간 내에 0.16 피트 하강하여 과녘에 맞는다. 그러나 이 문제를 풀 때 총알이 직선 운동을 한다고 가정했다. 이 가정은 총알이 실제로 포물선 운동을 한다는 결론과 일치되지 않는다.
위 두 문제는 전혀 모순이 없이 일관성있는 체계에 속하는 문제와 데이터 베이스 내에 모순이 존재할 수 있는 체계에 속하는 문제 간의 차이를 설명해준다. 모순이 없이 일관성 있는 체계에서 잘 적용하는 여러 추론 기법들이 모순이 있는 체계에서는 적용되지 못한다. 예를 들어 일반 논리학에서 데이터 베이스에 A 와 A 의 부정, 즉 ~A 가 포함되어 있을 경우, 어느 것이든지 증명할 수 있으나, 그러한 체계는 모순이 있는 체계에 속하는 문제의 답을 구하는데 거의 도움을 주지 못한다.
체스 문제를 다시 살펴 보자. 무한한 계산력이 이용될 수 있다고 가정할 때, 완벽한 프로그램을 만들기 위해 얼마나 많은 지식이 필요한가? 이를 위해서는 적절한 작은 양의 지식이 필요하다. 움직임의 정당성을 결정하는 규칙과 적절한 탐색 과정을 구현하는 간단한 제어 기법이 필요할 뿐이다. 물론 유용한 방법과 방식에 관한 특별한 지식은 탐색을 제한하고, 프로그램의 빠른 실행에 상당히 많은 도움을 줄 수 있다. 사실상 그러한 지식이 없었다면, 체스를 현실적으로 해결할 수 없었을 것이다.
그러나 미국의 차기 대통령 선거에서 민주당원이 지지하는 것과 공화당원이 지지하는 것을 결정하기 위해 일간 신문을 조사하는 문제를 살펴 보자. 무한한 계산력을 이용할 수 있다고 가정할 때, 이 문제를 풀기 위해 컴퓨터는 어느 정도의 지식을 필요로 하는가? 이 경우에는, 매우 많은 지식이 필요한데, 다음과 같은 사항을 알아야 한다 :
체스와 신문 이해의 두 문제는 풀이의 탐색을 제한하는데만 지식이 사용되는 문제와 풀이를 구하기 위해 많은 지식이 요구되는 문제 간의 차이를 설명한다.
컴퓨터와 사용자 간의 상호 작용이 문제시되지 않는 경우, 대다수의 사람들이 이해하지 못하는 프로그램을 작성할 수 있다. 그러나 후에 입력을 첨가하거나, 사용자를 확신시킬 필요가 있을 경우, 컴퓨터와 사용자 간을 중재하는 상호 작용이 필요하다.
예를 들어, 수학적인 정리를 증명하는 문제를 살펴 보자. 만약 증명의 존재 여부에 관심이 있거나, 증명이 존재할 경우, 프로그램 자체가 그 증명을 찾을 수 있다면, 증명을 찾기 위해 프로그램이 어떤 방법을 택하느냐 하는 것은 중요하지 않다. 예를 들어 매우 효율적이지만, 대부분의 사람들이 이해하기 어려운 비교 흡수 방법 (resolution) 을 사용할 수 있다. 그러나 이 외의 다른 경우에 있어서는 증명을 찾기 위해 사용된 방법이 중요한 관심사이다. 새롭고 매우 어려운 정리를 증명하고자 할 때, 수학자들이 증명을 읽어 가면서, 이것이 참인지 조사할 수 있도록, 수학에서 전형적으로 행해지는 증명 과정을 필요로 할 경우가 있다. 그 대신, 프로그램이 어디서부터 출발해야 할지를 모를 만큼, 정리에 대한 증명을 찾는 일은 매우 어렵다. 이 경우, 인간이 증명을 위해 필요한 방법을 적절히 제공할 수 있으며, 컴퓨터는 자문을 구할 수 있다. 컴퓨터를 의료 진단과 같은 인간 생활의 중요한 분야에 사용할 경우, 컴퓨터에서 이용되는 프로그램의 추론 과정을 확실히 이해하여야 한다.
위의 두 문제간의 차이를 다음과 같은 경우로 뚜렷이 구별할 수 있다 :
물론 위의 특성이 특정한 문제 영역을 엄밀하게 기술하지는 못한다. 위에서 알 수 있듯이 수학적인 정리를 증명하는 것을 위의 둘중의 어느 하나로 간주할 수 있다. 경우에 따라, 위의 두 형태 중의 하나를 선택하게 되는데, 이 결정은 문제 풀이 방법을 선택하는데 중요한 영향을 미친다.
