학습 (Learning)
인공지능 : Elaine Rich 저서, 유석인.전주식.한상영 편역, 상조사, 1986 (원서 : Artificial Intelligence, McGraw-Hill, 1983, Artificial Intelligence (2nd ed, 1991)), Page 327~348
7. 학습을 위한 발견 : AM (Discovery as Learning : AM)
8. 유사함에 의한 학습 (Learning by Analogy)
인공 지능학에 대해 자주 가해지는 비판 중의 하나는, 컴퓨터 시스템이 새로운 것을 배우고 환경에 적응할 수 있는 능력이 있을 때 까지는, 이 컴퓨터가 지능이 있다고 말할 수 없다는 것이다. 새로운 환경에 적응하고 새로운 문제들을 풀 수 있는 능력이 지능을 가진 물체의 중요한 특징이라는 것은 거의 의심할 여지가 없다. 그러한 능력을 가진 프로그램을 기대할 수 있겠는가? 계산학에 관한 가장 오래된 철학자 중의 한 사람인 에이다 어거스터 (Ada Augusta) 는 다음과 같이 서술했다.
수리 엔진 (analytical engine) 은 어떠한 것을 발생케하는 그 무엇도 할 수 없다.
그것은 단지 우리가 그것에서 실행하도록 지시하는 사항들만을 할 수 있다.
[Lovelace, 1961, p.284]
이러한 근거를 가지고 여러 인공 지능학에 대한 비평가들은 컴퓨터는 배울 수 없다고 말해왔다. 허나, 실제로 결코 배울 수 없다고 말하고 있는 것은 아니다. 어떠한 것도 우리가 컴퓨터에게 그에 주어진 입력을 실행 성능이 점차로 진보하도록 하는 방향으로 그가 해석하게끔 하는 것을 막지는 못한다.
처음부터 컴퓨터가 배우는 것이 가능한지 아닌지를 요구하는 것보다, 오히려 우리가 배운다고 말할 때 이것이 정확히 어떠한 행동들을 뜻하여 또한 어떠한 기계적인 동작들이 우리가 그러한 행동을 할 수 있게끔 하는지를 알아내려 하는 것이 훨씬 더 진보적이다. 먼저 학습이란 무엇인가에 대한 답을 해보도록 하자.
많은 심리학자들이 학습에 대해 오랫동안 연구해 왔기 때문에 아마도 그들이 생각하는 학습의 정의가 도움을 주지 않을까 한다. 다음과 같은 정의가 주어질 수 있다 :
위 정의의 주 문제점은 이 정의가 이용되기에는 너무 모호하다는 것이다. 우리는 학습을 행할 수 있는 방법들을 생각하기 위해 좀더 정확한 학습의 정의를 필요로 한다.
이를 위한 한 방법은 학습을 하나의 작업으로 정의할 것이 아니라, 학습 프로그램을 다른 프로그램들과는 달리 특정지우는 것이다. 불행히도 학습 프로그램이 정확히 무엇인가를 정의하려는 많은 시도 [Smith, 1977] 가 있어 왔음에도 불구하고, 그렇게 만족할 만한 정의가 내려지지 못하고 있다. 여기에는 두 가지 이유가 있다.
이러한 두 개의 문제점은 새로운 학습 방법을 찾기 보다는 생각되어지는 특정 학습 작업에 우리가 이전에 이만 검토한 지식 표기 (knowledge representation) 와 문제 풀이 (problem-solving) 를 위한 방법들을 적용하는 것이 학습 프로그램을 만드는 문제에 대한 정확한 길이라는 것을 암시하고 있다. 물론 우리가 학습 문제를 푸는 일반적인 방법을 생각한다는 것은, 사실은 적절한 학습 과정과 관련된 문제 영역에 관한 특정한 지식들이 중요하지 않다는 것을 뜻하는 것은 아니다. 우리가 이미 보인 바와 같이 모든 어려운 문제 풀이 작업도 지식의 이용을 요구한다. 우리가 이미 보인 바와 같이 모든 어려운 문제 풀이 작업도 지식의 이용을 요구한다. 실제로, 그러한 지식에 대한 필요가 문제 풀이 작업의 크기 (즉, 출발 지점과 목적 지점 사이에 생각되는 탐색 공간의 크기) 가 커짐에 따라 같이 커진다. 대부분의 학습 작업자들이 매우 큰 규모의 문제들이기 때문에 이들은 이용되어질 수 있는 양질의 지식에 크게 의존할 것이다. 허나 우리는 기본 방법들이 다른 영역에서와 같이 그러한 지식이 얻어질 수 있도록 모형 작업을 제공한다는 것을 볼 것이다.
인간들의 학습과 컴퓨터의 학습간의 유사함을 관찰하는 것은 재미있는 일이다. 사람들은 그들의 머리를 보완시키는 신경 조직 구조를 변화시키는 것에 의해 학습을 한다. 그렇다면 우리는 왜 단순한 조직을 가지고 시작하여 그 조직에 여러 연결망을 구축하는 것에 의해, 주어진 여건을 보강시키도록 하는 학습 프로그램을 만들 수 없겠는가? 또는, 신경 조직의 신인 동형 동성론이 생각되어야만 한다면 왜 우리는 무작위로 만들어진 프로그램 구조를 가지고 시작하여 보다 더 유용한 구조로써 진보시킬 수 없겠는가? 문제점은 학습이 어렵다는 점이다. 만일 아무 것도 없는 상태로부터 시작한다면 그로부터 단지 약간의 진전이 있는 것만을 얻을 것이다. 사람이 어려운 것을 배울 때 이미 그들이 알고 있는 다른 약간 덜 어려운 것들에 근거를 두고 이를 행하는 것이다. 무작위 구조를 가지고 시작하는 학습 프로그램을 만드는 많은 시도가 있어 왔음에도 불구하고, 이들 중에 어느 것도 그렇게 성공적인 것이 되지 못하고 있다. 이러한 이유 때문에 우리는 이러한 방법을 여기에서 더 이상 거론치 않을 것이다. 더 관심있는 독자들은 [Selfridge, 1959], [Rosenblatt, 1958 ; Minsky, 1972], [Friedberg, 1958] 을 참조할 수 있다.
