
�⺻���� ����Ǯ�� ���
�ΰ����� : Elaine Rich ����, ������.���ֽ�.�ѻ� ����, ������, 1986 (���� : Artificial Intelligence, McGraw-Hill, 1983, Artificial Intelligence (2nd ed, 1991)), Page 69~123
(1) �ش��� ������ ��Ʈ ��� (Generate-and-Test)
(2) ��� ������ ��� (Hill Climbing)
(3) ���� �켱 Ž�� ��� (Breadth-First Search)
(4) ���� �켱 Ž�� ��� (Best-First Search) : OR ����
(5) ���� ��� ��� (Problem Reduction)
(6) ���� ������ ���� ��� (Constraint Satisfaction)
(7) ���-���� �м� ��� (Means-Ends Analysis)
���ݱ��� �ΰ� ���� �о��� �������� ��κ�, �������� ������δ� Ǯ �� ���� ��ŭ �����ϴٴ� ���� �˾Ҵ� : ������ ������ Ž�� ����� �� Ž���� �����ϱ� ���� �̿�� �� �ִ� �������� ����� �Բ� ����Ͽ� �� �������� �ذ��ؾ� �Ѵ�. �� �忡�� ���ǵ� ���� Ž�� ����� ��� ������ Ž�� ����� �����̴�. �� ������� Ư���� �۾��̳�, ���� ������ �������� �ʰ� ������ �� ������, Ư���� ������ �����ϴ� ���, ���� Ư���� ���� ������ �̿��ϴ� ����� ���� ����� ����� ȿ������ �����ȴ�. �ֳ��ϸ�, ��� ��ü�δ� Ž�� �������� ���ϱ� ���� ���� �ð��� ������ ������ �ذ��� �� ���� �����̴�. �̷��� ���� ������ �� ������� �ҿ��� ��� (weak methods) �̶� �Ѵ�. ���� 20 �� ����, �ΰ� ���� �о��� ����� �������� Ǯ�� ���� - ������ ���� ������ - �� �ҿ��� ����� ���Ǿ�����, ���� Ư���� ���� ������ ��ġ��ų Ʋ�� �����ϸ�, �ΰ� ���� �ý����� �ٽ��� �̷�� �Դ�.
��� Ž�� ������ ���⼺ ������ Ž������ �� �� �ִµ�, ������ ������ ���¸� ��Ÿ���� ����, ��尣�� ���踦 ��Ÿ���� ���� �� ���� ��带 �����ϴ� ��ũ�� �����ȴ�. ���� ���, �� 5 �� �� ������ ������ ��Ÿ�� Ž�� �����̴�. ������ �� �� �ֵ���, �� ��ũ���� ��Ī�� �־����� �ʾ�����, �̵� ��ũ�� ���� �״� ������ �ۿ�� �����Ѵ�. Ž�� ������ ���� �� ��� ���·κ��� �����Ͽ� �ϳ� Ȥ�� �� �̻��� ���� ���¿��� ������ ��θ� ã�Ƴ���. ��Ģ��, ���� �������� ��� ������ �������� �����ϴ� ��� ��Ģ���� ����Ͽ� Ž�� ������ ������ ������, �̷��� �Ͽ� ���� ������ �ſ� ũ��, ���� ��ǻ� ������ ��� ��ΰ� Ž���Ǵ� ���� �ƴϰ�, ��κ��� ��δ� Ž���� �ʿ䵵 ���� ������, ������ ���������� ����� Ž���ϴ� ���, �־��� ��Ģ�� ����Ͽ� �Ͻ������� ������ ǥ���� �� Ž���� �κи��� ���������� ��Ÿ����. Ž�� ������ ������ ��, �Ͻ��� Ž�� ������ Ž�� ���α��� ���� ������ ������� ������ �κ� Ž�� �������� ���̸� �����ؾ� �Ѵ�.
Ž�� ����� ���� ���������� �����ϱ �ռ�, ��� Ž�� ���� �߿� ���ϴ� ���� �ټ� ������ �߿��� ���������� ���� ���� :
���� �ټ� ���� ������ �̷��� �������� �ٷ������.
���� ���� ������ ��� ���·κ��� ��ǥ ���·� ���� ��θ� ã�� ���� Ž�� ������ ��ǥ�̴�. �̷��� Ž���� ���� �� ���� �������� ������ �� �ִ�.
Ž�� ������ ���� �ý��� ���� ����Ͽ� ������ ������ ��Ī���� ������ ���� ����� ã�� �� �ִ�. Ư���� 8-������ ���� Ǫ�� ������ ���� ����. ������ Ǯ�� ���� ��Ģ�� �� 1 �� ���� �ְ�, �� ��Ģ�� ����Ͽ� �� 2 �� ������ ���� �߷����ε�, ���� �߷����ε� Ǯ �� �ִ�.
|
�� ���簢���� ������ ���� ���ڰ� �־����ٰ� ��������. |
||||
|
|
1 |
2 |
3 |
|
|
|
4 |
5 |
6 |
|
|
|
7 |
8 |
9 |
|
|
���簢�� 1 �� ��� �ְ�, ���簢�� 2 �� Ÿ�� n �� ������ �ִ�. �� ���簢�� 2 �� ��� �ְ�, ���簢�� 1 �� Ÿ�� n �� ������ �ִ�. ���簢�� 1 �� ��� �ְ�, ���簢�� 4 �� Ÿ�� n �� ������ �ִ�. �� ���簢�� 4 �� ��� �ְ�, ���簢�� 1 �� Ÿ�� n �� ������ �ִ�. ���簢�� 2 �� ��� �ְ�, ���簢�� 1 �� Ÿ�� n �� ������ �ִ�. �� ���簢�� 1 �� ��� �ְ� ���簢�� 2 �� Ÿ�� n �� ������ �ִ�. . . . |
||||
�� 1 8-������ Ǫ�� ��Ģ�� ��
|
��� ���� |
|
��ǥ ���� |
||||
|
2 |
8 |
3 |
|
1 |
2 |
3 |
|
1 |
6 |
4 |
|
8 |
|
4 |
|
7 |
|
5 |
|
7 |
6 |
5 |
�� 2 8-������ ��
���� �߷а� ���� �߷п��� ��� ������ ��Ģ�� ���ȴ�. ��Ģ�� ���� �߷п� ���� ���, ���ʸ� (���� ����) �� ���� ���¿� ��ġ�ϴ� ��Ģ�� ã��, ��ǥ ���¿� ������ ������ ���ο� ��带 ����� ���� �� ��Ģ�� �����ʸ� (���) �� ����Ѵ�. ���� �߷п� ���� ���, �����ʸ��� ���� ���¿� ��ġ�Ǵ� ��Ģ�� ���ʸ��� ���ο� ��带 ����� ���� ����Ѵ�. ������ ������� ���� �����ؾ� �� ���ο� ��ǥ ���¸� �ǹ��ϸ� ������ ���� ��ǥ ���� ���� �ϳ��� ��� ���¿� ��ġ�� ������ ������ ����Ѵ�.
8-������ ���, ���� �߷а� ���� �߷п� �״��� ū ���̰� ���� : �� ��� ��� ������ ���� ��θ� �����Ѵ�. ���� ��� ������ ���� �� �� ���� �ƴϸ�, ���� ������ ��ġ ������ ���� ���� �߷��� �� ȿ������ ���� Ȥ�� ���� �߷��� ȿ������ ���� �ִ�. ���� �� ������ ���ο� ���� �߷��� ������ �����ȴ� :
���� �� ���� ���� ����Ͽ� ���� �������� ������ �� ����. ���� ���� ��Ҹ� �����ϴ� ���� ã�� ������ ���� ����. ���� ��� ���������� ������ �� �ִ�. �����κ��� ���� ��ҷ� ���� �ͺ���, ���� ��ҿ��� ������ ���� ���� ȿ�����̴�. �� ������ ������ ����. �б� ����� ��� �ʿ��� �����ϵ��� ���� ����ϴ�. ���� ������ �����ϴ� ���� ã�� �� ���� ������ ���ֵǴ� ��Һ��� ������ ���ֵ� �� �ִ� ��Ұ� ���� ����. ��, ���� �װ��� �����ϴ� ���� �̹� �˰� �ִ� ��Ҵ� ������ ������ �� �ִ�. ���� ���� ���� ��Ҹ� �����ϴ� ���� ã�� �������� �� ��Ҹ� ã�⸸ �ϸ� ���� ������ �� �� �ִ�. �̰��� ���� ���� ��Ұ��� ���� ã�� ������ ��� ���� ��ҷκ��� ���� �߷��Ͽ� ���� ã�� ���� ȿ�����̶�� ���� �ǹ��Ѵ�.
�ݸ�, ���� ������ ���캸��. ���� ������ ���ĵ��� �����̸�, ��� ���нĵ� ���ԵǾ� �ִ�. ��� ���´� ���н��� �����ϰ� �ִ� Ư���� �����̸�, ���ϴ� ��ǥ ���¸� ó�� �İ� ��ġ�̸�, ��� ���нĵ� �������� �ʴ� �����̴�. �ϳ��� ��� ���¿� �ſ� ���� ������ ��ǥ ���¸� ������ ������ Ǯ�� �����Ѵ�. ���� �� ������ Ǯ�� ���ؼ���, ���н��� ���ԵǾ� ���� �ʴ� ������ �Ŀ��� ����Ͽ�, �̺� ������ �̿��� ���ϴ� Ư���� ���н��� ����� �ͺ���, ���нĿ��� ����Ͽ� ������ ���ԵǾ� ���� ���� ������ ���� �߷��ϴ� ���� ȿ�����̴�. ������ ���� ���� ��ǥ ���� �� �ϳ��� ��ǥ ���¸� ���� ������ ��, �� ���� �߷��� �ϴ� ���̴�. ���� �� ���� ���� ������� �б� ����� ���� ���� ��, ��� ���¿� ��ǥ ������ ������� ���� �߷��� ������ �����ϴµ� ��ġ�� �߿伺�� �����Ѵ�. ���� �б� ����� ������� ���� ��� �� ���� �߷� ������ �����ϴµ� �����Ǿ�� �Ѵ�.
������ ������ �����ϴ� ������ ���� ����. ��ǥ ���´� ������ �����̰�, ��� ���´� ������ ���� �����̴�. ��� ������ ���� ��ǥ ������ ���� ���� ����ϴ�. ���� �� �������� �߷��� ���� �б� ����� ���� ����. �� �� �ȵǴ� ������ ���� �������κ��� �̵��� �̿��Ͽ� �ſ� ���� ���� ������ ���� �� �ִ�. �ݸ�, �ſ� ���� �����κ��� �� �� �ȵǴ� ������ �̷���� �������� ���� �߷��� �� �ִ�. �����κ��� ������ ���� �߷��� ���� �б� ����� �����κ��� ���� �߷��� ���� �б� ������� �ξ� �۴�. �̷κ��� ������ ������ ���� ���� �߷��� ���� ȿ�������� �� �� �ִ�. ������ �����ϱ� ���� ��� �������ε� �߷��� �� ������, �տ��� ����� ���� ������ ���� �߷��� ����ϴ� �� ���� ��� (resolution) �� �ַ� ���ȴ�.
Ž���� ���� ������ �����ϴ� ����° ����, �� �߷� ������ ����ʿ� ���� �̰��� ���������� �����Ѱ��� ������ �ʿ䰡 �ִ����� ������ ���� ���� ����. �̰��� �ſ� �߿��� �۾��� �����ϴ� ���α��� ����� �����ؾ� ���� �����ϴµ� �߿��ϴ�. �ǻ�� �ڽ��� ������ ��ŭ ����� �߷��� ������ �� ���� ���� ���α��� ����� �Ƶ��� �� ����. �������� �����ϴ� ���α��� MYCIN �� �ۼ��� �� �� ������ �����Ǿ���. �� ���α��� ȯ���� ���� ���� ������ �����ϴ� ��ǥ ���·κ��� ���� �߷��Ѵ�. "���� ����ü�� ����ǿ��� ���� ����κ��� ������ ���� Ư���� �����ٸ�, �̰��� ����ü X �� Ȯ���� ����." ���� ���ϴ� ��Ģ�� ���� �߷��� ���� ���ȴ�. �� ��Ģ�� ����Ͽ� ���� �߷��Ͽ�, ���α��� "�װ��� ����ü X �� ���� ���θ� �����ϴµ� ������ �DZ� �����̴�" ��� ���� ���� "���� ����� �䱸�� ��Ʈ�� �����ϴ� ������ �����ΰ�?" �� ���� ������ ���� �� �ִ�.
�� �忡�� ���ǵ� ��κ��� Ž�� ����� ���� Ȥ�� ���� ��� ���̵��� Ž���� ���� ���� �� �ִ�. ���� ��Ģ�� ������ �����ϴ� ������ Ž���� �����Ѵٸ�, Ž�� ����� �����ϰ� Ư���� Ž�� �˰������� ���� ����� �� �ִ�. �̰Ϳ� ���� �� ���� ���ܴ� 3-6-7 ������ ������ ��� - ���� �м� ��� (means-ends analysis) �ε�, �̰��� �� �������θ� ��� �߷��ϴ� ���� �ƴ϶�, ���� ���¿� ��ǥ ���°��� ���̸� ���̴� �������� �߷��� �����ϴ� ������, �̸� ���� ���δ� ���� �߷��� ���δ� ���� �߷��� ���ȴ�.
�߷��� �� �ٸ� ����� ��� ���·κ����� ���� �߷а� ��ǥ ���·κ����� ���� �߷��� ���ÿ� �߷� ����� �߰� ��� �������� ���� ������ ��� �����ϴ� ���� ���� Ž�� (bidirectional search) �̴�. �̰��� �� ������ ��� ���� ���ݱ��� ���� ������ ���� ���� �Լ������� ������ �� ȿ�����̴�. �� 3 �� ���� ���� Ž���� ��ȿ������ ������ ��Ÿ����.
�� 3 �߸� ���� ���� ���� Ž���� ��
Ž�� ����� �����ϴ� ������ ����� Ʈ�� Ʈ������ (tree traversal) �̴�. �İ� ��带 ����� ���� Ʈ���� �� ������ ���Ǵ� ��Ģ�� ���� �����Ǵµ�, Ǯ�̸� ��Ÿ���� ��尡 �߰ߵ� ������ �� �� ������ �ٽ� ����, ��â�Ѵ�. �� 4 �� �� ������ ������ Ž�� Ʈ���� ��Ÿ����. �� ������ ���� �����ϰ� �����Ǹ�, ��� ���� ��, ���� ��Ȳ�� ��ϵ� ���� ���ʿ��ϴ�. ���� �� �������� �̹� �ѹ� �̻� ����� ��尡 �ٽ� ���� �� �ִ�. �̰��� ��ǻ� ���⼺ ������ Ž���ϴ� ���� ������ ������ Ʈ���� ó���߱� ������ ���Ѵ�.
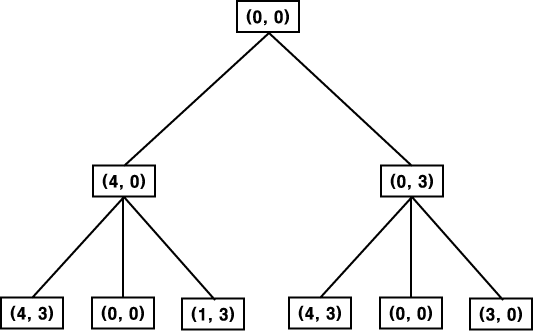
���� ���, �� 4 �� Ʈ������ �� �����ڿ��� 4 ������ ����, �ٸ� �ϳ����� 3 ������ ���� ��� ������ ��Ÿ���� ��� (4, 3) �� ���� 4 ���� ������ �� �����ڸ� ä�� ��, 3 ���� ������ �� �����ڸ� ä��ų� �� �ݴ��� ������ �� �����ڸ� ä�� �� �������. �� ������ ���, ���� ������ �߿����� �ʱ� ������ �� �� ��带 ��� ������ �ʿ䰡 ����. �� ���κ��� Ʈ���� ���� Ž�� ������ ������ �� ���ϴ� �� �ٸ� ������ �� �� �ִ�. ����° ������ ��� (0, 0) �� �ִ� (���, �̰��� �� �� ��Ÿ����). ���� �̰��� Ʈ���� ��Ʈ ���� ������ �����ν� �̹� ����, ��â�Ǿ���. �� ���� ��δ� ���ο� ���� Ȯ����� ���ϱ� ������, �̰͵��� ���ְ� ������ �ٸ� ��θ� ���� ������ ����ϸ� ȿ�����̴�.
�� 4 ���� �켱 Ž�� Ʈ���� �� ����

