구절구성기술의 한계
변형-생성문법의 이론 : Noam Chomsky, 이승환.이혜숙 공역, 범한서적주식회사, 1966 (원서 : Syntactic Structures,
Mouton & co, 1956), Page 43~60
1. 언어구조기술에 대한 두가지 모형을 검토해 왔다. 그 하나는 통신이론의 모형(communication theoretic model)이다. 이것은
언어를 Markov 과정으로 보는 견해에 기반을 둔 것으로서
언어학이론의 최소한도의 조건에 해당한다. 둘째는 직접성분분석에
기반을 둔 구절구성의 모형이다. 여기서, 첫째의 모형이 문법의
목적을 위하여 확실히 부적당하다는 것을 보았고 둘째 것이 첫째
모형보다 강력하며, 부적당한 것일지라도 첫째 것과 동일한
이유에서 부적당한 것이 아니라는 것도 알았다. 물론 구절구성으로
기술할 수 없는 언어(일반적인 의미에서)들이 있지만 영어 자체가
이런 형의 분석으로 기술이 전적으로 불가능한지는 아직 모르겠다.
그러나 구절구성의 이론이 언어학적 기술목적에 부당하다고
배격하는데는 다른 근거가 있다고 생각된다.ⓐ
어느 언어학이론의 부적당성을 가장 강력하게 증명하는 길은 그
이론이 자연언어에 전혀 적용될 수 없다는 것을 보이는 것이다.
또한 강력도가 약하긴 하지만 부적당성을 탈없이 충분히 입증하는
길은 그 이론에 의하여 성립될 수 있는 문법이 대단히
복잡하여지며(complex), 임의적이고 (ad hoc) '계시적이
아니다(unrevealing)'라는 것 등을 보이는 것이다. 또는 문법적인
문장을 기술하는 일종의 아주 간결한 방법이 그 이론에 따른
문법에 수용될 수 없음을 보이던가. 또는 자연언어의 특종의
기본적인 형식적 특성이 문법을 간결화하는데 이용될 수가 없다는
것 등을 보이면 된다. 지금까지 기술해온 문법형과 이러한 문법의
근저를 이루는 언어학이론의 개념이 근본적으로 부적당하다는
논제를 뒷 받침하는 위와 같은 증거를 상당히 많이 수집할 수
있다.
제시된 현재의 방법론[즉, 구절구성모형]의 적부를 알아보는
유일한 길은 이 방법론을 영어의 문장기술에 직접 시도해 보는
것이다. 가장 간단한 형의 범위를 벗어난 문장들을ⓑ 대상으로
삼고 특히 이 문장들을 만들어내는 규칙들 사이에 순위를
규정하려고 하면, 곧 다수의 난관과 복잡성에 직면하게 됨을 알 수
있다. 이러한 내용을 구체적으로 설명하자면 많은 노력과 지면이
들기 때문에 여기서는 다만 이러한 주장이 충분이 수긍될 수
있도록 입증할 수 있다는 것을 강조하여 둘 수밖에 없다.(이
문제에 대한 세밀한 분석은 필자의 "The logical structure of
linguistic theory"를 참조하라.) 이렇게 어렵고 큰 일을 택하는
대신 몇가지 간단한 예들을 요약함으로써 [∑, F]형의 문법이
상당히 수정될 수 있다는 가능성을 시사하겠다. §8에서 영어의
문장구조기술의 방법으로 성분분석(constituent analysis)이
부적당하다는 것을 입증하는 독립적인 방법론을
제시하겠다.
2. 문장형성을 위한 가장 생산적인 과정(productive process)의
한가지는 접속과정(process of conjunction)이다.
Z
+ X + W
와
Z
+ Y + W 라는
두 개의 문장이 있고, 여기에서
X
와
Y 가 이
문장들의 실제적인 구성성분(constituent)이라면,
일반적으로
Z-X+and+Y-W
라는 새로운
문장을 유도할 수 있다. 예를 들어보면, (20a-b)라는 두
문장으로부터 (21)이라는 새 문장을 유도할 수
있다:
(20) (a) the scene-of the movie-was in Chicago
(b) the scene-of the play-was in
Chicago
(21) the scene-of the movie and of the play-was in
Chicago.
반면,
X
와
Y 가
구성성분이 아닐 경우에는 일반적으로 이러한 과정을 밟을 수
없다.(주석 : (21)과 (23)은 접속과정이 가능하다는 것에 의문의 여지가
없는 극단의 경우들이다. 한편 이와는 달리 분명하지 않은 경우가
많다. 예를 들면, "John enjoyed the book and liked the
play"(NP
- VP + and + VP
형의 연결체)는
분명히 완전한 문장이라고 하겠지만, "John enjoyed and my friend
liked the play"(NP
+ Verb + and + Verb - NP
형의 연결체)를
보면 이것의 문법성(grammaticalness)에 대하여는 회의를 갖는
사람이 많다. 이렇게 둘째 문장과 같이 접속과정이 구성성분의
경계선(constituent boundary)을 넘는 경우는 그렇지 않은 경우
즉, "John enjoyed the play and my friend liked it"보다 휠씬
부자연스럽다. 그러나 전자에 대치할만한 다른 문장이 없다.
접속과정이 구성성분의 경계선을 넘는 문장은 통상 특수한
음운론적 특징을 갖는다. 즉, 유난히 긴 휴지(예문에서는
"liked"와 "the"사이에), 대립적(contrastive) 강약과 억양, 또는
속도가 빠른 구어에서는 모음을 약화시키거나 마지막 자리의
자음을 탈락시키지 않는 등의 현상을 들 수 있다. 이러한 특징은
비문법적 연속체를 읽을 때의 현상들이다. 이러한 현상들을
무리없이 문법적인 기술에 의하여 설명하려면 다음과 같이 된다.