지금까지 문제를 분류하는 특성에 대해 논의해 왔으며, 생성 시스템이, 문제의 풀이를 찾는 과정에서 수행되는 연산 작용을 나타내는데 매우 유용한 방법임을 알았다. 이 점에서 다음 두 가지 문제를 살펴 보자 :
1. 문제에서처럼, 생성 시스템을 이것의 구현을 용이하게 하는 특성의 집합으로 기술할 수 있는가?
2. 만약 그렇다면, 문제의 형태와 문제 풀이에 가장 적합한 생성 시스템의 형태 간에 어떤 관계가 있는가?
첫번째 질문에 대한 답은 "예" 이다. 생성 시스템을 분류하는 다음 정의를 살펴 보자. 단조적 생성 시스템 (monotonic production system) 은 앞서 적용된 규칙들이 후에 적용될 다른 규칙 (동시에 적용될 수도 있다) 에 영향을 주지 않는다. 부분적으로 상호 교환 가능한 생성 시스템 (partially commutative production system) 은 일련의 규칙에 의해 상태 X 가 상태 Y 로 전이 하였을 경우 이 일련의 규칙들을 어떠한 순서로 바꾸어 적용하여도 상태 X 를 상태 Y 로 전이시키는 생성 시스템이다. 상호 교환 가능 생성시스템은 단조적이고 부분적으로 상호 교환 가능한 생성 시스템이다.
|
|
단 조 적 |
비단조적 |
|
부분적으로 상호교환 가능 |
정리 증명 |
블럭 세계 8 - 퍼즐 |
|
부분적으로 상호교환 불가능 |
화학 합성 |
브 리 지 |
그림 15 생성 시스템의 4 가지 범주
생성 시스템의 종류와 문제의 종류 간에 어떤 관계가 있는 지의 여부에 대한 두번째 질문을 살펴 보자. 어느 문제라도 풀이를 얻는 방법을 기술하는 생성 시스템이 무한히 많이 존재하며, 이중 일부 생성 시스템은 나머지 생성 시스템보다 적합하고 효율적일 것이다. 어떤 생성 시스템에 의해서라도 풀이를 얻을 수 있는 문제는 어느 것이라도 상호 교환 가능한 생성 시스템을 사용하여 풀이를 구할 수 있다. 그러나 상호 교환 가능한 생성 시스템은 처리하기 힘들기 때문에 실질적으로 부적당하다 : 좀 더 간단한 상호 교환 불가능 시스템에 적용된 일련의 모든 규칙을 표기하기 위해 개개의 상태를 사용할 수 있다. 표면상 모든 문제는 어떤 생성 시스템에 의해서라도 모두 풀 수 있기 때문에 문제와 생성 시스템에 어떠한 관계도 없지만, 실질적으로 볼 때 문제와 생성 시스템 간에 명백한 관계가 있어, 이 생성 시스템에 의해 문제를 적절히 설명할 수 있다. 이를 위해 몇 가지 예를 살펴 보자. 그림 15 는 네 가지 종류의 생성 시스템을 각 생성 시스템에 의해 풀 수 있는 문제와 함께 보여 준다. 왼쪽 상단은 상호 교환 가능 생성 시스템을 나타낸다.
부분적으로 상호 교환 가능하고 단조적인 생성 시스템을 이용해 원상태 복구 가능한 문제를 풀 수 있고, 사실상 근본적으로 이 두 정의는 서로 같다. 원상태 복구 가능한 문제란 적당한 형식을 사용함으로써, 풀이 관계를 무시할 수 있는 문제임을 기억하라.
이 때 적당한 형식화가 부분적으로 상호 교환 가능하고 단조적인 생성 시스템을 의미한다. 이미 존재하는 것을 변화시키는 대신 새로운 것을 만들어 내는 문제가 일반적으로 원상태 복구 가능한 문제로써 정리 증명 문제와 이미 알려진 사실로 부터의 추론 문제가 이에 속하고, 부분적으로 상호 교환 가능하고 단조적인 생성 시스템에 의해 쉽게 구현될 수 있다.