�� 5 �� ������ ������ Ž�� ����
������ ��尡 �ѹ� �̻� ������� �� �Ҹ�Ǵ� ����� ���� ������ ���� �۾��� ÷���Ͽ� ���� �� �ִ�. Ž�� Ʈ���� Ʈ�������ϴ� ��� ���⼺ ������ Ʈ������ �Ѵ�. �� ��尡 ���� ���� ��ο� ���Ե� �� �ִٴ� ������ ������ Ʈ���� �ٸ���. �� 4 �� Ʈ���� �����ϴ� ������ �� 5 �� �ִ�. ��尡 ������ ������ ����Ǵ� �۾��� �����Ͽ� Ʈ���� Ž�� �������� ��ȯ��ų �� �ִ�. ������ ��带 �ܼ��� ������ ÷���ϴ� ��� ������ ���� ���� �Ѵ� :
1. ���ο� ��尡 �̹� �����ϴ� �������� ���θ� ���� ���ݱ��� ������� ������ �����Ѵ�.
2. �������� �ʴ´ٸ�, ���� �� ���� ���� �����Ѵ� :
1) ������ Ȯ���ϴ� ���, �̹� �����ϴ� �İ� ��带 ����Ű���� �����Ͽ�, ���� ��������� ���� �����Ѵ�.
2) ���� �� ��忡 ���� ���� ��� (�ִ� �Ÿ� Ȥ�� �ּ� ���) �� ����ϰ� �ִٸ�, ���ο� ��ΰ� �̹� �����ϰ� �ִ� ��κ��� �� ������ Ȥ�� �� �������� �����Ѵ�. ���� �̹� �˰� �ִ� ��κ��� �� ���ڴٸ� �ƹ� �ϵ� ���� �ʴ´�. ���� �̹� �˰� �ִ� ��κ��� �� ���ٸ�, �� ���ο� ��θ� �� ��带 �����ϴ� �ùٸ� ��η� ����Ű��, ���� �ʿ��ϴٸ� �ش�Ǵ� ��� ������ ��ȭ�� �İ� ��带 ���Ͽ� �����Ѵ�.
���⼭ ���ϴ� �� ���� �������� Ž�� ������ ��Ÿ���� ����Ŭ (cycle) �̴�. ����Ŭ�� ������ �� �� �̻� ��Ÿ���� ��带 �����ϰ� �ִ� ����̴�. ���� ��� �� 5 ���� ���̰� 2 �� ����Ŭ�� �� �� ���ԵǾ� �ִ�. �ϳ��� ��� (0, 0) �� ��� (4, 0) ����, �ٸ� �ϳ��� ��� (0, 0) �� ��� (0, 3) ���� �ٷ���� ����̴�. ����Ŭ�� �����ϸ�, ����� ���̸� Ư���� �ϳ��� ������ ���� �� ���� ������ ���� Ʈ������ �˰������� ���Ḧ ������ �� ����.
Ʈ�� ��� ������ Ž�������ν� ���� ��θ� ���� �� ������ �� �Ҹ�Ǵ� ����� ������ �� ������ ������ Ž���� ���ؼ��� ������ ��������� �� ��忡 ���� �̹� �����ϴ����� ���θ� �����ؾ� �ϴ� �ΰ����� ����� �䱸�ȴ�. ������ ���� �� ����� �Ƶ鿩�� ���� Ȥ�� �Ƶ鿩���� ���� ���� �ִ�. ���� ������ ��尡 ���� �ٸ� ����� ���� ������� �� �ִٸ� ���� Ž�� ������ ����ϴ� ���� ���� ȿ�����̴�. ���� Ž�� ������ ����Ǵ� ������� ��� �������� ������� ���� ����� ������ �κ������� ��ȣ ��ȯ�� ������ ���� �ý����� ó���� �����ϴ�. ü������ Ž�� ������ �������� ���� �����κ��� ���� ��带 ���� �� ���� �� �ִ�. �̰��� ���� ������ �� ������ ���������� ���Ѵ�.
Ž�� ������ Ʈ���� ������ ���� �̵��ϴ� �������� �����Ǵµ�, �� ���� ���� ���� ������ �ϳ��� ������ ǥ��ȴ�. ���� � ������� ������ ��带 ��Ÿ�� ���ΰ�? ü���� ���, �迭�� ����Ͽ� ��带 ��Ÿ�� �� �ִ�. �̶� �迭�� �� ���Ҵ� �ش�Ǵ� ������� ��ġ�� �ִ� ��⸻�� ��Ÿ����. �� �ٸ� ����� ����Ʈ�� ����Ͽ� ��Ÿ���� ������� ����Ʈ�� �� ���Ҵ� �ش�Ǵ� ��⸻�� ��ġ�� ��Ÿ����. �� ������ ������ ��� �� ���� �� �����ڿ� ���� ��� �ִ� ���� ���� ��Ÿ���� ������ ������ (a, b) �� ����Ͽ� �� ��带 ǥ���� �� �ִ�.
���� ���� Ǯ���� �ϴ� ������ ���� �����ϴٸ� ��� ������ �Ͼ�ڴ°�? �κ�Ʈ ������ ���, �κ�Ʈ�� Ž�� ���� ������ �κ�Ʈ �����θ� �����̰ų� Ȥ�� �ٸ� ��ü�� �����̴� ��带 ǥ���ϴ� ����� ���� ���� ����. ���� ����� ���� ������ �о߿����� ǥ� ����� ������ �� ���� ���� �κ����� ������ �����ϴ� ���� ȿ�����̴� :
���� ���, ���� ��ü�� ������ �κ�Ʈ ������ ��� ������ ��ü ���¿� ��ü���� ���踦 ��Ÿ���� ����� ���� ǥ���� �� �ִ� ����� �ʿ��ϴ�. ON(plant, table), UNDER(table, window) �� IN(table, room) �� ������ �����Ͽ� ������ ���¸� ������ ����� �� �ִ� ����� ã��, �ſ� ȿ������ ����� ����Ͽ� �Ϸ��� ���¸� ǥ���� ����� ã�ƾ� �Ѵ�.
���� �� ���� ���� �� ó�� �� ������ ������ ǥ���� ������ �Ѵ�. ��� ������ ǥ���̶� ������ ������ ������ Ǯ�̸� ���� ���� ����� ����������, �������ϰ� ����� �� �ִ� ��� ������� ���ߵǾ���. �� ����� ���� �ϳ��� ���� ���� (predicate logic) �� ���ʷ� �� �����ν�, �� 5 �忡�� �ٷ������. �� �ٸ� ����� ������ ��ü�� �������� ǥ��ȴ�. �� 7 �忡�� �� ����� �Ұ��ȴ�.
����° ������ Ž�� �����鿡�� �� �� Ư�� �߿��ϴ�. �� ��尡 �� ��带 ��Ÿ���� ��� �͵��� ����Ʈ�� ǥ���ȴٰ� ��������. ��� �̰��� ������ ����̶� ������, �� ��忡 ���� ����� �ſ� �� ��� Ž�� ���� ���� ���� �Ͽ� ���� ���캸��. ��� ��忡 ���� �� ����� �� ���� ǥ���ؾ� �ϱ� ������ �� ���� ��� �Ҹ�� ���̴�. ������ �̷��� ��带 ����� ��ȭ�� ���� ���� ��κ��� ����� �� ��忡 �����ϱ� ���ؼ� ���� �ð��� �Ҹ�� ���̴�. ���� ��� �κ�Ʈ ��������, ��� ��忡 ABOVE(ceiling, floor) �� ����ϱ� ���� ���� �ð��� �Ҹ�� �� �ִ�. �̷��� ���� � ����� �� ��忡�� ��� �ٸ����� �˾ƾ� �ϴ� ���� ������ ���� ��ư� �����.
�ٲ��� ���� ��� �Ӹ� �ƴ϶� �ٲ� ����� ǥ���ϴ� �������� ������ ���� ���� (frame problem) �� �Ѵ�. ����� ��� ǥ���ϴ� ���� ������ ��εǴ� ������ �оߵ� ������ �ٲ� ����� ã�Ƴ��� ������ ����� ������ ��εǴ� ������ �оߵ� �ִ�. ���� ��� ������ �κ�Ʈ ��������, â�� �Ʒ� �����鼭 �� ���� ȭ���� ������ �ִ� Ź�ڰ� �ִٰ� ��������. ���� �߾����� Ź�ڸ� �Ű� ������ �Ѵ�. �̶� Ź�ڿ� �Բ� ȭ�е� ���� ���� �߾����� Ź�ڸ� �Ű� ������ �Ѵ�. �̶� Ź�ڿ� �Բ� ȭ�е� ���� ���� �߾����� �Ű�������, â���� ������ ��ġ�� ������ ������ �� �ִ�.
�ʱ� ������ ����κ��� �����Ͽ� ������ �����Կ� ���� ���ϴ� ��ȭ�� �� ������ ����� �ݿ���Ű�鼭 ��ȭ�� ������ ���¸� ǥ���Ѵٰ� ��������. �� ����� ����Ͽ� �� ��帶�� ������ �����ϱ� ���� ���õ� ������ �ð��� ���� �ذ��� �� �ִ�. ó������ ���� Ž���ؾ� �� ���� ���� ������ �� ����� �Ǹ��� �ۿ��Ѵ�. ���� ������� ��� ��ȭ���� ������ �� ���ٸ� (���� ��� ������� ��ȭ�� ������ ������ ÷�������� ���� ��ȭ�� ������ ���̶�� �� ��ȭ�� ������ �� �ִ�.) �̹� ������ Ž���� ��� ������ ���� �����ؾ� �Ѵ�. ���� ���� ������ ����� �̹� ������� ��ȭ�� ��������� ���� ��ó�� �ؾ� �Ѵٴ� ���� ��� �� �� �ְڴ°�? ���� ��� ���� �� ����� Ź�ڸ� �ű� ���� ��ȭ�� ��ġ �Ͼ�� ���� ��ó�� �ϱ� ���� ������ �����ؾ� �ϴ°�? �� ���� ����� ����Ͽ� �� ������ �ذ��Ѵ� :
������ ���� �ذ� ��������� ������� ���� �ִ�. ���� ��� �κ�Ʈ �������� Ź�ڴ� �Ű����� ���� â�� �Ʒ� �־�����, �Ű��� �Ŀ��� ���� �߾ӿ� ������ ����ؾ� �Ѵ�. �̰��� �� ����� ����� �� ��ǿ� ���̾��� ���� �˷� �ִ� Ư���� ǥ�ø� ÷�������ν� ó���ȴ�. �� ǥ�ø� ���� ���� (state variable) �� �Ѵ�.
����, ���� ������ ������ ���� ���� ����� ������ ���, ���� ��� ������ ���Ż��� ���忡 �ִ� ��� �ô븦 �˸��� ��ǵ��� �з��ؾ� �Ѵ�. �̷��� ������ Ư�� �κ�Ʈ �������� ���ϴ� ��ó�� ���ذ� �Ұ����� �������� �߿��ϰ� �����Ǿ�� �ϴµ�, �̰��� �� 8 �忡�� �ٷ���� ���̴�.
������ ǥ���̳� ���� ������ �����ϰ� Ǯ�̸� ���� �� �ִ� ������ ������ �ƴϸ� Ư���� ������ �������� ������ ó���ϴ� ���� ȿ�����̴�. ���� ������ ǥ���� Ž�� ������ ���� �ſ� ��ȣ �������̱� ������, �� �忡�� Ž�� ����� �����ϴ� ���� �� �� �������� �����ؾ� �Ѵ�.
Ǯ�̸� ���� ������, ������ ��Ģ�� ������ ���� ���¿� �����Ͽ� ���ο� ���¸� ����� ���� �������� ������ Ǯ�� ���� Ž�� �������� �����Ͽ���. ȿ������ Ž���� ���ؼ���, Ư���� ��쿡 ����� �� �ִ� ��Ģ�� ���� �� ������ �� �� �߿��� Ǯ�̷� �̲� ���ɼ��� ���� ���� ���� �����ϴ� ����� �ʿ��ϴ�. ���� ���ݱ��� �� ����� ���ؼ��� ������� �ʾҴ�. �̸� ���� ���� ���¿� ��Ģ�� ������, �� ���� ������ ���Ͽ� ��ġ�ϴ� ���� �����ؾ� �Ѵ�. ��Ģ�� ���� �� �ý��� (rule-based system) ���� �� ���� ����� �߿��� ��ġ�� �����Ѵ�. ���ȵ� �� ���� ������� �Ʒ����� �Ұ��Ѵ�.
������ �� �ִ� ��Ģ�� �����ϴ� �� ���� �����, ������ ���¿� ��Ģ�� ���� ������ �ϳ��� ���ϸ鼭 ������ ���¿� ��ġ�ϴ� ���� ������ ���� ��Ģ�� ��� ã�� ���� ����̴�. ���� �� ������ ������� �� ���� �������� �����Ѵ� :
���� ù��° ������ ���� ó���� �� �ִ� ����� �����ϴ� ��쵵 �ִ�. ��Ģ���� ��� �����ϴ� ���, ���� ���¸� ��Ģ�� �������� ����Ͽ�, �װͰ� ��� ��ġ�ϴ� ��Ģ�� �����Ѵ�. ���� ���, 2-1 ������ �Ұ��� ü���� ���� ��Ģ���� �ٽ� ���� ����. �� 6 �� �ٽ� �Ұ��Ǿ��µ�, ������ ��Ģ�� ��� ã�� ����, ������� ���¿� �ſ� ū ���� �������� �����Ѵ�. ȿ������ �ؽ� �Լ��� �̿��Ͽ� ���� ������ ������ ��Ģ�� ã�Ƴ� �� �ִ�. �־��� ������� ���¸� ��Ÿ���� ��� ��Ģ���� �ϳ��� ������ Ű�� ������ ����Ǿ� �ֱ� ������, �� ��� ��Ģ���� �Բ� �߰ߵȴ�. ���� �� ������ ����ȭ ����� ��Ģ�� ���� ������ ������� ���¿� ��Ȯ�� ��ġ�� ���� �ۿ��ϴ� ������ ������ �ִ�. ���� �̰Ϳ� ���� �� ���� ������ ���� ����������, �Ϲݼ��� �����ϴ�. 2-1 ������ ���ǵ� ��ó�� �� 7 ���� ������ ��ó�� �� �� �Ϲ����� ���·� ��Ģ�� ǥ���ϴ� ���� ȿ�����̴�. ���� ���� �Ǹ� ����ȭ ����� ����� �� ����. ��ǻ�, ��Ģ�� �Ϲ����� ���·� ǥ���ϴ� �Ͱ� �� ���� ������ �ܼ��ϰ� �ϴ� �� ���̿��� ��ȣ ��������� �ִ�.