접속과정에 의하여 완전한 문법적인 기술에 의하여 설명하려면
다음과 같이 된다. 접속과정에 의하여 완전한 문법적인 문장을
형성할 때는 첫째 단일 구성성분들만을 접속시켜야 한다. 둘째, 두
쌍의 구성성분을 접속시킬 때 이것들이 주구성성분(major
constituent)(즉, (15)형 도표에서 윗자리로 올라 갈수록
주구성성분이 된다)일 경우는 결과적으로 형성되는 문장이
반문법적(semi-grammatical)인 것이 된다. 셋째, 둘째 경우보다 더
심하게 접속과정이 구성성분이 조직을 파괴하면 더욱 비문법적인
문장을 만들게 된다. 이와 같은 기술은 결국 문법성의 과정(degree
of grammaticalness)에 대한 개념과 더불어 문법성 대
비문법성이라는 양분론(dichotomy)을 제시하여야 한다. 그러나 본
연구내용에 있어서는 "John enjoyed and my friend liked the
play"유의 문장을 비문법적이라는 이유로 제거하거나 반문법적
문장으로 인정하거나 또는 이 문장의 특수 음운론적 자질을
고려하여 완전히 문법적인 문장이 될 수 있다던가 하는 문제는
중요하지 않다. 여하간, "John enjoyed and my friend liked the
ploy"유의 문장은 구성성분의 조직이 완전히 유지된 "John enjoyed
the play and liked the book"유의 문장과는 변별되는 언어표현의
부류를 형성하게 된다. 따라서 접속과정에 대한 규칙은 구성성분의
조직과의 관계를 분명히 해야 한다는 결론이 서게 되며 문법은 이
점을 밝혀야 한다.)ⓒ 예로서, (22a-b)에서 (23)을 형성할 수
없다는 것이다.
(22) (a) the-liner sailed down the-river
(b) the-tugboat chugged up
the-river
(23) the-liner sailed down the and tugboat chugged up
the-river.
이와 비슷한 경우로써,
X
와
Y 가 모두
구성성분이라 할지라도 다른 종류의 구성성분일 때는(즉, ⒂형의
도표에서 각각이 단일원점을 가졌더라도 원점들이 달리 표시되어
있을 때) 일반적으로 접속과정에 의하여 새로운 문장을 형성할 수
없다. 예를 들어 보면, (24a-b)에서 (25)를 만들어낼 수 없다는
것이다.
(24) (a) the scene-of the movie-was in Chicago
(b) the scene-of that I wrote-was in
Chicago
(25) the scene-of the movie and that I wrote-was in
Chicago.
요약하면, 접속과정의 가능성여부가 최초의 구절구성 결정에 가장
적절한 기준을 제공한다. 즉, 다음과 같은 규칙이 적용되는
방법으로 구성성분을 설정한다면 접속과정에 대한 기술을 간결화할
수 있다:
(26)
S1
과
S2
가
문법적 문장들이고,
S1
과
S2
의
차이는
X
가
S1
에
나타나고
Y
가
S2
에
나타난다는 것뿐이며(즉,
S1
= …
X …,
그리고
S2
=…
Y
…),
S1
과
S2
에
각각 나타나는
X
와
Y 가 같은
종류의 구성성분이라면,
S1
에서
X
대신
X
= and + Y 를
대치하여 만들어진
S3
도
문장이 된다(즉,
S3
= … X + and + Y
…).ⓓ
(26)에 부가적인 제약(qualification)이 필요함은 말할 나위도
없지만, (26)이 대략적으로나마 적용되도록 구성성분을 설정해
간다면 상당히 간결한 문법을 만들 수 있다. 다시 말하면, "and"의
분포(distribution)를 (26)과 같은 규칙도 없이 직접
기술하는 것보다 이러한 규칙에 제약을 부가하여 기술하는 방법이
휠씬 쉽다. 그런데, 여기에서 당면하는 문제는 [∑, F]형 문법이
가지고 있는 본질적인 제한(limitation) 때문에 (26)류의 규칙을
구절구성의 [∑, F]형 문법에 포함시킬 수 없다는 것이다.
S1
과
S2
에
(26)을 적용시켜서 새로운 문장 S3
를 유도할 때를 생각해
보면,
S1
과
S2
의
실제적인 모양뿐만 아니라 이것들의 구성성분의 구조(constituent
structure)도 알아야 하며, 이 문장들의 최종적인 모양뿐만 아니라
그 '유도경로(history of derivation)'도 알아야 한다는 것이
(26)에 필요한 근본적인 특성임을 알 수 있다. 그런데 [∑, F]형의
문법에서
X→Y 식
규칙의 주어진 연결체에 적용가능여부는 다만 그 연결체의
실제적인 모양(외모)에 의하여 좌우된다. 여기에서는 한 연결체의
모양이 어떻게 점차적인 과정으로 이루어 졌는가 하는 것이
문제시도지 않고 다만 그 연결체내에 X라는
부분연결체(substing)가 있으면 규칙 X→Y가 적용될 수 있고 X가
없으면 적용될 수 없다는 것만이 문제가 된다. 좀 다른 각도에서
생각해 보면 [∑, F]형 문법은 문장을 "좌측부터 우측으로"는
생성하지 못하고 "위부터 아래로"만 생성하는 극히 기초적인
과정으로도 생각할 수 있다는 것이다. 다음과 같은 구절구성문법이
있다고 하자:
(27) ∑:
Sentence
F:
X1
→ Y1
Xn
→
Yn
이런 문법은 최초상태와 최종상태를 포함하는 유한수의 내적상태로
이루어진 기계로 대신할 수 있다. 이 기계는 최초상태에서
Sentence
라는 요소를
만들므로써 다음의 새로운 상태로 이동하게 된다. 따라서 (27)의
F내에
Sentence→Yi 라는
규칙이 있으면 이 기계는
Yi 라는
연결체를 만들 수 있다.