부분적으로 상호 교환 가능하고 단조적인 생성 시스템은 행해온 풀이 경로가 해답을 찾을 수 없는 경로임을 알았을 때, 이전 상태로 후진할 필요가 없이 구현될 수 있기 때문에, 구현면에서 중요하다. 비록 체계적인 탐색을 보장하기 위해 후진 능력이 있는 시스템을 구현하는 것이 효과적일 수도 있지만, 문제 상태를 나타내는 실제 데이터 베이스를 다시 기록할 필요는 없다. 이것은 데이터 베이스를 재 기록할 필요가 없기 때문에, 탐색 과정 중 변화가 발생한 곳을 모두 기억할 필요가 없으므로 효율성을 많이 향상시킨다.
지금까지 변화가 일어나지 않고, 새로운 것이 만들어 지는 문제에 적합한 부분적으로 상호 교환 가능하고 단조적인 생성 시스템에 대해 논의해 왔다. 비 단조적이고, 부분적으로 상호 교환 가능한 생성 시스템은 변화가 발생할 수 있고, 발생한 변화를 일어나지 않은 것처럼 할 수 있으며, 연산이 행해진 순서가 중요하지 않는 문제에 적합하다. 이것은 8-퍼즐과 같은 문제에 적합하며, 간단한 움직임의 연산자가 실행된 순서는 중요하지 않고, 여러번 움직였기 때문에 최종 상태와 초기 상태가 다르다.
부분적으로 상호 교환이 불가능한 생성 시스템은 환원할 수 없는 변화가 발생하는 문제에 적합하다. 예를 들어 원하는 화합물을 만드는 과정을 결정하는 문제를 살펴 보자. "화학 약재 X 를 시험관에 넣어라" 혹은 "온도를 Y℃ 로 하라" 등의 작용자를 이용할 수 있는데 일단 이러한 연산자가 적용되면 화합물에 발생한 변화를 환원시킬 수 없다. 또한 연산 작용이 수행되는 순서도 최종 결과에 중요한 영향을 미친다. 즉 B 에 A 를 넣어 얻은 화합물에 C 를 넣어 생기는 화합물은 B 에 C 를 넣은 후, 다시 A 를 넣어 만들어진 화합물과 다르다. 원상태 복구가 불가능한 과정을 나타내는 문제를 다룰 때, 연산을 수행하는 순서를 올바로 결정해야 한다.
앞에서 다루어진 문제 외에도 많은 인공 지능 분야에서 다루어지는 많은 문제가 있다. 이 절에서는 그러한 문제를 소개하려 한다.
|
SEND + MORE |
|
DONALD + GERALD |
|
CROSS + ROADS |
|
MONEY |
|
ROBERT |
|
DANGER |
그림 16 암호 산술 연산 문제의 예
그림 16 에 보여지는 것처럼 문자로 표기된 산술 연산 문제를 살펴 보자. 문제에 대한 답을 올바로 하는 방법으로 문자에 값을 정해 준다. 만약 같은 문자가 한 번 이상 나타나면 매회 같은 값을 지정해야만 한다. 어떤 다른 두 개의 문자도 같은 값을 가질 수 없다.
이 장에서 특정한 문제를 푸는 프로그램을 작성하기 위해 취할 처음 두 단계를 다루었다 :
1. 문제를 정확히 정의하라. 문제 공간, 공간내에서의 움직임을 나타내는 작용자와 초기 상태와 목표 상태를 규정하라.
2. 문제가 속하는 곳을 결정하기 위해 문제를 분석하라.
문제 풀이 프로그램 작성의 세번째 단계는 지식을 표기하고, 문제 풀이를 위한 기법을 하나 혹은 그 이상 택하여, 문제에 그것을 적용하는 것이다. 몇몇 범용 문제 풀이 기법이 다음 장에서 소개되는데, 이들 중 일부는 이 장에서 문제 특성을 논의할 때 암시적으로 다루어졌다.
1. 이 장에서 언급된 다음 문제들을 2 절에서 논의된 7 개의 문제 특성면에서 각각 분석하라.
2. 상태 공간의 탐색을 사용하여 문제를 풀기 전에 적당한 상태 공간을 정의해야 한다. 위에 언급된 문제 중 이 장에서 상태 공간이 정의되지 않은 문제에 대해 적절한 상태 공간 표기를 찾아라.
3. 물 주전자 문제에 대한 최적해를 찾기 위해 분기와 한계 방법이 사용되는 방법을 설명하라.
4. 그림 8 과 같은 블럭 세계의 문제를 푸는 알고리즘을 작성하라.
5. 생성 시스템을 위한 인터프리터를 프로그램하라. 규칙을 가지고 있는 표와 현재 상태를 규칙의 좌측면과 비교하여 짝짓는 과정이 필요하다. 물 주전자 문제를 풀어라.