�� 6 ü�� ���� �ùٸ� �̵�
|
���� ���� (i ��, 2 ��) �� ���� �� (i ��, 3 ��) �� ��� ���� �� (i ��, 4 ��) �� ��� ���� |
�� |
���� (i ��, 2 ��) ���� (i ��, 4 ��) ���� �̵��� |
�� 7 ü�� ���� �̵��� ǥ���ϴ� �� �ٸ� ���
���� �����, ��� �ִ� ������ ����Ͽ� ��Ģ�� ���� ������ ǥ���� ���, ����ȭ ����� ���� ����� �� ���ٴ� ���� �ǹ������� �ʴ´�. ���� ���, ���� ������ ���� ���� ��������, ������ ���Ե� ��� �ִ� ������ ��Ģ�� �������� ����Ͽ� Ư���� ����� �����ϱ ������ ��� ��Ģ�� ����� ���� ã�Ƴ� �� �ִ�. ü���� ���, ��⸻�� �װ��� ��ġ�� ��Ģ�� �������� �̿��� �� �ִ�. ����ȭ ����� �������� �ұ��ϰ�, ��Ģ�� ���� �� �ý����� ȿ������ ����� ���� �� ����� �߿��ϰ� ���ȴ�.
������, �����ϴٰ� �����ϴ� ��� �� ��Ģ�� ���� �����ϴ� ������� ���� ��Ģ �߿��� ���� ������ ���� �����ϴ� ����� ��ȿ������ ��찡 �ִ�. Ư���� ��Ģ�� �־��� ���� ���¸� ���Ͽ� �� ��Ģ�� ���� ������ �����ϴ��� �����ϴ� ���� ����� ������ �ƴϴ�. ���� ������ Ư���� ��Ȳ���� ��Ȯ�ϰ� ������� �ʰ�, ��Ȳ�� ������ �� ������ ����� ���, ����ȭ ��������� ���� ������ ���Ѵ�. Ư���� ��Ȳ�� �־��� ��Ģ�� ���� ���ǰ� ��ġ�ϴ��� �����ϱ� ���ؼ��� �߿��� Ž�� ������ �䱸�ȴ�.
|
SON (Mary, John) SON (John, Bill) SON (Bill, Tom) SON (Bill, Joe) DAUGHTER (John, Sue) DAUGHTER (Sue, Judy) |
�� 8 ���� ��Ȳ�� ���� �ʱ� ������ ��
|
1 SON (x, y) �� SON (y, z) �� GRANDSON (x, z) 2 DAUGHTER (x, y) �� SON (y, z) �� GRANDSON (x, z) 3 SON (x, y) �� DAUGHTER (y, z) �� GRANDDAUGHTER (x, z) |
�� 9 ���� ��Ȳ�� �߷��ϱ� ���� ��Ģ
������ ������ �����ϰ� ���� ���, ������ ��ġ��Ű�� ���ؼ� ������ Ž���� �����ؾ� �Ѵ�. ���� ��� "�� (John) �� ���ڴ� �����ΰ�?" ��� ������ ���� ã�� ����. �̸� Ǯ�� ���� �� 8 �� ������ ������ ���̽��� �� 9 �� �ִ� ��Ģ���� ����Ѵ�. �ʱ� ���´� �� ������ ���̽��̸�, ��ǥ ���´� �ʱ� ���¿��� �־��� ��� �Ӹ� �ƴ϶� ���� ���ڰ� ���������� �˷� �ִ� ����� �����ϰ� �ִ� ������ ���̽��̴�. X �� ���� ���谡 �ִٸ�, ��Ģ 1 �� ��Ģ 2 �� ����Ͽ� �� ����� �˸���. ���� ��Ģ 1 �� ���� ���� ������ �����ϴ��� �����ϱ� ���ؼ���, Ư���� � Z �� ���� ���� SON (John, y) �� SON (y, z) �� �����ϴ� y �� �ϳ� ã�ƾ� �Ѵ�. �̸� ����, ��� �����ϰ� �ִ� ���� ���� �ϳ��� ������Ű�� y �� ã��, �װ��� �ٸ� �ϳ��� ������Ű���� �����ؾ� �Ѵ�. �̴� ���� �Ƶ��� ��� ã�� �� �̵� �� ���� �Ƶ��� ������ �ִ��� �����ϰų�, �Ƶ��� ���� ����� ��� ã��, �̵� �� ���� ���� �Ƶ������� ���������ν� �ذ�� �� �ִ�. �� ���, ���� ���� �Ƶ�κ��� �����Ͽ� �̵� �� ���� �Ƶ��� �������� �����Ѵٸ�, ���ʿ��ϰ� ���� ���ɼ��� �������� �ʾƵ� ������, ��� �����ϰ� �ִ� ������ �� ��� ���� ���� �����ؾ� �ϴ����� �� �̸� �� �� �ִ� ���� �ƴϴ�. ������, ��� �����ϰ� �ִ� �� ������ ������Ű�� ���� �ſ� ũ����, �̵� ��θ� ������Ű�� ���� ���� ���� ��찡 �ִ�.
���� ���� ������ ��ġ��ų �� ���ϴ� �� ���� �������� ������ �ش�. ù��° �������� ���ϰ� ������ ������� ��ġ�� �߰ߵǾ��ٴ� �� �Ӹ� �ƴ϶�, ������ ����� ��ġ�ϴ� ������ ã�� �������� ����� ���ε��� ����Ͽ�, ��Ģ�� ������ ���� �� ���ε��� ���ǵ��� �ؾ� �ϴ� ���̴�. ���� ������ ���Ͽ� ��ġ�ϴ� ���� ã�� �������� ���� ����, �� ��Ģ 1 �� ���� ������ x �� ����, y �� ���� ���� z �� ���� ���ε��� �� �����ȴٴ� ������ ��Ģ�� �����ϴ� ������ �����Ͽ�, ��Ģ�� ������ �� GRANDSON(x, z) �κ��� GRANDSON(John, Tom) �� �� �� �ֵ��� �Ѵ�.
�ι�° �������� �ϳ��� ��Ģ�� �� ���� �̻��� ������� ������ ���¿� ��ġ�Ǿ� ���� �ٸ� �������� ���� �� ������� �� �մٴ� ���̴�. ���� ������, ��Ģ 1 �� z �� ��� ���� ������ �� �ִµ�, z �� ���� �����ص�, �Ǵ� z �� ���� �����ص� ��� �ظ� ���� �� �ִ�. ���� ���� �̷��� ���°� Ǯ�̸� ��� ����� �߰� �ܰ迡�� ��Ÿ���ٸ�, ���� ��� �����ڸ� ã�� ������ ���� Ǯ�� ����� �߰� �ܰ迡 ��Ÿ���ٸ�, ��� ���ε��� ���� ȿ�������� �����ϰ� ��� �� �� ���� ������ �ִ�. ���� �־��� ������ �İ� ���°� �� �� �ִ� ������ ���� ����� ��Ģ�� ���� ���� �����Ǵ� ���� �ƴ϶� ��Ģ�� �����ϴ� ����� ���� ���� �����Ǵ� ������ �����ؾ� �Ѵ�.
��Ģ�� ���� ������ ���� ���¸� ������ ������� �ʰ� ��� �ʿ��� �������� �����ϴ� ��쿡, �� �� ������ �� ���� ������ �ʿ��ϴ�. �� ���, �Ϻ� ������ ������ �ٸ� �����κ��� ���ߵǴ� ����� ��Ÿ���� ���ؼ���, �������� ��Ģ�� ������ ���Ǿ�߸� �Ѵ�.
��Ģ�� ���� ������ ���� ���¿� �ٻ������� ��ġ ��Ű�� ���ؼ��� ������ �� ���� ������ �ʿ��ϴ� �̰��� ����, ���� ��Ȱ���� �Ͼ�� ��Ȳ�� ����� �� ���Ѵ�. ���� ���, ǥ��� �������� �ĵ����κ��� �̿� �����ϴ� ������ ���� ���� ���� ���α� (speech-understanding program) ������ �ٻ������� ��ġ�Ǵ� ��Ģ�� ����Ѵ�. ���������� �� ��, ������ ���� ������, �������� ��ȣ�� ������ �� �ְ�, ���� ���θ��� �����ϴ� ����� ���̰� �ֱ� ������, �̻����� ������ ��Ÿ���� ��Ģ�� ���� ����κ��� ������ �Է°� �ٻ������� ��ġ�� ���ۿ� ����. �̷��� ���, ��ġ��ų �� �ʿ��� ���� ������ ������ ��ȭ��Ŵ�� ���� ��ġ�� �� �ִ� ��Ģ�� ���� �����Ͽ�, ��������� �ֵ� Ž�� ������ ũ�Ⱑ �����ϱ� �빮��, �ٻ����� �� ������ ó���� Ư�� ��ƴ�. ��Ȯ�� �� ���� ����� �̿��� �� ��� ��Ģ�� ��ġ���� �ʾ�, Ž�� ������ ����� ���� ���ϰ� �ߴܵǾ�� �ϴ� ��Ȳ���� �ٻ����� �� ���� ����� ȿ�������� �ۿ��Ѵ�.
�Ϻ� ������ ���, ���� ��� ������ ���̰� ��Ģ�� ���� ���¿� ��ġ�� �� ���Ѵ�. �ϴ� ������ ���̰� �Ͼ��, ��Ģ�� ���� �������� �ʰ��� ������ Ž�� ������ ���� ������ �� �ִ�. ���� ���, �̰��� ELIZA ���� ���ϴµ�, Rogerian ġ�� ������ �ൿ�� �ùķ��̼��ϴ� �ΰ� ���� ���α��̴�. ELIZA �� ����� ���� ��ȭ�� �� ���� �� 10 �� �Ұ��Ǿ���. ����� �ɸ��п� ���� ELIZA �� ������ ������ ��Ģ��� �ڵ�ȭ �� �� �ִµ�, �� ��Ģ���� ���� �� 9-4 �� ��������. ELIZA �� ������� ������ ����� �������� ��ġ�ϴ� ��Ģ�� ã�� �� ��Ģ�� �������� ����Ͽ� ������ �����Ѵ�. ��Ģ���� �ٽ��� �Ǵ� �ܾ ���� ����ȭ �Ǿ� �ֱ� ������ ��ǻ� �Ҽ��� ��Ģ���� Ư���� ����� ��ġ�ȴ�. �������� ���� ��Ģ�� ��� �������� ����� �� �ִ�. ������ ���°� �ٸ� � ��Ģ���� ��ġ���� ���� �� �� ��Ģ�� ����Ͽ�, "������ �װͿ� ���� ���� �ֽÿ�" �� ���� ������ �����. �� ���, �ٻ����� �� ������ ���°� ��Ģ ��ü�� ���ؼ��� ���� �� ������ �����ؾ� �Ѵ�. ������ ���峻���� Ư���� �ܾ �̿��ϱ� ������ ��ü ����� ��ġ�� �ʿ�� ����. ���� �ϳ��� ��Ģ�� ���� ���� ���� ������� �� ��ġ�� �� �ִµ�, �̶� ���� ������ �������� ���⼺�� �����Ѵ�. �̰��� ELIZA �� ������ ����, �� ���� ��κ� �ո����� ������ �� �� �ִ� �ɷ»Ӹ� �ƴ϶�, �ſ� �������� ����, �� �ǻ����� ���ؿ� ������ ������ ������ �� �� �ִ� �ɷµ� ���� ������ �ش�. �ٻ��� �� ���� ����� ����� ��� ���� �� ���� ����� ��� ���� ���� �� �ִ�.
|
Men are all alike. IN WHAT WAY They're always bugging us about something or other. CAN YOU THINK OF A SPECIFIC EXAMPLE Well, my boyfriend made me come here. YOUR BOYFRIEND MADE YOU COME HERE He says I'm depressed much of the time. I AM SORRY TO HEAR YOU ARE DEPRESSED It's true. I am unhappy. DO YOU THINK COMING HERE WILL HELP YOU NOT TO BE UNHAPPY I need some help, that much seems certain. WHAT WOULD IT MEAN TO YOU IF YOU GOT SOME HELP Perhaps I could learn to get along with my mother. TELL ME MORE ABOUT YOUR FAMILY . . . |
�� 10 ELIZA �� ����� ���� ��ȭ
�� ���� ������ �״��� �������� ���� ��ó�� �����Ͽ�, �� ������ ��� ���� ���� (frame problem) �� ���� ����. ���� ������ ó���ϴ� ����� �� ��帶��, ���¿� ���� ����� ��� ������� �ʴ� ��� ���� ���κ����� ��ȭ���� ����ϴ� ���̴�. ���� �̷��� �Ѵٸ� ���ϴ� ��带 ã�� ������, �� ���κ��� �װ��� ���� ��带 ���� �����ϸ鼭 ��ġ�Ǵ� ���� ã�ƾ� �Ѵ�.
�� ���� ������ ���, �������� ���� ���¿� ��ġ�ϴ� ��Ģ���� ����� �������. Ž�� ����� ��Ģ�� ����Ǵ� ������ �����ϴ� �۾��� �ϴµ�, �� �۾��� �� ���ð������� �Բ� ó���� �� �ִ�. �� ���� ���� �� �� �ܰ踦 �浹 �ذ��� �ܰ�� �Ѵ�.
���� ���, �ý����� �Ϻ� ��Ģ�� ������ �ٸ� ��Ģ�� ���� ��Ÿ���� ��Ȳ�� Ư���� ��츦 ó���Ѵٰ� ��������. �̷��� Ư������ �� ��Ģ�� �Ϲݼ��� �� ��Ģ���� ���� �켱 ������ ������ �ִ�. �� ������ ������ �ٽ� ���� ����. �� �������� ��ǥ ���°� ������ ���� �ϳ��� n ������ ���� ��� �ٸ� �ϳ��� �� �����ڿ� n ������ ���� �Ű� �״� ���̶�� �Ѵٸ�, �� 2-3 �� ��Ģ�� ���� �� ���� ��Ģ�� ÷���ؾ� �Ѵ� :
11 (0, 2) �� (2, 0) 2 ������ ���� 4 ���� ���� �� �����ڿ� �Ű� �״´�.
12 (x, 2 + x > 0) �� (0, 2) 4 ���� ���� �����ڸ� ����.
�� ���ο� ��Ģ�� ������ ��Ģ���� Ư���� ����̴�. (0, 2) �� (X, Y | Y > 0) ���� ���� ������ �����̴� [��Ģ 6 �� ���� ����]. �̿� ���� Ư���� ��Ģ�� ����ϴ� ������ ���� ���� Ǯ���ڷ� �Ͽ��� Ž�� ������ �������� �ʰ� ���� ������ Ǯ�� ���� �̷��� ������ ������ �̿��ϵ��� �ϱ� ���ؼ��̴�. ���� ��ġ�� ��Ģ�� ã�� ���� �̿� ������ ��Ģ�� ��� �����ϴ� ����� ����Ѵٸ�, Ư�� �뵵�� ��Ģ�� ÷�������ν� Ž���� ����ȭ��Ű�� ���ٴ� Ž���� ������ �ʷ��Ѵ�. �̷��� ��Ȳ�� �����ϱ� ����, �Ϲݼ��� �ִ� ��Ģ�� Ư������ �ִ� ��Ģ�� �����Ͽ�, Ư������ �ִ� ��Ģ�� ���ϴ� �� ���� ������ ���ȴ�. �� ���� �������� �� ��Ģ�� �ٸ� ��Ģ���� ���� �Ϲݼ��� ���ٴ� ���� �����ϱ� ���� ������ ���� ������ �� ���� ����� ���ȴ� :
�� ���� ������ Ž�� ����� �ΰ��� ���� ���� �ִ� �� �ϳ��� ����� �� ���õ� ����� �߿伺�� ���� �װ͵鿡 ������ ���� �ִ� ���̴�. ����� ���� ���� ����� �ִ�. ������ ���� ��Ģ�� ã�� ���� ������� ����� ������ ��ġ��Ű�� ELIZA �� ���� ����. �Էµ� ���忡�� ELIZA �� �˰� �ִ� �ٽ� �ܾ ���� �� ���ԵǾ� ���� �� �մ�. ���� ���ٸ�, ELIZA �� �ٽ� �ܾ��� �߿伺�� ���� ������ ����Ͽ� ������ �ٽ� �ܾ �����Ѵ�. ���� �� ���� ������ ���� ���� �켱 ������ ���� �ٽ� �ܾ ã�Ƴ���.
�켱 ������ �ִ� �� ������ �� �ٸ� ���´� ���� ���¿� ��ġ�� �� �ִ� ���� ��ġ�� ���� �Լ��� ��Ÿ�� �� �ִ�. ���� ��� �ΰ��� �ܱⰣ�� ��� (human short-term memory : STM) �� �ൿ�� ���� ������ ������� �� ��, STM �� ���� ����� ��ġ�ϴ� ��Ģ�� �ܺο� ����� ����ϰų�, ��Ⱓ�� �� ������ ��Ͻ�Ű�� ���� ���ȴ�. �� ���� ������ ���� �ֱٿ� STM �� ���� �Է°� ��ġ�ϴ� ��Ģ�� ã���� �ϰ�, ���� ��ġ�ϴ� ��Ģ�� ã�� ���ϸ�, ������ STM �� ���� �Է°� ��ġ�ϴ� ��Ģ�� ã�´�.
�� ���� ������ Ž�� ������ ������ ���� �� �� ���� ��ȣ �ۿ��ϴ� ����� �����ȴ�. ���� ������ ����� ��Ȳ�� ���, �� ���� ������ �װ��� �⺻���� �۾��� �����ϴ� �������� Ž�� ������ ���� ������ �� �̿��� �� �ִµ�, �̸� ���� ������ ��ȣ ��ȯ�ϴ� ���� ����.
��Ģ�� ���� �� �ý��ۿ��� �� ���� ������ �������� �ʴٸ� ���� ���� Ž���� �䱸�ȴ�. ���� Ǯ���� �ʱ� �ܰ迡�� ���� �� �ִ� Ž�� ������ �� ���� ���������� �����ϰ� ���� �� �ִ�. ����, ���������δ� Ž���� ��ȯ���� ����� �������� �� ���� ���� ������ �����߸� �Ѵ�.
2-1-2 ������ ������ ����� ��� ���� �������� ���� Ǯ�� ������ ������ �� ������, ������ ���� Ǯ�̸� �߰��ϴµ� ������ �Ǵ� ������� ���ǵǾ����� �Ϲ������� ����� �� �ִ� ������ ����� Ư���� ������ Ǯ�̿� ������ Ư���� ������ ��Ÿ���� ������ ����� �ִ�. 6 ������ ������ ���� Ǯ�� ����� ���� ������ ��������� �־��� Ư���� �о߿� ���õ� ������ Ư�� �뵵�� ������ ����� �Բ� ���Ǿ�, Ư�� �о߿��� ����� �� �ִ�.
���� �� ���� ����� ����Ͽ� ���� Ư���� ���� ������ ����� ������, ��Ģ�� ���� �� Ž�� ������ ������ �� �ִ�.
������ ����� ���Ǵ� �� �Լ��� ������ ���¿� ���� ����� �� ������ �������� �ǹ��ϴ� ���� ����Ѵ�. Ž�� ������ ��Ÿ���� �� ��忡 ����, �� ��尡 Ǯ�̸� �̲��� ��λ� ���� Ȯ���� ����ġ�� �ִ� ������ ����� ���Ǵ� �� �Լ��� ����Ͽ� ���� ������ � ���� �����ؾ� ����, ���� �̰��� ��ġ�� ��� ������ �� �̰Ϳ� �־��� ���߰��� ���� �� �ִ�.
�� ������� ������ ����� ���Ǵ� �� �Լ��� ȿ�������� Ž�� ������ Ǯ�̷� �����ϴ� �߿��� ������ �Ѵ�. ����� ���ռ� ���ο� ���� �������� ����� �� ��, �ſ� ������ �� �Լ��� ����ص� ����� ���� �������� ���� �� �ִ� ��쵵 ������ �� �� ������ �� �Լ��� ����ؾ� �� ��쵵 �ִ�. �� 11 �� �� ���� ������ ���� ���, ������ ����� ���Ǵ� ������ �� �Լ��� �Ұ��Ͽ���. �� �Լ��� ���� Ŭ���� ȿ������ ��� (��, ü��, 8-����, ������) �� �ְ�, �� �Լ��� ���� �������� ������ ��� (��, ������ ���� �湮 ����) �� ������ �����϶�. �Ϲ������� �Լ��� ����ϴ� ����� �߿����� ������, �Լ����� ����ϴ� ���α��� ��쿡 ���� �Լ����� �ּ�ȭ�� �õ��� ���� �ְ�, �Լ����� �ִ�ȭ�� �õ��� ���� �ִ�.
|
ü�� 8-���� ������ ���� �湮 ���� ��� ���� |
���� ���� �ڱ� ���� ���� ������ ������ �� �ùٸ� ��ġ�� �ִ� Ÿ�ϵ��� �� �湮�� �Ÿ��� ��
�̱� �� �հ�, �̹� �ϳ��� ���� �ִ� � �� ���� ���� ��쿡�� ���ϱ� 2 |
�� 11 ������ ����� ���Ǵ� ������ �� �Լ����� ��
������ ����� ���Ǵ� �� �Լ��� ������, �̿� ������ ��ΰ� �� �� �̻� ������ ��, ���� ������ ��θ� ������ �����ν�, Ž�� ������ ���� ȿ������ �������� �����ϴ� ���̴�. ������ ����� ���Ǵ� �� �Լ��� Ž�� Ʈ�� (Ȥ�� ����) ���� �� ����� ��ġ�� ��Ȯ�� ���ϸ� �Ҽ��� Ǯ�� ������ ���� �� ����������. �ش������� ������ ����� ���Ǵ� �� �Լ��� �� �ۼ��ϸ� � Ž���� �������� �ʰ� ���� Ǯ�̸� ã�� ���� �ִ�. ���� ���� ������ ���, ���� �� �Լ��� ���ϴµ� �ҿ�Ǵ� ����� Ž�� �������� ������ ����� �ɰ��� �� �ֱ� ������, �ᱹ Ǯ���� �ϴ� ���κ��� ������ Ž���� �����Ͽ�, �װ��� ������ Ǯ�̸� ������ �� ������ ���������ν�, ������ �� �Լ��� ����� �� �ִ�. �Ϲ������� ������ ����� ���Ǵ� �� �Լ����� ��꿡 �ҿ�Ǵ� ���� �� �� �Լ��� ���� ����� Ž�� �ð��� ������ ���� ��������� ������ �ִ�.
������ ����� ���Ǵ� �� �Լ��� �⺻���� Ž�� ������� �����ϴ� ������ �� Ž�� ����� �Ұ��� �� ���ǵ� ���̴�.
������ Ž�� ����� ����� ������ ���� Ǯ�̸� ���� �� �ִ� �ſ� ������ ����̴�. �̷��� Ž���� �����ϱ� ���� ���Ǵ� ����� Ư���� ������ Ǯ �� �� Ž�� ����̶� �Ҹ���� ������ ���� ���� ���� ����� �Ұ��Ѵ�.
Ư���� ������ ���� ���� ����� ������ �� �忡�� ������ ������ Ư���� ���� �����ȴ�. �� ���� ���ο��� ������ ��ó�� ��� Ž�� ������ ���� ������ Ʈ�����ȷ� �����ȴ�. ������ ���� ������ ������ ������ OR �����̴�. �� ������ ������ Ǯ�� ����� ��Ÿ���� OR ������ �� 5 �� �Ұ��Ǿ���. �� ��忡 ����, �� ��尡 ��Ÿ���� ���·κ��� ������� �� �ִ� ���� �������� ��Ÿ���� ��ũ�� ���� �� �ִµ�, �� ��ũ�� ���� ����� ��带 ��ũ�� ���۵Ǵ� ����� �İ� ���� �θ���. ������ Ǯ�̸� ã�� ����, ���� �� �ʱ� ���¸� ��Ÿ���� ���κ��� ����Ͽ�, ��ǥ ���¸� ��Ÿ���� ��带 ã�� ������, �� ����� �İ� ��带 ���鼭 Ǯ���� ��θ� ã�´�. ������ ������ �� �� ó�� �ټ� ���� ���� OR ������ Ʈ������ ����� �����Ѵ�.
���� �Ϻ� ������ ���, �ϳ��� ��ũ�� ���� �İ� ��带 �����ϴ� ������ ����Ͽ� Ǯ�̸� ã�� ���� ȿ�����ε�, �̷��� ������ AND-OR ������ �ϸ�, Ž�� �˰������� �Ұ��� (6) ������ ���ǵ� ���̴�.
������ ����̶�� ���� ����� ����� ������ Ǫ�� ���� ��ġ���� �ƴ��� �����ؾ� �Ѵ�. ���� �� ����� �־��� ������ ���� �ʿ��� Ư���� ������ ����ȭ�ϰ� �̿��� �� �ִ� ��Ʋ�� ����� �ش�.
�ش��� ������ ��Ʈ ����� �ŷе� ���� ������ ������ν�, �̰��� ���� ������ ������ ���� :
ü������ ����� ����Ͽ� ������ �ش��� ����ٸ�, �ش��� ������ ���, �� ������ ���� �ݵ�� �ش��� ���� �� �ִ�. ���� �־��� ������ �ſ� ū ������ ���, �̰��� �����ϱ� ���ؼ��� �� �ð��� �䱸�� ���̴�.
�ش��� ������ ��Ʈ �˰������� ���� �켱 Ž���� �����̸�, �� ����� ü������ ���¿����� ���� ������ ��� Ž���Ѵ�. ���� �ش��� ���Ƿ� ����� ���鼭 �ش��� ������ ��Ʈ ����� ������ �� ������, �̷��� �ϸ� Ǯ�̸� ã�� ���� ��쵵 ���Ѵ�. �̿� ���� ���� �뿵 �ڹ��� �˰������� �˷��� �ִ�. �� �˰������� ���캸��. ���� �����̵鿡�� Ÿ�ڱ⸦ �־� ������� �ε帮�� �ϸ� �̷κ��� ���� ������ ������ �������� �ڹ����� ����� ��� å���� ����� ��ġ�� ��찡 ���Ѵ�. ü�������� Ž�� ������ �����ϴ� ���� ���迡���� Ǯ�̷� �̲� ���ɼ��� ���� ��δ� Ž������ �ʴµ�, �� ���ɼ��� �� 5 ������ ���ǵ� �� �Լ��� ���� ��������.
������ ���� ���� �켱 Ž�� Ʈ���� ����Ͽ� ü������ �ش��� ������ ��Ʈ ����� ���� ������ �� �ִ�. ���� Ʈ���� Ž���ϴ� �������� ���� �� ��Ÿ���� ���°� �����Ѵٸ�, ������ �Ұ��� ������ ������ Ž���ϱ �����ϵ��� �����ϴ� ���� ���� ȿ�����̴�.
������ ������ ���, �ش��� ������ ��Ʈ ����� ����Ͽ� ���� ������ ��� �����ϴ� �͵� �ո����� ����̴�. ���� ��� �� ���� ������ü�� �̷���� ������ �����غ���. �̶� ������ü�� �� ���� �� ���� ���� ���� �ϳ��� ĥ���� �ִ�. ������ü�� �ϳ��� ���� �迭�ϴµ�, �� ���� �� �鿡 �� ������ ��� ���������� ������ü�� �迭�ϰ��� �Ѵ�. ��� ���ɼ��� ü�������� ��� ���������ν� �� �迭�� ã�Ƴ� �� �ִ�. �̰��� ���� ������ �ش��� ������ ��Ʈ ����� ����Ͽ� ���� ã�Ƴ� �� �ִ�. �� ���� ���ڸ� �� �ٷ� �þ� ���� ��, ���� ���, ���� ���� �ٸ� ������ �麸�� ���ٰ� ����. ���� ���� ���� ���� ���ڸ� ���� �� ���̴� �ʿ� ������ �� �� ���� ����� ��Ÿ���� �ʵ��� ���� ������ ��� ���ϰ� �ϴ� ���� ȿ�����̴�.
����, �̺��� ����� ������ ���, ������ �ش��� ������ ��Ʈ ����� ��ȿ������ ��������� Ž���� ������ �����ϴ� �ٸ� ����� �Բ� ����ϸ�, �ſ� ȿ������ �� �ִ�. ���� ��� ���ݱ��� �ۼ��� ���� �������� �ΰ� ���� ���α��� �ϳ��� DENDRAL �μ� ���� ����Ʈ���� �� �ڱ� ���� (Nuclear Magnetic Resonance : NMR) �ڷḦ ����Ͽ�, ����ü�� ���� ������ �߷��ϴ� ���α��̴�. �̰��� ��ȹ (planning) �� ���� �ش��� ������ ��Ʈ�� �Ҹ���� ����� ����ϴµ�, �� ������� ���� ������ ���� ����� ����ϴ� ��ȹ ������ ���� ������ ������ ������ ����� �����. �ش��� ������ ��Ʈ ����� ����� ���ѵ� �����鸸�� �����ϱ� ���� �� ����� ����Ѵ�.
��ȹ ����� �ش��� ������ ��Ʈ ����� �����Ͽ� ����ϴ� ��ó��, ���� �ٸ� ���� Ǯ�� ������� �����Ͽ� ���� Ǯ�� ����� �Ѱ輺�� �غ��� �� �ִ�. ��ȹ ����� ���� ū ������ �ǵ���� �Ұ����ϱ� ������, �ټ� ����Ȯ�� �ظ� ���� �� �ִٴ� ���̴�. ���� �ش��� ������ ��Ʈ ������� ����� Ǯ���� ����� ����µ� �̰��� �̿��Ѵٸ�, ����Ȯ�ϴٴ� ������ �����õ��� �ʴ´�. ���� ������ �ش��� ������ ��Ʈ ������� ���ϴ� ���� �ð��� ���� ������ ������ ��ȹ�� ����Ͽ� ���� �� �ִ�.
��� ������ ����� Ž�� ���� ������ ������ ������ �����ϱ� ���� �ǵ���� ����� �ش��� ������ ��Ʈ ����� �� �����̴�. ������ �ش��� ������ ��Ʈ ������� ��Ʈ �Լ��� ��, �ƴϿ��� ���丸�� ������, �̰��� �־��� ���°� ��ǥ ���¿� �� ��������� ������ �� �ִ� ������ ����� ���Ǵ� �� �Լ��� �����Ͽ� �Ʒ� �������� ������ ��ó�� ����� �� �ִ�. �� ����� Ǯ�̿� ���� ���簡 ����ʰ� ���ÿ� ������ ����� ���Ǵ� �� �Լ��� ����� ����� �� �ֱ� ������ �ſ� ȿ�����̴�. ��� ������ ����� ���ν����� ������ ���� :
1. �ش��� ������ ��Ʈ ��������� ���� ������� ó������ ���Ƿ� �ش��� ������. �̷��� ������� �ش��� �־��� ������ �´� ���ϴ� �ش��̸� �ߴ��ϰ�, �ƴϸ� ���� ������ ��� �����϶�.
2. �� �ش信 ������ ��Ģ�� �����Ͽ� ���ο� �ش��� ������. ���� ���� ���ο� �ش��� ������� �� �ִ�.
3. ���� ������� ������ �ش信 ���� ������ �����϶�.
1) ��Ʈ �Լ��� ������ ���� �ش��� �־�, ���� ���ϴ� �ش��̶�� �ߴ��϶�.
2) ���ϴ� �ش��� �ƴ϶��, ����� �ش� �߿��� ���� ���� �ش�� ���� ����� ���� �����ϴ��� �����϶�. ���� �����Ѵٸ� �� �ش��� ����ϰ� ���� ������ �����϶�.
4. ������ ã�� ������ �ش��� ���� ������ ���ȵ� �ش����� ����϶�. �� �ܰ�� ���� ���� ��ǥ�� ������ ���ɼ��� ���� �������� ���� ������ Ž���� �ϴ� �ܰ��̴�.
5. �ܰ� 2 �� ���ư���.
�� ���� ���ڷ� �̷���� ���� ������ �ٽ� ���� ��� ��� ������ ������ �ۿ� ����� ���� ����. �� ������ Ǯ�� ����, ���� ������ Ư���� ��ġ�� ������ �ش�� �� ��������� ��Ÿ���� �� �Լ��� �����ؾ� �Ѵ�. �� ���� ������ �ִ� ���� �ٸ� ���� ���� ������ ������ ����� ���Ǵ� �� �Լ��� ������ �� �ִ�. �� ���� ���� Ǯ�̿����� �� �Լ��� 16 �� ���� ���� ���̴�. ������ ������ ��ġ�� ������Ű�� ����� ���ϴ� ��Ģ�� �����ؾ� �ϴµ�, ��ǻ� �� ���������� �ϳ��� ��Ģ���� ����ϴ�. �� ��Ģ�� ���� �ϳ��� �����Ͽ� ��� �� �������� 90° ȸ����Ű�� ���̴�. �̰��� ���ǵǸ�, ���� �ܰ�� �ʱ� ��ġ�� ����� �����ν�, ���Ƿ� ���� ���� �ְ�, �� ������ ��� ������ ����� ���Ǵ� �� �Լ��� �̿��Ͽ� ���� ���� �ִ�. ���ݺ��� ��� �����⸦ ������ ����. �� ���� ���� ��θ� ������ �������� ȸ����Ű�鼭, ���ϴ� Ǯ�̿� ���� ����� ��ġ�� ã�´�. ���� �� ����� ����� ��� �� �ܰ踶�� �ſ� ���� ��Ʈ�� ������ �䱸������, ��ǻ� ��� ������ �������� ��� ����� �ʿ䰡 ���� ������, �̵� �� �Ϻθ��� �����ϸ� �ȴ�. ���� ���ڸ� �� �� �����ϰ�, �װ��� ȸ����Ű�鼭 ������ ��ǥ ���¿� ��������� ���� �����Ѵ�. ���� �� ȸ���� �����Ѵٸ�, �� ȸ���� �����ϰ�, ���� ������ �����Ѵ�. ���� ���� �ʴٸ� ������ �ٸ� ���� �߿��� �ϳ��� ���� ȸ������ ����. ���� ���ϴ� ��ǥ ���·� �̲� �� �ִ� ȸ���� �ϳ��� �������� �ʴ´ٸ�, �̸� ��� ó���ϴ����� ������ ����ȴ�.
��� ������ ��������� ��ǥ ���·� �����ϴ� �������δ� ���¸� ��ȭ��ų �� ���� ��찡 ���ϴµ�, ������ �� �Լ��� ���� �ش밪�̳� ��� Ȥ�� ���̿� �������� �� �̷��� ���°� ���Ѵ�.
���� ������ Ȯ���� �ذ��Ѵٰ� �� ���� ������, �̸� ó���ϱ� ���� �� ���� ����� ���ȴ�.
���� �� �Լ��� ����Ѵٰ� �ؼ� ��� ������ ����� �� ȿ������ ���� �ƴϴ�. �ش����κ��� �־����� ����, ������ ���Ŀ� ���Ǵ� �� �Լ��� ���� ���ڱ� �۾����� ������ �� ����� ����ϴ� ���� �������ѵ�, �̴� ������ ��ġ ȿ�� (threshold ȿ��) �� �����ϴ� ����̴�. ��� ������ ����� 2-1-2 ������ ������ �ִ� �̿� �˰������ ���� �ٸ� �������� ����� �Բ� ���Ǿ�, Ž�� �ð��� �������� ���� ������ �ذ��� �� �ִ� ������ �ִ� �ݸ�, ȿ�������� ���� ��쵵 �ִٴ� ������ �ִ�. ����ϰ� �� ����ȭ�� �������� ��� ������ ����� �ſ� ��ȿ�����̴�.
�ش��� ������ ��Ʈ ��� �� ��� ������ ����� ���� �켱 Ž�� ����� �����̴�. ���� ����� ������ ����, �ſ� ���� ȿ������ �ش��� ���� �� ������, ���ʿ��� ��θ� Ž���ϱ� ���� ���� �ð��� �Һ��ϴ� ��찡 ����� ���Ѵ�. ���� �켱 Ž���� ���� ������ ��带 �����ϱ� �ռ� Ʈ���� ���� ������ �ִ� ��� ��带 ���� �����ϴ� ����̴�. �� ����� Ʈ�� Ž�� �Ӹ� �ƴ϶� ���� Ž������ ��ȯ���� ������ �� �ִ�.
Ʈ���� ���� ���� ������ ������ �ְ�, �ش��� �����Ѵٸ�, ���� �켱 Ž�� ����� ����Ͽ� �ش��� �ݵ�� ã�� �� �ִµ�, �̰��� ���� ������ �� �ִ�. ���� �ش��� �����Ѵٸ�, ��� ���·κ��� ��ǥ ���¸� �����ϴ�, ���� ���� (���ǻ� N �̶� ����.) �� ���� ��ΰ� �����Ѵ�. ���� �켱 Ž�� ������ ���̰� 1 �� ��θ� ��� Ž���ϴµ�, Ʈ������ ���� 1 �� ��ΰ� ���Ѱ� �����Ѵ�. ���� �ܰ迡��, ���Ѱ� �����ϴ� ���� 2 �� ��θ� �����Ѵ�. ���� N �� ��θ� ��� �����Ͽ� Ǯ�̸� ã�� ������ �� ������ ��� �����Ѵ�. Ǯ�̸� ã�� ���� ���� �켱 Ž�� ����� ����� ���, ������ ��θ� ã�� ���� �ƴ϶� �ִ� �Ÿ��� ���� ��θ� ã�� �Ǵ� ���̴�. ����, �ٸ� �������� �������� ������ �����Ѵٸ� (���� ���, Ž���ϱ �ʹ� ���� ����� �䱸�ϴ� ����), �̷��� ���� ��δ� ���ϴ� ���� ��ΰ� �ƴϴ�.
���� �켱 Ž�� ������� ���� �� ���� �������� �����Ѵ� :
1. ���� ��� ��Ұ� �ʿ��ϴ�. Ʈ���� �� ������ ��� ���� ���� ���� ���� ���� �Լ��� ����ϸ� �����ϴµ�, ��� ��尡 ���ÿ� ��ϵǾ�� �Ѵ�.
2. �����ؾ� �� ��� ���� ����� ���̿� ���� ���� �Լ������� ����ϱ� ������, ���� �ִ� ��ΰ� �ſ� �� ���, Ư�� ���� �۾��� ������ �䱸�ȴ�.
3. �������ϰų� ���ʿ��� �����ڴ� �����ؾ� �� ��� ���� ũ�� ������Ų��.
Ǯ�̷� �̲��� ��δ� ���� ������, �̵� ����� ���̰� �ſ� �� ������ ���� �켱 Ž�� ����� ����ϴ� ���� ��ȿ�����̴�. �̷��� �������� ���� �켱 Ž�� ����� ����ϴ� ���� ���� ȿ�����̴�.
���� �켱 Ž�� ����� ���� �켱 Ž�� ����� �������� ���� �ϳ��� ���� ����� ���� �켱 Ž�� ��� (Best-First Search) �̴�. ���� �켱 Ž���� �� �ܰ踶��, ������ ���Ŀ� ���Ǵ� ������ �� �Լ��� �����Ͽ�, ���ݱ��� ������� ��� �� Ǯ�̷� �̲� ���ɼ��� ���� ���� ��带 ���Ѵ�. �İ� ��带 ����� ���� ��Ģ�� �̿��Ͽ� ���õ� ��带 ����, Ȯ���Ѵ�. ���� �̵� �İ� ��� �߿� ���ϴ� ��ǥ ���°� ���ԵǾ� �ִٸ� ������ �ߴ��ϰ�, ���� �ʴٸ� ���� ������� �İ� ��带 ���ݱ��� ������� ���� ������ ���տ� ÷���Ѵ�. �ٽ� ��Ǯ�̷� �̲� ���ɼ��� ���� ���� ��带 ã�� ���� �켱 Ž���� ��� �����Ѵ�. Ǯ�̸� ���� ���ɼ��� ���� ���� �������� Ž���� ���� ���� ���� �켱 Ž�� ����� ����Ѵ�. ���� ���ϴ� ��ǥ Ǯ�̸� ã�� ���ϸ�, �������� �������� ������ ���ֵǾ� ���õǾ�����, ����� ���� ������ ������ �Ǵ� ��θ� ã�� Ž���� ����Ѵ�.