Yi 를
만들면 역시 새로운 상태로 이동하게 된다. 여기서
Yi 가
…
Xi …형의
연결체라면 규칙
Xi
→Yi 를
"적용"하여 …
Yi …형의
연결체를 만들 수 있다. 이런 식으로 이 기계가 한 상태에서
다음상태로 계속 이동하면 결국 최종연결체를 만들게 되며, 이때
기계는 최종상태에 놓이게 된다. 그래서 이 기계는 §4에서 설명한
유도과정을 형성하게 된다. 여기에서 중요한 점은 이 기계의
상태는 전적으로 바로 전에 만들어낸 연결체에 의하여 결정된다는
것이다(즉, 직전의 유도과정에 의한다는 것이다). 좀더 구체적으로
말하면, 직전에 형성된 연결체에 포함된 F의
'좌측(left-hand)'요소
X
i 의
부분집합(subset)에 의하여 이 기계의 상태가 결정된다. 한편,
규칙 (26)을 도리켜 생각해 보면, (26)은 (27)보다 더 강력한
기계를 필요로 한다. 즉, 유도과정의 다음 단계를 만들어 내기
위하여 그 이전에 만들어진 결정체들을 '도리켜 볼 수
있는(추고ㆍlook back, 또는 추적)' 기계가 (26)에는
필요하다.ⓔ
다른 한면을 보면, 규칙 (26)이 (27)보다 근본적으로 새로운 형의
규칙임을 알 수 있다. (26)은 변별되는 두 개의 문장 S1
과 S2
와
필연적인 관련을 맺어야 하는데 비하여 [∑, F]형 문법에는 이러한
이중관연성(double reference)을 포함시킬 길이 없다.
구절구성문법이 전적으로 영어에 적용될 수 없는 것은 아니지만
규칙 (26)이 구절구성문법에 포함될 수 없다는 사실은 위에 언급된
바와 같이, 비록 약하긴 하지만 충분한 이유에서 구절구성문법이
확실히 부적당하다는 것을 시사하고 있다. 규칙 (26)은 문법을
상당히 간결화시킨다. 다시 말하면, (26)이 구성성분결정을 위한
최선의 기준을 마련하여 준다는 것이다. (26)과 유사한 일반형의
많은 규칙이 (26)의 경우과 같이 이중기능을 수행한다는 것을 뒤에
논하겠다.
3. 문법 (13)에서
Verb 라는
요소를 한가지로만 분석하는 방법을 보았다. 즉,
Verb
가
hit 등이
되는 것을 보았을 뿐이다((13ⅵ) 참조). 여기에서 한가지 알 수
있는 것은 비록 동사어근(verbal root)을 고정시켜 놓는다고
하더라도(예를 들어,
take 를
고정했다고 하자), 이 고정된 요소가 갖는 형태는 여러 가지가
된다. 즉,
takes. has
+ taken, will + take, has + been + taken,
is
+ being + taken
등이 그것들이다.
그런데 이러한 "조동사(auxiliary verb)"에 대한 연구는
영어문법에서 매우 중요한 역할을 하게 된다. 좀 견해를 달리해
보면, 조동사의 행동(behavior)이 극히 규칙적이며 위에서 나열해
놓은 것과는 달리 간결하게 기술될 수 있는 것을 알게 된다.
그러나 한면, 이것들을 [∑i, F]형 문법에
직접 포함시키려고 할 때는 매우 복잡한 것으로 나타나게
된다.
우선 강세를 받지 않는(unstressed) 조동사를 살펴 보자.
"John
does read
books"의
does 가
아니고 "John
has read
the book"의
has 류의
조동사를 먼저 생각해 보자는 것이다.(강세를 받는(stressed)
조동사 "do"에 대하여는 §7.1(45)-(47)에서 다루겠다.) 문법
(13)에 규칙들을 첨가하면 평숙문(declarative sentence)에
나타나는 조동사들을 기술할 수 있다:
(28) (ⅰ)
Verb → Aux
+ V
(ⅱ)
V → hit, take, walk, read,
etc.
(ⅲ)
Aux → C(M)(have
+ en)(be + ing)(be + en)
(ⅳ)
M → will, can, may, shall, must
(29)
( i ) 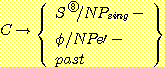
(주석 : (13ⅱ)가 p. 36의 각주 3에서 설명한 식으로 또는 이와
유사한 형으로 이미 전개되었다고 가정하고 있다.)
(ⅱ)
Af
를
past, S, φ, en, ing
등의 접사중 어느
하나의 표식로 설정하고,
v
를
M
나
V ,
또는
have
또는
be 의
표식(Verb 라는
구절에서 접사가 아닌 것)로 설정하면 다음의 규칙이
성립된다:
Aƒ + υ → υ
+ Aƒ#ⓖ
여기서 # 는 단어경계선 (word boundary) 으로
해석한다. (주석 : 문법이론을 더욱 세밀히 형성하는 입장에서는 # 를 단어차원에서의
연결표식 (concatenation operator) 로 해석하고, + 를 귀절구성단계에서의
연결표식으로 해석하게 된다. 따라서 (29) 귀절구성단계의 대상 (본질적으로
(15) 형의 도표들을 의미한다) 들을 단어의 연결체로 전사 (mapping) 하는 규정의
일부가 된다. 이 점에 대한 좀더 자세한 형식상의 설명에 대하여는 필자의
"The logical structure of linguistic theory" 를 참조하라.)