우리가 이미 위에서 말한 것처럼 가장 간단한 유형의 컴퓨터 학습은 단순히 자료를 기록하는 것이다. 많은 프로그램들이 많은 양의 자료를 기록할 수 있으나, 학습 프로그램으로써는 별 의의가 없다. 허나 기계적 학습이라 알려진 단순한 자료 저장을 이용하여 개발된 몇 가지 방법들은 단순한 학습이 프로그램의 다음 행동에 영향을 미친다는 것을 보여 주고 있다.
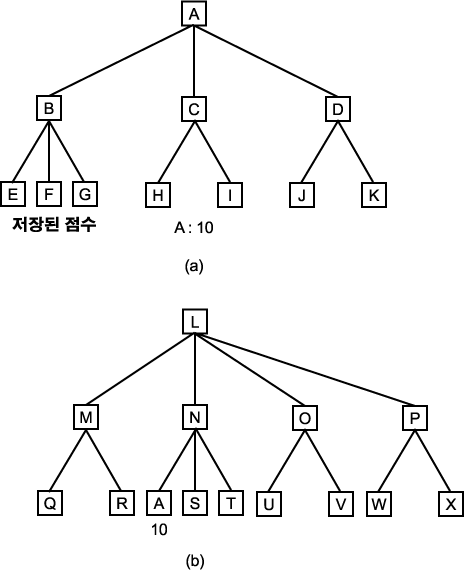
제 4 장에서 우리는 오래된 게임 프로그램의 하나인 사무엘의 체커 (checker) 프로그램에 대해 언급했다 [Samuel, 1963]. 이 프로그램은 체커 게임 발명자를 충분히 이길 수 있도록 게임 운영법을 배웠다. 이것은 그 종류의 학습을 개발했다. 즉, 우리가 지금 거론할 기계적 학습과 다음 장에서 거론할 변수 조정법이다. 사무엘의 프로그램은 체커-게임-트리를 이해하기 위해 최대-최소 (mini-max) 탐색 과정을 이용했다. 모든 그러한 프로그램들을 이용하는 경우에서 처럼, 시간 제약이 이 과정을 트리에서 단지 소수의 레벨 (level) 들 만을 탐색하도록 했다 (정확한 레벨 수는 여건에 따라 변화했다). 이것이 더 이상 탐색할 수 없을 때 게임판 위의 위치에 대해 정적 평가 함수 (static evaluation function) 를 적용하여 그 함수값을 가지고 게임-트리의 탐색을 계속했다. 이것이 트리를 탐색하여 마지막으로 계산된 함수값을 트리 루트 (root) 까지 후진시켜 발생되는 점수가 이 루트에 의해 표시되는 게임판 위의 위치에 대한 함수값으로 주어졌다. 그 다음 이것은 이러한 함수값에 의거하여 가장 최선의 방향을 결정하여 그 방향으로 행하게 했다. 허나, 이것은 또한 트리의 루트에 의해 주어지는 게임판 위치와 그에 주어진 정수를 기록했다. 이러한 상황은 그림 1(a) 에서 보여진다.
그림 1
이제는 그 후에 일어나는 게임의 상태로써 그림 1(b) 에 보여진 상황이 일어났다해보자. L 위치에 대한 정수를 계산키 위해 정적 평가 함수를 사용하는 대신에 A 위치에 대해 이미 저장된 정수를 이용할 수 있다. 이는 A 에 주어진 정수가 후진 방법에 의해 계산되었기 때문에 전에 A 를 위해 탐색에서 생각되어졌던 레벨 (level) 의 수 보다 몇 개의 더 많은 수의 레벨을 탐색한 결과를 낳게 한다.
이러한 유형의 기계적 학습은 매우 간단하다. 이는 어떠한 복잡한 문제 풀이 능력을 포함치 않은 것처럼 보인다. 허나 이것 또한 좀더 복잡한 학습 시스템에서 중요시 되고 있는 어떠한 능력을 필요로 한다. 그러한 능력은 다음과 같다.
방향 설정 (Direction) - 보다 많은 물체들이 저장되어지고 어느 주어진 위치에서 그들의 대부분이 생각되어짐에 따라 프로그램이 그들 중에서 가장 좋은 방향으로 이끌어갈 수 있는 물체를 선택할 수 있어야만 한다는 것은 매우 중요한 일이다. 사무엘의 프로그램에서는 이를 위해 적은 수의 움직임으로 도달할 수 있는 위치가 보다 많은 수의 움직임으로 도달할 수 있는 위치보다 더 좋게 평가되어졌다. 허나, 복잡한 문제 형상에서는 선택된 전략법에 기여할 수 있는 물체들을 그렇게 할 수 없는 물체들보다 뽑아낼 수 있는 방법으로 저장된 물체들을 특정지우기가 어려워진다.
이 시점에서 학습은 일종의 문제 풀이법과 유사하게 취급 되어질 수 있음을 알 수 있다. 학습의 성공여부는 그에 연관된 지식 근거를 어떻게 좋고 조직적으로 형성하는가에 달려 있다.
많은 프로그램들이 여러 근원으로부터 나오는 정보들을 하나의 요약적인 통계 숫자로 결합하는 평가 프로시쥬어에 의존한다. 게임 프로그램은 그에 대한 정적 평가 함수에 의존한다. 이 평가 함수는 각각의 유리함과 유동성과 같은 여러 요소들을 결합하여 특정한 게임판의 가능성을 나타내주는 하나의 숫자를 산출한다. 패턴 (pattern) 인식 프로그램은 때때로 여러 특징들을 결합하여 주어진 입력들이 놓아져야만 하는 정확한 범주를 결정한다. 이러한 프로그램을 만드는데 있어서 현재 생각되어지는 각각의 특성에 얼마만한 비중을 두어야만 하는 것을 미리 안다는 것이 항상 쉽지는 않다. 올바른 그러한 비중을 알아내는 한 방법은 올바른 기준에 대한 어느 예측된 값을 가지고 시작하여 프로그램으로 하여금 그의 경험을 가지고 그 기준들을 수정하게 하는 것이다. 전체적인 성공으로 이끌게끔 좋게 예측된 특성들은 그들의 비중이 늘어날 것이며, 그렇지 않은 특성들은 그들의 비중이 줄어 들어서 아마도 완전히 하락되는 지점까지 갈 것이다.