�� 12 ���� �켱 Ž��
�� 12 �� ���� �켱 Ž���� �ʱ� ���¸� ��Ÿ����. �ʱ� ���´� �ϳ��� ���� �����Ǿ� �ִµ�, �� ��带 Ȯ�� �����Ͽ� �� ���� ���ο� ��带 �����. ���� �ܰ迡�� ����� ��带 ���ϱ� ����, ������ ������� ��忡 ����� ����ϴ� �� �Լ��� �����Ѵ�. �̷κ��� ��� D �� Ǯ�̸� �̲� ���ɼ��� ���� ���� ���� ��Ÿ���� ������, �̰��� Ȯ�� �����Ͽ� �� ���� �İ� ��� E �� F �� ����� �� �� ���� ��忡 �ٽ� ������ ����� ���Ǵ� �� �Լ��� �����Ѵ�. ���ݱ��� ������ A-D-E/F ��κ��� A-B ��ΰ� �� ������ ������ ��Ÿ���� ������, B �� Ȯ�� �����Ͽ� G �� H ��� �İ� ��带 �����. ���� ���ο� G �� H �� ���Ͽ� �� ��ΰ� �ٸ� ��ε� ���� ��ȿ������ ������ �ǴܵǾ��� ������ D �� E �� ������ ��θ� �ٽ� �����Ѵ�. E �� Ȯ���Ͽ� I �� J �� �����, ���� �ܰ迡��, ���� ������ ������ �� ��� J �� Ȯ�� �����Ѵ�. ���ϴ� ��ǥ ���¸� ���� ������ �� ������ ��� �����Ѵ�.
���� �������� ��� Ʈ���� ���� �켱 Ž�� ����� �����Ͽ�����, �ߺ��Ǵ� ����� Ž���� ���ϱ� ���� ������ Ž���ϴ� ���� ȿ������ �� �ִ�. A* �˰������� ���� ������ ���� �켱 Ž���� ������ ������ν� �ſ� ȿ������ �˰������̴�. ����, A* �˰����� ���� ���� ����.
�� ��尡 ���� ���� ���� ��� �� ���¸� ��Ÿ���� ���⼺ ������ Ž���ϸ鼭 �˰������� ����ȴ�. �� ��忡�� ������ ���� ������ ���ԵǾ� �ִ� : ���� ���¿� ���� ���, �� ��尡 Ǯ�̷� �̲� ���ɼ��� �˸��� ǥ��, �� ��带 �İ� ���� ������� ���� ��带 �����ϴ� �θ� ��ũ (parent link) �� ����� �İ� ��带 ��Ÿ���� ���, �θ� ��ũ�� �ϴ� ���ϴ� ��ǥ ���¸� ã�� �Ǿ��� ��, �� ��ǥ ���¸� �̲� ��θ� ��ã�� ���� ���ȴ�. ���� �� ȿ������ ��ΰ� �̹� �����ϴ� ��忡�� �߰ߵȴٸ�, �̰��� �İ� ��带 Ž���ϱ� ���� �İ� ����� ����� ����Ѵ�.
A* �˰������� �����ϱ� ���� ��忡 ���� �� ���� ����� �ʿ��ϴ�.
���� ������ �� ����� ������ ���ϱ� ���� ������ ���Ŀ� ���Ǵ� �� �Լ��� �ʿ��ϴ�. �� �Լ��� �̿��Ͽ� �˰������� �� �� ���� ��θ� ���� Ž���� �� �ִ�. f' (����� ������ �ִ� �Լ� f �� �ٻ� �Լ�) �� �Ҹ���� �� �Լ��� g �� h' ��� �� �Լ��� ������ ���ǵȴ�. �Լ� g �� ��� ���·κ��� ���� ������ ���µ� �ҿ�� ����� ��Ÿ�� �����ν� �������� �ƴ϶�, ���� ��θ� ���� ��Ģ�� �����ϸ� ��带 ���� �� �ҿ�� ����� ���̴�. �Լ� h' �� ���� ���κ��� ��ǥ ���·� �� �� �ʿ��� ������ �����Ǵ� ����� ���������ν�, �̸� ���� ���� ������ ���� ������ �̿�ȴ�. �Լ� f' �� ��� ���·κ��� ���� ������� ��带 ���� ��ǥ ���·� �� �� �ʿ��� ����� �������̴�. ���� � ��带 ����� ��ΰ� �� �� �̻� �����Ѵٸ�, �˰������� �� �� ���� ������ ��θ� ������ ����Ѵ�. g �� h' �� ���ؾ� �ϱ� ������, h' �� ����� ���뼺 (���� ��尡 ���� ���� ����) �� �����ϴ� ���� �ƴ϶� �� ���κ��� ��ǥ ���·� �� �� �ʿ��� ��� (������ ���� ���� ��, �������� ���� ū ���� ��´�) �����ؾ� ���� �����϶�. ���� g �� ���� �ƴ� ���̾�� �Ѵ�. ���� ���� �ʴٸ�, Ž���ϴ� ������ ��ο� ����Ŭ�� ���ԵǾ� ���� ��� ����� ũ�Ⱑ Ŀ���� ����, ��ġ ���� �� ������ ��ó�� ��Ÿ���� �����̴�.
������ �˰������� �ۿ��ϴ� ����� �����ϴ�. ��ǥ ���¸� ��Ÿ���� ��尡 ������ ������, �� �ܰ踶�� �ϳ��� ��带 Ȯ�� �����ϴ� �����̴�. �� �ܰ踶�� ���ݱ��� ����������� ���� Ȯ�� �������� ���� ��� �� Ǯ�̷� �̲� ���ɼ��� ���� ���� ��带 �����Ѵ�. ���õ� ����� �İ� ��带 �����Ͽ�, ��� ������ ���Ŀ� ���Ǵ� �� �Լ��� �����ϰ�, �̵� �İ� ��� �� ������ ������� ���� �����Ͽ� OPEN ��Ͽ� ÷���Ѵ�. �� ������ �Ʒ����� ���� �����ȴ�.
A* �˰�����
1. ��� ������ ��带 ������ OPEN ���� �����϶�. �� ����� g ���� 0 ��, h' ���� ������ ����, ���� f' �� h' + 0 �� h' �� ���� �־��. CLOSED �� �� ������� �Ѵ�.
2. ��ǥ ���¸� ã�� ������ ���� ������ �ݺ� �����϶� : ���� OPEN �� ��� ��嵵 �������� �ʴ´ٸ�, �����̴�. ���� �ʴٸ� OPEN ���� ���� ���� f' ���� ���� ��带 �����϶�. �̰��� BESTNODE �� ����. OPEN ���� �װ��� �� CLOSED �� �־��. BESTNODE �� ��ǥ ������� �����϶�. ���ٸ� �ش��� �����Ѵٰ� �����϶� (���⼭ �ش���, ã�� ���� ����� BESTNODE �� �ǰ�, ã���� �ϴ� ���� ��ζ�� ��� ���¿� BESTNODE �� ������ ��ΰ� �ȴ�). ���� �ʴٸ�, BESTNODE �� �İ� ��带 �����϶�. ���� ���� BESTNODE �� �� ������ �����ϴ� ������ ������ ���� (���� �̵� �߿� �̹� ������� ��尡 �����ϴ��� �����ؾ� �Ѵ�). �� SUCCESSOR �� ���� ������ �����϶�.
1) SUCCESSOR �� BESTNODE �� �����ϴ� ��ũ�� ������. �� ���� ��ũ�� Ǯ�̸� ����� ��, Ǯ�̷� �̲� ��θ� ȸ���ϱ� ���� ���ȴ�.
2) g(SUCCESSOR) = g(BESTNODE) + BESTNODE ���� SUCCESSOR �� ��� ���� �ҿ�� ����� ����Ѵ�.
3) SUCCESSOR �� �̹� OPEN ��Ͽ� �ִ� ��� (��, �̹� ����������� ������� ���� ���) ���� �����϶�. ���� ���ٸ� �̰��� OLD �� �϶�. �� ��尡 �̹� ������ �����ϱ� ������, SUCCESSOR �� ������, BESTNODE �� �İ� ��� ��Ͽ� OLD �� ÷���Ѵ�. OLD �� �θ� ��ũ�� BESTNODE �� �����ϵ��� �����ؾ� ������ �����ؾ� �Ѵ�. SUCCESSOR �� ���� ����� g ����, OLD �� ���� ������� ���� ���� ��ο� ���� g ������ ���� �� �ִ�. ������� ���� ���� ��θ� ���� SUCCESSOR �� ���� ���� �ҿ�� ����� �� ������ �����ϱ� ���� ������ g ���� ��, �����϶�. ���� OLD �� ���õ� ����� �� ���ٸ�, ���� �ܰ踦 �����϶�. ���� SUCCESSOR �� ���õ� ����� �� ���ٸ�, �θ� ��ũ�� BESTNODE �� �����ϵ��� g(OLD) �� ���ο�, �� ���� ����� ��� ��θ� ����ϰ�, g'(OLD) �� �����϶�.
4) ���� SUCCESSOR �� OPEN �� ���ٸ�, CLOSED �� �ִ��� �����϶�. ���� ���ٸ�, �� ��带 CLOSEDOLD �� �ϰ�, BESTNODE �� �İ� ��� ��Ͽ� OLD �� ÷���϶�. ���ο� ��γ� �̹� ����� ��� ��, �ܰ� 2.3 ����ó�� ��� ���� �� ȿ���������� �����Ͽ� �θ� ��ũ��, g, f' �� ���� ������ ���϶�. ���� OLD �� ���� �� ���� ��θ� �߰��ߴٸ�, OLD �� �İ� ��忡 �� ����� �����Ͽ��� �Ѵ�. OLD �� �װ��� �İ� ��带 �����Ѵ�. �� ������ OPEN �� �ִ� ���� �����ų�, Ȥ�� ��带 �����ϵ��� �Ѵ�. ���ο� ����� �İ� ��忡 �����ϱ� ���ؼ��� OLD �������� Ʈ���� ���� �켱 Ž���� �����Ͽ� �� ����� g �� (�ᱹ f' ��) �� �����ϰ�, �İ� ��尡 ���� ��峪 Ȥ�� �� ���� ��ΰ� �̹� �߰ߵ� ��忡 �������� �� �б⸦ ����ģ��. �� ������ ���� ������ �� �ִ�. �� ����� �θ� ��ũ�� �������� �˷��� �װ��� �θ� �����ϵ��� �Ѵ�.
5) ���� SUCCESSOR �� OPEN ���� CLOSED ���� ���ԵǾ� ���� �ʴٸ�, �װ��� OPEN �� �ְ�, BESTNODE �� �İ� ��� ��Ͽ� ÷���϶�.
f'(SUCCESSOR) = g(SUCCESSOR) + h'(SUCCESSOR) �� ����϶�.
A* �˰����� ���� ���� ����ִ� ���� �߰��� �� �ִ�. ù��°�� �Լ� g �� �����̴�. ��� ��ü�� ���뼺�Ӹ� �ƴ϶�, �� ��带 �����ϰ� �ִ� ����� ���뼺 (h' �� ���� ������) �� ����, �Լ� g �� ����Ͽ� ���� �ܰ迡�� ���� Ȯ��� ��带 �����Ѵ�. f' ���� g �� ������ �� ��ǥ ���¿� ���� ����� �������� Ȯ�� �����Ǵ� ��带 �����ϴ� ���̴�. Ǯ�̸� ��� ���� ��ο� ������ ���´ٸ�, Ư�� g �� �����ϰ� ���ȴ�. ���� ��οʹ� ������� ���� Ǯ�̸� ����� �ϴ� ���, g �� �� 0 ���� �����Ͽ� ��ǥ�� ���� ����� ��带 �����Ѵ�. �ּ��� �ܰ� ���� ������ ��θ� ã�� ���Ѵٸ�, �� ��忡�� �װ��� �İ� ���� �� �� �ҿ�Ǵ� ����� ��� (�Ϲ������� 1) �� ���Ѵ�. ������ �� ��� ����� ���� �ٸ� ��Ģ�� �����ϰ� �ִ� ���� �ý����� ����Ͽ� ���� ���� ����� ��θ� ã���� �Ѵٸ�, �� ��忡�� �İ� ���� �� �� �ҿ�Ǵ� ��뿡 ���� �ý��۳� �ۿ���, �� ��Ģ�� ����� �ݿ���Ų��. A* �˰������� �ּ� ����� ��θ� ã�� ����, Ȥ�� Ǯ�̸� �̲��� ��θ� ������ �� ���� ã�� ���� ���� �� �ִ�.
�ι�°�� �� ���κ��� ��ǥ �������� �Ÿ��� ��Ÿ���� h �� �������� �Լ� h' �̴�. h' �� h �� ������ �������̶��, A* �� � Ž���� �������� �ʰ�, ��� ��ǥ ���¸� ã�� ���̴�. h' �� ȿ�����ϼ��� ��ǥ ���¿� ������ ������ ���̴�. ���� h' �� �� 0 �̶�� Ž���� g �� ���� ����ǰ�, ���� g �� 0 �̶��, Ž���� ���Ƿ� ����ȴ�. h' �� 0 �� �� ���� g �� �� 1 �̶��, Ž���� ���� �켱 Ž���̴�. ���� h' �� ����������, 0 �� �ƴ϶�� � ���� �Ͼ��? �� ��� Ž�� �������� ���� �� �ִ� �Ϳ� ���� �˾� ����. ���� h' �� h �� ���� ������ �ʴ´ٸ�, ���� ��ΰ� ������ ���, A* �˰������� ��ǥ ���·� ���� ���� ��� (g �� ���� ����) �� �ݵ�� ã�´�.
�� 13 �� ������ ��Ȳ�� ���� ����. ��� ��ũ�� ���� ����� 1 �̶� ����. ó���� A �� ������ ��� ��尡 OPEN ��Ͽ� �ִ� (���� ���� ��� B �� E �� ���� Ȯ��� �� �ܰ� ������ ���¸� ��Ÿ����). �� ��忡 ���� f' �� h' �� g �� ������ ǥ�õǾ���. �� ������, ��� b �� ���� ���� f' �� 4 �� ������ ������, ���� ���� Ȯ��ȴ�. ��� E ���� ��� B �� �İ� ����̰�, ��ǥ ���·κ��� 3 ��ŭ ������ �ִٰ� ��������. f'(E) �� f'(C) �� 5 �� ����. �̷� ��Ȳ������ ������� ����� ��θ� ���Ѵٰ� ��������. ���� E �� ���� Ȯ���Ѵ�. ��� F ���� ��� E �� �İ� ����̰�, ��ǥ�κ��� 3 ��ŭ ������ �ִٰ� �����ϸ�, ���� �ܰ迡�� ���� ��带 ���� �� �̻� ���ݱ��� ����� ��θ� ���� ������ �� ���� �����ؾ� �Ѵ�. f'(E) = 6 �̰� f'(C) = 5 �̴�. ���� ������ ��� C �� ���� Ȯ���Ѵ�. h(B) �� ���� ������ �۰� �����߱� ������ �̷� ���ʿ��� ����� �ϰ� �� ���̴�. ���� �ᱹ�� ���� �����ߴ� �ͺ��� B �� �� �ָ� ������ �ִٴ� ���� �߰��ϰ� �ǰ�, �����Ͽ� �ٸ� ��θ� ã�� �����Ѵ�.