(iii) υ—Aƒ 문맥을 제외한 장소에서 + 를 #
로
대치하라. # 를 처음과 마지막에 넣어라.
(28 iii) 에 나오는 기호들은 다음과 같이 해석 (적용) 된다. C 라는 요소는 반드시 택하여야 한다. 소괄호
안의
요소들은 하나도 택하지 않을 수도 있고, 택한다면 나열된 순서에 따라서 하나 또는
그 이상을 택할 수도 있다.
(29 i) 에서는 주어진 문맥의 제약에 따라 C
를
세 개의 형태소중의 하나로 전개한다. 이런 규칙의 적용형식을ⓗ 보이는
예로서 (14) 형의 다음과 같은 유도과정을 보자. 여기서는 처음 몇 단계의 부분은
삭제하였다.
(30) the + man + Verb + the + book (13ⅰ
―
v) 를 적용
the + man +
Aux + V + the + book (28 i)
the + man +
Aux + read + the + book (28 ii)
the + man +
C + have + en + be + ing + read + the + book (28 iii) 을 적용
―
C , have + en, 그리고 be + ing 의 요소들을 택하였다.
the + man +
S + have + en + be + ing + read + the + book (29 i)
the + man +
have + S # be + en # read + ing # the + book (29 ii) ― 세 번 적용
#
the # man # have + S # be + en # read + ing # the # book # (29 iii)
(19) 등의 형태음운규칙 (morphophonemic rule) 은 위의 유도과정의 마지막 열을 다음과 같이 음운표기로 전환시킨다
:
여기서는 (31) 을 철자로 표시하였다. 위와 같은 식으로
다른 모든 조동사구절이 생성될 수 있다. 문법적인 연결체만을 생성하기 위하여 이
규칙들에 부가되어야 할 다른 제약들에 대한 문제는 차후 다시 다루기로 하겠다.
여기에서는 한가지 주의해서 알아둘 일은 will + S → will, will + past →
would 가 된다는 등의 규칙이 형태음운규칙에 포함되어야 한다는 것이다. C 와 M
를
둘 다 같이 택할 수는 없고 C 나 M 의 하나만을 택할 수 있도록 (28 ⅲ)을 수정하면ⓘ
will + S → will 이 된다는 등의 규칙이 필요없게 된다. 그러나 이렇게
되면, (28 iv) 에 would, should, could, might 가 반드시 포함되어야 하며 또한
다른 면에서 '시제연결체' 에 대한 기술이 더욱 복잡하게 된다. 어느 쪽의 분석을
따르느냐 하는 것은 앞으로의 논제에 중요성을 갖지 않는다. 그러나 위에 말한 것
이외에도 부분적인 수정이 가능하다는 것을 말하여 둔다.
(30) 에 (29 i) 을 적용할 때 the + man 이
단수명사구절인 NPsing 라는 사실을 참작하였다는 것을
알 수 있다. 환언하면, the + man 이라는 구성성분의 구조를 알아내기 위하여 유도과정을
추론해 올라가 살펴보아야 했다는 것이다. (차후 그중 몇 가지를 다루겠지만, 여러
가지 이유로 인하여 (29 i) 과 NPsing 를 the + man
으로
전개하는 규칙의 순서를 바꾸어서 (29 i) 이 후자의 앞에 오도록 할 수가 없다) . 또한 (26) 과 같이 (29 i) 도 기초적인 Markov 특성을 가진 구절구성문법의
범위를 넘게 되며, 따라서 (29 i) 을 [Σ, F] 형 문법에 포함시킬 수 없게 된다.
규칙 (29 i) 는 [Σ, F] 형 문법의 조건들을
더 심하게 위반하고 있다. (29 i) 도 역시 구성성분의 구조 (즉, 유도과정의 지나간
경로) 를 참작해야 하며, 더 나아가서는 (29 i) 에서 요구되는 도치 (inversion) 를
구절구성의 형식으로는 나타낼 방법이 없다.ⓙ (29 i)가 위의
경우만이 아니라 문법의 다른 곳에서도 유용하다는 것을 살펴 볼 수 있다. Aƒ
가 ing 인 경우를 생각해 보자. to 와 ing 라는 두 형태소가 동사구절을
명사구절로 전환시킨다는 면에서 보면, 명사구절의 범주에 드는 유사한 기능을 가지고
있다. 예를 들면, 다음과 같은 것이 있다 :
(32) 
이러한 대등한 구성을 고체할 때, 문법 (13)
에 다음과 같은 규칙을 첨가할 수 있다 :
(33) 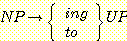
여기에서 규칙 (29 i) 는 ing + prove + that
+ theorem 을 proving # that + theorem 으로 도치하게 된다. VP 를 더
세밀하게 분석해 보면, 위에 나온 것과 유사한 구성의 적용범위가 사실상 훨씬 넓은
것을 알 수 있다.