사무엘의 체커 프로그램은 이러한 학습 방법을 전에 묘사된 기계적 학습 방법과 함께 이용했다. 이리하여 이러한 학습 방법의 좋은 예로써 사무엘의 학습 프로그램이 생각되어진다. 이 프로그램은 그의 평가 함수에서 다음과 같은 다항식을 이용했다 :
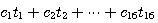
t 항들은 전체 평가에 기여하는 16 개 특성들의 값들로 주어진다. c 항들은 이러한 값들에 주어지는 변수 (비중) 들이다. 학습이 진행됨에 따라 c 값들은 변할 것이다.
변수 조정에 의거한 학습 프로그램의 구성에 있어서 가장 중요한 문제는 "언제 변수의 값이 증가되어야만 하고, 언제 감소되어야만 하는가?" 이다. 두번째 답하여질 문제는 "얼마만큼 그값이 변화되어져야만 하는가?" 이다. 첫번째 질문에 대한 간단한 답은 마지막 결과를 정확히 예측하는 항들의 변수들은 증가되어야만 하고 그렇지 않은 변수들은 감소되어야만 한다는 것이다. 어떠한 영역에서는 이것이 쉽게 행해질 수 있다. 만일 패턴 인식 프로그램이 입력을 인식키 위해 그의 평가 함수를 이용하여 올바른 답을 얻었다면 그 답을 예측케 한 모든 항들은 그들의 변수값을 증가하게 해야만 할 것이다. 허나 게임 놀이 프로그램에서는 그렇게 간단치 않다. 왜냐하면 프로그램이 각각의 움직임으로부터 어떠한 구체적인 회답을 얻지 못하기 때문이다. 게임의 마지막까지는 그것이 프로그램이 이길 수 있는 움직임인지 아닌지를 확실히 알 수가 없다. 심지어 그 프로그램이 어떠한 좋지 않은 방향으로 움직이게끔 했다 하더라도 프로그램이 이길 수가 있다. 어느 한 결과를 유도하는 각각의 단계에 적절하게 의무성을 책정하는 문제는 책임 배정 문제 (credit assignment problem) 로 알려져 있다.
사무엘의 프로그램은 이 문제를 풀기 위해 한 방법 (비록 완전치는 않지만) 을 이용하고 있다. 변수들에 대한 주어진 처음 값들이 매우 좋아서 전체 평가 함수가 우리가 원하는 만큼 정확하지는 않아도 정확한 점수를 적절히 측정할 만한 점수를 산출한다고 가정해 보자. 그럼 이러한 평가함수는 그 자체에 회답을 하는데에 이용되어질 수 있다. 좀더 높은 값들을 가진 위치로 유도하는 일련의 움직임들은 좋게 평가되어질 수 있다 (그리고 평가 함수에서 그들을 산출케 한 항들은 보강되어질 수 있다).
그러나, 이러한 방법의 한계성 때문에 사무엘의 다른 두 가지 일들을 했다. 하나는 진보가 이루어지고 있다는 것을 위한 추가 시험을 했다. 다른 하나는 이러한 과정의 계속 여부를 조정하는 추가의 너찌 (nudge) 를 만들었다 :
점수 함수에서의 항들의 비중에 대한 계속적인 변경을 통한 이러한 학습 과정은 많은 한계성을 가지고 있다. 이 대부분은 학습 과정이 다루고 있는 문제 구조에 대한 지식과 그 문제들은 이루고 있는 요소들 사이에 논리적 관계에 관한 충분한 탐색이 없는 것으로부터 일어난다. 더우기 학습 과정은 다양한 '언덕 오르기 방법' (Hill Climbing) 이기 때문에 이는 다른 언덕 오르기 방법 프로그램이 겪는 것과 같은 똑같은 어려움을 겪는다. 변수 조정은 분명히 전체적인 학습 문제에 대한 해결책은 아니다. 이는 매우 적은 추가의 지식이 이용되어지는 경우에서든지 또는 이것이 보다 더 깊은 지식이 이용되는 방법들이 합성되어지는 프로그램에서는 때때로 유용한 방법이다.
이 시점에서 우리는 학습이 일종의 문제 풀이와 유사하게끔 보이는 두번째 방법을 관찰했다. 이는 유사한 탐색 알고리즘에 의거한다. 이 경우에는 '언덕 오르기 방법' 이다.
학습이 일종의 문제 풀이를 위한 형태로써 간주되어질 수 있고 일반적인 문제 풀이법에 의해 풀어질 수 있다는 개념의 좋은 예는 오래전 시도되어진 한 학습 프로그램에 의해 보여질 수 있다.
GPS [Newell, 1963b] 는 오래전 개발된 문제 풀이 시스템이다. 이것은 3-6-7 절에서 검토되어졌던 '방법-목적 분석 방법' (means-ends analysis) 에 기본을 두고 있다. 어느 특정한 작업 여건에서 이 방법을 이용하기 위하여는 주어진 문제 상태와 목적 상태에 존재하는 각각의 중요한 차이점을 줄이는데 이용되는 일련의 문제 법칙들을 나타내는 일람표가 주어져야만 한다. 가령 우리가 문제 풀이 프로그램이 그러한 일람표를 주는 것 대신에 프로그램 자신의 경험으로부터 일람표를 습득하는 그러한 프로그램을 원한다 해보자. 이것이 어떻게 가능한 것인가?