�� 13 h' �� h �� ���� ���� ���
�� 14 h' �� h �� ���� ���� ���
�� 14 �� ������ ��Ȳ�� ���� ����. ù��° �ܰ迡�� B �� ���� Ȯ���ϰ�, �ι�° �ܰ迡�� E �� ���� Ȯ���Ѵ�. ���� �ܰ迡�� F �� Ȯ���Ͽ�, ��ħ�� G �� ��� ���� 4 �� Ǯ�� ��θ� ��´�. ���� D �κ��� ���� Ǯ�̷� ���� ���� 2 �� ��ΰ� �����Ѵٰ� �����ϸ�, ���� �� ��θ� ���� �� ����. h(D) �� ���� ������ ���� �����߱� ������, D �� �������� ���� ������, �� D �� ���� Ȯ������ ���� ä, �ٸ� ���� �������� Ǯ�̸� ã�� �� ���̴�. �Ϲ������� h' �� h �� ���� ���� ���, ��� ��ΰ� ���� ��κ��� ����� ������ ������ ��� ���� ��â���� �ʴ´ٸ�, ���� ���� ����� ���� ��θ� ã�� ���� ���� �ִ�. ���� �Ϲ������� �ݵ�� �����ظ� ã�ƾ� �ϴ� ���� �ƴϱ� ������, �̰��� �״��� ������ ���� �ʴ´�.
����°�� Ʈ���� �������� �����̴�. A* �˰������� ������ ������ ��, �ſ� �Ϲ����� ���·� ����ߴ�. ����, ������ ������ ��尡 �̹� OPEN �̳� CLOSED �� �����ϴ� ������� �����ϴ� �ܰ踦 �����Ͽ�, Ʈ���� �����ϱ� �˸µ��� A* �˰������� �ܼ�ȭ�� �� �ִ�. �� ��� ���� ���� ��带 ���� �� ������, ���� Ž���� ���� �� �����ؾ� �ϴ� ������ �ִ�.
���ݱ��� ��ǥ�� �̲��� �ϳ��� ��θ� ã�� ���� OR ������ Ž���ϴ� ����� ���� �����ߴ�. Ǯ���� �ϴ� ���� �߿���, ������ ���� ���� ���� �κ����� �����Ͽ� �̵� �κ����� ������ ���� ���� Ǯ�̸� ���� ��, �̰͵��� �ϳ��� �����ϸ� ���� Ǯ���� �ϴ� ������ Ǯ�̸� ���� �� �ִ� ������ �ִ�. �̷��� ������ �������� AND-OR ������ ����ϴ� ���� ���� ȿ�����̴�. ������ ���� (decomposition), Ȥ�� ��� (reduction) �ϸ�, ���� ���� �İ� ��带 ���� AND ��ũ�� ����� ���µ�, ���� ������ Ǯ�̸� ��� ���ؼ��� �̵� �İ� ��� ������ ���� ��� Ǯ�̸� ã�ƾ߸� �Ѵ�. ���� OR ��������ó��, �ϳ��� ���κ��� ���� ���� ��ũ�� ���� �� �ִµ�, �̰��� ������ Ǯ �� �ִ� ����� ���� �� �������� �ǹ��Ѵ�. �̷��� ���� ������, ���� ������ �ܼ��� AND ������ ���� �ʰ� AND-OR ������ �Ѵ�. �� 15 �� AND-OR ���� (Ʈ���� ����) �� �� ���� �Ұ��Ǿ���. AND ��ũ�� ��� �������� �����ϴ� ������ ǥ���Ѵ�.

�� 15 ������ AND-OR ����
Ǯ�̸� ã�� ���� AND-OR ������ �̿��Ѵٸ� A* �˰������ ����ϸ鼭, AND ȣ�� ������ ó���� �� �ִ� �˰������� �ʿ��ϴ�. �� �˰����� ����, ������ ��� ���κ��� ��ǥ ����, �� Ǯ�� ���¸� ��Ÿ���� ��带 �����ϴ� ��θ� ã�´�.
���� AND ��ũ�� �����ϰ� �ִ� �� ��Ҵ� �� �ڽ��� Ǯ�� ��带 ã�ƾ� �ϱ� ������ �� �� �̻��� Ǯ�� ���¿� �����Ѵ�.
�� 16 AND-OR ����
A* �˰������� AND-OR ������ Ž���� �������� ������ �����ϱ� ���� �� 16 (a) �� ���� ����. ��Ʈ ��� A �� ���� Ȯ���Ͽ�, �ϳ��� B ��, �ٸ� �ϳ��� C �� D �� �̲��� �� ���� ��ũ�� �����. �� ��忡 ǥ�õ� ���ڴ� �� ��忡 ���� f' �� ���̴�. ��� ���� �ۿ��� ����� ������ ����� �Ҹ�Ǹ�, �ϳ��� �İ� ��带 ���� ��ũ�� ó���ϱ� ���ؼ��� 1 �� �����, ���� ���� �İ� ��带 ���� AND ��ũ�� ���, �� ������ ó���ϱ� ���� 1 �� ����� �Ҹ�ȴٰ� ��������. ���� ���� f' ���� ���� ��带 ���� �ܰ迡�� ���� Ȯ��� ���� ������ ���, ��� C �� ���õǾ�� �Ѵ�. ���� ���� �̿� ������ ������ ���ϸ� ��带 �̿��ϱ� ���ؼ��� ��� D �� ���� �̿��ؾ� �ϱ� ������ �� AND ��ũ�� ó���ϱ� ���� �Ѻ�� 9(B + C + 2) �� �ʿ�������, ��� B �� ������ ���, �Ѻ�� 6 �� �ʿ����� �� �� �ְ� ���� B �� �������� ��θ� �����ϴ� ���� ���� ȿ�������� �� �� �ִ�. ���� �ܰ迡�� ���� Ȯ��� ��带 ������ �� �� ��忡 ���� f' ���Ӹ� �ƴ϶�, �� ��尡 ��� ���κ����� ���� ��ο� ���ԵǾ� �ִ����� ���ε� �����ؾ� �Ѵ�. �� 16 (b) �� ������ Ʈ���κ��� �̰��� ���� ������ �� �� �ִ�. ���� ������ ���� f' �� ������ 3 �� ���� ��� G �̴�. �̰��� �Ѻ�� a �� �ʿ�� �ϴ� ���� ������ ��ũ G-H �� �Ϻκ��̴�. ���� ��� G �� ����Ϸ���, ���� �Ѻ�� 27 �� �ʿ�� �ϴ� ��ũ I-J �� ����ؾ� �ϱ� ������, ���� ���� ����� �κ��� ���� ���Ѵ�. �Ѻ�� 18 �� �ʿ��� A �κ��� B �� ���� E �� F �� ���� ��ΰ� �� ȿ�����̴�. ����, ������ ��� G �� ���� Ȯ���ϴ� ���� �ƴ϶�, E �� F �� �����Ѵ�. �� �Ͻ����� AND-OR ������ Ž���ϱ� ����, �� �ܰ踶�� ���� �� ���� �۾��� �����ؾ� �Ѵ�.