구절구성의 [Σ, F] 형 조직내에서 (28 ⅲ) 과 (29) 의 효과를 기술하려면 그 설명이 상당히 복잡하게 된다는 것을
독자들도 알 수 있으리라 믿는다. 접속과정의 경우에서 볼 수 있듯이 유효하게 문법을
간결화하려면 직접성분분석의 조직에 해당하는 규칙들보다 더 복잡한 형의 규칙을
자유롭게 형성할 수 있어야 된다. (29 i) 를 자유롭게 형성함으로써 요소간의 상호종속관계를
고려하지 않고 (28 ⅲ)에서 조동사구절의 구성을 설명할 수 있었다.ⓚ 상호종속관계가
있는 연결체보다 독자적인 요소의 연결체를 기술하는 것이 항상 더 용이하다. 바꾸어
말하면, 조동사구절내에 불연결요소 (discontinuous element) 들이 있다는 것이
- 예를 들어 (30) 에서 have··en 과 be··ing 등의
요소 ― 이 불연결체들을 [Σ, F] 형 문법에서 다룰 수 없다는 것이다. (주석 : 구절구성의 개념으로 불연결체를 설명해 볼 수도 있다. 그러나 여러 차례에
걸친 이런 방향의 조직적인 시도에서 상당히 해결하기 어려운 문제들이 야기된다는
것을 알았다. 필자의 "System of syntactic analysis," Journal of symbolic
Logic18.242-56 (1953); C. F. Hockett의 "A formal statement of morphemic
analysis," Studies in Lingusisics 10.27-39 (1952) 와 "Two models of
grammatical description," Linguistics Today, Word 10.210-33 (1954) 를 참조하라.
위에 시도한 식으로 이번에는 구절구성을 좀 복자하게 해서라도 [Σ, F] 형 문법의
결합을 고쳐보려고 할 수도 있다. 그러나, 이러한 시도는 깊은 연구가 되지 않은데서
오는 결과라고 믿는다. 그리고 이러한 방법은 임의적이고 가치없는 이론전개에 그치고
만다. 구절구성의 개념은 언어의 아주 작은 한 부분에는 적합하지만 그 이외의 부분은
구절구성문법에서 얻은 연결체에 간단한 변형규칙 (transformation) 을 반복사용하여
유도된 것이라고 생각된다. 구절구성을 전개하여 언어의 전체를 직접적으로 다루려는
시도는 제한된 범위내에서 얻는 구절구성문법의 간결성과 변형 생성이론전개를 파괴하게
된다. 또한 이 방법은 계층구성 (level construction) 이라는 중요 논점을 읽게 된다.
다시 말하면, 실제언어의 방대한 복잡성을 간결한 몇 개의 언어학적 계층으로 나누어
기술하는 데서 얻는 간결성과 조직성을 잃게 된다는 것이다.)
(28 ⅲ) 에서는 이 요소들을 연결체 (continuity) 로 다루었고 그후 (29 i) 라는
하나의 간단한 규칙으로 이것들이 불연결체라는 것을 밝힌 것이다. Verb 라는 요소를
이러한 양식으로 분석하는 것이 광범위하고도 간결하게 영어통사론의 몇 가지 중요한
문제를 분석하는데 기반이 된다는 것을 §7 에서 논하겠다.
4. 구절구성의 개념이 적합하지 않다는 것을
보이는 세 번째의 예로써 능동과 피동의 관계 (active-passive relation) 를 살펴
보자. 피동문은 규칙 (28 ⅲ) 에서 be + en 이라는 요소를 선택하여 만든다. 그런데
be + en 은 조동사구절 가운데서도 여러 가지 심한 제약을 받기 때문에 특수한 요소가
된다. 그 제약의 하나로서 be + en 은 그 다음에 따르는 V 가 타동사일 때만 선택될
수 있다는 것을 들 수 있다(즉, was eaten 은 용납되지만, was occurred는 용납되지
않는다). 한편, 조동사구절내의 다른 요소들은 몇가지의 예외를 제외하고는 동사의
종류에 제한없이 자유로이 사용될 수 있다. 둘째의 제약은 V 의 다음에 명사구절이
따를 때에는 be+en 을 선택할 수 없다는 것을 들 수 있다 (즉, V가 타동사일지라도
일반적으로 NP + is + V + NP 가 영어의 문장이 될 수 없다. 다시 말하면, "lunch
is eaten John" 이라는 문장이 없다는 것이다). 좀더 살펴 보면 V 가 타동사이고
전치사구절 by + NP 가 V 를 뒤따르게 되면, 이때에는 반드시 be + en 을 선택해야
한다는 것을 알 수 있다 ( "lunch is eaten by John" 이라고는 할 수 있지만,
"John is eating by lunch" 등의 문장은 있을 수 없다). 끝으로 고려해야
할 것이 있다. 즉, (13) 을 완전한 문법으로 발전시키려면 주어와 목적어의 관계에
따르는 여러 가지 제약을 V 를 선택할 때 고려해야 한다는 것이다. 다시 말하면,
"John admires sincerity," "sincerity frightens John," "John
plays golf," "John drinks wine"등의 문장은 용납하고, 이것들의
역이 되는 비문장 (주석 : 여기서도 p.44의 각주 2 에 제시한 문법성의 수준 (levels
of grammaticalness)이라는 개념을 사용할 수 있다. 즉, "sincerity admires
John" 은 "John admires sincerity" 보다는 문법성의 수준이 낮지만
"of admires John" 보다는 확실히 높다. 문법성의 수준에 대한 실제적인
개념을 순수히 형식적인 방법론에 의하여 전개시킬 수 있다고 믿는다. 이 문제는
여기에서 피하기로 하겠다. (필자의 The logical structure of linguistic theory
를 참조하라. ) 피동구조에 있어서 이치 (inversion) 가 필요하다는 것을 보이는
좀더 강력한 설명에 대하여는 §7.5 를 참조하라.) "sincerity admires
John," "John frightens sincerity," "golf plays John,"
"wine drinks John" 등을 배제할 수 있도록 V 가 선택되어야 한다. 그런데
be + en 을 조동사의 일부로 선택하면 위에 말한 제약의 상호조직이 완전히 파괴되고
만다. 사실상 be + en 을 선택하는 경우에도 꼭 같은 상호종속관계가 유지되어야
하지만 이때에는 순서를 반대로 해야 한다. 즉, 모든 NP1 - V - NP2
에 대하여 이것에 해당하는 NP2 - is + Ven - by
+ NP1 을 형성할 수 있는데, 여기에서 문제는 피동구조를 문법 (13)
에 직접 포함시키려면 be + en 을 조동사의 일부로 선택한 모든 경우의 제약관계를
반대로 다시 설명해야 한다.ⓛ 이와 같은 조잡한 중복과 be + en 이라는
요소가 포함하는 특수제약을 회피할 수 있는 방법은 피동구조를 구절구성에서 기술적으로
제거하고 다음에 보이는 바와 같은 규칙 (34) 로 다시 도입하는 길이다 :
(34) S1 이 NP1 ― Aux
― V ― NP2 형의 문법적 문장이라면 이와 대등한 NP2 ―
Aux + be + en - V - by + NP1 도 역시 문법적 문장이다.