차이 일람표 (difference table) 를 습득하는 한 방법은 우리가 이전에 검토했던 변수 조정 과정과 유사한 방법을 적용하는 것이다. 먼저 줄여야 할 차이점이 있을 때 아무 문제 법칙이나 무작위로 뽑아 시도한다. 그 다음 일람표에 그러한 시도의 성공률을 기록한다. 결국 일람표는 주어진 법칙이 주어진 차이를 줄여주는 가능 비율을 나타나게 된다. 그러면 그 비율들은 어느 유효한 한계 수치 이상의 비율을 가진 모든 합에 가를 대입하고 그렇지 않은 모든 항에 부를 대입하는 것에 의해 가부항들로 바꾸어질 수 있다. 허나 비교적 작은 작업 범위에 대해서도 많은 수의 다른 차이 일람표들이 존재할 수 있다는 것을 유의하라. 만일 보다 많은 지식이 주어질 수 있으면, 보다 효과적인 학습 과정이 가능할지 모른다. 이것이 행해지는 법을 보기위해 각각의 이용할 수 있는 문제 법칙의 구조를 생각해 보자. 각각의 법칙은 그의 입력 형태를 묘사하는 왼쪽 부분과 그의 출력 형태를 묘사하는 오른쪽 부분을 가지고 있다. 두 부분을 비교하는 것에 의해 우리는 문제 법칙에 의해 만들 수 있는 변화와 이로부터 그 법칙이 줄일 수 있는 차이를 유도할 수 있다. GPS 가 새로운 영역에 적용되어질 때 일어나는 보다 더 흥미있는 학습문제는 문제 법칙들을 선택할 때 이용되는 일련의 효과적인 차이들을 결정하는 문제이다. 이러한 작업들 역시 우리가 법칙-차이 일람표 (operator-difference table) 를 구성하는 문제에서 처음 시도했던 방법과 유사한 제어할 수 없는 '언덕 오르기' 과정으로써 이루어질 수 있다. 허나, 이러한 문제에 대한 좀더 좋은 시도 방법은 법칙-차이 일람표를 구성하는 작업과 꼭 같이 우리가 문제 자체에서 발견할 수 있는 어떠한 구조를 개발하는 것이다. 우리가 이를 시도할 때 우리는 GPS 자체가 문제를 풀기위해 이용하는 방법을 GPS 가 사용하는 일람표 상의 차이들을 습득하는 문제에 응용할 수 있다.
주어진 문제 영역에서 쓰이는 GPS 의 또다른 사본에 의해 이용되어질 일련의 효과적인 차이들을 알아내는 문제에 GPS 를 적용하기 위해 다음과 같은 단계가 필요하다 :
1. 적용 영역에서 이용되어질 일련의 문제 법칙들을 입력으로 준다.
2. 학습 작업에 대한 목적을 정의한다. 이 목적은 적용 작업을 위한 일련의 효과적인 차이들을 산출하는 것이다.
3. 학습 작업에 의해 사용되어질 일련의 차이들을 정의한다. 이는 일련의 효과적인 차이들에 의해 만족되는 기준과 주어진 일련의 차이들에 대해 그들이 그 기준을 얼마나 잘 만족시키는 가를 알아보는 방법에 의해 행하여진다.
4. 학습 작업을 위한 일련의 문제 법칙들을 정의한다. 이러한 법칙들은 적용 영역에서 필요로 하는 차이들을 구성할 수 있어야만 한다. 이러한 차이들을 묘사하는 한 좋은 방법은 그들을 알아내는 프로그램을 만드는 것이다. 이와 같이 하여, 학습 작업에 있어서 문제 법칙들이 적용 작업을 위한 프로그램을 구성하는 데에 이용되어진다.
[Newell, 1960a] 는 이러한 과정의 훨씬 세부적인 묘사와 또한 이러한 학습 작업의 실행에 있어 GPS 의 효율성을 보이기 위해 만들어진 시뮬레이션 실험의 결과를 부여 주고 있다. 이러한 시도에 의해 예증되는 가장 중요한 원리는 학습이 하나의 문제 풀이로써 잘 주어질 수 있다는 것이다. 일면으로 보면 일련의 효과적인 차이들을 유도하는 문제는 이러한 차이들을 습득하는 문제이다. 다른 한면으로는 이 문제는 단순히 주어진 일련의 특성들을 만족시키는 구조 (이 경우에는 일련의 차이들) 를 구성하는 것이다.
그러한 구조의 발견은 논리적인 증명 또는 영어에서 질문에 대한 답변들과 같은 다른 구조들을 발견할 때 쓰이는 방법과 아주 흡사한 방법으로 행해질 수 있다.
유형화 (Classification) 는 특정한 입력에 그가 속해지는 한 유형의 이름을 주는 과정이다. 유형화 과정이 선택할 수 있는 유형들은 여러 방법으로 묘사되어질 수 있다. 그들의 정의는 그들의 사용 용도에 의거한다. 유형화는 많은 문제-풀이 작업들 중의 중요한 요소이다. 가장 단순한 형태로 이것은 직선적인 식별 작업으로 주어진다. 이의 예는 "이것은 어떠한 편지인가?" 와 같은 질문이다. 허나 때때로 유형화는 또 다른 동작 내에 끼워져 있다. 이것이 일어나는 두 가지 방법을 보기위해 다음과 같은 산출 법칙을 포함하는 문제-풀이 방법을 생각해 보자 :
If : the current goal is to get from place A to place B, and there is a WALL separating the two places
then : look for a DOORWAY in the WALL and go through it.
이 법칙을 성공적으로 이용하기 위해 시스템의 부합 단계는 물체를 WALL 로 밝힐 수 있어야만 한다. 이것이 없이는 법칙이 절대로 불려질 수 없다. 그러면 그 법칙을 적용하기 위해 시스템은 DOORWAY 를 인식할 수 있어야만 한다.
유형화가 행하여지기 위해서는 이용되어지는 유형들이 정의되어져야만 한다. 이는 다음과 같은 여러 방법으로 행해질 수 있다.

1-3-2 절에서 거론된 바와같이 이러한 각각의 일반적 방법들은 그 나름대로의 유리한 점과 불리한 점을 가지고 있다. 여기에서 주어진 첫번재 체계에 의한 통계학적 방법은 때때로 두번째에 의한 구조적 방법보다 더 효과적이다. 허나 두번째에 의한 방법은 보다 더 융통성이 있고 확대될 수 있다.
유형들이 묘사되어지는 방법에 관계없이 직접 손으로 좋은 유형의 정의들을 구성하는 것은 때때로 어렵다. 이는 완전히 이해되어지지 않거나 또는 급속히 변하는 영역에서는 특히 어렵다. 이리하여 그 자신이 유형 정의를 유도할 수 있는 유형화 프로그램을 만드는 개념은 호소력 있게 받아 들여질 수 있다. 유형 정의들을 구성하는 이러한 작업은 개념 학습이라 불리운다. 물론, 이 작업을 위해 이용되는 방법들은 유형 (개념) 들이 묘사되어지는 방법에 의해 좌우된다. 만일 유형들이 정수 함수들에 의해 묘사되어 진다면 개념 학습은 4 절에서 설명된 변수 조정 방법을 이용하여 행해질 수 있다. 그러나 만일 우리가 유형들을 구조학적으로 정의하기를 원한다면 유형 정의들을 습득하기 위한 새로운 방법이 필요하다. 이 절의 나머지에서 그러한 방법이 제시될 것이다.