�� 17 AO* �˰������� �۵�
�� ������ �� 17 �� ��������. �ܰ� 1 ���� �����ϴ� ���� ��� A �ϳ��μ�, ���� ������ �Ǵ� ����� ���� �ִ�. �̰��� Ȯ�� �����Ͽ� ��� B, C �� D �� ��´�.
��� B �� C �� ���� �Ѻ���� 9 �̸�, ��� D �� ���� �Ѻ���� 6 �̱� ������, ��� D �� ���� ��ũ�� ��� A �κ��� ������ ��� �� ���� ������ ��ũ�� ǥ��ȴ� (ǥ�õ� ��ũ�� ������ ȭ��ǥ�� ��Ÿ����). �ܰ� 2 ���� ���� Ȯ��� ���� ��� D �� �����Ѵ�. �� �ܰ迡�� �Ѻ���� �������� 10 �� ��� E �� F �� ���� ���ο� AND ��ũ�� ���������. ���� ��� D �� D ���� 10 ���� �����Ѵ�. �� ���� �� �����Ͽ� AND ��ũ B-C �� ��� D �� ���� ��ũ���� �� ������ ���� �˰� �ǰ�, �̰��� ������ ���� ��η� ǥ���Ѵ�. �ܰ� 3 ������, ��� A �κ��� �� ��ũ�� ���� Ž���ϸ鼭 Ȯ����� ���� ��� B �� C �� �߰��Ѵ�. ���� �� ��θ� ���� Ǯ�̸� ã���� �Ѵٸ�, ��� B �� C �� ���� Ȯ���ؾ� �ϴµ�, �� �� ��� B �� ���� Ž���Ѵ�. ��� B �� ���� Ȯ���Ͽ� �ϳ��� ��� G �� �ϳ��� ��� A �� ���� �� ���� ��ũ�� ��´�. f' ���� ���� �����Ͽ�, B �� f' ���� 6 ���� �����Ѵ�. ���� AND ��ũ B-C �� �Ѻ���� 12 (6 + 4 + 2) �� �����ȴ�. �̷κ��� ��� D �� ���� ��ũ�� ��� A �κ����� �� ���� ��ΰ� ���� �� �� �ִ�. ���� ������ ���� ��η� �̰��� ǥ���ϰ�, �ܰ� 4 ���� ��� E �� ��� F �� ���� Ȯ���Ѵ�. Ǯ�̸� ã�ų�, ��� ��θ� ���� �����Ͽ� Ǯ�̰� ������ �˰� �� ������ �� ������ �����Ѵ�.
A* �˰������� AND-OR ������ Ž���ϱ �������� �ι�° ������, ���κ��� ������ ���� ��ΰ� AND ��ũ�� ���� ����Ǿ� ������� �ִٸ�, �̵��� ��� �����ؾ� �Ѵٴ� ���̴�. A* �˰����� �� ���κ��� �ٸ� ���� ���� �ٶ����� ��δ� �� ���� ���� ����� ���� ����̴�. ���� AND-OR ������ Ž���� ��� �� �� ���� �ƴϴ�.

�� 18 �� ��ΰ� �� ���� ���
�� 18 (a) �� �Ұ��� ���� ���� ����. ��忡 ǥ�õ� ���ڴ� ��尡 ������ ������ ��Ÿ����. ���� �ܰ迡�� ��� 10 �� ���� Ȯ���Ͽ�, �װ��� �İ� ��� ���� �ϳ��� ��� 5 �� ����� ���� ��Ȳ�� �� 18 (b) �� ������. ��� 5 �� ���� �� ���ο� ��δ� ��� 3 �� ���� ��� 5 �� ���� ��κ��� ���. ���� ��� 3 �� ������ ��θ� ����ϱ� ���ؼ��� ��� 4 �� ����ؾ� �ϴµ�, ��� 4 �� Ǯ �� ���ٴ� ������ �̹� �˷��� �ֱ� ������, ��� 10 �� ����ϴ� ���� ȿ�����̴�.
A* �˰������� AND-OR ������ ó���ϱ �������� ����° ������, AND-OR �� ó���ϱ� ���� �˰������� ���� � ����Ŭ�� �����ϰ� ���� ���� �������� �ۿ��Ѵٴ� ���̴�. �̴� � ��ȯ ��ε� ������ �ʿ䰡 ���� ������ AND-OR ������ ����Ŭ�� ������ ������ �� �ִ�. ��ȯ ��δ� ���п��� ������ ������ �� ���� �� �ִ� ��ȯ �߷��� ��Ÿ����. Y �� �����ϸ�, X �� ������ �� ������ ���� �Ŀ�, �ٽ� X �� �����ϸ�, Y �� ������ �� ������ ���� �� �ִ�. ���� �̷� ��ȯ ��ηδ� ������ ������ �� ����. ��ȯ ��δ� �ش��� ã�µ� ���� ������ ���� �ʱ� ������, �������� ������ �� �ִ�. Ž�� �������� ����Ŭ�� ���������ν�, Ž�� �˰����� �� ���������� �κ��� ������, �̷� ���� ���� ���������� �κе� �ִ�. �İ� ��带 �����, �̰��� �̹� ������ �����ϴ� ������� �˰� �Ǹ�, �̹� ���� Ȯ��� ��� �߿��� �� ��带 �������� �ϴ� ��尡 �ִ��� �����ؾ� �Ѵ�. ���� ���� �ʴٸ� (����Ŭ�� ��������� �ʴ´�), �� ���� ���� ������ �߰ߵ� ��θ� ������ ���Խ�Ų��. �̷� ���縦 �����ν� �� 18 (c) �� ���� ������ ��������� ���� ������ �� �ִ�.
����, AND-OR ������ ������ Ž���� �����ϴ� �˰������� ��Ȯ�� �˾� ����. �� �˰������� AO* �˰������̶� �Ѵ�.
A* �˰����� ����ߴ� OPEN �� CLOSED ��� ���, Ž�� ���� �� ���ݱ��� ������ ������� �κ��� ��Ÿ���� ���� �ϳ��� ���� G �� ����Ѵ�. ������ �� ���� ���� �İ� ��׳� ���� ���� ��带 ����Ű�� ��ũ�� ������ ������, ���� �� ���κ��� Ǯ�� ������ ����� ��� �������� h' ���� ������ �ִ�. ��� ���κ��� ���� �������� ����� g ���� �������� �ʴ´�. �ϳ��� ������ ���¸� ����� ��ΰ� ���� �� ������ �� �ֱ� ������, �� �ϳ��� g ���� ����ϱ�� �Ұ����ϴ�. �̹� �˷��� ���� ����� ����� Ʈ�������̱� ������, g ���� ���ʿ��ϸ�, �̴� ���� ��ο� �ִ� ��常�� Ȯ���� ���� �������� �����Ѵ�. h' �� ����� ���뼺�� ���� �������̴�.
Ž���� ���� ���Ѱ��� ����ϴµ�, ���� Ǯ���� ���� ����� ���Ѱ����� ũ�� �Ǹ� Ž���� �ߴ��Ѵ�. ���Ѱ��� �� ������ ���� ����� �ʿ�� �ϴ� Ǯ�̴� ��� ���������̱� ������ (��� Ǯ�̸� ã�´� ������) �̸� ó���ϱ� ���� ���ȴ�.
AO* �˰�����
1. G �� �ʱ� ���¸� ��Ÿ���� ��带 �־�� (�� ��带 INIT �� �Ѵ�).
h' (INIT) �� ����϶�.
2. INIT �� SOLVED ��� ��Ī�� ���� ������, Ȥ�� INIT �� h' ���� ���Ѱ����� ũ�� �� ������ ���� ������ �ݺ� �����϶� :
1) INIT �κ��� ǥ�õ� ��ũ�� ã�� ���� Ȯ���� ����, �� ��ο� ��Ÿ��, ���� ���� Ȯ����� ���� ��� �� �ϳ��� �����϶�. ���õ� ��带 NODE �� �θ���.
2) NODE �� �İ� ��带 �����. ���� �İ� ��尡 ���ٸ�, ���Ѱ��� NODE �� h' ���� �־��. �̰��� NODE �� Ǯ �� ���� ������� ��Ÿ����. ���� �İ� ��尡 �ִٸ�, SUCCESSOR �� �Ҹ��� �� ��忡 ���� ���� �۾��� �����϶� :
��
���� G �� SUCCESSOR �� �־��.
�� SUCCESSOR �� �ܸ� ����̸�, SOLVED
�� ���ϰ�,
�� SUCCESSOR �� �ܸ� ��尡 �ƴϸ�, h' ���� ����϶�.
3) ������ �����Ͽ�, ������ ���� ������ ���� �������� �����϶� : SOLVED �� ǥ�õǾ��ų�, h' ���� ���Ͽ� �� ���� ���� ���鿡 ������ �ʿ䰡 �ִ� ����� ������ S �� ����. S �� �ʱⰪ���� NODE �� �־��. S �� �������� �� ������ ���� �۾��� �ݺ� �����϶� :
��
S �� ���ԵǾ� �ִ� ��� �߿���, �װ��� �ļ� ��尡 ���� G �� ���ԵǾ� ����
�ʴ� ��带 ���϶� (��, ������ ��� ������ ���� �̰��� ���� ��带 �����ϱ�
����, �� ��� ��ü���� �����Ѵ�). �� ��带 CURRENT �� �θ���, S ���� �����϶�.
�� CURRENT �κ��� ������ ��ũ ������ ���� ����� ����϶�. �� ��ũ�� ����� ��ũ�� ���� �ִ� �� ������ h' ���� ���� �� �̰��� �ٽ� ��ũ ��ü�� ���� ���� ���̴�. CURRENT �κ��� ������ ��ũ�� ���� ���� ����� �ּҰ��� CURRENT �� ���ο� h'������ �Ѵ�.
�� ���ܰ迡�� ���� �ּ� ����� ���� ��ũ�� ǥ�������ν�, CURRENT �κ����� ���� ��θ� ǥ���϶�.
�� ������ ǥ�õ� ��ũ�� ����, CURRENT �� ����� ��� ������ SOLVED �� ����������, CURRENT �� SOLVED �� ǥ���϶�.
�� CURRENT �� SOLVED �� ǥ�õǾ��ų�, CURRENT �� �ּ� ����� �ٲ���ٸ� �װ��� ���ο� ���¸� ���� ���� �����ؾ� �Ѵ�. ���� CURRENT �� ��� ���� ������ S �� ÷���϶�.
�� �˰������� �ۿ� ��������, ���� ���� ������ ������ �� �ִ�. �ܰ� 2.3.5 ����, ����� �ٲ� ����� ���� ���� ����� ������ ���ϴ� ����� ���տ� ÷���ȴ�. �� �˰����� ����� ��ó��, ����� �ٲ� ����� ��� ���� ��带 �� ���տ� ���� �ִ´�. �̷� ����, �̹� �������� �ʴٰ� �˷��� ���� ��θ� ���� �����ϸ鼭, ����� ��ȭ�� ������ �� �ִ�. ���� ���, �� 19 ���� ����������, C �� �������� ��ΰ� B �� ���� �������� ��κ��� �� �����ϱ� ������, B �� �������� ��θ� ���� Ȯ���ϴ� ���� �����̴�. ���� ��� E �� ����� ������ ��, �� ��ȭ�� ��� C �Ӹ� �ƴ϶� ��� B ���� ������ �ʴ´ٸ�, ��� B �� �� ������ ��ó�� ���� �� �ִ�.

�� 19 ���ʿ��� ���� ����
���� ��� ��� E �� ���� Ȯ���Ͽ�, �̰��� ����� 10 ���� �����Ǿ��ٰ� ����. �̶� ��� C �� ����� ���� �����ȴ�. �̰� ������ ���, ��� B �� ���� ���� 11 �� ����� ���, ��� C �� ���� �������� 12 �� ����� �ҿ�Ǵ� ������ ��Ÿ���� ������, ��� A �κ��� ����Ͽ� ��� B �� ���� �������� ��θ� ���� ������ ��η� �����Ѵ�. �� �������� ��� D �� ���� Ȯ���ϴ� ���� �ܰ迡�� �� �Ǽ��� �˰� �ȴ�. ��� D �� ���� ����� ��ȭ�� ��� B �� �����Ͽ�, ��� B �� ����� �ٽ� ����� ��, ��ȭ�� ��� E �� ����� ���� ���̴�. ���� ���� ��� B �� ����� �ٽ� ��� A �� ���ǰ�, �̷κ��� ��� C �� ���� �������� ��ΰ� �� ������ ������ �˰� �ȴ�. ���� B �� ���� Ȯ���ϱ� ���� �ð��� �Ҹ�Ǿ��� ��, Ǯ�̸� ��µ��� ������ ���� �ʴ´�. ���� ����� ���� ��尡 Ž�� ������ ���� �ؿ� ��ġ�Ѵٸ�, ������ ���� �߰����� ���� ���� �ִ�. �� 20 (a) �� �̰��� ���� ��������. �� 20 (b) ó�� ��� G �� ����� ���� ��, �� ��ȭ�� ��� ��� E �� �������� �ʴ´ٸ�, ��ȭ�� ���Ŀ� ���� �ݿ����� �ʱ� ������, ��� B �� ���� ��������, ������ �ƴ� Ǯ�� ��θ� ��� �ȴ�.

�� 20 �ݵ�� �ʿ��� ���� ����

�� 21 �μ� ��ǥ�� ���� ��ȣ �ۿ�
AO* �˰����� �����Ǵ� �ι�° ������ AO* �˰������� �κ� ��ǥ�� ���� ��ȣ �ۿ��� �������� ���Ѵٴ� ���̴�. �̸� �����ϱ� ���� �� 21 �� ���� ����. ��� C �� ��� E �� �ᱹ�� ������ Ǯ�̸� �̲��ٰ� ������ ��, AO* �˰������� ����Ͽ� �� �� ��带 ��� ������ ������ Ǯ�̸� ���� �� �ִ�. AND-OR ���� �� �ִ� ��� A �� Ǯ�� ���ؼ��� �ݵ�� ��� C �� D �� ���� Ǯ�̸� ã�ƾ� �Ѵ�. ����, �˰������� ��� C �� Ǯ�� ������ ��� D �� Ǯ�� ������ ������ ������ ������ �����Ͽ�, ��� D �� Ǯ�� ���� ������ ���� Ȯ��� ��带 ��� E �� �����Ѵ�. ���� ��� C ���� ��� A �� Ǯ�� ���� �ݵ�� Ǯ������ �ϱ� ������, ��� D �� ������Ű�� ���� ������ �̰��� ����ϴ� ���� ���� ȿ�����̴�. ���� AO* �˰������� �̷��� ��ȣ �ۿ��� �������� ���ϱ� ������, ������ �ƴ� ��θ� ã�� �� ���̴�. 8-1 ������ �� ������ �ٷ����.
�ΰ� ������ ���� �������� �־��� ������ �������Ѿ� �ϴ� ������ �� �� �ִµ�, �̷��� ������ ��ǥ ���´� �־��� ���� ������ ������Ų ���� �����̴�. 2-4 ������ ���ǵ� ��ȣ ��� ������ 10 �忡�� ���ǵ� �ν� ������ ��� ���Եȴ�. ������ �۾��� ������ ��, ���ѵ� �ð�, ��� ���� ��Ḧ ������Ű�� ���� ������ ���� �ؾ� �ϱ� ������, ������ �۾��� ���� ������ ���� ������ �� �� �ִ�. ���� ������ ���� ������ Ǯ�� ���� Ư���� ���ο� Ž�� ����� �ʿ��� ���� �ƴϰ�, ���ݱ��� ������ Ž�� ������� �̿��� Ǯ �� �ִ�. �־��� ���� ������ �������Ѿ� �ϴ� ������ ������ Ư�� ������, ������ Ǯ��� ���� ���ϴ� ���� ������ ��ϰ� ���Ҿ� ���� ���¿� ���� ����� �����ϰ�, ���� �� ����� ó���ϴ� Ž�� ����� �����ϴ� ���� ȿ�����̴�. ��, ������ Ǯ�̸� ã�� Ž���� ������ ��, ���ÿ� �� ���� Ž���� �ʿ��ϴ�.
�ϳ��� ���� ���� ����� ���� �������� ����Ǵ� Ž���̰�, �ٸ� �ϳ��� ���� ���� �������� ����Ǵ� Ž���ε�, �̶� ��Ģ�� ���ϰ� ������ ���Ŀ� ���Ǵ� �� �Լ��� ���� ���� ���� ���� ��ġ�� �˷��ش�.
���� ������ ���� ����� ���� �� �ٸ� ���ش� ���� ������ ��� ������ ��� (��, ��ü���� �ִ밪�� �����ϰ�, �ٸ� ��������� �ִ밪�� �������� �ʴ´�) ���� ���� ���̴�. ��� ������ ����� ����Ǵ� ���� �������� �� ���´� ���� ���ܵ��� ���� ������ Ǯ���� ������ ��Ÿ����. �� ����� ����Ǵ� ������ ������ Ǯ���� ������ �پ��� ���¸� ���� �����̴� ������ �����Ѵ�.
���� ������ ���� ����� ������ ���� �Ϲ����� ���´� ������ ���� :
1. ������ Ǯ�̰� �߰ߵǰų�, Ȥ�� ��� ��θ� ������ Ǯ�̰� ���ٴ� ���� �˰� �� ������ ������ �����϶� :
1) Ž�� �������� ���� Ȯ����� ���� ��带 �����϶�.
2) ���ο� ������ ���� ������ ��� ����� ����, ���õ� ��忡 ���� ���ǿ� ���� ���� ��Ģ�� �����϶�.
3) ���� ������ ������ ����� �����Ѵٸ�, �� ��θ� ������ ������ ǥ���϶�.
4) ���� ������ ������ ������ Ǯ�̸� ��Ÿ���ٸ� �������� ǥ���϶�.
5) ����� ������ Ǯ�̵� �߰ߵ��� �ʾҴٸ� ���� ������ ���� ���հ� ������� ���� �ϰ��Ǵ� ���ο� �κ��� Ǯ�̸� ����� ����, ���� ������ ��Ģ�� �����϶�. �� �κ��� Ǯ�̸� Ž�� ������ �־��.
�� �������� ���� �߿��� ���� �߰��� �� �ִ�. �ܰ� 1.1 ������ �ܼ��� ���� Ȯ����� ���� ��带 �����Ѵٰ� ���������, ��带 �����ϴ� ����� ����, �˰������� �ൿ�� ũ�� ������ �´�. ���� ���� ������ ��ϰ� ���� ���¸� ǥ���ϴ� ����� ���ؼ��� ������� �ʾҴ�. ���� �پ��� ����� ����Ͽ�, �� ������ ó���� �� �ִ�.
������ ���� ����, �˰������� �ۿ��ϴ� ����� �� ������ �ذ��ϴ� ����� ���� ������ �� �ִ�.
|
���� |
SEND + MORE MONEY |
|
|
���� ���� |
|
|
|
��� ���ڵ� ���� ���� ���� �ʴ´�. ��� ���� ��Ģ�� ����߸� �Ѵ�. |
||
|
�ʱ� ���� ���� |
S = ? E = ? N = ? D = ? M = ? O = ? R = ? Y = ? |
C1 = ? C2 = ? C3 = ? C4 = ? |
�� 22 ��ȣ ��� ����
�� 22 �� �Ұ��� ��ȣ ��� ������ ���� ����. ���� ������ �ʱ� ��ϰ� �ʱ� ���� ���°� ���� ���� ��������. ��ǥ ���´� ��� ���� ������ �����ϴ� ������� ��� ���ڿ� ���ڸ� ���� �ִ� ���� �����̴�.
Ǯ�� ������ ����Ŭ�� ����ȴ�. �� ����Ŭ���� ���� �� ������ �������� :
1. ������ ���ο� ���� ������ ����� ����, ���� ���ǿ� ���� ���� ��Ģ�� �����Ѵ�.
2. ���� ������ ���� ���¿� ���� �䱸�Ǵ� ��� ����� �����ϱ� ����, ���� ��� ��Ģ�� �����϶�. �ΰ��Ǵ� ����� �����ϱ� ���� �ٸ� ��Ģ�� �����ϰ�, ���� ����Ŭ���� �ٽ� ���ο� ���� ������ ������.
����, �� �ܰ踶�� ���� ���� ��Ģ�� ����� �� �ֱ� ������, ������ ���Ŀ� ���Ǵ� ������ �� �Լ��� ����Ͽ� ���� ������ ���� ��Ģ�� �����Ѵ�. ���� ���, �� ���� ���� ���� �� �ִ� ���ڿ�, ���� ���� ���� ���� �� �ִ� ���ڰ� �ִٸ�, ���ں��� ���ڸ� �����ϴ� ���� ���� ȿ�����̴�. ������ ���� �����̶�� �� ������ ���� �߰� �ܰ��� ��ġ�� ������� �ʱ� ����, ���� �켱 Ž�� ����� �̿��Ͽ� �̰��� �����Ѵ�. ��ȣ ��Ÿ���� �ƴ� ��Ģ�� ��� �Բ� ������ �� �ְ�, ���� �ϳ��� �ܰ�� �� �� �ִµ�, �̴� ��ȣ ��� �������� ���� �� �� �ִ�.