예를 들어 보면, John - C - admire - sincerity
가 문장이라면, sincerity - C + be + en - admire - by + John (여기에
(29) 와 (19) 를 적용하면 "sincerity is admired by John"이 된다) 도
역시 문장이 된다.
(34) 를 가짐으로써 be + en 이라는 요소와 이에
따르는 모든 특수제약들을 (28 iii) 에서 삭제할 수 있다. be + en 이 타동사를
요구한다는 사실, be + en 이 V + NP 앞에는 올 수 없고 반드시 V + by
+ NP (여기에서 V 는 타동사) 앞에 와야 한다는 사실과 앞뒤의 명사구절의 순서를
도치해야 한다는 사실들은 (34) 에 의한 자동적인 결과가 된다. 따라서 이 규칙은
문법을 상당히 간결화시킨다. (34) 는 [Σ, F] 형 문법의 범위를 훨씬 넘게 된다.
(29 ii) 와 마찬가지로, (34) 는 이 규칙이 적용되는 연결체의 구성성분구조와의
관연 (reference) 을 필요로 하며, 또한 구조상으로 결정된 의식 (structurally determined
manner) 에 따라 연결체내의 요소들을 도치시켜야 한다.ⓜ
5. 지금까지 세가지의 규칙 ((26), (29), (34))
을 살펴 보았다. 이 세가지 규칙은 영어의 기술을 상당히 간결하게는 해주지만 [Σ, F]
형 문법에 포함시킬 수는 없다. 이러한 류의 수없이 많은 규칙가운데 몇가지를 다시
다루어 보기로 하겠다. 영어에 대한 구절구성문법의 한계를 좀더 연구해보면 이 문법은
걷잡을 수 없이 복잡하다는 것을 알 수 있으며 위에 말한 류의 규칙 [(26), (29),
(34) 따위] 을 포함하는 문법이 아니고서는 문법으로서의 가치가 없음을 결정적으로
알게된다.
이 보조적 역할을 하는 규칙들의 내용을 좀더 신중히
연구하면 언어구조에 대한 아주 새로운 개념에 도달하게 된다. 이러한 규칙들의 명명을
"문법적 변형 (규칙) (grammatical transformation)" 이라고 부르기로
하자. T 라는 문법적변형은 구성성분의 구조가 명시된 하나의 주어진 연결체 ((26)
과 같은 경우에는 연결체들의 한 집합) 에 작용 (operate) 하여 이것을 유도된 새로운
구성성분의 구조를 가진 다른 하나의 연결체로 전위시킨다.ⓝ T
의 작용과정을 정확히 보이려면 상당히 세밀한 설명이 필요하게 된다. 여기에서는
세밀한 설명을 피하고 문법적 기술에 있어서 명백히 필요한 특성을 가진 변형 (transformation)
의 자연스럽고 당연한 해법을 보이는 한도에서 그 복잡한 내용을 어느 정도
전개해 보겠다. (주석 : 필자의 "Three models for the description of language"
(p. 28의 주석 3을 참조) 에서 간단히 논한 변형에 대한 설명을 보아라. 변형해법의
발전과정과 변형 생성문법에 대한 자세한 설명은 필자의 The logical structure of
linguistic theory 와 Transformational Analysis 를 참조하라. 방법론이 좀 다른
변형분석 (transformational analysis) 에 대하여는 Z. S. Harris 의 "Cooccurrence
and transformation in linguistic structure" Language 33.283-340 (1957)
을 참조하라.)