구조학적 개념 학습 프로그램의 좋은 예는 [Winston, 1975a] 에서 주어지고 있다. 그래서 이것을 우리의 모델 (model) 로 이용할 것이다. 이 프로그램은 단순한 블럭 (block) 세계 영역에서 동작되었다. 예를 들면, 이것은 그림 2 에서 보여지는 HOUSE, TENT ARCH 라는 것을 배웠다. 이 그림은 또한 각각의 개념에 대한 근사항 (near-miss) 을 보여주고 있다. 근사항이란 질문에 대한 개념의 예가 아니라, 그러한 에에 아주 유사한 물체를 말한다.
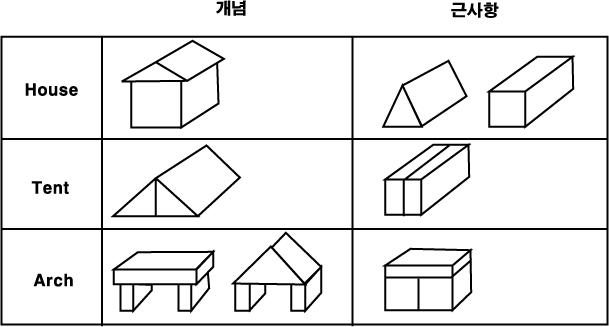
그림 2
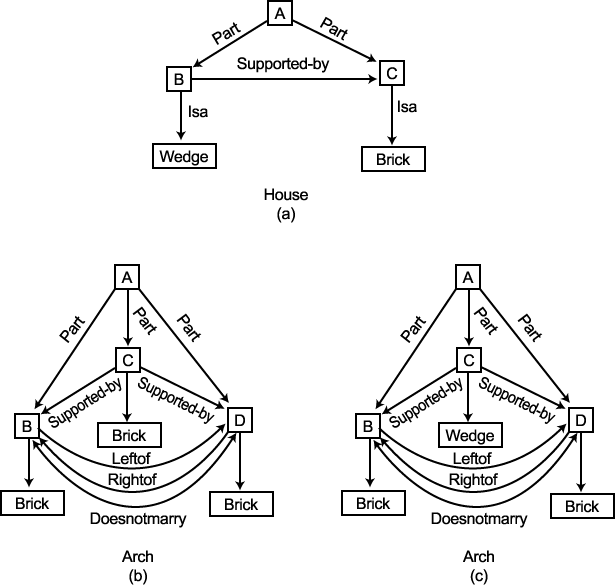
그림 3
이 프로그램은 블럭 세계 구조를 이루는 선 그림 (a line drawing) 을 가지고 시작했다. 이것은 선 그림을 분석하고 물체의 구조적 묘사를 나타내는 시맨틱 네트 (semantic net) 를 형성하기 위해 3 절에서 10-3 절에서 묘사한 것과 같은 과정을 이용했다. 다음에 이 구조적 묘사는 학습 프로그램에 입력으로 주어졌다. 그림 2 의 HOUSE 에 대한 그러한 구조적 묘사의 예는 그림 3(a) 에서 보여진다. 점 A 는 두 개의 부분들 WEDGE 에 대한 점 B, 그리고 BRICK 에 대한 점 C 로 이루어지는 전체 구조를 나타낸다. 그림 3(b) 와 3(c) 는 그림 2 의 두 개의 ARCH 구조들의 묘사를 나타낸다. 이 묘사들은 꼭대기에 있는 물체들의 형태들에 대한 것, 하나는 BRICK 이고 다른 하나는 WEDGE 을 제외하고는 서로 동일하다. 두 개의 받치고 있는 물체들이 LEFTOF 와 RIGHTOF 에 의해 연결되고 있을 뿐만 아니라, 그들이 MARRY 하지 않는다고 말해주는 DOESNOT MARRY 에 의해 연결되고 있음을 주시하라. 만일 두 개의 물체가 서로 접하는 면들을 가지고 있고, 또한 공통의 가장자리를 가지고 있다면, 그들은 MARRY 한다. MARRY 에 대한 정의는 ARCH 에 대한 정의를 내리는데 매우 중요하다. 이것이 그림 2 에서 보여지는 처음의 아치 (arch) 구조와 그에 근사한 아치 구조 사이의 차이점이다.
Winston 프로그램이 개념 형성 문제에 대해 사용하는 근본적 방법은 다음과 같이 묘사될 수 있다.
1. 개념에 대한 하나의 알려진 예의 구조적 묘사를 가지고 시작한다. 이 묘사를 개념 정이라 부른다.
2. 개념에 대한 또 다른 알려진 예들의 묘사를 조사한다. 세워진 정의를 이러한 것들이 포함될 수 있도록 일반화한다.
3. 개념의 근사항에 대한 묘사들을 조사한다. 이들을 배제하도록 세워진 정의를 제한한다.
이 과정에서 두번째 단계와 세번째 단계는 서로 얽혀질 수 있다.
이 과정의 두번째 단계와 세번째 단계는 구조들 사이에의 유사함과 차이점을 찾아낼 수 있는 비교 과정에 상당히 의존한다. 이 과정은, 주어진 산출 법칙이 특정한 문제 상태에 적용될 수 있는지 없는지를 결정하는 과정과 같은, 여느 다른 부합 과정에서 쓰이는 방법으로 적용되어져야만 한다. 유사함뿐만 아니라 차이점도 발견되어야만 하기 때문에 이 과정은 정확한 비교와 근사한 비료를 함께 실행해야만 한다. 이 비교 과정의 출력은 그에 주어진 입력 구조들 사이의 공통점을 나타내는 골격 구조이다. 이것은 입력들 사이의 특정한 유사함과 차이점을 나타내는 일련의 비교 사항들로 주석이 달아진다.