�� 23 ��ȣ ��� ������ Ǫ�� ����
���� ���� ó���ϴ� ó�� �� �ܰ��� ����� �� 23 �� ��Ÿ�� �ִ�. ���� ����������, ���� ������ ���� �������� �ʱ� ������, ÷���� ���ǵ鸸 �� �������� ��������. �̰��� �� �۾� �о߿� ���õ� ���� ������ �ո����� Ǯ���̴�. ������ Ǫ�� �������� �ϳ��� �� ��Ϻ��� ����� �������� ���� ������ ����ϴ� ���� �����ѵ�, �̰��� ��� �����̶�� ��� ������ ���̸鿡�� �� �� ȿ�����̴�. �� ������ ó���ϱ� ���� �ϳ��� �߾� ������ ���̽��� ��� ���� ������ ����Ű��, ���� �� ���� �������� ���� ��ó�� �ؾ� �� ��ȭ�� �� ��帶�� ��Ͻ�Ų��. �� ���� �������κ��� ���� �ڸ� �ø����� ��Ÿ���� ���� C1, C2, C3, C4 �� ���������κ��� ����Ѵ�.
ó����, ���� ������ ����� ������ ������ ���� ����ȴ� :
���� ������ Ǫ�� ������ ��������. ���� �������κ��� ��� M �� O �� ���� ���� �� �ִ�. E �� ������ 2 �� �����Ͽ� ���� ����Ŭ�� ��������.
���� �� �ܰ迡�� ���� ������ ����� �������κ��� ������ Ǫ�� �������� ��� �Ѿ��, ���� Ǯ�� ������ ���� ���ǿ� ��Ȯ���� ���� ���ԵǾ� ������ �˰� �ȴ�.
���� ��쿡 ���� ���� ������ ����� �������κ��� ������ Ǫ�� �������� ��� �絵�ϴ� ���� ���� ȿ������ ���� �ִ�. �̰��� ���� ������ ����� �������� ��� �絵�ϴ� ���� ���� ȿ������ ���� �ִ�. �̰��� ���� ������ ����� �������� �̿�� �� �ִ� ������ ���� ����, ������ Ǫ�� �������� �̿�� �� �ִ� ������ ���� ���� ��� �����Ѵ�. ���� �̰��� ���� ������ ���� ������ Ǫ�� ó�� �� �ܰ迡���� �Ϲ������� �����Ѵ�. �̷��� Ư¡�� �̿��� ���� ������ ����� ������ 2 + D = 10 + Y �� ���� �����Ͽ� ������ ���� ���� ������ ����� :
���� ������ Ǫ�� �������� ��� �Ѿ� ����. ������ Ǫ�� ������ N = 3 ���� ����ϰ� �ݵ�� 8 �̳� 9 �� ���� �������� ������ ���� ���� D �� �����Ѵ�.
���� ����Ŭ����, ������ Ǫ�� ������ D = 8 �� ����� ��� ����� ������ �˰� �ǰ�, �����Ͽ� D = 9 �� �����ϴµ�, �� ���� ����� �������� �˰� �ȴ�. �̷� ���� ���� ������ ����� ������ ��� �絵��, ������ �����ߴ� ������ ��ü ������ �����Ѵ�. ���⼭ 2 + D = Y �̰� C1 = 0 ���� �˰�, ������ ���������� 2 + D = Y �� �������� ���̱� ������ ������ �ʴ´�.
�� �������� �� ���� �߿��� ���� �� �� �ִ�. ���� ������ ����� ��Ģ�� �ʿ��� ����, �̰��� ������ ���� ������ �����ؼ��� �ȵȴٴ� ���̴�. ���� �̰��� ��� ���� ���� ������ ������ �ʿ䵵 ����. ���� ��� D > 7 �̶�� ���� �˾��� �� Y �� 1, 2, Ȥ�� 3 �� ���� ���� �� ���ٰ� �־����ٸ�, D > 10 �̶�� ����� �������� ��. ���� D �� �� �ڸ� ���ڸ� ǥ���ϱ� ������ �̴� �Ұ����ϴ�.
�ι�°�� ������ �� �ִ� ���� �б� ����� �����Ͽ� ���� ������ ȿ������ ����ų �� �ִٴ� ���̴�. �̿� ������ ���� ������ ���� �ʴ� �ͺ���, ������ �� ���� �����ϴ� ���� ȿ�����̴�. ���� ���� ������ OR �� ���¸� ����, ������ Ǫ�� �������� �Ͽ��� ������ ��� �߿��� �ϳ��� �����ϵ��� �ϴ� �ͺ���, �� ���� ���¸��� �������� �ϴ� ���� ȿ�����̴�. ������ ���� ���� ����, ������ ���� ���� �ͺ��� Ǯ�̸� ���� Ȯ���� ũ��.
����°�� �� ����Ŭ���� Ȯ�� ������ ��带 �����ϴ� ����̴�. �����ϱ� ����, ��� ��Ҹ鿡�� �� �� ȿ�����̱� ������, �� ������ ���� �켱 ���� ����� ���Ǿ���. ���� �ٸ� ���� ����� ���� ���� �� �ִ�.
��ȣ ��� ����� ���� ���� ������ ���� ������ Ǯ�� ����, ������ ������ ����� ���� ����� ������ Ǯ�� ���� ���ݱ��� ���ǵ� ������ Ž�� ����� ������ �����ش�.
���ݱ��� ���� Ȥ�� ���� �߷��� Ž�� ����� ���� �����ߴ�. �̴� �־��� ������ ���� �������� ������ �����Ͽ� Ǯ�̸� ã�ư��� ���̾���. ���� ���� ���� ������ ȥ���Ͽ� ����ϴ� ���� ȿ������ �� �ִ�. �̷��� ȥ�� ����� ����Ͽ�, ���� ������ �߿� �κ��� Ǯ��, �ٽ� ���� ���� �߿� �κп� ���� Ǯ�̸� �Բ� ������ �� �Ͼ�� ���� ������ Ǯ �� �ִµ�, �̸� ���� ���-���� �м� ����̶� �Ҹ���� ����� ���ȴ�.
���-���� �м� ��� (means-ends analysis) �� ���� ���¿� ��ǥ ���°��� ���̸� Ž���ϴµ� ������ �д�. �̷��� ���̸� ã����, �� ���̸� ���� �� �ִ� ������ (operator) �� ã�ƾ߸� �Ѵ�. ���� ��κ��� ���, �����ڸ� ���� ���¿� ������ �� ���� ������, �����ڸ� �����ų �� �ִ� ���·� ����� �μ� ���� (subproblem) �� �����Ѵ�. �̷��� �ص� ���ϴ� ���¸� �����ڰ� ��Ȯ�� ������ ���� ���, ������ �μ� ������ �����, �� ������ ���� ������� ���·κ��� ��ǥ ���¸� ã���� �Ѵ�. ���� ���̰� �ùٷ� ���õǰ� �����ڰ� ������ �� ���̸� ȿ�������� ���� �� �ִٸ�, ���� ������ Ǫ�� �ͺ��� �� ���� �μ� ������ Ǫ�� ���� �ξ� �� ����. �� �� ������ ���-���� �м� ����� ��ȯ������ ������ �� �ִ�. ���� ū ������ �ذ��ϱ� ���� ���̿� �켱 ���� ������ ���Ͽ� ���� �켱 ������ ���� ���̰� ���� �켱 ������ ���� ���̺��� ���� �����ǵ��� �Ѵ�.
���-���� �м� ����� �̿��� ù��° �ΰ� ���� ���α��� ���� ���� Ǯ�� ���� (General Problem Solver) �̴�. �̴� �ΰ��� �ϴ� ���� �ùķ��̼��ϴ� ���α��� �ۼ��ϴ� �Ͱ� �ܼ��� � ������ε� ������ Ǫ�� ���α��� �ۼ��ϴ� �� ������ ��踦 �������ϰ� �ϴ� ���� ���̴�.
���ݱ��� �����ߴ� ���� Ǯ�� �������ó��, ���-���� �м� ����� �ϳ��� ���� ���¸� �ٸ� ���·� ��ȭ��Ű�� ��Ģ�� ���տ� ���� �����ȴ�. ���� �� ��Ģ�� �� ��鿡 ������ ���¸� ����� �ʿ�� ����. �� ��� ��Ģ�� �̿��ϱ� ���� �����Ǿ���� ���� (��Ģ�� ���� �����̶� �Ҹ����) �� ����ϴ� ������� ��Ģ�� ���������ν� ���ϴ� ���� ������ ����� ���������� ǥ���Ѵ�.
|
������ |
|
|
PUSH (obj, loc) |
���� ���� ��� |
|
CARRY (obj, loc) |
���� ���� ��� |
|
WALK (loc) |
���� ���� ��� |
|
PICKUP (obj) |
���� ���� ��� |
|
PUTDOWN (obj) |
���� ���� ��� |
|
PLACE (obj1, obj2) |
���� ���� ��� |
�� 24 �κ�Ʈ�� �����ڵ�
|
|
Push |
Carry |
Walk |
Pick up |
Put down |
Place |
|
��ü �̵� |
�� |
�� |
|
|
|
|
|
�κ�Ʈ �̵� |
|
|
�� |
|
|
|
|
��ü ���� |
|
|
|
�� |
|
|
|
��ü �÷����� |
|
|
|
|
|
�� |
|
�ƾ� ���� |
|
|
|
|
�� |
�� |
|
��ü ���� |
|
|
|
�� |
|
|
�� 25 ����ǥ
�ܼ��� ���� ���� �ϴ� �κ�Ʈ�� ���� ���캸��. �� 24 �� ���� ���ǰ� ����� ǥ���� �̿� ������ �����ڰ� ��������. �� 25 �� �� �����ڰ� ������ ���� ��Ÿ���� ����ǥ�̴�. �� ǥ���� �����ֵ���, �ϳ��� ���̸� ���� �� �ִ� �����ڰ� ���� �� ������ ���� �ְ�, ���� �ϳ��� �����ڰ� ���� ���� ���̸� ���� ���� �ִ�.
|
A |
B |
C |
D |
||||
|
|
|
|
|
|
|
|
|
|
Push |
|||||||
|
��� ���� |
|
|
|
|
��ǥ ���� |
||
�� 26 ���-���� �м� ����� ���� (CARRY)
�κ�Ʈ�� �� ���� ������ ���� �ִ� å���� �� �濡�� �ٸ� ������ �ű�� ������ �־����ٰ� ��������. ���� å�� ���� ���ǵ� �Ű����� �Ѵ�. ��� ���¿� ��ǥ ���� ���� ���̴� å���� ��ġ�̴�. �� ���̸� ���̱� ���� PUSH �� CARRY �� ������ �� �ִ�. ���� CARRY �� ���� �����Ѵٸ� �̰��� ���� ������ �����Ǿ�� �Ѵ�. �̴� �� ���� ���̸� �ٿ��߸� �ϴ� ����� ���´�. �� ���� ���̴� �κ�Ʈ�� ��ġ�� å���� ũ���̴�. WALK �� �����Ͽ� �κ�Ʈ�� ��ġ�� ó���� �� ������, ��ü�� ũ�⸦ �ٲ� �����ڰ� ����. ���� �� ��θ� �̿��ؼ��� ������ Ǯ �� ����. ������ ���õ� �� �ִ� �����ڴ� PUSH �̴�. �� 26 �� PUSH �� ����ϴ� ��쿡 ���� Ǯ�� ������ ���� �̷���� ������ �����ش�. �̷��� �Ͽ� ������ � ���� �ϴ� ����� ã������ ���� �� ���� ������ ���� ����. ���� �� ���� ����ƴ��Ͽ� �� ��ǥ ���¿� �̸��� ���� �ƴϴ�. ���� �� 26 ���� ������ A, B, C, D �� ��ġ �� A �� B ���� C �� D ������ ���̸� �ٿ��߸� �Ѵ�.
PUSH �� �� ���� ���� ������ ������ �ִµ�, �� �� �� ���� ��� ���¿� ��ǥ ���°��� ���̸� �����. å���� ũ�� ������ �ϳ��� ���� ������ �ƹ��� ���̵� ������ ���Ѵ�. �κ�Ʈ�� WALK �� ����Ͽ� �ùٸ� ��ġ�� �� �� �ִ�. ���� PICKUP �� �ѹ� ������ ��, �ι�° PICKUP �� �����Ͽ� ������ ġ�� �� �ִ�. ���� PICKUP �� �ѹ� ������ ��, �ι�° PICKUP �� �����Ϸ��� �κ�Ʈ�� ���� ���߸� �ϴ� �� �ٸ� ���̰� ���Ѵ�. �� ���̴� PUTDOWN �� ����Ͽ� ���� �� �ִ�.
|
A |
|
|
|
|
B |
C |
E |
D |
|||||
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
Pick up |
Put down |
Pick up |
Put down |
Push |
|
Place |
|
|||||
|
��� ���� |
|
|
|
|
|
��ǥ ���� |
|
||||||
�� 27 ���-���� ����� ���� ���� (PUSH)
�ϴ� PUSH �� ����Ǹ� ���� ���°� ��ǥ ���¿� ����������� ������ ��ǥ ���´� �ƴϴ�. å���� �ű� �� å�� ���� �־��� ������ �ٽ� �÷� ���ƾ߸� �Ѵ�. PLACE �� ����Ͽ� ������ �÷����� �� ������ �̸� ��� ������ ���� ����. �κ�Ʈ�� ������ ��ƾ� �ϱ� ������ �� �ٸ� ���̸� �ٿ��� �Ѵ�. �̷��� ������ ���� Ǯ�� ������ ���� ������� ������ �� 27 �� ��������. C �� E �� ������ ���̴� �κ�Ʈ�� ������ �ٽ� ���� ���� WALK �� ����� �� PICKUP �� CARRY �� ������� ����Ͽ� ���� �� �ִ�.
���⼭ ������ �κ�Ʈ ���������� �������� ������ �����Ǿ���. ������ ���̸� �����ϴ� ������ �ſ� �߿��ϴ�. �������� �����ϴ� ������ ū ���̸� ������ ���� ���̺��� ���� ���̴� ���� �߿��� ���̴�.
���ݱ��� ������ ������ ������ ������ ������ Ǯ��� �������ϴ�. �� ������ ������ ����. ���̰� ���� ���� ���� �� �̵��� ������ �ſ� ���� (n ���� ���̿� ���ؼ��� n! ��ŭ�� ������ �ִ�). ���� �ϳ��� ���̸� ���̴� ���� �ٸ� ���̸� ���̴� �ϰ� �븳�� �� �ִ�. ������ ���� ������ ���, �ʿ��� ����ǥ�� �ſ� ũ��. �� 8 �忡���� �������� ���-���� �м� ����� Ȯ���Ͽ� �̷��� �������� �ذ��� �� �ִ� ����� ���� �ٷ��.
���ݱ��� Ž���� �ʿ�� �ϴ� ���� ���� ���� Ǯ�� ����� ���� �ٷ����. Ž�� ������ ���Ǵ� ����� �߿��� �������� �� Ž�� ������ �� ���� ���ΰ��̴�. Ž�� ������ ���ٴ� ���� Ž�� ������ ȿ���� Ž�� ������ �߰��� ���� ��Ȯ���� ������ ���Ѵ�. ����������, ���� Ǯ�� �˰������� ������ ���� �ΰ� ���� �о��� ����� �˰������� �ۼ��Ͽ� ��ǻ�Ϳ� ���� ������� �� ���� ������ ���� ����� �����ϴ� ���� �����̾���. �̷��� ����� ���������� �˰������� �м��ϰų� �̷��� �м��� �Ұ����� ��� �����ϰ� ���õ� �����鿡 ���Ͽ� �˰������� ������ ��������� �м��ϴ� �پ ��İ��� ������ �̷��. �ΰ� ���� �о��� ����� ����ϴ� ������ ��� �� ���� ������ ������ �̴�, ������ ����.
�ι�° ������ �ſ� �߿��ϴ�. ��κ��� �ΰ� ���� �о� ���α��� ���� ���Ǵ� ������ ������ ������ �̸� ����ϴ� ���α��� ������ �м��� �ſ� ��ư� �����.
���� �̷��� �о߿��� �� ���� ��̷ο� ����� �ִ�. ����, ���α��� �ۼ��� �� ���α��� ���ɿ� ���Ͽ� ��Ȯ�ϰ� ���� �� �������� ���α��� ������ �� ���ο� �δ� ���� �߿��ϴ�.
��� �������� ������ �ƴ�����, �̹� �տ��� ���� �ٿ� ����, Ž�� ������ ���� �߿��� �м� ����� �б� ����� F �̰�, ���̰� D �� Ž�� Ʈ���� ��� ������ FD ��� ����̴�. �̷��� ������ �м��� ���� �� ������ ���Ͽ� �ش�.
FD ��� ������ ����κ��� ���� �� ���� ����� �� �� ������ �����̴�. ����, �� ���� ������ ������ ����. ���� �� 2 �忡�� ������ ���, Ʈ�� ��ü�� �����ϰ� Ž���ϴ� �ͺ��� �� ���� ����� �� ���� �ִ�. �� ������� ������ ���� �� ������ �з��ǰ�, �� �з��� ������� �ֿ� �������� �ִ�.
���� �����ϰԵ� ���� ������ ���Ͽ� Ʈ�� ��ü�� �����ϰ� Ž���ϴ� ����� �Ϲ����� ����� ����ϴ� ��쿡�� ���� �ð��� ũ�� �������� ���Ѵ�. ���� ���, ���� 2-1-2 ���� ������ �б�� �Ѱ迡 ���� ����� ������ Ž�� ������� ���� �� ������, ���� �ð��� ���� ũ� ���� �Լ������� ����Ѵ�. ������ ���� �湮 ������ ���ؼ��� ���� �Լ��� �˰����� �� ���� ������ �� �ִ� �˰������� �˷��� ���� ������, ���� �ƹ��� ���� �˰������� �˷�������� ������� �ʴ´�. ������ ���� �湮 ������ NP-���� ������ ���Ѵ�. NP-���� ������ �����ϰ� ����� �� �ִ� ��� �ϵ��� ���ÿ� ó���Ǵ� �� ������ (nondeterminstic) ��ǻ�Ϳ� ���� ����� �� ���� �Լ��� �ð��� �ɸ��� �˰����� ���ؼ��� Ǯ�� �� �ִ� �����̰�, �̷��� ������ �Ϲ����� ��ǻ�Ϳ� ���� Ǯ ������ ���� �Լ��� �ð��� �ɸ��� �˰����� �����Ѵ�. �̷��� �η��� �����鿡 ���ؼ���, �� �η��� ���ϴ� � ������ �Ϲ����� ������ (determinstic) ��ǻ�Ϳ� ���� ���� �Լ��� �ð��� �ɸ��� �˰����� ���� Ǯ�� �� �ִٸ� ������ �����鵵 ���������� ���� �Լ��� �ð��� �ɸ��� �˰����� ���� Ǯ �� �ִ�. �̷��� �������� �� �η��� �������� ���� �����ϴٴ� ���� ������ �� �ִ�. ���������� �ƹ��� NP-���� ������ ������ ��ǻ�Ϳ��� ���� �Լ��� �ð��� Ǯ �� �ִ� �˰������� ã�� ���Ͽ�����, �����ε� �ƹ��� �̷� ���� ���� ���� ������ ���δ�.
���� ���� �������� �˾ƺ���. �տ��� �̹� ���� ���, �ΰ� ���� �о߸� �����ϴ� �� ���� ����� �ΰ� ������ NP-���� ������ ���� �Լ��� �ð��� Ǯ���� �ϴ� ���̴�.
��� �̸� ������ �� �ִ°����� �� ������ �ִ�. ù��° ����� ��� �־��� ��찡 �ƴϴ��� ��������� �� �� ������ ����� �� �ִ� �˰������� ã�� ���̴�. �ι�° ����� ������ �� �ִ� �ð� ���� �Ƶ��� �� �ִ� ���� ���ϴ� �ٻ����� �˰������� ã�� ���̴�.
�б�� �Ѱ迡 ���� ��� (branch-and-bound strategy) �� ��������� �� �� ������ ����� �� �ִ� �˰������� �ϳ��̸�, �̷��� ������ �˰����� ���Ͽ� ������ ���� ������ ���Ͽ��� �� �ִ�.
����, �����ϰԵ� ������� �ð��� �ɸ��� ������ ���� ����� ���Ǿ �����δ� �� ����� ���� ���������� ���� ��찡 ����. ������ �б�� �Ѱ迡 ���� ��������� ��� �ð��� ���� �Լ����̴�. ���� ���� ������ �亸�ٴ� ���� �ٻ簪���� �����ؾ� �� �ʿ䰡 �ִ�. ���� �� 2 ���� 2-1-3 ������ ������ ������ ���� �湮�� ���� �ִ� �̿� �˰������� �ٻ簪�� ���ϴ� ����� ���� ���̴�. �� �˰������� �����ϱ� ���� �ɸ��� �ð��� �ſ� ���� �� �� �ִ�. ó���� �ؾ� �� ���� N ���� ���ø� �湮�ϴ� ������ ���� �ִ� ���̴�. �ϳ��� ���ø� �湮 ������ ���� ���� ������ �� ���ð� �̹� �湮 ������ ���ԵǾ� �ִ°��� ���ؾ� �Ѵ�. �̷��� �� ��, �� ���ø� ���� ���� �� ��������� (N - 1)/2 �� ���� �ϰ� �ǰ�, ��ü������ N(N - 1)/2 �� ���ϰ� �ȴ�. �� �˰������� �����ϱ� ���� �ʿ��� �ð��� N(N - 1)/2 �� Ȥ�� ������ N2 �� ������� �� �� �ִ�. �̴� ���� �Լ��� ����ϴ� �ð����� �ξ� ������. ������ �̷��� �Ͽ� ���� ����� �� �� �������� �����̴�. ���� ���� ���� ���ɸ鿡�� ������ �� ������ ���� ��� ���� �ʿ��� �ð����ٵ� ���� ��Ȯ���� ���Ͽ� �˾ƺ���.
A* �˰������� ���� ������ ��Ȯ�� ���� ã�� ����� ���� ���̴�. ���� h' �� h �� ���� ���Ͽ� ������ �ʴ´ٸ� A* �˰������� �ִ� ��θ� ã�� �� �ִ�. �̷��� ���, �ҿ�Ǵ� �ð��� h' �� ��Ȯ���� �� �ִ�. ���� h' �� h �� ����� �ٻ簪�� ����� �� �ִٸ�, ��� ��쿡 ���� h' �� ����Ȯ�Ͽ� Ž�� �ð��� �� �� �ɸ��� ��Ȳ�� �� �� �����Ѵ� �Ͽ���, A* �˰������� ��κ��� ��� �� ȿ�������� ����ȴ�. ��������� A* �˰������� �� ������ �������� Ư���� ������ h' �� ǥ���غ���. ��� h' �� ���� ������ ��ȭ�Ѵٸ� h �� ���� ���ϴ� ��찡 ���Ǿ� �ִ� ��θ� ã�� ���� ���� �ִ�. ���� ���� ��ο� �̷��� �Ͽ� ����� ��ο��� ���� ū ���̴� (h' - h) �� ���Ѵ�. ���� ���� h' �� ������ ������ �� �ִٸ�, ���� ������ ���ѵ� �� �ִ�. Ǯ�� ����� ������ �ذ��ϱ� ���Ͽ� ���� ������ �ƴ� ������� ���� �������� �˰������� ������ �� �ִ�. �� ��� �˷����� ���� ������ ��캸�� ��� ����� ���� ����� ���� ���ϱ� ���Ͽ� �ɸ��� ��� �ð��� ���Ͽ� ���� �� �ִ�. ����, ���� ���ϴµ� �ɸ��� �ð��� ���� ��Ȯ������ ���迡 ���Ͽ� �˰������� ������ �� �ִ�.
������� ������ ������, ���� ���ϴµ� �ɸ��� �ð��� ���� ��Ȯ������ ���踦 A* �˰����� �����Ͽ� �˾ƺ���. �̸� ���� ���� ���� ���� ���� ���� ����� ������ �м��Ѵ�. A* �˰����� �־��� ����� ������ ���Ǵ� h' �� �Լ��� ����ȴ�. ���� �ΰ� ���� �о��� �����鿡 ���Ͽ�, �־��� ���� ������ ����� ���ɿ� ���� ������ ��谪�� ���� ������ ��κ��� ��� �������ϴ�. �̷��� ��谪�� �Ϲ������� ������ �ʹ� ũ��. �ֳ��ϸ�, �ΰ� ���� �о߿��� ���Ǵ� ����, �� ���� ������ ������ ������ ���� ���� ���� ���� ������ �������� �ʾұ� �����̴�. �ΰ� ���� �о߿����� ������� ������ ���� �߿��ϴ�.
���Ƿ� ���õ� ���������� �˰������� ��� ������ ���������� �м��ϴ� ���� �־��� ���� ������ ��� ���� �м��ϴ� �Ϻ��� ��ƴ�. ������� ���� �м��� ���� Į�� ����� ����� �ùķ��̼ǿ� ���� �����ϴ� ���� ���� ���� ��찡 ���� �ִ�. ���� �������� ������� ������ �м��ϱ� ���Ͽ����� ������ ������ ���Ͽ� ���������� ����ϴ� ���� �Ұ����ϱ� ������ ���� ī�� ����� ���� �ʿ��ϴ�.
�� 2 �忡���� �ΰ� ���� �о��� ������ Ǯ�� ���� ���α��� �ۼ��� �� ���ؾ� �� ������ �ܰ迡 ���� �����ߴ�. �� �ܰ�� ������ ����.
1. ������ ��Ȯ�� �����϶�. ���� ����, ���� �������� �������� ���� �����ڿ� ��� ���� �� ��ǥ ���¸� �����϶�.
2. ������ �м��Ͽ� �ϰ� ���� �߿��� Ư¡ �� ������ ���ϴ� ���� ���϶�.
3. ������ ǥ���ϰ� ������ Ǫ�� ����� �ϳ� �̻� �����Ͽ� �̰��� ������ �����϶�.
�� �忡���� ���� ���� Ǯ�� ����� �Ұ��Ͽ� ���� ���� �� ����° �ܰ迡 ���� �����ߴ�. ���� �߿��� �鿡�� ������ �˰�������� �ٸ���. �̴� ������ ����.
�� �忡���� ���� ����� �����ϸ鼭 ������ ����� ���Ǵ� �� �Լ��� ���Ͽ� �����Ͽ���. ���� Ư���� ���� �������� �̷��� ������� ������ ����ϴ� ����� ���ؼ��� �Ͻ������� �����Ͽ���. ���� �忡���� Ư���� ������ ���� ������ �����ϱ� ���� ����Ǵ� Ư�� ������ ���� Ǯ�� ����Ӹ� �ƴ϶� �� ������ ǥ���ϴ� ����� ���� �ٷ��.
1. ���� Ǯ�̸� ���� Ž���� ���� (�˷��� ��� ���·κ��� ��ǥ ���·�) Ȥ�� ���� ��ǥ ���·κ��� ��� ���·�) ���� ����ȴ�. ��� ���ο� ���� Ư���� ������ ���� ������ ������ �����Ǵ°�?
2. ���� ���� Ǯ�̸� ���� Ž�� ���α��� ���� ������ ������ Ǯ�� ���� �ۼ��ȴٸ� Ž���� �������� Ȥ�� �������� ��������� �����϶�.
��
�����ν� (pattern recognition)
�� ���� ���� (blocks world)
�� ���
���� (language understanding)
3. ���� ������ ���� ������ ����� ���Ǵ� ������ �� �Լ��� ����� ���ƶ�.
��
���� ����
�� ���� ���� (theorem proving)
�� ������� ������ ����
4. � ������ ���� �������� ���� �켱 Ž���� ���� �켱 Ž������ ȿ�����ΰ�?
5. ���� �켱 Ž���� �ܼ��� ���� �켱 Ž������ �������� ���� �����ΰ�?
6. A* �˰������� ù �ܰ迡 ���� ���� (1) �� ��Ȳ�� ��������ٰ� ���� (a + b �� ��忡�� h' �� ���� a �̰� g �� ���� b ���� �ǹ��Ѵ�). �ι�° �ܰ迡���� (2) �� ��Ȳ, ���� ����° �ܰ迡���� (3) �� ��Ȳ�� ��������ٰ� ����.