위에서 살핀 몇 가지의 예에서 이미 변형 생성문법
(transformational grammar) 의 몇 가지 본질적인 특성을 알아낼 수 있다. 그중 한가지
분명한 것은 변형규칙을 적용시킬 때 순서 (order) 를 규정해야 한다는 것이다. 예를
들면, 피동변형 (passive transformation) 의 규칙 (34) 는 (29) 이전에 적용되어야
한다. 특히 (29 i) 이전에 적용되어야만 결정적으로 생성되는 피동문에서 동사요소
(verbal element)와 그 문장의 문법적 주어 (grammatical subject) 문의 수의 일치
(agreement in number) 를 이룰 수 있다. ⓞ 또한 (34) 가 (29 ii) 에
앞서야만, 새롭게 삽입된 요소 be + en 에 (29 ii) 가 적절하게 적용될 수 있다.ⓟ
((29) 를 [Σ, F]형 문법으로 간주할 수 있는 가의 여부를 논할 때, NPsing 를 the
+ man 등으로 분석하는 규칙에 앞서서 (29 i) 를 적용할 수 없다는 것을 말하였다.ⓠ
이것에 대한 한가지 이유가 지금에 와서 명확해 졌다. (29 i) 은 (34) 이후에 적용되어야
한다. 이러한 순서가 성립되지 않으면 피동문에서 주어와 동사, 그리고 동사와 '행위자
(agent)' 간에 적절한 선택관계 (selectional relations) 가 유지되지 않는다.ⓡ)
둘째로 해야 할 점은 변형을 필순
(obligatory) 와 수의 (optional) 로 구분한다는 것이다. 예를 들면, (29)는 모든
유도과정에 필수적으로 적용되어야 한다. (29) 가 적용되지 않은 것은 문장이 될
수 없다. (주석: (29 i) 에서는 세 규칙 가운데 세 번째 것만이 필수이다. 즉, past
는 NP 가 NPsing 이거나 NPpl 이거나를 불문하고 이것들 뒤에
올 수 있다. (29 i) 의 C 라 는 요소와 같이 한 요소가 필수적으로 전개되어야
하고, 그 전개에서 몇 가지의 선택의 가능성이 있으면, 그 가능선택의 마지막 것만을
필수로 하고 그 외의 것은 수의로 하면 된다.ⓣ) 반면 (34) 라는 피동변형규칙은
적용될 수 있는 경우에서 적용해도 좋고 적용안해도 된다. 적용하고 안하고를 막론하고
양쪽이 모두 그 결과가 문장이 된다. 따라서 (29) 를 필수변형규칙 (obligatory transformation)
이라고 하며 (34) 를 수의변형규칙 (optional transformation) 이라고 한다.
변형을 필수와 수의로 구분함으로써 언어의 문장들을
근본적으로 분류하게 된다. [Σ, F] 의 부분과 변형의 부분으로 이루어진 문법 G
가 있다고 하자. 그리고 변형의 부분은 필수변형규칙과 수의변형규칙으로 되어 있다고
하자. 문법 G 에 의하면, [Σ, F] 분법에서 만들어진 최종연결체에 필수변형규칙을
적용하여 생성된 문장의 집합을 그 언어의 핵 (kernel) 이라고 규정한다. 문법 G
는 변형규칙이 핵문 (kernel sentence) (좀더 정확히 말하면 핵문의 기조를 이루는
형식, 즉 그 문법의 [Σ, F] 부분에서 만들어진 최종연결체에 적용되도록 구성되어야
한다. 다시 말하면, 변형규칙은 변환형 (transform) 을 유도한다는 것이다. 따라서
언어의 모든 문장을 첫째 핵에 속하는 것과, 둘째로 하나 또는 그 이상의 핵문의
기조가 되는 연결체에 하나 또는 그 이상의 변형규칙을 적용하여 유도된 문장으로
구별한다.
지금까지 설명한 내용을 정리하면, 문법을 세 부분으로
배열구성 (tripartite arrangement) 된 것으로 간주할 수 있다. 구절구성 (tripartite
arrangement) 된 것으로 간주할 수 있다. 구절구성계층에 해당하는 부분은 X→Y 형
규칙의 연속으로 되어 있고, 이보다 하위의 계층은 X→Y 형과 기본적으로 같은 형의
형태음운규칙들로 이루어져 있다. 그리고 구절구성부분과 그보다 하위계층부분을
연결 짖는 세 번째의 부분으로 일연의 변형규칙이 있다. 따라서 이상과 같은 세 부분으로
형성되는 문법은 다음과 같은 모양을 갖게 된다:
(35) Σ : Sentence
F
:
|
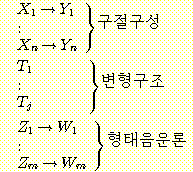
|
이러한 문법으로 문장을 생성하려면 첫째 Sentence
로 시작되는 유도과정을 형성한다. 즉, F 의 규칙을 순서에 따라 적용하여 형태소의
연속으로 된 최종연결체를 얻는다. 여기에서 형태소의 배열순서는 비록 올바른 것이
아닐 수도 있다.ⓤ 둘째로 일연의 T1…Tj 라는
변형규칙을 적용한다. 이때 모든 필수변형규칙은 반드시 적용되어야 하며, 수의변형규칙들은
임의에 따라 적용된다. 이 변형규칙은 연결체내의 요소를 도치시키기도 하고 형태소를
첨가 (add) 또는 삭제 (delete) 하기도 한다.ⓥ 이래서 결과적으로 단어의 연결체
(a string of words) 가 형성된다. 이렇게 두 과정으로 지난 다음 세 번째로 형태음운규칙을
적용하게 되는데 여기에서는 단어연결체를 음운연결체 (a string of phonemes)로
전환시킨다. 지금까지 논의된 규칙들 가운데서 (13), (17), (28) 은 문법에서 구절구성부분에
포함되며, (26) 과 (29) 를 변형생성이론에 부합되도록 타당하게 전면적으로 형식화시킨
것이
변형부분에 포함된다. 형태음운론의 부분은 (19) 와 같은 규칙들로 이루어 진다.
문장의 생성과정을 상기한 양식으로 다루려면 문장의 한 집합에 작용하는 (26) 과
같은 규칙의ⓦ 기능을 타당하게 일반화시켜야 하며 (이러한 일반화는 용이하게 이루어질
수 있다), 변형규칙이 변환형 (transform) 에 반복적용되어 점차적으로 복잡한 문장을
생성할 수 있도록 해야 한다.