이 방법이 어떻게 작용되는지를 보기 위해 아치 (arch) 가 무엇인가를 배우는 과정을 살펴볼 것이다. 먼저 그림 3(b) 와 같은 아치 묘사가 주어졌다 하자. 그럼 이것이 ARCH 개념의 정의가 된다. 그 다음 그림 3(c) 와 같은 아치 묘사가 주어졌다 하자. 비교 과정은 그것이 C 점들에 의해 표현되는 물체들이 동일하지 않다는 점을 제외하고는 두 개의 입력 구조들에 대한 유사한 구조를 산출할 것이다. 이 구조는 그림 4 와 같이 주어진다. 점 C 로부터 나오는 C-NOTE 연결 부분은 비교 과정에 의해 발견되는 차이점을 묘사한다. 이것은 차이점이 ISA 연결 부분에서 일어나고 처음 구조에서는 ISA 연결 부분이 BRICK 을 가리키고 두번째 구조에서는 WEDGE 를 가리키고 그리고 만일 우리가 BRICK 와 WEDGE 에서 나오는 ISA 연결 부분들을 따라가 보면 이러한 연결 부분들이 결국에는 합쳐진다는 것을 주지하고 있다.
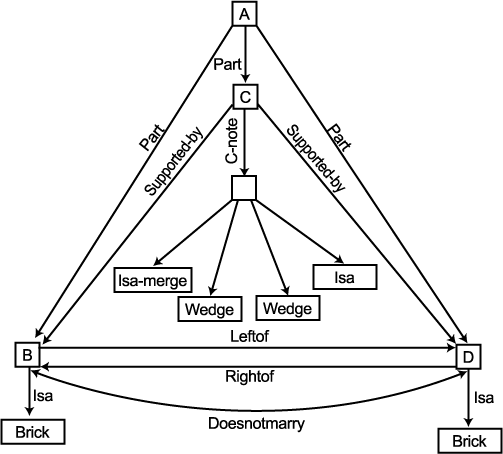
그림 4
이 시점에서 ARCH 개념의 새로운 묘사가 발생되어질 수 있다. 이 묘사는 점 C 가 BRICK 이나 WEDGE 이어야만 한다고 단순히 말할 수 있다. 허나 이러한 특별한 연결은 이미 알려진 중요한 사항들에 별 영향을 끼치지 않기 때문에 BRICK 과 WEDGE 에 대한 ISA 부분을 그들이 합쳐지는 부분까지 추적하는 것이 더 좋다. 이것이 점 OBJECT 에서 일어난다. 가정한다면 그림 5 에 보여지는 ARCH 정의가 세워질 수 있다.
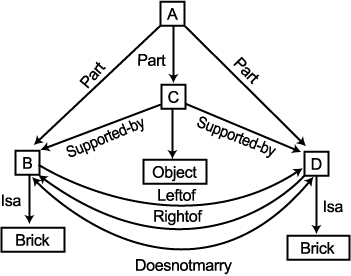
그림 5
다음은 그림 2 에서 보여지는 근사한 물체들이 주어졌다 하자. 이번에는 비교 과정이 현재 세워져 있는 정의와 근사항 사이의 유일한 차이점이 점 B 와 점 C 사이의 연결 부분에 있다는 것을 주지할 것이다. 허나 이것은 근사항이기 때문에 우리는 이를 포함하도록 정의를 넓히기를 원하지 않는다. 대신에 이것이 배제되도록 정의를 제한하기를 원한다. 이를 위해 우리는 제시된 몇 개의 예에서 가능함을 단순히 표기하는 DOESNOTMARRY 연결 부분을 수정한다. 이제는 MUSTNOTMARRY 로 말해져야만 한다.
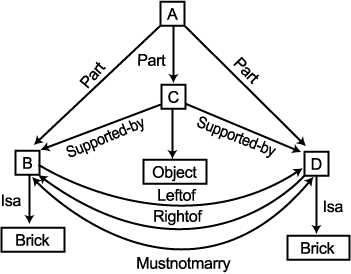
그림 6
이 시점에서 ARCH 묘사는 그림 6 에서 보여진다. 실제로 MUSTNOTMARRY 는 완전히 새로운 연결 부분이어서는 안된다. MARRY 와 DOESNOTMARRY 와 MUSTNOTMARRY 사이의 관계를 반영하는 연결 부분상의 어떠한 구조가 있어야만 한다. 이는 독자들에게 연습 문제로 남겨둔다.
우리가 방금 검토한 개념 학습에 대한 방법은 여러 종류의 학습 프로그램에 의해 이용되어져 오고 있다. 비록 그러한 모든 프로그램들이 동일하지는 않지만 그들은 하나의 중요한 특성을 공유하고 있다. 그들은 주어진 여건에서 그들에게 습득되는 개념의 예들을 주는 어떠한 입력에 의존하고 있다. 허나 그들은 여러 중요한 측면에서 달라질 수 있다.
우리는 이미 거론되었던 일반적 문제 풀이 방법들이 학습 프로그램의 구성에 어떻게 적용되는지에 대한 또다른 예를 보았다. 이러한 방법들은 다음과 같은 항들을 포함한다 :
학습이란 하나의 물체가 지식을 얻는 과정이다. 보통 그러한 지식은, 선생으로써 학생에게 공급할 수 있는, 어떠한 몇 개의 다른 물체들에 의해 이미 가져지고 있다. 발견 (discovery) 이란 어떠한 물체가 지식을 이미 그것을 가지고 있는 다른 물체의 도움없이 얻는 일종의 제한된 형태의 학습이다. 때때로 어떠한 지식은 그 누구도 가지고 있지 않을 수 있다. 우리는 이같은 것에 대해 '과학적 발견' 이란 절을 사용한다. 발견이란 분명히 학습이다. 허나 이는 또한 다른 유형의 학습보다 보다 더 뚜렷한 문제-풀이이다. 그럼 예를 들어 수학에서 어떠한 것을 발견할 수 있는 프로그램을 만들기를 원한다 해보자. 우리는 그러한 프로그램이 우리가 이미 검토한 문제-풀이 방법들에 상당히 의존해야만 한다고 생각한다. 실제로 AM [Lenat, 1977a ; Lenat, 1977b ; Lenat, 1982b] 이라 불리우는 그러한 프로그램이 존재한다. 이는 많은 양의 표준 계수 이론 (Number Theory) 의 발견에 근본이 되었던 몇 개의 기본적인 집합 이론 (Set Theory) 개념들을 가지고 시작했다. AM 의 자세한 구조에 대해서는 [Lenat, 1977a ; Lenat, 1977b ; Lenat, 1982b] 를 참조하라.