��
� ��尡 ���� �ܰ迡�� Ȯ�� �����Ǵ°�?
�� �����ذ� �߰ߵȴٰ�
������ �� �ִ°�?
7. �˰�������
����Ŭ�� ������ �������� �����ϰ� �ۿ��ϴ� ������? ���ο� ��ΰ� �̹�
�����ϴ� ��忡�� ������� ��, ���� �� ��ΰ� �̹� ������� ��κ��� �������ϴٸ�
�ܼ��� �� ��θ� �������ν� ����Ŭ�� ������ �� �ִ�.
���� g �� ���� �ƴ�
����� ����Ŭ�� ��ΰ� ����Ŭ�� ���� ������ ��κ��� ���� ȿ������ �� ����.
���� ���, ��尡 ������� ������� ��ȣ�� �ٿ��� �ִ� �Ʒ� ���� (1) ��
����. ��� 4 �� ��� 6 �� �İ� ����� ����� �ܼ��� ����� �� ����. �̴�
��� 6 �� ������ ��ΰ� ��� 2 �� ������ ��κ��� ��� �����̴�. ������
������ ���� ��� 6 �� �İ� ���� ��� 5 �� ��ϵǴ� ���� ���� �� �ִ�.

���� ���� (2) ����, ���� 7 �κ��� ��� 6 ������ ��ΰ� ��ϵ��� �ʰ� ���� �ܰ迡�� ��� 7 �� ��� 3 �� �İ� ����� ����� �˰� �ȴٸ� ��� ���� ���ϴ°�?
8. A* �˰������� �ܰ� 2-3-1 ������ S ���� �ƹ��� �İ� ��嵵 ������ ���� ��尡 S �κ��� ���õ� ���� �䱸�Ѵ�. �� ��带 ȿ�������� �����ϱ� ���� S �� ó���ϴ� ����� ��� ������ �� �ִ°�? ��� E �� ����� �ٲ� ���, ������ ����� ���� ������ �����ϰ� ������� Ȯ���϶�.

9. ����Ŭ�� �����ϴ� ������ A* �˰������� �ۿ��� �� �ֵ��� ������ �� �ִ�. ����Ŭ�� �����ϴµ� �ʿ��� ���� ���ϱ� ���� �̷��� A* �˰������� ����� �� �ִ�. A* �˰������� ��� ��ȭ���Ѿ� �ϳ�? ��ȭ�� �˰������� �Ʒ� ���� (1) �� �����Ͽ� ��� C �� ����� ������ �� �ùٷ� ������ �� �ִ��� Ȯ���϶�. ���� ���� (2) �� (3) ����, ��� F �� ���� �ܰ�� ���� Ȯ��ǰ� ��� A �� �̰��� ������ �İ� ���� ������ ��, ������ �˰����� ���� ��� ������ �ùٸ��� �̷�����°� Ȯ���϶�.

10. �Ʒ� ������, (a) ó�� �迭�� ���ڸ� (b) �� ���� �迭�ǵ��� �ű�� ������ Ǯ���� �Ѵ�. �̶�, pickup, putdown, stack, unstack �̶�� �����ڸ� ����Ѵ�. ��� ������ ����� ����Ͽ� �� ������ Ǫ�� ���� �ո����ΰ�? �� ������?

11. ���� ��ȣ ��� ������ Ǯ�� ���� ���� ������ ���� ������ ���ȴ�. �� ��, �� ������ ������ �����϶�.
CROSS
+ROADS
DANGER
12. �� ��ҷκ��� �ٸ� ��ҷ� �Űܰ��� ������ Ǯ�� ���� ���-���� �м� ����� ��� ���dz� �����϶�. �� ��, �̿��� �� �ִ� �����ڴ� walk, drive, take the bus, take a cab, fly ��� �����϶�.
13. ������ ���� �켱 Ž�� ������ �̿��Ͽ� � ������ Ǭ�ٰ� ��������. �̷��� ���, Ž�� ������ Ʈ���� ������ ����Ͽ� �����ȴ�. ����, �� Ž�� ������ ���� ��, ���� �ٸ� ��尡 ��������� A �� ��������ٰ� ��������. �̿� ���ٿ� ���� ������ ���ȴٸ�, �� Ž�� ������ ��������� ��尡 �̹� ������� �ִ°��� �����ϴ� �ð���ŭ �ɸ���, ��尡 �̹� �����ϴ����� ���ΰ� ������� �ʴ´ٸ� B ���� ��带 �����ϴ� �ð���ŭ �ɸ���. ��� ������� ������ Ʈ���� ������ �����ϴ°�? �Ķ���� A �� B �ܿ� ��� ������ �ʿ��Ѱ�?
14. �ٻ簪�� ���ϴ� �ִ� �̿� �˰����� �������� �־ǰ��� ������ (log N + 1)/2 ���� ũ�� ������ �����϶�.