한 문장의 생성과정에서 필수변형규칙만이 적용되었을
때 그 문장의 핵문 (kernel sentence) 이라고 부분다. 그 내용을 좀더 연구해 보면,
문법가운데 구절구성과 형태음운론의 부분에서 필수규칙 (obligatory rule) 의 개요를
추출해낼 수 있다는 것을 알게 된다. 필수규칙이란 문장의 생성과정에서 그 규칙에
이르면 반드시 적용해야 하는 규칙이다. §4 의 마지막 몇 항에서 구절구성규칙의
내용이 언어구조에 대한 개념과 형태음운규칙에서 얻을 수 있는 것과는 본질적으로
다른 "표시의 계층" 을 제시한다는 것을 밝혔다. 문법의 세째 부분 [형태음운론]
에 포함되는 명 계층에서는 일반적으로 한 언어표현이 구성요소의 단일연결체 (a
single sequence of elements) 로 표시된다. 그러나 구절구성은 순위를 가진 계층으로
구분할 수가 없다. 즉, 구절구성의 계층에서는 한 언어표현이 상하의 순위를 붙일
수 없는 연결체의 한 집합으로 표시된다.ⓧ 이때의 연결체의 한 집합은
(15) 형 도표와 대등한 것이 된다. 변형계층에서는 하나의 언어표현은 핵문 (좀더
정확히 말하면, 핵문의 기조가 되는 연결체) 에서 시작되는 유도과정에 사용된 좀더
추상적인 변형규칙의 한 연속으로 표시된다. 이러한 모든 경우를 포함하는 "언어학적
계층 (linguistic level)" 에 대한 보편 타당한 정의를 내릴 수 있다. (주석
: 필자의
The logical structure of linguistic theory 와 Transformational Analysis
를 참조하라.) 그리고 이러한 명명의 구조를 언어학적 계층으로 설정하는 근거에
대해서는 뒤에 언급하겠다.
적절하게 형성된 변형분석 (transformational analysis)
이 본질적으로 구절구성에 의한 기술보다 훨씬 좌측부터 우측으로 생성하는 유한사태의
Markov 과정에 의한 기술보다 본질적으로 더 강력하다는 것과 마찬가지이다. 이미
예를 든 바 있는 (10 iii) 형의 언어는 무제약규칙 (context-free rule) 으로 이루어진
구절구성기술의 한계를 벗어나며 변형규칙에 의해야만 비로소 유도될 수 있다. (주석
: 최초연결체가
Sentence 가 되고 a 와 b 들로 형성된 모든 무한연결체의 집합을 최종산출 (terminal
output) 로 하는 [Σ, F] 형 문법을 G 라고 하자. 이런 문법은 실재하고 있다. 그리고
G 를 구절구성부분으로 하고, Sentence 인 K 에 작용하여 이것을 K+ K 로 전환하는
변형규칙 T 로 보강된 문법을 G´ 라고 하자. 그러면 (10 iii) 이 G´의
산출 (output) 이 된다. §4.2 를 참조하라.) 여기에서 간과할 수 없는 중요한
사실은 변형계층을 첨가함으로써 사실적으로 문법을 간결화할 수 있다는 것이다.
그 이유는 변형규칙을 가짐으로써 구절구성은 직접 핵문을 기술하는 데에만 사용하게
되기 때문이다. 다시 말하면, [Σ, F] 형 문법은 핵문의 기조를 이루는 최종연결체만을
유도한다는 것이다. 따라서 [Σ, F] 의 기술로 용이하게 유도되는 최종연결체가 기조가
되는 문장을 핵문이라고 하며, 반면 이것에 맞는 변형규칙을 간단한 방법으로 최종연결체에
적용하면 다른 모든 문장이 유도될 수 있다.ⓨ 변형분석이 문법을 간결화하는
예를 여기까지 이르는 동안 몇 가지 볼 수 있었다. 앞으로도 이러한 것을 좀더 살펴
보겠다. 영어의 전면적인 통사론연구를 해 보면 더 많은 경우를 찾아낼 수가 있다.
(35) 형 문법에 대하여 오해하기 쉽기 때문에 한가지
언급해 둘 것이 있다. 위에 말한 문법들은 문장생성의 방안으로 제안된 것이다. 그런데,
문법은 청자 (hearer) 의 입장보다 화자 (speaker) 의 입장에서 이루어 졌다는 견해를
가지고 (35) 와 같은 경우, 문법이 균형을 잃고 있다는 (assymmetry) 생각을 이따금
갖게 한다. 다시 말하면 문법이론이 언어표현의 종합과정 (synthesis) 에 치중하고
언어표현구조의 분석과 재구 (reconstruction) 에는 관계가 없는 것처럼 인식하고
있다. 사실상 지금까지 논의되어온 문법형들은 화자와 청자라는 입장과 언어표현의
종합과 분석이라는 입장에서 중립적 (neutral) 이었다. 문법은 하나의 주어진 언어표현을
어떻게 종합하느냐 또는 분석하느냐 하는 문제와는 관계가 없다. 실재에 있어서 화자와
청자가 수행하는 양쪽 기능이 본질적으로 동일하며, 양자가 모두 (35) 형 문법의
범위 밖의 것이다. 명명의 문법은 그 문법이 생성하는 언어표현집합의 단순한 기술에
불과하다. 또한 이러한 문법은 그 문법이 기술하는 언어표현간의 형식상의 문법적관계를
구절구성과 변형구조등의 개념으로 재현한다. 이와 같은 문제는 구조상 가능한 화합물
(compounds) 에 관한 화학이론의 일부와 비유하여 생각하면 명백해질 수 있다. 화학이론이
천연적으로 가능한 모든 화합물을 생성할 수 있다는 논거는 문법이 문법적으로
"가능한" 모든 언어표현을 생성한다는 것과 같다. 또한 본 화학이론이
특종 화합물의 정성분석 (qualitative analysis) 및 종합에 대한 방법의 기반을 이룬다
함은
특종 언어표현에 대한 분석 및 종합의 특수 문제해결을 문법에서 찾는다는 것과 마찬가지이다.ⓩ