유사함 (analogy) 이란 강력한 추론 (inference) 도구이다. 이는 간결히 묘사되어진 물체들 사이의 비슷함 (similarity) 을 말한다. 허나 동시에 이러한 비슷함을 알아내는데 필요한 작업양의 일부를 말하는 사람 (또는 선생, 정보 처리자) 으로부터 듣는 사람 (또는 학생) 으로 운반케 한다. 그래서 예를 들면 만일 내가 너에게 '빌은 소방차와 같다' 라고 말한다면 나는 이미 너에게 어떠한 것을 말했다. 허나 이러한 정보를 이용하기 위해 너는 '빌이 소방차와 같다' 라고 주어진 방법 위에서 결정해야만 한다.
유사함을 통한 사고의 기계화에 관한 오래 전에 행해진 작업은 지능 테스트에 제시되는 일종의 인위적 여건 위에서 행하여졌다 [Evans, 1968]. 허나 실제로 학습은 좀더 실질적인 여건 위에서 유사함의 결과로써 일어나는 것이다. [Winston, 1979] 은 이를 행하는 시스템을 묘사하고 있다. 이는 우리가 다른 학습 시스템에서 본 방법들의 많은 부분을 똑같이 사용하고 있다. 우리는 이제 이러한 방법들을 검토하고 이들이 어떻게 작용하는지를 볼 것이다.
|
BILL |
ISA SEX ACTIVITY-LEVEL LOUDNESS AGGRESSIVENESS |
PERSON MALE
MEDIUM |
|
FIRE-ENGINE |
ISA COLOR ACTIVITY-LEVEL LOUDNESS FUEL-EFFICIENCY LADDER-HEIGHT |
VEHICLE RED FAST VERY HIGH AVERAGE XOR (LONG, SHORT) |
|
AGGRESSIVENESS |
ISA |
PERSONALITY-TRAIT |
물체들에 관한 지식이 일련의 골격 구조들로 표시된다고 가정하자. 그러면 유사함을 통한 학습은 하나의 골격 (근원지) 의 슬롯 (slot) 들로부터 다른 골격 (목적지) 의 슬롯들로 값들을 이전시키는 것으로써 묘사되어질 수 있다. 이러한 이전의 두 가지 단계를 통해 행해진다 :
1. 목적 골격으로 이전되어지는 값들을 지닌 제안되어진 슬롯을 발생키 위해 근원 골격을 이용한다.
2. 1 단계에 제안되어진 유사함을 여과하기 위해 목적 골격에 현재 존재하는 정보를 이용한다.
이러한 과정의 예로써 위에서 주어졌던 빌 (Bill) 과 소방차 (fire-engine) 사이의 유사항을 생각해 보자. BILL 과 FIRE-ENGINE 에 대한 구조 골격은 그림 9 에서 보여진다. 이 예에서 FIRE-ENGINE 은 근원 골격이고 BILL 은 목적 골격이다. 우리의 목적은 FIRE-ENGINE 으로부터 집어낸 정보들로 BILL 의 내용을 증가시키는 것이다. 이는 다음과 같은 경험적 지식 (heuristics) 을 이용하여 할 수 있다.
1. 극한값들로 채워져 있는 슬롯들을 뽑는다.
2. 중요하다고 알려진 슬롯들을 뽑는다.
3. 목적 골격에 상대적으로 가까운 어떠한 골격도 갖고 있지 않는 슬롯들을 뽑는다.
4. 목적 골격에 상대적으로 가까운 어떠한 골격도 가지고 있지 않는 값들을 가진 슬롯들을 뽑는다.
5. 모든 근원 골격의 슬롯들을 뽑는다.
이와 같은 일련의 경험적 지식들의 좋은 이전이 발견되어질 때까지 적용되어진다. 우리의 예에서는 다음과 같은 결과를 얻을 것이다.
1. ACTIVITY-LEVEL 과 LOUDNESS 슬롯들은 극한값들로 채워져 있다. 그래서 이들을 먼저 뽑을 것이다.
2. 만일 이들이 존재하지 않았다면 두번째 법칙이 특별히 중요하다고 표시된 모든 슬롯들을 뽑을 것이다. 이 예에서 그러한 슬롯들은 존재하지 않는다.
3. 다음 법칙은 LADDER-HEIGHT 슬롯을 뽑을 것이다. 왜냐하면 이 슬롯은 VEHICLES 의 다른 유형들에 대한 골격 구조들에서 존재하지 않기 때문이다.
4. 다음 법칙은 COLOR 슬롯을 뽑을 것이다. 왜냐하면 어떠한 다른 VEHICLES 도 RED 와 같은 COLOR 를 갖고 있지 않기 때문이다.
5. 마지막 법칙은, 만일 이것이 적용된다면, 단순히 가능한 유사함으로써 FIRE-ENGINE 의 모든 슬롯들을 암시할 것이다.
뽑혀진 근원 골격의 슬롯들로부터 이루어진 일련의 가능한 이전 골격들이 제안되어진 후에 목적 골격에 대한 지식을 이용하여 이 골격들을 여과해야만 한다. 이러한 지식은 다음과 같은 일련의 경험적 여과 지식 (filtering heuristics) 에 의해 개발되어진다.
1. 목적 골격에서 아직 여과되어지지 않은 슬롯들을 뽑는다.
2. 목적 골격의 전형적인 예에 존재하는 슬롯들을 뽑는다.
3. 만일 2 단계에서 아무것도 뽑히지 않았다면 목적 골격에 상대적으로 가까운 골격들에 존재하는 슬롯들을 뽑는다.
4. 만일 이 시점까지 아무 것도 뽑히지 않았다면 목적 골격에 존재하는 슬롯들에 유사한 슬롯들을 뽑는다.
5. 만일 이 시점까지 아무것도 뽑히지 않았다면 목적 골격에 상대적으로 가까운 골격에 존재하는 슬롯들에 유사한 슬롯들을 뽑는다.
우리의 예에서는 이러한 법칙들이 다음과 같이 적용할 것이다 :
1. 1 법칙은 어떠한 제안된 슬롯도 제거하지 못할 것이다.
2. 2 법칙은 ACTIVITY-LEVEL 과 LOUDNESS 를 뽑을 것이다. 왜냐하면 이들은 PERSON 골격에서 전형적으로 존재하기 때문이다. 이는 우리의 예에서 볼 때 그들을 해당하는 값들이 없이도 빌 (Bill) 에 대한 골격 속으로 집어 넣을 수 있다는 것으로부터 알 수 있다.
3. 만일 이러한 슬롯들이 제안되어지지 않았다면 다음 법칙은 PERSON 에 대한 다른 골격들에 존재하는 슬롯들을 뽑았을 것이다.
4. 만일 ACTIVITY-LEVEL
과 LOUDNESS 가 전형적인 사람들의 부분으로써 명확히 표시되어지지 않았다면
그들은 역시 이번 법칙에 의해 뽑혀진다.
AGGRESSIVENESS 가 존재하고 AGGRESSIVENESS
가 PERSONALITY-TRAIT 로 알려져 있기 때문에 다른 PERSONALITY-TRAIT 로 알려져
있기 때문에 다른 PERSONALITY-TRAIT 들이 뽑힐 것이다.
5. 만일 AGGRESSIVENESS 가 빌 (Bill) 에 대해 알려져 있지 않고 다른 PERSON 에게 대해 알려져 있었다면 다른 PERSONALITY 슬롯들이 이번 법칙에 의해 뽑힐 것이다.
|
BILL |
ISA SEX ACTIVITY-LEVEL LOUDNESS AGGRESSIVENESS |
PERSON MALE FAST VERY-HIGH MEDIUM |
그림 10
이 과정의 마지막에서 빌 (Bill) 을 묘사하는 골격은 그림 10 에서 보여지는 것과 같이 될 것이다.
이 과정은 우리가 연구했던 다른 학습 과정들과 같이 지식 표기와 사고 (reasoning) 를 위한 표준 방법들에 의존한다. 이들은 다음과 같은 것을 포함한다.
유사항을 통한 사고는 문제 풀이와 학습 모두의 강력한 형태이기 때문에 계속해서 주목을 받아오고 있다. 이러한 작업의 두 가지 예들은 [Winston, 1980 ; Carbonell, 1981b] 에서 보여진다.
학습 프로그램들의 이러한 예들을 본 것으로부터 이제는 이 장의 처음에서 학습은 단순히 문제-풀이 작업의 다른 유형이라고 말했을 때 (비록, 특히 어려운 것이지만서도) 우리가 무엇을 뜻했는가가 뚜렷해졌다. 우리가 검토한 프로그램들에 의해 이용된 방법들은 다른 문제-풀이 프로그램에서 이용되어진 방법들과 똑같다. 이러한 방법들의 핵심은 다음과 같다 :
이러한 과정들을 이용하는 학습 프로그램은 다른 문제 풀이 프로그램들이 갖는 똑같은 어려움을 가지고 있다. 예를 들면, 결정적인 문제는 지식이 표시되어지는 정확한 일련의 기본 요소들의 선택이다. 예를 들면 Winston 의 프로그램에서와 같이 개념 학습 프로그램은 각각의 예가 묘사되어지는 기본적 요소들에 의해 제한되어진다. 만일 COLOR 가 이용되는 기본 요소들 중의 하나가 아니라면 GREEN ARCH 의 묘사가 가능하지 않다. Samuel 의 프로그램에서 사용된 것과 같은 변수 조정 학습 플그램은 처음에 결정한 생각되어 질 수 있는 모든 항들에 의해 제한되어진다. 이는 또한 주어진 본문을 내부적인 형태로 바꾸어서 그러한 형태에 근거를 둔 질문에 답하는 자연 언어 이해 프로그램 (natural language understanding program) 이 갖는 똑같은 문제점이다. 만일 어떠한 질문이 지식 표기를 위한 기본 요소들이 아닌 다른 요소들을 포함한다면 그에 대한 답은 가능하지 않다.
이와같이 하여, 매우 많은 문제-풀이 단계들을 요하는 것으로 인하여 많은 학습 문제들이 어려워짐에도 불구하고 그러한 단계들을 행할 때 이용되는 방법들이 표준적 문제-풀이 방법들을 통하여 얻어질 수 있다는 것을 알 수 있다. [Michalski, 1983] 은 컴퓨터 학습 문제와 그를 실행하는 여러 시도들에 관해 자세히 서술해 주고 있다.
1. 사무엘의 기계-학습 과정을 체스 (chess) 게임에 적용하는 것이 적절한가? 만일 적절하다면 그 이유는 무엇이며, 그렇지 않다면 그 이유는 무엇인가?
2. TABLE 개념이 크고 평편한 위와 적어도 3 개의 분리된 다리를 가진 모든 물체들을 포함하도록 정의되었다 하자. Winston 의 프로그램이 이 개념을 어떻게 배우는지를 보여라. TABLE 에 대한 일련의 묘사와 TABLE 에 대한 근사항 (near-miss) 을 주고 이 개념 정의가 어떻게 진보되어지는 지를 보여라.
3. 6 절에서 우리는 개념 정의를 나타내는 구조의 연결 부분들이 개념의 정의가 진보됨에 따라 변화되어지는 방법을 설명했다. 예를 들어, 우리는 DOESNOTMARRY 연결 부분이 MUSTNOTMARRY 로 변화되어야만 한다는 것을 보였다. 이것이 어떠한 방법으로 행하여져야만 하는가? MARRY, DOESMARRY, MUSTNOTMARRY, 그리고 MUSTMARRY 들의 관계를 나타내는 방법을 보여서 이들이 아치 (arch) 물체들 또는 그렇지 않은 물체들을 나타내는 새로운 구조들과 개념 정의 사이를 비교할 때 쉽게 이용될 수 있도록 하라.
4. 영어와 같은 언어를 위한 문법을 배우는 문제를 생각하라. 입력으로써, 그러한 프로그램이 한 문장과 그 문장의 의미를 표시하는 법을 가지고 주어졌다하자. 이것은 문장을 듣고 동시에 어떠한 것을 보는 어린이의 경험과 유사하다. 그러한 프로그램이 이 장에서 거론된 방법들을 이용하여 어떻게 만들어질 수 있겠는가?